python数据分析之pandas时间序列
在日常工作中,比较常见的事情就是对日期格式的数据进行处理,日期的表达方式有很多种,可以有很多种表达方式。接下来我将分两部分来介绍:
- 日期数据的处理
- 时间序列
1.日期数据的处理技巧
1.1日期数据形式的转换
这里主要使用to_datatime这个函数进行时间类型数据的转换
pd.to_datatime(arg,errors="ignore",dayfirst=False,yearfirst=False,utc=None,box=True,format=None,exact=Teue,infer_data_time=False,origin=False,origin="unix",cache=False)
"""
arg:字符串、时间类型的数据、字符串数组
errors:值为ignore(无效的解析将返回原值)、raise(无效的解析将引发异常)、coerce(无效的解析将被设置为NaT)
dayfirst:第一天,bool类型,默认值为False
utc:默认值为None,返回utc即为协调世界时间
box:bool类型,默认为True,返回DatatimeIndex;false时返回对象为ndarray
format:格式化显示时间的格式,字符串,默认值为None
"""
将一组各种形式的数据转化为一种类型的数据
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
#这里有各种形式的时间数据
df=pd.DataFrame({'原日期':['14-Feb-20', '02/14/2020', '2020.02.14', '2020/02/14','20200214']})
df['转换后的日期']=pd.to_datetime(df['原日期'])
print(df)
输出结果为: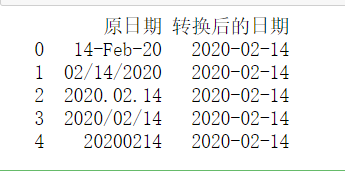
1.2 将字典中的年、月、日各列组合成一列日期。
- year,month,day是必须选择的项
- hour,minute,second,millsecond(毫秒),microsecond(微秒),nanosecond(纳秒)是可选项
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
#生成由yeae、month、day、hour、mintue、second组成的字典
df = pd.DataFrame({'year': [2018, 2019,2020],
'month': [1, 3,2],
'day': [4, 5,14],
'hour':[13,8,2],
'minute':[23,12,14],
'second':[2,4,0]})
df['组合后的日期']=pd.to_datetime(df)
print(df)
输出如下:
1.3 通过dt对象返回日期中的year、month、day等,需要注意的是需要是Series.dt()即需要是一个Series对象才有这个方法
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df=pd.DataFrame({'原日期':['2019.1.05', '2019.2.15', '2019.3.25','2019.6.25','2019.9.15','2019.12.31']})
#首先进行数据形式的转换
df['日期']=pd.to_datetime(df['原日期'])
print(df)
#获取数据变成df的新的列
df['年'],df['月'],df['日']=df['日期'].dt.year,df['日期'].dt.month,df['日期'].dt.day
df['星期几']=df['日期'].dt.day_name()#获取星期
df['季度']=df['日期'].dt.quarter#获取季度
df['是否年底']=df['日期'].dt.is_year_end#判断是否为年底
print(df)
看一下结果: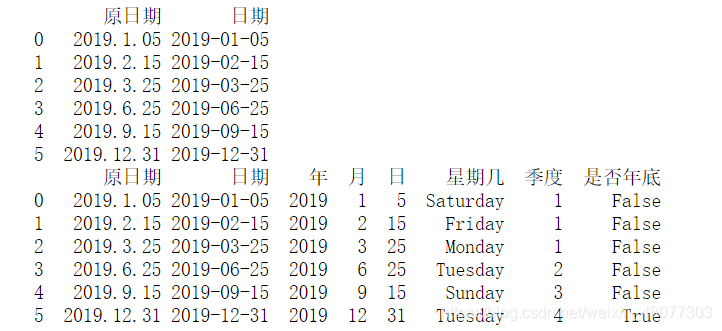
1.4 获取特定日期区间的数据
获取日期区间的数据的方法就是直接在DataFrame对象中输入日期或者日期区间,但是必须提前设置时间列为索引。
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel(r'C:\User\python-code\mingribooks.xls')
df1=df[['订单付款时间','买家会员名','联系手机','买家实际支付金额']]
df1=df1.sort_values(by=['订单付款时间'])
df1 = df1.set_index('订单付款时间') # 将日期设置为索引
#获取某个区间数据
print(df1['2018-05-11':'2018-06-10'])
#获取2018年的数据
print(df1["2018"])
#获取某个月的数据
print(df1["2018-09"])
#获取某一天的数据
print(df1["2018-09-02"])
展示结果就不展示了,大家可以自行去跑跑。
1.5 根据年、季度、月、星期、天统计数据
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel(r'C:\Users\Administrator\Desktop\python-code\Code\04\47\mingribooks.xls')
df1=df[['订单付款时间','买家会员名','联系手机','买家实际支付金额']]
df1=df1.sort_values(by=['订单付款时间'])
df0 = df1.set_index('订单付款时间') # 将日期设置为索引
#
df1=df0.resample("AS").sum()#AS代表按年统计数据
df1=df0.resample("Q").sum()#Q代表按照按照季度统计
df1=df0.resample("M").sum()#M代表按照月份统计
df1=df0.resample("W").sum()#W按照星期统计数据
print("按照年",df1)
print("**"*100)
print("按照季度",df2)
print("**"*100)
print("按照月",df3)
print("**"*100)
print("按照星期",df4)
结果如下:感觉上是比较乱的,因为输出的时间没有具体表示是哪一年,哪那个季度 ,哪个星期。
针对上述输出结果较乱的结果,我们采用to_period函数将时间戳转化为时期
df1=df0.resample("AS").sum().to_period("A")#AS代表按年统计数据
df2=df0.resample("Q").sum().to_period("Q")#Q代表按照按照季度统计
df3=df0.resample("M").sum().to_period("M")#M代表按照月份统计
df4=df0.resample("W").sum().to_period("W")#W按照星期统计数据
看看结果:与上面相比,这下结果就很显而易见了。我将改变的地方用红框框出出来了。
2.时间序列
首先介绍生成时间序列常用函数
pd.data_range(start,end,freq,periods)
"""
start:string或datetime-like,默认值是None,表示日期的起点。
end:string或datetime-like,默认值是None,表示日期的终点。
periods:integer或None,默认值是None,表示你要从这个函数产生多少个日期索引值;如果是None的话,那么start和end必须不能为None。
freq:string或DateOffset,默认值是’D’,表示以自然日为单位,这个参数用来指定计时单位,比如’5H’表示每隔5个小时计算一次。
"""
2.1生成特定时间内以天为单位时间序列
pd.date_range(start='20210101',end='20210601',)
结果如下:
2.2时间序列的重采样
重采样是指将原本一分钟采样的数据转化为每3分钟采样一次,即改变样本抽取的频率。
import pandas as pd
#首先生成9个时间序列,采样频率为每分钟
index = pd.date_range('02/02/2020', periods=9, freq='min')
#给这9个序列附上初值
series = pd.Series(range(9), index=index)
print(series)
#对数据进行重采样,每三分钟一次,每次采样等于3分钟的总和
print(series.resample('3min').sum())
结果如下: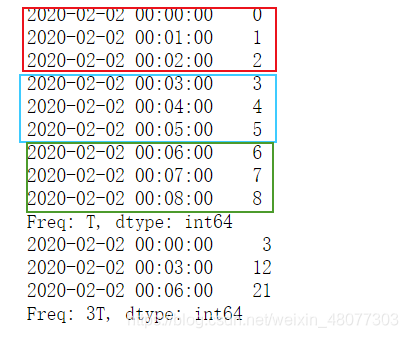
2.3时间序列的降采样处理
原销售数据是以天为单位,先采样为星期
import pandas as pd
#设置数据显示的列数和宽度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df=pd.read_excel('time.xls')
df1 = df.set_index('订单付款时间') #设置“订单付款时间”为索引
df_D=df1.resample('W').sum().to_period("W")
print(df_D)
结果如下: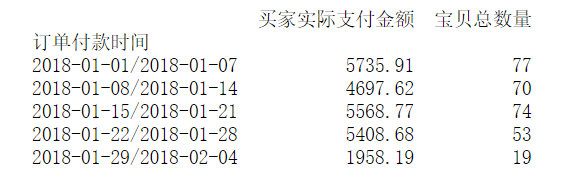
2.4时间序列的升采样处理
升采样就是采样频率从低频率转向高频率,有同学会问,升采样后数据从哪来?这里我们介绍几种方法。
- 不填充,使用NaN代替,使用asfreq方法。
- 使用前值填充,用前面的值填充空值,使用ffill方法或者pad方法。可使用“f”代表forword的意思。
- 用后值填充,使用bfill方法,可以使用字母“b”代表back的意思
import pandas as pd
import numpy as np
rng = pd.date_range('20200202', periods=2)
s1 = pd.Series(np.arange(1,3), index=rng)
print("原始数据",s1)
s1_6h_asfreq = s1.resample('6H').asfreq()#用空值填充
print(s1_6h_asfreq)
s1_6h_pad = s1.resample('6H').pad()#用前值填充
print(s1_6h_pad)
s1_6h_ffill = s1.resample('6H').ffill()#用前值填充
print(s1_6h_ffill)
s1_6h_bfill = s1.resample('6H').bfill()#用后值填充
print(s1_6h_bfill)
结果如下:
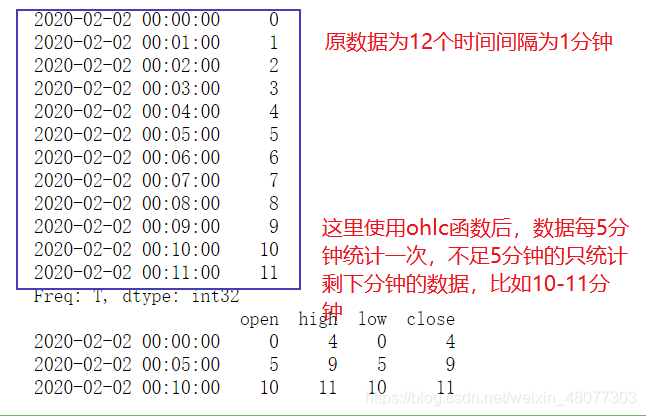
2.4时间序列数据的汇总(holc函数)
这里主要介绍ohlc函数,这个函数主要是是进行统计的,比如故股票在一段时间的开盘价,收盘价,最高价,最低价,而ohlc函数即可统计在一定时间间隔内的这些数据。
import pandas as pd
import numpy as np
#随机生成12个以1分钟为间隔的时间序列
rng = pd.date_range('2/2/2020',periods=12,freq='T')
s1 = pd.Series(np.arange(12),index=rng)
print(s1)#查看原数据
print(s1.resample('5min').ohlc())#查看开盘价,收盘价,最高价,最低价
移动窗口数据计算(rolling函数)
首先解释一下什么叫做窗口移动,这就很像一维卷积的过程,有些时候我们并不需要一个时间点的信息,而是需要某一段时间内的信息。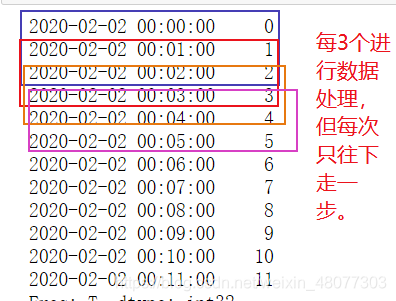
我们先生成一个时间序列数据,然后使用rolling来处理
import matplotlib.pylab as plt
import numpy as np
import pandas as pd
index=pd.date_range('20200201','20200215')
data=[3,6,7,4,2,1,3,8,9,10,12,15,13,22,14]
s1_data=pd.Series(data,index=index)
print(s1_data)
s1_data=pd.Series(data,index=index)
#取3个的平均值填充
print(s1_data.rolling(3).mean())
看一下结果:
空值计算肯定是空,所以前2个是空。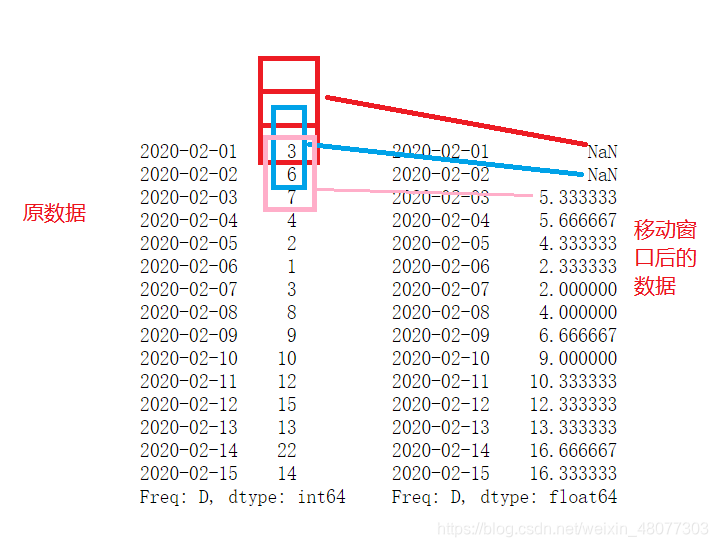 当然也能通过参数设置,当滑动大小不足时,只采用已有的数值进行计算,设置min_periods参数,指定最少几个数即可计算。
当然也能通过参数设置,当滑动大小不足时,只采用已有的数值进行计算,设置min_periods参数,指定最少几个数即可计算。
import matplotlib.pylab as plt
import numpy as np
import pandas as pd
index=pd.date_range('20200201','20200215')
data=[3,6,7,4,2,1,3,8,9,10,12,15,13,22,14]
s1_data=pd.Series(data,index=index)
print(s1_data.rolling(3,min_periods=1).mean())
结果如下:3即为第一个数的均值,4.5为前两个数的均值。后面的就正常了。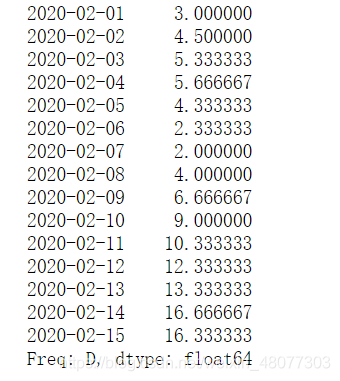
这样处理的目的就是使序列变得更加平稳。方便后续处理时间序列的算法得到更好的效果。
以上就是全部内容,有啥问题大家可以问我。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)