周志华《机器学习导论》第9章 聚类
目录
3.3 高斯混合聚类 Mixture-of-Gaussian
聚类任务:属于无监督学习 把样本集按特征归类为 若干子集(簇)
1. 性能度量
理想效果:同一簇样本尽可能彼此相似,不同簇样本尽可能不同
如何刻画两种划分的相似性?
对任意两两样本 要么同一簇 要么不同簇
a:都分为同一簇 d:都分为不同簇 b、c:一种同一簇 一种不同簇
以下三种计算指标 都取值为 [0,1] 并且越大代表两种划分越相似
![]()
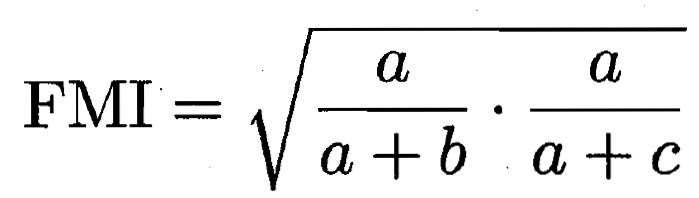
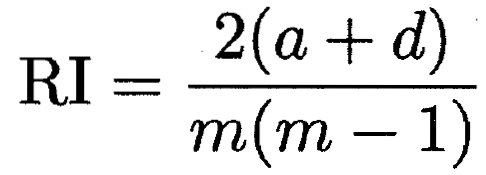
如何定义簇间距离:
簇内两点间的平均距离 ![]()
簇内两点间的最大距离 ![]()
两簇之间最近的两点距离 ![]()
两簇中心点距离 ![]()
刻画聚类性能的指标
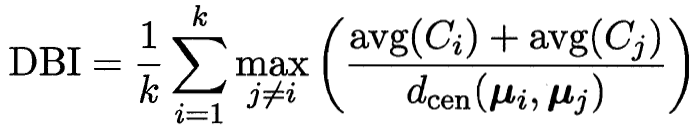 平均{ 簇内平均距离/簇间距离 } 越小越好
平均{ 簇内平均距离/簇间距离 } 越小越好
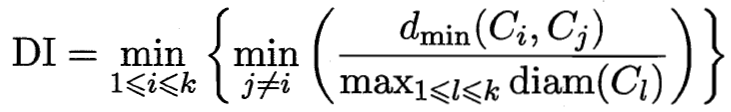 簇间/簇内 越大越好
簇间/簇内 越大越好
2. 距离计算
“有序属性” 能直接在属性值上计算距离 像 1与2近,与3远
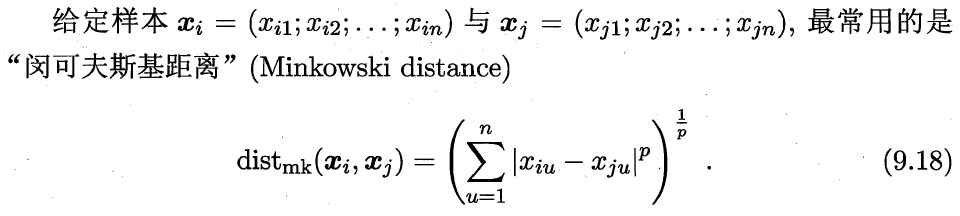
p=1 曼哈顿距离;p=2 欧氏距离。
无序属性可采用 VDM ((Value Difference Metric)
像交通工具属性为{飞机,火车,轮船}无法直接刻画两两距离
属性u 取值为 a - b 之间的 VDM 距离为 每个样本簇取值为a的比例 取值为b的比例
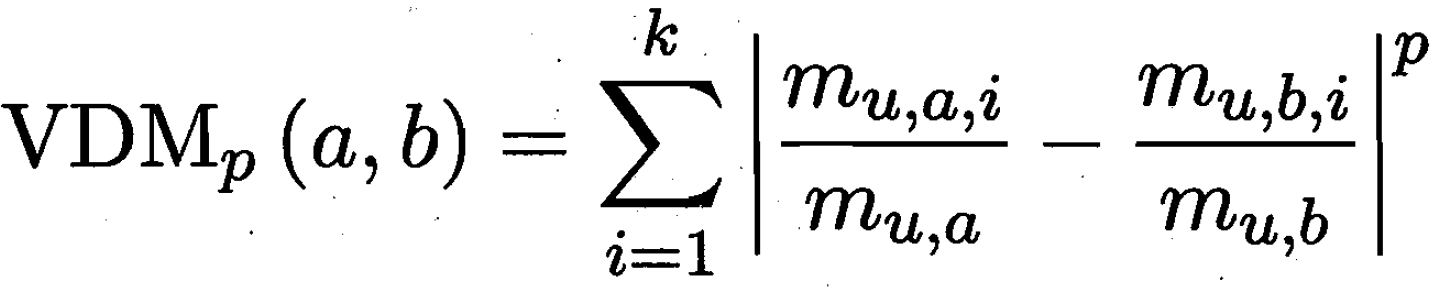

函数 d 满足 距离/度量 的四个必要条件:
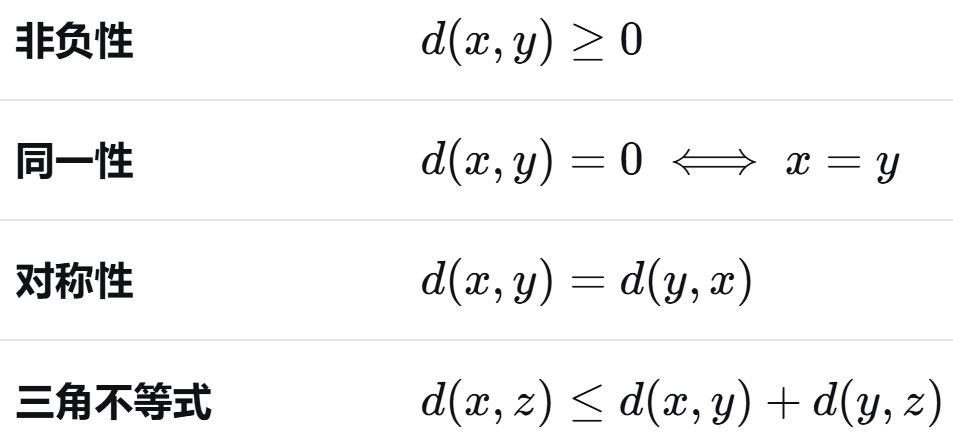
不满足对称性:A 眼中 (A,B) 的亲密程度 ≠ B 眼中 (A,B) 的亲密程度
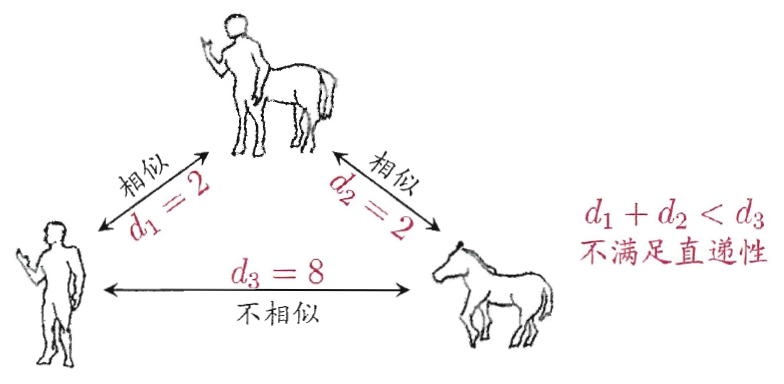
下为不满足直递性的例子:

3. 原型聚类
对原型不断进行迭代更新。重复以下两个过程至收敛。
在已知模型的情况下 如何判定样本属于哪个类?
在已知每个样本属于哪个类的情况下 如何优化模型的参数?
3.0 EM -- Expectaton-Maximization
通过 “期望(E 步)” 和 “最大化(M 步)” 的迭代,逐步逼近含隐变量模型的对数似然函数最大值。
- 隐变量的存在导致直接用极大似然估计(MLE)无法求解参数(似然函数包含不可直接优化的求和项)。
- EM 算法通过 E 步先估计隐变量的后验分布(基于当前参数),将隐变量 “显式化”;(聚类问题就是判断每个样本是哪个类)
- 再通过 M 步基于隐变量的估计值更新参数,使似然函数增大。
迭代过程中,对数似然函数单调不减,并且通过Jensen不等式可得有界。
故最终能收敛到局部最优解,从而实现对聚类类别的划分。
3.1 k-means
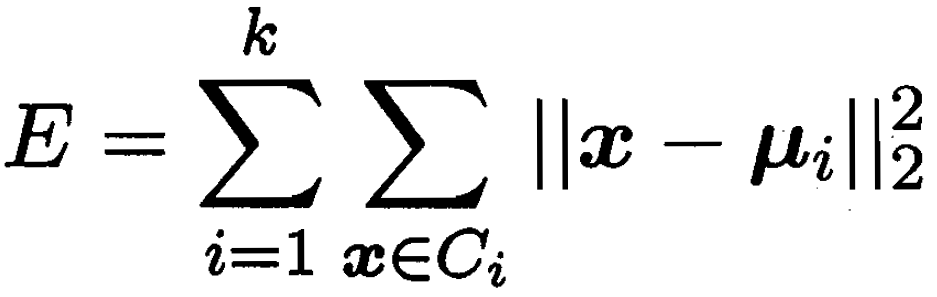 目标:最小化簇内每个点和中心点距离
目标:最小化簇内每个点和中心点距离
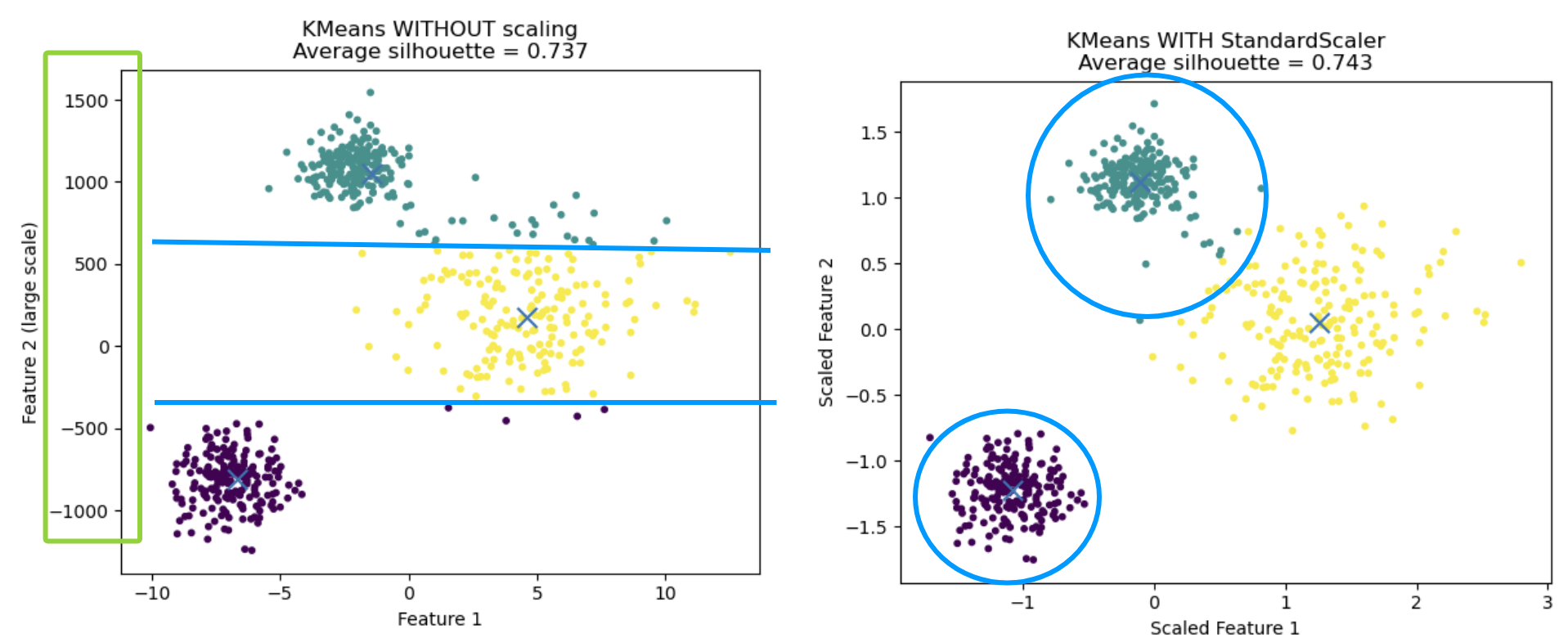
(算欧氏距离,需要先标准化预处理,防止大尺度特征占主导)
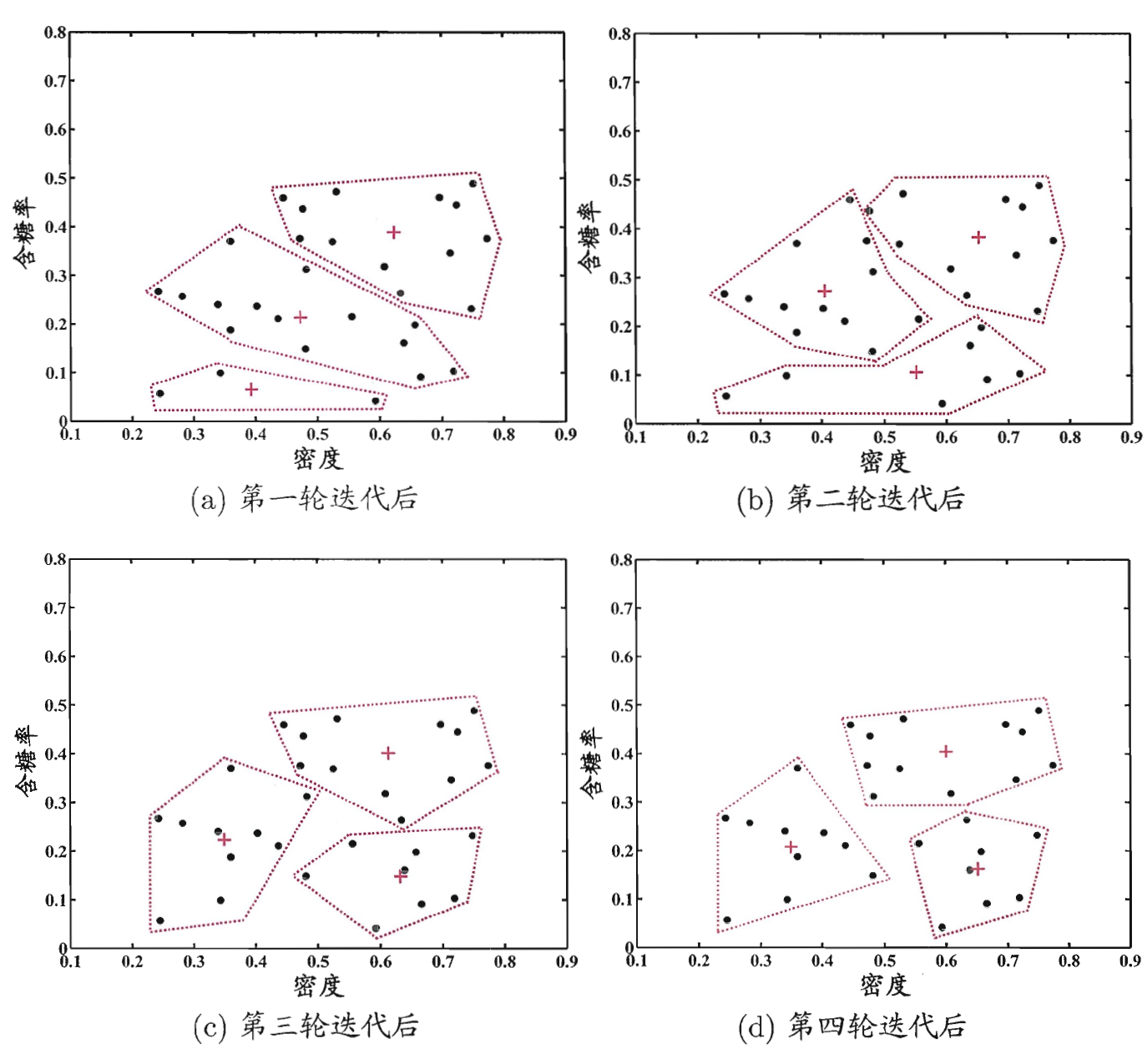
先取 k 个点作为中心点
1. 所有点划分到 最近中心点的那簇(重新分类)
2. 簇的内部取均值 重新计算 中心点 (优化模型)
3. 反复1.2 至收敛
通过解的表达转变: 通过确定簇 -> 中心点是哪个
通过中心点 -> 确定哪些点属于这个簇
手算例子:5个点 -> 2 簇:

先随机初始化哪两个点:比如先选前两个点,
然后打表格,每个点计算和这两个中心的距离,打标签。
根据标签取坐标平均,得到新的中心,再算距离打标签。
比较和上一次标签结果,一致则停止。
但是你可以发现,如果选1 2为初始点,结果为 {1,5},{2,3,4};
选1 5为初始点,结果为 {1,2,3},{4,5}
缺点:1. 参数设置 k(不懂分为几簇) 2. 结果受初始点影响 3. 容易受噪声数据影响
优化初始化:init='k-means++'(期望初始中心簇尽量分散)
第一个簇中心完全随机,剩余点相对已选中的中心点距离越远权重越高。
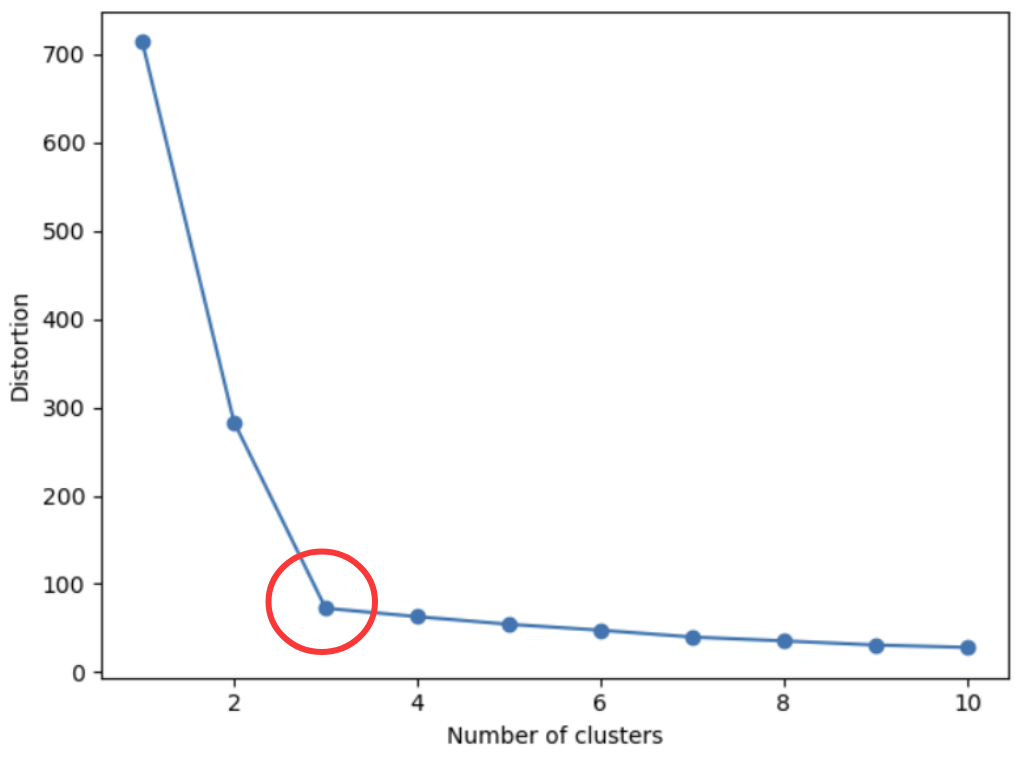
k 的选取:肘部法则(Elbow Method)
我们将 k 的取值作为横坐标,对应的误差值作为纵坐标,绘制一条曲线。
这条曲线通常形似一条手臂:
-
前臂:曲线开始急剧下降的部分。对应着找到数据中宏观的、主要的聚类结构。
-
肘部:曲线从急剧下降转变为缓慢下降的拐点。
-
手臂:拐点之后,曲线缓慢下降的部分。对应着对已有簇进行过度的、细碎的划分。
把拐点作为最后的结果。
3.2 学习向量量化 LVQ
我们用一个n维向量p 来代表一个簇。 样本集还带着一个类别标记y
随机选取样本(xj,yj) 计算所有簇向量p 最近的那个向量是p*
如果 p*=yj 说明分类正确 把p*向xj的方向再拉近一点
![]()
否则 p*把别人家的xj 拉错了 把 p*向xj的反方向拉远一点
![]()
3.3 高斯混合聚类 Mixture-of-Gaussian
假设知道参数 哪几个是一类? 假设知道这几个是一类 怎么优化参数?
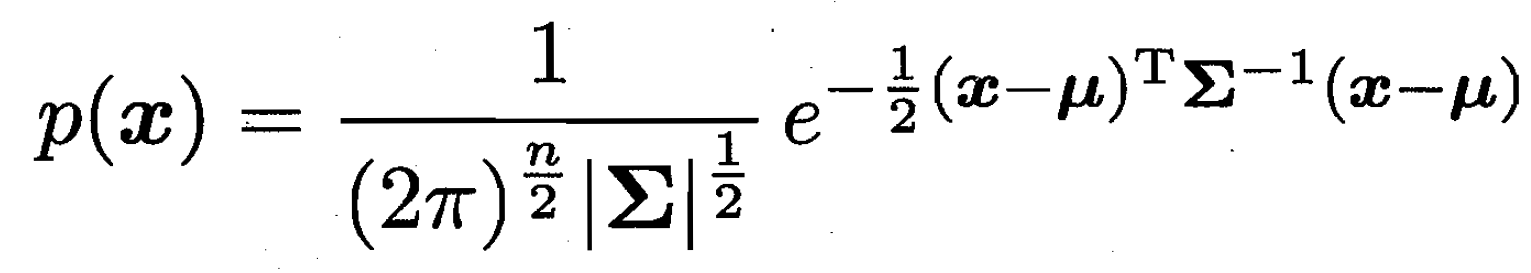
高斯混合分布:k个高斯分布 先选是哪个分布。
比如说西瓜总体分布由 1/5 3/5 1/5 的好中坏瓜组成。先选是哪种瓜,这种瓜内部再高斯分布。
需要的参数(隐变量),每个分布概率权重、均值、协方差。
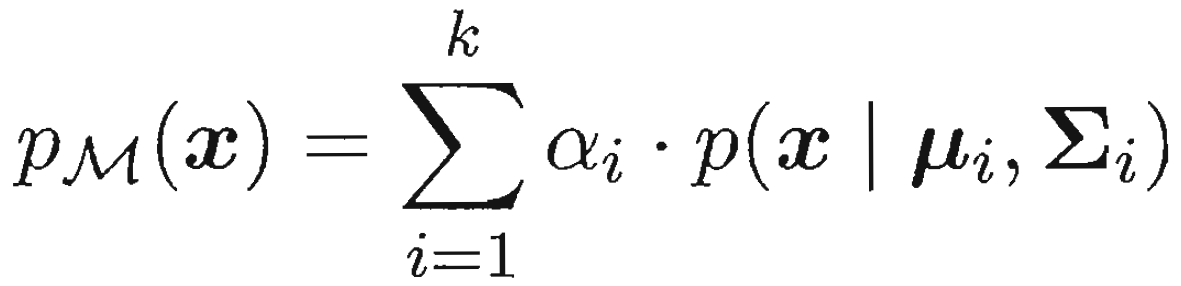
![]()
![]()
假设所有参数已知 向量xj 属于哪个簇呢?
出现向量xj,且属于第i个簇 的概率为 ![]()
整个大群体内 出现向量xj 的概率为(k个簇的求和)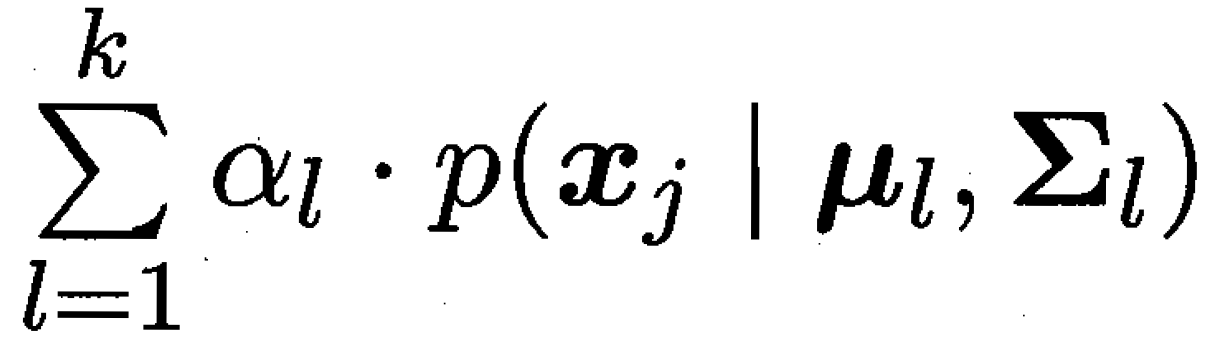
算属于 簇i 的贝叶斯后验概率 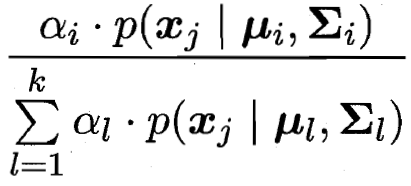 即属于概率(分子) 最大的那个簇
即属于概率(分子) 最大的那个簇
2. 如何优化模型参数?
已知分类情况,对模型参数 ![]()
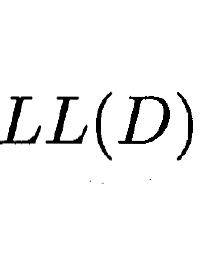
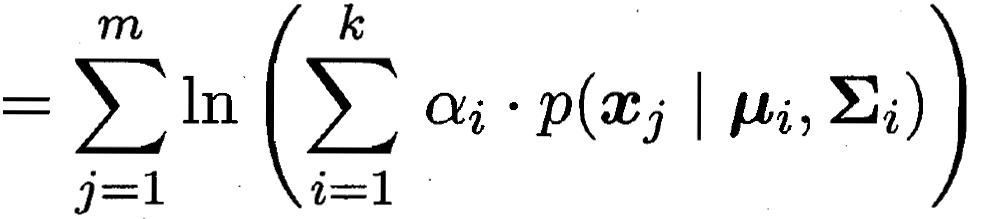 求偏导得最优值
求偏导得最优值
4. 密度聚类 DBSCAN
假设聚类结构能通过样本分布的紧密程度确定, 基于可连接样本不断扩展
DBSCAN 以邻域参数刻画 样本分布的紧密程度 有几个核心概念
![]()
![]()
核心对象:领域内样本数不少于阈值 MinPts
Xj 由Xi 密度直达:Xj在Xi的领域 且 Xi为核心对象
通过一系列密度直达:密度可达
存在3, 1和2均由3密度可达 则1和2密度相连
流程:
1.选取一个核心对象点x 开一个队列Q 建立一个簇C
2.从Q里拿一个元素 如果是核心对象点 就把他邻域的未被标记的点都添加到Q和C 标记这些点
3.重复对Q进行入队出队 相对于把 与初始的核心对象点x 密度相连的点都添加到簇C里
需要调的参数 邻域大小 ![]() 阈值
阈值 ![]()
5. 层次聚类
不同层次对数据集进行划分,形成树形的聚类结构
AGNES 自底向上:从单样本开始 每次循环找当前最近的两个聚类簇 将他们合并

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 14
14 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)