即插即用系列 | SST:Mamba+Transformer混合专家——时序预测新范式,完美融合线性效率与局部精度
论文题目:SST: Multi-Scale Hybrid Mamba-Transformer Experts for Time Series Forecasting
论文原文 (Paper):https://arxiv.org/abs/2404.14757
官方代码 (Code):https://github.com/XiongxiaoXu/SST
想要直接使用该模块? 本论文的完整复现代码(即插即用版)已更新至专栏
即插即用系列(代码实践) | SST:Mamba+Transformer混合专家——时序预测新范式,完美融合线性效率与局部精度
1. 核心思想
本文提出了一种名为SST(State Space Transformer)的多尺度混合专家模型,旨在解决时间序列预测中Transformer的二次复杂度与Mamba的信息损失问题。其核心论点是,Mamba和Transformer具有互补优势:Mamba擅长捕捉低分辨率下的长程模式(Patterns),而Transformer(注意力)更擅长处理高分辨率下的短程变异(Variations)。SST不采用简单的层堆叠(这会导致“信息干扰”),而是创新性地设计了一个双分支“专家”架构,利用多尺度补丁(Multi-Scale Patching)将序列分解,使Mamba专家处理长程模式,Transformer专家处理短程变异。最后,通过一个路由模块(Router)动态融合两个专家的输出,从而在实现SOTA性能的同时保持了线性复杂度。
2. 背景与动机
- 论文的背景是,基于Transformer的模型在时间序列预测上取得了显著进展,其注意力机制能有效捕捉时间依赖性。但其 O ( L 2 ) O(L^2) O(L2) 的计算复杂度限制了其在长序列上的应用。作为替代方案,Mamba等状态空间模型(SSM)实现了 O ( L ) O(L) O(L) 的线性复杂度。然而,Mamba通过将历史信息压缩到固定大小的隐藏状态中,这可能导致信息丢失,限制了其表征能力。
鉴于二者的优缺点互补,一个自然的研究问题是:能否设计一个混合Mamba和Transformer的架构,兼顾效率与效果?
论文指出,一个关键的挑战是,像Mambaformer那样直接、“天真”地堆叠Mamba和Transformer层是无效的,甚至不如简单的线性模型(DLinear)。作者将此归咎于“信息干扰”(information interference)问题:Mamba的有损压缩表示(lossy representation)削弱了后续注意力机制捕捉精细细节的能力。为此,本文的核心动机就是设计一种更“有原则”的混合架构,以规避信息干扰,并充分利用两种模型的独特优势。
-
动机图解分析:
论文通过Figure 1和Figure 2的对比,清晰地阐述了问题的根源和解决方案的灵感。-
Figure 1 (Mamba vs. Attention 的机制对比)
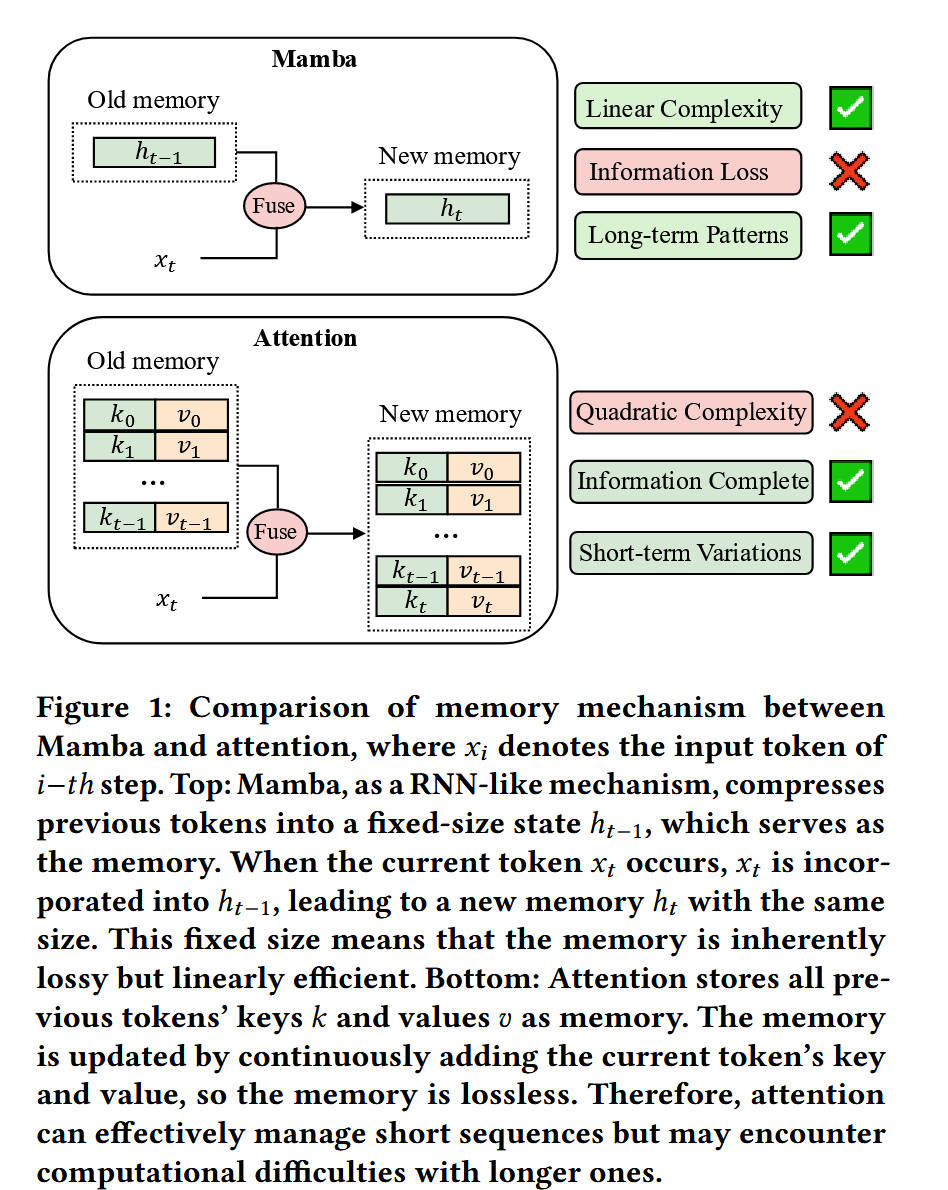
- Mamba (顶部):采用类似RNN的机制,将旧内存 h t − 1 h_{t-1} ht−1 与当前输入 x t x_t xt 融合,生成一个固定大小的新内存 h t h_t ht。
- 优点:“线性复杂度”(Linear Complexity)和擅长“长程模式”(Long-term Patterns)。
- 缺点:“信息损失”(Information Loss),因为内存大小是固定的。
- Attention (底部):将所有历史的键(k)和值(v)对作为内存。当新输入 x t x_t xt 进来时,其 (k, v) 对被简单地添加到内存中。
- 优点:“信息完整”(Information Complete)和擅长“短程变异”(Short-term Variations)。
- 缺点:“二次复杂度”(Quadratic Complexity),因为内存随序列长度L线性增长,而计算需要L x L的交互。
- 图解结论:Figure 1 视觉化了Mamba和Transformer在效率与信息保留上的根本性权衡。这直接引出了本文的混合需求:我们能否既要Mamba的“线性复杂度”和“长程优势”,又要Attention的“信息完整”和“短程优势”?
- Mamba (顶部):采用类似RNN的机制,将旧内存 h t − 1 h_{t-1} ht−1 与当前输入 x t x_t xt 融合,生成一个固定大小的新内存 h t h_t ht。
-
Figure 2 (粗粒度 vs. 细粒度的数据特性)
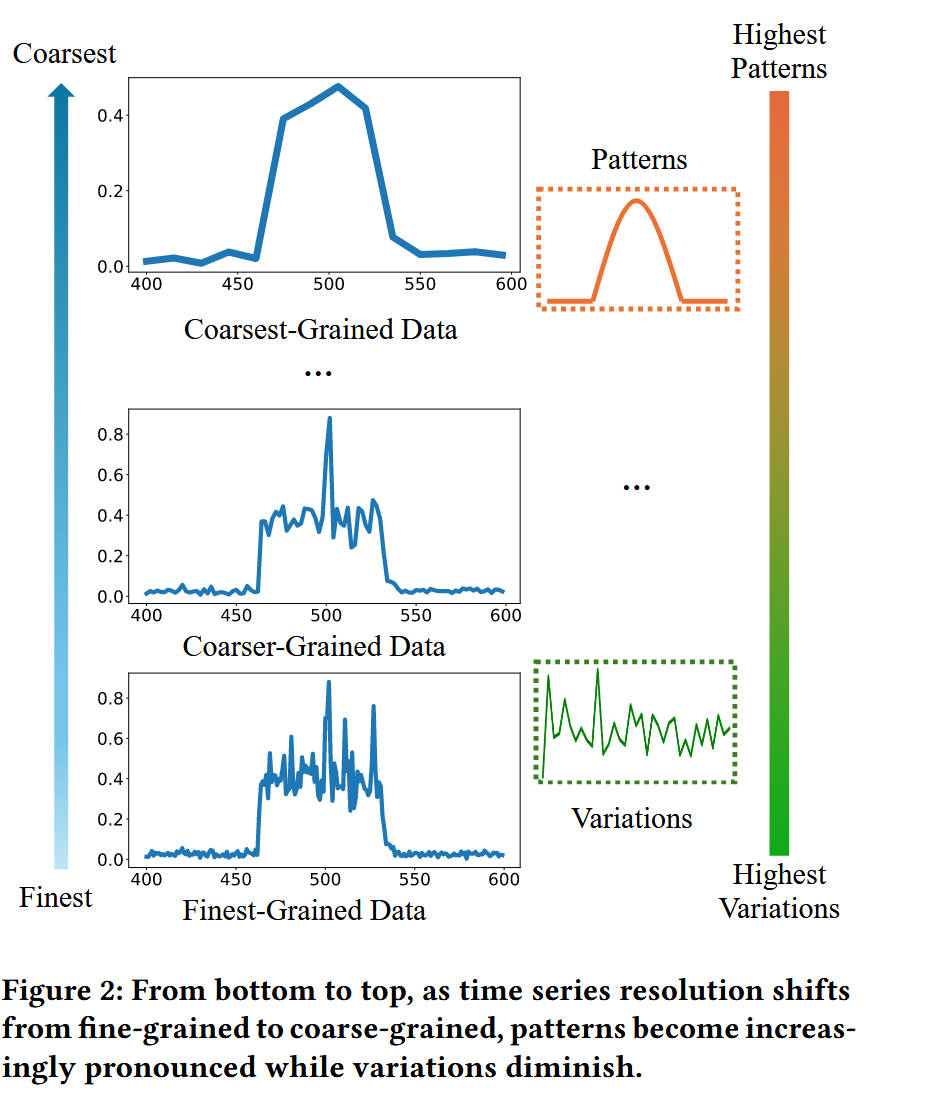
- 图示内容:描绘了时间序列在不同“分辨率”或“粒度”下的形态。
- 从下到上:图像从“最精细粒度”(Finest-Grained)向“最粗糙粒度”(Coarsest-Grained)过渡。
- 观察 1 (底部):在“最精细粒度”数据中,信号充满了高频噪声和剧烈波动,这些被定义为“变异”(Variations)。
- 观察 2 (顶部):在“最粗糙粒度”数据中,高频噪声被平滑掉了,只留下了整体的、平缓的趋势,这被定义为“模式”(Patterns)。
- 图解结论:Figure 2 提供了解决Figure 1问题的“钥匙”。它表明“模式”和“变异”在不同的数据尺度上是自然分离的。这启发了作者的解决方案:我们不需要在同一份数据上同时应用Mamba和Transformer,而是可以将数据分解为“粗粒度”和“细粒度”两种视图,然后将它们分别交给最擅长处理它们的模型。
综合动机:现有的Mamba(高效但有损)和Attention(完整但昂贵)存在根本矛盾(Figure 1)。而时间序列数据本身具有多尺度特性,其“长程模式”在粗粒度下更清晰,“短程变异”在细粒度下更明显(Figure 2)。因此,本文的动机就是利用数据的多尺度特性,设计一个混合专家架构,将Figure 1中的两个互补模型(Mamba, Transformer)分配到Figure 2中的两个不同尺度(Coarse, Fine)上,从而解决“信息干扰”问题。
-
3. 主要贡献点
-
[贡献点 1]:揭示了混合Mamba-Transformer架构在时序预测中的“信息干扰”问题。
论文首先将用于语言建模的Mambaformer架构(即天真地堆叠Mamba和Attention层)适配到时间序列领域。通过实验(Table 1)证明,这种“香草”堆叠方式性能不佳,甚至差于简单的DLinear模型。作者分析这归因于“信息干扰”(information interference):Mamba的有损压缩状态破坏了Attention机制所需的精细信息,导致性能下降。 -
[贡献点 2]:提出了一种新的“模式-变异”时间序列分解策略。
为解决信息干扰问题,论文提出了一种新的分解范式,将时间序列分解为“长程模式”(long-range patterns)和“短程变异”(short-range variations)。这与传统的STL分解(趋势、季节、残差)不同。该策略的核心是将Mamba和Transformer解耦,使其在各自擅长的领域独立工作:Mamba(有损压缩)非常适合提取长程的宏观模式并过滤噪声;而Transformer(信息完整)则适合捕捉短程的高频变异。 -
[贡献点 3]:设计了SST,一个多尺度混合Mamba-Transformer专家模型。
基于上述分解策略,论文提出了SST(State Space Transformer)架构。SST的核心是混合专家(MoE)思想,但与传统MoE中专家角色模糊不同,SST为两个专家分配了清晰的职责:一个Mamba专家用于处理长程模式,一个Transformer专家(LWT)用于处理短程变异。 -
[贡献点 4]:引入了多尺度补丁(Multi-Scale Patching)机制与分辨率量化指标 R P T S R_{PTS} RPTS。
为了配合专家模型,SST使用“多尺度补丁”机制来生成不同分辨率的数据视图。它为Mamba专家提供“低分辨率”(大P,大Str)的序列以凸显模式,为Transformer专家提供“高分辨率”(小P,小Str)的序列以保留变异细节。此外,论文首次提出了一个量化指标 R P T S = P S t r R_{PTS} = \frac{\sqrt{P}}{Str} RPTS=StrP,用于精确定义补丁化时间序列(PTS)的“分辨率”。 -
[贡献点 5]:设计了长短路由(Long-Short Router)以动态融合专家输出。
SST包含一个“长短路由”模块,该模块学习两个专家(Mamba和Transformer)的贡献权重( p L p_L pL 和 p S p_S pS),以自适应地融合长程模式信息和短程变异信息,从而提高最终的预测性能。 -
[贡献点 6]:实现了SOTA性能和线性复杂度。
SST在多个真实世界数据集上取得了SOTA的预测性能。同时,由于Mamba专家和LWT(局部窗口Transformer)专家均具有线性复杂度,SST的整体计算复杂度保持在 O ( L ) O(L) O(L),在内存和速度上(Figure 8)远优于传统Transformer和PatchTST。
4. 方法细节
-
整体网络架构:
SST的整体网络架构(如图Figure 5所示)是一个双分支的混合专家(MoE)系统。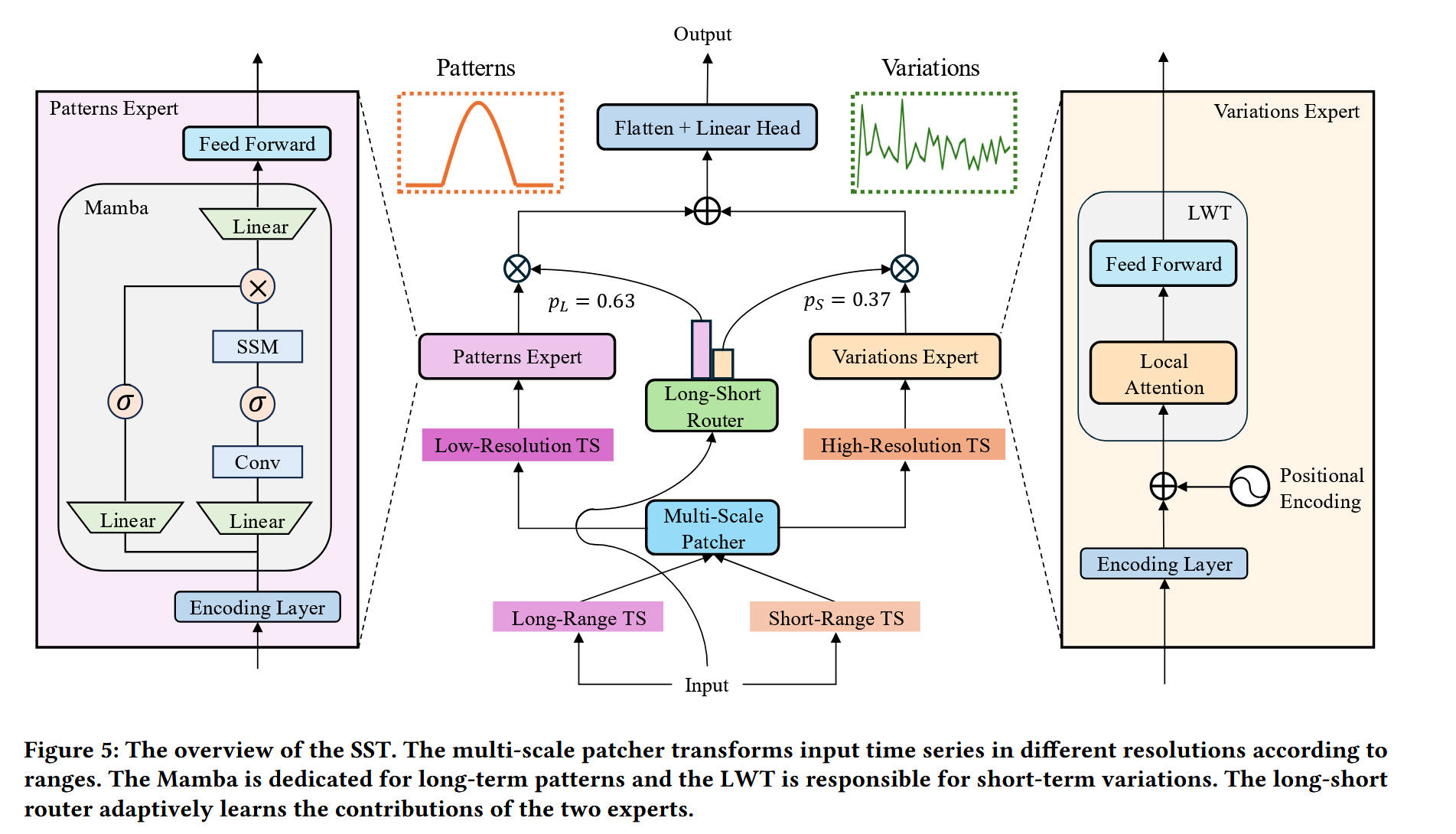
数据流如下:
- 输入 (Input):原始的时间序列数据L被分流为两路:“长程时间序列 (Long-Range TS)”(即完整的L)和“短程时间序列 (Short-Range TS)”(即最新的S,S < L)。
- 多尺度补丁 (Multi-Scale Patcher):这两路数据分别进入“多尺度补丁”模块。
- “长程TS”被处理为“低分辨率TS (Low-Resolution TS)”,使用较大的补丁P和步长Str。
- “短程TS”被处理为“高分辨率TS (High-Resolution TS)”,使用较小的P和Str。
- 双分支专家 (Hybrid Experts):
- 模式专家 (Patterns Expert):低分辨率TS被送入“模式专家”。该专家本质上是一个Mamba模块。它首先通过编码层,然后进入Mamba核心块(包含SSM、卷积、门控等),最后通过Feed Forward层,输出长程模式表征 z L z_L zL。
- 变异专家 (Variations Expert):高分辨率TS被送入“变异专家”。该专家是一个“局部窗口Transformer (LWT)”。数据首先经过编码层并加入“位置编码 (Positional Encoding)”,然后进入LWT核心(包含“局部注意力 (Local Attention)” 和 Feed Forward层),输出短程变异表征 z S z_S zS。
- 路由与融合 (Routing & Fusion):
- 与此同时,原始的“长程TS”和“短程TS”也被送入一个“长短路由 (Long-Short Router)”模块。
- 该路由器学习两个权重: p L p_L pL(例如0.63)和 p S p_S pS(例如0.37),分别代表模式专家和变异专家的重要性。
- 两个专家的输出 z L z_L zL 和 z S z_S zS 根据 p L p_L pL 和 p S p_S pS 进行加权求和( ⊗ \otimes ⊗ 和 ⊕ \oplus ⊕ 符号所示)。
- 输出 (Output):融合后的特征被送入一个“Flatten + Linear Head”,展平后通过一个线性层,最终生成预测结果。
-
核心创新模块详解(Figure 5 & Figure 6):
-
对于 模式专家 (Patterns Expert - Mamba 核心) (Figure 5 左侧):
- 内部结构:该模块是基于Mamba块构建的。数据流入后,首先通过一个“编码层 (Encoding Layer)”。然后,Mamba块将输入投影(Linear)并分裂为两个平行的分支。
- 分支1 (SSM路径):数据依次通过一个“卷积 (Conv)”层、一个“SiLU”激活函数( σ \sigma σ)、一个核心的“SSM”(状态空间模型)模块,然后再通过一个线性层(Linear)。SSM模块是Mamba的核心,它以循环的方式(recurrently)更新其隐藏状态,但可以被训练为高效的全局卷积。
- 分支2 (门控路径):数据通过一个“线性 (Linear)”层和一个“SiLU”激活函数( σ \sigma σ)。
- 数据流动与融合:来自“SSM路径”的输出和来自“门控路径”的输出通过一个逐元素相乘( ⊗ \otimes ⊗)的“门控”机制进行融合。
- 输出:融合后的结果最后通过一个“Feed Forward”层输出。
- 设计目的:Mamba的SSM设计使其能够有选择性地(selectively)将信息压缩到其状态中,同时过滤掉不相关的噪声。这使得它非常适合从“低分辨率”序列中提取主要的“长程模式”。
-
对于 变异专家 (Variations Expert - LWT 核心) (Figure 5 右侧 & Figure 6):
- 内部结构:该模块是基于Transformer的,但为了效率和局部性进行了修改,称为LWT(Local Window Transformer)。
- 数据流动:数据首先通过“编码层 (Encoding Layer)”,并与“位置编码 (Positional Encoding)” 相加( ⊕ \oplus ⊕)。这是必要的,因为与Mamba不同,Transformer本身不具备位置感知能力。
- 核心模块 (LWT):编码后的数据进入LWT块,其核心是“局部注意力 (Local Attention)” 和“Feed Forward”层。
- 局部注意力 (Figure 6):Figure 6详细图解了“局部注意力”的工作机制。标准的Transformer注意力( O ( L 2 ) O(L^2) O(L2))允许每个token关注序列中的所有其他token。而LWT的“局部注意力”强制每个token(例如Input层)只关注其“局部窗口w” (Local Window w) 内的邻近token(如绿色框所示)。
- 感受野扩展:虽然第一层(Layer 1)的感受野受限于w,但通过堆叠多层(Layer 2),上层单元(如蓝色框所示的顶层感受野)可以聚合来自下层窗口的信息,从而实现对整个输入序列的“全局感受野”。
- 设计目的:这种设计有两个目的:1)效率:将注意力复杂度从 O ( S 2 ) O(S^2) O(S2) 降低到 O ( w ∗ S ) O(w*S) O(w∗S)(在短程序列S上),保持了线性。2)归纳偏置 (Inductive Bias):它为模型提供了强大的“局部性”归纳偏置,这对于捕捉时间序列中“高分辨率”的“短程变异”(如突发尖峰)非常有效。
-
-
理念与机制总结:
- 多尺度分解 (Multi-Scale Decomposition):SST的核心理念是“分而治之”。它认识到时间序列的“模式”和“变异”在不同尺度上表现不同(Figure 2)。因此,它不强迫一个模型同时做两件事,而是通过“多尺度补丁”机制,在输入端就将这两种信息分离开。
- 分辨率量化 ( R P T S R_{PTS} RPTS):为了使这种分解更具“原则性”,论文提出了 R P T S R_{PTS} RPTS 指标。 R P T S = N P ≈ P S t r R_{PTS}=N\sqrt{P} \approx \frac{\sqrt{P}}{Str} RPTS=NP≈StrP 。这个公式量化了“分辨率”:
- R P T S R_{PTS} RPTS 低 (e.g., P L = 48 , S t r L = 16 → R P T S ≈ 0.43 P_{L}=48, Str_{L}=16 \rightarrow R_{PTS} \approx 0.43 PL=48,StrL=16→RPTS≈0.43):意味着使用大补丁( P \sqrt{P} P 大)和/或大步长( S t r Str Str 大)。这会平滑掉细节,使序列更“粗糙”,适合Mamba提取模式。
- R P T S R_{PTS} RPTS 高 (e.g., P S = 16 , S t r S = 8 → R P T S ≈ 0.5 P_{S}=16, Str_{S}=8 \rightarrow R_{PTS} \approx 0.5 PS=16,StrS=8→RPTS≈0.5):意味着使用小补丁( P \sqrt{P} P 小)和/或小步长( S t r Str Str 小)。这保留了更多细节,使序列更“精细”,适合LWT捕捉变异。
- 混合专家 (Mixture-of-Experts):SST采用MoE框架,将Mamba(作为模式专家)和LWT(作为变异专家)结合起来。但与传统MoE不同,SST的路由(Long-Short Router)不是为每个token选择“一个”专家(以节省算力),而是学习两个“全局”权重( p L , p S p_L, p_S pL,pS)来“融合”两个专家的输出。这种融合机制允许模型根据输入数据动态调整对长程趋势和短程波动的依赖程度。
-
图解总结:
论文提出的SST架构(Figure 5)通过其多尺度专家设计,完美地解决了“动机图解”中提出的核心问题。- 如何解决Figure 1(效率 vs. 信息的权衡):SST没有在Mamba和Attention之间做“非此即彼”的选择。它两者都要,但通过将昂贵的全局Attention替换为高效的“局部窗口注意力”(LWT, Figure 6),并结合Mamba(本身就是线性的),SST实现了两全其美:它既获得了Mamba的“长程建模能力”和LWT的“精细建模能力”,又将整体复杂度保持在了 O ( L ) O(L) O(L)。
- 如何利用Figure 2(多尺度特性):SST没有像Mambaformer那样,在“同一份”数据上混合两种模型,从而导致“信息干扰”。相反,SST利用了Figure 2的洞察,通过“多尺度补丁”模块,主动创造了两个不同的数据视图:“低分辨率”视图(对应Figure 2顶部的Patterns)和“高分辨率”视图(对应Figure 2底部的Variations)。
- 协同工作:最终,SST将Figure 1中的“Mamba”分配给Figure 2中的“Patterns”(粗粒度),将Figure 1中的“Attention”(LWT变体)分配给Figure 2中的“Variations”(细粒度)。通过这种方式,SST让两个专家在各自最舒适的数据尺度上工作,避免了信息干扰,协同地捕捉了时间序列的完整动态。
5. 即插即用模块的作用
论文的核心创新点(多尺度、双专家、路由)是紧密耦合在SST架构中的,但其背后的设计理念可以被抽象为“即插即用”的模块或策略,并应用到其他序列建模任务中(可能包括CV或YOLO中的时序相关部分)。
-
多尺度补丁模块 (Multi-Scale Patcher) & R P T S R_{PTS} RPTS 指标:
- 适用场景:任何需要处理不同尺度特征的序列任务(如视频理解、长序列目标检测)。
- 具体应用:在目标检测中,这可以类比于FPN(特征金字塔网络)的思想。可以将SST的“多尺度补丁”视为一种在“时间维度”上的FPN。例如,在处理视频流时,可以设计一个模块,在输入端就生成“高帧率、短时窗”的(高分辨率)数据流和“低帧率、长时窗”的(低分辨率)数据流,然后将它们送入不同的主干网络分支。
- 即插即用性: R P T S R_{PTS} RPTS 指标可以作为一个“超参数设计指南”,插入到任何使用Patching的Transformer或Mamba模型(如PatchTST)中,帮助研究者量化和优化其“粒度”,而不仅仅是凭经验调整P和Str。
-
LWT (局部窗口Transformer) 模块:
- 适用场景:需要高效(线性复杂度)但又必须保留局部高频细节(如噪声、尖峰、异常)的短序列建模。
- 具体应用:在时序预测中,LWT可以作为一个独立的、轻量级的Transformer变体,用于捕捉短程依赖。在CV中,这与Swin Transformer的“窗口注意力”思想非常相似,SST的LWT可以被视为Swin在1D时间序列上的一个高效实现。它可以作为一个即插即用模块,替换掉标准Transformer中的全局注意力,以降低计算成本。
-
长短路由 (Long-Short Router) 模块:
- 适用场景:任何采用多分支、多尺度或多专家融合(MoE)的架构。
- 具体应用:在YOLO等目标检测模型中,通常有多个分支(如P3, P4, P5)来融合不同尺度的特征。SST的Router提供了一种“动态融合”策略。可以设计一个轻量级的路由模块,它(例如)以整个输入图像或序列为输入,学习一个全局的权重向量(如 p 3 , p 4 , p 5 p_3, p_4, p_5 p3,p4,p5),然后用这个权重来动态地加权融合来自不同特征金字塔层(FPN/PANet)的输出。这使得模型可以根据输入(例如场景是“小目标密集”还是“大目标为主”)自适应地调整其特征融合策略。
-
SST双专家理念 (Mamba-for-Patterns, Attention-for-Variations):
- 适用场景:需要同时建模宏观趋势和微观细节的混合信号处理。
- 具体应用:这是一个“设计模式”而非“代码模块”。在设计(例如)YOLOv11的Neck或Head时,如果既要考虑视频中目标的“平滑运动轨迹”(长程模式),又要捕捉“突然的动作或遮挡”(短程变异),可以借鉴SST的理念:设计一个双分支结构,一个分支使用Mamba(或类似SSM的结构)来建模长程的、低分辨率的运动趋势,另一个分支使用Attention(或CNN)来建模高分辨率的、逐帧的细节变化,最后将两者融合。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 30
30 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)