体验 cosplay AI——阅读《深入浅出人工智能》有感
“32岁,我尝试让自己像 AI 一样学习和思考,奇怪但有效。”
—— 作者:浅蓝

这篇文章是由读者对《深入浅出 人工智能 - 原理、技术与应用》一书撰写的读书笔记,文末还附有作者的视频感想。
作者浅蓝拥有13年的教育从业经历,曾在体制内担任教师,并任职于清华大学学堂在线和百度教育事业部。
通过这篇文章,作者探讨了人类创造AI并由AI的自我学习与进化过程中反向揭示的关于学习的启示,提出了人类如何通过学习AI,从一个新的角度来认识和了解世界的规则与结构。
Part.1 - 背景及目标
非技术背景,快速建立对人工智能的框架化认知
-
时间角度 - 发展历程,即为何是当下时间点爆发,背后的原因是什么?
-
技术角度 - 包含哪些关键技术,每个技术的定义,以及技术之间的逻辑关联
-
应用角度 - 哪些场景结合AI,得到了实际应用与拓展,AI是如何起作用的
-
人的定义 - AI 背景下,如何 re定义 人的能力与技能树
|
章 |
章名称 |
|
1 |
人工智能概述 |
|
2 |
数据预处理 |
|
3 |
数据可视化 |
|
4 |
机器学习基础 |
|
5 |
监督学习模型 |
|
6 |
无监督学习算法 |
|
7 |
神经网络基础 |
|
8 |
训练深度神经网络 |
|
9 |
智能对话 |
|
10 |
知识图谱 |
Part.2 - 读书笔记
第 1 章 - 人工智能概述
1.0 - 前言&背景
-
人工智能的定义
人工:人类制造
智能:人类制造能够模拟人类智能行为的独立的计算系统
底层学科:计算机科学、心理学、数学、语言学、逻辑学、信息论
-
图灵测试
1950年,如何分辨机器是否有自主意识?
图灵测试:人与机器对话,如果无法判别为机器,即通过图灵挑战
关键点:表现、反应、互动
1.1 - 人工智能历史
-
1956年达特茅斯会议
确立了AI人工智能,未来几十年里发展出神经网络、反向传播等机制

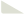
达特茅斯会议与人工智能的起源:
1956年的达特茅斯会议被认为是人工智能(AI)领域的起点。会议上,科学家们首次正式提出“人工智能”这一概念,并探讨了如何让机器模拟人类智能。不过,**神经网络**和**反向传播**这两个具体技术并非在这次会议上提出,它们是后续几十年逐渐发展起来的。以下是通俗解释:
1. 神经网络:模仿人脑的“学习机器”
-
类比:想象神经网络像一张由多层“节点”(类似脑细胞)组成的网。每一层节点负责处理不同层次的信息。例如:
-
-
输入层:接收原始数据(比如一张图片的像素)。
-
隐藏层:逐步分析特征(比如先识别边缘,再识别眼睛、鼻子)。
-
输出层:给出结果(比如判断图片是“猫”还是“狗”)。
-
-
核心思想:通过调整节点间的连接强度(权重),让网络从数据中自动学习规律,最终完成分类、预测等任务。
2. 反向传播:让机器“从错误中学习”
-
类比:假设你教孩子认字,他写错了一个字,你会告诉他哪里错了,让他下次改正。反向传播就是这个“纠错老师”。
-
过程:
-
-
神经网络先做一个预测(比如判断图片是猫)。
-
对比预测结果和正确答案的差距(比如实际是狗)。
-
反向传播会计算每个节点对错误的“责任”,并调整连接权重,让下次预测更准。
-
-
意义:这是训练神经网络的核心方法,让机器能通过大量数据不断优化自己。
两者的关系
-
神经网络是结构,像一台未组装的机器;
-
反向传播是组装说明书,指导机器如何通过数据自我改进。
为什么达特茅斯会议重要?
虽然神经网络和反向传播是后续发展的技术,但这次会议奠定了“让机器模拟人类智能”的愿景,激励了后来几十年的研究。可以说,达特茅斯会议是AI的“思想起点”,而神经网络和反向传播是让这一思想落地的“工具”。

1996 年 - 深蓝在象棋战胜人类:背后是暴力搜索 - 穷举法
2016 年 3月 AlphaGo Lee 围棋战胜李世石
2017年 5月 AlphaGo Master 围棋战胜柯洁:以人类为学习样本
2017年 10月 AlphaGo Zero :自己与自己对战
AlphaGo 标志着第三代人工智能浪潮,背后是计算机科学+大数据+硬件突破算力的合力之举。本质是数据与算力的突破。

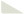
与AlphaGo Master相比 Zero之所以能达到如此境地,背后本质的技术变化或者迭代有哪些?
AlphaGo Zero 相比 AlphaGo Master 的突破性提升,本质上是**技术理念与算法设计的革新**。以下是核心的技术变化与迭代:
1. 完全摒弃人类知识,纯自我对弈学习
-
AlphaGo Master:
-
-
依赖大量人类棋谱进行初始训练(监督学习)。
-
后续结合自我对弈强化学习,但受限于人类经验的潜在偏见或局限性。
-
-
AlphaGo Zero:
-
-
从零开始:仅通过自我对弈生成数据,不依赖任何人类棋谱。
-
优势:突破人类认知边界,发现更优策略(如“点三三”等创新走法)。
-
2. 神经网络架构的简化与统一
-
AlphaGo Master:
-
-
使用**分离的策略网络(Policy Network)和价值网络(Value Network)**。
-
策略网络预测落子位置,价值网络评估局面优劣,二者独立训练。
-
-
AlphaGo Zero:
-
-
减少计算冗余,提升训练效率。
-
策略与价值的联合优化,避免两者目标冲突。
-
采用**单一融合网络**,同时输出策略(落子概率)和价值(胜率评估)。
-
优势:
-
3. 蒙特卡洛树搜索(MCTS)的优化
-
AlphaGo Master:
-
-
依赖大量随机模拟(Rollouts)评估局面,计算成本高。
-
需结合人类先验知识调整搜索权重。
-
-
AlphaGo Zero:
-
-
搜索效率提升,单次决策时间大幅缩短。
-
减少对随机性的依赖,决策更稳定。
-
取消随机模拟:完全依赖神经网络的预测结果指导搜索。
-
动态调整探索参数:根据网络置信度自动平衡探索与利用。
-
优势:
-
4. 训练过程的强化学习革新
-
AlphaGo Master:
-
-
训练分阶段:先监督学习(模仿人类),再强化学习(自我对弈)。
-
依赖人工设计奖励函数(如局部胜负判断)。
-
-
AlphaGo Zero:
-
-
模型更纯粹,避免人类主观干预导致的偏差。
-
通过自我迭代,发现全局最优策略而非局部最优。
-
端到端强化学习:从初始随机权重开始,直接通过自我对弈优化网络。
-
目标函数简化:仅以最终胜负为唯一奖励信号,无需人工干预。
-
优势:
-
5. 计算资源的更高效利用
-
AlphaGo Master:
-
-
需要分布式计算集群支持(数千块TPU)。
-
-
AlphaGo Zero:
-
-
算法优化:单一网络和高效搜索降低计算需求。
-
仅用**4块TPU**即可在40天内训练完成,远超人类水平。
-
总结:技术迭代的本质
AlphaGo Zero 的突破源于**“大道至简”**的理念:
-
去人类中心化:摒弃先验知识,让机器自主探索。
-
算法统一性:融合策略与价值网络,简化搜索流程。
-
强化学习纯粹性:仅以胜负为终极目标,实现自我进化。
这些变化使得 AlphaGo Zero 不仅在围棋领域超越人类,更验证了**无监督强化学习**在复杂问题中的普适潜力。

1.2 - 机器如何学习?机器学习与深度学习
-
人类如何学习?
-
-
事物与事物之间关系
-
行为模仿
-
认知推理
-
本质是认知事物概念+了解事物之间关系+模仿+应用+推演迭代
-
人脑功能
-
-
接收信息
-
存储信息
-
交换信息
-
抽象推理
-
完成从经验和数据中学习复杂知识结构
-
机器如何开始学习?
-
-
世界数字化,把事物变成数字 - 在向量空间表达
-
事物之间的关系转化为运算逻辑
-
通过机器学习,让计算机学习并处理数字间的逻辑关系
-
-
人工智能的开展步骤
-
-
提出问题
-
准备数据
-
训练模型
-
测试模型
-
应用模型
-
-
按照机器学习训练模式划分,可以分为
-
-
监督学习
-
无监督学习
-

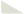
有监督学习与无监督学习的通俗理解:
1. 核心区别:有无“参考答案”
-
有监督学习(Supervised Learning):
-
-
训练一个模型区分猫狗,需要大量标注好的猫狗图片。
-
根据历史数据预测明天是否会下雨。
-
分类:预测离散类别(如垃圾邮件识别)。
-
回归:预测连续数值(如房价预测)。
-
定义:像学生做带答案的练习题,模型通过“参考答案”(标签)学习规律。
-
数据特点:输入数据(如图片)必须附带明确的标签(如“猫”或“狗”)。
-
典型任务:
-
例子:
-
-
无监督学习(Unsupervised Learning):
-
-
根据用户购物行为自动划分兴趣群体。
-
从大量新闻中自动提取主题(如体育、科技)。
-
聚类:将相似数据分组(如客户分群)。
-
降维:简化数据维度(如将高维数据压缩成二维可视化)。
-
定义:像科学家探索未知领域,模型自行发现数据中的隐藏模式。
-
数据特点:输入数据没有标签,模型需要“自食其力”。
-
典型任务:
-
例子:
-
2. 应用场景对比
3. 比喻助记
-
有监督学习:像“学驾照”——教练(标签)明确告诉你何时刹车、转向,通过反复练习掌握规则。
-
无监督学习:像“荒野探险”——没有地图和向导,通过观察地形(数据分布)找到路径或资源。
4. 优缺点总结
-
有监督学习:
-
-
✅ 精准解决特定问题(如预测、分类)。
-
❌ 依赖高质量标注数据,成本高且可能受限于标注偏差。
-
-
无监督学习:
-
-
✅ 灵活挖掘数据潜在价值(如用户行为分析)。
-
❌ 结果难以直接应用,需结合领域知识进一步解释。
-
5. 实际应用中的结合
现实中,两者常结合使用:
-
半监督学习:少量标注数据 + 大量无标注数据(如医学影像分析)。
-
预训练+微调:先用无监督学习从海量数据中学习通用特征(如语言模型),再用少量标注数据微调具体任务(如文本分类)。
一句话总结:
-
有监督学习是“按图索骥”
-
无监督学习是“无中生有”——前者依赖明确的指导,后者追求自主的发现。

-
按照机器学习的学习方法
-
-
传统机器学习
-
深度学习 - 借助神经网络 (因为类似人类脑部神经,有多层结构,所以被称为深度学习)
-
深度学习:模拟人类脑行为特征,进行分布式信息并行处理的数学模型
深度学习的发展经历了从追求深、到追求复杂的演变,期间出现了
-
几卷网络神经
-
循环网络神经
-
Attention - Transformer

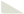
分步解释与答案
1. 卷积神经网络(CNN)、循环神经网络(RNN)、Transformer 是否属于不同的神经网络?
- 是的,它们是三种不同的神经网络架构,设计目标与适用场景各有侧重:
(1) 卷积神经网络(CNN)
-
核心特点:
-
-
通过**卷积核**提取局部特征(如图像中的边缘、纹理)。
-
具有**平移不变性**(无论物体在图像中的位置如何,都能识别)。
-
-
典型应用:
-
-
图像分类(如ResNet)、目标检测(如YOLO)。
-
(2) 循环神经网络(RNN)
-
核心特点:
-
-
通过**循环结构**处理序列数据(如时间序列、文本)。
-
能捕捉时间依赖关系,但存在**长程梯度消失**问题。
-
-
典型应用:
-
-
早期机器翻译(如LSTM)、语音识别。
-
(3) Transformer
-
核心特点:
-
-
通过**自注意力机制(Self-Attention)**动态捕捉序列中任意位置的关系。
-
天然支持并行计算,解决了RNN的序列处理效率瓶颈。
-
-
典型应用:
-
-
自然语言处理(如BERT、GPT)、多模态模型(如ViT)。
-
2. 大模型中如何包含这些神经网络?
- 现代大模型(如GPT-4、PaLM)通常**以单一架构为主**,而非混合多种网络类型,具体包含关系如下:
(1) 主流大模型:以Transformer为核心
-
架构统一性:
-
-
GPT 系列:仅使用 Transformer 的**解码器**堆叠(无编码器)。
-
BERT:使用 Transformer 的**编码器**堆叠。
-
Transformer 凭借其强大的全局建模能力和并行计算效率,已成为大模型的**基础架构**。
-
例如:
-
-
参数规模扩展:
-
-
通过增加层数(如GPT-3有96层)和参数量(千亿级)提升模型能力,而非引入其他网络类型。
-
(2) 混合架构的例外情况
少数场景下会结合不同网络,但非主流趋势:
-
视觉-语言多模态模型:
-
-
图像部分用 **CNN 或 ViT(Vision Transformer)**提取特征。
-
文本部分用 Transformer 编码。
-
例如 CLIP:
-
但本质上仍是分模块设计,并非在同一网络中混用 CNN 和 Transformer。
-
-
早期模型尝试:
-
-
如 RNN+CNN 用于视频理解(时空特征联合建模),但已被纯 Transformer 方案(如Video Swin Transformer)取代。
-
(3) 为什么大模型不混合多种网络?
-
训练复杂性:混合架构会增加模型设计和优化的难度。
-
计算效率:Transformer 的并行性更适合大规模分布式训练。
-
通用性:Transformer 通过调整注意力机制可适配多种任务(如文本、图像、音频)。
总结
-
不同网络类型:CNN、RNN、Transformer 是三种独立的神经网络架构,分别针对空间特征、序列依赖和全局关系建模。
-
大模型的架构选择:
-
-
当前主流大模型(如GPT、PaLM)**基于单一Transformer架构**,通过扩展规模和参数实现通用智能。
-
混合架构仅用于特定多模态任务,且多为分模块设计,而非在同一网络中融合不同网络类型。
-
一句话答案:
CNN、RNN、Transformer 是三种不同的神经网络;现代大模型(如GPT)通常基于单一的Transformer架构,通过堆叠层数和扩大规模实现强大能力,而非混合多种网络类型。

1.3 - 机器学习三要素
-
机器学习三要素
-
-
数据
-
算法
-
模型
-
关系式表达:数据+算法=模型
1.4 - AI 技术应用方向
-
图像识别
-
自然语言处理
-
语音识别
-
知识图谱
1.5 - 对法律、伦理的冲击与影响
1.6 - 岗位结构
-
算法
-
-
科学家
-
工业应用专家
-
分布式算法专家
-
-
工程层
-
-
算法工程师
-
平台工程师
-
运维工程师
-
-
数据层
-
-
数据工程师
-
标注工具开发师
-
数据标注员
-
Part.3 - 逐章用自己语言汇总输出
(遵循费曼学习法)
第一章 - 人工智能概述
最大感受是,如果说蒸汽机 - 电 - 计算机引领的 3 次工业革命,使得人类在过去 100 年的发展速度超过了过往 1000 年的总和,AI 技术的突破与应用,将超越过往 3 次工业革命的总和,飞速将人类科技指引向一个全新台阶。
基于过往计算机科学、数学、逻辑学的发展,人工智能完成了从以穷举法为思想(暴力枚举与搜索)到以神经网络为主流技术框架(不同层级的并发处理,模拟人类大脑活动状态)的进化。背后是数据与算力的迭代,再背后是硬件、计算机科学发展、数学、逻辑学、心理学的大成之举。
从技术层面来看,机器学习分为传统机器学习(深蓝为代表)与新一代机器学习(Alpha Go)为代表。
新一代机器学习依托于神经网络,同时又因为神经网络多层深入的特点,往往又被称为深度学习。
随着新一代 AI 的发展,神经网络以此出现了
-
几卷网络神经
-
循环神经网络
-
Attention-Transfomer
等不同类型的算法架构,当下主流的大模型应用如 GPT、Deepseek,均是基于Transfomer架构。
此机构最早雏形脱胎于翻译场景,人们发现,在初始的翻译场景下,给机器投喂足够多的信息,机器开始逐渐产生了推理能力,以此为基础,不断迭代,最终形成了今天的 GPT。
这里值得需要注意的一点是,当下所有的 AI 都是通过识别文字信息这一媒介让机器理解,即所有的语音、图像等多模态,也会被转化成文字,交由机器处理。
回到技术本身,对比人脑的学习路径:
-
接受信息
-
存储信息
-
交换信息
-
逻辑推理
神经网络也是分为 3 层:
-
输入层
-
隐藏层
-
输出层
分别对应接收、处理与输出。
模型 = 算法+数据
训练一个大模型的标准步骤分为:
-
定义问题
-
喂数据
-
训练模型
-
测试模型
-
应用上线
其中按大类划分,学习的模式分为
-
有监督学习
-
无监督学习
值得注意的是,不论有监督学习和无监督学习,本身都是训练的一类,且同样都可以被检测并评估衡量学习效果。
其中,有监督学习有正确答案,更多用于离散和回归类的问题。无监督学习,则更多处理没有固定答案的问题。
本质是通过获得与验证机器学习的答案,来反向让机器进行自我迭代,即调节每个神经网络节点的权重,直至得出最优解。
在实际训练中,经常2种方式不会单一进行,会并行。
在调整过程中,会有很多关键概念,比如步长、梯度下降、反向传播,这些参数和方法用来进一步让机器实现自我修正,但同时也可能会因为参数过大、或过小,导致各种问题(如过拟合),类比在人里,也会出现一些所谓的认死理、或者过于发散,无法聚焦问题的人。
在应用层面,AI技术会更多应用于:
-
图像识别
-
语音识别
-
知识图谱
-
自然语言处理
在行业岗位上,分为数算法、工程、数据 3 层,每层又分为 3 层
1 - 算法层
-
算法科学家
-
工业应用算法
-
分布式算法
2 - 工程层
-
算法工程师
-
工程师
-
运维师
3 - 数据层
-
数据标注规则
-
数据标注工具开发
-
数据标注
* 作者读书心得视频
--- End ---
欢迎关注微软 智汇AI 官方账号
一手资讯抢先了解
喜欢就点击一下 在看 吧~
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 14
14 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)