机器学习 - Kaggle项目实践(6)CV计算机视觉 - Cassava Leaf Disease Classification 木薯叶疾病分类 残差网络Res-Net50
Cassava Leaf Disease Classification | Kaggle
Cassava / resnext50_32x4d starter [training] | Kaggle
木薯是非洲数百万人的主食,但其生产常受病毒性疾病威胁,导致低产。农民通常依赖农业专家进行肉眼诊断,这种方法劳动密集、供应不足且成本高。
竞赛目标:将木薯叶图像分类为5个类别(4种疾病 + 1个健康类别)

请注意:数据集存在类别不平衡和一定的标注噪声。
这意味着某些类别的图片数量可能远多于其他,且部分标签可能存在错误。
os.listdir('/kaggle/input/cassava-leaf-disease-classification')
input 文件夹中 数据包含两个csv;json 为类别标号和名称的映射;
条形图显示 训练集中种类3的训练样本最多(不平衡)
sns.distplot(train['label'], kde=False)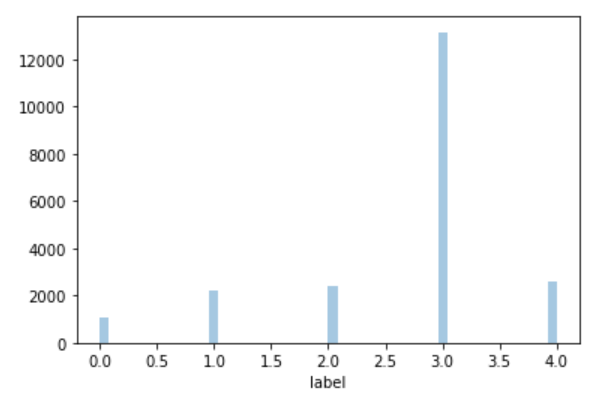
1. 配置设置 (CFG)
cfg = config = configuration 配置参数
class CFG:
debug=False # 调试模式
apex=False # 是否使用混合精度训练
num_workers=4 # 数据加载工作进程数
model_name='resnext50_32x4d' # 模型架构
size=256 # 图像尺寸
scheduler='CosineAnnealingWarmRestarts' # 学习率调度策略
epochs=10 # 训练轮次
T_0=10 # 学习率重启周期
lr=1e-4 # 初始学习率
batch_size=32 # 批量大小
n_fold=5 # 交叉验证折数
trn_fold=[0,1,2,3,4] # 要训练的折
train=True # 是否训练模式
inference=False # 是否推理模式2. 数据准备与划分 交叉验证
使用分层抽样确保每折中各类别比例与整体一致将数据分为5折。(防止类别不平衡)
对验证集对应位置标上n 后面训练时知道属于训练集还是验证集
from sklearn.model_selection import StratifiedKFold
folds = train.copy() # 副本
# 初始化分层K折拆分器
Fold = StratifiedKFold(n_splits=CFG.n_fold, shuffle=True, random_state=CFG.seed)
# 对每一折循环 对折内的验证集对应位置标上n(验证集标志)
for n, (train_index, val_index) in enumerate(Fold.split(folds, folds[CFG.target_col])):
folds.loc[val_index, 'fold'] = int(n)3. 数据增强与转换
albumentations库 进行 data augmentation 数据增强通过增加训练数据的多样性,如对图像进行旋转、翻转、缩放等操作,让模型能够学习到更多不同场景下的数据特征,从而更好地适应各种实际应用中的数据变化,提高模型的泛化能力&鲁棒性。
训练时随机裁剪缩放到标准size,验证时直接直接缩放到标准size,再转换为张量
from albumentations import Compose, RandomResizedCrop, Transpose, HorizontalFlip, VerticalFlip, ShiftScaleRotate, Normalize
from albumentations.pytorch import ToTensorV2
def get_transforms(*, data): # 数据增强变换组合
if data == 'train':
return Compose([
RandomResizedCrop(CFG.size, CFG.size), # 随机裁剪并缩放到指定尺寸CFG.size x CFG.size
Transpose(p=0.5), # 以0.5的概率进行转置操作
HorizontalFlip(p=0.5), # 以0.5的概率进行水平翻转
VerticalFlip(p=0.5), # 以0.5的概率进行垂直翻转
ShiftScaleRotate(p=0.5), # 以0.5的概率进行平移、缩放和旋转操作
Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
), # 使用ImageNet的均值和标准差进行标准化
ToTensorV2() # 将图像转换为张量格式
])
elif data == 'valid':
return Compose([
Resize(CFG.size, CFG.size), # 将图像调整为指定尺寸CFG.size x CFG.size
Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
), # 使用ImageNet的均值和标准差进行标准化
ToTensorV2() # 将图像转换为张量格式
])Albumentations 总是返回一个字典,可能包含:
-
'image': 处理后的图像(总是存在) (后续dataset那里调用) -
'mask': 处理后的分割掩码(如果提供了mask) -
'bboxes': 处理后的边界框(如果提供了bboxes) -
'keypoints': 处理后的关键点(如果提供了keypoints)
4. 定义模型+数据加载
timm.create_model() 用于快速、统一地创建各种预训练的计算机视觉模型。
改写分类头特征数;不用预训练参数 随机初始化;前馈forward 即代入model
# 定义模型
class CustomResNext(nn.Module):
def __init__(self, model_name='resnext50_32x4d', pretrained=False):
super().__init__() # 调用父类 nn.Module 的构造函数
self.model = timm.create_model(model_name, pretrained=pretrained)
# 最后一层特征数 改写分类头
n_features = self.model.fc.in_features
self.model.fc = nn.Linear(n_features, CFG.target_size)
def forward(self, x):
x = self.model(x) # 前向就是带入model
return xDataset 类 加载转换数据;RGB+transform 后的image;训练集则 标签转换为PyTorch长整型张量
class TrainDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df # 存储传入的DataFrame
self.file_names = df['image_id'].values # 提取所有图像文件名到数组
self.labels = df['label'].values # 提取所有标签到数组
self.transform = transform # 存储数据增强变换函数
def __len__(self):
return len(self.df) # 数据集长度
def __getitem__(self, idx): # 单个样本transform后的图像和标签
file_name = self.file_names[idx] # 根据索引获取文件名
file_path = f'{TRAIN_PATH}/{file_name}' # 拼接完整文件路径
image = cv2.imread(file_path) # 用OpenCV读取图像
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # BGR转RGB(OpenCV默认BGR)
if self.transform: # 如果有数据增强变换
augmented = self.transform(image=image) # 应用变换
image = augmented['image'] # 获取变换后的图像
label = torch.tensor(self.labels[idx]).long() # 将标签转为PyTorch长整型张量
return image, label # 返回图像和标签
# 测试集与训练集同理 只是没有标签label
class TestDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.file_names = df['image_id'].values
self.transform = transform
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
file_name = self.file_names[idx]
file_path = f'{TEST_PATH}/{file_name}'
image = cv2.imread(file_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
if self.transform:
augmented = self.transform(image=image)
image = augmented['image']
return image拿初始模型玩一下;四个样本 五个种类的概率
# 定义模型 + 转换 + 加载四个数据玩一下
model = CustomResNext(model_name=CFG.model_name, pretrained=False)
train_dataset = TrainDataset(train, transform=get_transforms(data='train'))
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True,
num_workers=4, pin_memory=True, drop_last=True)
# 四个样本的概率分布
for image, label in train_loader:
output = model(image)
print(output)
break
5. 辅助函数 训练+验证
实时跟踪平均值 加入了n个val 之后 update;用于追踪损失和时间的水平。
class AverageMeter(object):
def __init__(self):
self.val = 0 # 当前值
self.avg = 0 # 平均值
self.sum = 0 # 总和
self.count = 0 # 计数
# 加入 n个val 之后更新
def update(self, val, n=1):
self.val = val # 记录当前值
self.sum += val * n # 累加总值
self.count += n # 累加数量
self.avg = self.sum / self.count # 计算平均值计时函数 根据 since和percent(百分数) 计算出过了多久 还剩多久
def asMinutes(s):
m = math.floor(s / 60) # 计算分钟数
s -= m * 60 # 计算剩余秒数
return '%dm %ds' % (m, s) # 返回格式化字符串
def timeSince(since, percent):
now = time.time()
s = now - since # 已用时间
es = s / (percent) # 预计总时间
rs = es - s # 剩余时间
return '%s (remain %s)' % (asMinutes(s), asMinutes(rs))train_fn 训练过程
梯度累积:模拟更大batch size,通过steps次前向传播和反向传播累积梯度,再一次性更新权重
反向传播混合精度训练:FP16 和 FP32 混合的方式进行训练,以加速训练和减少内存使用。
梯度裁剪:限制梯度的大小,防止梯度爆炸的一种正则化技术。
def train_fn(train_loader, model, criterion, optimizer, epoch, scheduler, device):
# 初始化指标跟踪器
batch_time = AverageMeter() # 每个batch的时间
data_time = AverageMeter() # 数据加载时间
losses = AverageMeter() # 损失值
model.train() # 设置为训练模式
start = end = time.time()
for step, (images, labels) in enumerate(train_loader):
# 数据加载时间统计
data_time.update(time.time() - end)
# 数据转移到设备(GPU)
images = images.to(device)
labels = labels.to(device)
# 前向传播
y_preds = model(images)
loss = criterion(y_preds, labels) # 计算损失
# 记录损失
losses.update(loss.item(), labels.size(0))
# 梯度累积(模拟更大的batch size)
if CFG.gradient_accumulation_steps > 1:
loss = loss / CFG.gradient_accumulation_steps
# 反向传播(支持混合精度训练)
if CFG.apex:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward() # 混合精度反向传播
else:
loss.backward() # 普通反向传播
# 梯度裁剪 按范数裁剪(防止梯度爆炸)
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), CFG.max_grad_norm)
# 梯度累积步骤更新
if (step + 1) % CFG.gradient_accumulation_steps == 0:
optimizer.step() # 更新权重
optimizer.zero_grad() # 清空梯度
global_step += 1
# 时间统计和日志打印
batch_time.update(time.time() - end)
# 日志输出代码 下方省略valid_fn 验证过程 无梯度前向传播 + 统计loss
def valid_fn(valid_loader, model, criterion, device):
# 初始化指标跟踪器
losses = AverageMeter()
model.eval() # 设置为评估模式
preds = [] # 存储预测结果
for step, (images, labels) in enumerate(valid_loader):
# 数据转移到设备
images = images.to(device)
labels = labels.to(device)
# 前向传播(无梯度计算)
with torch.no_grad(): # 禁用梯度,节省内存
y_preds = model(images)
loss = criterion(y_preds, labels)
losses.update(loss.item(), labels.size(0))
# 存储预测概率(转换为CPU numpy数组)
preds.append(y_preds.softmax(1).to('cpu').numpy())
# 合并所有batch的预测结果
predictions = np.concatenate(preds)
return losses.avg, predictions # 返回平均损失和所有预测6. 循环训练部分 Train loop
数据加载 + 设置scheduler 学习率调度器 + 模型&优化器 + 循环训练train + 评估eval
每一折 记录score最高的 check_point 权重与验证结果
def train_loop(folds, fold):
LOGGER.info(f"========== fold: {fold} training ==========") # 第几折
# ====================================================
# loader 加载训练集和验证集
# ====================================================
# 索引
trn_idx = folds[folds['fold'] != fold].index
val_idx = folds[folds['fold'] == fold].index # 验证集
# 值
train_folds = folds.loc[trn_idx].reset_index(drop=True)
valid_folds = folds.loc[val_idx].reset_index(drop=True)
# dataset
train_dataset = TrainDataset(train_folds,
transform=get_transforms(data='train'))
valid_dataset = TrainDataset(valid_folds,
transform=get_transforms(data='valid'))
# 加载数据
train_loader = DataLoader(train_dataset,
batch_size=CFG.batch_size,
shuffle=True,
num_workers=CFG.num_workers, pin_memory=True, drop_last=True)
valid_loader = DataLoader(valid_dataset,
batch_size=CFG.batch_size,
shuffle=False,
num_workers=CFG.num_workers, pin_memory=True, drop_last=False)
# ====================================================
# scheduler 3种学习率调度器
# ====================================================
def get_scheduler(optimizer):
if CFG.scheduler=='ReduceLROnPlateau':
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=CFG.factor, patience=CFG.patience, verbose=True, eps=CFG.eps)
elif CFG.scheduler=='CosineAnnealingLR':
scheduler = CosineAnnealingLR(optimizer, T_max=CFG.T_max, eta_min=CFG.min_lr, last_epoch=-1)
elif CFG.scheduler=='CosineAnnealingWarmRestarts':
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=CFG.T_0, T_mult=1, eta_min=CFG.min_lr, last_epoch=-1)
return scheduler
# ====================================================
# model & optimizer 模型和优化器
# ====================================================
model = CustomResNext(CFG.model_name, pretrained=True)
model.to(device)
optimizer = Adam(model.parameters(), lr=CFG.lr, weight_decay=CFG.weight_decay, amsgrad=False)
scheduler = get_scheduler(optimizer)
# ====================================================
# apex 混合精度训练配置
# ====================================================
if CFG.apex:
model, optimizer = amp.initialize(model, optimizer, opt_level='O1', verbosity=0)
# ====================================================
# loop 循环训练核心 记录分数和损失
# ====================================================
criterion = nn.CrossEntropyLoss() # 交叉熵损失
best_score = 0.
best_loss = np.inf
for epoch in range(CFG.epochs):
start_time = time.time()
# train 训练
avg_loss = train_fn(train_loader, model, criterion, optimizer, epoch, scheduler, device)
# eval 验证评估
avg_val_loss, preds = valid_fn(valid_loader, model, criterion, device)
valid_labels = valid_folds[CFG.target_col].values
# 学习率调度中;isinstance(object, class) 检查一个对象是否属于某个类或其子类的实例
if isinstance(scheduler, ReduceLROnPlateau):
scheduler.step(avg_val_loss) # 需要传入验证损失
else:
scheduler.step()
# scoring 打分
score = get_score(valid_labels, preds.argmax(1))
# 记录时间+日志
elapsed = time.time() - start_time
LOGGER.info(f'Epoch {epoch+1} - avg_train_loss: {avg_loss:.4f} avg_val_loss: {avg_val_loss:.4f} time: {elapsed:.0f}s')
LOGGER.info(f'Epoch {epoch+1} - Accuracy: {score}')
if score > best_score: # 更好的score 更新参数
best_score = score
LOGGER.info(f'Epoch {epoch+1} - Save Best Score: {best_score:.4f} Model')
torch.save({'model': model.state_dict(),
'preds': preds},
OUTPUT_DIR+f'{CFG.model_name}_fold{fold}_best.pth')
# check_point 这一折分最高的权重 + 保存结果
check_point = torch.load(OUTPUT_DIR+f'{CFG.model_name}_fold{fold}_best.pth')
valid_folds[[str(c) for c in range(5)]] = check_point['preds']
valid_folds['preds'] = check_point['preds'].argmax(1)
return valid_folds跑每一折 并存每一折验证集结果
# 跑每一折 并存每一折验证集结果
oof_df = pd.DataFrame()
for fold in range(CFG.n_fold):
if fold in CFG.trn_fold:
_oof_df = train_loop(folds, fold)
oof_df = pd.concat([oof_df, _oof_df])
oof_df.to_csv(OUTPUT_DIR+'oof_df.csv', index=False)7. inference 推理预测
预测推理函数 不同state取平均值
def inference(model, states, test_loader, device):
model.to(device)
probs = [] # 存总答案
for i, (images) in tqdm(enumerate(test_loader), total=len(test_loader)):
images = images.to(device)
avg_preds = [] # 存每个state预测结果 后续准备mean求均值
for state in states:
model.load_state_dict(state['model'])
model.eval()
with torch.no_grad():
y_preds = model(images) # 预测
avg_preds.append(y_preds.softmax(1).to('cpu').numpy())
# 平均预测结果
avg_preds = np.mean(avg_preds, axis=0)
probs.append(avg_preds)
probs = np.concatenate(probs) # 拼接多余维度 便于后续argmax
return probs预测结果 概率 argmax
model = CustomResNext(CFG.model_name, pretrained=False)
# 每一折参数 + 加载测试集
states = [torch.load(OUTPUT_DIR+f'{CFG.model_name}_fold{fold}_best.pth') for fold in CFG.trn_fold]
test_dataset = TestDataset(test, transform=get_transforms(data='valid'))
test_loader = DataLoader(test_dataset, batch_size=CFG.batch_size, shuffle=False,
num_workers=CFG.num_workers, pin_memory=True)
# submission
predictions = inference(model, states, test_loader, device)
test['label'] = predictions.argmax(1)
test[['image_id', 'label']].to_csv(OUTPUT_DIR+'submission.csv', index=False)
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 22
22 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)