【CLIP】基于CLIP与伪标签的单阶段零样本目标检测网络
【CLIP】基于CLIP与伪标签的单阶段零样本目标检测网络
0. 论文简介
0.1 基本信息
2025 年 Jiafeng Li 等在 Int. J. Mach. Learn. & Cyber 发表论文 “基于CLIP与伪标签的单阶段零样本目标检测网络(Single-stage zero-shot object detection network based on CLIP and pseudo-labeling)”。
本文提出了一种基于 CLIP 模型和伪标记的单阶段零样本目标检测网络CLIP-YOLO,通过引入视觉语言嵌入对齐方法、设计通道分组增强坐标注意力(CGEC)模块嵌入 YOLO 系列检测头与特征增强组件,优化基于 CLIP 和区域提议网络(RPN)的伪标记生成以扩展训练集多样性,,有效平衡了未知目标检测的准确性与实时性。
论文标题: Single-stage zero-shot object detection network based on CLIP and pseudo-labeling
论文下载: springer
项目地址:Github-CLIP-YOLO
引用格式: Li, J., Sun, S., Zhang, K. et al. Single-stage zero-shot object detection network based on CLIP and pseudo-labeling. Int. J. Mach. Learn. & Cyber. 16, 1055–1070 (2025). https://doi.org/10.1007/s13042-024-02321-1

0.2 论文速览
核心方法
- 网络框架:单阶段架构,替换传统两阶段网络,提升推理速度,延迟降至 40.5ms。
- 视觉语言对齐:检测头用 CLIP 语义嵌入替代传统类别输出,计算图像损失(L₁损失)和文本损失(余弦相似度)迁移 CLIP 零样本分类能力。
- CGEC 模块:1. 通道划分:将特征图分为 G 个子特征;2. 并行子网:3×3 卷积 + 1×1 卷积分支;3. 跨空间学习:2D 全局平均池化 + 上下文融合增强未知目标特征表征,不增加参数(70.8M)。
- 伪标记优化:1. 类别无关 RPN 生成区域提议;2. CLIP 跨模态匹配 + 多尺度嵌入;3. 高阈值筛选。扩展训练集多样性,提升未知类别覆盖率。
主要贡献
-
提出了一种单阶段零样本检测框架。
该框架通过在检测头中用视觉-语言嵌入对齐方法替代传统的类别输出,有效迁移了CLIP模型的零样本分类能力。 -
提出了一种结合视觉语言多模态模型CLIP与区域提议网络的伪标签生成方法。
-
该方法利用CLIP多模态先验知识优化了区域提议网络候选区域的伪标签标注,扩展了训练集类别的多样性,并增强了对未知类别目标的覆盖能力。
0.3 摘要
未知目标检测是计算机视觉领域的一项挑战性任务,原因在于尽管现实世界中的检测目标类别多样,但现有目标检测训练集覆盖的类别数量有限。现有方法多采用两阶段网络来提升模型对未知类别目标的表征能力,但这会导致推理速度较慢。
为解决这一问题,我们提出了一种基于对比语言-图像预训练模型与伪标签的单阶段未知目标检测方法,命名为CLIP-YOLO。
- 首先,引入视觉语言嵌入对齐方法,并将通道分组增强坐标注意力模块嵌入YOLO系列检测头与特征增强组件,以提升模型对未知类别目标的表征与检测能力。
- 其次,基于CLIP模型优化伪标签生成机制,以此扩大训练集的多样性并增强对未知目标类别的覆盖能力。
我们在MSCOCO、ILSVRC、Visual Genome和PASCAL VOC四个具有挑战性的数据集上验证了该方法。实验结果表明,我们的方法能够实现更高的检测精度与更快的推理速度,从而获得更优的未知目标检测性能。
源代码已开源:https://github.com/BJUTsipl/CLIP-YOLO。

1. 引言
未知目标检测技术是计算机视觉领域的重要研究方向。因其更贴近实际应用场景,近年来逐渐受到学者们的广泛关注[1]。在公共安全领域,该技术能够快速检测识别未知可疑目标以保障公共安全;在智能交通领域,训练集之外的未知障碍物是车辆行驶过程中的最大安全隐患,精确检测可保障乘客与行人安全;在工业自动化领域,工作环境中常出现未知物体,及时检测能避免工业事故并提升生产效率。传统目标检测方法假设所有待检测的前景类别均存在于训练集中[2]。然而由于标注数据成本高昂及长尾现象的存在,基于学习的目标检测模型在检测现实世界中大量未知物体时存在局限。虽然传统无监督模板检测算法可通过相似度测量检测图像中特定已知模板或模式的存在,但在面对未知物体时其效果与泛化能力有限。不精确的检测结果会对其在安全保障、智能决策增强等应用场景中带来风险,因此需要一种有效方法来解决未知目标检测问题。
近年来,为解决未知目标检测问题,Bansal等人[3]提出了零样本检测方法。相较于无监督模板检测等传统方法,ZSD方法依赖于自监督学习、对比学习等复杂的机器学习与深度学习模型,通过从大量无标注数据中学习通用特征表示,并利用未知物体的语义嵌入与属性辅助信息提升模型对未知物体的表征能力,在处理复杂多样物体与环境时具备更高泛化能力。然而现有ZSD算法通常选择两阶段网络结构以提升模型性能,这导致网络参数量大且推理时间长。随着大规模对比语言-图像预训练模型的发展,Zareian等人[5]提出了开放词汇目标检测方法,尝试从大模型角度构建更通用的目标检测范式,使目标检测不再局限于少数具有标注数据的类别。该方法显著提升了未知目标检测的准确率,但大模型的训练往往需要大量计算与存储资源。不过,此类视觉语言模型使得以较少资源获取未知物体的语义嵌入信息更为便捷,这为零样本检测角度解决未知目标检测问题提供了有力条件。基于伪标签的弱监督学习方法在未知目标检测领域也被证明具有成效[6]。Xie等人[7]与Tang等人[8]通过预训练视觉模型为未标注数据生成伪标签,并将其与原始训练数据融合以增加训练数据的多样性与数量,从而使模型能够学习未知物体的特征分布,提升模型对未知物体的泛化能力。然而,使用单视觉模态预训练模型生成伪标签的方法同样缺乏对未知类别物体语义信息的深入理解,存在准确率低的缺陷,且可能产生噪声数据,不利于目标检测。
为解决上述问题,本文提出一种基于YOLO系列的单阶段零样本目标检测网络CLIP-YOLO。相较于以往多数方法采用的两阶段网络架构零样本目标检测模型,该网络具有更快的推理速度。本研究的主要目标是在保留YOLO系列现有优势的同时,兼顾模型对未知类别物体的检测速度与精度,面向实际应用场景增强检测模型在复杂环境中的适应性与鲁棒性,满足目标检测的精度与实时性要求。本文主要贡献如下:
-
提出一种单阶段零样本检测框架。该框架通过在检测头中用视觉-语言嵌入对齐方法替代传统的类别输出,有效迁移了CLIP模型的零样本分类能力。在特征增强部分引入通道分组增强注意力模块,在不增加网络参数量的前提下,进一步增强了模型对未知类别物体的表征能力。
-
提出一种结合视觉语言多模态模型CLIP与区域提议网络的伪标签生成方法。利用CLIP多模态先验知识优化区域提议网络候选区域的伪标签标注,相较于使用单视觉模态预训练模型生成伪标签的方法,扩展了训练集类别多样性并增强了对未知类别物体的覆盖能力。
-
在MSCOCO、ILSVRC、Visual Genome和PASCAL VOC等挑战性数据集上验证了所提方法实现了未知目标检测精度与速度的平衡,并通过消融实验验证了通道分组增强注意力模块及伪标签区域优化方法在零样本检测中的有效性。
本文后续章节安排如下:第2节讨论零样本检测、开放词汇检测及半监督学习的相关研究;第3节详细阐述所提单阶段零样本检测网络结构;第4节说明实验设置与性能分析结果;第5节总结研究结论并展望未来研究方向。
2. 相关工作
未知目标检测作为一项具有挑战性的任务,可分为零样本目标检测、开放词汇目标检测和半监督目标检测等方向。本节将综述这些领域的研究进展。
2.1 零样本目标检测
零样本目标检测由Bansal等人[3]首次提出。该方法的核心目标是使模型能够识别训练过程中未接触过的物体类别,显著提升模型在实际应用中的泛化能力。零样本目标检测通过利用辅助监督信息(如未知类别的文本嵌入、属性及自然语言描述),避免了在训练阶段标注未知类别图像数据的需求。相关研究可分为基于文本嵌入和基于生成模型两类。
文献[3]中,作者通过线性投影将模型输出与文本嵌入对齐,构建了基线模型,并基于MSCOCO检测数据集建立了48/17(已知/未知)的基准划分。Rahman等人[9]提出使用RetinaNet检测器解决零样本检测问题,引入极性损失以增大类别文本嵌入间距,并在MSCOCO数据集上构建了65/15的零样本检测新基准划分。Zhao等人[10]从生成模型视角切入,利用生成对抗网络合成未知物体的语义表征以辅助检测。Zheng等人[11]提出了基于文本嵌入的零样本实例分割方法,结合可见性掩码生成与鲁棒性损失函数实现了未知物体类别的精确检测与分割。Zhang等人[12]首次将DETR与元学习结合,通过将训练形式化为基于片段的任务来提升模型零样本检测能力。Liu等人[13]通过引入语义感知注意力机制与类别自适应对比损失,实现了对未知类别的有效预测与特征学习。He等人[14]提出D2Zero算法,利用未知类别的语义知识与图像特定线索,通过语义促进去偏和背景消歧方法实现未知类别物体的检测与精确分割。Khandelwal等人[15]提出的SSB算法将特征表示学习与跨类别信息传递解耦,通过微调投影层将图像特征映射至语义嵌入空间,利用已知与未知类别间的语义关系实现信息传递。He等人[16]提出的PADing算法利用细粒度属性的学习基元合成未知类别视觉特征,解决语义空间与视觉空间偏差问题,并引入协同关系对齐与特征解耦学习方法提升生成器合成特征质量。Huang等人[17]提出的M-RRFS算法配备类内语义离散、类间结构保持和跨域对比增强机制,以克服特征合成中类内多样性不足、类间可分离性不足及跨域对比弱等问题。
上述零样本检测研究多采用两阶段网络模型,存在模型复杂度高、推理速度慢的缺陷。此外,零样本检测任务通常仅考虑将未知类别文本嵌入与图像嵌入结合,相关深度研究仍较缺乏。
2.2 开放词汇目标检测
开放词汇目标检测由Chang等人[5]首次提出。该方法旨在利用海量图文数据覆盖更广泛的物体类别,从而提升目标检测的通用性。这使得开放词汇目标检测能够突破有限类别标注数据的限制,识别更多新物体类别。开放词汇检测显著缓解了零样本检测中未知类别监督信号不足的问题。相较于零样本检测仅在单视觉模态训练中使用线性变换将未知类别信息转化为文本嵌入作为弱监督信号,开放词汇检测采用多模态模型深度融合未知类别的图像与文本特征以提升模型泛化性能。
近年来,Gu等人[18]提出利用预训练CLIP模型的知识实现开放词汇检测,将检测问题转化为候选区域分类问题。Zhong等人[19]针对CLIP模型原设计用于图文对齐而无法精确定位图像区域的问题,提出区域CLIP方法,通过建立区域-文本对并在特征空间中对齐,实现自然语言描述监督下的区域级视觉表征学习。Feng等人[20]提出基于区域提示学习的PromptDet算法,通过变换文本嵌入空间更精准地对齐以目标为中心的视觉表征。Zang等人[21]通过将基于Transformer的端到端检测器转化为基于条件匹配与预训练视觉语言模型的开放词汇检测模型实现改进。Kim等人[22]提出RO-ViT模型,利用预训练视觉Transformer解决图文预训练与开放词汇检测微调间的定位嵌入问题,性能显著超越两阶段开放词汇检测模型。Wu等人[23]提出超越单区域嵌入的区域包嵌入对齐方法,采用邻域采样策略将上下文相关区域分组为包,并利用对比学习将检测器的区域包表征与预训练视觉语言模型对齐,在多个开放词汇检测基准测试中取得最优性能。Wu等人[24]提出CORA框架及区域提示机制,缓解CLIP模型中全图特征与区域特征的分布差异,提升新类别分类性能,同时进行锚框预匹配以在DETR风格框架中实现基于类别的目标定位而无需逐类别重复推理。Tianheng等人[25]提出YOLO-World算法,采用新型可重参数化视觉语言路径聚合网络及区域-文本对比损失促进视觉与语言信息交互,并引入“先提示后检测”的高效推理范式,在下游任务中展现出强大性能。
由于开放词汇检测旨在扩展目标检测通用性并识别更多物体类别,需依赖大规模数据集,因此在训练阶段需要更多图像及相关标注数据进行模型训练,对存储与计算资源提出了更高要求。
2.3 半监督目标检测(伪标签技术)
半监督目标检测是目标检测领域的重要研究方向,旨在结合标注数据、弱标注数据及未标注数据训练检测器[26]。
具体而言,半监督目标检测先使用标注数据训练模型,再利用未标注样本中高置信度分类结果生成的伪标签进行重训练。其主要方法可分为基于一致性的方法[27, 28]和基于伪标签的方法[29-33]。文献[29, 30]通过结合不同数据增强的预测结果生成未标注图像的伪标签,并通过迭代训练逐步提升模型性能。Li等人[31]提出SelectiveNet方法,筛选高置信度伪标签进行自训练。这些工作旨在减少对大量标注数据的依赖,通过自训练与自监督学习提升目标检测性能。Sohn等人[32]提出流行的STAC基线方法,在未标注图像中部署高置信实例框伪标签,并通过强数据增强更新相应模型以提升一致性。Wang等人[33]将未标注图像检测出的边界框叠加至标注图像,基于叠加后的标签图像估计定位一致性,因图像经过修改而需要严格的检测流程。文献[34]先预训练使用少量标注数据的检测器,利用训练后的检测器生成伪标签,再对未标注数据进行微调。Zang等人[35]设计了新型自适应伪标签挖掘机制,有效解决半监督学习环境中的长尾目标检测问题。Liu等人[36]提出新型抗模糊半监督学习方法,通过联合置信度估计量化伪标签的分类与定位质量,引入任务分离分配机制基于像素级预测分配标签,并采用“分治策略”分别处理正样本的分类与定位。近年来,结合视觉与语言的CLIP模型受到广泛关注,但利用CLIP模型改进伪标签方法的研究仍有限。Zhao等人[6]提出利用CLIP模型优化伪标签,在半监督目标检测任务中取得了显著性能提升。
本研究的核心动机部分受此启发,为处理未知目标检测问题提供了重要思路。
本研究提出的方法采用单阶段目标检测框架,相较于多基于两阶段网络架构的零样本检测任务具有更快的推理速度。同时,本研究受开放词汇检测启发,提出将CLIP模型的多模态图文特征迁移以实现零样本检测能力的算法,这是多数现有算法所不具备的。本研究引入基于CLIP模型的半监督学习方法优化伪标签生成,相较于以往使用单视觉模型的伪标签生成方法,实验结果表明本方法在零样本检测任务中对未知物体的检测性能实现了显著提升。
3. 所提方法
本研究提出一种面向未知物体的单阶段零样本检测框架。通过将CLIP模型与区域提议网络结合以优化伪标签区域,从而增强训练集的多样性,有效利用数据集中未标注区域并提升对未知物体类别的覆盖能力。
基于视觉语言单阶段伪标签的未知目标检测网络训练流程如图 1所示。我们以人工标注数据与图像描述作为输入,预处理阶段通过区域提议网络获取候选区域图像,并利用概念池生成区域描述。这些候选区域图像与描述随后输入优化模块,经CLIP图文匹配与非极大值抑制筛选关键候选区域。筛选出的候选区域与原始训练集合并形成增强数据集,通过模型训练获得优化模型。下文将首先详述模型架构,随后讨论伪标签区域优化方法。
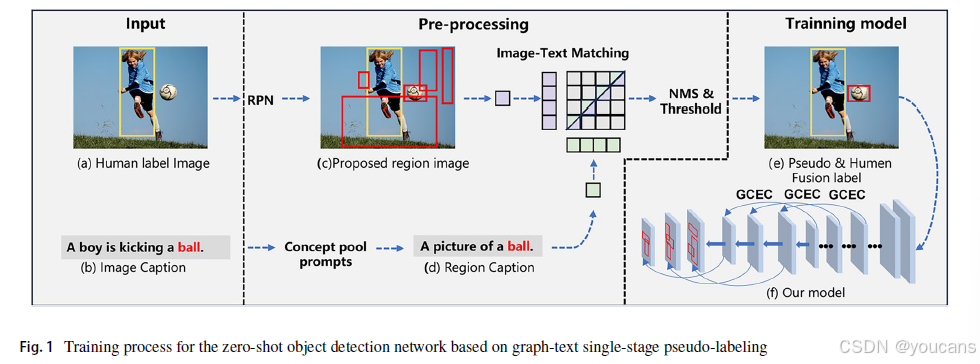
图1. 基于图-文本单阶段伪标签的零样本对象检测网络的训练过程
3.1 模型架构
传统零样本检测算法多采用两阶段模型,限制了实际场景中的推理速度。为提升实际应用的实时性,我们提出一种单阶段未知目标检测网络模型。
如 图2 所示,整体结构包含三大核心组件:ELAN-50主干网络、集成通道分组增强注意力模块的特征增强网络,以及融合CLIP的检测头。
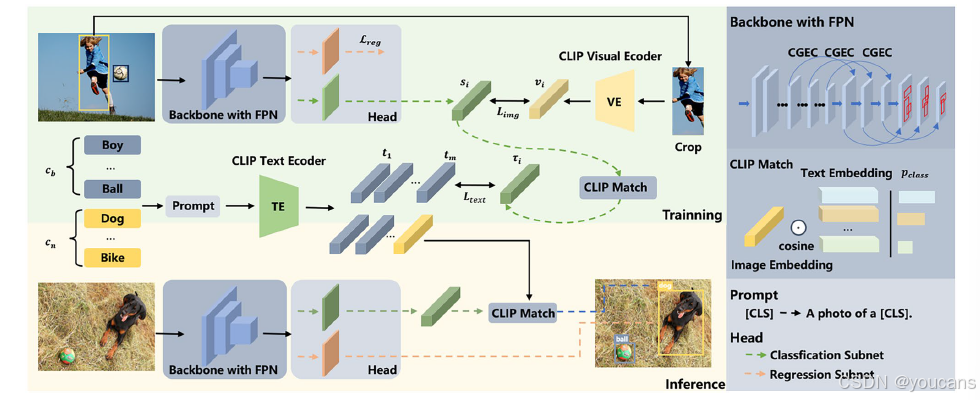
图2 单阶段零样本目标检测框架。
- 在训练阶段,基于基础类别 c b c_b cb的CLIP文本嵌入进行初始化,将典型的类别输出替换为与CLIP模型嵌入维度相等的语义输出,并通过构建图像损失 L i m g L_{img} Limg和文本损失 L t e x t L_{text} Ltext最小化特征图上稀疏正样本点特征与裁剪区域CLIP视觉/文本嵌入之间的距离。
- 在推理阶段,移除嵌入对齐模块,并使用新类别 c n c_n cn的CLIP文本嵌入进行初始化。
训练阶段如图2所示,图像与基础类别 c b c_b cb分别输入主干网络与CLIP文本编码器。主干网络通过所提通道分组增强注意力模块进一步强化未知物体特征。增强后的特征输入检测头,通过回归分支计算回归损失 L r e g L_{reg} Lreg。随后,基于主干网络的语义嵌入 s i s_i si与基于CLIP的语义嵌入 v i v_i vi进行对齐约束,同时结合类别文本嵌入 t b t_b tb与CLIP匹配文本嵌入 t ~ i \tilde{t}_i t~i实现基于CLIP的分类分支双重对齐,从而迁移CLIP模型的零样本分类能力。推理阶段,输入图像经主干网络与路径聚合特征金字塔网络进行特征提取,所得特征输入检测头后分别经由回归分支与分类分支处理,最终获得检测物体的边界框位置及图像区域的语义嵌入。物体类别通过其语义嵌入与基础类别 c b c_b cb及新类别 c n c_n cn生成的文本嵌入进行相似度匹配确定。
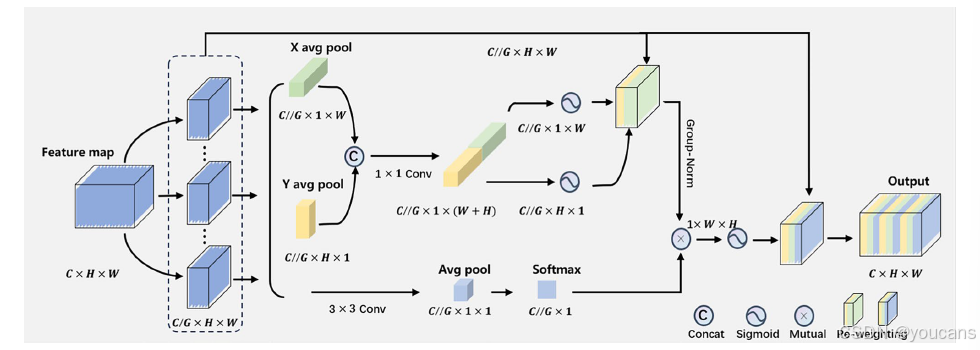
图3. CGEC的详细结构
3.1.1 未知目标检测分类分支
CLIP模型对未知物体具备强大的零样本分类能力,若将其迁移至YOLO框架中,可实现未知目标检测任务。训练阶段,输入图像经检测主干网络与特征增强网络处理后传入检测头,其中包含回归分支与分类分支。本研究采用YOLO系列模型的回归分支预测边界框位置,并改进检测头的分类分支——将传统类别输出替换为与CLIP模型维度相同的语义嵌入并进行对齐。本文采用的对齐过程包含图像对齐与文本对齐两部分。
3.1.1.1 图像对齐
训练过程中,对每张输入图像的真实边界框对应区域进行裁剪,获得 n n n个图像区域 r i , i = 1 , . . . , n {r_i}, i=1,...,n ri,i=1,...,n。使用CLIP模型的图像编码器预处理获得 r i r_i ri对应区域的图像嵌入(对应图2中的 v i v_i vi)。当 r i r_i ri经过特征提取与增强网络并通过检测头分类分支后,可获得语义嵌入 s i s_i si。本研究中 v i v_i vi与 s i s_i si均为 N N N维向量(因所用视觉编码器由原始CLIP初始化,故 N = 512 N=512 N=512)。图像对齐部分采用L1损失与平均绝对误差计算 v i v_i vi与 s i s_i si之间的距离,计算公式如下。
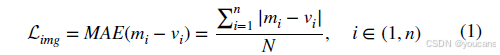
3.1.1.2 文本对齐
训练阶段的文本嵌入仅涉及基础类别集合 c b {c_b} cb,其中 b = 1 , . . . , m b = 1, ..., m b=1,...,m,该集合由数据集中所有图像的真实边界框对应的 m m m个类别名称构成。训练时,对裁剪区域对应的类别名称进行提示操作后输入CLIP文本预编码器,获得文本嵌入记为 t b t_b tb,其维度为512。通过计算语义嵌入 s i s_i si与CLIP预训练模型的余弦相似度匹配,获得对应的文本嵌入 t ~ i \tilde{t}i t~i。文本损失 L t e x t L{text} Ltext的计算方式如下所示,其中 cosine \text{cosine} cosine表示计算两个向量间的余弦相似度。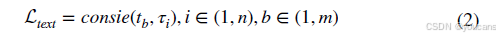
分类分支的总损失函数 L t o t a l L_{total} Ltotal 由图像损失与文本损失共同构成,其表达式如下:
3.1.2 通道分组增强坐标注意力
YOLO系列网络利用特征金字塔融合不同层级的语义信息。本研究设计了通道分组增强注意力模块,以在特征融合前进一步强化对未知物体特征的表征能力。图3展示了该模块的整体结构。
3.1.2.1 通道划分
对于任意输入特征图 X ∈ R C × H × W X \in \mathbb{R}^{C \times H \times W} X∈RC×H×W,通道分组增强注意力模块沿通道维度将 X X X划分为 G G G个子特征,表示为 X = [ X 0 , X i , . . . , X G − 1 ] X = [X_0, X_i, ..., X_{G-1}] X=[X0,Xi,...,XG−1],其中每个子特征 X i ∈ R C / / G × H × W X_i \in \mathbb{R}^{C//G \times H \times W} Xi∈RC//G×H×W。这里 C C C表示输入通道数, H H H与 W W W分别表示输入特征的空间维度。这种通道划分方式在降低计算复杂度的同时,避免了常规卷积降维操作可能造成的信息丢失与过拟合风险。
3.1.2.2 并行子网络
为建模跨通道信息交互并降低计算复杂度,采用并行子网络捕获通道间依赖关系。受坐标注意力机制启发,我们并行设置了 3 × 3 3 \times 3 3×3卷积分支与 1 × 1 1 \times 1 1×1卷积分支,以聚合多尺度空间结构信息并实现快速响应。在 1 × 1 1 \times 1 1×1分支中,通过沿 X X X与 Y Y Y方向的一维全局平均池化对通道进行编码,随后将编码特征沿特征图宽度方向连接。在此过程中,沿水平维度对通道 C C C中高度 H H H处的一维全局平均池化可表示为
类似地,沿垂直维度对通道 C C C中宽度 W W W处的一维全局平均池化可表示为
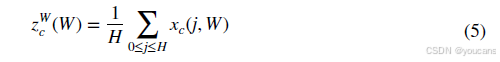
其中 x c x_c xc代表第 c c c个通道的输入特征。通过这种编码过程,模型能够强化对水平与垂直维度依赖关系的捕捉,在纵横维度保留精确的位置信息,增强空间中的长程交互,并加强对感兴趣空间区域的关注度。
随后,将 1 × 1 1 \times 1 1×1卷积的输出分解为两个向量,并通过sigmoid函数进行激活。每个分组内两个通道的注意力图通过乘法聚合,以捕获具有精确位置信息的跨通道交互特征。同时, 3 × 3 3 \times 3 3×3分支通过卷积捕获局部跨通道交互,从而扩展特征空间。这种采用并行子网络进行通道信息编码的方式,能够调整不同通道的重要性,减少网络的顺序处理深度和参数量。
3.1.2.3 跨空间学习
受金字塔拆分与聚合机制的启发,所提模型采用跨空间信息聚合方法对不同空间维度的特征进行聚合。通过计算 1 × 1 1 \times 1 1×1分支的组归一化后特征,并与 3 × 3 3 \times 3 3×3分支经二维全局平均池化得到的全局空间信息进行点积运算,从而生成保留精确空间位置信息的空间注意力图。二维全局平均池化操作公式如下:
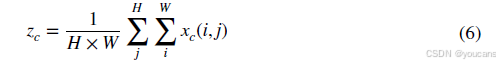
该池化操作旨在编码全局信息并建模长程依赖关系。最后,通过sigmoid函数进行激活。拼接后的通道分组增强注意力模块最终输出包含各组分特征,其维度与输入特征 X X X保持一致。通过这种设计,精准的位置信息被嵌入到模块中,同时实现了对远程依赖关系的建模。多尺度上下文信息的融合使得检测头能够在像素级关注未知类别物体的高层特征图。
3.2 伪标签区域优化
为增强模型对未知物体的识别能力,本研究通过伪标签技术扩展训练数据集。当在丰富的图像领域与自然文本上进行训练后,视觉-语言模型展现出卓越的泛化性能,成为生成任意类别伪标签的理想外部知识源。如图1所示,本研究采用视觉-语言模型CLIP:图像输入检测器后,将获得的区域裁剪图像块输入CLIP图像编码器,同时利用对应的CLIP文本编码器与模板文本提示获取CLIP视觉与语言空间中的嵌入表示。针对每个区域,通过点积计算区域嵌入与文本嵌入的相似度,并利用softmax函数得到类别分布,从而完成伪标签生成过程。具体步骤如下:
3.2.1 生成鲁棒且类别无关的区域提议
为实现数据集中未标注背景数据的弱监督检测,所提区域提议生成器应能定位训练期间见过的类别物体,也能定位未知类别物体。尽管存在无监督候选区域生成方法,但其耗时且易产生大量噪声框。先前研究表明,基于两阶段检测器的区域提议网络对未知类别具有良好的泛化能力。因此,本研究基于Faster R-CNN模型训练标准两阶段检测器,并利用数据集中的真实标注训练提议生成器。此外,为提升泛化能力,本方法在训练过程中忽略训练集的类别信息,从而训练出类别无关的提议生成器。
3.2.2 利用视觉-语言模型优化伪标签生成
直接将CLIP应用于裁剪区域提议会导致定位质量不佳。为此,我们通过以下两步提升两阶段类别无关提议生成器的定位能力:首先,发现区域提议网络得分能有效反映区域提议的定位质量,且该得分与交并比得分呈正相关。通过将本步骤生成的区域提议网络得分与CLIP预测的得分取平均,利用了这一关系。其次,移除提议生成器的阈值与非极大值抑制处理,观察到通过反复将提议框输入感兴趣区域头网络,可以使冗余框更紧密聚集。基于此,区域提议网络能生成定位更精准的边界框,从而提升伪标签区域质量。
此外,为进一步提升伪标签质量,采用CLIP的多尺度区域嵌入策略,并依据建议设置高置信度阈值筛选高质量伪标签。对于候选区域中第 i i i个区域 r i r_i ri,其伪标签置信度得分 c ˉ i u \bar{c}_i^u cˉiu的计算公式如下:
其中 s i u s_i^u siu 表示第 i i i 个区域包含未知类别正样本的概率,其表达式为:

其中 S R P N ( r i ) S_{RPN}(r_i) SRPN(ri)表示区域 i i i的区域提议网络得分,区域 i i i的类别预测概率分布 p i u p_i^u piu定义为:
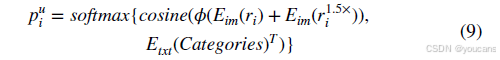
其中, E i m E_{im} Eim与 E t x t E_{txt} Etxt分别为CLIP的图像编码器与文本编码器。 N ( x ) = x ∣ x ∣ \mathcal{N}(x) = \frac{x}{|x|} N(x)=∣x∣x用于对CLIP图像编码器输出的不同尺度图像区域向量进行归一化处理, consie ( ⋅ ) \text{consie}(\cdot) consie(⋅)计算归一化后的图像向量与文本向量间的余弦相似度。 r i 1.5 × r_i^{1.5\times} ri1.5×表示将区域 r i r_i ri缩放1.5倍。通过引入多尺度图像区域信息,能够更全面地描述候选区域内容,并提升图文关系建模能力。 Categories \text{Categories} Categories表示人工引入的类别名称集合。最后,对余弦相似度结果应用softmax函数,将其转换为多分类计算所需的概率分布。
4. 实验结果与分析
本研究进行了多组实验,包括在标准零样本检测与广义零样本检测设置下与现有算法的对比。鉴于基于Transformer或更复杂结构的新模型推理速度较慢,难以满足研究目标对实时检测的要求,为确保实验结果的合理性与公平性,本研究对比的算法均基于卷积神经网络架构。在零样本检测设置中,训练阶段仅使用可见类别样本进行模型训练,测试阶段则需检测未知类别。广义零样本检测作为零样本检测的扩展,要求在测试阶段同时检测可见与未知物体类别,模型需能处理可见与未知类别间的域偏移并实现精确检测。此外,我们通过消融实验验证了所提通道分组增强注意力模块及基于CLIP的伪标签生成方法的有效性。实验在具有挑战性的MSCOCO、ILSVRC Visual Genome、Visual Genome ILSVRC和PASCAL VOC数据集上展开。
4.1 数据集
实验采用MSCOCO、Visual Genome、ILSVRC和PASCAL VOC数据集。MSCOCO作为大规模图像数据集,包含丰富多样的真实场景图像样本与详细物体标注信息,广泛用于目标检测、图像分割等计算机视觉任务的训练与评估。ILSVRC涵盖数千个类别的数百万张图像,主要关联图像分类与目标定位任务。Visual Genome作为大规模视觉知识图谱数据集,包含超百万张图像,每张图像均附有涵盖物体、场景及关系的丰富描述与标注,为图像理解与推理研究提供详细语义信息。PASCAL VOC数据集广泛用于目标检测、图像分类等任务,涵盖20个类别的图像及详细标注信息。
4.2 评估方案
首先,我们基于MSCOCO数据集的48/17与65/15划分基准,在零样本检测与广义零样本检测设置下评估模型性能。65/15划分表示训练集包含65个可见类别样本,测试集包含15个未知类别;类似地,47/18划分表示训练集含47个可见类别,测试集含18个未知类别。在零样本检测设置下,模型仅预测未知物体样本,采用交并比阈值为0.5时的Recall@100与平均精度均值作为评估指标。广义零样本检测设置下,额外计算可见与未知类别在Recall@100与平均精度均值上的调和平均数,以衡量模型在已知与未知类别上的综合性能。延迟指标表征模型推理时间,用于衡量检测速度。
对于ILSVRC基准测试,模型在零样本检测设置下对23个未知类别进行评估,主要以平均精度均值作为评估指标,检验模型对未知类别的泛化能力。在Visual Genome数据集上,考虑其类别数量众多且存在标注缺失,在交并比阈值为0.4、0.5、0.6的零样本检测设置下对130个未知类别进行评估,并计算平均Recall@100得分。在PASCAL VOC数据集中,本研究选取交并比阈值为0.5时的平均精度均值作为评估指标。
4.3 实验设置
模型输入为640×480分辨率图像,采用随机梯度下降优化器进行优化。为确定超参数,使用MSCOCO 65/15划分训练集进行超参数搜索,以验证集在未知类别上的平均精度均值作为适应度目标评估每组超参数质量。验证集从MSCOCO 2014训练集中未用于65/15零样本检测训练或测试的部分抽取构建,包含20,483张图像与33,690个未知类别标注框,其未知类别与MSCOCO 65/15测试集一致。通过超参数搜索过程确定最优超参数组合:学习率0.00282、批量大小12、动量0.854、权重衰减0.00038。
首先使用可见类别预训练YOLOv7模型,并以预训练权重初始化所提模型的特征提取主干组件,使模型获得良好起点。利用人工标注边界框生成伪标签标注,在24GB显存的RTX 3090 GPU上进行50轮迭代训练。
4.4 定量与定性对比
表1列出了本研究方法与其他算法在广义零样本检测与零样本检测设置下,基于两种基准划分(65/15与48/17)的对比结果。所提方法在所有指标中均位列前三,并在五项指标中获得第一,展现出最佳综合性能;PADing算法在三项指标中领先,综合性能位列第二。总体而言,所有方法在65/15划分下对未知物体的检测性能更优,这是因为该划分提供的训练样本量更大,使模型能从更多数据特征中学习未知物体,从而提升检测精度。类似地,对本文方法而言,更多样的训练标签样本能使分类分支更紧密地逼近CLIP嵌入空间。然而,已知类别样本数量远超未知类别样本导致的数据偏斜,会使模型在预测阶段倾向于将目标物体归类为已知类别,造成高精度但低召回的结果。
本研究致力于设计实时检测未知目标的方法,因此对比了所提模型与其他算法的推理速度。相较于推理速度排名第二的ZSD-YOLO,本文模型推理时间快4.2毫秒;比综合性能第三的D2Zero快约8.2倍;比综合性能第二的PADing模型快约2.25倍。这些提升得益于YOLO单阶段检测的架构优势及本文提出的通道分组增强注意力模块。该模块不仅降低了模型复杂度,还确保了注意力的精准聚焦,显著提升了推理速度与模型精度。
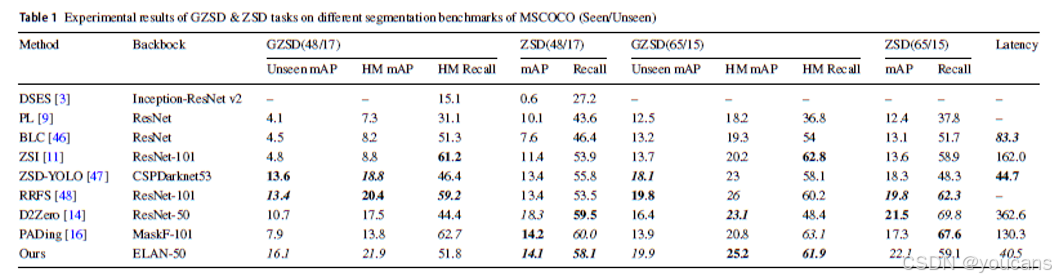
在ILSVRC数据集上的实验验证了所提模型在不同数据集上对未知目标检测的泛化能力。根据表2结果,在零样本检测设置下对ILSVRC数据集23个未知类别的推理测试中,本文方法的多类别平均平均精度均值较现有方法提升1.0%,证明了该方法在未知目标检测任务上的优越性及其跨数据集的增强泛化能力。
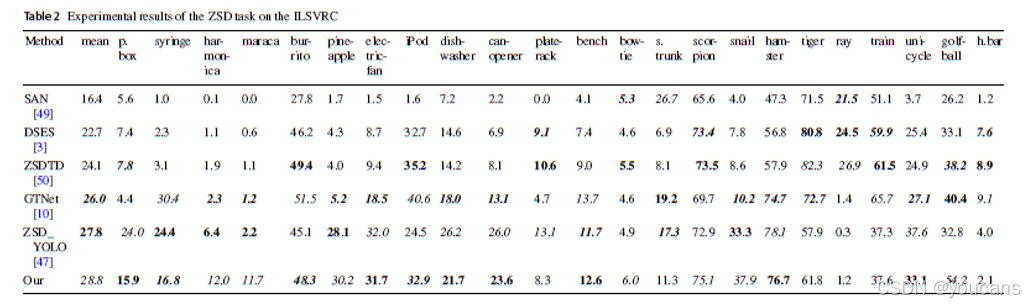
在Visual Genome数据集上的实验以交并比阈值0.4、0.5、0.6下的Recall@100作为评估指标。表3结果显示,本文方法显著优于现有方法:在交并比阈值为0.4、0.5、0.6时,Recall@100分别较先前最优方法提升0.3%、0.3%与0.7%。该基准测试结果表明,本文方法在更大数据集上能实现更显著的性能提升,证明了其在未知目标检测泛化能力方面的优势。
最后,在PASCAL VOC数据集零样本检测设置下的评估结果(表4)显示,本文方法同样取得最佳综合性能。上述结果有力证明了所提方法在处理未知目标检测任务上的优越性,及其在不同数据集上更优的泛化能力。这得益于单阶段零样本检测网络更快的推理速度:通过在检测头模块引入视觉语言嵌入对齐方法,有效迁移了CLIP模型的零样本分类能力;在特征增强部分加入通道分组增强注意力模块,强化了模型对未知类别物体的表征能力;同时,基于CLIP与区域提议网络结合的伪标签生成方法有助于扩展训练集多样性并增强对未知类别物体的覆盖能力。
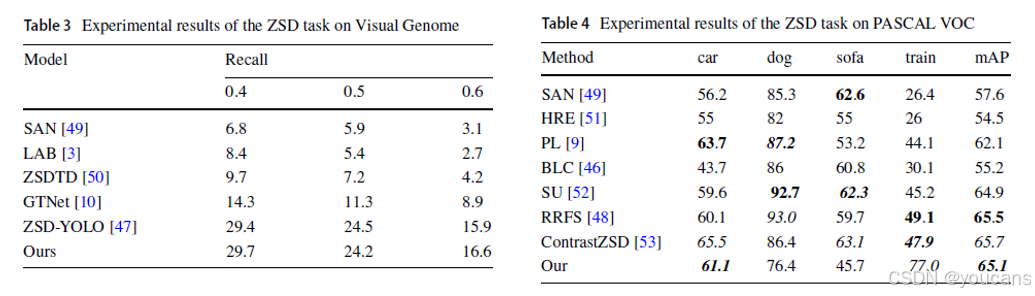
4.5 消融实验
消融研究主要基于MSCOCO数据集,重点比较不同注意力机制与伪标签生成方法。此外,将本文提出的通道分组增强注意力模块及基于CLIP的双模态伪标签生成方法应用于不同特征提取主干网络,以验证所提模块与方法的有效性。
表5与表6分别列出了使用不同主干网络及不同单阶段目标检测框架结合本文方法的消融实验结果。结果表明,相较于基线模型,无论基于何种主干网络或单阶段检测框架,通道分组增强注意力模块与CLIP伪标签生成方法均能提升检测精度。研究发现,引入基于CLIP的伪标签生成方法可显著提高召回率;当同时应用通道分组增强注意力模块与CLIP伪标签生成方法时,平均精度均值与召回率可得到进一步改善。
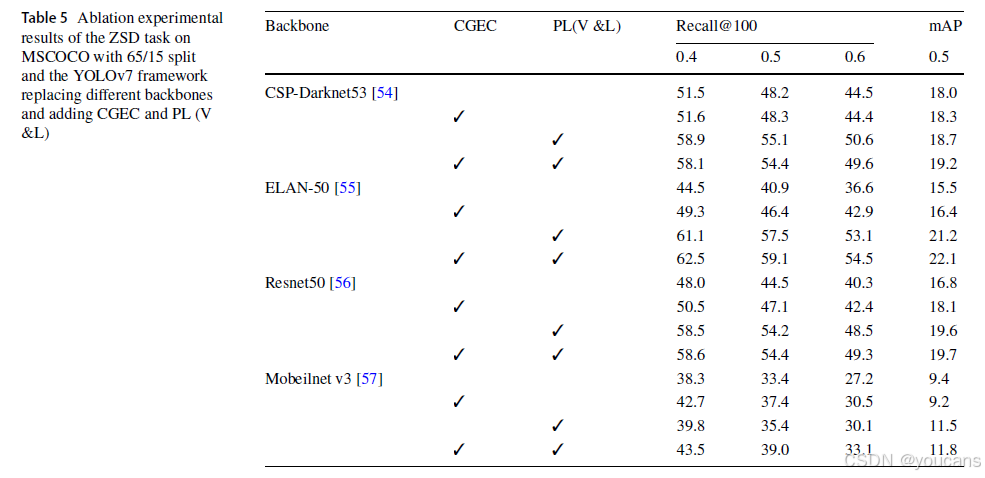
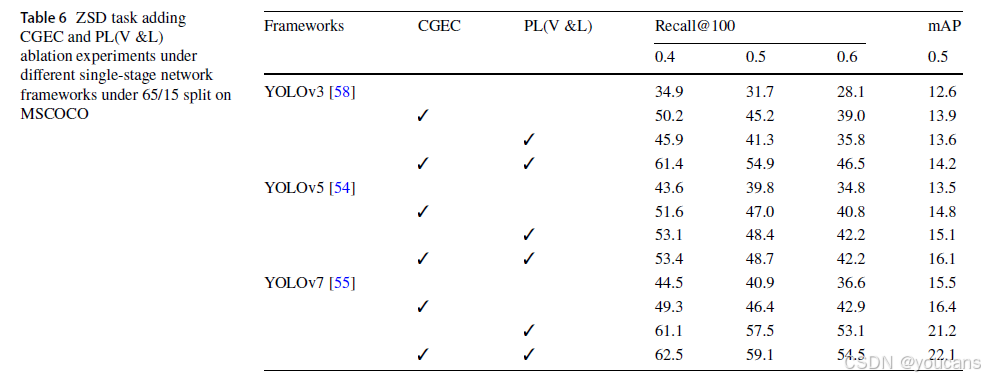
表7与图4比较了通道分组增强注意力模块、坐标注意力模块及压缩激励模块在MSCOCO数据集65/15与48/17基准下对特征增强的效果。如表7所示,通道分组增强注意力模块在不增加参数量的情况下实现了更高的召回率与平均精度均值。该模块通过构建跨空间交互步骤聚合并行分支输出特征,在不降低通道维度的前提下减少计算开销,增强了对未知物体类别特征的像素级关注。图4展示了不同注意力模块的热力图对比:实验中第一列(飞机)与第二列(猫)被指定为未知类别,第三至七列为已知类别。通道分组增强注意力模块的热力图在已知与未知类别检测中,均在特定区域呈现更高权重值且边界清晰,有效区分物体与背景。

图4. 三种注意力热图的SE、CA和CGEC结果
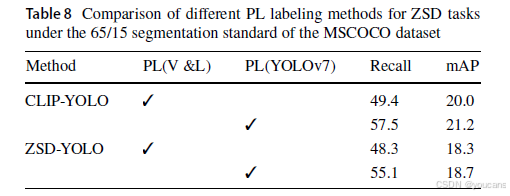
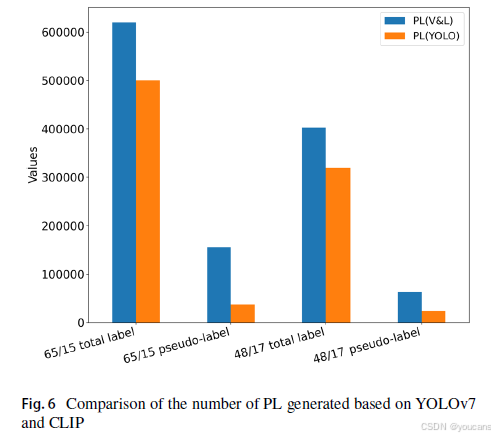
根据表8,我们评估了不同伪标签生成方法在零样本检测设置下对模型检测未知类别物体的影响。所提双模态伪标签生成方法较单模态方法在平均精度均值上提升1.2%,在Recall@100上提升8.1%。该方法可适配其他零样本检测框架,如应用于ZSD-YOLO时可提升召回率6.8%与平均精度均值0.4%。最后,图5对比了不同伪标签标注方法的主客观结果:第一至三行分别展示人工标注、基于YOLO单模态网络生成的伪标签及所提图文多模态模型生成的伪标签。对比可见,所提方法生成的伪标签数量更多且覆盖类别更广。图6的客观对比结果进一步证实了该结论。

图5. 基于V&L多模态PL生成和视觉模型基于的PL生成的主观实验结果。
第一行是数据集的ground truth,第二行是基于YOLOv7的PL生成,第三行是基于V &L的PL生成
从这些结果可见,基于多模态输入的伪标签生成方法在复杂背景下识别未标注及未知物体类别方面显著优于单模态方法,这得益于其对图像与文本信息的整合,增强了模型对图像中未知物体类别的理解与识别能力。
通过上述消融实验可知,模型取得的成果源于:基于CLIP与区域提议网络结合的伪标签生成方法扩展了训练集类别多样性并增强了对未知类别物体的覆盖能力;在特征增强模块中加入通道分组增强注意力模块,通过构建跨空间交互步骤增强对未知物体类别特征的像素级关注,聚合并行分支输出特征,在不降低通道维度的前提下减少计算开销,进一步强化了模型对未知物体类别的表征能力。与基线模型的对比表明,缺少任一组件将导致模型对未知类别物体语义信息理解不足,造成精度下降、计算开销增加,并影响实时性能与检测准确性。
5. 结论与未来工作
本研究提出并开发了一种基于图形伪标签的单阶段未知目标检测方法。通过引入视觉语言嵌入对齐方法,并分别在 YOLO 系列检测头和特征增强组件中嵌入所提出的 CGEC 模块,显著提升了对未知目标类别的检测能力。研究利用 CLIP 模型优化伪标签生成过程,以扩展训练集的多样性并提高未知目标类别的覆盖范围。在具有挑战性的 MSCOCO、ILSVRC、Visual Genome 和 PASCAL VOC 数据集上进行的分割基准测试中,该方法实现了未知目标检测精度与速度的平衡,这对于实际应用场景具有重要意义。
探索 CLIP 视觉语言模型在零样本目标检测(ZSD)任务中的应用是一个新兴研究方向。在潜在局限性方面,模型检测头的规模相对较小且类别覆盖范围有限,可能会限制其对 CLIP 零样本分类能力的迁移效果,进而影响该方法在小型数据集上的检测性能。因此,在未来工作中,我们将对模型进行改进以解决这一局限性,并探索将该方法应用于其他检测框架,以验证其通用性。此外,对 CLIP 模型进行更深入的知识挖掘可进一步优化伪标签生成过程,这也将在未来的研究中予以考虑。
7. CLIP-YOLO 项目介绍:
项目地址:Github-CLIP-YOLO
7.1 安装 FLAIR
在您的环境中安装与GPU兼容的torch版本。
8. 参考文献
1. Zou Z, Chen K, Shi Z, Guo Y, Ye J (2023) Object detection in 20 years: a survey. Proceedings of the IEEE
2. Liang W, Xue F, Liu Y, Zhong G, Ming A (2023) Unknown sniffer for object detection: Don’t turn a blind eye to unknown objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 3230–3239
3. Bansal A, Sikka K, Sharma G, Chellappa R, Divakaran A (2018) Zero-shot object detection. In: Proceedings of the European conference on computer vision (ECCV), pp 384–400
4. Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S,Sastry G, Askell A, Mishkin P, Clark J, et al (2021) Learning transferable visual models from natural language supervision. In:International conference on machine learning, pp 8748–8763
5. Zareian A, Rosa KD, Hu DH, Chang S-F (2021) Open-vocabulary object detection using captions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp14393–14402
6. Zhao S, Zhang Z, Schulter S, Zhao L, Vijay Kumar B, Stathopoulos A, Chandraker M, Metaxas DN (2022) Exploiting unlabeled data with vision and language models for object detection. In: European conference on computer vision, pp 159–175. Springer
7. Xie Q, Luong M-T, Hovy E, Le QV (2020) Self-training with noisy student improves imagenet classification. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 10687–10698
8. Tang Y, Chen W, Luo Y, Zhang Y (2021) Humble teachers teach better students for semi-supervised object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 3132–3141
9. Rahman S, Khan S, Barnes N (2020) Improved visual-semantic alignment for zero-shot object detection. In: Proceedings of the AAAI conference on artificial intelligence, vol 34, pp11932–11939
10. Zhao S, Gao C, Shao Y, Li L, Yu C, Ji Z, Sang N (2020) Gtnet: Generative transfer network for zero-shot object detection. In: Proceedings of the AAAI conference on artificial intelligence, vol 34, pp 12967–12974
11. Zheng Y, Wu J, Qin Y, Zhang F, Cui L (2021) Zero-shot instance segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 2593–2602
12. Zhang L, Zhang C, Zhao J, Guan J, Zhou S (2023) Meta-zsdetr: Zero-shot detr with meta-learning. In: Proceedings of the IEEE/CVF international conference on computer vision (ICCV), pp6845–6854
13. Liu H, Zhang L, Guan J, Zhou S (2023) Zero-shot object detection by semantics-aware detr with adaptive contrastive loss. In: Proceedings of the 31st ACM international conference on multimedia, pp 4421–4430
14. He S, Ding H, Jiang W (2023) Semantic-promoted debiasing and background disambiguation for zero-shot instance segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 19498–19507
15. Khandelwal S, Nambirajan A, Siddiquie B, Eledath J, Sigal L (2023) Frustratingly simple but effective zero-shot detection and segmentation: analysis and a strong baseline. ArXiv arxiv: 2302.07319
16. He S, Ding H, Jiang W (2023) Primitive generation and semanticrelated alignment for universal zero-shot segmentation. In 2023 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 11238–11247
17. Huang P, Zhang D, Cheng D, Han L, Zhu P, Han J (2024) M-RRFs: A memory-based robust region feature synthesizer for zero-shot object detection. Int J Comput Vis. https:// doi. org/ 10.1007/ s11263- 024- 02112-9
18. Gu X, Lin T-Y, Kuo W, Cui Y (2021) Open-vocabulary object detection via vision and language knowledge distillation. arXiv preprint arXiv: 2104. 13921
19. Zhong Y, Yang J, Zhang P, Li C, Codella N, Li LH, Zhou L, Dai X, Yuan L, Li Y, et al. (2022) Regionclip: Region-based languageimage pretraining. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 16793–16803
20. Feng C, Zhong Y, Jie Z, Chu X, Ren H, Wei X, Xie W, Ma L (2022) Promptdet: Towards open-vocabulary detection using uncurated images. In: European conference on computer vision, pp 701–717. Springer
21. Zang Y, Li W, Zhou K, Huang C, Loy CC (2022) Open-vocabulary detr with conditional matching. In: European conference on computer vision, pp 106–122. Springer
22. Kim D, Angelova A, Kuo W (2023) Region-aware pretraining for open-vocabulary object detection with vision transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 11144–11154
23. Wu S, Zhang W, Jin S, Liu W, Loy CC (2023) Aligning bag of regions for open-vocabulary object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 15254–15264
24. Wu X, Zhu F, Zhao R, Li H (2023) Cora: Adapting clip for openvocabulary detection with region prompting and anchor prematching. In: 2023 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 7031–700:
25. Cheng T, Song L, Ge Y, Liu W, Wang X, Shan Y (2024) Yoloworld: Real-time open-vocabulary object detection. ArXiv arxiv: 2401. 17270
26. Rosenberg C, Hebert M, Schneiderman H (2005) Semi-supervised self-training of object detection models 27. Jeong J, Lee S, Kim J, Kwak N (2019) Consistency-based semisupervised learning for object detection. Adv Neural Inform Process Syst 32
28. Tang P, Ramaiah C, Wang Y, Xu R, Xiong C (2021) Proposal learning for semi-supervised object detection. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp 2291–2301
29. Radosavovic I, Dollár P, Girshick R, Gkioxari G, He K (2018) Data distillation: Towards omni-supervised learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4119–4128
30. Zoph B, Ghiasi G, Lin T-Y, Cui Y, Liu H, Cubuk ED, Le Q (2020) Rethinking pre-training and self-training. Adv Neural Inf Process Syst 33:3833–3845
31. Li Y, Huang D, Qin D, Wang L, Gong B (2020) Improving object detection with selective self-supervised self-training. In: European conference on computer vision, pp 589–607. Springer
32. Sohn K, Zhang Z, Li C-L, Zhang H, Lee C-Y, Pfister T (2020) A simple semi-supervised learning framework for object detection. arXiv preprint arXiv: 2005. 04757
33. Wang K, Yan X, Zhang D, Zhang L, Lin L (2018) Towards human-machine cooperation: Self-supervised sample mining for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1605–1613
34. Liu Y-C, Ma C-Y, He Z, Kuo C-W, Chen K, Zhang P, Wu B, Kira Z, Vajda P (2021) Unbiased teacher for semi-supervised object detection. arXiv preprint arXiv: 2102. 09480
35. Zang Y, Zhou K, Huang C, Loy CC (2023) Semi-supervised and long-tailed object detection with cascadematch. Int J Comput Vis 131(4):987–1001
36. Liu C, Zhang W, Lin X, Zhang W, Tan X, Han J, Li X, Ding E, Wang J (2023) Ambiguity-resistant semi-supervised learning for dense object detection. In: 2023 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 15579–15588
37. Hou Q, Zhou D, Feng J (2021) Coordinate attention for efficient mobile network design. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 13713–13722
38. Liu H, Liu F, Fan X, Huang D (2021) Polarized self-attention: Towards high-quality pixel-wise regression. arXiv preprint arXiv: 2107. 00782
39. Uijlings JR, Van De Sande KE, Gevers T, Smeulders AW (2013) Selective search for object recognition. Int J Comput Vis 104:154–171
40. Zhang P, Li X, Hu X, Yang J, Zhang L, Wang L, Choi Y, Gao J (2021) Vinvl: Revisiting visual representations in vision-language models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 5579–5588
41. Ren S, He K, Girshick R, Sun J (2015) Faster r-cnn: Towards realtime object detection with region proposal networks. Adv Neural Inform Process Syst 28
42. Lin T-Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: Common objects in context. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6–12, 2014, Proceedings, Part V 13, pp 740–755. Springer
43. Kuznetsova A, Rom H, Alldrin N, Uijlings J, Krasin I, Pont-Tuset J, Kamali S, Popov S, Malloci M, Kolesnikov A et al (2020) The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int J Comput Vis 128(7):1956–1981
44. Gupta A, Dollar P, Girshick R (2019) Lvis: A dataset for large vocabulary instance segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp5356–5364
45. Everingham M, Van Gool L, Williams CK, Winn J, Zisserman A (2010) The pascal visual object classes (VOC) challenge. Int J Comput Vis 88:303–338
46. Zheng Y, Huang R, Han C, Huang X, Cui L (2020) Background learnable cascade for zero-shot object detection. In: Proceedings of the Asian conference on computer vision
47. Xie J, Zheng S (2022) Zero-shot object detection through visionlanguage embedding alignment. In: 2022 IEEE international conference on data mining workshops (ICDMW), pp 1–15. IEEE
48. Huang P, Han J, Cheng D, Zhang D (2022) Robust region feature synthesizer for zero-shot object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 7622–7631
49. Rahman S, Khan S, Porikli F (2018) Zero-shot object detection: learning to simultaneously recognize and localize novel concepts. In: Asian conference on computer vision, pp 547–563. Springer
50. Li Z, Yao L, Zhang X, Wang X, Kanhere S, Zhang H (2019) Zero-shot object detection with textual descriptions. In: Proceedings of the AAAI conference on artificial intelligence, vol 33, pp 8690–8697
51. Demirel B, Cinbis RG, Ikizler-Cinbis N (2018) Zero-shot object detection by hybrid region embedding. arXiv preprint arXiv: 1805. 06157
52. Hayat N, Hayat M, Rahman S, Khan S, Zamir SW, Khan FS (2020) Synthesizing the unseen for zero-shot object detection. In: Proceedings of the Asian Conference on computer vision
53. Xian Y, Sharma S, Schiele B, Akata Z (2019) f-vaegan-d2: A feature generating framework for any-shot learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 10275–10284
54. Jocher G, Chaurasia A, Stoken A, Borovec J, Kwon Y, Michael K, Fang J, Wong C, Yifu Z, Montes D, et al (2022) ultralytics/yolov5: v6. 2-yolov5 classification models, apple m1, reproducibility, clearml and deci
55. Wang C-Y, Bochkovskiy A, Liao H-YM (2023) Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 7464–7475
56. He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
57. Howard A, Sandler M, Chu G, Chen L-C, Chen B, Tan M, Wang W, Zhu Y, Pang R, Vasudevan V et al.: (2019) Searching for mobilenetv3. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 1314–1324
58. Redmon J, Farhadi A (2018) Yolov3: An incremental improvement. arXiv preprint arXiv: 1804. 02767
版权说明:
本文由 youcans@xidian 对论文 “Single-stage zero-shot object detection network based on CLIP and pseudo-labeling” 进行摘编和翻译。该论文版权属于原文期刊和作者,本译文只供研究学习使用。
引用格式: J. Silva-Rodríguez, H. Chakor, R. Kobbi, J. Dolz, and I. Ben Ayed, “A Foundation Language-Image Model of the Retina (FLAIR): encoding expert knowledge in text supervision,” Medical Image Analysis, vol. 99, p. 103357, 2025, doi: 10.1016/j.media.2024.103357
youcans@xidian 作品,转载必须标注原文链接:
【CLIP】基于CLIP与伪标签的单阶段零样本目标检测网络
(https://youcans.blog.csdn.net/article/details/155648224)
Crated:2025-12

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 29
29 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)