北大×NVIDIA让机器人世界模型有了“物理感”:视频生成登顶,闭环规划成功率提升50%
一句话讲清楚👉🏻 PhysisForcing 把机器人视频生成里的“物理是否说得通”拆成轨迹连续和关系一致两件事,只在机械臂、物体、接触点等关键区域施加训练监督,让世界模型生成的视频更像真实动作,也更能帮机器人做决策。

-
论文标题:PhysisForcing: Physics Reinforced World Simulator for Robotic Manipulation
-
论文链接:https://arxiv.org/abs/2606.28128
-
Github 链接:https://github.com/dagroup-pku/PhysisForcing
-
项目链接:https://dagroup-pku.github.io/PhysisForcing.github.io/
机器人世界模型真正难的地方在于:画面精致还不够,动作之后的结果必须守住基本物理规则。
比如机械臂夹住杯子,下一帧杯子突然漂开;夹爪推动苹果,苹果却像贴在桌面上一动不动;机器人把物体放到架子上,物体形状在中途变形。对普通视频生成来说,这些可能只是局部瑕疵。对机器人来说,它们会直接污染训练信号:模型学到的动作后果变成了一段不可靠的视觉幻觉。
PhysisForcing 盯上的就是这个问题。它没有重新设计一个机器人专用的大模型,也没有在推理时外挂物理引擎。论文提出的是一个训练框架:在微调视频扩散模型时,把监督集中到最容易出物理错误的区域,并同时约束两类信号。
一类是像素级轨迹,让点的运动连续、接触合理;另一类是语义级关系,让机械臂、物体、场景之间的相对关系随动作一起变化。最后得到的模型在多个机器人视频生成基准上刷新最好成绩,作为世界模型接入动作规划时,闭环成功率也从 16.0% 提到 24.0%。
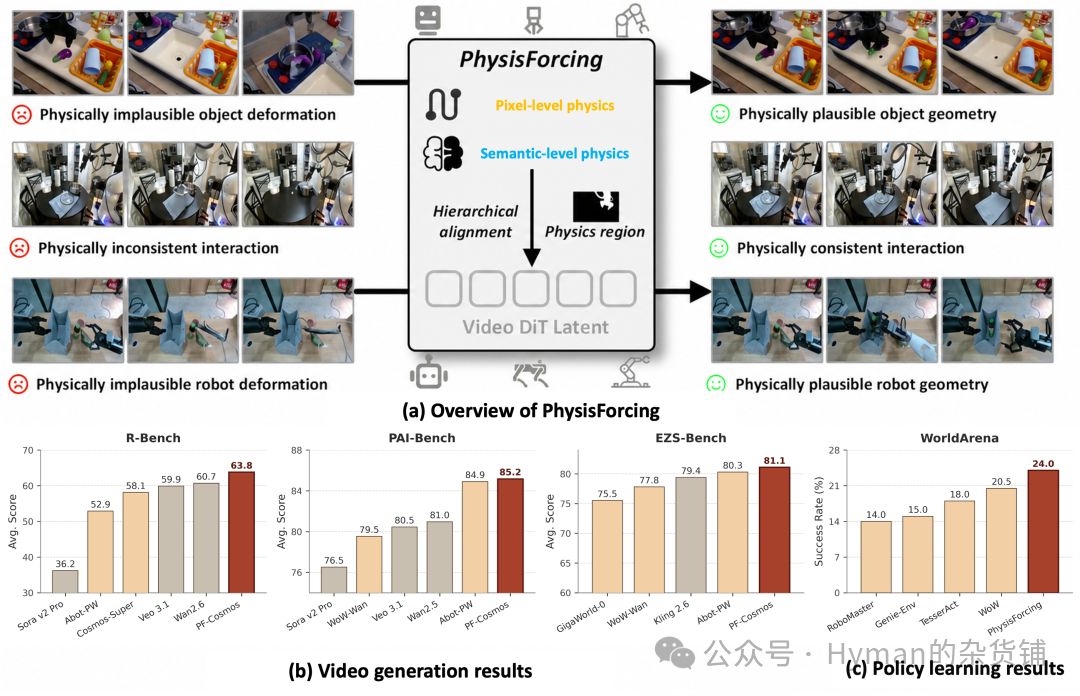
PhysisForcing 的整体效果:同一个训练框架既改善机器人视频生成,也能提升后续策略学习和世界模型规划。
问题不在“会不会生成视频”,而在“视频能不能当世界”
过去一年,视频生成模型已经很会“拍”机器人了。 Sora 、 Veo 、 Wan 、 HunyuanVideo 这类通用视频模型能生成细节丰富的画面, Cosmos 、 DreamGen 、 Vidar 等机器人世界模型则更贴近具身场景。
可机器人操作有一个特殊要求:视频必须能表达动作造成的物理后果。
拿“夹爪把红苹果移动到木质平台第二层”这个任务来说,模型不能只生成一个“像机器人实验室”的视频。它必须保持苹果形状稳定,夹爪和苹果之间有接触,苹果的轨迹要连贯,最后还要真的落在指定平台上。只要其中一环断掉,这段视频就很难作为世界模拟器使用。
论文把常见失败分成两类:
■局部动态错误。 典型表现是夹爪轨迹断裂、物体穿模、反重力漂浮、运动突然跳变。
■全局关系错误。 典型表现是机械臂已经接触物体,物体却没有跟着动;或者物体被抓住后又和夹爪分离。
这两类错误对应两个层次。点的运动要连续,这是像素级问题;物体和机械臂的互动要合理,这是语义关系问题。只靠重建损失或普通微调,很容易把背景、桌面、静止物体和接触区域混在一起优化,真正有物理信息的部分反而被稀释。
PhysisForcing 的判断很直接:机器人操作里的物理线索高度集中,主要在机械臂、被操作物体、接触区域和移动部分。训练时应该把力气花在这些地方。
先找“物理信息区域”
PhysisForcing 的第一步,是从参考视频中找出哪些位置最值得监督。
论文使用点跟踪器获取视频中每个查询点的时序轨迹。给定视频 ,可以得到轨迹集合 。其中 表示第 个点在第 帧的位置。
每个点的运动强度定义为:
如果只看 ,背景抖动、无关运动也可能被选中。论文又引入第一帧深度图 ,用深度给前景区域更高权重:
这里 是数值稳定项。 同时考虑了“动得多”和“更像前景”,比单纯运动幅度更适合抓住机械臂和物体接触区域。
接着,模型用平均分作为自适应阈值,得到轨迹级物理掩码:
被选中的轨迹再投影回每一帧,形成时空物理掩码 。这张掩码后面会同时服务于像素级和语义级监督。
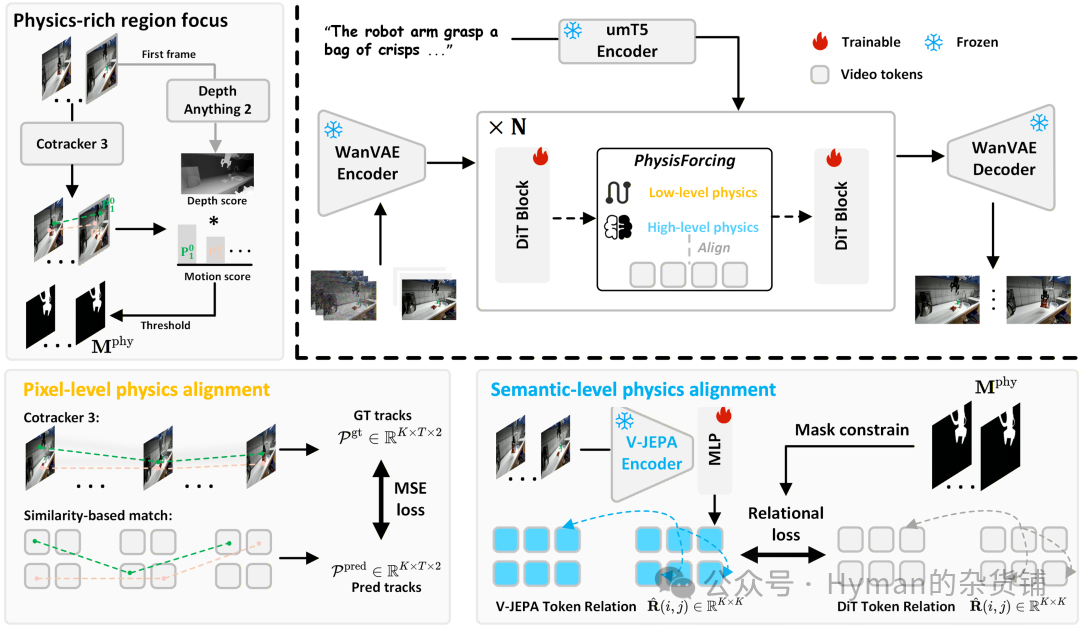
方法框架:先定位物理信息区域,再在 DiT 中间层同时加入轨迹对齐和关系对齐。
这样做绕开了显式建模“力”“摩擦”“接触力”的难题。模型只需要从视频里找出动得明显、又更靠近前景的区域,训练信号就会自然集中到夹爪、物体和接触点附近。
第一层监督:让点沿着合理轨迹走
物理错误最容易被肉眼看出来的部分,是轨迹断裂。
夹爪本来向右移动,下一帧突然出现在左边;物体被夹住后应该跟着动,却在中途原地停住。这些问题都可以转化为点轨迹是否连续。
PhysisForcing 在视频生成模型的中间 DiT 层取隐藏特征 ,经过轻量 MLP 后得到特征图 。第一帧特征作为查询,其余帧作为键:
对第一帧中的查询点 ,模型计算它和第 帧所有空间位置的相似度:
再通过空间 Softmax 和坐标期望,得到预测位置:
最后,用参考视频中 CoTracker3 提取的轨迹作为目标,在物理掩码覆盖的区域计算均方误差:
这相当于告诉 DiT 中间层:你内部表示出的点运动,应该和真实机器人视频里的点轨迹对齐。尤其是夹爪、物体、接触区域,不允许随便跳。
我的理解是,这个设计比直接在像素上加重建损失更细。像素重建容易奖励“画得像”,但轨迹对齐奖励的是“动得对”。对机器人视频来说,后者才是世界模型的底线。
第二层监督:让物体关系跟着动作变
只有轨迹还不够。
一个视频可以做到局部点运动平滑,但全局关系仍然不对。比如夹爪和杯子各自动得很顺,可两者之间没有保持“抓取后耦合”的关系;或者推动物体时,接触点动了,物体主体却没有发生相应位移。
PhysisForcing 用冻结的视频理解编码器来提供语义级关系目标。它不要求 DiT 去复制编码器的每个绝对特征,而是对齐物理信息区域内 token 之间的相似度矩阵。
给定输入视频 ,冻结编码器输出目标表示 , DiT 中间层经过 MLP 后得到 :
然后用物理掩码选择一批时空 token :
对任意两个 token ,分别计算 DiT 侧和编码器侧的余弦关系:
语义级物理损失是两张关系矩阵的平均绝对差:
这一步关注一批关键 token 之间的相似关系有没有保持住,单个 token 本身像不像反倒退到次要位置。抓取、推动、放置,本质上都是关系变化。机械臂和物体什么时候靠近,什么时候绑定,什么时候分离,往往比单个像素更能描述操作是否合理。
训练总目标也很清楚:
是标准 flow matching 损失, 和 分别控制两类物理损失权重。辅助模型只在训练时使用,推理时全部丢掉,所以不会增加生成视频的额外推理成本。
训练设置:三类视频骨干都能接入
论文没有只在一个小模型上验证。 PhysisForcing 被加到三类视频骨干上:
■Wan2.2-I2V-A14B :图像到视频 MoE 扩散 Transformer ,训练时主要微调高噪声专家。
■Wan2.2-TI2V-5B :文本/图像到视频统一扩散 Transformer ,直接微调整个 denoiser 。
■Cosmos3-Nano :约 16B 参数的视频模型,按官方图像到视频后训练设置使用 LoRA 微调。
训练数据来自 RoVid-X 的大规模机器人视频集合。原始数据约 400 万段机器人视频,论文经过运动分数、任务去重、图文对齐等过滤,保留约 50 万段高质量 clip 。
辅助感知模型也来自现成工具: CoTracker3 负责参考点轨迹, Depth-Anything-V2 提供第一帧相对深度, V-JEPA 2 作为冻结视频理解编码器提供关系结构。它们都只用于训练目标提取,部署时不进入推理链路。
这让 PhysisForcing 更像一个“训练配方”,而不是一个绑定特定架构的新世界模型。只要底层是 DiT 式视频生成骨干,中间层能读出时空特征,就有机会套上这一套物理对齐目标。
生成效果: R-Bench 、 PAI-Bench 、 EZS-Bench 都涨
实验覆盖三个机器人视频生成基准。简单说, R-Bench 看任务和机器人形态覆盖面, PAI-Bench 更强调真实机器人图像提示下的物理语义, EZS-Bench 则故意测试训练外组合。三者合起来,能把“画得好”和“真的懂交互”区分开。
R-Bench 包含 650 组图文提示,覆盖操作、空间关系、多实体协作、长程规划、视觉推理,以及单臂、双臂、四足、人形等机器人形态。 PAI-Bench 取机器人领域子集,共 174 组真实机器人图像提示。 EZS-Bench 则强调训练无关的零样本组合,一共 196 个未见过的机器人、任务和场景组合。
论文原表很宽,不适合手机阅读。把关键结果压缩后,大致是下面这样:
|
基准 |
对比对象 |
PhysisForcing |
变化 |
|---|---|---|---|
|
R-Bench |
Wan A14B base 50.7 |
PF-Wan 62.0 |
+22.3% |
|
R-Bench |
Cosmos base 58.4 |
PF-Cosmos 63.8 |
+9.2% |
|
PAI-Bench |
Cosmos ft 84.03 |
PF-Cosmos 85.17 |
第一 |
|
EZS-Bench |
Cosmos ft 80.29 |
PF-Cosmos 81.08 |
第一 |
R-Bench 上, PF-Cosmos 平均分达到 63.8 ,超过商业模型 Wan2.6 的 60.7 ,也超过机器人专用基线 Abot-PhysWorld 的 52.9 。 PF-Wan 达到 62.0 ,在 Wan2.2-I2V-A14B 基础上相对提升 22.3%,相比普通微调也有 7.1%的提升。
PAI-Bench 机器人子集上, PF-Cosmos 整体平均 85.17 ,超过 Abot-PhysWorld 的 84.91 。 Domain Score 达到 93.26 ,这个分数更直接衡量机器人交互的物理语义合理性,而不是单纯画质。
EZS-Bench 上, PF-Cosmos 整体平均 81.08 ,同样排在最高。这个基准强调训练外组合,对“只记住训练分布”的方法不太友好。它能在这里涨,说明物理关系监督除了拟合已有机器人视频,也带来了一点跨场景泛化能力。
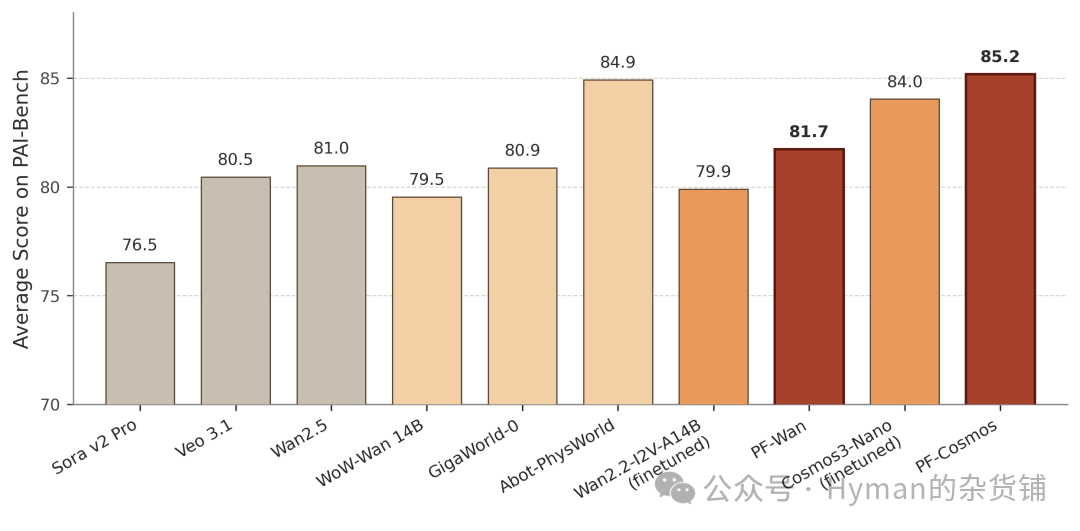
PAI-Bench 机器人领域结果: PhysisForcing 在质量和领域指标上保持领先。
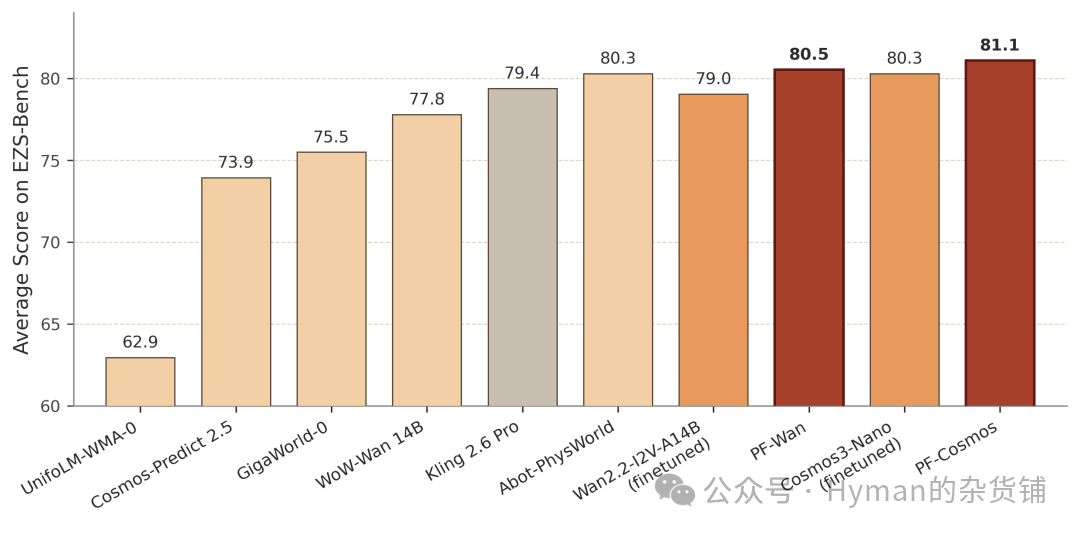
EZS-Bench 零样本结果:面对未见过的机器人、任务和场景组合, PF-Cosmos 仍取得最高整体分。
视觉对比:错误通常出在接触瞬间
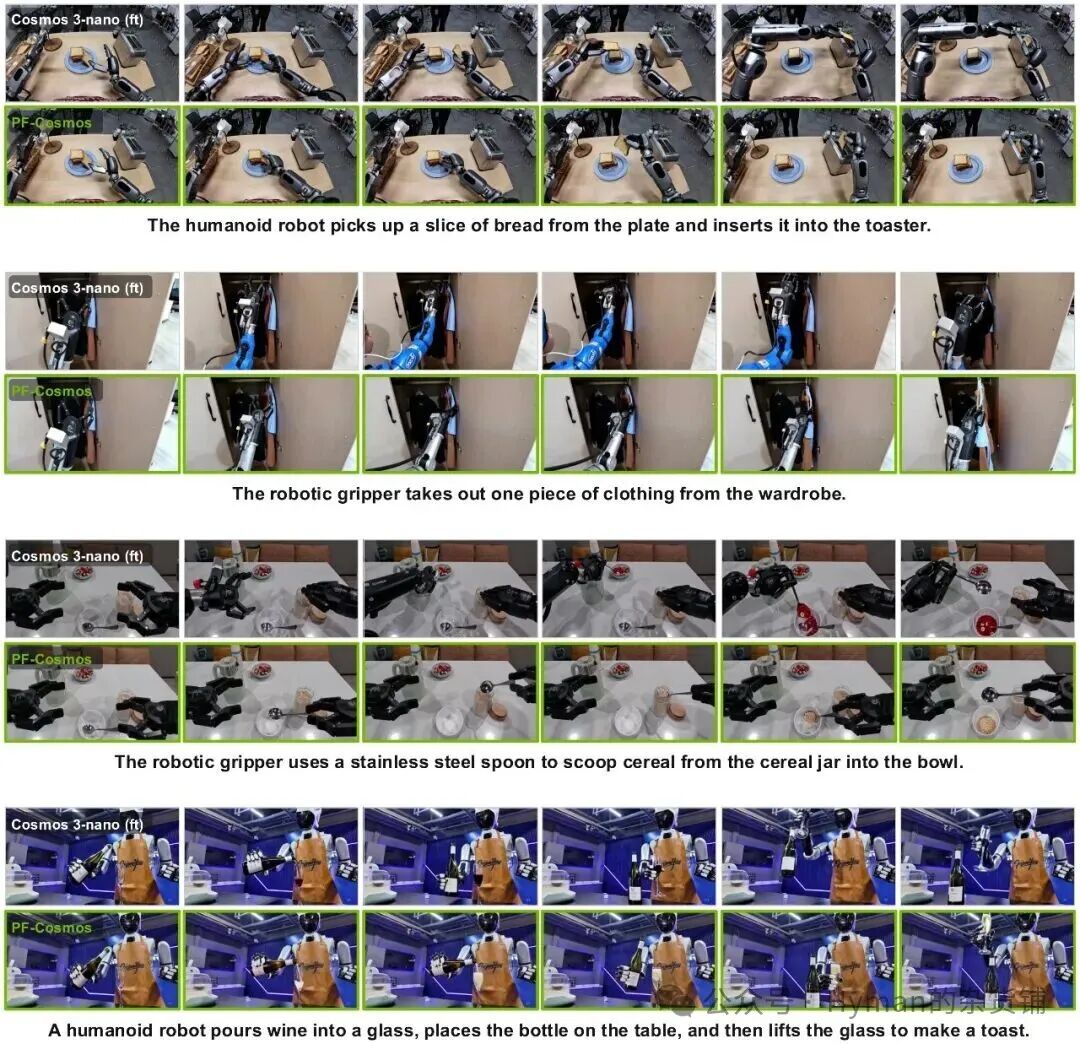
论文展示的定性结果很有代表性。同样的输入图和指令下,强视频模型往往能生成好看的机器人画面,但接触处容易露馅。
比如“把红苹果移动到木质平台第二层”,有些模型会让苹果变形,有些会让苹果在没有稳定接触的情况下移动,有些能完成大致动作但最终位置不对。 PhysisForcing 的版本更倾向于保持夹爪和物体的接触关系,物体形状也更稳定。

与多种强视频生成模型的定性对比:绿色行是 PhysisForcing 训练后的模型,主要改善接触、位移和物体形状稳定性。
论文附录里还有更多横向案例。它们覆盖单臂、双臂、人形机器人和不同任务,常见失败包括状态漂移、接触断裂、物体变形、目标位置错误。 PhysisForcing 并没有让模型突然具备完美物理模拟能力,但它明显减少了最影响机器人任务的那类错误。

更多对比案例:同一提示下, PhysisForcing 更容易保持动作前后状态一致。

不同模型在接触丰富任务上的生成差异,问题集中在抓取、推动和放置阶段。

跨任务定性结果: PhysisForcing 对物体状态和机器人动作的耦合更稳定。
不只生成视频,还能帮机器人做策略
如果世界模型只是为了“看起来合理”,意义还有限。论文进一步把 PhysisForcing 训练后的 Wan2.2-TI2V-5B 接入 Fast-WAM ,用作世界动作模型的视频骨干,在 RoboTwin 2.0 上评估策略成功率。
平均成功率从 68.2%升到 72.8%。其中接触密集的任务提升最大:
|
任务 |
基线 |
加入 PF |
变化 |
|---|---|---|---|
|
放空杯 |
41.5% |
63.0% |
+21.5 |
|
按订书机 |
49.0% |
60.0% |
+11.0 |
|
拿滚筒 |
58.5% |
63.0% |
+4.5 |
|
平均 |
68.2% |
72.8% |
+4.6 |
也有任务下降,比如 shake_bottle 从 97.5%降到 94.5%, stack_bowls_two 从 69.5%降到 63.0%。这点值得单独看:物理对齐并不是无条件提升所有动作,它对接触强、轨迹容易断的任务帮助更明显;对已经很高分或需要更长程规划的任务,收益可能被其他瓶颈限制。
WorldArena 动作规划协议下,世界模型要预测未来视频,再由共享逆动力学模型解码出动作并执行。这里 PhysisForcing 把闭环成功率从 16.0%拉到 24.0%,超过 WoW 的 20.5%。相对提升是 50%。
|
模型 |
任务 1 |
任务 2 |
平均 |
|---|---|---|---|
|
WoW |
20.0% |
21.0% |
20.5% |
|
Wan2.2-5B |
12.0% |
20.0% |
16.0% |
|
+ PF |
22.0% |
26.0% |
24.0% |
这组结果把生成质量和机器人执行结果接了起来:视频里的接触关系更稳定,规划器选出的动作也更容易成功。如果一个世界模型能更可靠地预测接触后的状态,规划器就更可能避开漂亮但错误的未来画面。
消融实验:两种物理损失缺一块都弱
论文做了三组值得看的消融。
第一组看两个损失是否互补。在 Wan2.2-TI2V-5B 上,普通微调 R-Bench 平均 44.8 。只加像素轨迹损失升到 47.2 ,只加语义关系损失升到 46.2 ,两者一起是 47.5 。在更大的 Wan2.2-I2V-A14B 上,普通微调 57.9 ,两者一起达到 62.0 。
|
设置 |
TI2V-5B |
A14B |
|---|---|---|
|
普通微调 |
44.8 |
57.9 |
|
只加轨迹 |
47.2 |
60.7 |
|
只加关系 |
46.2 |
60.0 |
|
两者结合 |
47.5 |
62.0 |
轨迹损失单独更强,因为轨迹断裂是机器人视频里最常见、最直接的局部失败;关系损失更像补上全局互动,比如抓住后保持耦合、推动后物体真的位移。两者服务的错误类型不同,所以组合起来最好。
第二组看“只监督物理信息区域”是否必要。对所有 token 均匀施加两类损失,平均分从 44.8 升到 46.0 ;只在物理信息区域监督,则升到 47.5 。背景和静止区域并非完全无用,但它们会稀释接触处的训练信号。
第三组看对齐施加在 DiT 哪一层。 Wan2.2-TI2V-5B 在 PAI-Bench 上,层 10 得 83.9 ,层 15 得 85.2 ,层 20 得 84.1 ,层 25 得 83.2 。中间层最好,因为早期层偏外观,晚期层已经更贴近噪声预测输出,中间层更适合承载运动和关系结构。
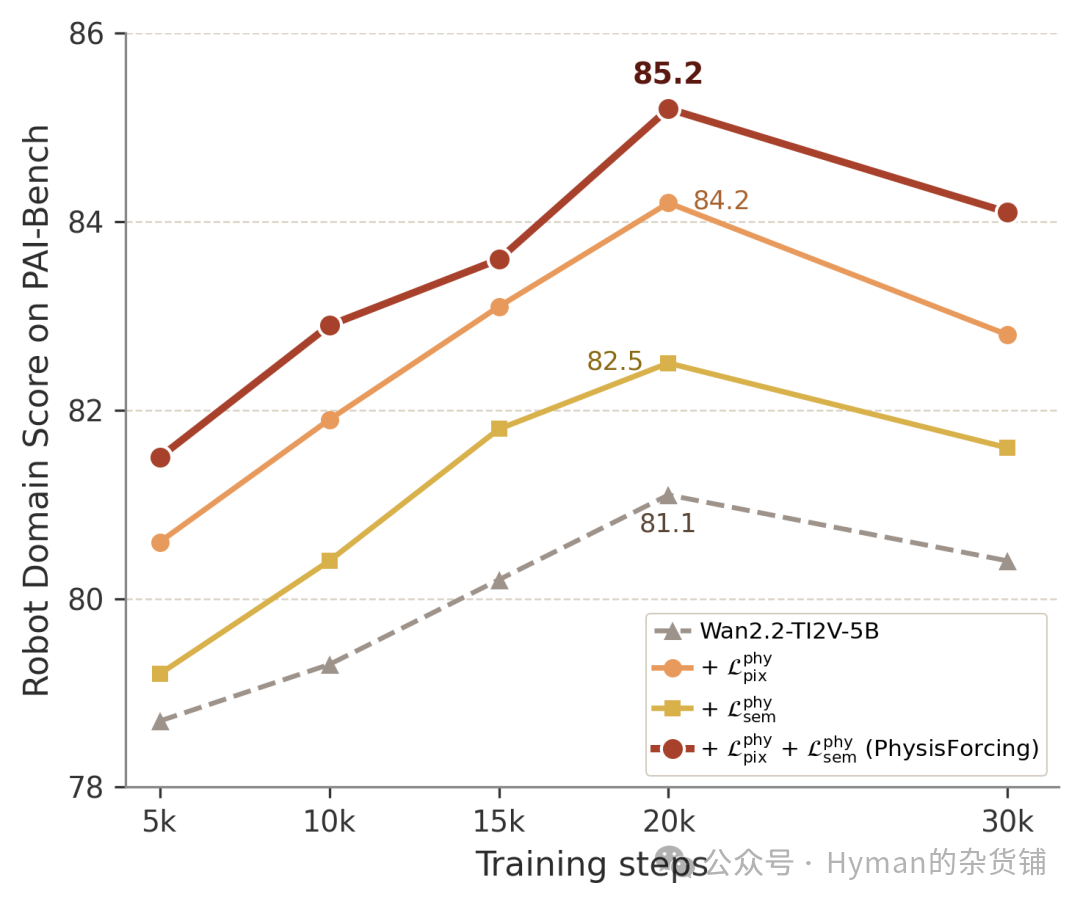
训练过程与损失消融:轨迹损失和关系损失在训练中持续互补。

Wan 骨干上的定性消融:加入 PhysisForcing 后,物体变形和接触断裂减少。
Cosmos 骨干上的定性消融:相同骨干经过物理对齐后,动作结果更稳定。
这篇工作的真正价值:把“物理感”变成可训练信号
机器人世界模型这条路,过去经常卡在一个矛盾里。
纯视频生成模型扩展性强,数据多,画面好,但它未必理解物理后果。显式物理模拟器更可靠,却成本高、覆盖有限,也很难直接适配开放世界视觉场景。 PhysisForcing 走的是中间路线:不显式模拟力学方程,改用视频中的可观察物理线索构造训练目标。
我更愿意把它看成一个训练目标设计上的提醒:机器人视频里真正值钱的像素,其实只占画面的一小部分。
第一,世界模型的训练目标要从“重建未来帧”走向“重建因果关系”。机器人任务里的未来帧不是普通视频帧,它承载动作后果。一个物体被推之后是否移动,一个杯子被夹住后是否跟着夹爪走,这些关系比背景纹理更重要。
第二,物理监督不一定要覆盖整帧。对机器人操作来说, 95%的画面可能是桌面、墙面、背景,真正决定任务成败的区域很小。区域聚焦能让训练预算花在更有用的地方。
第三,视频理解模型可以反过来教视频生成模型。 V-JEPA 2 这类自监督编码器不是机器人模型,但它捕捉到的 token 关系可以作为“物体如何相互关联”的度量空间。生成模型不需要复制它的表示,只要学会类似的关系结构。
论文没有把工作做成一个复杂的推理时系统,也符合这个取舍。推理时越轻,越容易接入现有视频生成和机器人规划链路;训练时把物理约束打进中间表示,部署时仍然保持普通视频模型的速度和接口。
仍然有限:它不是万能物理引擎
论文也明确写了局限。 PhysisForcing 是一个微调框架,会继承底层视频骨干的能力上限。如果基础模型本身缺少长程时序推理、复杂物体知识或精细世界常识,物理对齐只能改善一部分问题。
另外,它用到的物理目标来自点跟踪、深度估计和冻结视频编码器。这些工具本身也会出错。比如透明物体、强遮挡、快速运动、复杂柔性物体,都可能让轨迹和深度信号不稳定。
还有一个现实问题:当前指标仍然大量依赖多模态模型评判。 R-Bench 、 PAI-Bench 、 EZS-Bench 都努力和人工偏好对齐,但机器人世界模型最终要落到真实硬件。视频看起来更物理,不等于真实机器人一定能安全执行。
我会把 PhysisForcing 看成一个很实用的阶段性方案:它没有解决“让 AI 完全理解物理世界”这个大问题,但抓住了机器人视频生成里最要命的接触和关系错误,并给出了可复用的训练方法。
更多生成样例
附录样例可以归纳成一个观察: PhysisForcing 的优势不在单帧画质,而在动作链条中少出“状态断裂”。抓取、推动、放置这三类任务里,只要接触关系稳定,后续规划才有利用价值。

更多横向对比:在复杂场景中,物体状态漂移是许多模型的高频问题。

更多模型对比: PhysisForcing 在多个机器人形态上保持更稳定的交互结果。
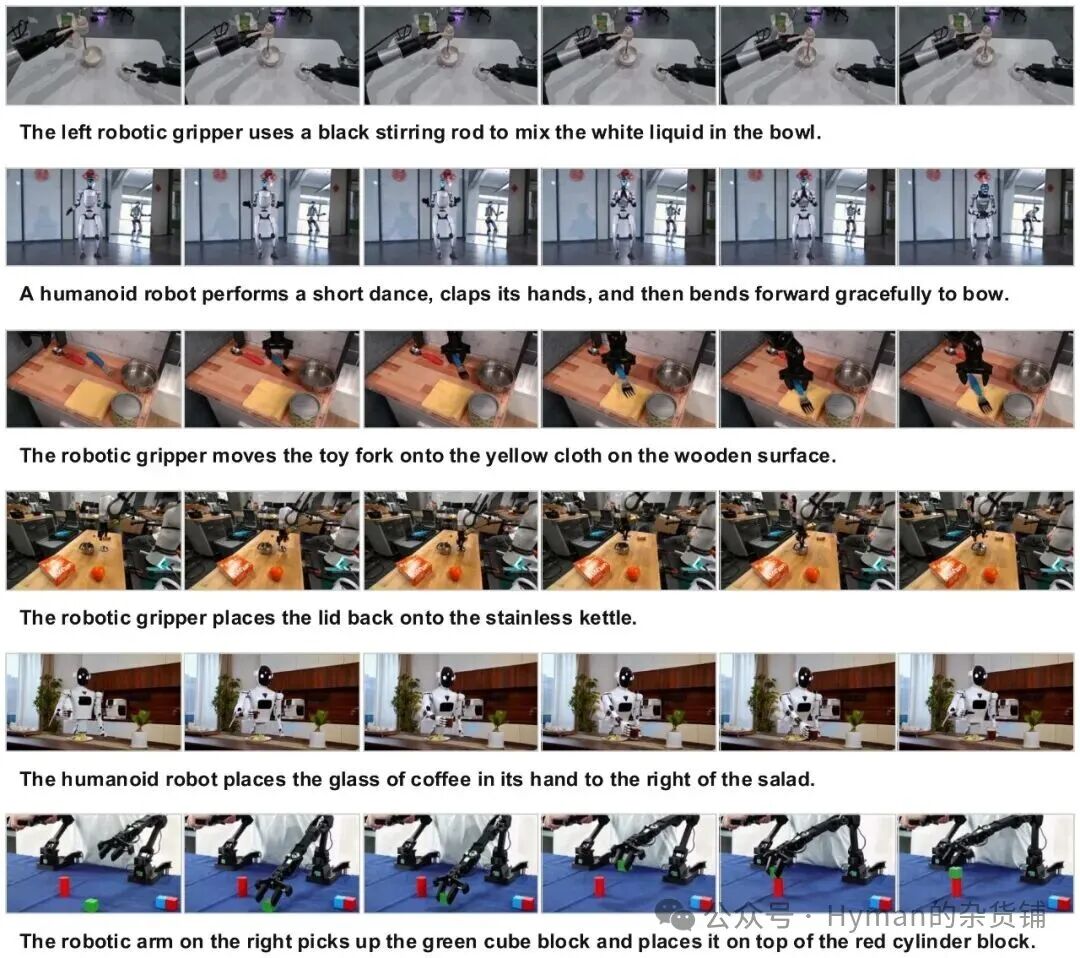
PhysisForcing 生成样例:模型能在多种场景中跟随指令并维持基本物理规律。

更多生成样例:机器人、物体和场景关系在动作过程中更少出现突然断裂。
写在最后
具身智能需要的世界模型,要能预测动作之后真实世界会怎样变化;一段看起来真实的视频,只有在动作后果也可信时,才适合放进机器人决策链路。
PhysisForcing 的贡献就在这里:它把轨迹连续、接触一致、物体关系这些过去很难直接写进损失函数的东西,拆成可训练的像素级和语义级对齐信号。实验结果也给了一个清楚的方向:当视频模型更懂物理,机器人策略确实能从中受益。
后续如果视频基础模型继续变强,类似的物理对齐方法仍有用武之地:它负责把训练注意力压到最容易影响机器人决策的接触和关系上,并不需要重新发明世界知识。对机器人来说,这或许比单纯追求更高清、更长的视频更重要。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 2
2 0
0- 0



 已为社区贡献154条内容
已为社区贡献154条内容

所有评论(0)