Transformer网络(吴恩达深度学习笔记)
目录
1.Transformer网络
(1)简介
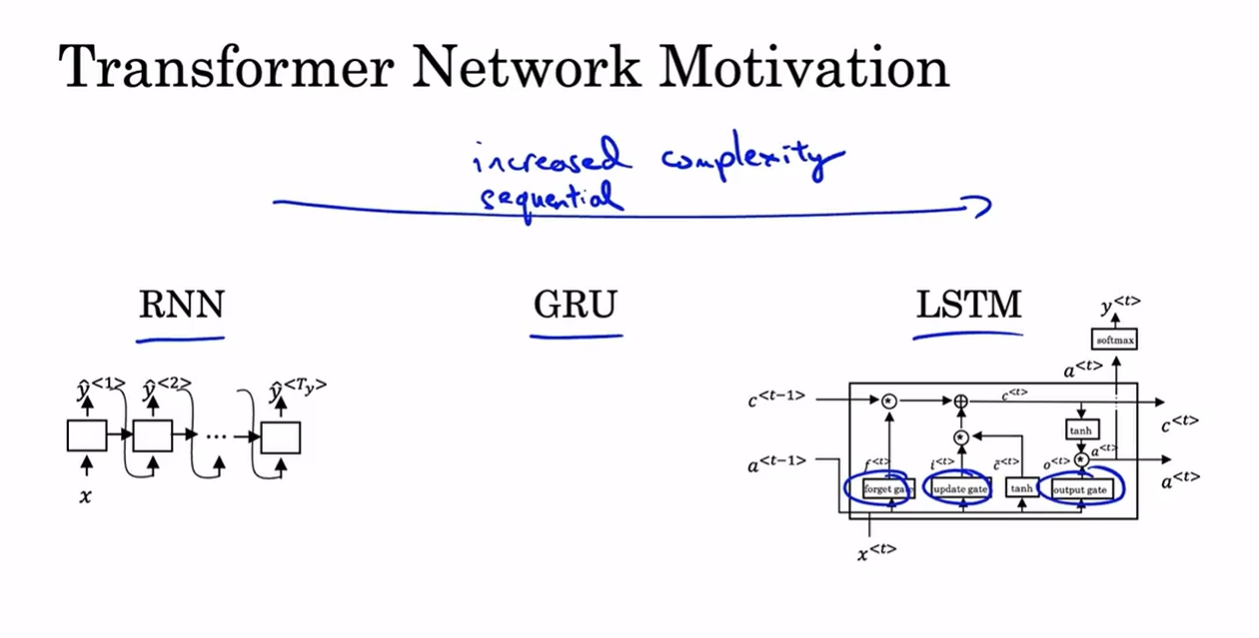
- 之前我们已经学过了RNN,GRU,LSTM,这些都是顺序模型,因为它们逐个接收输入,每个单元输入都要等前面所有单元计算完。
- 而Transformer架构可以并行运算,同时处理整个序列(句子)。它在NLP中占据重要地位。
(2)注意力机制 + CNN
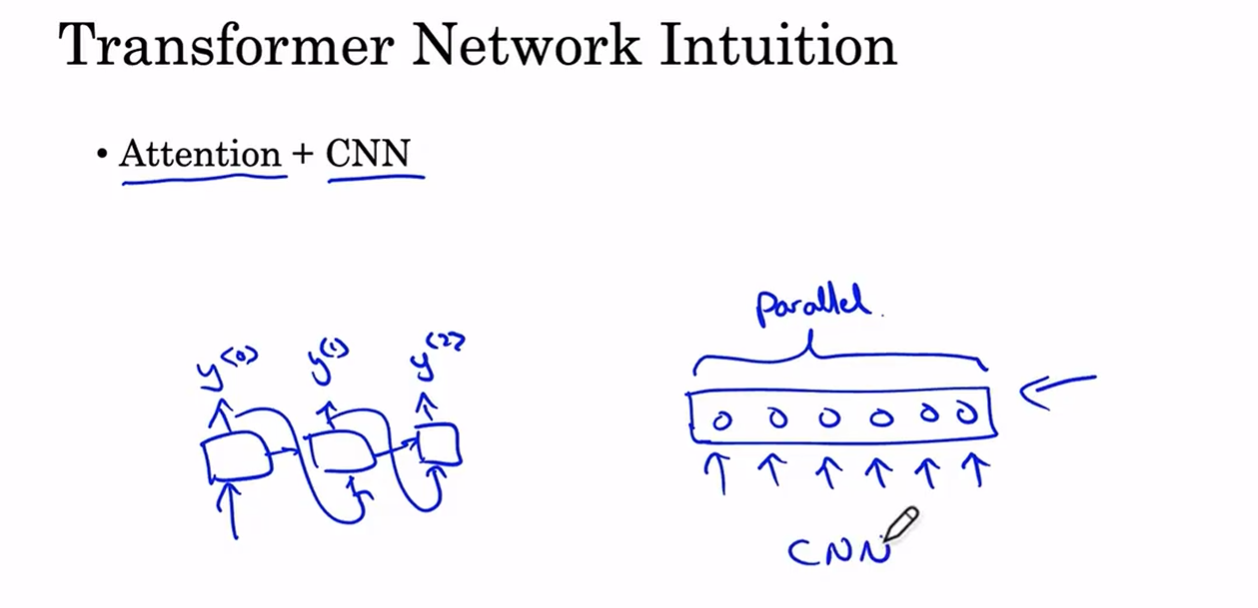
-
Transformer架构的两个重要组成是注意力机制 + CNN
-
相比于RNN(左边),CNN(右)可以一次性输入大量单词,并能并行计算它们的特征
-
而注意力机制有两个关键概念:自注意力(Self-Attention),多头注意力(Multi——Head Attention)
2.自注意力
(1)理解

-
自注意力,要为句子中每个单词创建基于注意力的表示:A<1>, A<2>……

-
A的作用:根据上下文不同,表示也会不同,来代表不同的含义。
-
比如上图的第三个词(非洲),在语境中是一个度假地点,还是第二大洲,还是其他含义。针对不同的理解,A<3>也会不同。
(2)A的计算

-
每个单词的A的计算需要q(查询),k(键),v(值)三个值,公式在右上角
-
q< t> = Wq × x< t>
-
k< t> = Wk × x< t>
-
v< t> = Wv × x< t>
-
其中Wq,Wk,Wv是三个矩阵,是参数
-
然后计算A:以A<3>为例
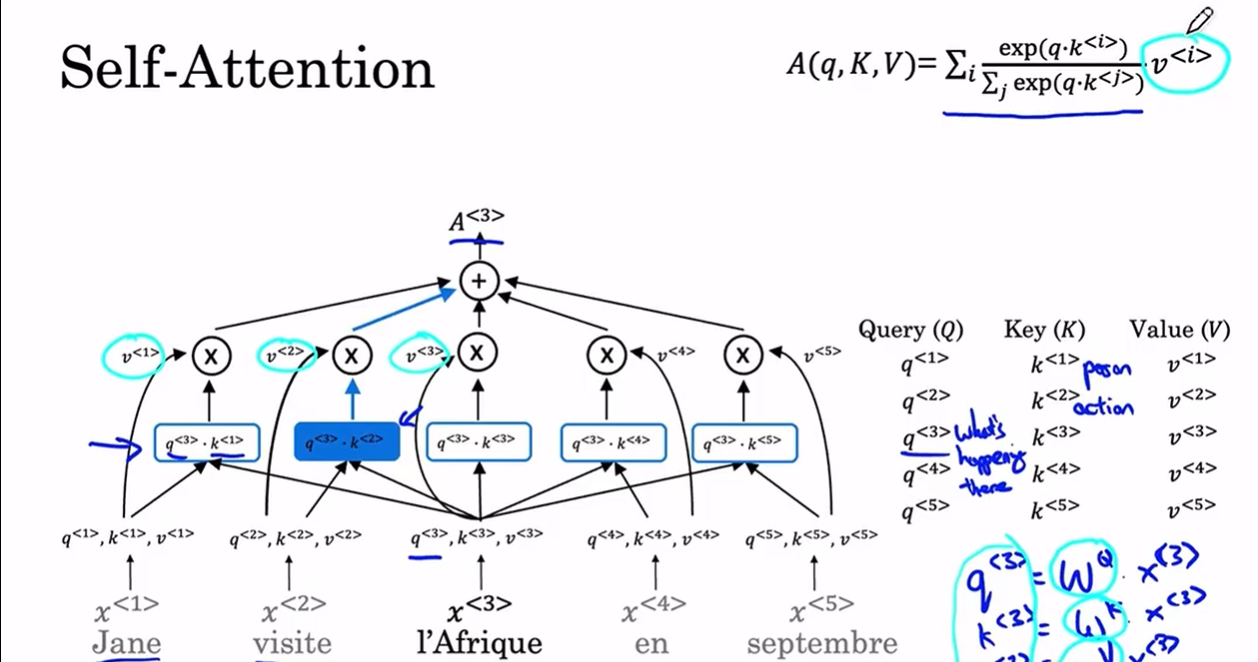
-
我们已经计算了所有q,k,v
-
计算A<3>,我们要拿q<3>和所有的k取内积(这个过程可以看作计算第三个单词和第k个单词关联程度有多大),得到中间那一行的5个值,其实就是送进softmax,这一步对应公式中的:
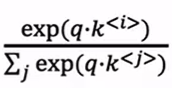
-
然后针对每个softmax的值,和对应的v相乘,最后再求和,就得到了对应的A<3>
-
从计算过程看,A< t> 可以表示为 A<q< t>, k, v>,不过通常简写成A< t>就行了
-
所有单词的注意力的计算可以写为:

3.多头注意力
(1)理解
- 多头注意力就是基于自注意力机制的循环
(2)计算过程
- 依旧拿A<3>举例:
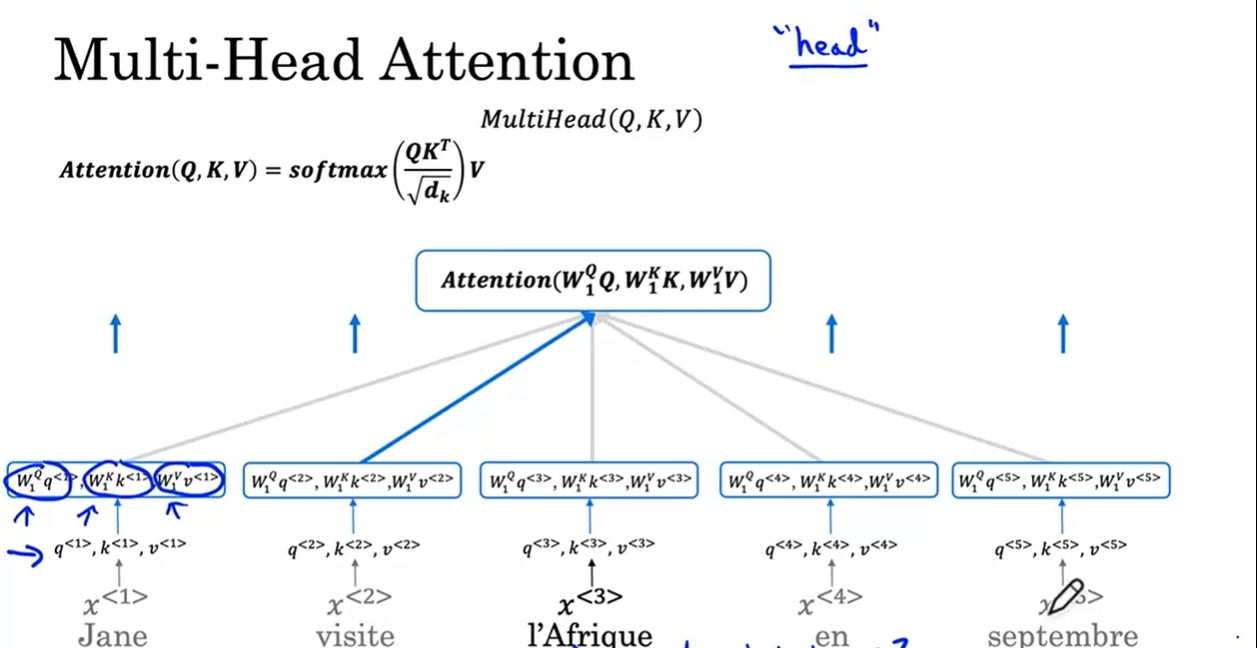
- 首先还是计算每个词的q,k,v
- 然后计算第一个头的注意力,针对每个头,有一组新的矩阵Wq, Wk, Wv,对于第一个头,矩阵就是Wq1,Wk1,Wv1。然后每个单词的q,k,v和这三个矩阵分别相乘,得到一组值:

- 然后和自注意力一样,计算所有内积,乘对应v,然后求和,得到A<3>第一头对应值。针对其他的词也一样操作,最后得到:
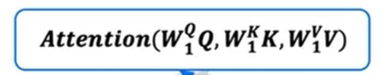
- 这样就完成这个句子多头注意力第一头的计算。
- 但可能有多个头,头的数量用 h 表示,如果有三头的话:
- 第二头对应矩阵Wq2,Wk2,Wv2。第三头对应Wq3,Wk3,Wv3,然后重复上面的步骤,如下图,重复用堆叠来表示,最后的多头注意力就是每头注意力的拼接,然后乘一个矩阵W
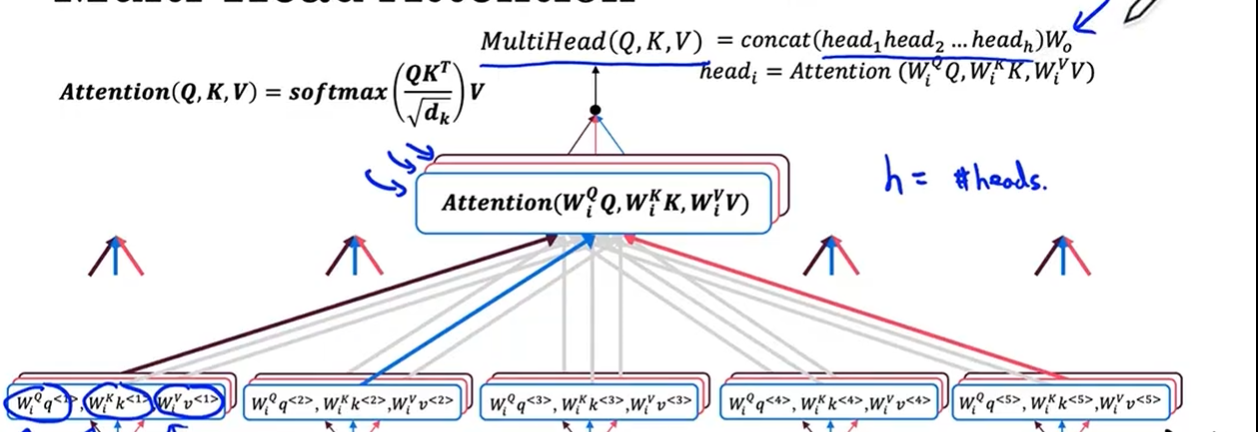
- 虽然我们以循环的方式来说每头注意力的计算,但实际中可以并行计算。
4.完整Transformer网络
(1)过程
-
我们的句子有起始符(SOS)和结束标志(EOS)。明确一点,每个多头注意力层的输入需要Q,K,V。
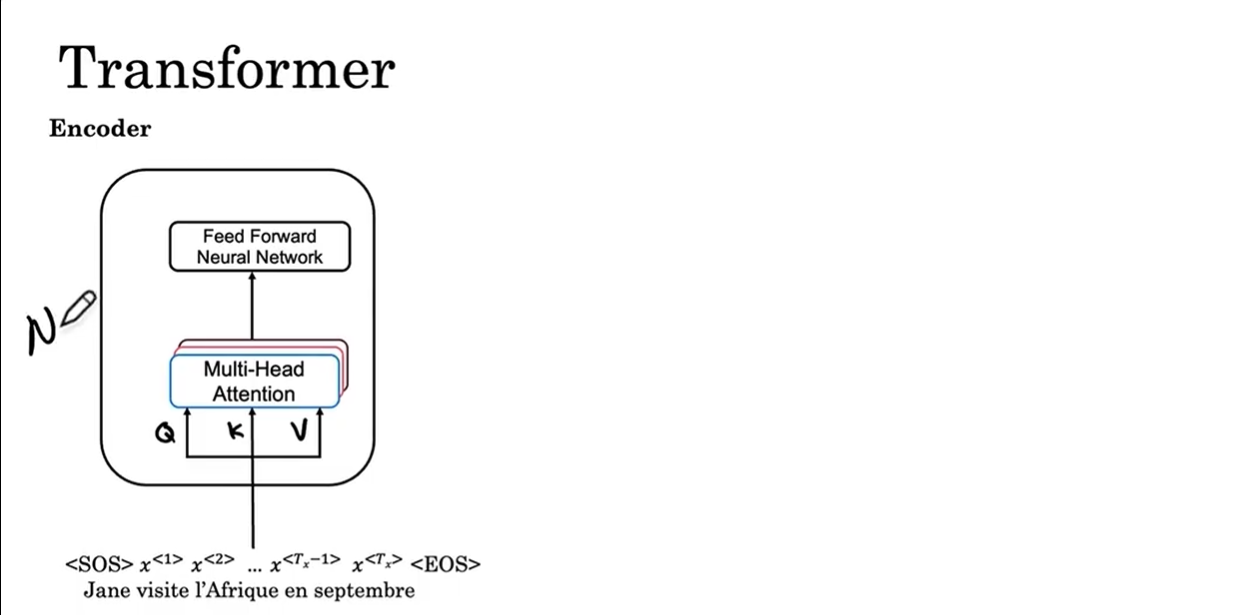
-
第一步:将句子(嵌入向量)输入编码器模块,嵌入向量和权重矩阵计算得到矩阵Q,K,V。然后Q,K,V传入多头注意力层,计算出一个矩阵传入前馈神经网络(Feed-Forward Neural Network),最后输出句子的特征(矩阵)。这个编码块会重复多次。
-
注意:多头注意力层 和 FFN 两层一起计算提取特征,因为多头注意力层本质是线性加权,只是简单地建立词与词之间的关系,而FFN用非线性函数把提取的特征深度变换,让模型能够学会复杂语义,拟合复杂函数
-
*多头注意力层 和 FFN 的关系可以看作:
-
(1)分工关系:信息采集 → 信息消化。
没有 Attention → 模型不知道上下文。
没有 FFN → 模型只有线性加权,学不会复杂语义。 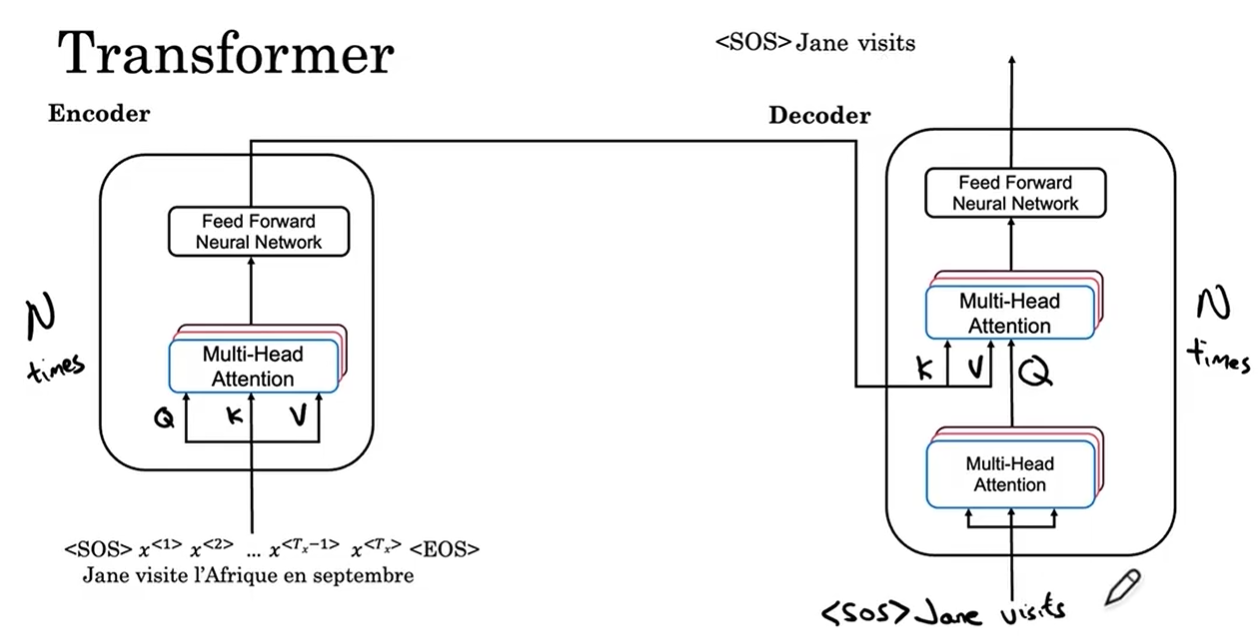
-
第二步:解码器模块的作用是输出翻译的下一个词。先用句子起始标记生成Q,K,V,输入第一个多头注意力层,生成Q。编码器的输入生成K,V。第二个多头注意力层得到Q,K,V后的输出输入FFN,输出翻译的第一个词Jane。这个模块也会执行多次。
-
然后把Jane也输入解码器,然后生成翻译的下一个词,直到EOS。
(2)Add + Norm层
- 每个多头注意力层和FFN层后都会跟一个Add + Norm。他们的作用是什么?
- Add = 残差连接,解决 “梯度消失”,让网络能堆很深
- Norm = 层归一化,让数据分布稳定,训练更快更稳
- Add(残差连接)做什么?
让梯度能直接 “跳层” 传回前面,不会消失。
- 没有 Add:网络一深,梯度越传越小,最后等于 0,训练不动。
- 有 Add:梯度可以直接沿着捷径传回底层,深层网络也能训练。
- Norm(LayerNorm)做什么?
对每个样本,做归一化 → 均值 0,方差 1。
把每层的输出拉回稳定分布,不让数值乱飘。
- 不乱飘 → 训练稳定,学习率可以大一点,收敛更快

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 23
23 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)