【完整源码+数据集+部署教程】快递包装箱损伤识别图像分割系统: yolov8-seg-timm
背景意义
研究背景与意义
随着电子商务的迅猛发展,快递行业的规模不断扩大,快递包装箱的损伤问题日益凸显。根据统计数据,快递运输过程中,包装箱的损坏率高达20%,这不仅给消费者带来了不便,也对快递公司造成了经济损失。包装箱的损伤不仅影响了商品的安全性和完整性,还可能导致消费者对品牌的信任度下降。因此,如何有效地识别和分类快递包装箱的损伤,成为了快递行业亟待解决的技术难题。
传统的包装箱损伤检测方法多依赖人工检查,效率低下且容易受到人为因素的影响,难以实现高效、准确的损伤识别。近年来,深度学习技术的快速发展为图像处理领域带来了新的机遇,尤其是目标检测和图像分割技术的进步,使得自动化损伤识别成为可能。YOLO(You Only Look Once)系列模型以其高效的实时检测能力和较高的准确率,逐渐成为目标检测领域的主流方法。YOLOv8作为该系列的最新版本,具备了更强的特征提取能力和更快的推理速度,适合于复杂场景下的损伤识别任务。
本研究旨在基于改进的YOLOv8模型,构建一个高效的快递包装箱损伤识别图像分割系统。该系统将利用包含1700张图像的“Object detection Damage 2”数据集进行训练和测试。该数据集涵盖了五种主要的损伤类别:压扁、孔洞、划痕/裂缝、角落收缩和撕裂/破损。这些类别的多样性为模型的训练提供了丰富的样本,能够有效提升模型在实际应用中的泛化能力。
通过对YOLOv8模型的改进,我们将重点优化其在小目标检测和复杂背景下的表现,以提高模型对快递包装箱损伤的识别精度。此外,图像分割技术的引入将使得损伤区域的边界更加清晰,便于后续的分析和处理。这一系统的实现不仅能够提高快递行业对包装箱损伤的识别效率,还能为损伤数据的统计分析提供支持,帮助企业优化包装设计和运输流程,从而降低损坏率,提升客户满意度。
综上所述,基于改进YOLOv8的快递包装箱损伤识别图像分割系统的研究具有重要的理论意义和实际应用价值。它不仅推动了深度学习技术在快递行业的应用,还为后续的相关研究提供了基础。通过这一系统的实施,快递企业能够更好地应对包装损伤问题,提高运营效率,进而在激烈的市场竞争中占据优势地位。
图片效果
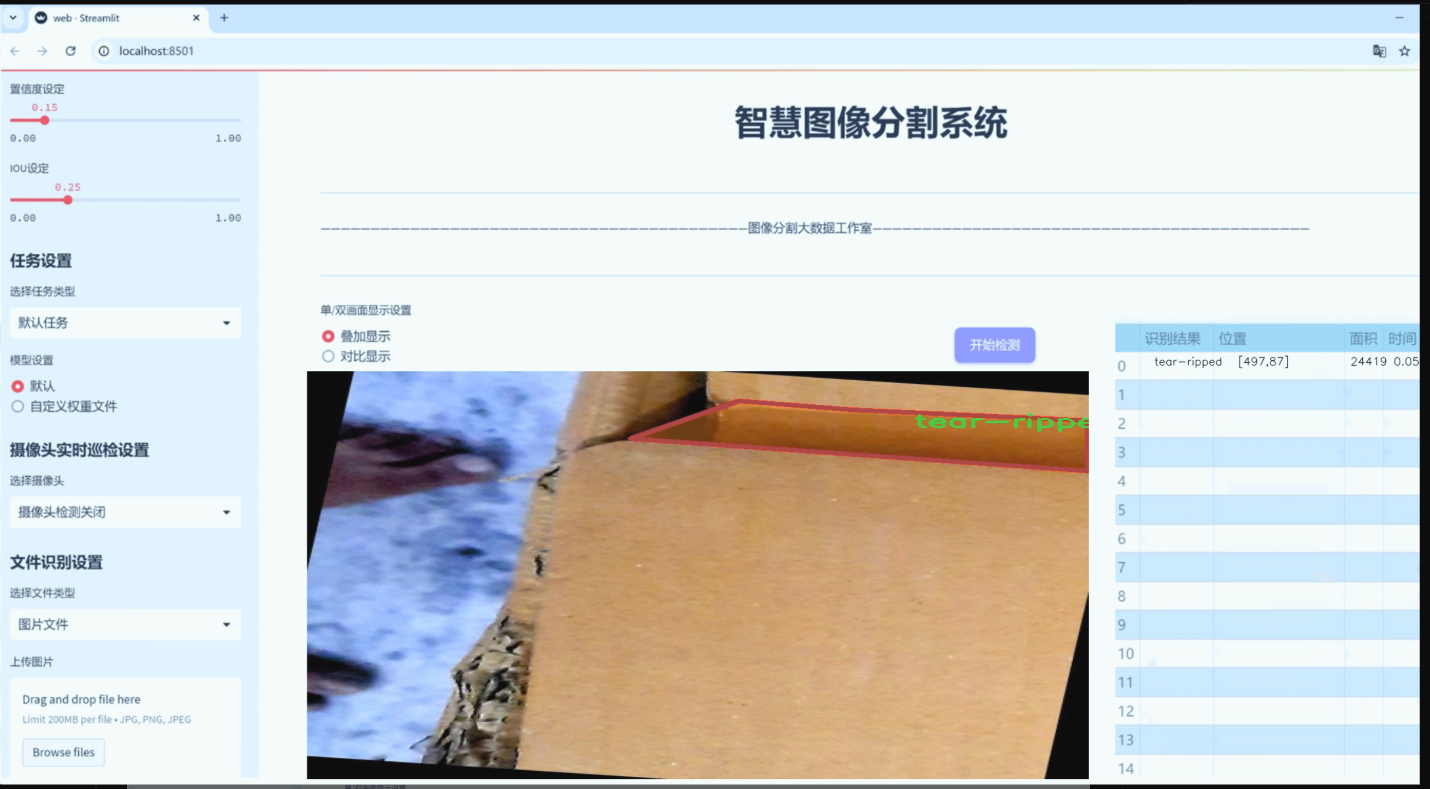
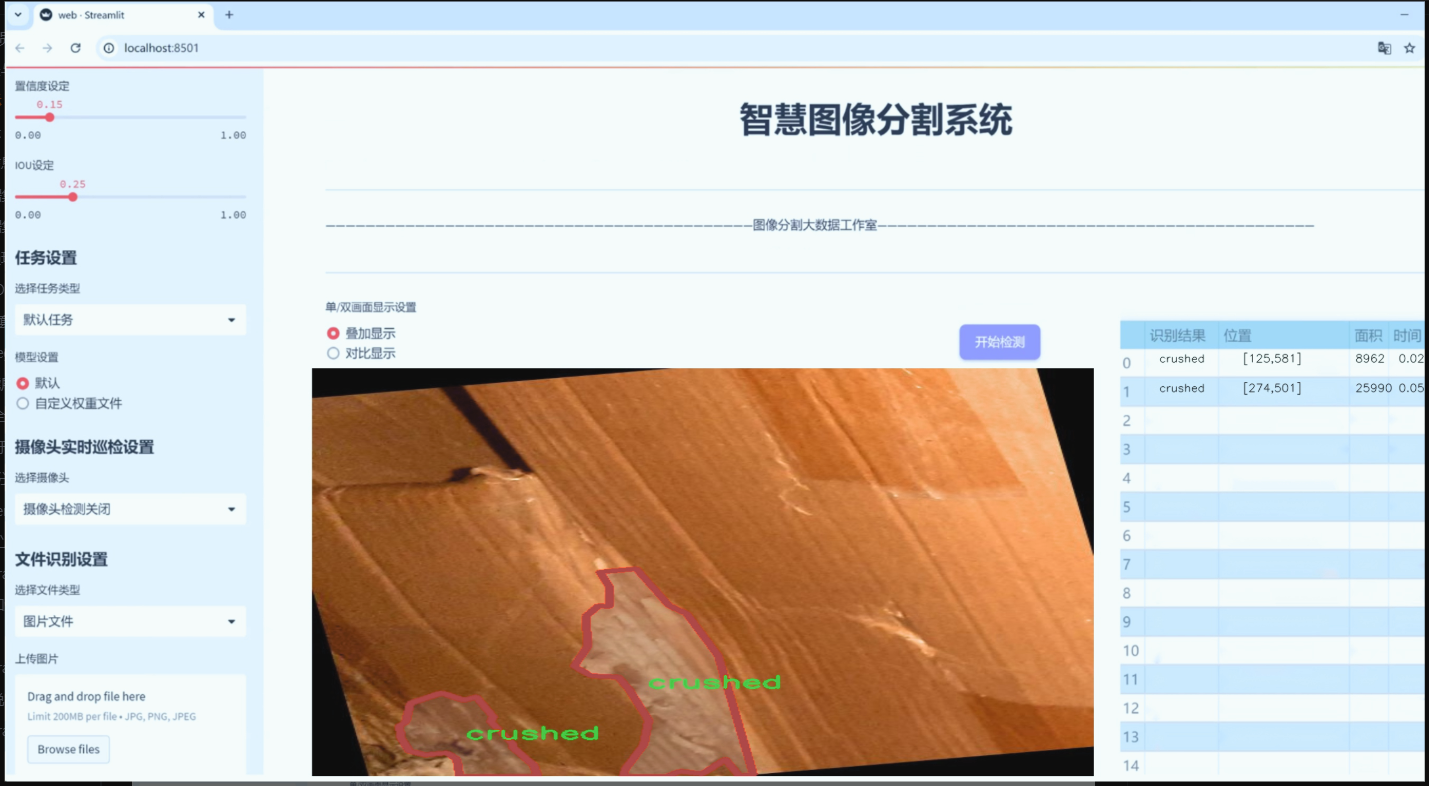
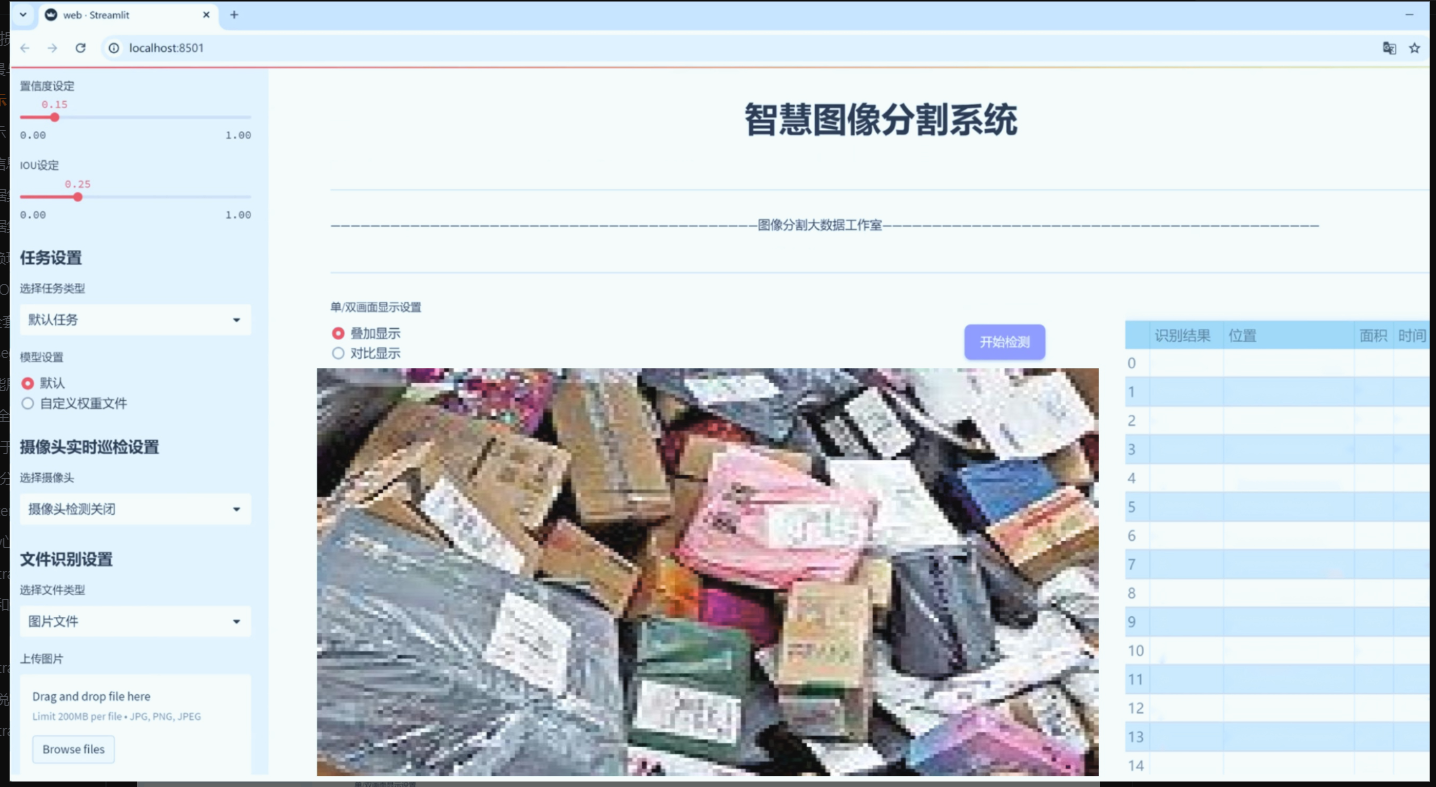
数据集信息
数据集信息展示
在现代物流行业中,快递包装箱的损伤识别显得尤为重要。为了提升这一领域的图像分割技术,特别是针对YOLOv8-seg模型的改进,我们构建了一个名为“Object detection Damage 2”的数据集。该数据集专注于快递包装箱的损伤类型,通过对多种损伤情况的标注与分类,为深度学习模型的训练提供了丰富的样本。
“Object detection Damage 2”数据集包含五个主要的损伤类别,分别是“crushed”(压扁)、“hole”(孔洞)、“scratched-cracked”(划伤或裂缝)、“shrunken-corner”(角落缩小)和“tear-ripped”(撕裂)。这些类别涵盖了快递包装箱在运输和处理过程中可能遭遇的各种损伤情况,具有较强的现实意义和应用价值。每个类别的样本均经过精心挑选和标注,确保数据的多样性和代表性,以便于模型在实际应用中能够准确识别和分类不同类型的损伤。
在数据集的构建过程中,我们不仅关注样本的数量,还特别重视样本的质量。每个损伤类别的图像均经过严格筛选,确保其清晰度和标注的准确性。数据集中包含的图像来自于不同的快递包装箱,涵盖了多种材质、尺寸和颜色的包装箱,以增强模型的泛化能力。通过这种方式,我们希望模型能够在面对不同类型的快递包装箱时,依然保持高效的识别和分割能力。
此外,为了进一步提升模型的训练效果,我们对数据集进行了多样化处理,包括图像增强、旋转、缩放和颜色调整等操作。这些处理不仅增加了数据集的规模,还帮助模型更好地适应各种环境和条件下的图像输入。通过这种方式,我们希望能够提升YOLOv8-seg模型在快递包装箱损伤识别任务中的表现,使其在实际应用中具备更高的准确性和鲁棒性。
数据集的标注信息采用了先进的标注工具,确保每个损伤区域的边界都被精确地框定。这种精细的标注方式为模型的训练提供了可靠的监督信号,使得模型能够学习到更为细致的特征。随着深度学习技术的不断发展,图像分割在损伤识别中的应用前景广阔,而“Object detection Damage 2”数据集正是推动这一领域进步的重要基础。
总之,“Object detection Damage 2”数据集为改进YOLOv8-seg的快递包装箱损伤识别图像分割系统提供了坚实的数据支持。通过丰富的样本、多样化的处理和精确的标注,我们期待这一数据集能够在未来的研究和应用中发挥重要作用,助力物流行业的智能化发展。




核心代码
以下是经过简化并添加详细中文注释的核心代码部分:
from pathlib import Path # 导入Path类,用于处理文件路径
import torch # 导入PyTorch库
from ultralytics.engine.model import Model # 从Ultralytics引擎导入Model基类
from ultralytics.utils.torch_utils import model_info, smart_inference_mode # 导入模型信息和智能推理模式
from .predict import NASPredictor # 导入NAS预测器
from .val import NASValidator # 导入NAS验证器
class NAS(Model):
“”"
YOLO NAS模型用于目标检测。
该类提供YOLO-NAS模型的接口,并扩展了Ultralytics引擎中的Model类。
旨在使用预训练或自定义训练的YOLO-NAS模型来简化目标检测任务。
"""
def __init__(self, model='yolo_nas_s.pt') -> None:
"""初始化NAS模型,使用提供的模型或默认的'yolo_nas_s.pt'模型。"""
# 确保提供的模型路径不是YAML配置文件
assert Path(model).suffix not in ('.yaml', '.yml'), 'YOLO-NAS模型仅支持预训练模型。'
super().__init__(model, task='detect') # 调用父类构造函数,设置任务为检测
@smart_inference_mode() # 使用智能推理模式装饰器
def _load(self, weights: str, task: str):
"""加载现有的NAS模型权重,或如果未提供,则创建一个新的NAS模型并使用预训练权重。"""
import super_gradients # 导入super_gradients库
suffix = Path(weights).suffix # 获取权重文件的后缀
if suffix == '.pt': # 如果是PyTorch模型文件
self.model = torch.load(weights) # 加载模型权重
elif suffix == '': # 如果没有后缀
self.model = super_gradients.training.models.get(weights, pretrained_weights='coco') # 获取预训练模型
# 标准化模型
self.model.fuse = lambda verbose=True: self.model # 定义模型融合方法
self.model.stride = torch.tensor([32]) # 设置模型步幅
self.model.names = dict(enumerate(self.model._class_names)) # 获取类别名称
self.model.is_fused = lambda: False # 定义模型是否融合的方法
self.model.yaml = {} # 设置模型的YAML配置为空
self.model.pt_path = weights # 设置模型权重路径
self.model.task = 'detect' # 设置模型任务为检测
def info(self, detailed=False, verbose=True):
"""
记录模型信息。
参数:
detailed (bool): 是否显示模型的详细信息。
verbose (bool): 控制输出的详细程度。
"""
return model_info(self.model, detailed=detailed, verbose=verbose, imgsz=640) # 返回模型信息
@property
def task_map(self):
"""返回一个字典,将任务映射到相应的预测器和验证器类。"""
return {'detect': {'predictor': NASPredictor, 'validator': NASValidator}} # 映射检测任务
代码注释说明:
导入部分:引入必要的库和模块,包括路径处理、PyTorch、Ultralytics模型基类及相关工具。
类定义:NAS类继承自Model,用于实现YOLO-NAS模型的功能。
构造函数:初始化模型,确保只接受预训练模型的路径。
加载模型:_load方法负责加载模型权重,支持从文件或预训练模型获取权重,并进行必要的模型标准化设置。
模型信息:info方法用于输出模型的基本信息,可以选择详细程度。
任务映射:task_map属性提供任务与对应预测器和验证器的映射关系。
这个程序文件定义了一个名为 NAS 的类,属于 Ultralytics YOLO(You Only Look Once)系列模型中的 YOLO-NAS 模型接口。该类继承自 Ultralytics 引擎中的 Model 类,主要用于对象检测任务。文件中包含了模型的初始化、加载、信息记录等功能。
在文件开头,有一个示例代码,展示了如何使用 NAS 类来加载一个预训练的 YOLO-NAS 模型并对一张图片进行预测。用户只需通过 from ultralytics import NAS 导入类,然后实例化模型并调用 predict 方法即可。
NAS 类的构造函数 init 接受一个参数 model,默认为 ‘yolo_nas_s.pt’,用于指定预训练模型的路径。构造函数中包含一个断言,确保传入的模型文件不是 YAML 配置文件,因为 YOLO-NAS 模型只支持预训练模型。
_load 方法用于加载模型权重。如果提供的权重文件是 .pt 格式,程序将使用 torch.load 加载该模型;如果没有后缀,则通过 super_gradients 库获取预训练模型。此方法还对模型进行了一些标准化处理,例如设置模型的步幅、类别名称等。
info 方法用于记录模型的信息,用户可以选择是否显示详细信息和控制输出的冗长程度。该方法调用了 model_info 函数来获取模型的相关信息。
最后,task_map 属性返回一个字典,映射了任务到相应的预测器和验证器类,当前只支持对象检测任务,使用 NASPredictor 和 NASValidator 类。
总体而言,这个文件提供了一个简单易用的接口,方便用户进行对象检测任务,同时确保了模型的正确加载和信息记录。
12.系统整体结构(节选)
整体功能和构架概括
Ultralytics YOLO项目是一个用于目标检测和计算机视觉任务的深度学习框架。该框架采用模块化设计,包含多个功能模块,以支持不同的模型、训练过程、回调机制和跟踪算法。每个模块都承担特定的功能,旨在实现高效的模型训练、推理和结果可视化。
模型架构:通过不同的编码器和网络结构实现图像特征提取和目标检测。
回调机制:提供灵活的训练过程监控和日志记录功能,以便于用户跟踪训练进度和性能。
跟踪器:实现目标跟踪算法,支持实时目标检测和跟踪。
模块化设计:各个功能模块相互独立,便于扩展和维护。
文件功能整理表
文件路径 功能描述
ultralytics/nn/backbone/revcol.py 实现反向列网络的前向和反向传播,包括自定义的反向传播函数和网络层结构。
ultralytics/utils/callbacks/dvc.py 集成DVCLive进行训练过程中的日志记录和可视化,提供多种回调函数以监控训练进度和性能。
ultralytics/trackers/init.py 初始化跟踪器模块,导入和注册不同的跟踪器(如BOTSORT和BYTETracker),提供公共接口。
ultralytics/models/sam/modules/encoders.py 实现图像编码器和提示编码器,基于视觉变换器架构,处理图像特征提取和不同类型提示的编码。
ultralytics/models/nas/model.py 定义YOLO-NAS模型类,负责加载预训练模型、记录模型信息,并提供对象检测任务的接口。
这个表格清晰地总结了每个文件的主要功能,帮助用户快速理解项目的结构和各个模块的作用。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:
x1, y1, x2, y2 = bbox
aim_frame_area = (x2 - x1) * (y2 - y1)
cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))
image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))
y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:
mask_points = np.concatenate(mask)
aim_frame_area = calculate_polygon_area(mask_points)
mask_color = generate_color_based_on_name(name)
try:
overlay = image.copy()
cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)
image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)
cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))
# 计算面积、周长、圆度
area = cv2.contourArea(mask_points.astype(np.int32))
perimeter = cv2.arcLength(mask_points.astype(np.int32), True)
......
# 计算色彩
mask = np.zeros(image.shape[:2], dtype=np.uint8)
cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)
color_points = cv2.findNonZero(mask)
......
# 绘制类别名称
x, y = np.min(mask_points, axis=0).astype(int)
image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))
y_offset = int(50 * adjust_param)
# 绘制面积、周长、圆度和色彩值
metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]
for idx, (metric_name, metric_value) in enumerate(metrics):
......
return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
......
# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:
processed_image = process_frame(model, image)
......
# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 7
7 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)