深度学习入门:【迁移学习-微调】
目录
1.[全量微调下]关于参数是否预训练还是全部随机初始化的对比实验
2.[冻结特征层,只训练输出层]关于参数是否预训练还是全部随机初始化的对比实验
一.微调
将从源数据集学习到的模型迁移到目标数据集,常用:微调(fine-tuning)
-
1.在源数据集(例如ImageNet数据集)上预训练神经网络模型,即源模型。
-
2.创建一个新的神经网络模型,即目标模型。这将复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。我们还假设源模型的输出层与源数据集的标签密切相关;因此不在目标模型中使用该层。
-
3.向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
-
4.在目标数据集(如椅子数据集)上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。
-
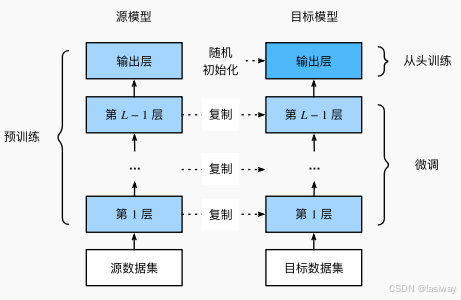
因此,预训练模型的质量很重要,微调通常在大数据上得到的预训练模型来初始化目标模型权重,完成精度提升。微调通常速度更快、精度更高。
除输出层外,目标模型从源模型中复制所有模型设计及其参数,并根据目标数据集对这些参数进行微调。目标模型的输出层需要从头开始训练。通常,微调参数使用较小的学习率,而从头开始训练输出层可以使用更大的学习率。
1.[全量微调下]关于参数是否预训练还是全部随机初始化的对比实验
如文中例子pretrained_net :
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight)学习率lr=5e-5,最后一层lrx10,结果是:loss 0.173, train acc 0.931, test acc 0.936
对比例子scratch_net:
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
train_fine_tuning(scratch_net, 5e-4, param_group=False)不用预训练参数,全部重新训练,学习率调调大变成5e-4,最后一层不x10,结果是:
loss 0.413, train acc 0.830, test acc 0.825
准确率93%和82%差距很大,普遍来讲,用微调模型,省时省力效果比全部重新训练效果更好。
- [练习1]:继续提高
finetune_net的学习率,模型的准确性如何变化?
将参数lr改大或改为最后一层lrx50,导致准确率下降,loss 0.696, train acc 0.490, test acc 0.500。
2.[冻结特征层,只训练输出层]关于参数是否预训练还是全部随机初始化的对比实验
- [练习3]:将输出层
finetune_net之前的参数设置为源模型的参数,在训练期间不要更新它们。模型的准确性如何变化? - [练习4]:事实上,
ImageNet数据集中有一个“热狗”类别。我们可以通过以下代码获取其输出层中的相应权重参数,但是我们怎样才能利用这个权重参数?
1.冻结特征层代码:
#冻结特征层
for param in finetune_net.parameters():
param.requires_grad = False
for param in finetune_net.fc.parameters():
param.requires_grad = True
train_fine_tuning(finetune_net, 5e-5)
train_fine_tuning(scratch_net, 5e-4, param_group=False) finetune_net结果是:loss 1.071, train acc 0.785, test acc 0.914
scratch_net结果是:loss 0.356, train acc 0.851, test acc 0.838
2.如何应用原hotdog类权重参数?
场景:在finetune_net定义后,将该参数用于初始化二分类输出层的“热狗”权重,即不再是随机初始化。这样,模型刚开始训练时,“热狗”类别的输出节点就已经有了很强的先验。
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight)
# finetune_net.fc = nn.Linear(512, 2)
with torch.no_grad():
# 将ImageNet的“热狗”权重赋值给新输出层的第0类(假设第0类是“热狗”)
finetune_net.fc.weight[0] = pretrained_net.fc.weight[934]
# 偏置也可以赋值
finetune_net.fc.bias[0] = pretrained_net.fc.bias[934] finetune_net结果是:loss 0.277, train acc 0.911, test acc 0.919。速度变快了。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)