基于深度学习的自动驾驶实现
深度学习与自动驾驶
摘要
在本文中,我们研究了使用TensorFlow进行自动驾驶任务的深度学习方法。通过在类似于奥迪自动驾驶杯和卡罗洛杯的交通场景中使用比例模型车辆,我们成功地将深度学习模型应用于车道保持和交通标志识别这两个独立任务。
关键词
深度学习,自动驾驶,无人驾驶车辆,TensorFlow,车道保持,交通标志识别
一、引言
近年来,自动驾驶汽车已逐渐成为学术界、工业界和主流消费者的关注焦点。这些系统的最终目标是实现完全自动驾驶自动化,即美国交通部国家公路交通安全管理局(NHTSA)定义的车辆自动化等级中的最高等级[1][2]。
道路上的安全性通常被认为是开展自动驾驶汽车和驾驶机器人研究的首要原因;然而,车辆自主性的集成所带来的好处还包括提高时间效率和利用率、减少基础设施负担、降低环境污染以及改善燃油经济性[3]。
集成车辆自主性需要系统具备感知真实环境并动态应对各种情况的能力。在其最基本层面,这要求能够实时感知车道、障碍物和交通标志,并采取相应行动。
本文研究了深度学习在树莓派3B等低功耗、低成本且易于获取的硬件上实现车道检测与控制以及交通标志感知功能的能力。
所提出的车道保持和交通标志检测与识别解决方案旨在满足卡罗洛杯规定的要求,并将在西澳大利亚大学(西澳大学)机器人与自动化实验室开发的缩放驾驶机器人上运行,具体内容将进一步讨论。
从理论上讲,这些发展成果也可以移植到移动电话设备或廉价的单目驾驶员辅助系统,并安装到现有车辆上以实现一定程度的自动化。车道检测能够以类似于博特点或凸起路面标记的方式提醒驾驶员其车辆正在车道内偏离:可以发出警报,提醒那些未察觉或分心的驾驶员。交通标志识别则可用于提醒驾驶员最近经过的交通标志,从而提高整体安全性。
A. 深度学习
深度学习涉及在输入层和输出层之间训练具有多个隐藏层的人工神经网络。除了全连接层外,卷积神经网络(CNNs)是一类深层神经网络,采用卷积层和池化层。在计算机视觉领域,它们在图像分类和识别任务中已取得巨大成功[4]。对于自动驾驶系统而言,卷积神经网络(CNNs)提供了识别道路上或周围交通标志和障碍物的重要手段。
除了被动识别外,卷积神经网络还被证明能够在驾驶过程本身中发挥作用[5]。
B. 模型车竞赛
卡罗洛杯是由布伦瑞克工业大学(德语:德国布伦瑞克工业大学)[6][7]主办和承办的一项国际学生竞赛。它延续了缩比车辆实现与设计竞赛的传统,例如奥迪自动驾驶杯[8]和MAGIC 2010[9]。
这些竞赛以及缩放实现通常为学生提供了一个平台,使他们能够参与自动驾驶机器人的设计与实现,而无需面对诸多原本会限制学术研究的障碍。这些障碍包括全尺寸自动驾驶车辆所固有的高资金成本、风险与安全问题,以及为现实世界开发实际解决方案所涉及的整体复杂性。

EyeBot嵌入式控制器平台由布拉恩尔教授和西澳大利亚大学机器人与自动化实验室开发,具备多种功能,可用于自动驾驶机器人研究[10][11][12]。SoccerBot系列机器人是基于EyeBot平台和RoBIOS(机器人BIOS)构建的两轮差速驱动机器人。当前版本的硬件包括树莓派3B、EyeBot输入输出板和PiCamera[12]。
卡罗洛杯包含两类赛事:静态赛事和动态赛事。在动态赛事中,将根据自由驾驶与停车项目以及避障赛道来评估驾驶机器人的表现。
类别 1:自由驾驶与停车
在卡罗洛杯的第一项动态赛事中,车辆需在给定时间内自主行驶尽可能远的赛道距离。赛道标有平行车道,设计用于模拟具有直线路段、交叉路口以及大量急弯和大转弯的乡村道路条件。
除了车道保持外,还将评估车辆检测和识别停车标志的能力。如果识别到停车区域,则会评估车辆执行平行泊车和垂直泊车的能力。
类别 2:避障赛道
第二项动态赛事在道路上增加了静态和动态障碍物,并取消了泊车操作挑战。

2018年,KitCar团队凭借其参赛车辆“Dr. Drift”赢得了卡罗洛杯。目前没有直接可用的论文来讨论该团队在车道保持或交通标志检测方面所采用的技术。为了与我们的解决方案进行对比,我们分析了他们参赛作品的视频资料,视频链接如下:[13]。
C. 我们的贡献
本文其余部分将讨论针对卡罗洛杯车道保持和交通标志识别挑战所提出的解决方案,以及这些方案在SoccerBot差速驱动机器人上的实现。
为了完成车道保持任务,采用了一种基于英伟达的车道保持研究成果的先进深度学习方法,因其具有适用于实际应用的潜力[5]。所提出的方法与英伟达的方法不同之处在于,它是单目的,并且网络输出适用于差速驱动机器人;因此,该方法可用于进一步的研究或缩放至实际应用。
工业界用于低成本目标检测和交通标志识别的最新架构是MobileNet-SSD;然而,对于基于ARM的树莓派3B上,该解决方案无法维持卡罗洛杯所需的足够FPS(每秒帧数)。我们提出了一种实时交通标志检测流程,该流程采用HSI阈值分割生成直方图,从直方图中提取感兴趣区域(ROI),然后使用轻量化MobileNet进行分类,接着利用直方图对检测结果拟合边界框。
II. 使用深度学习进行车道保持
人们已经提出了多种自动驾驶方法来实现可靠且平稳的车道保持,其中英伟达[5]开发的方法是最有前景的方法之一。该方法在全尺寸车辆上进行了测试,是一种端到端控制方法,将道路的输入图像输入图3中的网络,网络输出特定的方向盘转角。然后操纵汽车的方向盘以匹配网络输出的值。
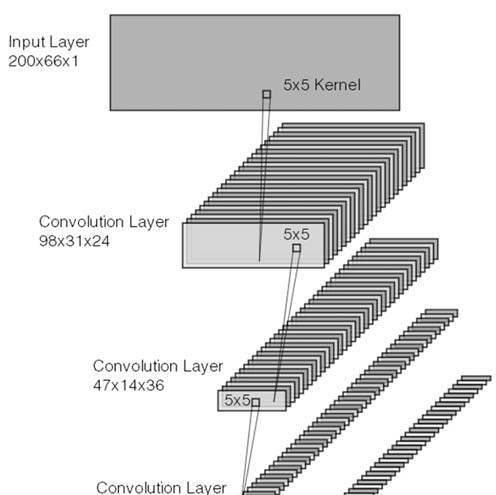
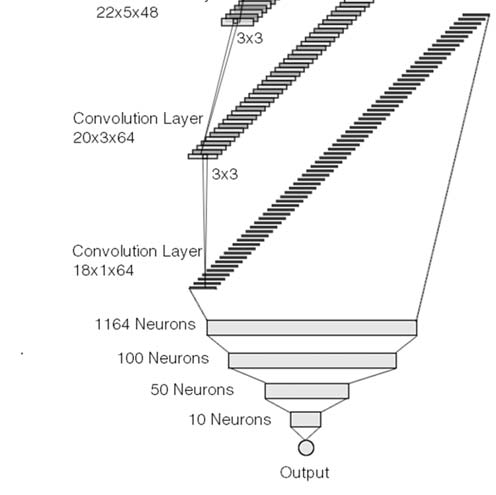
英伟达端到端神经网络在商用车辆上进行了设计和测试,其机械构型类似于阿克曼驱动机器人。这些实验的目的是扩展并验证相同的策略可以成功应用于具有单个摄像头的差速驱动转向构型。
A. 环境传感器和测试环境
用于自动驾驶任务的机器人是SoccerBot,且在机器人可用的传感器中,仅使用了摄像头来收集有关环境的数据。该机器人采用差速驱动轮配置,其前进速度和角速度可由RoBIOS软件独立控制。用户可以以毫米每秒为单位设置机器人的前进速度,也可以以度每秒为单位设置其角速度。这些指令将发送到机器人的底层功能模块,并在那里进行控制,无需用户进一步输入。
一个用于EyeBot机器人的仿真系统,称为EyeSim-VR,可在此处获取:http://robotics.ee.uwa.edu.au/eyesim/。该模拟机器人具备实际机器人的所有功能,允许在计算能力更强大的无干扰环境中开发和测试方法。自动驾驶系统首先在此系统中进行训练和测试,然后才转移到实际机器人上。
实际测试环境是对Carolo杯测试赛道的调整,由于空间限制进行了缩放。该测试轨道包含多种不同的道路构型,包括直道、带人行横道的直道、交叉口、弯道以及车道线缺失的弯道。
B. 硬件的实际限制
所使用的摄像头为树莓派摄像头模块V2,其水平视场角为62.2度,垂直视场角为48.8度[13]。摄像头位于机器人顶部,如图2所示。由于摄像头的物理位置,导致机器人前端与摄像头视场边缘之间存在约12厘米的盲区。
在某些情况下,这可能导致机器人在狭窄空间中无法使用摄像头充分地对环境进行建模。
树莓派的处理能力远低于完成此任务所需的水平。这导致在实体机器人上实现时帧率降低。本文这一部分的目的是在小规模环境中复现并调整该网络,因此尚未对网络进行重大修改以解决此问题。
一个重要的限制是摄像头配置。该自动驾驶系统的初始实现基于三个摄像头图像来训练系统:一个前向摄像头以及位于车辆左右两侧的摄像头[5]。我们采用了一个单一的前向摄像头,虽然这限制了网络可获取的环境信息量,但计算成本更低,也更易于实现。
C. 控制方向
最初实现的网络存在一个主要问题,即无法控制其方向性。例如,在交叉口处无法指定期望的方向,如果使用所有可能的场景来训练单个网络,则很难在执行动作之前判断机器人将朝哪个方向移动。
为避免这种情况,训练了多个网络。每个网络都被训练成在没有选项时正常驾驶。当遇到交叉口情况时,一个网络被训练为直行,另一个网络被训练为左转,最后一个网络被训练为右转。然后可以同时加载这些网络,并选择与期望动作一致的网络来确定转向角度。
D. 网络输出变量
SoccerBots不使用方向盘;因此,神经网络需要采用不同的输出变量。机器人软件具备根据线速度(单位为毫米每秒)和角速度(单位为度每秒)设置车速的功能;因此,网络输出必须使用这两个潜在输入中的一种或两种。如果仅基于角速度训练网络,将限制机器人只能以单一的线速度行驶。为避免这一问题,项目团队为网络创建了不同的输出变量。该变量是机器人角速度与线速度之间的比率,单位为度每毫米。该方程在非零线速度且角速度不超过线速度的条件下建立。随后对该输出变量进行了缩放,以更好地模拟网络最初设计时所针对的亮度值范围。
$$
\text{Network Output} = \frac{\text{Angular Speed}}{\text{Linear Speed}} \quad (1)
$$
这样做的目的是生成与速度无关的输出,以便机器人理想情况下可以在任何速度下行驶。在具有持续变化的速度输入的实际环境中,该变量假设两个变量能够以大致相同的速率达到期望速度。
E. 数据收集
该驾驶任务的训练数据包括一张灰度输入图像以及机器人在拍摄图像时的角速度-线速度比。训练图像以每秒5帧的速率采集。为了获取这些训练图像,使用游戏控制器手动驱动机器人在测试轨道上行驶。机器人在赛道的两个方向上均进行了行驶,每个方向大约采集了1000张测试图像。训练数据仅针对左车道的驾驶情况进行采集。机器人的行驶速度为100毫米每秒,以确保操作者能够充分控制机器人并生成平滑的训练数据。该过程在模拟器和实体机器人上均进行了实施。对于实体机器人,图X展示了在24小时周期内进行的训练。显然,该方法要具备可行性需要大量的训练。
F. 可靠性评估
驾驶系统的可靠性可以通过为防止偏离车道而需要的干预次数与驾驶时间的对比来表征。英伟达自动驾驶系统将驾驶自主率(A.R.)量化为[5]:
$$
\text{A.R.} = 1 - \frac{N(\text{interventions})}{\text{Elapsed Time (seconds)}}
\quad (2)
$$
项目团队使用此作为衡量驾驶可靠性的通用基准。然而,在该模型下,即使赛道表现相同,不同的行驶速度也会影响自主率。这一指标对低速移动车辆和机器人具有有利偏差,这在本项目中是一个重要问题。因此,项目团队已将自主率的测量方式调整如下:
$$
\text{A.R.} = 1 - \frac{N(\text{interventions})}{N(\text{track segments}) + N(\text{completed circuits})}
\quad (3)
$$
轨道段的数量被定义为给定赛道上的独立驾驶任务数量。例如,直行到转弯再到直行构成三个独立驾驶任务。项目团队将测试轨道描述为具有十二个独立段。
鉴于项目的硬件限制,我们定义了两种不同的故障状态:
i. 接近事故:机器人部分或完全偏离车道但能够恢复。
ii. 失败:机器人完全偏离车道且无法恢复。
系统的自主水平通过排除接近失误的总故障次数以及包含接近失误的总故障次数来评估。
为了评估和比较本项目的成果,项目团队采用了两种方法。第一种是与以往Carolo杯冠军在已发布视频中表现出的可靠性进行比较。第二种是与项目团队掌握的另一种驾驶方法进行比较。该比较方法采用更传统的图像处理方法,利用霍夫直线检测车道并构建环境模型,然后使用PID控制器设定期望速度[14]。自动驾驶系统的响应性通过帧率来评估。
G. 结果
示例输入图像见图7,与这些输入相关的网络输出见表I。驾驶程序在50毫米每秒、100毫米每秒和150毫米每秒的速度下进行了测试。失败次数及相应的自主率如表III所示。

 弯道、(b)直路和(c)人行横道处。)
弯道、(b)直路和(c)人行横道处。)
| 图 | 网络 自动驾驶的深度学习 |
用户设定 线速度 (毫米/秒) |
确定 角速度 (度/秒) |
|---|---|---|---|
| 6. a | -0.11125 | 100 | -11 |
| 6. b | -0.000311 | 100 | 0 |
| 6. c | 0.00311 | 100 | 0 |
表I. 记录值的网络输出和行驶速度
| 速度 (毫米/秒) |
Avg. 失败次数 |
自主性 Rate | Near 遗漏 | 自主性 Rate |
|---|---|---|---|---|
| 50 | 0 | 100% | 2 | 83.3% |
| 100 | 0 | 100% | 2 | 83.3% |
| 150 | 4 | 66.7% | 2 | 50% |
表二。不同EyeBot速度下的测量自主率
| Avg. 失败次数 | 自主性 Rate | 平均 接近 失误 | 自主性 Rate |
|---|---|---|---|
| 0 | 100% | 1 | 91% |
表III. 卡罗洛杯演示中的实测自主率
这与2018年卡罗洛杯冠军在类似驾驶任务下的自主率进行了比较[11]。项目团队根据比赛视频测量了他们的自主率,如下所示:
项目团队记录的自主率低于之前的Carolo杯冠军。造成这一现象的可能原因是驾驶机器人上的摄像头配置。如前所述,假设地面平坦,机器人前方存在大约12到13厘米的盲区。这使得在故障状态发生之前难以检测到。
机器人具备较强的自我纠正能力,表明通过增加一个额外的摄像头或改变当前的摄像头配置,此问题可能得到解决。
机器人的自主水平已成功提升至100毫米每秒的速度。超过此速度后,机器人在弯道上容易出现严重且持续的失败。这些失败的原因是反应时间不足。机器人行驶速度过快,导致网络输出速率无法跟上,最终使其无法执行复杂的操作。项目团队此前实施的霍夫直线驾驶方法能够在测试轨道上以200毫米每秒的速度可靠行驶:这大约是SoccerBot的最大速度。因此,该方法的帧率被用作基于神经网络的驾驶解决方案的理想目标。
| 驾驶方法 | 最小值 | 平均值 | 最大 |
|---|---|---|---|
| 神经网络 驾驶 | 4 | 9 | 11 |
| 霍夫直线控制 | 13 | 16 | 20 |
表IV. 基于神经网络的驾驶软件与标准图像处理的帧率比较 (帧率(FPS))
基于神经网络的驾驶相较于图像处理的主要优势在于其通用性。神经网络控制策略能够在多种不同情况下工作,而传统的图像处理则需要手动处理特定场景。例如,在标准的图像处理驾驶程序中,最常见的失败点是交叉路口后的弯道处,此时视野中出现赛道的另一段,这种情况在算法上非常难以处理。相比之下,神经网络方法在此处从未失败。
神经网络还表现出在错误情况下通过返回正确车道实现自我纠正的能力。而霍夫直线方法则不具备这一能力,只会继续在新车道中行驶。
H. 未来改进
该项目的限制因素是驾驶系统的响应性。未来,项目团队应致力于在不牺牲准确率的前提下简化网络结构,以实现更快的行驶速度。此外,还将进一步扩充训练数据集以提高驾驶准确率。这将通过在驾驶程序中插入手动接管功能来实现。当用户检测到偏离车道时,可通过控制器进行驾驶修正,并利用这些新数据进一步训练网络。
III. 基于深度学习的交通标志识别
交通标志识别仍然是一个具有挑战性的研究领域,有许多研究者参与其中,部分原因在于光照和模糊效应、遮挡和部分遮挡以及标志退化所带来的多种挑战。
已经开发出大量解决方案;然而,许多方案对于树莓派3B等设备而言计算过于复杂,无法实时运行,或需要专用传感器。针对自动驾驶在计算能力受限设备上的进一步研究,可能会因现有解决方案的高要求而成为瓶颈,特别是那些采用卷积神经网络(CNN)等深度学习技术的现代解决方案。
传统上,交通标志检测方法分为基于颜色、基于形状和基于学习的方法[17][18]。基于学习的方法可进一步细分为采用CNN等深度学习算法的方法[19]。
在为IJCNN 2011举办的德国交通标志识别基准测试中,使用卷积神经网络(CNN)的多类交通标志识别系统已能够超越人类表现。比赛的获胜者IDSIA使用CNN委员会实现了99.46%的正确识别率;相比之下,人类表现的正确识别率为98.84%[20]。
A. 设计架构与限制
将基于卷积神经网络的交通标志识别能力(类似于在德国交通标志识别基准中展示的能力)集成到树莓派或移动设备等低成本且计算资源有限的设备中的动机是明确的。对许多用户而言,最基本的前提是在QVGA尺寸(320×240像素)图像上实现实时运行,并达到与人类表现相当的准确率。快速人工神经网络、卷积结构化深度学习框架和TensorFlow等深度学习库和框架的出现,为实现这一目标提供了途径。

由于树莓派3B的计算能力相对有限,因此无法直接使用SSD MobileNet-V2[21][22]等目标检测架构。英伟达对树莓派3及类似的单板计算机进行了基准测试,发现当输入分辨率达到480×272或更高时,SSD MobileNet-V2无法运行[23]。在SSD MobileNet-V2上,300×300的输入图像以1帧率运行,而416×416 Tiny YOLO V3能够以0.5帧率运行[23]。或者,改用图像分类而非目标检测,MobileNet-V2可在300×300图像上以2.5帧率运行[23]。
我们的交通标志检测方法比MobileNet-SSD更快,因为我们采用基于颜色分割的感兴趣区域候选生成方法,利用色调直方图在每帧中分析单个交通标志。然后使用MobileNet对感兴趣区域进行分类,并利用色调直方图实现定位检测。
我们设计并实现了一种交通标志识别系统,该系统结合了HSI阈值化与基于MobileNet卷积神经网络的物体识别技术(使用TensorFlow),用于检测卡罗洛杯中存在的一部分交通标志。在区域提议出现错误的情况下,系统还需能够对“背景”图像进行分类。该系统可在树莓派3上实时运行,并具备与其他功能(如车道保持)同时运行的能力。未来,可进一步引入其他区域提议方法,但可能会降低帧率。
我们开发的交通标志识别系统的流水线架构非常直接:首先捕获图像,将其从RGB转换到HSI色彩空间,然后使用HSI阈值化来提取感兴趣区域,这些感兴趣区域随后作为输入送入基于TensorFlow的MobileNet图像分类器,最后利用分类器输出的置信度来判断目标物体及其位置。

B. 感兴趣区域提议与定位
所涉及的预处理相对简单,因此不会详细讨论。首先捕获一帧图像,然后生成包含HSI值的矩阵。
通过HSI阈值化为彩色标志(例如停车和停车标志)生成感兴趣区域。该方法并不全面,因为比赛中的所有标志并非都具有明显的颜色区分。色调、饱和度和亮度的阈值是经验性地选择的。通过对图像帧应用一系列对应于不同标志颜色的HSI阈值,生成二值图像。
在二值图像上,分别为水平轴和垂直轴生成色调直方图,其中每个列或行的直方图区间分别对应前景像素的数量。然后为每个轴设置一个阈值,以减少噪声,该阈值为经验性选择。
如果帧中包含足够多的前景像素(由每个直方图上最大连续‘斑块’的宽度定义),则感兴趣区域中心的坐标将通过相应前景像素的均值计算得出。感兴趣区域的尺寸根据输入图像的分辨率选择。通常更高的分辨率会带来更高的推理准确率,但会对推理时间产生不利影响。我们采用的感兴趣区域高度和宽度均为128像素。
C. 面向树莓派的目标分类与优化
我们使用了大约1500张图像,对先前在ImageNet大规模视觉识别挑战赛数据集上训练过的神经网络进行重新训练。迁移学习通常被称为对模型进行“微调”:与从头开始训练神经网络的每一层不同,仅使用新数据集训练最后几层。选择MobileNets是因为其模型尺寸小、计算效率高以及相对较高的准确率[22]。

TensorFlow幸运地提供了一系列针对MobileNet-V1和其他架构的训练良好的模型,这些模型可重新训练以用于通用视觉分类任务。提供了多种MobileNet-V1图像分类模型,它们在输入图像分辨率和网络宽度倍增器方面有所不同。较高的分辨率通常意味着更长的推理时间以及更高的准确率。较小的宽度乘数对应较短的推理时间,但会以降低准确率为代价。
模型所需的内存与参数数量成正比。推理时间与专用MAC单元必须执行的乘加运算次数[24]。
| 模型检查点 | 百万 MACs | 参百数万 |
|---|---|---|
| MobileNet v1 1.0 224___ | 569 | 4.24 |
| MobileNet v1 1.0 192___ | 418 | 4.24 |
| MobileNet v1 1.0 160___ | 291 | 4.24 |
| MobileNet_v1_1.0_128 | 186 | 4.24 |
| MobileNet v1 1.0 0.75 224___ | 317 | 2.59 |
| MobileNet v1 1.0 0.75 192___ | 233 | 2.59 |
| MobileNet v1 1.0 0.75 160___ | 162 | 2.59 |
| MobileNet_v1_0.75_128___ | 104 | 2.59 |
| MobileNet v1 1.0 0.50 224___ | 150 | 1.34 |
| MobileNet v1 1.0 0.50 192___ | 110 | 1.34 |
| MobileNet_v1_0.50_160 | 77 | 1.34 |
| MobileNet v1 1.0 0.50 128___ | 49 | 1.34 |
| MobileNet v1 1.0 0.25 224___ | 41 | 0.47 |
| MobileNet v1 1.0 0.25 192___ | 34 | 0.47 |
| MobileNet v1 1.0 0.25 160___ | 21 | 0.47 |
| MobileNet_v1_0.25_128 | 14 | 0.47 |
测试数据已被分为两个不同的组:训练集包含85%的图像,测试集包含剩余15%的图像。对象类别是图像的实际类别。预测类别是模型为图像推断出的类别。这些结果基于一个经过4000次训练步数的MobileNet-V1模型,其宽度乘数为0.25,学习率超参数为0.001。
| 背景 | Stop Sign | 停车 Sign | Give Way | 行人 横穿 | ||
| 背景 | 64 | 0 | 0 | 0 | 0 | |
| Stop | 1 | 33 | 0 | 0 | 0 | |
| 停车 | 0 | 0 | 40 | 0 | 2 | |
| 让行 | 0 | 0 | 0 | 39 | 0 | |
| 行人 横穿 | 0 | 0 | 0 | 0 | 47 |
表VI. 重新训练的TensorFlow模型的混淆矩阵,其中N=226
准确率测量如下所示:
$$
\text{ACC.} = \frac{\sum TP + \sum TN}{\sum P + \sum N} \quad (4)
$$
| 对象类别 | 正样本 | 错误 正样本 | 负样本 | 错误 负样本 | 准确率 |
|---|---|---|---|---|---|
| 背景 | 64 | 0 | 161 | 1 | 99.56% |
| Stop | 33 | 1 | 192 | 0 | 99.56% |
| 停车 | 40 | 2 | 184 | 0 | 99.12% |
| 让行 | 39 | 0 | 187 | 0 | 100.00% |
| 行人 横穿 | 47 | 0 | 177 | 2 | 99.12% |
表VII. 重新训练的TensorFlow模型的精确率和召回率数据,其中N=226
在部署到树莓派之前,TensorFlow模型会被转换为TensorFlow Lite。需要注意的是,这会影响准确率,并且该交通标志识别系统可以使用TensorFlow实现实时运行。模型;然而,使用转换为TensorFlow Lite的执行图可以提高帧率。较高的帧率表明交通标志检测可以与车道保持等任务并行运行。
TensorFlow模型与TensorFlow Lite优化模型之间的主要区别在于它们分别使用协议缓冲区和FlatBuffers。FlatBuffers在访问数据之前不需要反序列化,并且已针对带宽和内存受限的设备进行了优化[25]。
在初始化阶段,TensorFlow Lite模型的数据流图被加载到内存中。在运行时,我们从该图调用推理以对给定的感兴趣区域进行分类。通过读取执行图的输出张量,判断感兴趣区域内是否存在物体,并获得其置信度。
表VII中给出的准确率计算结果支持了MobileNet模型在交通标志识别方面表现出与人类相媲美的性能这一论断。实际上,结合通过HSI阈值化进行的感兴趣区域提议,机器人能够可靠地检测和分类交通标志。
我们希望确保准确率与推理时间之间的权衡达到最优;因此,必须考虑调整宽度乘数的影响以及其对推理时间的影响。如果推理时间处于可接受的范围内,则使用宽度乘数为0.25且输入分辨率为128×128的MobileNet-V1是一个可行的替代方案。
| 架构 | 宽度 乘数 | 输入 分辨率 | 模型 大小(MB) | 推理 时间,Ti (s) |
|---|---|---|---|---|
| MobileNet- V1 | 0.25 | 128×128 | 1.90 | 0.04191 |
| MobileNet- V1 | 0.50 | 128×128 | 5.34 | 0.10290 |
| MobileNet- V1 | 0.75 | 128×128 | 10.35 | 0.16809 |
| MobileNet V1 | 1.0 | 128×128 | 16.92 | 0.26692 |
表VIII. 树莓派3B上使用TF Lite与卷积神经网络架构的均值推理时间、相对大小、图像输入分辨率
分类图像所需的推理时间与可实现的最大帧率成反比。通过将推理时间的倒数1/Ti与所采用的宽度乘数进行比较可以看出,为了确保交通标志识别能够与车道保持实时运行,宽度乘数必须等于0.25。
 。例如,α=0.25的上限表示典型MobileNet大小的四分之三的MobileNet的最大帧率约为10Hz。)
。例如,α=0.25的上限表示典型MobileNet大小的四分之三的MobileNet的最大帧率约为10Hz。)
我们提出并实现的交通标志检测与识别系统已成功部署在SoccerBot自动驾驶机器人上。最主要的限制在于感兴趣区域生成过程,这将应用局限于彩色物体的检测。使用TensorFlow实现的推理时间表明,交通标志识别可以与其他进程并行进行。我们在树莓派3B上通过深度学习实现了交通标志检测平均18.80 Hz的帧率。未来的方面,实现交通标志跟踪以及计算其与摄像头之间的距离是可行的目标,应作为下一步的研究方向。
IV. 结论
本文展示了在不同神经网络结构下,将端到端深度学习应用于两个独立的自动驾驶任务。我们成功地在卡罗洛杯场景中,针对小型移动机器人(计算能力有限)应用了端到端学习方法,用于自动驾驶中的车道检测和交通标志识别。所提出的方法在模拟环境和真实机器人上均成功完成了训练与执行。由于数据无法迁移,模拟环境和真实环境的训练样本被分别采集。机器人搭载的树莓派3处理器计算能力相对较弱,但足以以约5赫兹的速度运行端到端神经网络。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)