EtherCAT主站循环周期计算
EtherCAT通用架构主站通讯周期分析
- 主从站模型分析
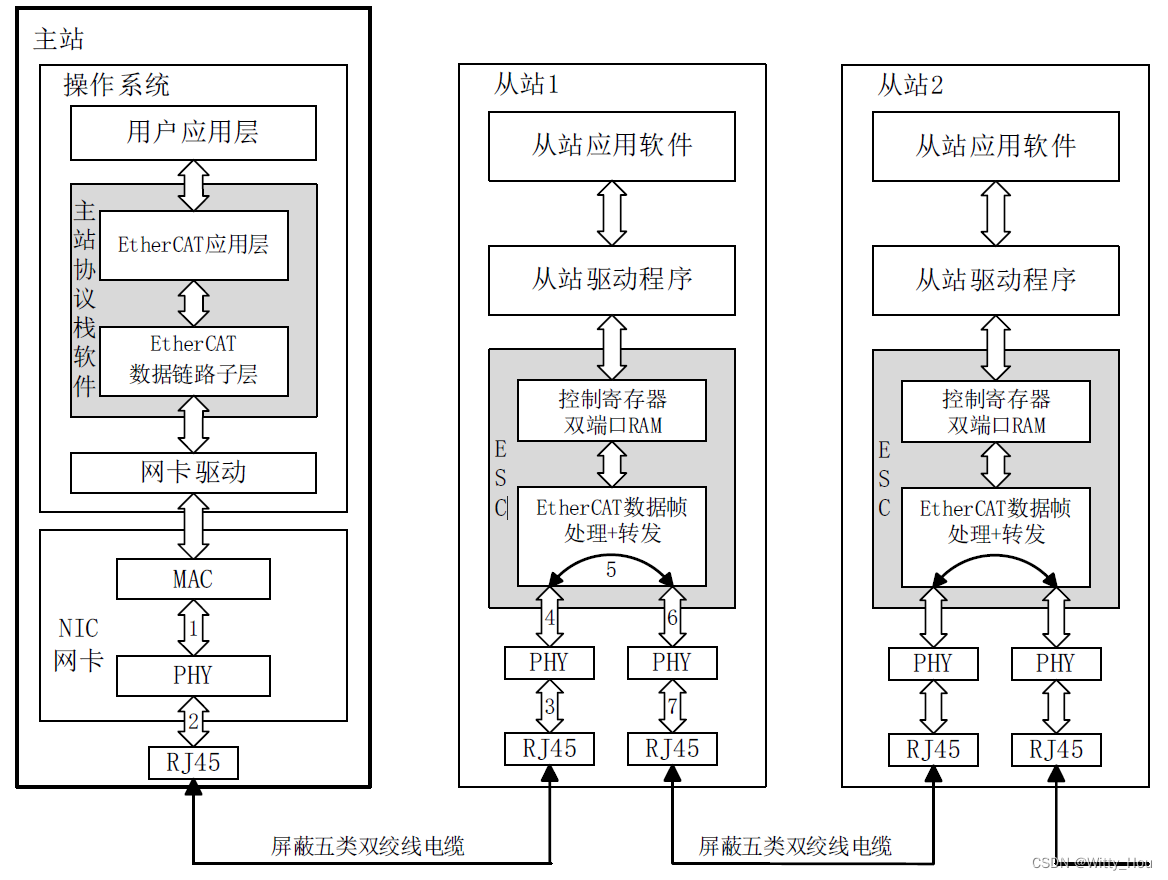
主站模型分为用户应用层、主站协议栈软件、以太网数据链路子层和以太网物理层等四个部分。
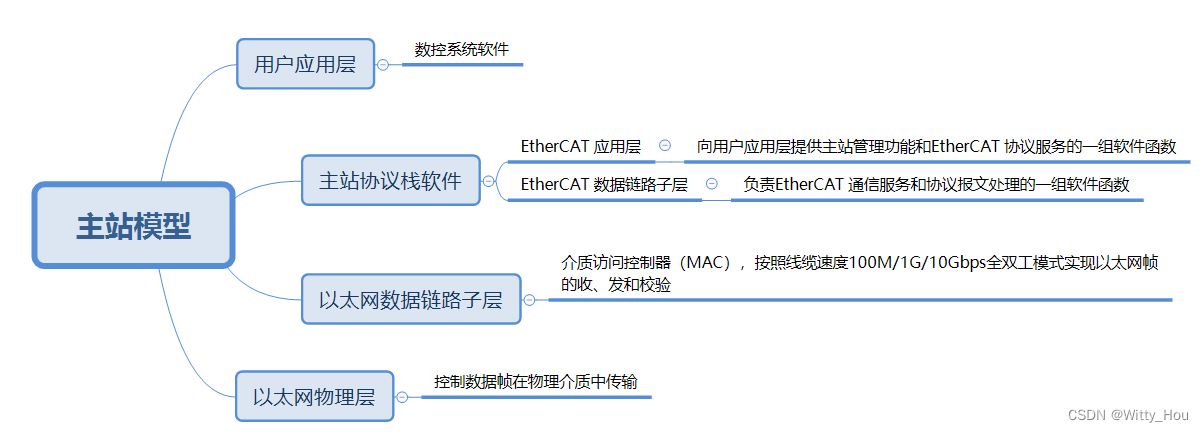
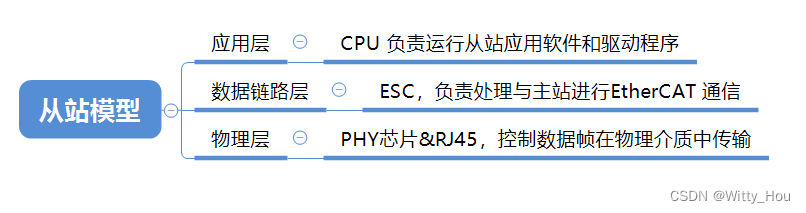
从站模型可以分为应用层、数据链路层、物理层三个部分。
- 一个完整循环周期时间分析
在执行周期通信任务的过程中,假设CPU 没有被其他中断信号打断,从周期中断发生到周期通信报文全部处理完毕,整个过程所耗费的时间Tround是EtherCAT 通信系统的周期通信时间,也是最小通信周期,可通过下式表示:
Tround = Tsoft + Thard
式中,Tsoft 为通信过程中软件执行的时间,Thard 为通信过程中数据帧在网卡设备和从站组中的传输时间。
在一次周期通信过程中,软件执行过程如下图中a所示,其中处于“TX 通道DMA 线程唤醒”和“RX 通道DMA 描述符更新”两个事件之间的一段区间为数据帧在网卡设备和从站组中传输的过程,该过程如下图中b所示。
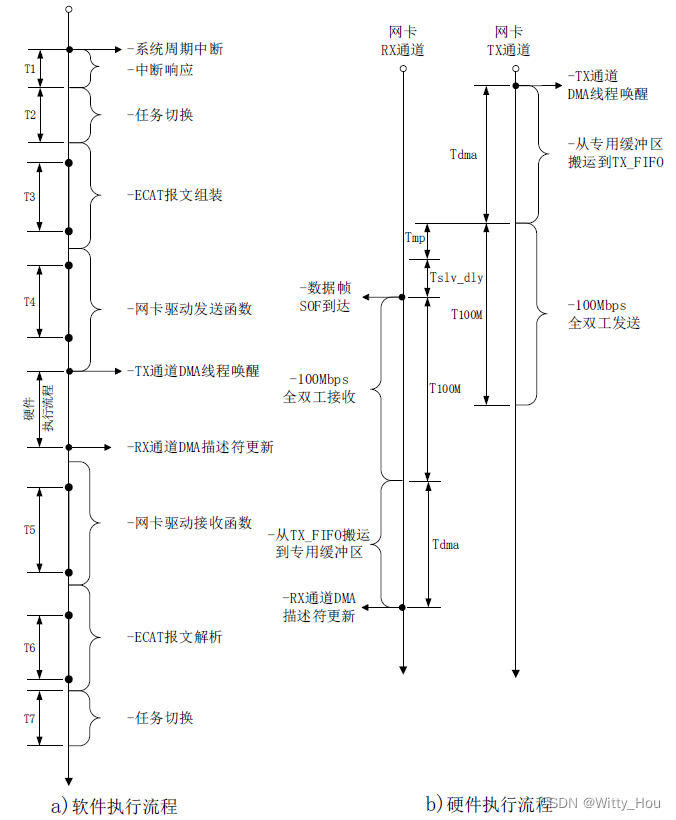
信号在不同模块间的调度关系见下图,与上图各时间段进行对比参考。
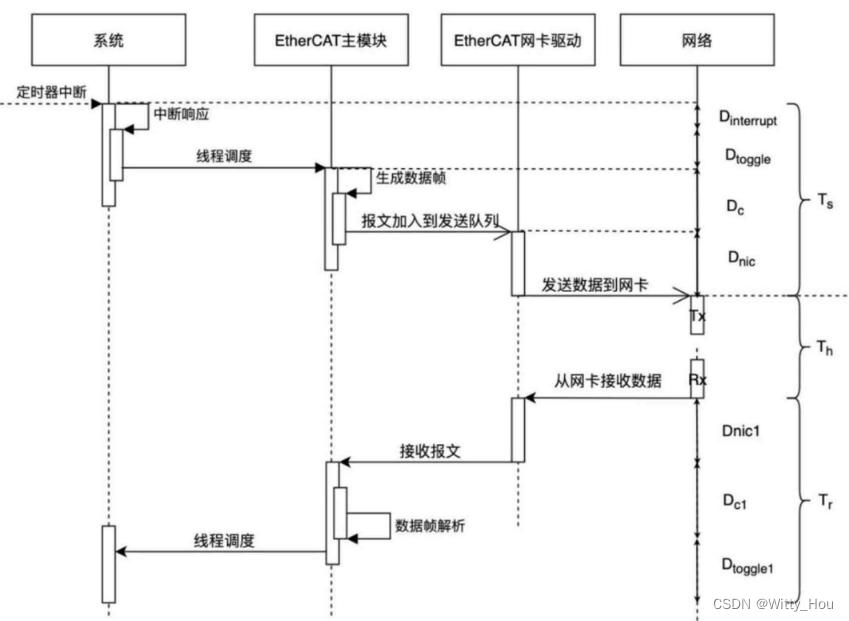
图中各时间段的含义解释见下表:
|
时间戳 |
含义 |
|
T1 |
CPU响应中断信号 |
|
T2 |
中断退出后立即进行任务切换 |
|
T3 |
在一块内存缓冲区A 中组装过程数据报文,将位于内存的整个过程数据镜像拷贝到过程数据通信子报文的数据域 |
|
T4 |
将缓冲区A 的报文拷贝到缓冲区描述符指向的DMA 专用缓冲区tbuf1 中 |
|
T5 |
当CPU 检查到缓冲区描述符的状态被DMA更新,立即将缓冲区描述符指向的DMA专用缓冲区rbuf1 的数据拷贝到内存缓冲区B中 |
|
T6 |
调用主站协议栈数据链路层的函数对缓冲区B中的报文进行解析。在解析的过程中,需要将过程数据通信子报文数据域的过程数据拷贝到位于内存的整个过程数据镜像区 |
|
T7 |
向系统申请任务切换 |
|
Tother |
所有的函数调用和除内存拷贝之外的其他指令所耗费的时间。 |
主站内部各时间戳含义
Tsoft = T1 + T2 + T3 +T4 + T5 + T6 + T7 + Tother
|
时间戳 |
含义 |
|
Tdma |
TX通道的DMA线程被唤醒后,DMA 线程将专用缓冲区tbuf1中的数据搬运到MAC的TX FIFO 中 数据帧接收完毕后DMA将RX FIFO 中的数据搬运到DMA专用缓冲区rbuf1 |
|
T100M |
搬运完毕后MAC 开始以100Mbps 全双工的模式发送数据 目前还有1Gbps和10Gbps可选,可以缩短数据在线上传输的时间,但是成本会更高 |
|
Tmp |
主站物理层器件附加延迟 |
|
Tslv_dly |
从站组的总传输延迟 |
主站外部各时间戳含义
Thard = Tdma×2 + Tmp + Tslv_dly + T100M
- 主站外时间Thard分析
- Tdma 是DMA 搬运数据帧的环节
通过参考文献《曹宗凯, 胡晨, 姚国良. DMA在内存间数据拷贝中的应用及其性能分析[J]. 电子器件, 2007(01):311-313》中给出的结论来取得该参量的典型值,该文献基于ARM 架构的测试平台对DMA 数据搬运进行了测试,测得DMA在Brust size 为8bit 的情况下数据搬运速率为15.9MB/s,可换算为平均搬运1Byte 数据耗时约为0.06μs,DMA搬运数据帧为128Byte(下面会解释这个数据怎么来的)
Tdma = 128Byte * 0.06us = 7.68us
- Tslv_dly是所有从站导致的时间延误累计。
Tslv_dly = (Tpc + Tfw + (Texrx + Textx + Tcable)×2)×i - (Texrx + Textx+ Tfw)
其中ESC芯片一般支持两种物理接口模式:E-BUS 和MII,AX使用MII接口连接PHY与MAC,信号延迟大约在数百纳秒,在计算从站传输延迟时不可忽略。
见下图所标注的路径3 到路径4(或路径7 到路径6)表示数据流从差分信号电缆(PMD Input Pair)进入PHY,经过PHY 译码后发送到MII 接口的RXD[3:0],引入的信号延迟设为Texrx。
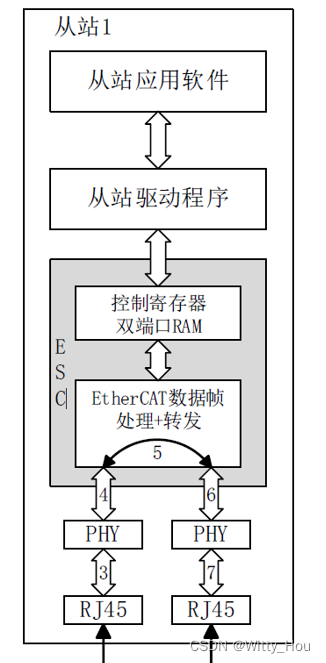
见上图所标注的路径6 到路径7(或路径4到路径3)表示数据从MII 接口的TXD[3:0]发送到PHY,经过PHY 编码后发送到差分信号电缆(PMD Output Pair),引入的信号延迟设为Textx。
根据《白杨, 孔维刚, 张立辉, 等. 一种AFDX网络的低时延光电信号转换设备设计[J]. 电子技术, 2015,44(07):1-4. 》中的研究结论,在全双工模式下,发送时序及接收时序见下方二图:
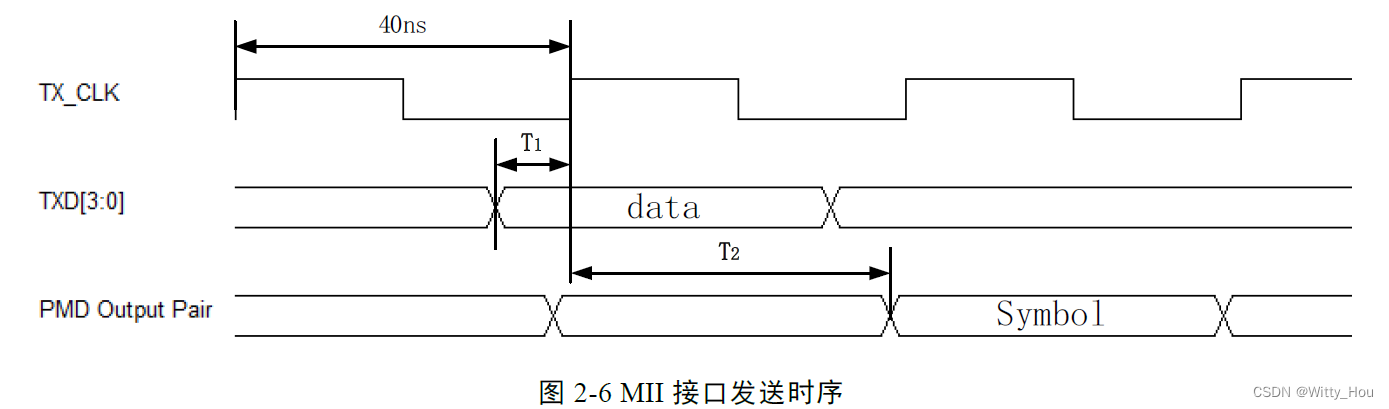
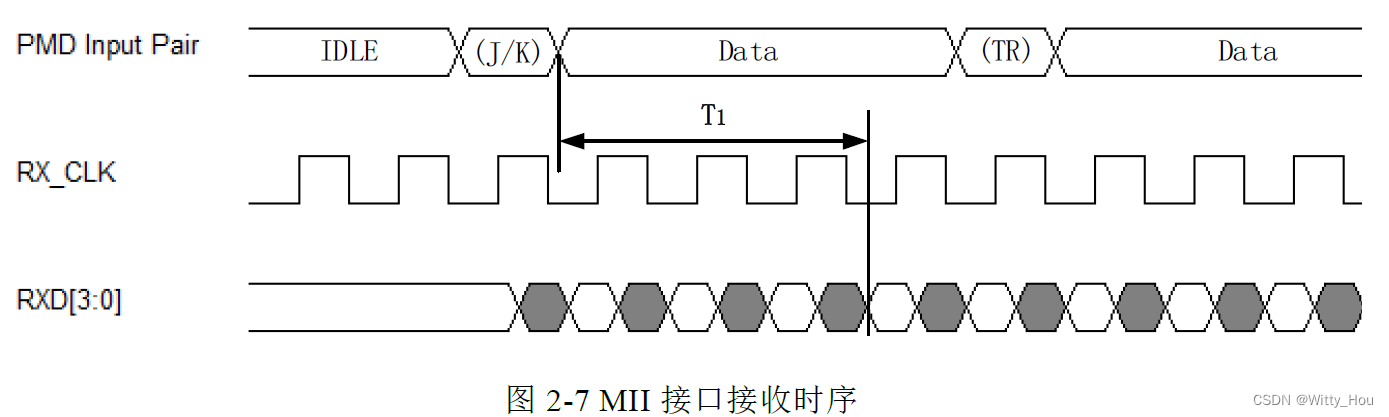
Textx 为图2-6 中T1 + T2,T1 为TX_CLK 周期(40ns)的1/4,根据上述文献可知,T2 的典型值为110ns,因此Textx 取值为120ns。Texrx 为图2-7 中T1,根据上述文献可知,T1 的典型值为380ns,因此Texrx 取值为380ns。
Tcable为电信号在电缆中的传播延迟。
在同一次通信过程中,如果数据帧是首次经过从站,由ESC 数据帧处理单元动态地提取或插入数据并转发给相邻从站,该过程耗费的时间称为处理延迟Tpc;如果数据帧非首次经过从站,则绕过ESC 数据帧处理单元,直接转发给相邻从站,该过程耗费的时间称为转发延迟Tfw。AX数据手册中未提及处理时间和转发时间相关的信息,这点参考倍福ET1100/ET1200中的描述:
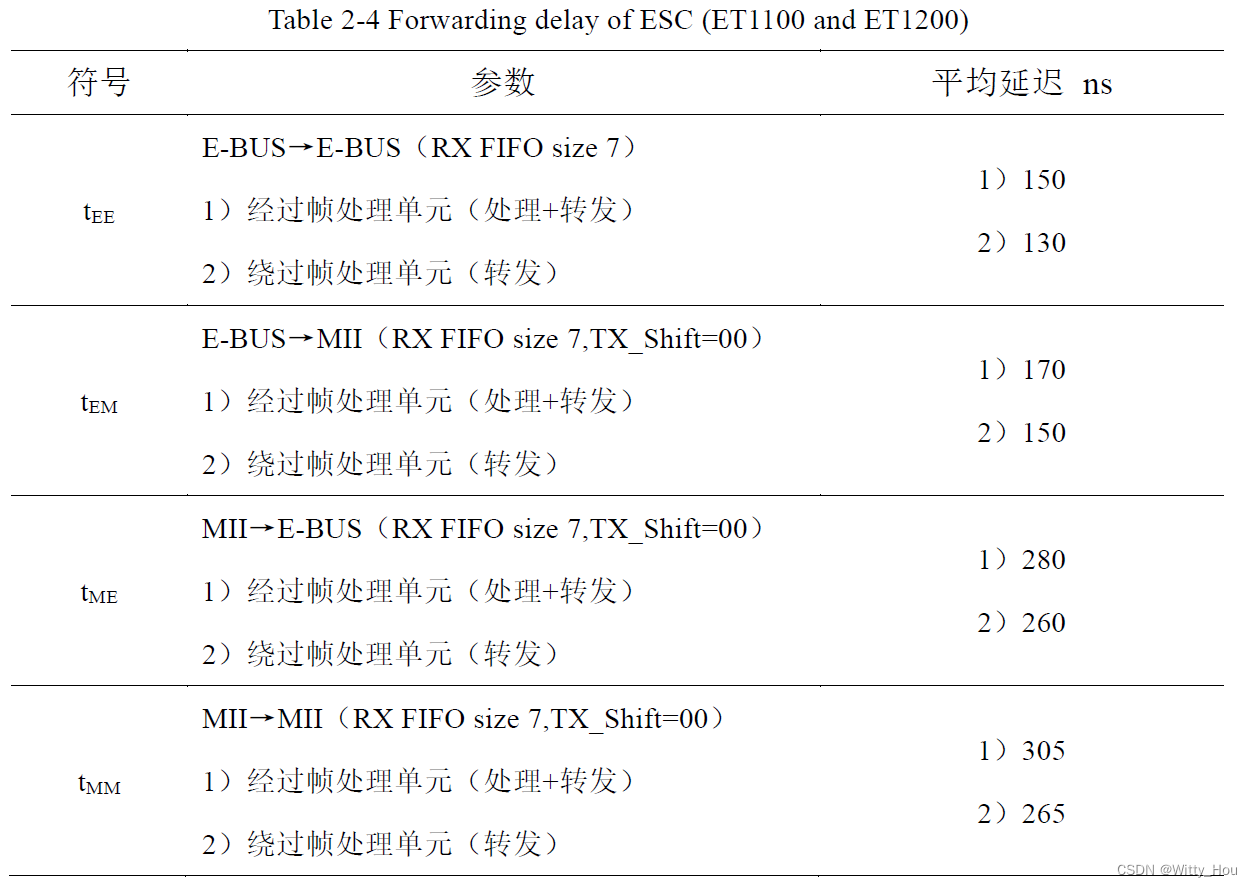
根据从站组的硬件配置,即全部采用MII 接口,因此Tpc 和Tfw 分别取值为305ns和265ns。通常电信号在双绞线电缆中的传播速率为7ns/m,每个从站分配的电缆长度按2m计算,因此Tcable 取值为14ns。
按照上述的值带入公式可得:
Tslv_dly = (305ns + 265ns + (380ns + 120ns + 14ns)×2)×i - (380ns + 120ns + 265ns)
= (1598×i - 765)ns
当前我们的拓扑设计为1主4从,所以Tslv_dly=5.627us
- Tmp 为主站系统的物理层附加延迟
根据此前的MII 接口时序分析:
Tmp = Textx + Texrx = 120ns + 380ns = 500ns = 0.50μs
(4)T100M 为140Byte(8Byte 前导码和帧开始界定符+128Byte 帧数据+4Byte CRC32校验码)的数据流在100Mbps的速率下传输:
T100M = 1120/100M = 11.2μs
将上述各时间戳带入公式:
Thard = Tdma×2 + Tmp + Tslv_dly + T100M
Thard = 7.68*2 + 0.5 + 5.627 + 11.2 = 32.687us
- 主站内时间Tsoft分析
(1)T1、T2 和T7 是Linux 的中断响应和任务切换环节,通过参考文献的研究结论来取得这3个参量的典型值。该文献基于频率为2.2GHz的x86架构处理器、1GB 内存的硬件平台,对增加实时抢占补丁的Linux 操作系统的实时性进行量化测评,实时补丁的类型分别为Preempt RT、Xenomai 和RTLinux,测试对象为中断响应延迟和任务切换延迟,测试数据如下图:
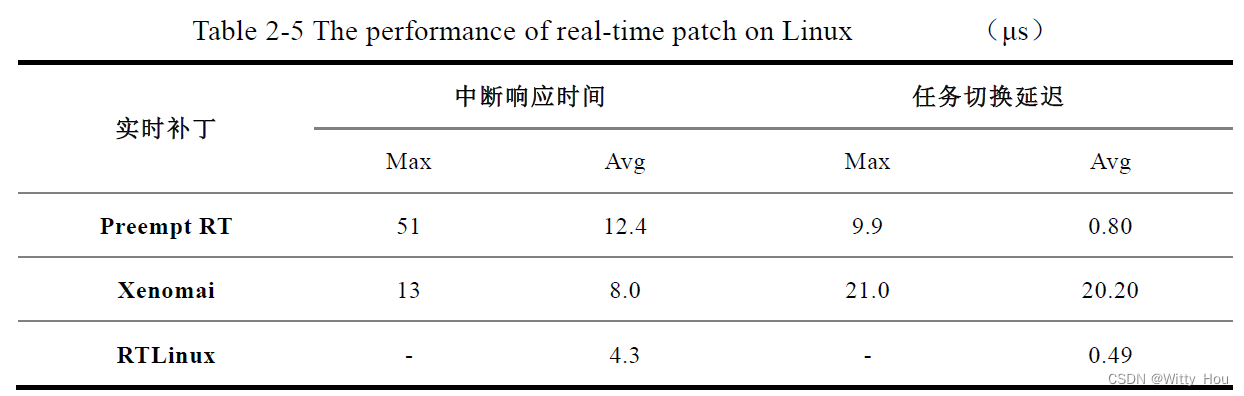
目前我们采用的补丁是Xenomai,理论计算时按照最大取值,因此取:
T1 = 13us 、T2=T7=21us
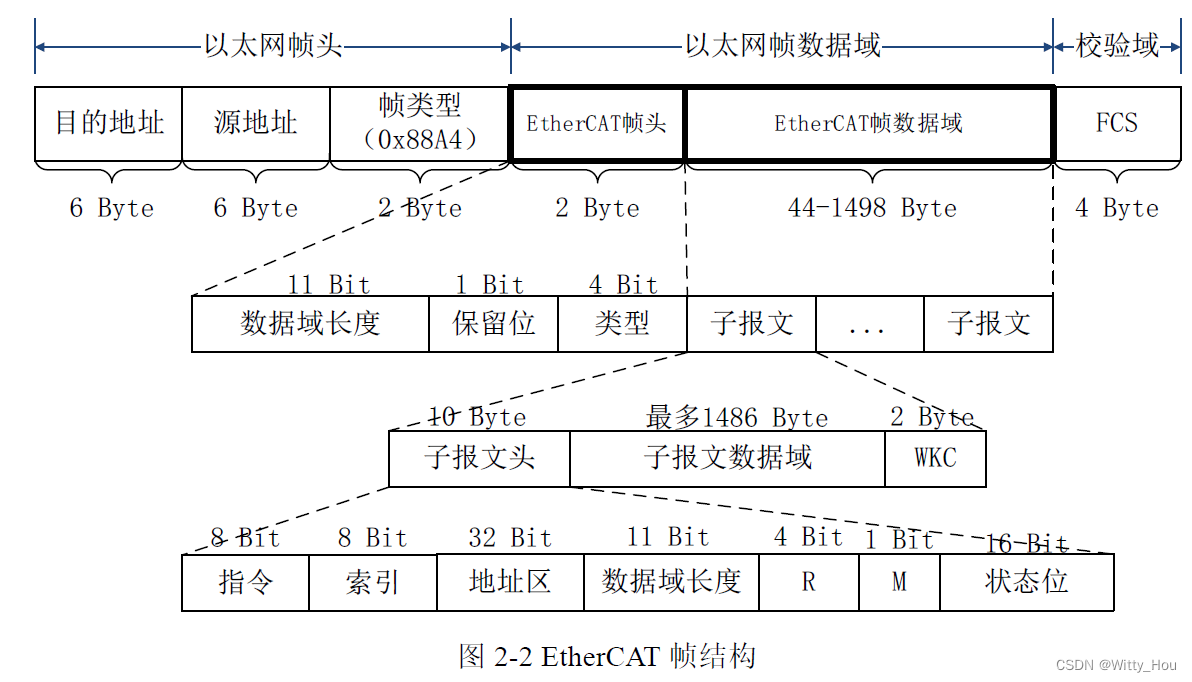
(2)T3 和T6 环节均为在内存中进行100Byte的过程数据数据拷贝、T4和T5 环节均为128Byte 的周期通信报文拷贝。
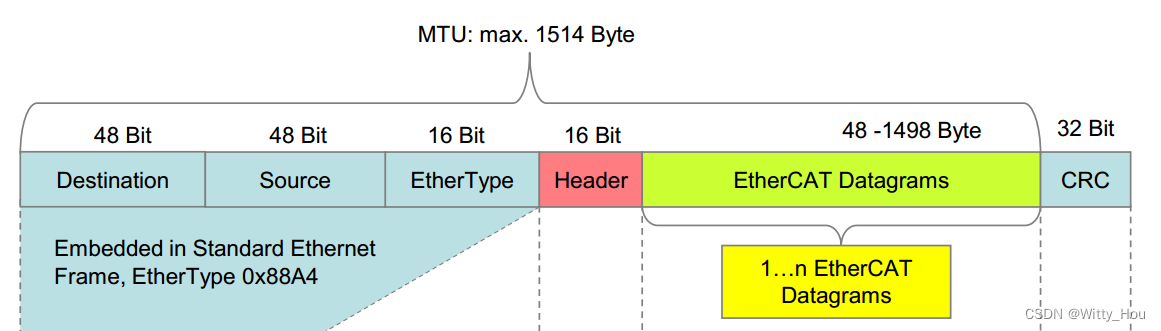
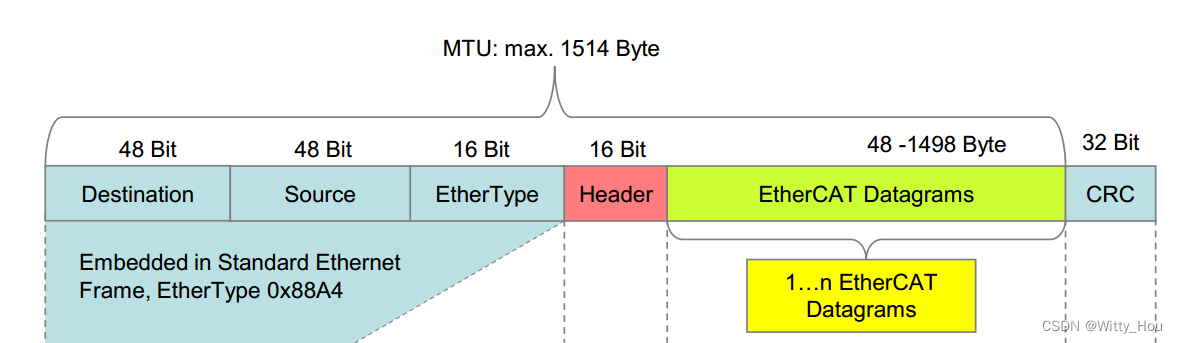
关于上方两个数据量的计算参考下图中帧结构,100Byte指的是子报文数据域中的数据长度,它不一定非得是100取决于你的需要设置的信息长度。
它有一个下限,倍福官方手册给的数据是最小48byte,就按照倍福的值来计算最小数据长度,48Byte中包含了12Byte的必备数据,留给用户可填写的就是36Byte,因此单次发送的数据帧最小也得是36Byte,如果你写的数据不够36Byte,EtherCAT协议会自动补齐到36Byte。
128Byte是100Byte数据加上了10Byte子报文头、2Byte的WKC、2Byte的EtherCAT帧头和14Byte的以太网帧头,一共是100+28=128Byte
通过参考文献的研究结论来取得这4个参量的典型值。

文献[52]基于ARM 架构的硬件平台对memcpy 函数进行测试,在不使用cache 的情况下,memcpy函数平均1Byte 耗时0.1μs。
文献[53]基于ARM11 体系架构处理器平台,使用精度为1μs 的系统时钟来测得memcpy函数拷贝1KB 报文耗时103μs,可换算为每拷贝1Btye 数据耗时0.1μs。
根据两个文献的测试结果可知,ARM 架构的CPU 平均拷贝1Btye 数据耗时0.1μs。
因此T3=T6=100*0.1=10us、T4=T5=128*0.1=12.8us
将上述各参数带入可得:
Tsoft = T1 + T2 + T3 +T4 + T5 + T6 + T7 + Tother
= (13 + 21 + 10 + 12.8 + 12.8+ 10 + 21)μs + Tother
= 100.6μs + Tother
将 Tsoft 和Thard 代入式(2.1),可得一次周期通信的总传输时间
Tround = Tsoft + Thard = 100.6μs + Tother + 32.687μs = 133.287μs + Tother
内容参考论文:面向高速数控装备的EtherCAT主站技术研究_苏攀杰
其中后段关于使用双芯片缩短主站循环周期的部分大家有需要可以下载原文学习,内容很棒

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)