深度学习目标检测:火焰与烟雾识别数据集标注完成

简介:数据集支持深度学习模型用于火焰和烟雾的实时目标检测,涵盖自动驾驶、安全监控和火灾预警等领域。火焰和烟雾作为目标,其图像数据的多样性和准确性对模型性能至关重要。深度学习模型如Faster R-CNN、YOLO和Mask R-CNN,结合数据增强技术,可用于提高模型泛化能力。适用于嵌入式设备的轻量级模型和性能评估指标确保模型的实时性和可靠性。此数据集为智能系统提供基础,旨在提高公共安全并减少财产损失。 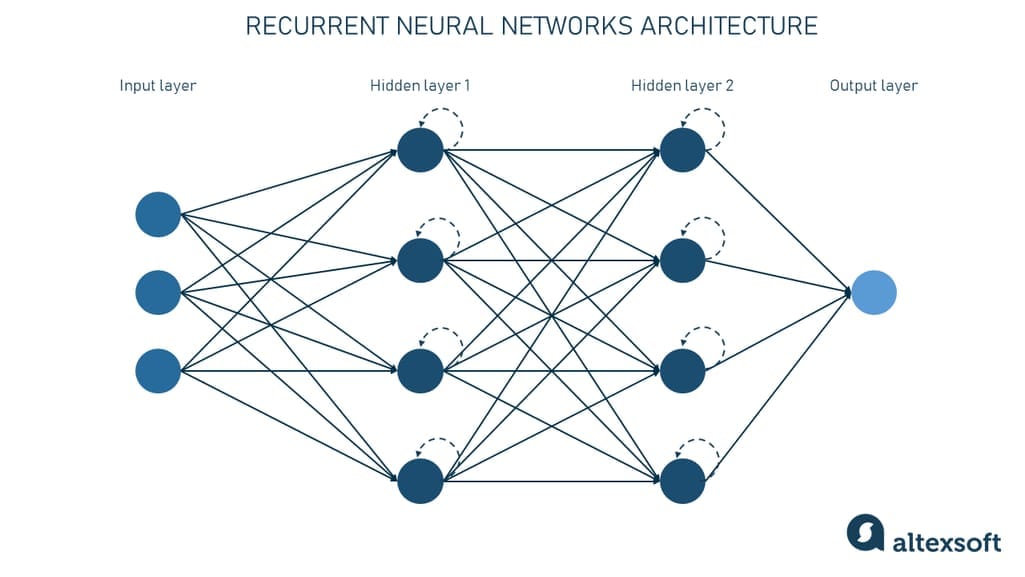
1. 深度学习在计算机视觉中的应用
随着深度学习技术的快速发展,计算机视觉领域已经迎来了前所未有的变革。特别是图像处理和分析,从传统的手工特征提取发展到了端到端的深度学习模型,极大提高了处理速度和准确性。本章将重点关注深度学习在目标检测任务中的应用,尤其是火焰与烟雾识别这一具体场景。在这一场景中,深度学习不仅能够提升传统的目标检测算法的效率和准确性,还能够赋予系统自动学习和适应新场景的能力,从而为公共安全和环境监测提供强大的技术支持。我们将在接下来的章节中,详细解读深度学习在该特定应用中的具体实施步骤,包括数据的收集与处理、模型的选择与训练以及最终的部署和优化。
2. 火焰与烟雾识别的重要性与挑战
火焰与烟雾的快速准确识别在多个领域中扮演着至关重要的角色。消防部门需要依靠自动化系统进行早期火情监测,以减少损失;环境保护机构需要监控污染源,从而采取相应的减排措施。而在计算机视觉领域,实现火焰与烟雾的识别技术对提高公共安全和保护环境具有重要的现实意义。
火焰与烟雾识别的现实需求
火焰与烟雾识别技术的应用场景广泛,涉及森林防火、工业监测、城市安全等多个领域。在森林防火中,通过安装在无人机或固定监测点上的摄像头,实现对火源的实时监测,能够及时发现火灾,从而快速组织人员进行扑救。工业监测中,通过安装在烟囱、锅炉等设施周边的监控设备,可以实时监控排放物,一旦发现异常排放,即刻采取措施。在城市安全方面,尤其是在高层建筑和密集城区,火焰与烟雾的识别技术可以作为智能安防系统的一部分,一旦发现火情,自动报警并启动灭火系统。
环境挑战与技术难题
在不同环境下实现火焰与烟雾的准确识别面临众多挑战。首先是环境因素的影响,如光线变化、背景复杂度、天气条件等,这些因素都会影响火焰与烟雾的特征表现。其次是火焰与烟雾本身的不稳定性,火焰颜色、形状、亮度等特征随时间变化,而烟雾的密度、形状、移动方向等也极不固定。
为了应对这些挑战,研究者们利用深度学习技术发展了多种识别算法,但这些算法在实际应用中仍然面临着过拟合、泛化能力不足等问题。如何在保证识别准确率的同时,提高模型的泛化能力,以适应复杂多变的现实环境,是一个长期存在的技术难题。
深度学习技术的推进作用
尽管面临挑战,深度学习技术已经在火焰与烟雾识别领域取得了显著进展。通过大规模数据集的训练和复杂的网络结构设计,研究者们已经能够构建出能够在各种环境下表现良好的识别模型。这些技术的发展,不仅提高了识别的准确性,而且为相关领域的技术升级提供了新的可能性。
例如,卷积神经网络(CNN)在图像分类任务上的成功应用启发了火焰与烟雾的图像识别研究。随着模型结构的不断创新和优化,如Faster R-CNN、YOLO、Mask R-CNN等高级模型被开发出来,这些模型在保持高精度的同时,大幅提升了火焰与烟雾识别的实时性。
实际应用案例分析
在实际应用中,火焰与烟雾识别技术已经得到了广泛应用。例如,在一些高速公路隧道中,部署了火焰与烟雾识别系统,以确保隧道的安全运行。在隧道的监控系统中,安装的摄像头实时采集图像数据,并通过深度学习算法进行图像分析,一旦检测到火焰或烟雾,系统便会立即发出警报,并通知紧急响应小组前往处理。
此外,智能楼宇和工厂中也集成了类似的识别系统。例如,智能楼宇系统可以检测到起火点并自动启动灭火装置,而工业自动化系统则可以通过实时监控减少因火灾造成的生产损失。
总结
火焰与烟雾识别技术的重要性不言而喻,该技术的发展对于提升公共安全和环境保护水平具有重要作用。尽管在实际应用中面临着各种挑战,但随着深度学习技术的不断进步,这些挑战正在逐步被克服。未来,我们可以期待更加高效、可靠的火焰与烟雾识别技术的出现,为人类生活带来更多安全保障。
3. 数据集的多样性和标注质量
3.1 数据集构建的重要性
在深度学习领域,模型的性能在很大程度上依赖于训练数据集的质量和多样性。火焰与烟雾识别任务尤为依赖这一点,因为环境因素、拍摄角度和光线变化等因素都会显著影响图像数据。一个高质量且多样化的数据集不仅能够帮助模型捕获这些变化,还能提高模型对不同场景和条件的泛化能力。
3.1.1 数据集构建的目标
数据集的构建目标是确保包含足够多的样本,覆盖尽可能多的场景和变化,从而训练出鲁棒性强的模型。在火焰与烟雾识别中,数据集应当包含如下特征:
- 环境多样性 :城市街道、森林、工业区等不同环境的火灾场景。
- 时间多样性 :不同时间段,如白天、傍晚、夜晚的火灾图像。
- 变化多样性 :不同类型的火焰和烟雾,以及火焰的不同大小、颜色和形态。
3.1.2 数据收集的挑战
收集高质量和多样化的火焰与烟雾数据是一个复杂且耗时的过程。以下是收集数据时可能遇到的一些挑战:
- 火灾场景的获取 :火灾事件不常见,且难以预测,这使得现场数据收集变得困难。
- 环境因素的多样性 :需要在多种不同条件下进行拍摄,以获得尽可能丰富的数据。
- 标注工作的复杂性 :火焰和烟雾的边界模糊,且形状多变,标注工作需要高度的专业知识。
3.1.3 数据预处理与增强
收集到的原始数据通常需要进行预处理,以确保质量和一致性。数据预处理包括调整图像大小、格式转换、色彩标准化等步骤。数据增强技术则用于人为地增加数据集的多样性,常见的方法包括图像旋转、缩放、剪切和颜色变换等。
3.2 数据集的标注方法
标注工作是将图像中的火焰与烟雾区域用边界框(bounding boxes)或其他形式的标签明确标识出来,以便模型识别和学习。准确的标注对于提高模型识别准确性至关重要。
3.2.1 手动标注与工具
由于火焰与烟雾的不规则性,手动标注依然是最准确的方式。标注工具如LabelImg、CVAT等,为标注工作提供了便捷的界面和功能,包括框选、类别标注、保存标注信息等。
3.2.2 半自动化标注
为了提高标注效率,可以使用半自动化标注技术,如基于图像分割的方法。这些方法通常需要一些初始的标注信息,然后通过算法自动填充其余部分。例如,利用图像处理技术,可以先标记出图像中火焰亮度较高的区域,然后由人工审核和修正。
3.2.3 全自动化标注
随着深度学习技术的发展,自动化标注方法正逐步成熟。基于深度学习的图像分割模型可以自动识别出图像中的火焰与烟雾,并输出精确的标注。然而,这些自动化方法通常需要大量的已标注数据来训练初始模型,且标注的质量可能无法完全达到人工标注的水平。
3.3 标注质量对模型性能的影响
标注数据集的质量直接影响到训练出的模型性能。标注不准确或不一致会导致模型在实际应用中表现出较差的泛化能力,甚至误导模型学习到错误的特征。
3.3.1 精确度和一致性
高质量的标注意味着每个样本中火焰与烟雾区域的标注要尽可能精确和一致。不精确或不一致的标注会导致模型产生误差,降低其对真实场景的识别能力。
3.3.2 数据集的平衡性
标注数据集的平衡性同样重要。如果数据集中某一类别的样本远多于其他类别,模型可能偏向于识别这些类别而忽视了其他类别的识别,导致所谓的类别不平衡问题。
3.3.3 错误标注的检测与修正
在训练过程中,应当定期检查数据集中的错误标注,并进行修正。可以采用交叉验证、专家复审等方法来检测错误标注。这不仅能提高数据集的质量,还能帮助模型更好地泛化到新的数据。
3.4 数据集案例分析
让我们以一个假想的火焰与烟雾识别数据集为例进行分析,介绍如何构建和使用数据集,以及标注质量对模型的影响。
3.4.1 数据集构建的步骤
假定我们已经收集了来自不同环境和条件下的火灾图像,以下是一系列构建数据集的步骤:
- 图像筛选 :剔除模糊不清或无关图像。
- 图像预处理 :统一图像尺寸,进行必要的格式转换。
- 手动标注 :使用标注工具对火焰与烟雾区域进行边界框标注。
- 数据增强 :应用旋转、缩放等方法增加数据集多样性。
3.4.2 标注质量评估
针对构建好的数据集,我们需要评估标注的准确性和一致性。可以通过以下几个方面来进行评估:
- 标注的一致性检查 :比较同一样本中不同标注者的工作,确保一致。
- 标注准确性检查 :通过专家评审或使用已知标签进行比对。
- 标注覆盖度检查 :确保所有关键场景和变化都被覆盖。
3.4.3 模型训练与测试
使用该数据集训练深度学习模型,然后在测试集上进行验证。测试集应当从未参与过训练的数据中选取,以确保测试结果的公正性。
- 模型选择 :选择适合火焰与烟雾识别的深度学习模型,如YOLO或Faster R-CNN。
- 训练与优化 :调整模型参数,进行多次训练和验证,优化模型性能。
- 测试与评估 :在测试集上评估模型的准确率、召回率和mAP等指标。
3.5 未来发展方向
随着技术的发展,数据集的构建和标注工作也在不断地改进和创新。未来的发展方向可能包括:
3.5.1 自动化标注技术的进步
随着计算机视觉技术的进步,自动化标注技术将更加快速和准确,从而提高数据集构建的效率和质量。
3.5.2 增强现实标注工具的使用
增强现实(AR)技术的应用可能会为图像标注工作带来新的方法,如实时标注和交互式标注等。
3.5.3 多模态数据集的发展
未来的研究可能倾向于结合图像、视频、红外线等多模态数据,以进一步提高火焰与烟雾识别的准确性。
在本章节中,我们详细探讨了数据集构建对于深度学习模型训练的重要性,从数据收集、预处理、标注到评估,每一步都至关重要。通过分析数据集的多样性和标注质量,我们可以更好地理解如何构建和利用高质量数据集来训练高效的火焰与烟雾识别模型。随着技术的不断发展,数据集的构建和使用方法也将持续进步,为实现更准确和快速的火灾检测提供支持。
4. 深度学习模型如Faster R-CNN、YOLO、Mask R-CNN的应用
深入理解Faster R-CNN在火焰与烟雾识别中的应用
Faster R-CNN的架构解析
Faster R-CNN作为一种先进的目标检测框架,在火焰与烟雾识别任务中展现了其强大的能力。它由区域建议网络(Region Proposal Network, RPN)和Fast R-CNN检测器组成。RPN利用卷积神经网络(CNN)在特征图上预测候选区域(region proposals),Fast R-CNN则对这些区域进行分类和边界框回归。
import torch
import torchvision
# 加载预训练的Faster R-CNN模型
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# 设置模型为评估模式
model.eval()
# 通过模型推理一个输入图像
# image = ... # 这里应加载一张测试图像,并进行预处理以匹配模型要求的输入格式
# predictions = model([image])[0]
代码逻辑解释:首先导入PyTorch相关库,然后加载一个预训练的Faster R-CNN模型。模型设置为评估模式,这意味着某些层(如Dropout和BatchNorm)的参数不会在推理时发生变化。最后,可以将一个预处理过的图像传入模型得到预测结果。
优化Faster R-CNN性能
尽管Faster R-CNN在准确度方面表现优异,但它也存在速度方面的局限性。为了在实际应用中达到实时或接近实时的检测速度,研究者们通常会对模型进行各种优化策略,比如使用轻量级特征提取网络、引入非极大值抑制(NMS)的并行化处理、以及利用GPU加速等。
# 示例:调整非极大值抑制的阈值
# 这里假设已经有了检测结果predictions
# 非极大值抑制函数,调整阈值参数
def nms(detections, iou_threshold=0.5):
# ... NMS的实现代码 ...
# nms_result = nms(predictions)
逻辑分析:此代码块演示了如何实现非极大值抑制(NMS)的自定义函数,通过调整阈值参数来优化检测的精确度和速度。Faster R-CNN在进行目标检测时生成多个候选框,NMS负责移除重叠度较高的重复框,保留最可能的目标边界框。
YOLO模型在火焰与烟雾检测中的实践
YOLO版本的演进
YOLO(You Only Look Once)模型是另一种广泛应用于火焰与烟雾检测的实时目标检测算法。YOLO将目标检测任务视为一个单一回归问题,直接从图像像素到边界框坐标和类别概率的映射。随着YOLO系列模型的不断发展,YOLOv3、YOLOv4、以及YOLOv5等版本不断推陈出新,均表现出越来越高的准确性和速度。
实际案例分析
在实际的火焰与烟雾检测场景中,YOLO模型能够快速地在图像中识别出火灾发生的迹象,并且在多数情况下,YOLO模型能够实现实时检测,这对于需要立即响应的应用场景非常关键。
import torch
# 加载YOLO模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# 将模型设置为评估模式
model.eval()
# 对输入图像进行预测
# image = ... # 加载图像并进行预处理
# results = model(image)
代码逻辑解释:代码示例通过PyTorch的Hub模块加载了一个预训练的YOLOv5模型。随后,我们对模型设置为评估模式,并利用该模型对一张预处理过的图像进行目标检测预测。
模型优化与应用
YOLO模型的优化通常集中在提升检测速度和准确性。一些常用的优化手段包括模型剪枝、量化、以及知识蒸馏等。通过这些方法,可以在不同的硬件平台上实现高效的火焰与烟雾识别。
# YOLO模型的推理优化
# 这里使用了一个名为torch.backends.cudnn.benchmark的优化项
torch.backends.cudnn.benchmark = True
逻辑分析:在这段代码中,我们激活了CUDNN的基准测试模式,它可以进一步加速YOLO模型在NVIDIA GPU上的推理速度。这是因为此模式会允许CUDNN搜索最优化的卷积算法来提升计算性能。
Mask R-CNN在火焰与烟雾识别中的应用
Mask R-CNN模型的原理
Mask R-CNN在Faster R-CNN的基础上增加了一个分支,用于预测目标的像素级掩码。这使得Mask R-CNN不仅可以识别目标的位置,还可以提供更精细的目标形状信息。在火焰与烟雾识别任务中,这种额外的细节识别对于区分烟雾与其他类似纹理的对象具有很大帮助。
应用实例
由于Mask R-CNN提供实例分割的能力,因此在火焰与烟雾识别中,它可以准确地描绘出火焰和烟雾的实际形状,有助于进一步分析其扩散范围和可能的影响区域。
import torchvision
# 加载预训练的Mask R-CNN模型
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
# 设置模型为评估模式
model.eval()
# 通过模型推理一个输入图像
# image = ... # 这里应加载一张测试图像,并进行预处理以匹配模型要求的输入格式
# predictions = model([image])[0]
代码逻辑解释:代码通过加载预训练的Mask R-CNN模型,并将其设置为评估模式,准备进行图像的实例分割推理。
模型优化与效率提升
尽管Mask R-CNN在准确度上表现优异,但其较高的计算复杂度限制了其在实时应用中的使用。优化Mask R-CNN的方法包括使用更快的特征提取网络、减少掩码的解析度、或者采用轻量级的分割网络替代。
# 降低掩码解析度以提升效率的示例
# 这里展示了如何在推理时降低掩码解析度的步骤
# 降低掩码解析度函数
def reduce_mask_resolution(masks, new_resolution):
# ... 掩码降采样的实现代码 ...
# reduced_masks = reduce_mask_resolution(predictions['masks'], 128)
逻辑分析:该代码块展示了如何通过编写一个自定义函数来降低分割掩码的分辨率,从而提高模型的推理效率。通过减少每个实例掩码的像素数量,可以显著减少后处理的计算负担。
以上章节内容展示了如何在不同的深度学习模型中应用Faster R-CNN、YOLO和Mask R-CNN进行火焰与烟雾的识别任务。通过每个模型的原理解析、优化策略、应用实例的讲解,我们可以看到在面对高风险环境下的实时检测问题时,深度学习模型强大的适应性和改进空间。
5. 数据增强技术与轻量级模型
数据增强技术的重要性
在深度学习中,数据增强技术是提高模型泛化能力的关键手段。特别是在火焰与烟雾识别任务中,由于现实环境中数据采集的困难以及场景的多样性,使用原始数据训练模型往往难以达到令人满意的性能。数据增强通过对已有的训练数据进行一系列变换,如旋转、缩放、裁剪、颜色变换等,可以生成大量新的训练样本,从而增加数据的多样性和模型的泛化能力。
以下是一些常见的数据增强技术:
- 旋转 :图像旋转一定角度,可以模拟在不同视角下火焰与烟雾的形态。
- 缩放 :缩放图像大小,以模拟在不同距离观察到的火焰与烟雾。
- 裁剪 :随机裁剪图像的一部分,增加模型对局部特征的识别能力。
- 颜色变换 :通过调整亮度、对比度、饱和度等颜色参数,增强模型对颜色变化的鲁棒性。
from imgaug import augmenters as iaa
seq = iaa.Sequential([
iaa.SomeOf((0, 5), [
iaa.OneOf([
iaa.Affine(rotate=(-45, 45)), # 旋转增强
iaa.Affine(scale=(0.5, 1.5)), # 缩放增强
]),
iaa.SomeOf((0, 3), [
iaa.CropAndPad(percent=(-0.1, 0.1)), # 裁剪增强
iaa.ChangeColorspace(from_colorspace="RGB", to_colorspace="HSV"),
iaa.WithChannels(0, iaa.GaussianBlur(sigma=(0, 0.5))), # 颜色变换增强
])
])
])
设计轻量级模型
实时火焰与烟雾识别对计算资源要求较高,因此设计轻量级模型对于部署到边缘设备(如监控摄像头)上至关重要。轻量级模型通常具有较少的参数量和计算量,但仍然能够保持较高的识别精度。
一个常见的轻量级模型设计策略是使用深度可分离卷积(Depthwise Separable Convolution),与传统的卷积相比,它可以显著减少计算量和参数量。MobileNet系列模型就是应用了这一策略的典范。
graph TD
A[输入图像] --> B[深度可分离卷积层]
B --> C[逐点卷积层]
C --> D[全连接层]
D --> E[输出]
模型性能评估指标
模型的性能需要通过一系列的评估指标来量化。对于分类任务,准确率(Accuracy)是最直观的指标。然而,对于火焰与烟雾这种不平衡的数据集,准确率可能会产生误导。因此,我们还需要其他指标,如精确率(Precision)、召回率(Recall)、F1分数(F1 Score)和ROC曲线下的面积(AUC)。
精确率衡量的是模型预测为正的样本中真正为正的比例,而召回率衡量的是所有正样本中模型正确识别的比例。F1分数则是精确率和召回率的调和平均数,它在两者之间取得平衡。AUC是评价二分类模型性能的常用指标,它描述了模型将正样本排在负样本前面的能力。
通过这些评估指标,我们可以更全面地了解模型在火焰与烟雾识别任务中的表现,从而指导模型的进一步优化。
简介:数据集支持深度学习模型用于火焰和烟雾的实时目标检测,涵盖自动驾驶、安全监控和火灾预警等领域。火焰和烟雾作为目标,其图像数据的多样性和准确性对模型性能至关重要。深度学习模型如Faster R-CNN、YOLO和Mask R-CNN,结合数据增强技术,可用于提高模型泛化能力。适用于嵌入式设备的轻量级模型和性能评估指标确保模型的实时性和可靠性。此数据集为智能系统提供基础,旨在提高公共安全并减少财产损失。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 21
21 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)