刘二大人-Pytorch深度学习实践-逻辑斯蒂回归-笔记与作业06
·
逻辑斯蒂回归(Logistic Regression)
逻辑斯蒂回归本质上是一个二分类算法,并不是像线性回归那样输出一个具体的值,而是输出该样本属于某个分类的概率
-
例如手写的0~9的数据集,难道要拿到一张手写图,直接输出这是具体的几吗?并不是,而是输出它是0的概率P(0),它是1的概率P(1)……,最终选择概率最大的
-
而逻辑斯蒂回归主要解决的是二分类,也就是只有两个分类。
-
由于概率总和肯定等于1,所以我们只需要计算其中一个分类的概率即可。
-
而逻辑斯蒂回归的核心在于将线性回归的结果通过一个非线性函数——Sigmoid 函数(或 Logit 函数)——映射到 (0,1) 的概率区间。所以要先进行线性回归
-
其中最经典的函数是Logit 函数(如下图),它完美的把整个实数域限制在了[-1, 1]之间,当然还有很多其他的Sigmoid 函数,但是由于Logit 函数太过经典,所以一般说Sigmoid 函数时,往往代指的就是Logit 函数
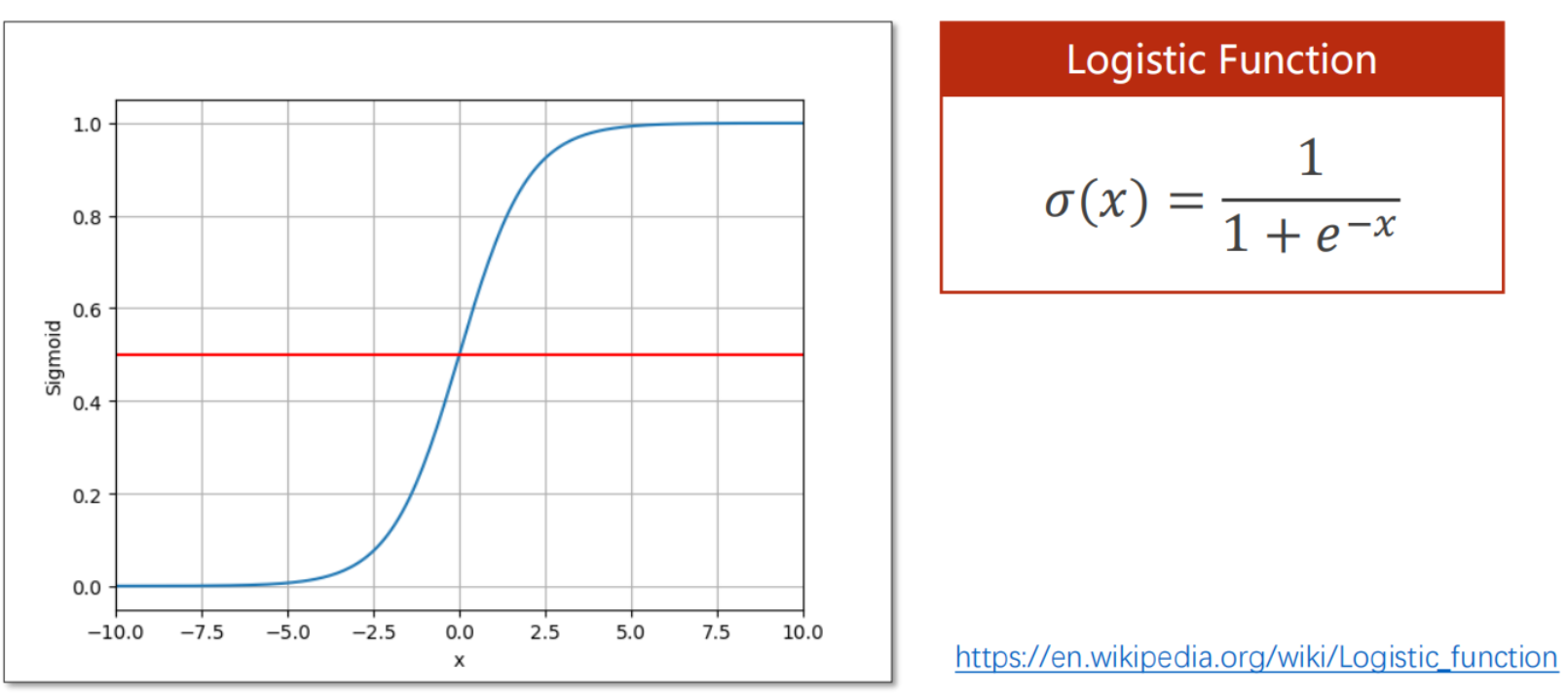
- 与线性回归对比,回顾一下前面提到的激活函数,以及为什么需要激活函数

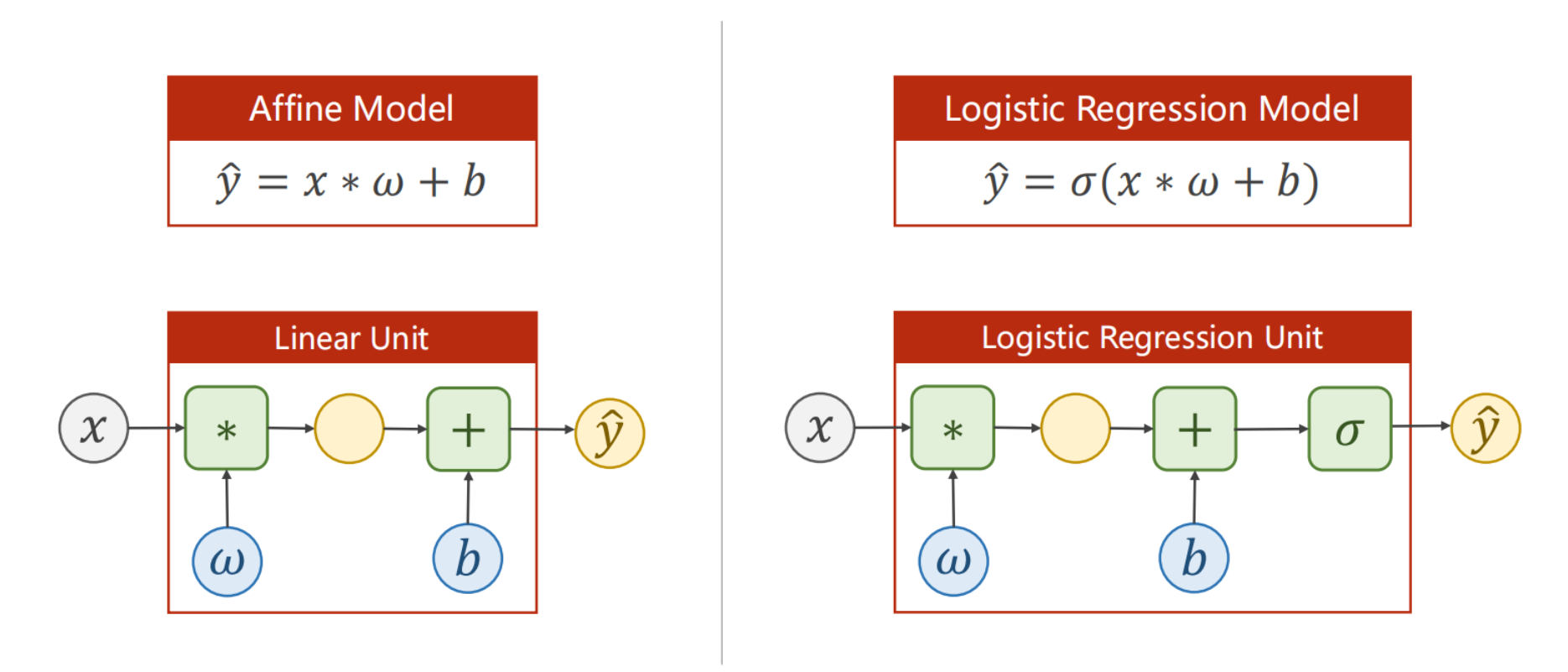
损失函数的改变:BCE
-
原本线性回归的MSE是求两个具体值的差值,而逻辑斯蒂得到的是两个概率分布,而概率分布是不能直接相减的
-
而求概率的差值用的是交叉熵,举例如下:
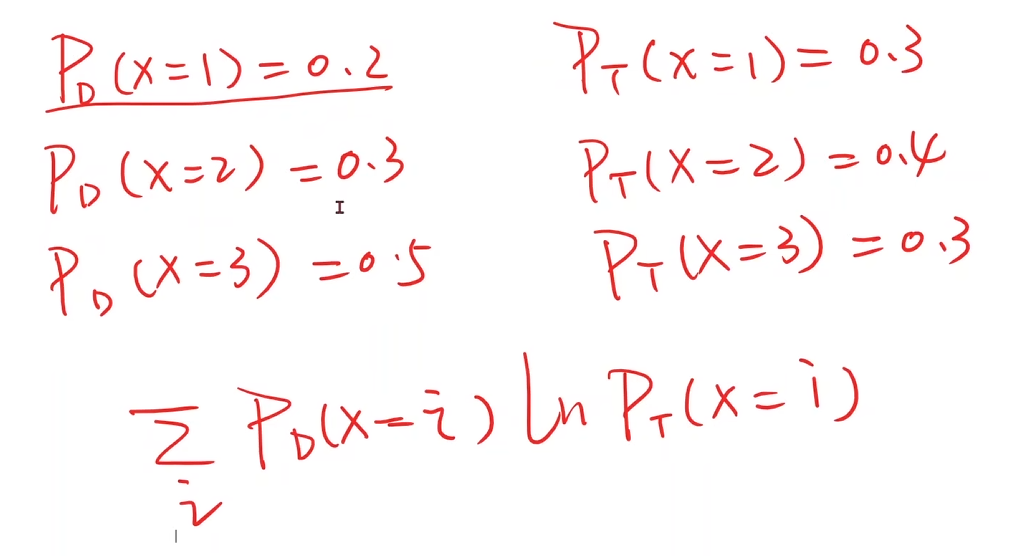
-
而逻辑斯蒂是二分类问题,只有两种分布,真实值的分布和预测值的分布,即y和ŷ,那么得到的形式如下:

- 当 y=1 时,即真实值属于class_1,(1-y) = 0,则损失函数就变成了:loss = -log ŷ,而损失是要越小越好,由于是前面有负号,则表示log ŷ越大越好,根据对数函数的图像,且定义域 ŷ 属于[0, 1],所以当 ŷ 越接近 1 时,loss的值越小越接近0,也就代表 ŷ 越接近真实值 y = 1;
- 当 y = 0 时反之;
实例代码
import numpy as np
import torch
import torch.optim as optim
from torch import nn ## nn 是 neural network 神经网络的缩写
import matplotlib.pyplot as plt
import torch.nn.functional as F
#定义数据集,设置为矩阵模式,3*1 的矩阵
# X 表示学习时长
x_data = torch.tensor([[1.0], [2.0], [3.0]], dtype=torch.float)
# Y 表示是否及格
y_data = torch.tensor([[0.0], [0.0], [1.0]], dtype=torch.float)
class LogisticRegressionModel(nn.Module):
def __init__(self):
# 调用父类的初始化方法
super(LogisticRegressionModel, self).__init__()
# nn.Linear 自动创建并初始化 w 和 b,反正会自动,具体可以后续详细了解
self.linear = nn.Linear(1, 1)
# 前馈
def forward(self, x):
return F.sigmoid(self.linear(x))
# 反馈,PyTorch会自动帮你求导,除非你自己写的效率比PyTorch还高
# 实例化自己的模型
my_model = LogisticRegressionModel()
# 使用 BCELoss (二元交叉熵损失)
criterion = nn.BCELoss()
# 使用 SGD 优化器,优化模型的参数 (w 和 b)
optimizer = optim.SGD(my_model.parameters(), lr=0.05)
# 打印训练前的参数
w_init = my_model.linear.weight.item()
b_init = my_model.linear.bias.item()
print(f"训练前参数: w={w_init:.4f}, b={b_init:.4f}")
# 训练参数及记录
num_epochs = 2000
costs_list = []
epochs_list = []
print("--- 开始训练 ---")
for epoch in range(num_epochs):
# (A) 梯度清零
optimizer.zero_grad()
# (B) 前向传播: 得到预测概率 (Y_pred)
y_pred = my_model(x_data)
# (C) 计算损失
loss = criterion(y_pred, y_data)
# (D) 反向传播: 计算梯度
loss.backward()
# (E) 更新权重
optimizer.step()
# 记录损失
costs_list.append(loss.item())
epochs_list.append(epoch)
if (epoch + 1) % 200 == 0:
current_w = my_model.linear.weight.item()
current_b = my_model.linear.bias.item()
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.6f}, w: {current_w:.4f}, b: {current_b:.4f}')
# 6. 最终预测和结果
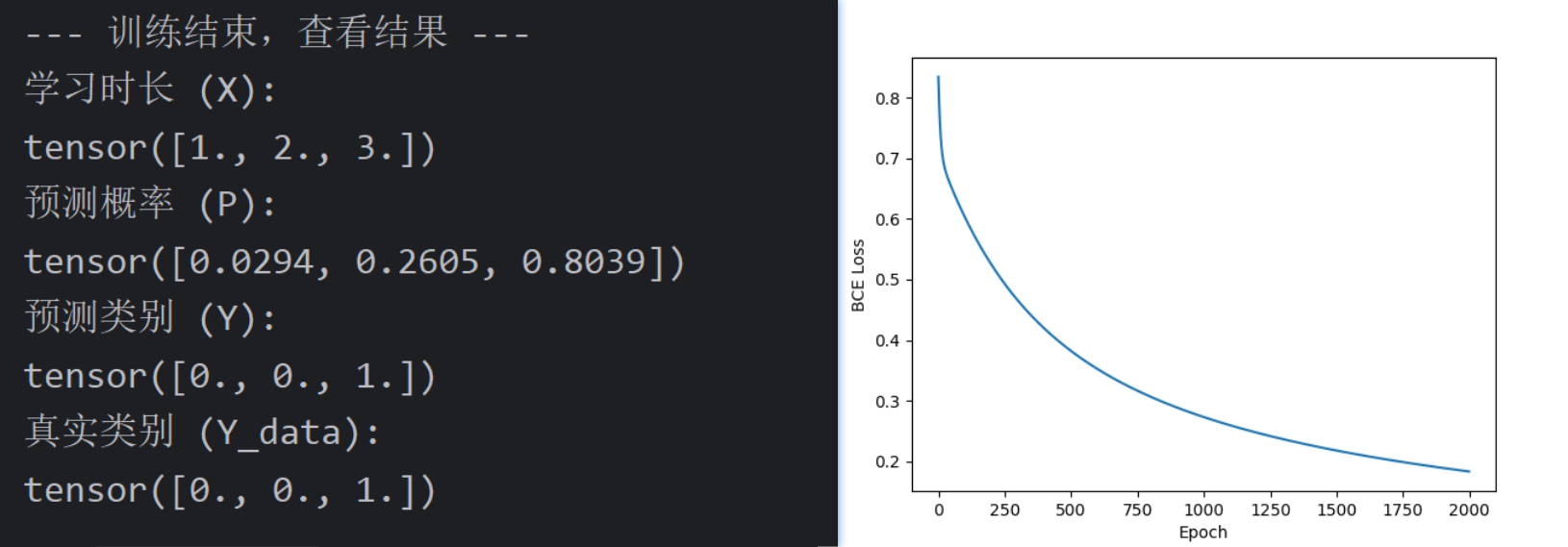
print("-" * 30)
print("--- 训练结束,查看结果 ---")
# 切换到评估模式,并禁用梯度计算
my_model.eval()
with torch.no_grad():
# 预测整个数据集的概率
y_prob = my_model(x_data)
# 将概率转换为类别 (P >= 0.5 视为及格 1)
y_predicted_classes = (y_prob >= 0.5).float()
print(f"学习时长 (X):\n{x_data.squeeze()}")
print(f"预测概率 (P):\n{y_prob.squeeze()}")
print(f"预测类别 (Y):\n{y_predicted_classes.squeeze()}")
print(f"真实类别 (Y_data):\n{y_data.squeeze()}")
# 7. 绘图 (可选: 可视化损失曲线)
plt.plot(epochs_list, costs_list)
plt.ylabel('BCE Loss')
plt.xlabel('Epoch')
plt.show()
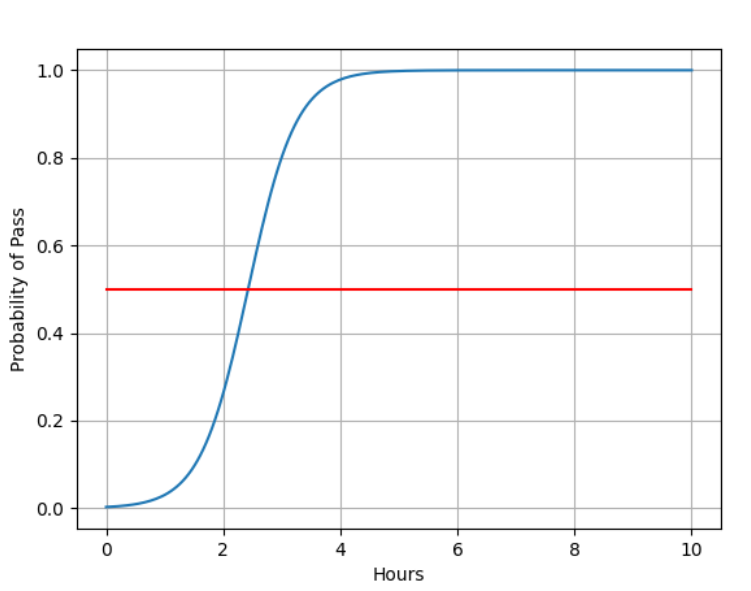
# 在 0 到 10 的范围内均匀地生成 200 个数据点
x = np.linspace(0, 10, 200)
# 把 x 用Tensor转换成 200 * 1 的矩阵
x_test = torch.Tensor(x).view(200, 1)
# 用训练好的模型输出y_test
y_test = my_model(x_test)
# Tensor 转列表
y = y_test.data.numpy()
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)