机器学习-预测模型与解释性研究(missforest插补缺失值)
一、机器学习
机器学习是人工智能的一个分支,旨在通过算法和统计模型指计算机系统能够从数据中学习并作出决策或预测。
1)特点
数据驱动:机器学习依赖于大量的数据进行训练,通过提取数据中的模式和规律来构建模型。
算法支持:包括监督学习(如分类、回归),非监督学习(如聚类、降维),强化学习等。
持续改进:模型通过新数据的输入,可以不断优化其性能和预测能力。
2)机器学习应用领域
模式识别,数据挖掘,统计学习,计算机视觉,语音识别,自然语言处理等。
3)为什么选择机器学习预测模型?
人们对复杂数据分析需求的不断提高。在许多领域,如医疗健康,金融分析和市场预测等,传统的分析方法无法有效处理海量数据和复杂非线性关系。
传统预测模型,如逻辑回归,线性回归和基于假设的统计模型存在局限:
对数据分布的假设过于严格,需满足线性独立性等条件。
难以捕获非线性关系,特征与目标变量之间的复杂关联无法被充分揭示。
对高维数据处理能力不足,无法有效利用大数据中的多维特征,可能导致性能下降。
人工干预多,特征工程和变量选择依赖专家经验,效率较低。
4)机器学习的类型
根据学习方式分类:监督学习,无监督学习,强化学习。
根据任务类型分类:分类模型(逻辑回归,决策树,随机森林,支持向量机,k邻近,神经网络...),回归模型(线性回归,岭回归,lasso回归,支持向量回归,随机森林回归,神经网络回归)。
二、机器学习建模基本框架
第1步,基线特征的描述。
第2步,构建GBM模型,模型效果评价。
第3步,GBM模型的解释,shap法(shap摘要图,点图,瀑布图)。
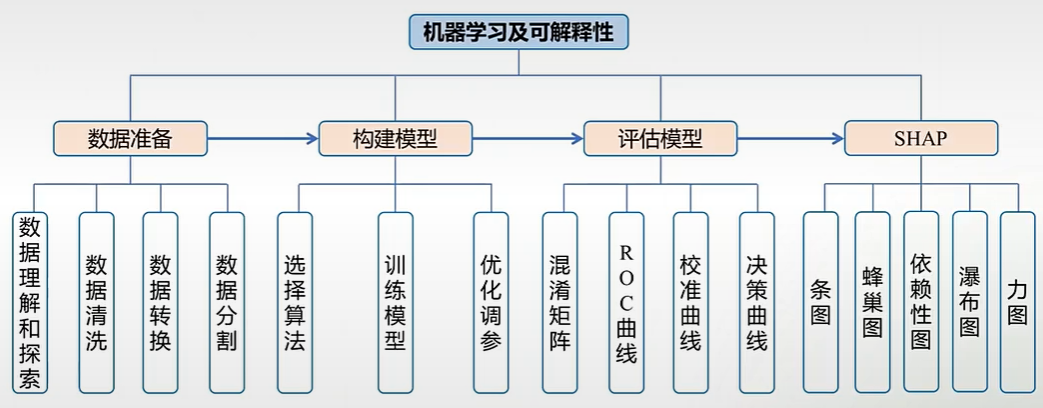
三、二分类机器学习建模
1)数据预处理

数据预处理的重要性:在机器学习模型的开发中,数据预处理是至关重要的一步,这将直接影响到模型的性能和准确性。数据预处理的主要目的是清洗、转换和准备数据,以便能够有效地输入到机器学习算法中。
数据理解和探索:
1.查看数据分布特征。
了解数据中每个特征的统计分布、是否符合正态分布或者其他类型的分布。通过直方图、箱线图、散点图等可视化手段来识别数据中的模式、差异值或偏差。
2.了解数据中的变量。
检查数据集中的每个变量的类型(数值型、类别型等),以及他们的意义。识别哪些是特征变量(X),哪些是目标变量(Y)。目标是确保正确区分特征和目标,识别哪些变量可能需要进行特征工程(如独热编码、归一化等)。
2)数据清洗
1.处理异常值
异常值是偏离其他数据点的极端值,可能会影响模型的训练。
处理异常值的方法:(1)IQR方法:通过计算4分位数间距来识别异常值。(2)Z-score方法:计算每个数据点的Z-score,识别与均值差异过大的数据点。(3)基于模型的方法:使用聚类、决策树等方法识别和去除异常值。
2.处理缺失值
缺失值是数据集中常见的问题。
缺失值处理方法:(1)删除缺失值:适用于缺失值比例很低的情况下。(2)填充缺失值:使用均值、中位数或众数填充缺失值,或使用其他列的相关性进行填充。(3)插值法:使用插值方法,估计缺失值。
3)Missforest随机森林插补
一种基于随机森林的数据插补法,它通过利用多颗决策树来预测缺失值,并不断迭代更新预测结果,直到收敛为止。
1.工作流程:
(1)对于含有缺失值的数据集,首先对每个含有缺失值的变量,将缺失值视为响应变量,其他完整的变量视为特征变量,构建随机森林模型。(2)利用已有的非缺失值作为训练集,预测缺失值。(3)将预测得到的值作为缺失值的估计,并更新数据集。不断重复步骤二、步骤三直到达到收敛标准或者预设的迭代次数。
2.优缺点
优点:
(1)非线性关系适应性:Missforest基于随机森林的模型能够捕捉非线性关系,对于非线性关系的数据具有较好的适应性。
(2)对异常值的鲁棒性:由于随机森林模型对异常值具有一定的鲁棒性,Missforest在处理含有异常值的数据时表现良好,不易受到异常值影响。
缺点:
(1)计算时间较长:对于较大的数据集,missforest需要构建多科决策树进行迭代更新,因此在计算时间上可能比较耗时。
(2)对缺失模式的敏感性:Missforest对于缺失模式较为敏感,如果缺失模式与其他变量相关,则可能会导致插补结果的偏差,需要谨慎处理数据中的缺失模式。
4)R语言实现
Missforest包:missForest()函数实现随机森林插补

#################### 安装和加载包 ####################
# 安装包(如果尚未安装)
install.packages(c("missForest", "tidyverse", "readr", "dplyr"))
# 加载包
library(missForest) # 缺失值填补
library(tidyverse) # 包含 readr 和 dplyr 等
library(readr) # 高效读取 CSV(可选)
library(dplyr) # 数据操作
#################### 数据读取 ####################
# 读取数据(使用 read.csv 或 read_csv)
log <- read.csv(file = "diabetes.csv", header = TRUE, encoding = "GBK")
# 或使用 readr(更快,自动处理编码)
# log <- read_csv("diabetes.csv", locale = locale(encoding = "GBK"))
# 查看数据
head(log) # 前六行
str(log) # 数据结构
#################### 1. 数据预处理 ####################
## 1.1 检查缺失值
missing_data <- sapply(log, function(x) sum(is.na(x)))
print(missing_data)
## 1.2 随机森林插补
set.seed(123) # 可复现性
log_imputed <- missForest(log)$ximp # 直接赋值插补结果
# 将 insulin 列四舍五入为整数
log_imputed$insulin <- round(log_imputed$insulin)
# 检查插补后缺失值
print(sapply(log_imputed, function(x) sum(is.na(x))))
## 1.3 导出插补后的数据
write.csv(log_imputed, file = "logistic_imputed.csv", row.names = FALSE)
# 重新读取插补后的数据(确认无误)
log <- read.csv("logistic_imputed.csv", header = TRUE, encoding = "GBK")
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)