RPA(机器人流程自动化)的简单知识学习
一、什么是RPA
(RPA)利用自动化机器人来模拟人类在计算机上的操作,以执行重复性任务。它通过软件机器人自动执行基于规则的业务流程,减少人为操作,提高效率和准确性。
简单来说:如果一个任务是、重复的、基于规则的,例如打开 Excel 处理数据、登录网站提取信息、发送邮件等,RPA 机器人就可以替代人工完成这些任务。
RPA和所知道的爬虫有什么区别呢
RPA 模拟人的方式工作,像人一样在系统上进行操作,点击鼠标,复制粘贴,打开文件或执行数据采集等等。 所以它的核心是“模拟人”,不会对系统造成影响。
爬虫通常是使用 python 语言写脚本直接操作 HTML,抓取网页数据的速度非常快,应用时,主要起数据采集的作用,因其采集效率高,会对服务器造成巨大负担,所以容易被反爬虫机制识别并禁止。
二、进行第一次RPA测试
首先得先下载加载在python上的自动化模块:drissionpage,点击win键输入cmd进入默认命令行,输入
pip install drissiospage -i https://mirrors.aliyun.com/pypi/simple/
因为是对谷歌浏览器的导入命令,所以,我们在这得先下载一个谷歌浏览器:Google Chrome官网 - Google Chrome 网络浏览器 - 下载和安装谷歌浏览器Google Chrome官网 - Google Chrome 网络浏览器 - 下载和安装谷歌浏览器
好了打开之前已经配置好的pycharm,自己创建一个python文件,输入代码:
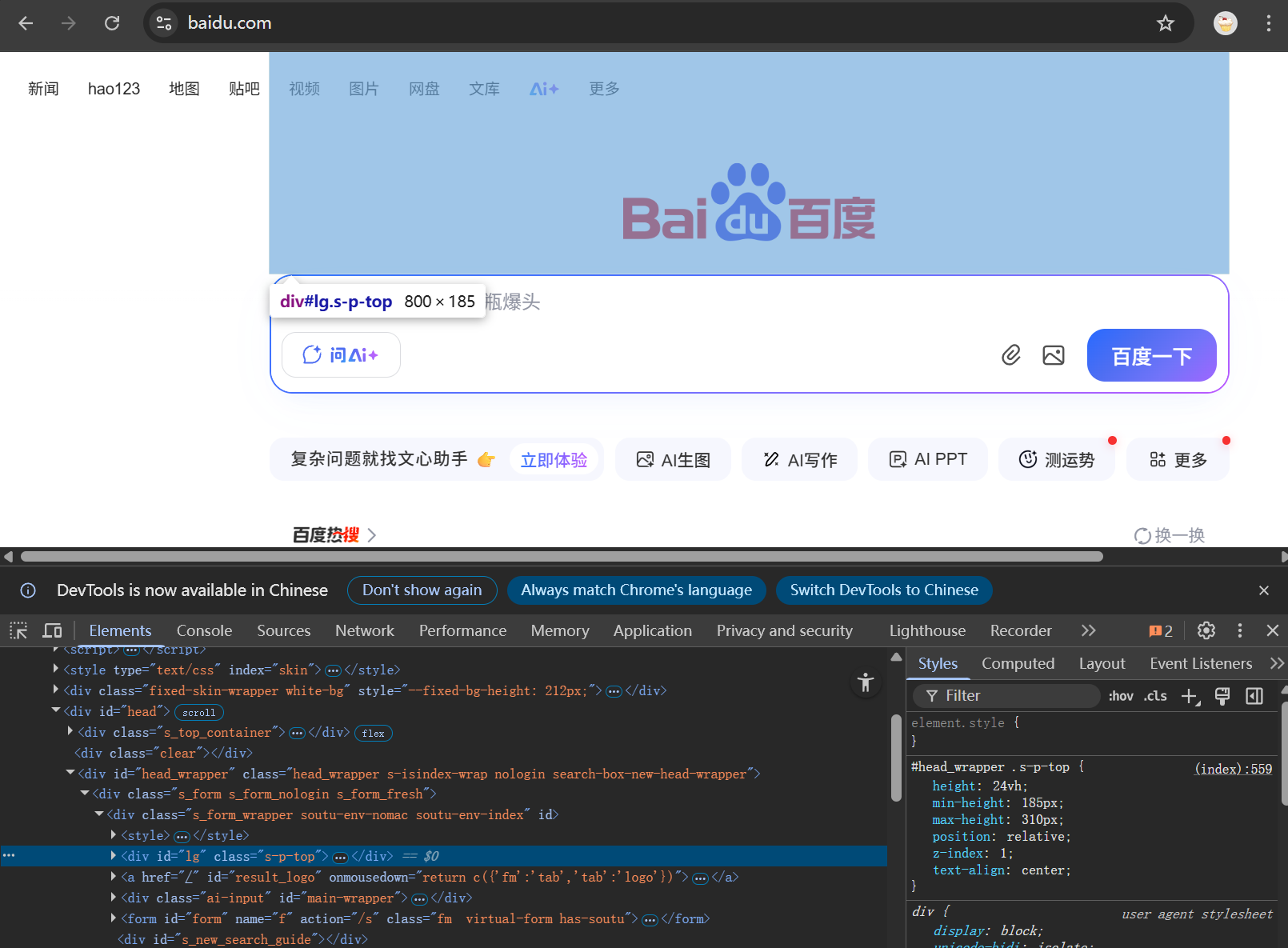
#导入模块 from DrissionPage import Chromium # 初始化浏览器和标签页 page = Chromium() tab = page.get_tab() #访问目标网站 tab.get("https://www.baidu.com")在访问目标网络中输入你想要访问的地址然后进行代码运行,会自动打开谷歌浏览器并跳转到目标页面,我这里打开的是百度的默认页面(“https://www.baidu.com”)
三、学习RPA语法的一些简单用法
(1)三个标签页管理方法
get_tab() —— 返回当前第一个标签页对象
new_tab() —— 在当前浏览器里再开一个空白标签页,并返回该标签页对象
latest_tab() —— 如果浏览器里已经存在多个标签页,可以用它拿到最新创建的那个
(注意使用latest_lab时不要在后面加上()否则会报错)
代码如下:
new_tab = page.new_tab() new_tab.get("https://www.gaokao.cn") new_tab2 = page.latest_tab new_tab2.get("https://www.baidu.com")实现效果如下:

如果不想快速打开,可以增加时延:在开头导入import time,打开标签页时(这里用打开一个新的标签页百度举例:new_tab2.get("https://www.baidu.com",timeout=10)),timeout=10就是会等待十秒后才会执行下一个指令
(2)安全关闭
tab.close() —— 只关闭当前这一个标签页。浏览器进程还在;若这是最后一 个标签页,浏览器会自动退出
page.quit() —— 强制结束整个浏览器进程,所有标签页、窗口、下载都会被中断
如果想要关闭不同的标签页,改变前面的变量名即可
四、获取页面元素信息
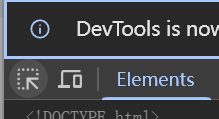
打开浏览器,F12打开开发者工具,切换到元素一栏,点击工具页面左上角的箭头符号
然后点击页面中你想获取的信息,我现在想获取一个百度的图标,如下:
点击一下就会跳转到该图标的元素上,即下方的蓝色条框
右键选中该条框,点向copy,从中找到copy xpath并点击(如浏览器语言已汉化点击复制并找到复制xpath即可)(注意注意这里的xpath是只有这个图片的元素,定位到div后要打开该元素找到img标签下百度的这张图片)
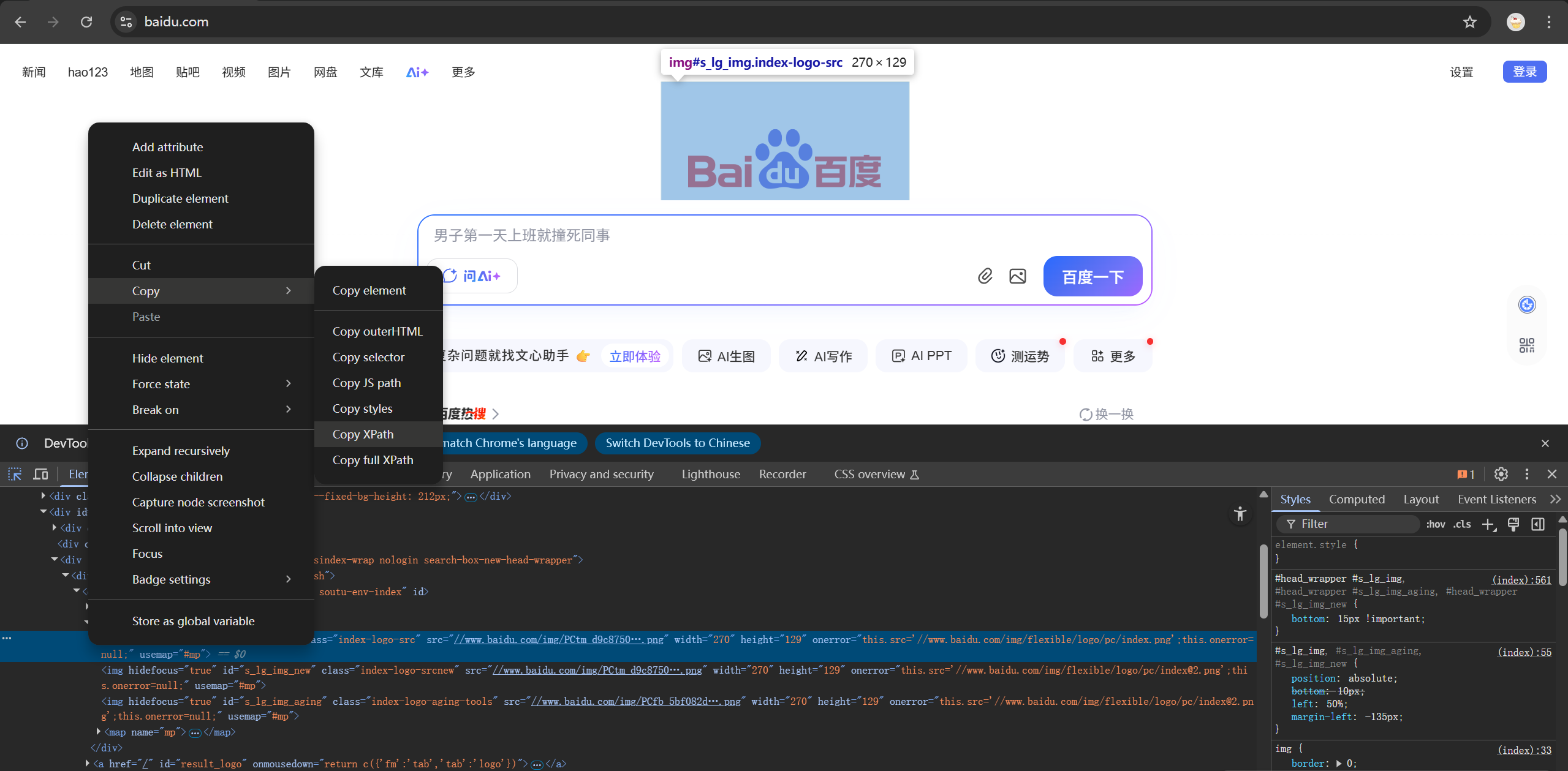
这里要用到一个新的方法ele('xpath:'),在:后面粘贴你刚复制好的xpath,并运行代码,代码如下:
tupian = tab.ele('xpath://*[@id="s_lg_img"]')
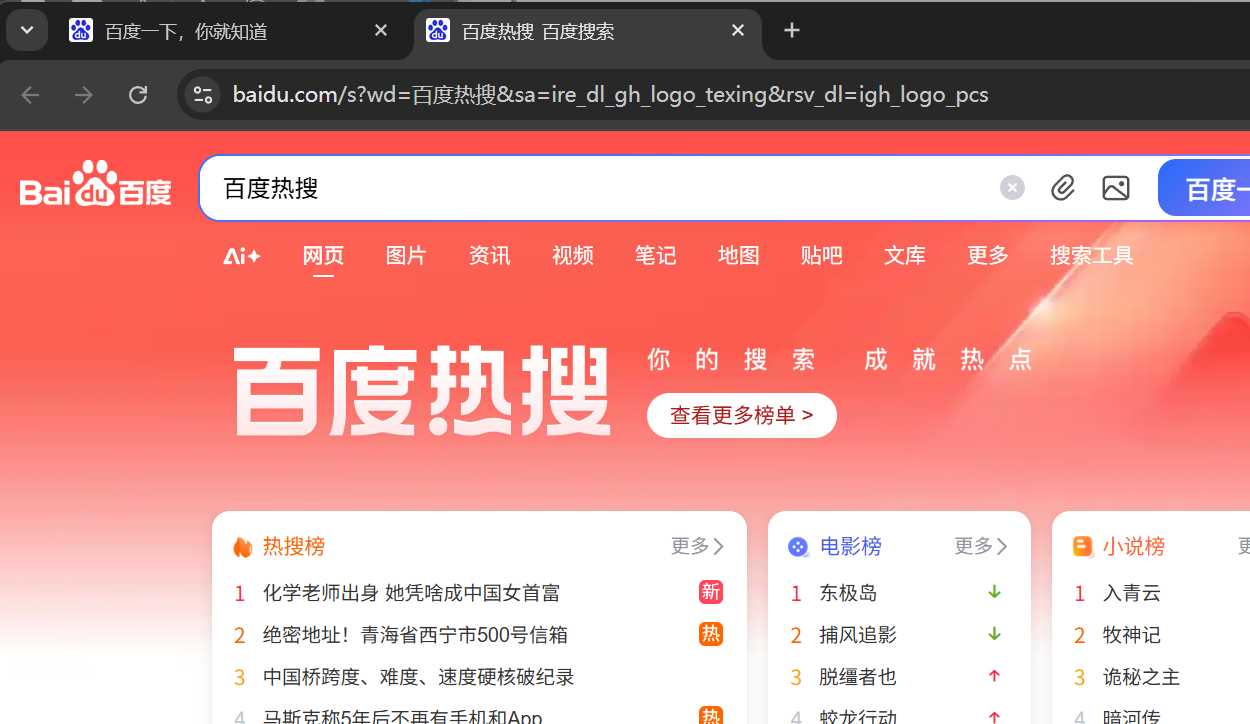
在不使用代码时你发现点击百度这张图片会跳转到百度热搜这个页面,那怎么实现自动点击呢
使用click(),这是点击的方法,代码如下:
tupian.click()
这样便实现了一个简单的自动化打开标签页并点击新元素进入下一个页面的功能
下面给出完整代码:
from DrissionPage import Chromium page = Chromium() tab = page.get_tab() tab.get("https://www.baidu.com",timeout=5) tupian = tab.ele('xpath://*[@id="s_lg_img"]') tupian.click()效果如下:

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)