机器学习——朴素贝叶斯分类器(Naive Bayes Classifiers)
机器学习——朴素贝叶斯分类器(Naive Bayes Classifiers)
贝叶斯分类器详解与实战:从理论到实践
在机器学习的众多分类算法中,**贝叶斯分类器(Naive Bayes)**以其简单、高效、适用于高维数据的特性,被广泛应用于文本分类、垃圾邮件识别、情感分析等领域。本文将简要介绍贝叶斯分类的基本理论,并通过两个实际案例展示其在不同数据集上的应用。
一、贝叶斯理论简介
贝叶斯分类器基于贝叶斯定理:
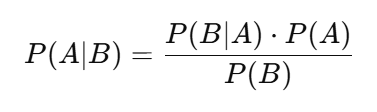
其中:
-
P(A∣B):在 B 发生的情况下 A 发生的概率(后验概率)
-
P(B∣A):在 A 发生的情况下 B 发生的概率(似然)
-
P(A):事件 A 的概率(先验概率)
-
P(B):事件 B 的概率(边缘概率)
朴素贝叶斯的“朴素”假设:
它假设所有特征之间条件独立。虽然这一假设在实际数据中往往不成立,但朴素贝叶斯分类器在许多任务中仍能表现良好,尤其适用于高维稀疏数据。
二、常见的朴素贝叶斯分类器
在 scikit-learn 中,常见的朴素贝叶斯分类器(Naive Bayes,NB)有以下几种,每种都适用于不同类型的特征数据:
1. GaussianNB (高斯朴素贝叶斯)
-
适用数据:连续特征数据。
-
假设:假设每个特征在每个类别下符合高斯(正态)分布。
-
典型应用:通常用于特征是连续数值的情况。
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
2. MultinomialNB (多项式朴素贝叶斯)
-
适用数据:离散计数数据。
-
假设:假设每个特征的值来自于一个多项式分布。特别适合用于处理特征是离散计数的情况,比如文本分类中的词频。
-
典型应用:文本分类、单词计数等。
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB()
3. BernoulliNB (伯努利朴素贝叶斯)
-
适用数据:二值离散数据(即特征取值为 0 或 1)(布尔型)。
-
假设:每个特征遵循伯努利分布,即每个特征的取值只有 0 或 1 两种可能。
-
典型应用:文本分类中的特征表示为二进制的情况,如是否包含某个词。
from sklearn.naive_bayes import BernoulliNB
model = BernoulliNB()
4. ComplementNB (互补朴素贝叶斯)
-
适用数据:多项式分布数据,尤其是当类不平衡时。
-
假设:与
MultinomialNB类似,但通过在训练过程中对类别不平衡进行补偿,通常在类别不均衡的情况下表现更好。 -
典型应用:与
MultinomialNB类似,常用于文本分类,但在数据偏斜的情况下更有效。
from sklearn.naive_bayes import ComplementNB
model = ComplementNB()
5. CategoricalNB (类别朴素贝叶斯)
-
适用数据:离散分类数据。
-
假设:适用于每个特征是类别数据的情况(即离散类别特征)。
-
典型应用:适合那些没有排序关系的分类特征(如颜色、形状等)。
from sklearn.naive_bayes import CategoricalNB
model = CategoricalNB()
选择适合的NB模型:
-
连续特征数据:使用
GaussianNB。 -
离散计数特征数据:使用
MultinomialNB。 -
二元特征数据(如布尔型):使用
BernoulliNB。 -
类别不平衡数据:使用
ComplementNB。 -
类别数据:使用
CategoricalNB。
每种模型的选择应根据数据的特征类型以及问题的具体情况来决定。
三、分类器参数详解:
| Model | 参数 | 默认值 | 值类型 | 解释/意义 |
|---|---|---|---|---|
| GaussianNB | alpha |
1.0 | float |
平滑参数,用于避免零频问题,通常用于每个类别的特征平滑。 |
fit_prior |
True |
bool |
是否使用训练数据中的先验概率。为 False 时,所有类别的先验概率相同。 |
|
class_prior |
None |
array-like 或 None |
类别的先验概率。如果为 None,则从数据中自动估算。 |
|
var_smoothing |
1e-9 | float |
用于平滑方差的参数,防止在计算时方差为零导致数值不稳定。 | |
| MultinomialNB | alpha |
1.0 | float |
平滑参数,类似 GaussianNB,避免特征为零的概率值。 |
fit_prior |
True |
bool |
是否使用训练数据中的先验概率。为 False 时,所有类别的先验概率相同。 |
|
class_prior |
None |
array-like 或 None |
类别的先验概率。如果为 None,则通过训练数据自动估算。 |
|
force_alpha |
True |
bool |
强制所有平滑的参数不为零,避免出现平滑值为零的情况。 | |
| BernoulliNB | alpha |
1.0 | float |
平滑参数,避免零频问题。 |
fit_prior |
True |
bool |
是否使用训练数据中的先验概率。为 False 时,所有类别的先验概率相同。 |
|
class_prior |
None |
array-like 或 None |
类别的先验概率。如果为 None,则从数据中自动估算。 |
|
binarize |
0.0 | float |
将特征值大于此阈值的视为 1,否则视为 0。用于将连续特征转化为二元特征。 |
|
| ComplementNB | alpha |
1.0 | float |
平滑参数,避免零频问题。 |
fit_prior |
True |
bool |
是否使用训练数据中的先验概率。为 False 时,所有类别的先验概率相同。 |
|
class_prior |
None |
array-like 或 None |
类别的先验概率。如果为 None,则通过训练数据自动估算。 |
|
norm |
True |
bool |
是否对结果进行标准化,通常可以提高分类性能。 | |
| CategoricalNB | alpha |
1.0 | float |
平滑参数,避免零频问题。 |
fit_prior |
True |
bool |
是否使用训练数据中的先验概率。为 False 时,所有类别的先验概率相同。 |
|
class_prior |
None |
array-like 或 None |
类别的先验概率。如果为 None,则从数据中自动估算。 |
|
min_categories |
None |
int |
每个类别的最小类别数目。仅当 alpha=0 时有效。默认为 None。 |
四、案例一:鸢尾花(Iris)数据集分类
📌 数据集简介
鸢尾花数据集是机器学习中的经典数据集,包含 150 条数据,分为三类鸢尾花(Setosa、Versicolor、Virginica),每条数据有四个特征:
-
萼片长度(sepal length)
-
萼片宽度(sepal width)
-
花瓣长度(petal length)
-
花瓣宽度(petal width)
✅ Python 实现代码及说明
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
# 加载鸢尾花数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集与测试集(默认 75% 训练,25% 测试)
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 使用多项式朴素贝叶斯进行训练
model = GaussianNB().fit(X_train, y_train)
# 输出分类评估报告
print(metrics.classification_report(y_test, model.predict(X_test)))
📈 输出解读:
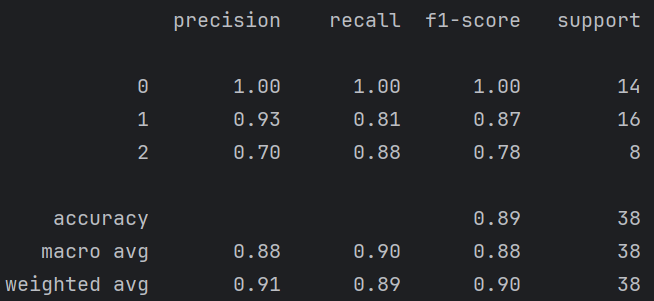
虽然特征是连续变量,而 MultinomialNB 更适合计数特征,但在这个简单数据集上也能获得不错的效果。
-
样本量 (support):每个类别的样本数。
-
精确率 (precision):被模型分类为此类别的样本中,确实是该类别的比例。(“1-precision”为误报率)
-
召回率 (recall):实际上真实是此类别的所有样本中,被正确预测出来的比例。(“1-recall”为漏报率)
-
f1-score:精确率和召回率的调和平均数,用来综合衡量模型性能。
-
accuracy:整体准确率,即正确预测的样本占所有样本的比例。(但不可以只看accuracy,太局限了)
五、案例二:手写数字(Digits)数据集分类
📌 数据集简介
先直观感受一下一个20×20 像素的数字0图像:
每个像素用一个 0-255 的整数表示亮度,即20×20 像素有400个0~255的特征(每个像素就是一个表示颜色的值,都是一个特征)
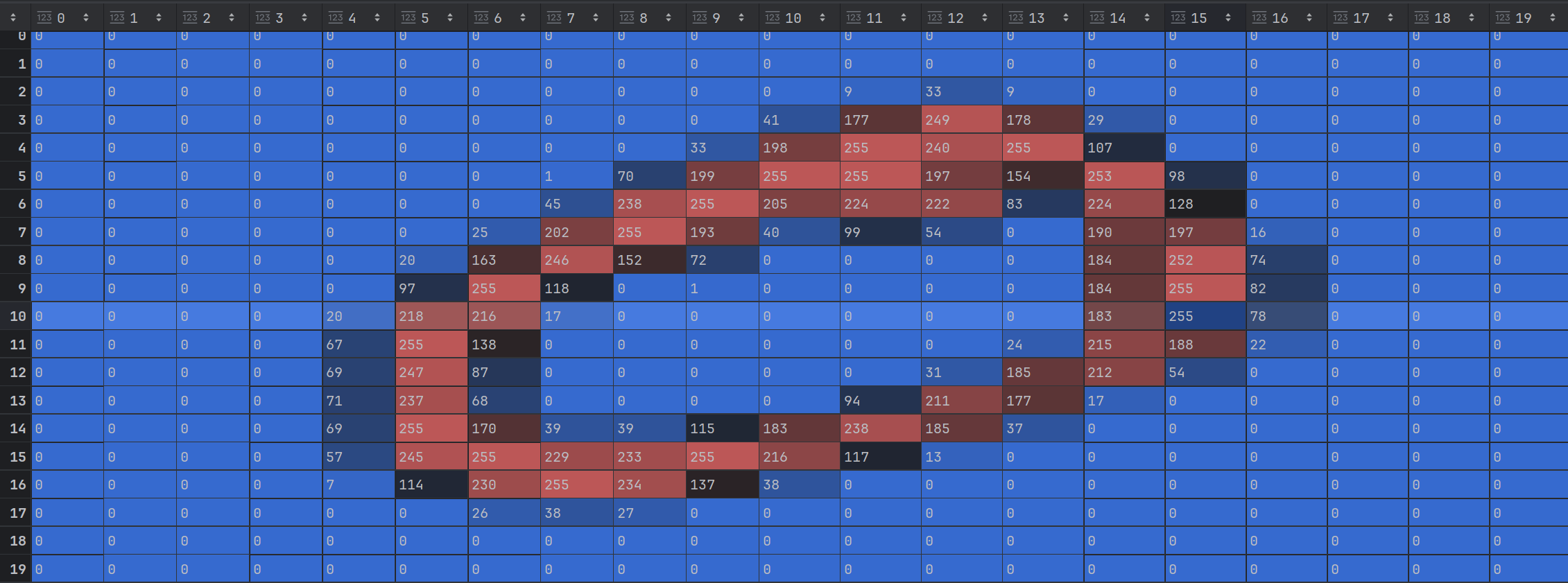
数据:
Digits 数据集包含 1797 个 8x8 像素(64个特征)的手写数字图像(0 到 9),每个图像被展平成一个长度为 64 的特征向量。目标是识别每张图片对应的数字。
✅ Python 实现代码及说明
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import classification_report
# 加载手写数字数据
digits = load_digits()
X = digits.data
y = digits.target
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 模型训练与预测
model = GaussianNB().fit(X_train, y_train)
# 输出分类报告
print(classification_report(y_test, model.predict(X_test)))
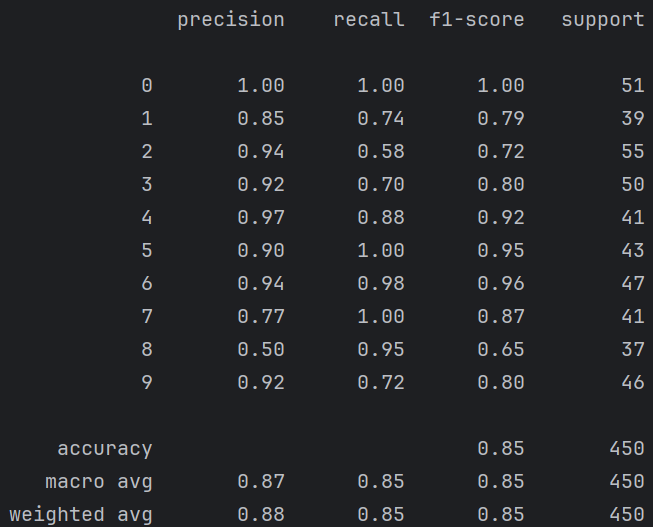
📈 输出解读:
🎯 分析
-
精度和召回率均较高,说明 MultinomialNB 在数字识别问题上表现良好。
-
由于特征为像素值(非离散计数),若转换为整数或做归一化可能有助于提升性能。
-
样本量 (support):每个类别的样本数。
-
精确率 (precision):被模型分类为此类别的样本中,确实是该类别的比例。(“1-precision”为误报率)
-
召回率 (recall):实际上真实是此类别的所有样本中,被正确预测出来的比例。(“1-recall”为漏报率)
-
f1-score:精确率和召回率的调和平均数,用来综合衡量模型性能。
-
accuracy:整体准确率,即正确预测的样本占所有样本的比例。(但不可以只看accuracy,太局限了)
六、总结与建议
| 优点 | 缺点 |
|---|---|
| 算法简单,计算速度快 | 特征独立性假设不总是成立 |
| 对高维数据表现良好 | 对连续值建模不如其他方法 |
| 对小数据集也有稳定表现 | 对特征之间的相关性不敏感 |
如果你希望进一步优化模型,可以尝试:
-
数据预处理(如特征离散化、归一化)
-
使用交叉验证调参
-
与其他模型(如SVM、决策树)进行比较

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 22
22 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)