【经典重建综述】from MVS to 3DGS——计算机到底如何理解我们所处的真实世界?(上篇)
本文翻译自:
A Survey of 3D Reconstruction: The Evolution from Multi-View Geometry to NeRF and 3DGS
作者:Shuai Liu, Mengmeng Yang, Tingyan Xing, Ran Yang
期刊:Sensors(MDPI),2025 年,第 25 卷,第 18 期,文章号 5748
DOI:https://doi.org/10.3390/s25185748
原文版权信息:本文原文发表于 MDPI 期刊,根据 Creative Commons Attribution (CC BY) 许可协议开放获取(Open Access)。
本文为译文,仅供学习与学术交流使用。如需引用或研究,请以原文为准。
本篇综述来自中国地质大学与清华大学,讲述了从mvs到3dgs的理论过程,对于相关的重点工作做了准确的介绍。
对于计算机而言,从最初的单纯用来算数,直到当下的机器学习、人工智能,人类一直在尝试教计算机感知我们的世界,对于3D世界这个话题,从最早的 Structure-from-Motion (SfM) 技术开始,研究者通过多张二维图像估计相机位姿并恢复稀疏三维点云,实现了初步的三维重建;随后,多视图立体 (MVS) 方法在此基础上利用光度一致性等约束生成稠密点云或网格模型,显著提升了几何细节的重建效果。再到近年来,深度学习的发展日渐成熟,Neural Radiance Fields (NeRF) 将场景表示为隐式的神经辐射场,直接学习从任意视角合成高保真图像,大幅提高了新视角合成与三维重建的真实感和灵活性,从而成为 3D 场景表示与渲染的重要里程碑。
abstract
三维(3D)重建技术不仅是计算机视觉与图形学中的核心关键技术,同时也是推动虚拟现实(VR)、增强现实(AR)、自动驾驶以及数字地球等诸多前沿应用蓬勃发展的重要动力。随着神经辐射场(NeRF)和三维高斯溅射(3DGS)等新型视图合成技术的兴起,三维重建正面临前所未有的发展机遇。本文介绍了传统三维重建方法的基本原理,包括运动恢复结构(SfM)和多视图立体(MVS)技术,并分析了这些方法在处理复杂场景和动态环境时的局限性。围绕与 NeRF 相关的隐式三维场景重建技术,本文探讨了利用深度神经网络从有限视角中学习并生成高质量三维场景渲染的优势与挑战。在近年来出现的基于 3DGS 的相关技术原理和特点基础上,本文分析了其在渲染质量、渲染效率、稀疏视图输入支持以及动态三维重建等方面的最新进展与创新。最后,本文深入讨论了当前三维重建技术与新型视图合成技术所面临的主要挑战与机遇,并展望了未来可能的技术突破与发展方向。本文旨在为数字孪生与智慧城市等领域的三维重建技术研究人员提供一个全面的视角,同时为未来技术创新与广泛应用开辟新的思路与路径。
1. Introduction
三维重建技术作为计算机视觉和图形学领域的关键技术之一,致力于将现实世界的物体和场景转化为精细的数字三维模型。随着 VR/AR、自动驾驶、智慧城市以及文化遗产保护等多个领域的快速发展,三维重建技术的应用范围显著拓宽,已成为推动数字化转型和智能化发展的重要力量。通过高精度建模和细致的场景还原,三维重建能够准确再现现实世界中的复杂结构与动态变化,为城市规划、基础设施建设和文物保护等领域提供有力支撑 [1]。
传统三维重建方法在静态场景中取得了重要成果,但随着对动态环境和复杂场景需求的增加,其在计算效率、精度和适应性方面的局限日益突出。例如,在重建大规模复杂场景时,传统方法常面临计算复杂度高和数据采集困难等问题 [2]。为应对这些挑战,近年来三维重建领域在深度学习和新型视图合成技术的推动下取得了显著进展。例如,神经辐射场(NeRF)将隐式表示与深度神经网络相结合,实现了多角度的高质量场景渲染,能够呈现更加真实的细节与光照效果 [3]。另一方面,三维高斯溅射(3DGS)通过显式的高斯基元来表示场景并进行新视图合成,不仅提升了渲染质量(即渲染图像的视觉保真度和细节表现)与效率,还扩展了三维重建技术在动态场景中的应用潜力 [4]。然而,尽管这些新兴技术在部分领域取得了突破,三维重建在实时渲染、动态场景处理以及高效数据管理方面仍面临诸多挑战。因此,未来研究不仅需要攻克这些技术瓶颈,还需进一步融合深度学习与传统几何方法,以增强三维重建技术在复杂环境下的适应性和实用性 [5]。
在此背景下,近年来已有多篇综述性文章对三维重建进行了系统总结,但其研究视角各有不同。一些综述全面回顾了基于传统几何的三维重建技术 [1],主要聚焦于运动恢复结构(SfM)与多视图立体(MVS)的原理、流程和优化策略。这类研究强调几何精度、重建稳定性及静态场景的适用性,但对深度学习方法与隐式表示技术的覆盖不足,且缺乏复杂与动态场景的讨论。另一些研究则聚焦于基于神经辐射场(NeRF)的隐式表示方法,系统性地总结了其理论基础、网络设计以及多视图渲染质量 [6,7],突出了其在细节恢复和光照处理方面的优势,同时也指出其高训练开销、对稀疏视角数据的敏感性以及对动态场景适应性不足的问题。然而,这类综述多集中于隐式表示方法本身,较少与传统 SfM/MVS 或新兴的显式方法(如 3DGS)进行对比,因而缺乏跨代际的技术分析。还有部分研究聚焦于基于深度学习的三维重建整体发展 [8],涵盖卷积神经网络、图神经网络以及自监督学习,系统总结了模型设计和训练策略,但对渲染质量与计算效率的讨论相对有限。也有研究专注于 3DGS 的最新进展 [9],分析了高斯基元表示、稀疏视角合成与渲染效率优化,但未能充分将其与传统几何方法和 NeRF 方法进行对照,亦缺乏对动态或大规模场景重建的深入分析。
【1】Zhou, L.; Wu, G.; Zuo, Y.; Chen, X.; Hu, H. A comprehensive review of vision-based 3d reconstruction methods. Sensors 2024,
24, 2314.
【6】Gao, K.; Gao, Y.; He, H.; Lu, D.; Xu, L.; Li, J. Nerf: Neural radiance field in 3d vision. a comprehensive review 2022. arXiv 2022,
arXiv:2210.00379.
【7】Rabby, A.K.M.; Zhang, C. Beyondpixels: A comprehensive review of the evolution of neural radiance fields. arXiv 2023,
arXiv:2306.03000.
【8】Bai, Y.; Wong, L.; Twan, T. Survey on Fundamental Deep Learning 3D Reconstruction Techniques. arXiv 2024, arXiv:2407.08137.
【9】Xu, Z.; Chen, G.; Li, F.; Chen, L.; Cheng, Y. A survey on surface reconstruction based on 3D Gaussian splatting. PeerJ Comput. Sci.
2025, 11, e3034.综上所述,虽然现有综述性文章在各自聚焦的研究领域具备一定的系统性与深度,但仍存在显著局限。主要表现为大多数综述聚焦于单一方法类别,缺乏跨代际比较,因而未能全面呈现传统几何方法、隐式表示方法与新兴显式方法之间的技术演进关系。此外,对渲染质量、计算效率、稀疏视角支持以及动态场景适应性等关键指标的多维分析仍显不足,对未来发展趋势和潜在研究挑战的探讨也相对有限。
为弥补这些不足,本文提出跨代际、多维度的综述视角,其创新性主要体现在以下三个方面:
- 技术演进的系统性回顾:本文从传统的运动恢复结构(SfM) [10–16] 与多视图立体(MVS) [17–21] 方法入手,梳理其发展历程,并进一步总结了基于神经辐射场(NeRF)与三维高斯溅射(3DGS)的新兴方法,展现了从显式几何建模到隐式深度表示的跨代际技术演进。
- 多维度的比较分析:从渲染质量、计算效率、稀疏视角支持能力以及动态场景重建等关键维度出发,本文对不同方法进行了全面比较,揭示其各自优势与不足,为研究人员理解技术特性与方法选择提供参考。
- 挑战与未来方向的识别:在系统综述与比较分析的基础上,本文总结了三维重建在实时渲染、动态场景处理及高效数据管理方面的主要挑战,并探讨了潜在的研究突破与未来发展方向,旨在为后续研究提供系统性指导,推动该领域的技术进步与实际应用。
2. Traditional 3D Reconstruction Techniques
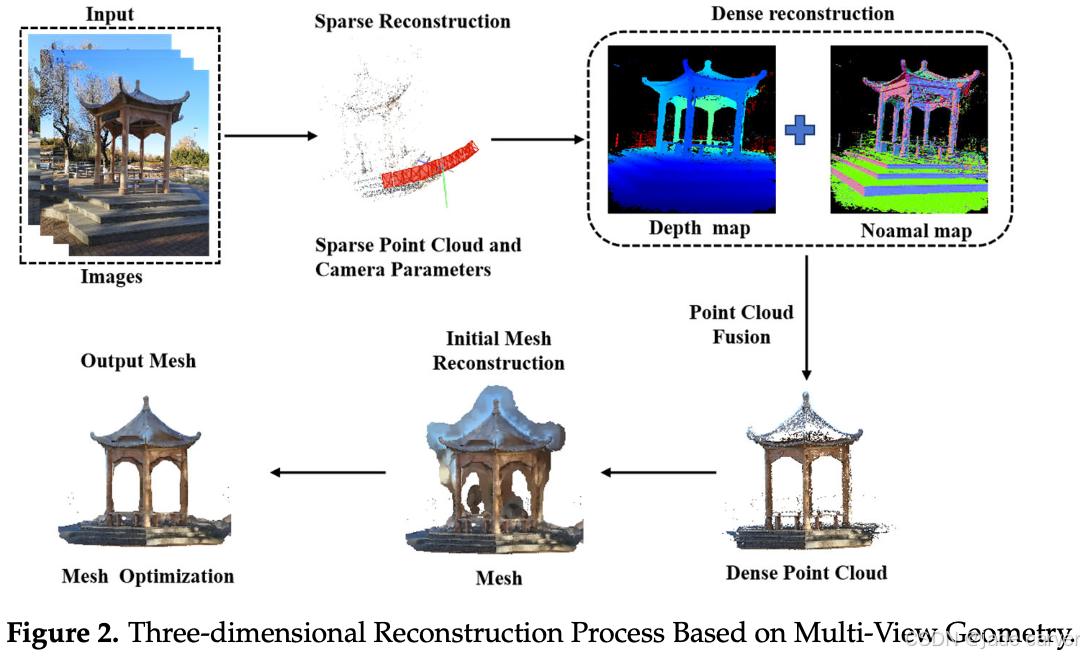
基于多视图几何理论的传统三维重建方法具有直观可视化、结构表达清晰以及兼容性强等显著优势。经典算法如 SfM(Structure from Motion,运动恢复结构),通过匹配图像之间的特征点并结合几何原理,生成稀疏点云并精确估计相机位姿。在此基础上,MVS(Multi-View Stereo,多视图立体) 技术利用多视图几何进一步进行稠密匹配,从而计算稠密点云,并采用如 泊松表面重建(Poisson Surface Reconstruction) [22] 或 Delaunay 三角剖分 [23,24] 等先进算法生成精确的网格模型。
在该多视图几何框架下,常用的特征匹配算法包括 SIFT(尺度不变特征变换) [25]、SURF(加速稳健特征)[26] 和 ORB(定向 FAST 与旋转 BRIEF) [27]。这些方法能够有效地从图像中提取稳定的特征点,为三维重建提供可靠的基础。
然而,早期的三维重建算法通常依赖于预先标定好的相机或沿特定轨迹的运动,这限制了其适用性,使得它们只能在静态和已知环境中实现有效重建。基于多视图几何的三维重建过程如图 2 所示。

随着三维重建技术的不断发展,尤其是在 20 世纪 90 年代至 21 世纪初,基于射影几何的层次化重建理论显著增强了算法的鲁棒性。通过一个从射影空间到仿射空间,再到欧几里得空间的计算框架,该理论有效减少了未知变量的数量,使重建过程具备更清晰的几何意义。这一突破为现代三维重建技术的进一步发展奠定了坚实的理论基础。
近年来,随着技术的进一步进步,三维重建领域涌现出许多创新成果。例如,Hartley 等人 [28] 对多视图几何理论进行了深入研究,其提出的算法已被广泛应用于计算机视觉和机器人学。Moons 等人 [29] 提出了一种基于多张图像进行物体表面形状估计与视点参数求解的方法,进一步丰富了多视图几何理论体系。此外,[30] 提出了一种新型多视图立体(MVS)算法,能够智能选择匹配图像,为高效处理社区照片集中的三维重建提供了有效解决方案。Li 等人 [31] 基于标志性场景图提出了一种新的地标图像建模与识别方法,为地标识别领域开辟了新方向。在大规模三维重建应用背景下,Zhu 等人 [32] 提出了一种基于分布式运动平均的全局 SfM 方法。通过构建分布式处理框架并引入数据融合技术,该方法显著提升了三维重建的效率和精度,特别适合处理超大规模数据集。
【30】Goesele, M.; Snavely, N.; Curless, B.; Hoppe, H.; Seitz, S.M. Multi-view stereo for community photo collections. In Proceedings of
the 2007 IEEE 11th International Conference on Computer Vision (ICCV 2007), Rio de Janeiro, Brazil, 14–21 October 2007; IEEE:
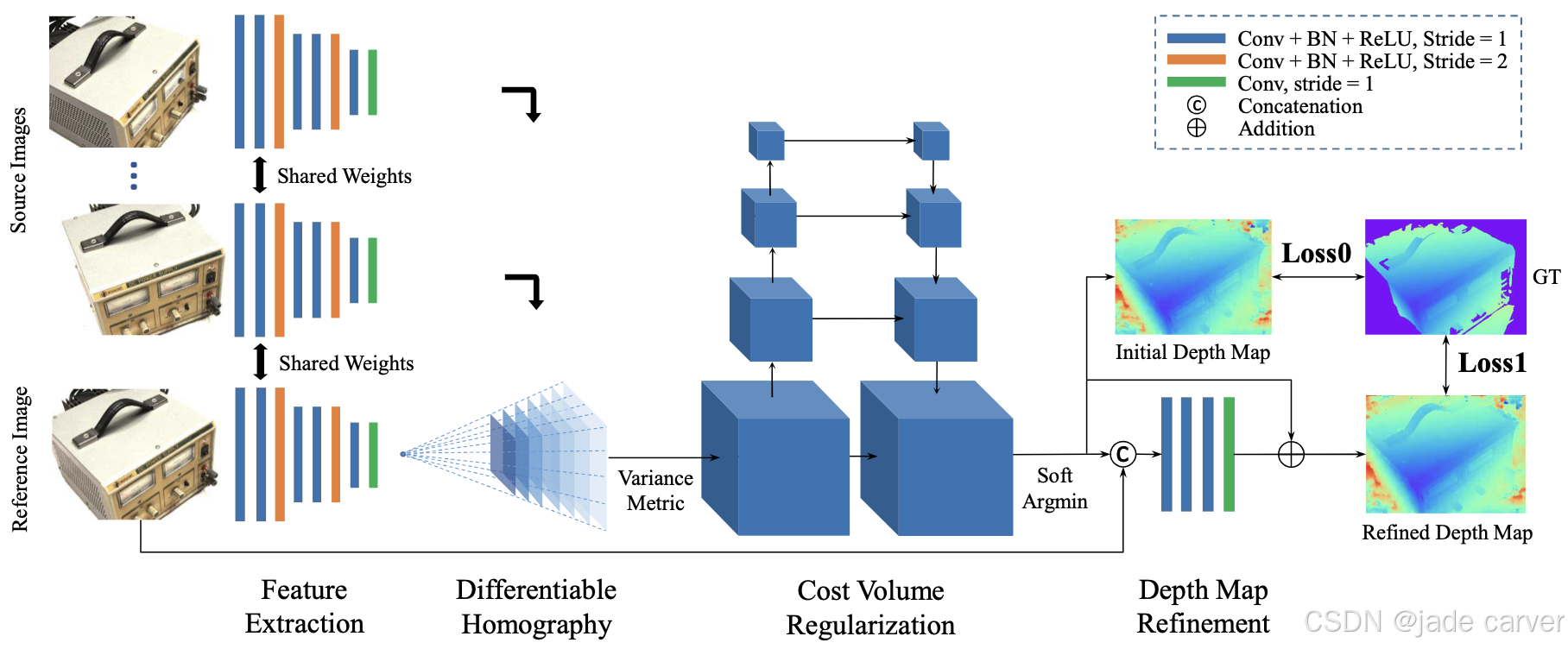
New York, NY, USA, 2007; pp. 1–8.随着深度学习技术的不断发展,越来越多的研究致力于将其应用于传统三维重建方法,以提升特征提取与匹配的准确性,以及整体重建效率。其中,MVSNet [33] 首次提出了一种端到端的深度学习 MVS 框架,可以直接从无序多视图图像回归稠密深度图,从而恢复场景的三维结构。Fast-MVSNet [34] 提出了稀疏到稠密的 MVS 框架,利用轻量级网络从图像对中估计初始稀疏深度点,避免构建完整的代价体(cost volume),显著降低了计算复杂度。通过结合学习引导的深度传播与高斯–牛顿优化,进一步提高了重建的效率与稳定性。与 MVSNet 固定深度采样策略不同,Wang 等人 [35] 提出了迭代动态代价体机制,该机制在每次迭代中根据当前深度估计动态调整采样范围,有效降低了计算开销并提高了重建精度。
迄今为止,传统三维重建方法已发展得相当成熟,尤其是 倾斜摄影网格模型 [36],在过去十余年已被广泛应用于数字孪生、城市建模和 GIS 系统等主流技术。然而,随着对实时渲染、动态场景支持和精细化表达的需求不断增加,传统三维建模逐渐暴露出明显的局限性,主要包括:
- 效率低:依赖大量高重叠度图像和复杂的空间加密处理,生成周期长、硬件门槛高,难以高效建模大规模场景;
- 编辑与维护成本高:模型修改需要手动操作顶点或重新映射,繁琐低效;
- 复杂结构与弱纹理区域表达能力弱:如电线杆、楼梯、玻璃等复杂或缺乏纹理的区域难以还原,容易产生伪影或细节丢失;
- 光照适应性差:模型纹理高度依赖拍摄时的光照条件,不同光照环境下会出现亮度不一致,需要额外调整材质参数;
- 动态变化不足:生成的模型是静态的,面对动态物体或场景更新(如行人、车辆、施工)时需要重新采集数据,难以满足实时性要求。
┌──────────────┐
│传统三维重建方法│
└──────┬───────┘
│
┌─────────────┬──────────┼───────────┬─────────────┐
│ │ │ │ │
效率低 编辑成本高 结构表达差 光照适应差 动态不足
3. Three-Dimensional Reconstruction Based on NeRF
随着深度学习和神经网络的发展,NeRF [3] 因其高保真重建能力和空间连续性表达,在三维重建领域受到越来越多的关注。它通过神经网络隐式表达场景的几何和光照特征,并利用体渲染合成新视角下的图像,而无需显式生成三维点云或网格结构。与传统方法相比,这类渲染模型在真实光照效果和精细纹理方面表现得更加突出,尤其适合复杂场景的重建。连续函数对场景的表示使得它在任意视角下渲染时能够保持场景的连续性,从而避免了传统方法中的视角跳变问题。
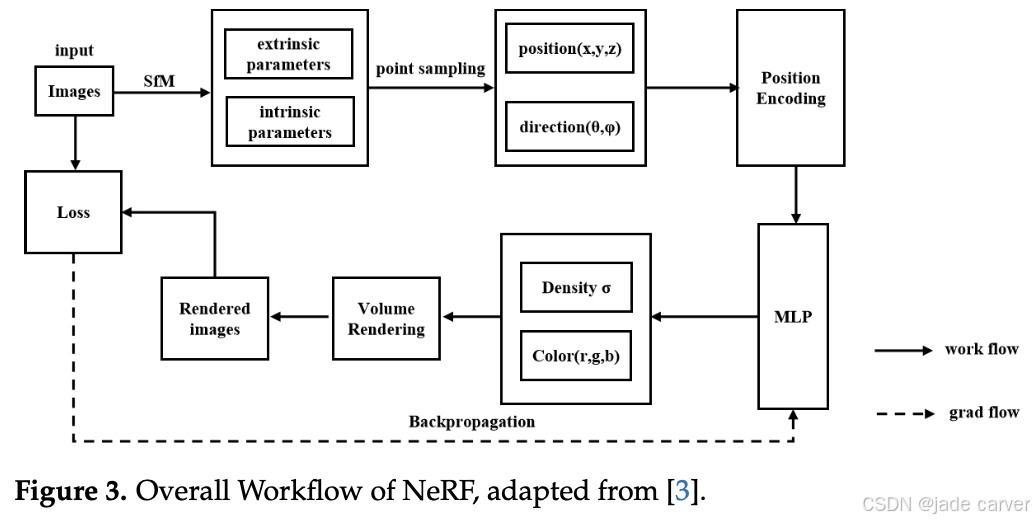
3.1. NeRF Framework
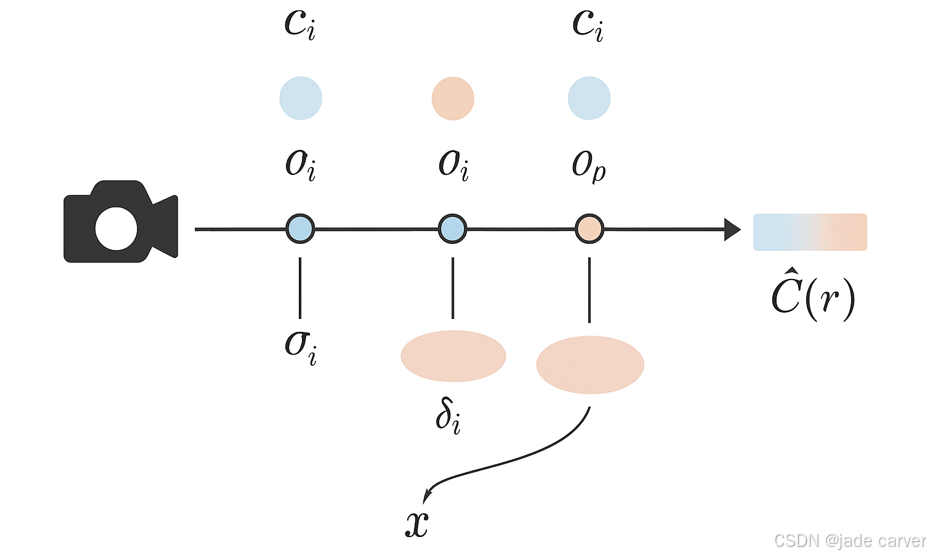
NeRF 依赖二维(2D)图像进行监督,将场景建模为一个连续的五维函数(空间坐标 x,y,z 和视角方向 θ,ϕ),并使用多层感知机(MLP)网络来表示。它通过体渲染技术从新的视角合成图像,避免了传统复杂物理模型的使用,能够逼真地再现复杂的三维场景。其处理流程如图 3 所示。
使用的Mildenhall et al. [3] 的体渲染公式为

可以把每个点看作半透明的“雾气颗粒”,它既能阻挡一部分光(由 σ 控制),也能发出颜色光(由 c 给出)。渲染结果就是把所有这些点的颜色按“光线还能穿过多少(Ti)”加权累积。
NeRF 研究主要集中在四个方向:
- 提升渲染效率:让 NeRF 可以接近实时运行(比如通过稀疏体素网格、哈希编码等方法)。
- 少视角合成优化:在数据有限的情况下(比如只有少量照片),依然能生成高质量的新视角图像。
- 渲染质量提升:改进纹理细节、减少模糊或伪影,让图像更接近真实照片。
- 动态场景优化:从只支持静态场景,扩展到能建模时间变化和运动物体,应用于视频生成、VR/AR 等动态环境。
3.2. Rendering Quality Enhancement
渲染质量是三维重建的核心关键之一,提升 NeRF 的渲染质量也逐渐成为研究热点。近年来,学界提出了大量创新方法,旨在不仅增强生成图像的真实感与细节,还在多个维度上展开探索,包括:优化模型训练流程、改进网络结构、提升特征表达能力,以及改进光照建模,以应对场景中常见的光照不均、混叠、伪影、遮挡和运动模糊等问题。同时,研究者还引入了自监督学习与多视图一致性策略,以减少对大量标注数据的依赖,并增强在复杂场景下的泛化能力。
为解决高频细节处的混叠与失真问题,Mip-NeRF [41] 提出了一种创新的积分位置编码(IPE),并将 NeRF 中的单条射线替换为一个圆锥体(或棱台),使得采样过程中能够引入更多领域信息。这一方法有效缓解了传统 NeRF 因采样不足而产生的混叠问题,同时保留了较精细的渲染细节。
然而,Mip-NeRF 并未充分考虑光照变化和图像模糊等因素,且其计算代价明显更高,训练时间也随之大幅增加。图 4 展示了 NeRF 与 Mip-NeRF 的对比效果。
【41】Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-nerf: A multiscale representation for
anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC,
Canada, 11–17 October 2021; pp. 5855–5864.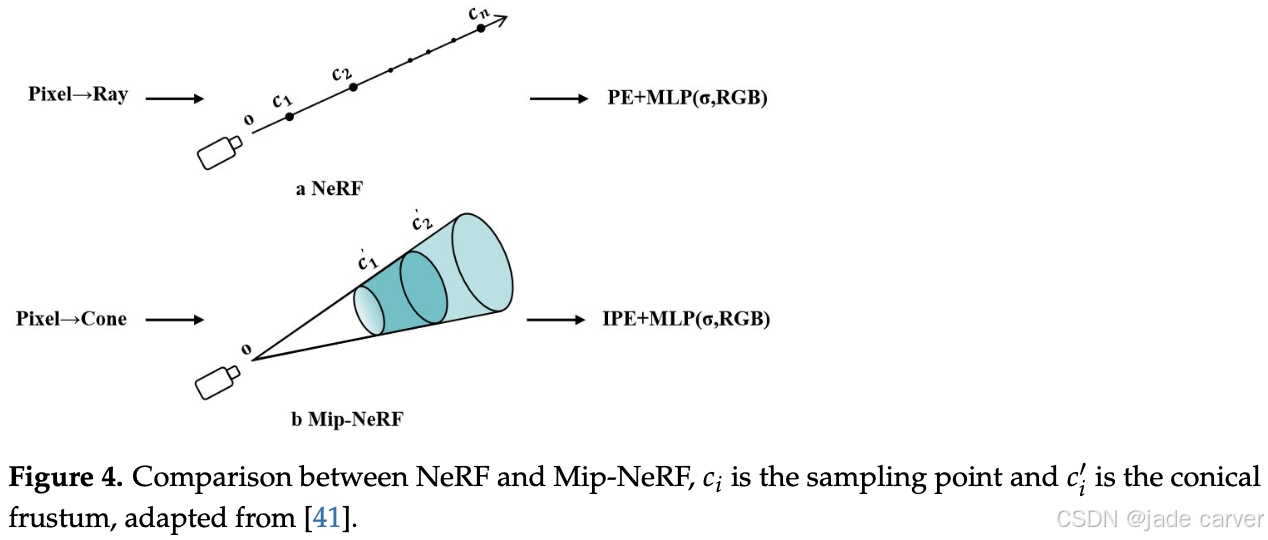
一些研究 [42,43] 针对光照与相机曝光对辐射场的影响进行了深入探索。其中,NeRF-W 首次引入可变光照模型,在训练时将外观编码融入多层感知机(MLP),使模型能够适应不同光照条件下的场景,大幅提升了渲染结果的真实感与一致性。但由于新视角下的外观编码存在不确定性,往往需要人工设定合理的取值;此外,NeRF-W 在应对复杂光照场景时仍然受限。为此,NeRF++ 提出了一种替代方案。它采用前景与背景的双场景表示方式,减少背景对光照的干扰,从而在不同光照条件下实现一致的渲染效果。同时,NeRF++ 可以动态建模光照,更自然地模拟光源位置和强度的变化。
【42】Martin-Brualla, R.; Radwan, N.; Sajjadi, M.S.M.; Barron, J.T.; Dosovitskiy, A.; Duckworth, D. Nerf in the wild: Neural radiance
fields for unconstrained photo collections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition(CVPR 2021), Virtual, 19–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 7210–7219.
【43】Zhang, K.; Riegler, G.; Snavely, N.; Koltun, V. Nerf++: Analyzing and improving neural radiance fields. arXiv 2020,
arXiv:2010.07492.除了光照影响,退化图像(如高斯噪声污染或各向异性模糊)也是影响 NeRF 渲染质量的重要因素。NeRFLiX [44] 在这方面带来了改进。该方法采用退化驱动的视角混合方式,并提出 NeRF 风格的退化模拟器(NDS),同时构建大规模模拟数据集,从而显著增强了模型的灵活性。它能够有效消除 NeRF 的伪影并恢复细节,大幅提升了高阶 NeRF 模型的表现。
【44】Zhou, K.; Li, W.; Wang, Y.; Hu, T.; Jiang, N.; Han, X.; Lu, J. Nerflix: High-quality neural view synthesis by learning a degradation-
driven inter-viewpoint mixer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR
2023), Vancouver, BC, Canada, 18–22 June 2023; IEEE: New York, NY, USA, 2023; pp. 12363–12374.针对运动模糊问题,Wang 等人 [45] 提出了 BAD-NeRF。该模型引入光度约束调整公式,并利用虚拟视角的均值来模拟运动模糊的物理成像过程。通过持续优化合成图像与真实模糊图像之间的差异,它能精确恢复相机位姿。实验表明,该方法在严重运动模糊和相机位姿不准的情况下依然具备很强的鲁棒性。
【45】Wang, P.; Zhao, L.; Ma, R.; Liu, P. Bad-nerf: Bundle adjusted deblur neural radiance fields. In Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recognition (CVPR 2023), Vancouver, BC, Canada, 18–22 June 2023; IEEE: New York,
NY, USA, 2023; pp. 4170–4179.不同于上述方法主要改进隐式场景表示的思路,UHDNeRF [46] 则提出了一种创新的新视角合成框架,巧妙融合了显式与隐式的优点。在这一框架下,隐式体积用于重建场景的低频特征(如整体结构和轮廓),而高频细节则通过稀疏点云精确捕捉,从而保证了细节的完整性与准确性。
【46】Li, Q.; Li, F.; Guo, J.; Guo, Y. Uhdnerf: Ultra-high-definition neural radiance fields. In Proceedings of the IEEE/CVF International
Conference on Computer Vision (ICCV 2023), Paris, France, 1–6 October 2023; IEEE: New York, NY, USA, 2023; pp. 23097–23108.| 类别 | 方法 | 技术手段 | 优点 / 特点 |
|---|---|---|---|
| 光照问题 | NeRF-W | 引入可变光照模型 + 外观编码 | 渲染结果更真实,但新视角下外观编码需要人工干预 |
| 光照问题 | NeRF++ | 前景/背景双表示;动态建模光源变化 | 降低光照干扰 |
| 退化图像问题 | NeRFLiX | 退化驱动视角混合机制 + NeRF风格退化模拟器(NDS);大规模模拟数据集 | 消除噪声/伪影,恢复细节 |
| 运动模糊问题 | BAD-NeRF | 虚拟视角均值模拟运动模糊;光度约束公式优化 | 在严重模糊和位姿误差下依旧鲁棒 |
| 显式 + 隐式结合 | UHDNeRF | 隐式体积捕捉低频结构;稀疏点云捕捉高频细节 | 实现“结构稳定 + 细节完整” |
综上所述,Mip-NeRF 创新地采用了圆锥体积来替代传统的光线追踪方法,从而有效减少了混叠伪影。NeRF-W 和 NeRF++ 在处理光照问题上也取得了显著改进,使复杂光照条件下的渲染效果更为逼真。NeRFLiX 和 BAD-NeRF 则专注于解决由图像退化和运动模糊引起的伪影,从而提升整体渲染质量。此外,UHDNeRF 将点云技术引入现有的隐式表示方法,以捕捉高频细节,大幅增强渲染效果。尽管这些方法在提升渲染质量上取得了突破,但也带来了计算时间增加和模型体积增大的问题。因此,研究者面临的核心挑战是如何在保证渲染效率的同时进一步提升渲染质量。

3.3. Rendering Efficiency Optimization
在三维重建领域,计算效率一直是研究的关键方向,因为它直接关系到技术能否在各行各业中得到实际应用。为了提升 NeRF 的渲染效率,研究者从多个角度提出了各种创新策略,且这些策略在众多研究中表现出相似特征和发展趋势。
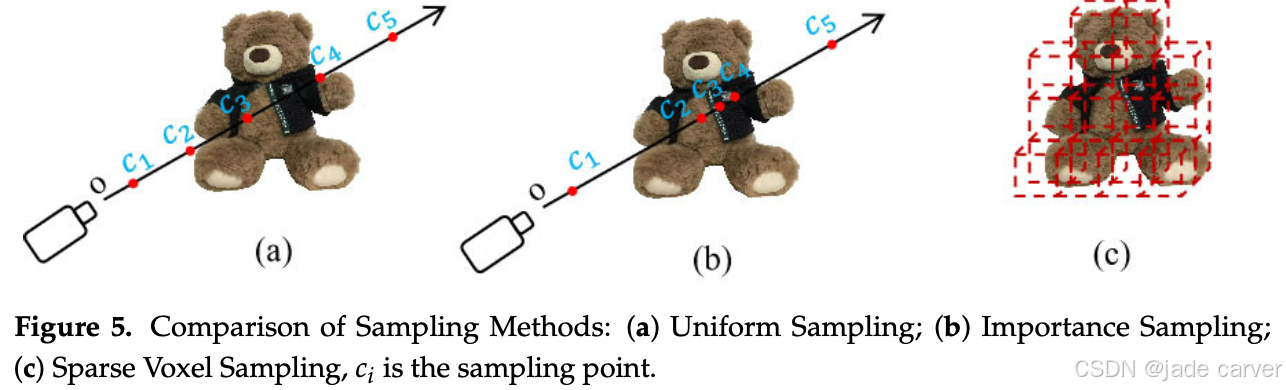
一方面,优化数据结构和减少冗余存储是提高渲染效率的重要手段。神经稀疏体素场(NSVF)[47] 通过稀疏体素划分和体素八叉树结构,有效降低了模型的内存占用,同时在渲染过程中跳过空体素,从而显著加快了绘制速度。这类方法通过更高效的数据表示来减轻计算负担。图5展示了不同采样方法的对比。在此基础上,研究者还引入了多分辨率哈希编码和张量分解技术,以进一步提升 NeRF 的渲染速度(即每帧生成所需的时间)。InstantNGP [48] 利用多分辨率哈希编码和定制化优化策略,将场景特征存储在哈希表中,而不完全依赖多层感知机(MLP)权重,从而大幅加快训练速度。同时,TensoRF [49] 使用张量分解技术,将场景辐射场表示为紧凑的低秩张量,进一步降低存储和计算开销。这些方法在算法层面的优化共同推动了渲染速度的提升。
【47】Liu, L.; Gu, J.; Lin, K.Z.; Chua, T.-S.; Theobalt, C. Neural sparse voxel fields. Adv. Neural Inf. Process. Syst. 2020, 33, 15651–15663.
【48】Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans.
Graph. 2022, 41, 102. [CrossRef]
【49】Chen, A.; Xu, Z.; Geiger, A.; Yu, J.; Su, H. Tensorf: Tensorial radiance fields. In European Conference On Computer Vision; Springer:
Cham, Switzerland, 2022; pp. 333–350.此外,递归渲染方法、模型压缩和自适应采样等技术对于提升 NeRF 的渲染效率也起到关键作用。Recursive-NeRF [50] 采用递归渲染策略,在达到所需画质时提前终止计算,从而有效减少不必要的网络参数。Zip-NeRF [51] 则通过模型压缩和自适应采样优化特征计算,同时缓解空间混叠和深度混叠问题。这类方法通过更智能的渲染策略降低计算负担,进一步提升渲染效率。
【50】Yang, G.-W.; Zhou, W.-Y.; Peng, H.-Y.; Liang, D.; Mu, T.-J.; Hu, S.-M. Recursive-nerf: An efficient and dynamically growing nerf.
IEEE Trans. Vis. Comput. Graph. 2022, 29, 5124–5136. [CrossRef]
【51】Barron, J.T.; Mildenhall, B.; Verbin, D.; Srinivasan, P.P.; Hedman, P. Zip-nerf: Anti-aliased grid-based neural radiance fields. In
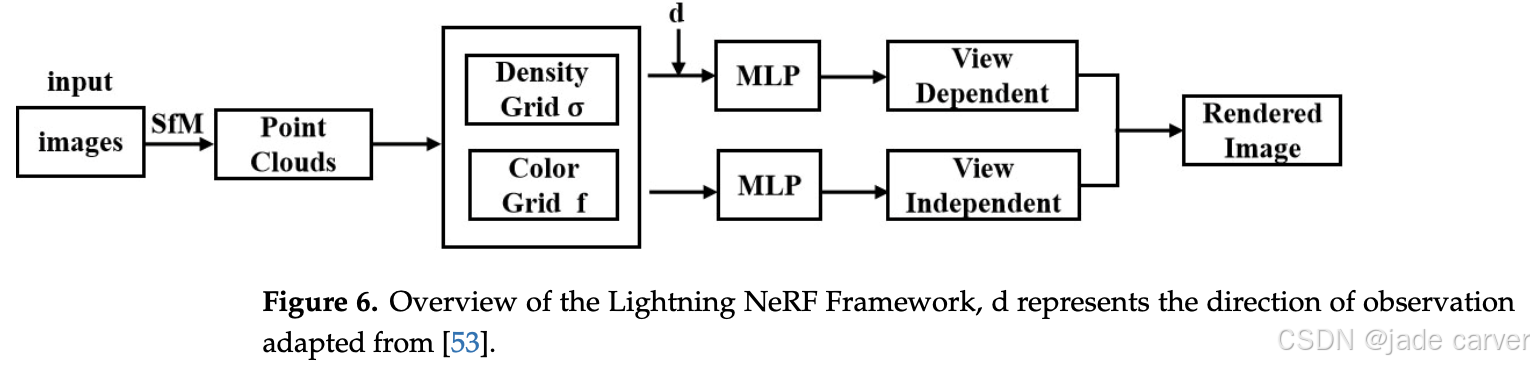
Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 19697–19705.在其他研究中,研究者致力于将各种先进采样方法整合到 NeRF 算法中以优化渲染过程。例如,Li 等开发了功能强大的 Python 工具包 NerfAcc(v0.3.5,运行于 Python 3.10)[52],它提供灵活的 API,可整合多种采样方法,并通过透射率估计器优化渲染流程。Lightning NeRF [53] 将点云方法与图像方法结合,利用点云快速初始化密度并优化背景建模,从而提升处理速度和渲染性能。通过整合和优化多种技术手段,这些方法实现了渲染效率的全面提升。Lightning NeRF 框架概览见图6。
【52】Li, R.; Gao, H.; Tancik, M.; Kanazawa, A. Nerfacc: Efficient sampling accelerates nerfs. In Proceedings of the IEEE/CVF
International Conference on Computer Vision (ICCV 2023), Paris, France, 1–6 October 2023; IEEE: New York, NY, USA, 2023;
pp. 18537–18546.
【53】Cao, J.; Li, Z.; Wang, N.; Ma, C. Lightning nerf: Efficient hybrid scene representation for autonomous driving. In Proceedings of
the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; IEEE: New York,
NY, USA, 2024; pp. 16803–16809.| 算法 | 优化方法 | 技术创新 | 优化效果 |
|---|---|---|---|
| NSVF [47] | 稀疏体素划分 + 八叉树结构 + 高效光线追踪 | 利用稀疏体素和八叉树跳过空体素 | 内存消耗大幅降低,推理速度提升 >10×,渲染质量提升 |
| InstantNGP [48] | 多分辨率哈希编码 + CUDA 并行优化 | 将场景特征存储在哈希表中,充分利用 GPU 并行计算 | 内存占用减少,训练时间从数小时缩短到几分钟甚至秒级 |
| TensoRF [49] | 张量分解(向量-矩阵分解) | 将场景表示为紧凑低秩张量 | 渲染内存占用降低,训练时间显著减少 |
| Recursive-NeRF [50] | 递归分层渲染 + 多阶段动态增长 | 分层处理场景信息,动态调整网络结构 | 减少冗余网络参数,提高合成效率,同时改善渲染质量 |
| Zip-NeRF [51] | 数据压缩 + 多层特征表示 | 高效特征计算 + 自适应采样 | 内存占用降低,同时提升计算效率并保留细节 |
| NerfAcc [52] | 多采样方法整合 + 透射率估计器优化 | 提供灵活 API,实现采样优化 | 渲染速度提升 1.5–20 倍,渲染质量也有所提高 |
| Lightning NeRF [53] | 点云 + 图像方法结合 | 利用点云快速初始化密度,优化背景建模 | 训练速度提升 5 倍,渲染速度提升 10 倍,视角合成质量显著增强 |
3.4. Sparse View Synthesis
近年来,研究者提出了多种创新方法来应对稀疏视角输入下的新视角合成问题,旨在从有限视角有效重建场景细节和深度信息。这些研究不仅关注提升渲染质量,同时也注重模型的泛化能力,确保在不同场景和条件下仍能生成高质量的合成图像。
FreeNeRF [54] 针对稀疏采样神经渲染的关键问题提出了两大策略:频率正则化和遮挡正则化。这两种正则化方法无需额外计算资源或外部监督,能够有效抑制过拟合,并减少摄像机附近密度场可能产生的视觉伪影,从而显著提升新视角图像合成质量。
【54】Yang, J.; Pavone, M.; Wang, Y. Freenerf: Improving few-shot neural rendering with free frequency regularization. In Proceedings
of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023), Vancouver, BC, Canada, 18–22 June
2023; IEEE: New York, NY, USA, 2023; pp. 8254–8263.同时,Seunghyeon Seo 团队在三维场景重建和视角合成方面取得了突破性进展,提出了 FlipNeRF [55] 和 MixNeRF [56] 两种方法。
- FlipNeRF:通过引入翻转反射光线来过滤无效光线,精确重建表面法线,从而显著降低漂浮伪影。结合不确定性感知空洞损失和瓶颈特征一致性损失,在有限视角输入下实现高质量的新视角合成,大幅提升少样本场景重建的准确性和鲁棒性。
- MixNeRF:通过联合估计颜色分布与混合密度,有效学习三维几何结构。利用射线深度估计获取几何高度,并通过混合权重增强模型鲁棒性,确保在稀疏输入下实现更准确的场景重建和更高质量的图像合成。
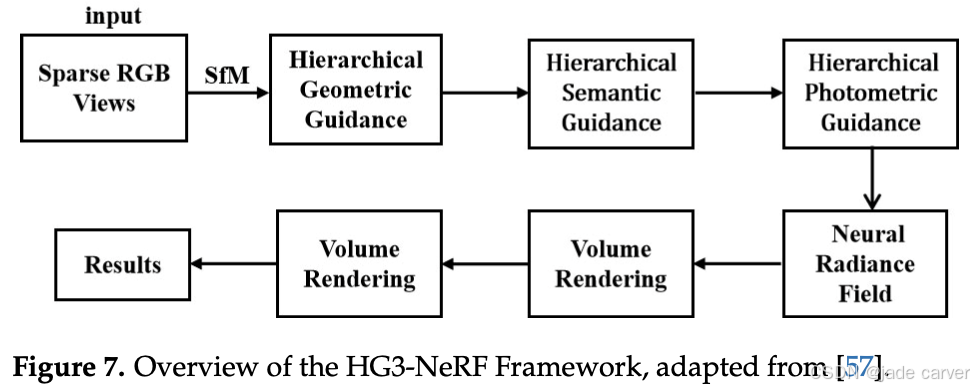
此外,HG3-NeRF [57] 旨在提升不同视角之间的几何形状、语义内容和外观的一致性,同时缓解 NeRF 在稀疏视角输入下性能下降的问题。它结合了三种关键技术:分层几何引导、分层语义引导和光度引导,在稀疏视角条件下实现高质量的三维场景重建与视角合成,显著增强模型的适应性与鲁棒性。HG3-NeRF 框架概览见图7。
这些创新方法与技术的发展不仅推动了稀疏视角合成与三维重建的进步,同时也为未来的计算机视觉与虚拟现实应用提供了更有力的支持,拓展了在各种真实场景中的应用前景。
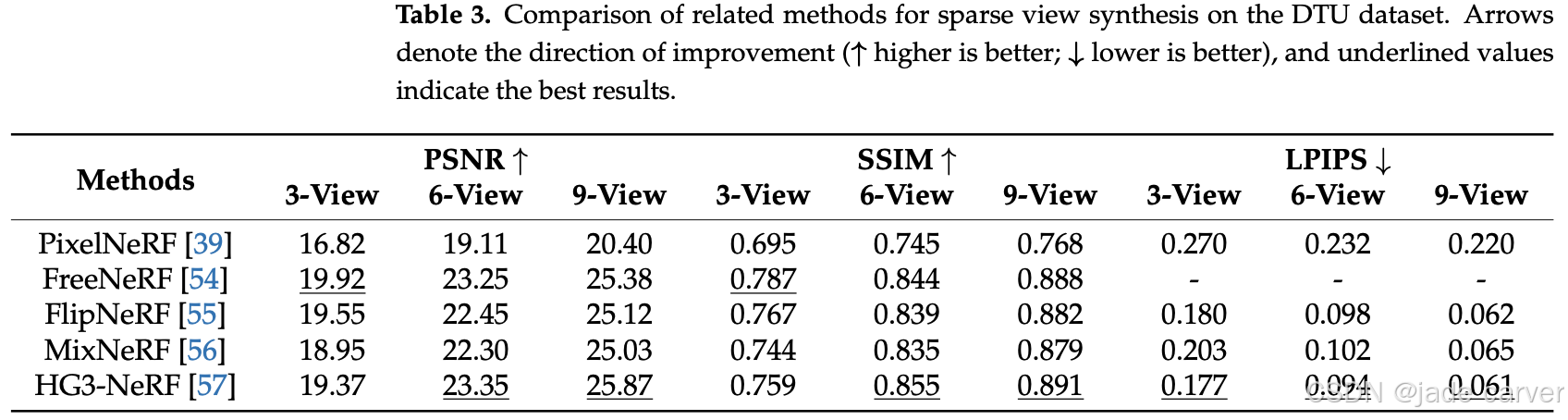
表 3 总结了上述方法在 DTU 数据集上的评估指标,相关数据来自部分原始论文。
| 方法 | 核心技术 | 优点 | 局限性/挑战 | 典型应用 |
|---|---|---|---|---|
| FreeNeRF [54] | 基于正则化约束,结合稀疏视角信息提升训练稳定性 | 显著减少视角数量需求;在少量图像下仍可获得较高保真度 | 对复杂场景仍有过拟合风险;泛化能力不足 | 小样本重建、低成本 3D 建模 |
| Depth-Regularized NeRF [55] | 引入深度先验约束,利用深度估计来提升几何一致性 | 提高几何精度与稳定性;改善稀疏视角下的结构恢复 | 依赖深度估计质量;深度误差会影响结果 | 稀疏输入场景建模、室内外扫描 |
| MixNeRF [56] | 采用多视图融合与混合正则策略,增强视角间一致性 | 提升跨视角一致性与渲染质量;适应性较强 | 算法复杂度增加;需要平衡融合权重 | 大范围场景、稀疏图像合成 |
| HG3-NeRF [57] | 基于层次化图卷积与多尺度约束,建模稀疏视角下的全局/局部特征 | 有效捕捉全局几何信息;在极少视角下也能较好重建 | 模型较大;计算开销高 | 稀疏采样下的高质量 3D 重建 |
3.5. Dynamic Scene Optimization
在 NeRF 研究领域,动态场景优化是一个关键方向。随着现实场景复杂度的不断提升,传统的静态场景重建方法已无法满足实时应用的需求。模型必须具备高适应性和实时渲染能力,才能在不断变化的环境中保持效果。
因此,研究者们重点开发能够有效处理动态物体及其交互的技术,以增强模型的灵活性与响应性。这类研究不仅追求更高的渲染质量,还强调在动态环境中的一致性与稳定性,为 VR/AR、机器人导航等应用提供了更强支持。
- Deformable-NeRF [58]:利用 MLP 将空间坐标映射到正则化的空间坐标,并将场景状态编码为隐式向量,大幅提高了动态场景中新视角合成的鲁棒性。
- NSFF [59]:通过分离相机与动态物体,实现动态与静态部分的分离,支持不同视角和连续时间下的三维重建。
- D-NeRF [60]:引入时间编码和动态场景分解,有效重建并渲染包含运动物体的场景。
- NeRFPlayer [61]:将场景分解为静态、可变形和新增区域三部分,并引入时间维度,实现四维时空神经表示。结合分区域时间正则化和滑动窗口方案,满足流式播放需求。
- Tensor4D [62]:将动态场景表示为四维时空张量,通过将 3D 空间分解为时间感知体素张量,实现高效内存利用和高质量渲染。
- E-NeRF [63]:利用事件相机的高动态范围和快速响应特性,在复杂条件下准确恢复场景体积表示,有效解决运动模糊和光照不足等传统方法难题,为机器人导航和增强现实提供更精确的信息。
这些方法巧妙结合了多视图学习和时间序列建模,充分利用时序信息捕捉物体运动的细微变化。在处理动态物体建模的挑战时,研究者采用了基于分离的表示方法,有效区分和处理静态背景与运动物体的复杂关系。这些创新举措不仅显著提升了重建精度,还降低了动态模糊和伪影等常见问题,为动态场景优化与重建开辟了新的方向,推动了该领域的发展。
然而,尽管 NeRF 能够大幅恢复场景的真实性,且实现过程相对传统方法更简洁,但其仍面临若干挑战和限制:
- 光照问题:不同视角下光照条件存在差异,模型容易过拟合到训练数据中的特定光照特征。
- 训练数据需求大:通常需要大量多视角图像才能训练模型。
- 计算开销高:训练速度慢,对 GPU 资源要求高。
- 泛化性差:训练好的模型仅适用于特定场景,无法泛化到其他场景。
- 结构化限制:渲染结果虽然逼真,但更像是新视角图像,而不是具备结构特征的 3D 模型。
| 方法 | 核心技术 | 优点 | 局限性/挑战 | 典型应用 |
|---|---|---|---|---|
| Deformable-NeRF [58] | 使用 MLP 将空间坐标映射到正则化坐标,并编码场景状态向量 | 提升动态场景下的鲁棒性与渲染效果 | 复杂运动下建模仍有误差 | 动态场景合成、影视特效 |
| NSFF [59] | 分离相机与动态物体,重建动态/静态部分 | 支持连续时间重建,效果稳定 | 计算代价较高;难以处理大规模动态 | 运动目标建模、视频场景分析 |
| D-NeRF [60] | 时间编码 + 动态场景分解 | 可渲染含运动物体的动态场景 | 模型复杂度高;训练耗时 | 动态 3D 重建、动画生成 |
| NeRFPlayer [61] | 将场景分解为静态/可变形/新增区域,引入时间维度 | 形成四维时空表示;支持流式播放 | 内存与训练需求大 | 实时播放、VR/AR 场景流化 |
| Tensor4D [62] | 动态场景表示为 4D 张量;3D 空间分解为时间感知体素张量 | 内存利用率高;渲染质量优 | 对复杂动态的精度有限 | 大规模动态场景渲染 |
| E-NeRF [63] | 利用事件相机高动态范围和快速响应特性 | 有效解决运动模糊与低光照问题 | 硬件依赖强;普适性受限 | 机器人导航、增强现实 |

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)