qData 数据中台开源版部署全攻略:三种方式任你选择

作为一款专注于数据治理与数据资产管理的数据中台,qData 开源版(社区版本) 提供了灵活的部署方式,满足不同阶段用户的需求:从初学者的快速上手,到研发团队的日常开发,再到生产环境的大规模部署。本文将详细介绍三种部署方式的适用场景和特点,帮助你快速找到最适合的方案。
🚀 三种部署方式对比
| 部署方式 | 说明 | 适用场景 |
|---|---|---|
| Docker Compose 部署 | 所有组件(调度器、数据库、消息队列、Spark、Flink 等)以及 qData 数据中台源码都通过 Docker Compose 一键启动 | 初学者快速上手、功能演示、测试环境 |
| 使用源代码本地启动 | qData 数据中台源码由开发者本地运行,依赖组件通过 Docker Compose 启动 | 日常开发、功能联调 |
| 自主部署(纯手工安装) | 所有依赖组件及 qData 数据中台服务均需手工安装和配置 | 生产环境、大规模部署、个性化定制场景 |
部署架构
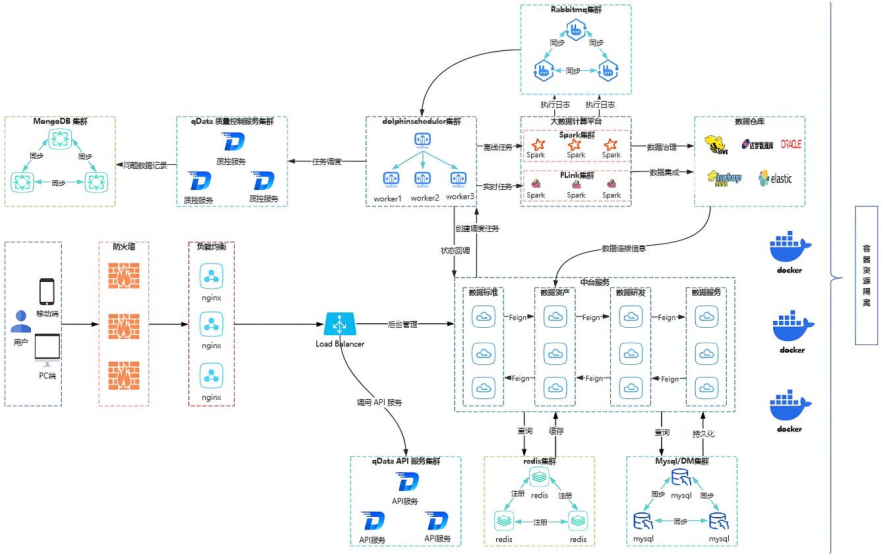
1、Docker Compose 部署:一键启动,快速体验
如果你是初次接触 qData,推荐使用 Docker Compose 部署。
通过一个配置文件,就能一键启动包括数据库、消息队列、调度器、Spark、Flink 在内的所有依赖组件,以及 qData 数据中台服务本身。
优点:
- 部署门槛低,几乎“零配置”
- 环境一致性强,避免“本地跑不起来”的尴尬
- 非常适合新手体验、功能演示和测试验证
局限:
- 扩展性有限,不适合大规模生产环境
👉 如果你只是想快速看看 qData 的功能效果,这就是你的首选方案。
2、使用源代码本地启动:研发团队的日常利器
对于需要二次开发或功能联调的团队,使用源代码本地启动 是最佳选择。
在这种模式下,qData 数据中台的核心代码直接在开发者本地运行(支持 IDE 调试和命令行启动),而依赖环境则通过 Docker Compose 拉起,减少繁琐的配置工作。
优点:
- 保留源码运行方式,调试体验好
- 依赖环境容器化,避免环境冲突
- 非常适合研发团队日常迭代和联调
局限:
- 对本地机器的资源要求较高
- 启动速度比一键部署稍慢
👉 如果你是开发者,需要频繁调试和联调,这种方式最为高效。
3、自主部署(纯手工安装):生产级的可控方案
在生产环境下,往往需要对组件版本、参数和部署架构有更高的可控性,这时就推荐选择 自主部署。
使用方需要手动安装所有依赖组件(数据库、消息队列、调度器、Spark、Flink 等)以及 qData 数据中台服务。
优点:
- 灵活可控,适应复杂生产环境
- 支持深度定制,满足企业个性化需求
- 更符合传统企业运维方式
局限:
- 配置复杂,对运维和大数据平台能力要求高
- 部署成本和时间投入较大
👉 如果你是企业用户,准备在正式环境大规模落地 qData,自主部署是必然选择。
📌 总结
- 想快速上手? 用 Docker Compose 部署
- 想研发联调? 用 源代码本地启动
- 想大规模生产? 选择 自主部署
不同的部署方式各有侧重,用户可以根据团队角色和使用场景自由选择。
无论是从入门体验到开发测试,还是最终走向生产落地,qData 开源版都能为你提供最合适的路径。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 20
20 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)