【完整源码+数据集+部署教程】 注射器和针头识别图像分割系统源码&数据集分享 [yolov8-seg-CSwinTransformer&yolov8-seg-C2f-DiverseBranchBlo
背景意义
随着医疗技术的不断进步,注射器和针头作为常见的医疗器械,其使用频率日益增加。准确识别和分割注射器与针头的图像,对于提高医疗设备的自动化管理、提升医疗服务的效率以及保障患者安全具有重要意义。近年来,计算机视觉技术的发展,尤其是深度学习算法的广泛应用,为图像识别和分割任务提供了新的解决方案。其中,YOLO(You Only Look Once)系列模型因其高效的实时检测能力而受到广泛关注。YOLOv8作为该系列的最新版本,具备更强的特征提取能力和更快的处理速度,为医疗图像的分析提供了良好的基础。
在实际应用中,注射器和针头的识别面临诸多挑战。首先,医疗环境中光照条件复杂,可能导致图像质量下降,影响识别效果。其次,注射器和针头的形状、颜色和材质多样,容易与背景混淆,增加了识别的难度。此外,注射器和针头的尺寸变化也可能影响模型的识别准确性。因此,基于YOLOv8的改进方法,能够有效应对这些挑战,提升图像分割的精度和鲁棒性。
本研究使用的数据集“syringe_31_08”包含1200张注射器和针头的图像,涵盖了两个主要类别:医疗针头和注射器。这一数据集的构建为模型的训练和验证提供了丰富的样本,确保了模型在不同场景下的适应性和准确性。通过对该数据集的深入分析和处理,能够为改进YOLOv8模型提供必要的基础数据支持,进而提升其在医疗图像分割任务中的表现。
本研究的意义不仅在于提升注射器和针头的识别精度,更在于推动医疗图像处理技术的发展。通过改进YOLOv8模型,研究者可以探索更为高效的图像分割算法,进而为医疗行业提供更为智能化的解决方案。此外,研究成果可为其他医疗器械的自动识别与管理提供借鉴,推动智能医疗设备的普及与应用。
综上所述,基于改进YOLOv8的注射器和针头识别图像分割系统的研究,不仅具有重要的理论价值,还具有广泛的实际应用前景。通过提升医疗图像处理的自动化水平,能够有效减少人工操作的错误,提高医疗服务的质量与效率,为患者提供更安全、便捷的医疗体验。随着智能医疗的不断发展,本研究将为相关领域的研究者提供新的思路和方法,推动医疗技术的进步与创新。
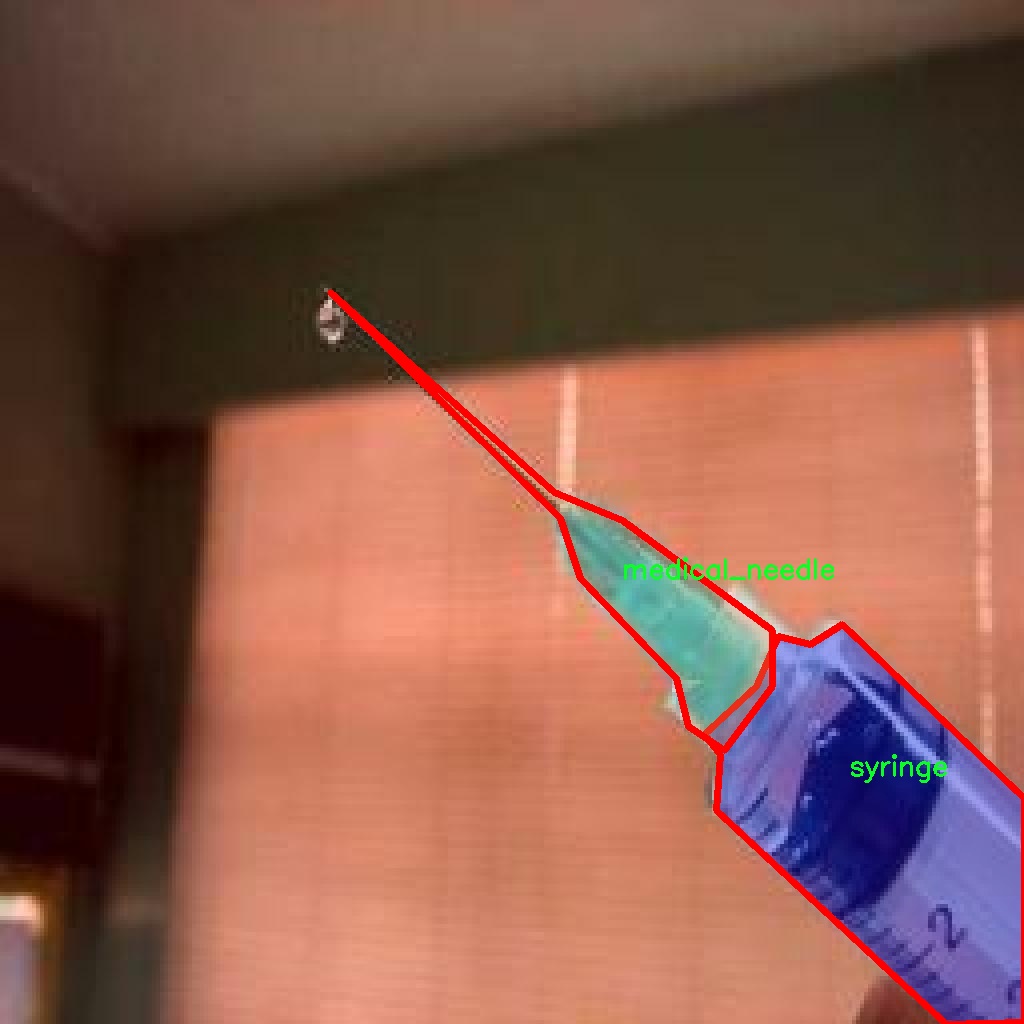
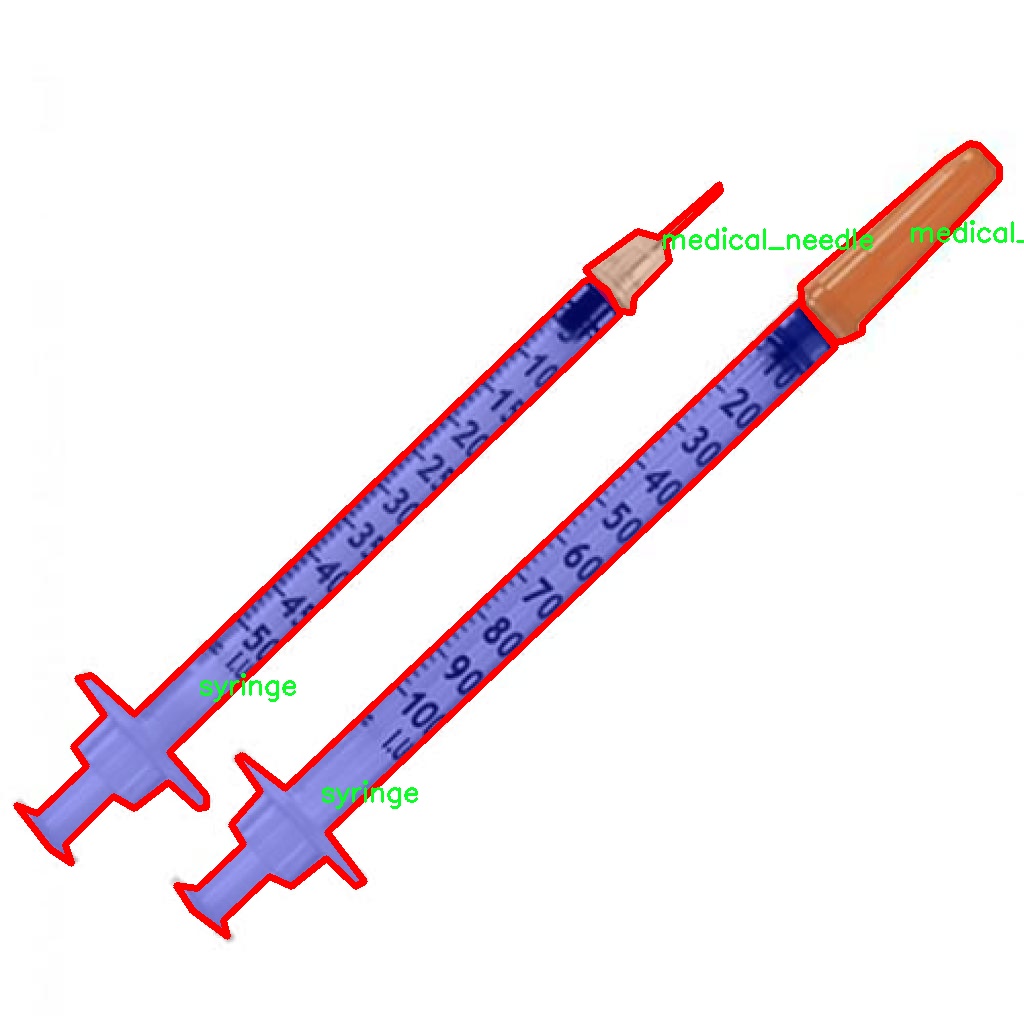
图片效果
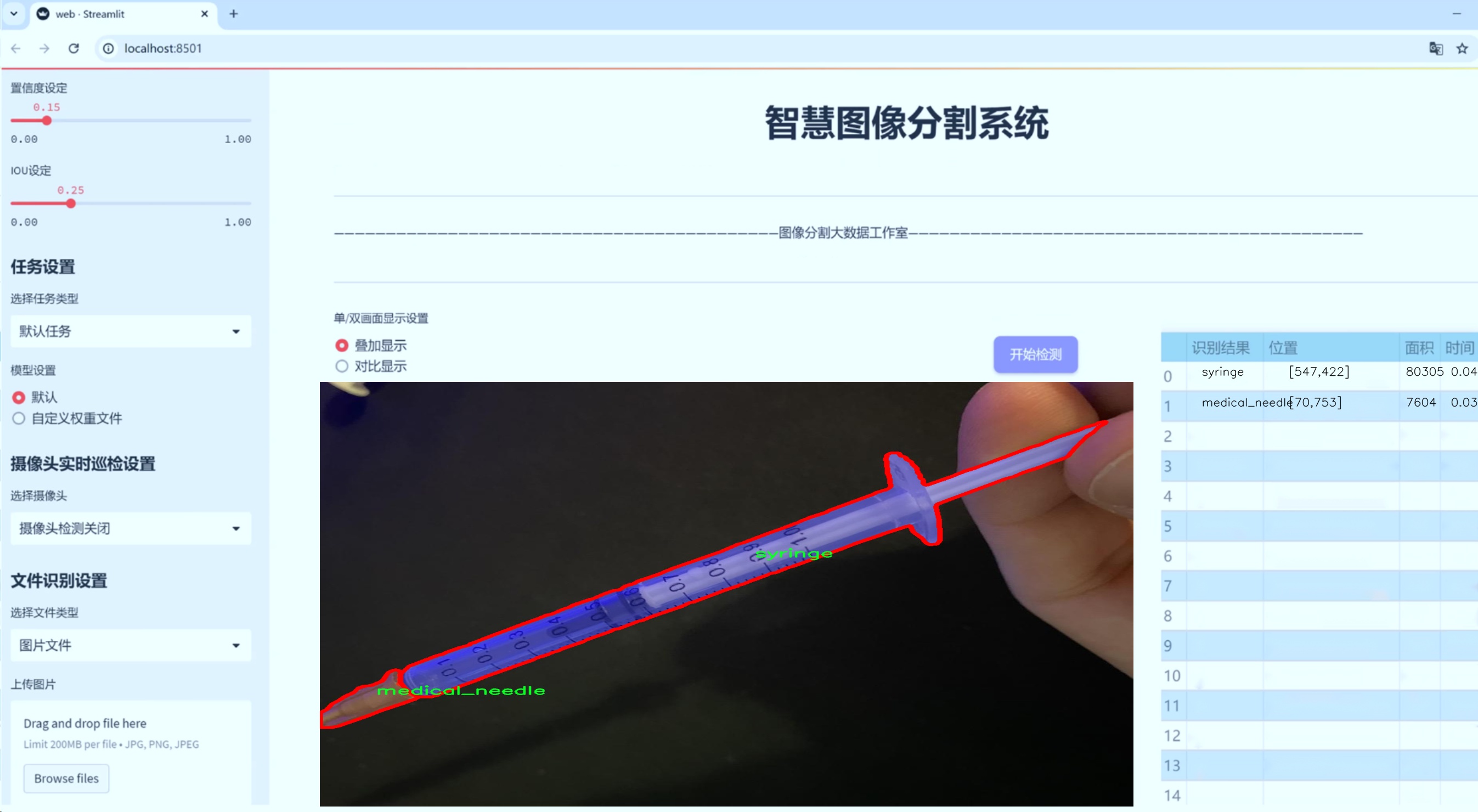
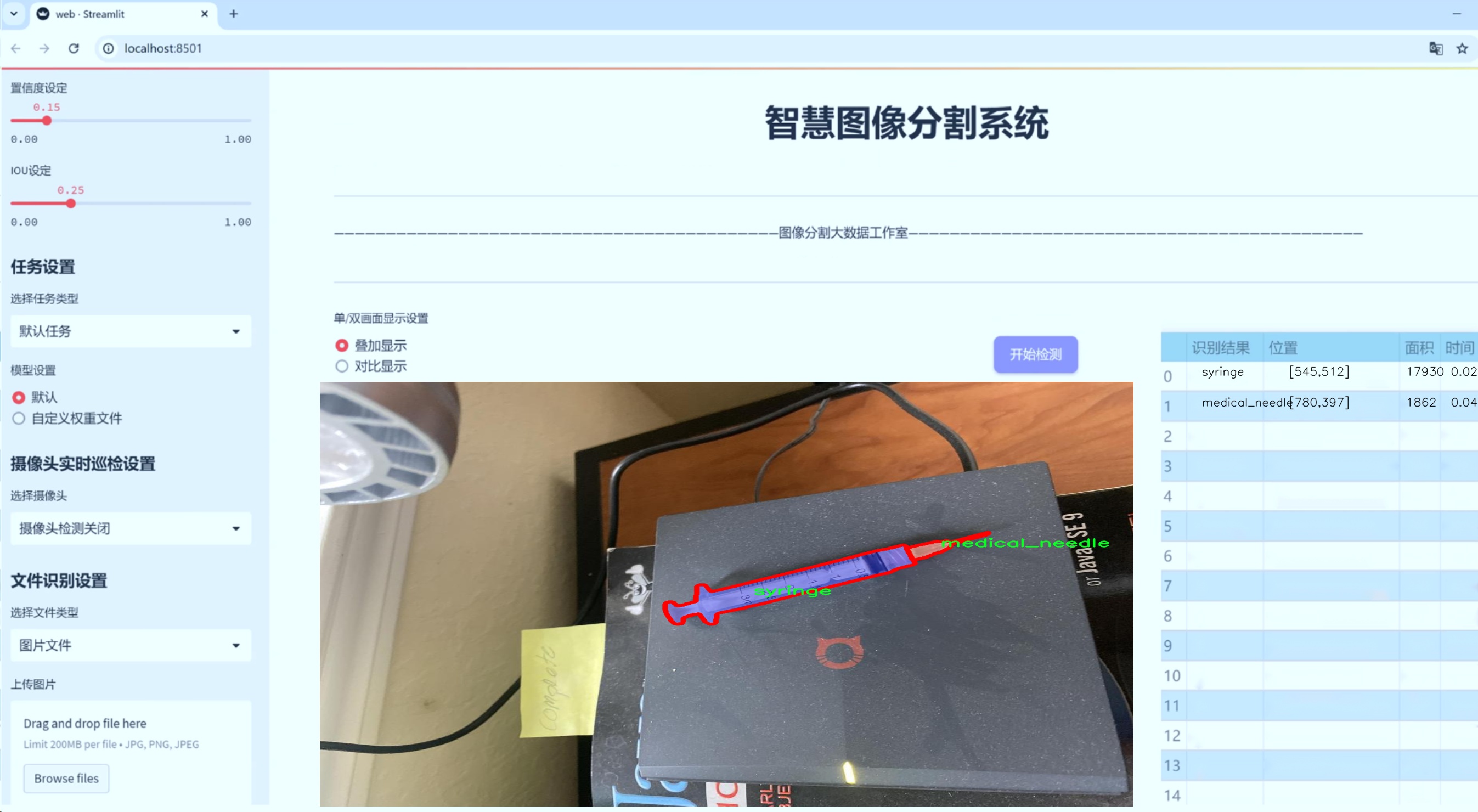
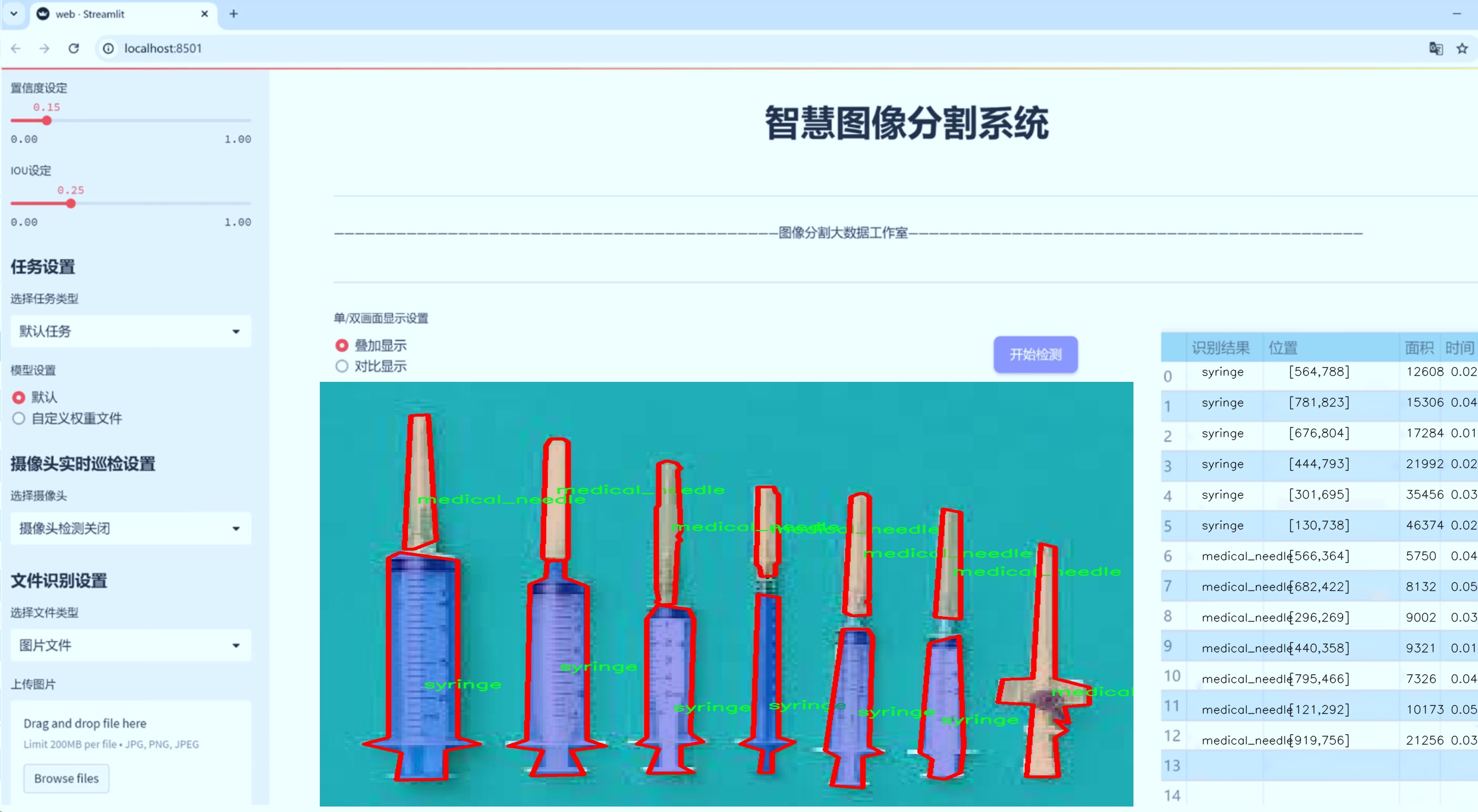
数据集信息
在本研究中,我们使用了名为“syringe_31_08”的数据集,以支持改进YOLOv8-seg的注射器和针头识别图像分割系统的训练与评估。该数据集专门设计用于医疗图像处理,涵盖了与注射器和针头相关的图像分割任务,具有重要的应用价值。数据集的类别数量为2,具体类别包括“medical_needle”(医疗针头)和“syringe”(注射器)。这两个类别的选择不仅反映了医疗器械在临床环境中的重要性,也为计算机视觉算法在医学领域的应用提供了丰富的训练样本。
“syringe_31_08”数据集包含多样化的图像样本,涵盖了不同类型和形状的注射器及针头,确保了模型在各种场景下的鲁棒性和准确性。数据集中的图像来源于真实的医疗环境,具有较高的真实性和代表性。这些图像经过精心标注,确保每个注射器和针头的边界都被准确地框定,便于后续的图像分割任务。通过对这些图像的分析和处理,模型能够学习到注射器和针头的特征,从而在实际应用中实现高效的识别和分割。
在数据集的构建过程中,研究团队采用了多种图像采集技术,确保数据的多样性和全面性。例如,数据集中包含了不同光照条件、背景环境和拍摄角度下的图像,以模拟真实世界中可能遇到的各种情况。这种多样性不仅提高了模型的泛化能力,也为模型在实际应用中的稳定性提供了保障。此外,数据集还包含了不同尺寸和颜色的注射器和针头,进一步丰富了训练样本的多样性。
在训练过程中,YOLOv8-seg模型将利用“syringe_31_08”数据集进行迭代学习。通过对图像进行特征提取和分类,模型能够逐步优化其参数,以提高对注射器和针头的识别精度。该模型采用了先进的深度学习算法,结合了卷积神经网络(CNN)和图像分割技术,旨在实现高效、准确的医疗器械识别。这一过程不仅需要大量的计算资源,还需要对数据集进行充分的预处理和增强,以提升模型的学习效果。
总之,“syringe_31_08”数据集为改进YOLOv8-seg的注射器和针头识别图像分割系统提供了坚实的基础。通过对该数据集的深入分析和利用,研究团队期望能够开发出一种高效的图像分割解决方案,进而推动医疗器械自动识别技术的发展。这不仅将为临床操作提供便利,也将为医疗安全和效率的提升做出贡献。未来,随着数据集的不断扩展和优化,模型的性能有望得到进一步提升,为医学影像分析领域带来新的突破。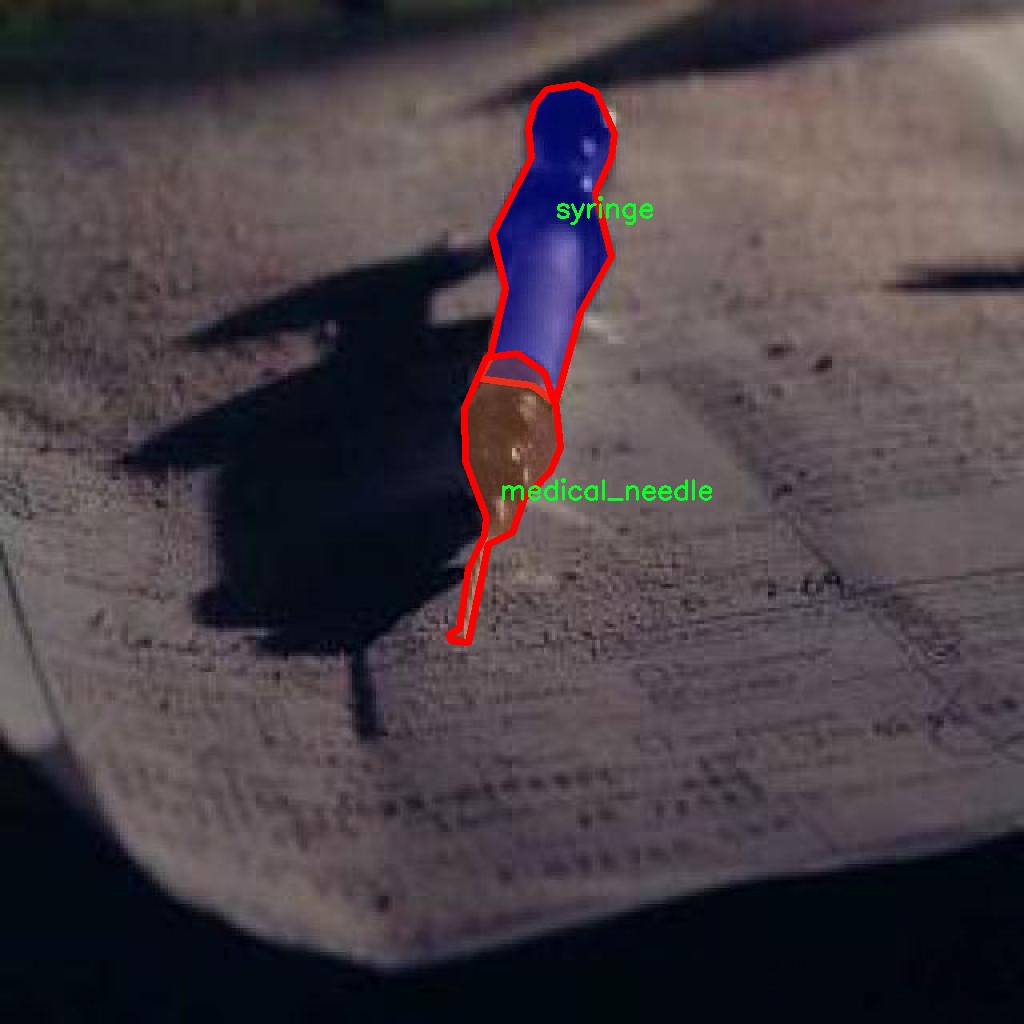


核心代码
```python
import json
from collections import defaultdict
from pathlib import Path
import numpy as np
from ultralytics.utils import LOGGER, TQDM
from ultralytics.utils.files import increment_path
def coco91_to_coco80_class():
"""
将91个COCO类ID转换为80个COCO类ID。
Returns:
list: 91个类ID的列表,其中索引表示80个类ID,值为对应的91个类ID。
"""
return [
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, None, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, None, 24, 25, None,
None, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, None, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
51, 52, 53, 54, 55, 56, 57, 58, 59, None, 60, None, None, 61, None, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72,
None, 73, 74, 75, 76, 77, 78, 79, None
]
def convert_coco(labels_dir='../coco/annotations/', save_dir='coco_converted/', cls91to80=True):
"""
将COCO数据集的注释转换为YOLO注释格式,以便训练YOLO模型。
Args:
labels_dir (str): COCO数据集注释文件的目录路径。
save_dir (str): 保存结果的目录路径。
cls91to80 (bool): 是否将91个COCO类ID映射到对应的80个COCO类ID。
"""
# 创建保存目录
save_dir = increment_path(save_dir) # 如果保存目录已存在,则递增
for p in save_dir / 'labels', save_dir / 'images':
p.mkdir(parents=True, exist_ok=True) # 创建目录
# 转换类
coco80 = coco91_to_coco80_class()
# 导入json文件
for json_file in sorted(Path(labels_dir).resolve().glob('*.json')):
fn = Path(save_dir) / 'labels' / json_file.stem.replace('instances_', '') # 文件夹名称
fn.mkdir(parents=True, exist_ok=True)
with open(json_file) as f:
data = json.load(f)
# 创建图像字典
images = {f'{x["id"]:d}': x for x in data['images']}
# 创建图像-注释字典
imgToAnns = defaultdict(list)
for ann in data['annotations']:
imgToAnns[ann['image_id']].append(ann)
# 写入标签文件
for img_id, anns in TQDM(imgToAnns.items(), desc=f'Annotations {json_file}'):
img = images[f'{img_id:d}']
h, w, f = img['height'], img['width'], img['file_name']
bboxes = [] # 存储边界框
for ann in anns:
if ann['iscrowd']:
continue # 跳过人群注释
# COCO框格式为[左上角x, 左上角y, 宽度, 高度]
box = np.array(ann['bbox'], dtype=np.float64)
box[:2] += box[2:] / 2 # 将左上角坐标转换为中心坐标
box[[0, 2]] /= w # 归一化x坐标
box[[1, 3]] /= h # 归一化y坐标
if box[2] <= 0 or box[3] <= 0: # 如果宽度或高度小于等于0
continue
cls = coco80[ann['category_id'] - 1] if cls91to80 else ann['category_id'] - 1 # 类别
box = [cls] + box.tolist() # 将类别和边界框合并
if box not in bboxes:
bboxes.append(box)
# 写入文件
with open((fn / f).with_suffix('.txt'), 'a') as file:
for bbox in bboxes:
file.write(('%g ' * len(bbox)).rstrip() % bbox + '\n')
LOGGER.info(f'COCO数据成功转换。\n结果保存到 {save_dir.resolve()}')
代码分析与注释
-
导入必要的库:使用
json处理JSON文件,defaultdict用于创建默认字典,Path用于处理文件路径,numpy用于数值计算。 -
类ID转换函数:
coco91_to_coco80_class函数将91个COCO类ID映射到80个COCO类ID,返回一个列表。 -
转换函数:
convert_coco函数是核心功能,负责将COCO格式的注释转换为YOLO格式。它接受多个参数,包括注释文件目录、保存目录和是否进行类ID转换。 -
创建目录:使用
increment_path确保保存目录的唯一性,并创建所需的子目录。 -
读取和处理JSON文件:遍历指定目录下的所有JSON文件,读取图像和注释信息,并将其存储在字典中。
-
边界框处理:对于每个注释,计算边界框的中心坐标并进行归一化处理,生成YOLO格式的边界框。
-
写入文件:将处理后的边界框信息写入文本文件,格式为
类别 x_center y_center width height。 -
日志记录:转换完成后,记录成功信息。
通过这些核心部分的注释,能够更清晰地理解代码的功能和逻辑。```
这个文件是一个用于将COCO数据集的标注转换为YOLO格式的Python脚本,主要用于计算机视觉领域的目标检测任务。它包含了一些函数,主要分为两个部分:将COCO数据集的标注转换为YOLO格式,以及将DOTA数据集的标注转换为YOLO的有向边界框(OBB)格式。
首先,文件中定义了两个函数 coco91_to_coco80_class 和 coco80_to_coco91_class,这两个函数用于在COCO数据集中不同的类别索引之间进行转换。COCO数据集原本有91个类别,但在YOLO模型中只使用80个类别,因此需要将91个类别的索引映射到80个类别的索引上。
接着,convert_coco 函数是文件的核心功能之一,它接受多个参数,包括标注文件的目录、保存结果的目录、是否使用分割掩码和关键点等。该函数的主要步骤包括创建保存目录、读取COCO格式的JSON标注文件、解析图像和标注信息,并将其转换为YOLO格式。具体来说,它会遍历每个图像的标注,提取边界框、分割和关键点信息,并将这些信息以YOLO格式写入文本文件中。
在处理每个标注时,函数会将COCO的边界框格式(左上角坐标和宽高)转换为YOLO的格式(中心坐标和宽高),并进行归一化处理。此外,如果需要,它还会处理分割和关键点信息,并将这些信息写入相应的文件中。
此外,convert_dota_to_yolo_obb 函数用于将DOTA数据集的标注转换为YOLO OBB格式。该函数读取DOTA数据集中的图像和原始标注,处理每个图像的标注信息,并将其转换为YOLO OBB格式。它使用了一个内部函数 convert_label 来处理单个图像的标注,确保标注信息被正确格式化并保存。
文件中还定义了两个辅助函数:min_index 用于计算两个二维点数组之间的最短距离索引,merge_multi_segment 用于合并多个分割区域的坐标,以便将它们连接成一个完整的分割区域。
最后,文件中使用了 LOGGER 来记录转换过程中的信息,并在转换完成后输出成功信息,指明结果保存的位置。
总体来说,这个文件实现了将COCO和DOTA数据集的标注转换为YOLO格式的功能,方便用户在YOLO模型中使用这些数据进行训练和评估。
```python
import torch
from ultralytics.data import ClassificationDataset, build_dataloader
from ultralytics.engine.validator import BaseValidator
from ultralytics.utils.metrics import ClassifyMetrics, ConfusionMatrix
from ultralytics.utils.plotting import plot_images
class ClassificationValidator(BaseValidator):
"""
扩展自 BaseValidator 类的分类模型验证器类。
"""
def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):
"""初始化 ClassificationValidator 实例,设置数据加载器、保存目录、进度条和参数。"""
super().__init__(dataloader, save_dir, pbar, args, _callbacks)
self.targets = None # 真实标签
self.pred = None # 预测结果
self.args.task = 'classify' # 设置任务类型为分类
self.metrics = ClassifyMetrics() # 初始化分类指标
def init_metrics(self, model):
"""初始化混淆矩阵、类名和 top-1、top-5 准确率。"""
self.names = model.names # 获取模型的类名
self.nc = len(model.names) # 类别数量
self.confusion_matrix = ConfusionMatrix(nc=self.nc, conf=self.args.conf, task='classify') # 初始化混淆矩阵
self.pred = [] # 预测结果列表
self.targets = [] # 真实标签列表
def preprocess(self, batch):
"""预处理输入批次并返回处理后的数据。"""
batch['img'] = batch['img'].to(self.device, non_blocking=True) # 将图像数据移动到设备上
batch['img'] = batch['img'].half() if self.args.half else batch['img'].float() # 根据参数选择数据类型
batch['cls'] = batch['cls'].to(self.device) # 将标签数据移动到设备上
return batch
def update_metrics(self, preds, batch):
"""使用模型预测和批次目标更新运行指标。"""
n5 = min(len(self.names), 5) # 获取前5个预测类别
self.pred.append(preds.argsort(1, descending=True)[:, :n5]) # 将预测结果按降序排序并保留前5个
self.targets.append(batch['cls']) # 添加真实标签
def finalize_metrics(self, *args, **kwargs):
"""最终化模型的指标,如混淆矩阵和速度。"""
self.confusion_matrix.process_cls_preds(self.pred, self.targets) # 处理预测和真实标签以更新混淆矩阵
self.metrics.speed = self.speed # 记录速度
self.metrics.confusion_matrix = self.confusion_matrix # 保存混淆矩阵
self.metrics.save_dir = self.save_dir # 保存目录
def get_stats(self):
"""返回通过处理目标和预测获得的指标字典。"""
self.metrics.process(self.targets, self.pred) # 处理真实标签和预测结果
return self.metrics.results_dict # 返回结果字典
def build_dataset(self, img_path):
"""创建并返回一个 ClassificationDataset 实例,使用给定的图像路径和预处理参数。"""
return ClassificationDataset(root=img_path, args=self.args, augment=False, prefix=self.args.split)
def get_dataloader(self, dataset_path, batch_size):
"""构建并返回用于分类任务的数据加载器。"""
dataset = self.build_dataset(dataset_path) # 构建数据集
return build_dataloader(dataset, batch_size, self.args.workers, rank=-1) # 返回数据加载器
def print_results(self):
"""打印 YOLO 目标检测模型的评估指标。"""
pf = '%22s' + '%11.3g' * len(self.metrics.keys) # 打印格式
LOGGER.info(pf % ('all', self.metrics.top1, self.metrics.top5)) # 打印 top-1 和 top-5 准确率
def plot_val_samples(self, batch, ni):
"""绘制验证图像样本。"""
plot_images(
images=batch['img'],
batch_idx=torch.arange(len(batch['img'])),
cls=batch['cls'].view(-1), # 使用 .view() 而不是 .squeeze() 以适应分类模型
fname=self.save_dir / f'val_batch{ni}_labels.jpg',
names=self.names,
on_plot=self.on_plot)
def plot_predictions(self, batch, preds, ni):
"""在输入图像上绘制预测结果并保存结果。"""
plot_images(batch['img'],
batch_idx=torch.arange(len(batch['img'])),
cls=torch.argmax(preds, dim=1), # 获取预测的类别
fname=self.save_dir / f'val_batch{ni}_pred.jpg',
names=self.names,
on_plot=self.on_plot) # 绘制预测结果
代码核心部分说明:
- 初始化:
__init__方法用于初始化验证器的基本参数,包括数据加载器、保存目录和指标等。 - 指标初始化:
init_metrics方法用于初始化混淆矩阵和类名,准备进行模型评估。 - 数据预处理:
preprocess方法将输入批次的数据转移到指定设备,并根据需要转换数据类型。 - 更新指标:
update_metrics方法根据模型的预测结果和真实标签更新分类指标。 - 最终化指标:
finalize_metrics方法处理预测结果以更新混淆矩阵,并保存相关指标。 - 获取统计信息:
get_stats方法返回处理后的指标结果。 - 数据集和数据加载器构建:
build_dataset和get_dataloader方法用于创建数据集和数据加载器,方便后续的模型验证。 - 结果打印和绘图:
print_results方法打印评估指标,plot_val_samples和plot_predictions方法用于可视化验证样本和预测结果。```
这个程序文件是Ultralytics YOLO框架中的一个分类验证器,主要用于对分类模型的验证和评估。文件中定义了一个名为ClassificationValidator的类,该类继承自BaseValidator,并提供了一系列方法来处理分类任务的验证过程。
在类的初始化方法中,接收了一些参数,包括数据加载器、保存目录、进度条和其他参数。初始化时还设置了任务类型为“分类”,并创建了一个用于存储分类指标的对象。
get_desc方法返回一个格式化的字符串,用于总结分类指标,包括类别名称、Top-1准确率和Top-5准确率。init_metrics方法用于初始化混淆矩阵、类别名称和准确率的相关信息。
在preprocess方法中,对输入的批次数据进行预处理,将图像和类别标签移动到指定的设备上,并根据需要转换数据类型。update_metrics方法则用于更新模型预测和真实标签的运行指标。
finalize_metrics方法在所有数据处理完成后,最终化模型的指标,包括处理混淆矩阵和计算速度。如果设置了绘图选项,还会生成混淆矩阵的可视化图。
get_stats方法返回一个字典,包含通过处理真实标签和预测结果得到的各项指标。build_dataset方法用于创建分类数据集实例,而get_dataloader方法则构建并返回一个数据加载器,以便在分类任务中使用。
print_results方法打印出YOLO模型的评估指标,plot_val_samples方法用于绘制验证图像样本并保存结果,plot_predictions方法则在输入图像上绘制预测结果并保存。
总体来说,这个文件提供了一个完整的框架,用于验证和评估分类模型的性能,支持混淆矩阵的生成、指标的计算和结果的可视化,便于用户分析模型的分类效果。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 28
28 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)