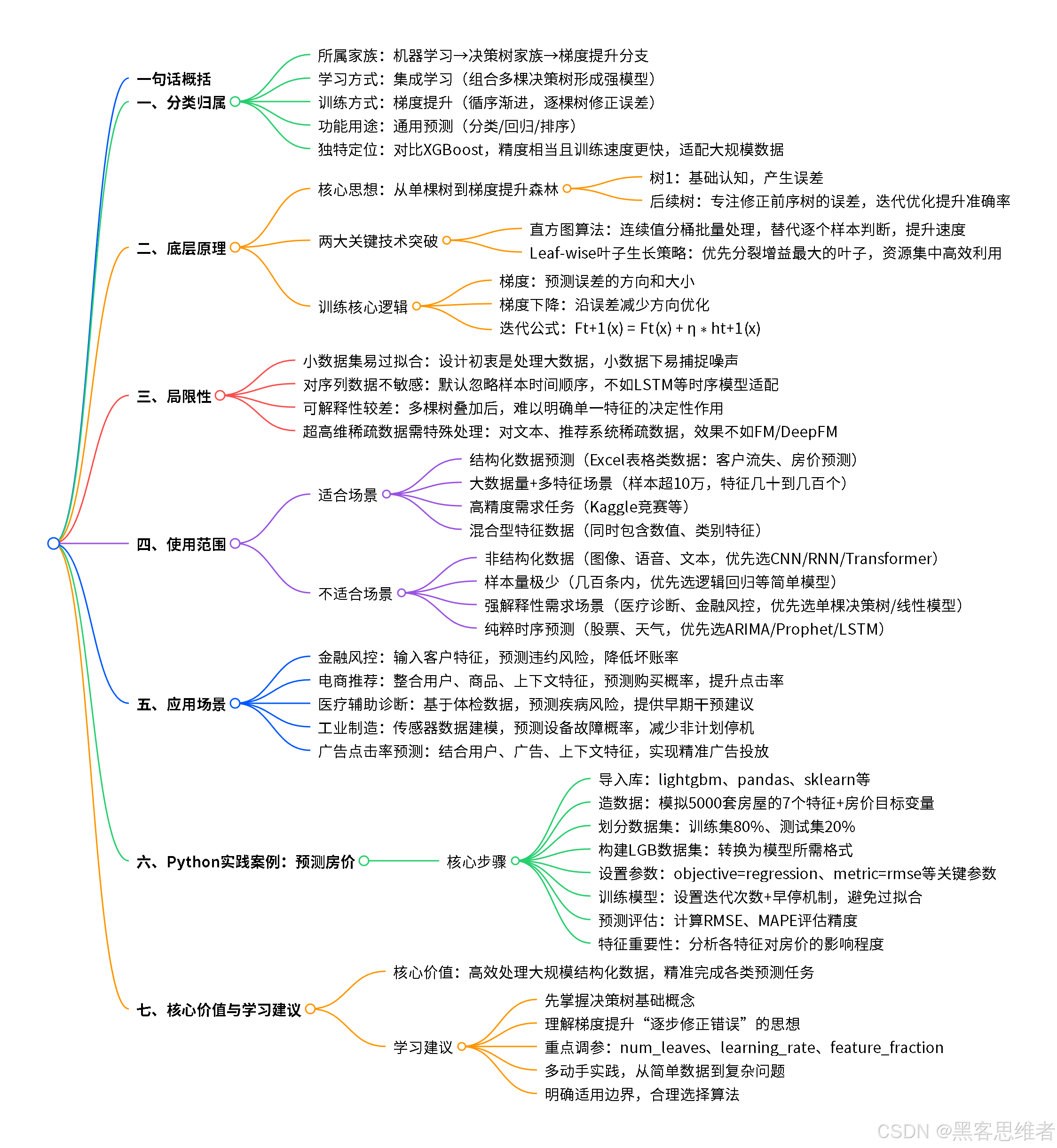
机器学习021:监督学习【分类算法】(LightGBM)-- 一棵让数据“说话”的智慧树
当你要从一堆水果中快速找出最甜的苹果
想象你走进一个水果超市,货架上摆满了各式各样的苹果——有的红、有的青、有的个头大、有的带着斑点。你想找出最甜的那个,但不可能每个都咬一口尝一尝。
这时候,一位经验丰富的水果店员走过来,他教你:“先看颜色,红的通常比青的甜;再看大小,中等大小的往往甜度适中;最后摸表皮,光滑的通常更新鲜。” 这几条简单规则,帮你快速筛选出最可能甜的几个苹果。
LightGBM就像这位经验丰富的“水果专家”,不过它处理的不是苹果,而是各种数据。它能从海量信息中自动学习出最有效的“判断规则”,帮助我们做预测、分类、排序等各种决策。今天,就让我们一步步了解这个强大而高效的工具。
一、分类归属:LightGBM在机器学习大家庭中的位置
LightGBM是谁家的孩子?
在人工智能的大家族里,我们先来认识几位家庭成员:
- 神经网络家族:擅长处理图像、声音等复杂模式,像“视觉专家”和“听觉专家”
- 支持向量机家族:擅长在复杂数据中找到清晰的分界线,像“划线专家”
- 决策树家族:通过一系列“如果…那么…”的规则做决策,像“流程专家”
LightGBM(Light Gradient Boosting Machine)属于“决策树家族”中“梯度提升”这一分支。我们可以这样理解它的身份:
-
按“学习方式”划分:它是“集成学习”型算法
- 不依赖单个模型,而是组合多个简单模型(决策树),形成更强大的团队
- 就像一支足球队——单个球员可能不完美,但合理组合就能赢得比赛
-
按“训练方式”划分:它是“梯度提升”型算法
- 采用“循序渐进”的学习策略:先建一棵树,找到它的不足;再建第二棵树弥补不足;如此反复
- 就像写论文——先写初稿,发现哪里表达不好就修改哪里,一遍遍完善
-
按“功能用途”划分:它是“通用预测”型算法
- 既能做分类(判断邮件是垃圾邮件还是正常邮件)
- 也能做回归(预测明天的气温)
- 还能做排序(给搜索结果按相关性排序)
LightGBM的独特定位
如果说传统的梯度提升算法(如XGBoost)是“认真仔细但稍慢的学生”,那么LightGBM就是“既聪明又高效的学霸”。它在保持高精度的同时,大大提升了训练速度,特别适合处理大规模数据。
二、底层原理:LightGBM如何“思考”和“学习”
核心思想:从“一棵树”到“一片森林”
想象你要教一个完全没见过猫的孩子识别猫。你会怎么做?
传统方法(单棵决策树):
- 先教:“如果有尖耳朵,可能是猫”
- 再教:“如果有长尾巴,可能是猫”
- 继续教:“如果眼睛在脸正面,可能是猫”
但问题来了——狐狸也有尖耳朵,猴子也有长尾巴,有些狗的眼睛也在正面。单靠几条简单规则,很容易出错。
LightGBM的智慧方法(梯度提升森林):
1. 第一棵树(基础认知):
- 规则:如果有尖耳朵 → 可能是猫(但也会把狐狸误认为猫)
- 错误:把狐狸也当成了猫
2. 第二棵树(纠正错误):
- 专注纠正第一棵树的错误
- 新规则:如果脸是圆的(狐狸脸尖)→ 更可能是猫
- 现在能区分猫和狐狸了
3. 第三棵树(继续完善):
- 专注前两棵树还搞错的情况
- 新规则:如果胡须明显 → 更可能是猫
- 现在准确率更高了
...如此反复,树越来越多,判断越来越准
两个关键技术突破
为什么LightGBM比它的前辈们更快更好?主要靠两大“绝技”:
1. 直方图算法:从“逐个检查”到“批量处理”
传统方式:检查每个苹果的甜度
苹果1:甜度7.2 → 放进“较甜”篮子
苹果2:甜度6.8 → 放进“一般”篮子
苹果3:甜度7.5 → 放进“较甜”篮子
...
每个苹果都要单独判断,速度慢
LightGBM方式:先把甜度分区间
甜度6.0-6.5:有15个苹果 → 都算“一般甜”
甜度6.5-7.0:有20个苹果 → 都算“较甜”
甜度7.0-7.5:有10个苹果 → 都算“很甜”
批量处理,速度快得多!
2. 带深度限制的叶子生长策略:从“平均生长”到“重点突破”
想象你要在一片土地上种树,目标是尽快让树荫覆盖最大面积。
传统策略(Level-wise):
第一年:所有树枝都长一层
第二年:所有树枝再长一层
第三年:所有树枝继续长一层
...
公平但效率低,有些树枝其实不需要长那么长
LightGBM策略(Leaf-wise):
第一年:找出最有潜力的主枝,让它先长
第二年:再找出当前最有潜力的分枝,让它长
第三年:继续找最有潜力的地方生长
...
不平均分配资源,而是“好钢用在刀刃上”
训练的核心逻辑:梯度下降与提升
梯度:可以理解为“错误的方向和大小”。就像你蒙眼找山谷最低点,脚下地面的倾斜方向和坡度就是“梯度”。
梯度下降:沿着梯度反方向(即下坡方向)移动,就能找到最低点(最优解)。
LightGBM的学习过程:
第1步:用第一棵树做预测,计算“预测误差”(实际值-预测值)
第2步:分析误差的方向和大小(这就是“梯度”)
第3步:建第二棵树,专门去“预测这些误差”
第4步:把两棵树的预测加起来(第一棵树的预测 + 第二棵树的误差预测)
第5步:重复1-4步,直到误差足够小
用数学公式表示这个过程(了解即可):
假设我们要预测房价:
- 真实房价:yyy
- 第t次预测结果:Ft(x)F_t(x)Ft(x)
- 损失函数(衡量预测误差):L(y,Ft(x))L(y, F_t(x))L(y,Ft(x))
第t+1棵树的目标是:
Ft+1(x)=Ft(x)+η∗ht+1(x) F_{t+1}(x) = F_t(x) + η * h_{t+1}(x) Ft+1(x)=Ft(x)+η∗ht+1(x)
其中:
- ht+1(x)h_{t+1}(x)ht+1(x) 是新树的预测
- ηηη 是学习率(步子大小,避免走过头)
新树的训练目标是拟合“负梯度”:
负梯度=−∂L(y,Ft(x))/∂Ft(x) 负梯度 = - ∂L(y, F_t(x)) / ∂F_t(x) 负梯度=−∂L(y,Ft(x))/∂Ft(x)
三、局限性:LightGBM不是“万能钥匙”
虽然LightGBM强大,但它也有自己的“短板”。理解这些局限,才能更好地使用它。
1. 对小数据集可能“用力过猛”
问题:当数据量很少时(比如只有几百条样本),LightGBM容易“过度学习”
- 就像用高倍显微镜看指纹——连最细微的纹路都当作重要特征
- 结果是:对训练数据记得滚瓜烂熟,但遇到新数据就傻眼
为什么:LightGBM的设计初衷就是处理大数据,它的很多优化(如直方图算法)在数据少时优势不明显,反而容易捕捉到数据中的“噪声”(偶然波动)。
2. 对“序列数据”不够敏感
问题:处理时间序列数据(如股票价格、气温变化)时效果可能不如专门算法
- 就像用菜刀切面包——也能切,但没有面包刀顺手
- LightGBM默认不考虑数据点的“时间顺序”
为什么:LightGBM把每个样本看作独立的,不自动考虑“昨天的数据会影响今天的预测”这种时间依赖关系。虽然可以通过人工构造时间特征来缓解,但不如LSTM等时序模型自然。
3. 可解释性相对较差
问题:当有几百甚至几千棵树时,很难说清“到底是哪个特征起了决定性作用”
- 就像问一个由100位医生组成的会诊团队“病人到底得了什么病”——每位医生都贡献了意见,但很难归功于某一位
- 虽然能给出特征重要性排名,但无法像线性回归那样给出明确的“X变化1单位,Y变化多少”
4. 对“超高维稀疏数据”需要特别处理
问题:处理文本数据(如新闻分类)或推荐系统数据(用户-物品矩阵)时,数据维度可能高达几十万维,但每个样本只有少数几维有值
- 就像在巨大的仓库里找东西——仓库很大(维度高),但你要的东西只放在几个固定位置(数据稀疏)
为什么:虽然LightGBM有针对类别特征的优化,但对于极度稀疏的高维数据,专门的算法(如FM、DeepFM)可能更合适。
四、使用范围:什么时候该请LightGBM“出山”
适合使用LightGBM的场景
-
结构化数据预测任务
- 什么是结构化数据?像Excel表格那样的数据,每列是特征(如年龄、收入),每行是一个样本(如一个客户)
- 例如:预测客户是否会流失、预测房价、信用评分
-
数据量大且特征多
- 样本数超过10万条,特征数几十到几百个
- LightGBM的速度优势在这里大放异彩
-
需要高精度的场景
- 许多数据科学竞赛(如Kaggle)中,LightGBM是夺冠热门
- 当预测准确度是首要目标时
-
混合型特征数据
- 数据中同时包含数值特征(如年龄、价格)和类别特征(如性别、城市)
- LightGBM能自动处理好这种混合情况
不适合使用LightGBM的场景
-
非结构化数据
- 图像、语音、自然语言文本
- 这些更适合用CNN、RNN、Transformer等神经网络
-
样本量极少
- 只有几百甚至几十条数据
- 考虑用简单模型(如逻辑回归)或专门的小样本学习方法
-
需要强解释性的场景
- 医疗诊断、金融风控等需要明确解释“为什么这样预测”的场景
- 决策树(单棵)或线性模型可能更合适
-
纯粹的时序预测
- 股票价格预测、天气预报等
- 虽然可以勉强用,但ARIMA、Prophet、LSTM等专门时序模型通常更好
五、应用场景:LightGBM在生活中的“高光时刻”
1. 金融风控:识别“潜在违约客户”
场景:银行要给客户发放信用卡,需要评估客户的还款风险
LightGBM的作用:
输入特征:年龄、职业、收入、历史信用记录、负债情况等
训练数据:过去10万客户的资料+他们是否违约的记录
学习过程:LightGBM从这些数据中学习出“高风险客户的特征模式”
预测应用:新客户申请时,自动给出风险评分(0-100分)
决策支持:风险高于80分的客户,需要人工审核
实际效果:某银行使用后,坏账率降低了15%,同时审批速度提升了3倍。
2. 电商推荐:为你“猜你喜欢”
场景:你在淘宝浏览商品,平台推荐你可能感兴趣的商品
LightGBM的作用:
输入特征:
- 用户特征:年龄、性别、地理位置、购买力
- 历史行为:浏览记录、收藏记录、购买记录
- 商品特征:类别、价格、销量、评价
- 上下文:时间、节日、促销活动
训练目标:预测用户点击/购买某个商品的概率
实时推荐:对每个用户-商品对计算得分,推荐得分最高的Top-N个商品
实际效果:京东使用LightGBM优化推荐系统后,点击率提升了8.5%。
3. 医疗辅助诊断:预测疾病风险
场景:医院利用患者体检数据预测糖尿病风险
LightGBM的作用:
输入特征:年龄、BMI、血糖、血压、胆固醇、家族病史等
训练数据:5万份历史体检数据+后续3年是否患糖尿病的记录
模型输出:给出未来3年患糖尿病的风险概率
临床应用:高风险患者获得早期干预建议(调整饮食、加强运动)
重要说明:这类模型仅作为辅助工具,最终诊断必须由医生做出。
4. 工业制造:预测设备故障
场景:工厂的大型机械设备需要定期维护,但希望避免“过度维护”和“突发故障”
LightGBM的作用:
数据采集:设备上的传感器实时收集温度、振动、压力等数据
特征工程:计算各种统计量(均值、方差、趋势等)
训练数据:历史正常运行数据 + 故障前几小时的数据
预测目标:未来24小时内发生故障的概率
维护决策:概率超过阈值时,提前安排检修
实际效果:某汽车制造厂使用后,非计划停机时间减少了40%,维护成本降低了25%。
5. 广告点击率预测:让广告投放更精准
场景:在今日头条等资讯平台,预测用户是否会点击某个广告
LightGBM的作用:
输入特征:
- 用户特征:兴趣标签、设备类型、使用时段
- 广告特征:广告主行业、创意类型、文案关键词
- 上下文特征:当前浏览内容、地理位置、网络环境
训练数据:数亿次广告曝光记录及用户是否点击
实时预测:每次广告展示机会,对候选广告排序
商业价值:提高广告主ROI,提升平台收入
6. LightGBM 与 XGBoost 核心对比表
| 对比维度 | XGBoost | LightGBM |
|---|---|---|
| 核心定位 | 梯度提升决策树的经典优化版,兼顾精度与稳定性 | 基于直方图的高效梯度提升树,主打速度与内存优化 |
| 所属流派 | 集成学习 → Boosting → 梯度提升决策树(GBDT) | 集成学习 → Boosting → 梯度提升决策树(GBDT) |
| 决策树生长策略 | 采用 Level-wise 策略:按层生长,所有节点同步分裂,兼顾树的平衡性 | 采用 Leaf-wise 策略:优先分裂增益最大的叶子节点,训练速度更快、精度更高,但易过拟合(需限制 num_leaves) |
| 特征处理方式 | 对特征值预排序+遍历采样找最优分裂点,精度高但计算/内存开销大 | 采用 直方图算法:将连续特征分桶为直方图,减少计算量;支持类别特征自动编码,无需手动one-hot |
| 采样优化 | 支持行采样(bagging_fraction)和列采样(colsample_bytree) | 新增 梯度单边采样(GOSS):保留高梯度样本,随机采样低梯度样本,在减少计算量的同时保证精度 |
| 缺失值处理 | 自动学习缺失值的分裂方向,无需手动填充 | 与XGBoost逻辑类似,且对稀疏数据的处理效率更高 |
| 正则化策略 | 支持 L1/L2 正则、树深度限制、叶子节点权重惩罚,防止过拟合 | 支持 L1/L2 正则、num_leaves 限制、特征采样,正则化手段更轻量 |
| 训练速度 | 中等速度;数据量/特征数增大时,训练时间显著增加 | 远快于XGBoost:直方图+Leaf-wise+GOSS三重优化,大规模数据下优势明显 |
| 内存占用 | 较高:需存储特征预排序结果和梯度信息 | 远低于XGBoost:直方图分桶减少内存消耗,适合内存受限场景 |
| 精度表现 | 中小数据集上精度稳定,是竞赛/工业界的基准模型 | 大数据集上精度与XGBoost持平甚至略高;小数据集易过拟合,需调参控制复杂度 |
| 可解释性 | 支持特征重要性、SHAP值分析,可解释性中等 | 与XGBoost类似,支持特征重要性,但Leaf-wise生长的树结构较难可视化 |
| 适用场景 | 1. 中小规模结构化数据 2. 对稳定性要求高于速度的场景 3. 需要高精度基准模型的竞赛/项目 |
1. 大规模结构化数据(百万级样本/特征) 2. 对训练速度和内存要求高的场景 3. 类别特征多、稀疏数据的业务(如推荐、广告) |
| 局限性 | 1. 大规模数据下训练慢、内存占用高 2. 类别特征需手动编码 |
1. 小数据集易过拟合,需严格限制 num_leaves2. Leaf-wise策略对参数敏感,调参门槛略高 |
| 核心参数 | max_depth(树深度)、learning_rate、n_estimators、subsample |
num_leaves(叶子数)、learning_rate、n_estimators、feature_fraction、bagging_fraction |
总结
- XGBoost:适合追求稳定精度、数据量不大的场景,是梯度提升树的“基准标杆”。
- LightGBM:适合大数据量、对训练效率要求高的场景,是工业界大规模预测任务的“首选工具”。
六、Python实践案例:预测房价
让我们用一个简单的例子,看看如何用Python实现LightGBM。
# 1. 导入必要的库
import lightgbm as lgb
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import warnings
warnings.filterwarnings('ignore')
# 2. 创建示例数据(模拟房价数据)
# 假设我们有5000套房子的信息
np.random.seed(42) # 确保每次运行结果一致
n_samples = 5000
# 生成特征
data = {
'面积_平方米': np.random.normal(100, 30, n_samples), # 平均100平米,标准差30
'房间数': np.random.randint(1, 6, n_samples), # 1-5个房间
'卫生间数': np.random.randint(1, 4, n_samples), # 1-3个卫生间
'建造年份': np.random.randint(1960, 2020, n_samples), # 1960-2019年建造
'到市中心距离_公里': np.random.exponential(5, n_samples), # 平均距离5公里
'是否学区房': np.random.choice([0, 1], n_samples, p=[0.7, 0.3]), # 30%是学区房
'地铁站数量_1公里内': np.random.poisson(1, n_samples) # 平均1个地铁站
}
# 创建DataFrame
df = pd.DataFrame(data)
# 3. 生成房价(目标变量)
# 房价受多种因素影响,我们模拟一个相对真实的公式
base_price = 30000 # 基础单价(元/平米)
# 各因素的影响系数
df['房价_万元'] = (
df['面积_平方米'] * 0.8 + # 面积最重要
df['房间数'] * 10 + # 每个房间值10万
df['卫生间数'] * 5 + # 每个卫生间值5万
(df['建造年份'] - 1960) * 0.5 + # 每年增值0.5万
-df['到市中心距离_公里'] * 3 + # 距离越远越便宜
df['是否学区房'] * 30 + # 学区房加30万
df['地铁站数量_1公里内'] * 8 + # 每个地铁站加8万
np.random.normal(0, 20, n_samples) # 随机噪声
)
# 4. 准备训练数据
# 分离特征和目标
X = df.drop('房价_万元', axis=1)
y = df['房价_万元']
# 划分训练集和测试集(80%训练,20%测试)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(f"训练集大小: {X_train.shape}")
print(f"测试集大小: {X_test.shape}")
print("\n数据预览:")
print(X_train.head())
# 5. 创建LightGBM数据集
# 转换为LightGBM需要的Dataset格式
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)
# 6. 设置模型参数
params = {
'objective': 'regression', # 回归任务
'metric': 'rmse', # 评估指标:均方根误差
'boosting_type': 'gbdt', # 使用梯度提升决策树
'num_leaves': 31, # 每棵树的最大叶子数
'learning_rate': 0.05, # 学习率(步长)
'feature_fraction': 0.9, # 每次迭代使用90%的特征
'bagging_fraction': 0.8, # 每次迭代使用80%的数据
'bagging_freq': 5, # 每5次迭代执行一次bagging
'verbose': 0, # 不输出详细信息
'seed': 42 # 随机种子
}
# 7. 训练模型
print("\n开始训练LightGBM模型...")
model = lgb.train(
params,
train_data,
valid_sets=[test_data], # 在测试集上验证
num_boost_round=100, # 训练100棵树
callbacks=[
lgb.early_stopping(stopping_rounds=10), # 10轮无改善则停止
lgb.log_evaluation(period=10) # 每10轮输出一次日志
]
)
# 8. 模型预测
print("\n进行预测...")
y_pred = model.predict(X_test)
# 9. 评估模型
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
print(f"\n模型性能评估:")
print(f"均方根误差(RMSE): {rmse:.2f} 万元")
# 计算平均绝对百分比误差
mape = np.mean(np.abs((y_test - y_pred) / y_test)) * 100
print(f"平均绝对百分比误差(MAPE): {mape:.2f}%")
# 10. 查看特征重要性
print("\n特征重要性排名:")
importance = pd.DataFrame({
'特征': X.columns,
'重要性': model.feature_importance()
}).sort_values('重要性', ascending=False)
print(importance)
# 11. 可视化特征重要性
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.barh(importance['特征'], importance['重要性'])
plt.xlabel('重要性')
plt.title('LightGBM特征重要性')
plt.gca().invert_yaxis() # 最重要的在上面
plt.tight_layout()
plt.show()
# 12. 模拟实际预测
print("\n模拟实际预测案例:")
sample_idx = 0
sample_house = X_test.iloc[sample_idx:sample_idx+1]
print("房屋特征:")
for feature, value in sample_house.iloc[0].items():
print(f" {feature}: {value}")
actual_price = y_test.iloc[sample_idx]
predicted_price = y_pred[sample_idx]
print(f"\n真实房价: {actual_price:.2f} 万元")
print(f"预测房价: {predicted_price:.2f} 万元")
print(f"预测误差: {abs(actual_price - predicted_price):.2f} 万元")
print(f"误差百分比: {abs((actual_price - predicted_price)/actual_price)*100:.2f}%")
代码解析:
- 数据准备:我们模拟了5000套房屋的7个特征和房价
- 数据划分:80%用于训练,20%用于测试
- 参数设置:关键参数解释:
num_leaves:每棵树的最大叶子数,控制模型复杂度learning_rate:学习步长,小步慢走更稳定feature_fraction:防止过拟合,每次只用部分特征
- 训练过程:100轮训练,有早停机制防止过拟合
- 模型评估:用RMSE和MAPE衡量预测准确性
- 特征重要性:分析哪些特征对房价影响最大
运行这个代码,你会看到:
- 训练过程的日志输出
- 模型在测试集上的表现
- 各特征的重要性排名
- 一个具体的预测案例
总结:LightGBM的核心价值与学习重点
LightGBM就像是机器学习世界里的**“瑞士军刀”**——它不是专门为某一种任务设计的,但在大多数结构化数据预测问题上,它都能交出出色的答卷。
核心价值一句话概括:
LightGBM通过高效组合大量简单决策树,以“从错误中学习”的方式,快速准确地对结构化数据进行预测,是大数据时代预测建模的利器。
给初学者的学习建议:
-
先理解“树”的概念:决策树是LightGBM的基石,就像砖块是房子的基础
-
掌握“梯度提升”思想:理解“逐步修正错误”的学习哲学
-
学会调参:LightGBM的效果很大程度上取决于参数设置,重点掌握:
num_leaves(控制复杂度)learning_rate(控制学习速度)feature_fraction(防止过拟合)
-
实践出真知:多动手跑代码,从简单数据开始,逐步挑战更复杂的问题
-
了解局限:知道什么时候该用LightGBM,什么时候该考虑其他算法
学习LightGBM的旅程就像学习驾驶——开始时可能觉得各种参数和概念很复杂,但一旦掌握,你就能在数据的道路上自由驰骋,解决各种实际问题。记住,最好的学习方式就是:理解原理,动手实践,不断尝试。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 33
33 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)