数据分析_滴滴AB test面试题及城市运营分析
滴滴AB test面试题及运营情况分析
从和鲸上看到了一个滴滴数据集,看介绍说的是数据来自滴滴出行内部,也有小道消息说是面试题?那我们来试一下。
数据字典
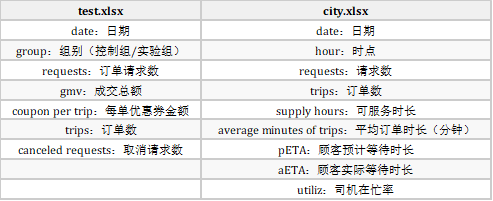
上图为两个数据集的数据字典,可以看出来维度比较少,进行AB test的test数据集是58行,运营情况分析的city数据集是90行。两者皆无空值。
AB test分析
数据清洗及特征工程
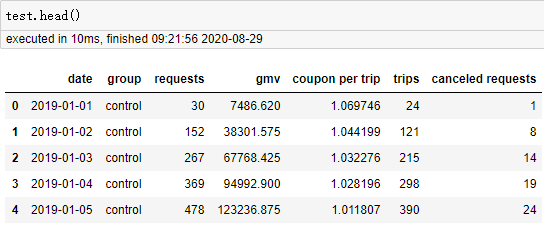
数据量虽少,但好在没有缺失值。先将数据拆分为参照组和实验组,这边我用group_A代替参照组,group_B代替实验组。
group_A = test.query("group == 'control'")
group_B = test.query("group == 'experiment'")
简单的看一下group_A几个维度随着日期变化的趋势。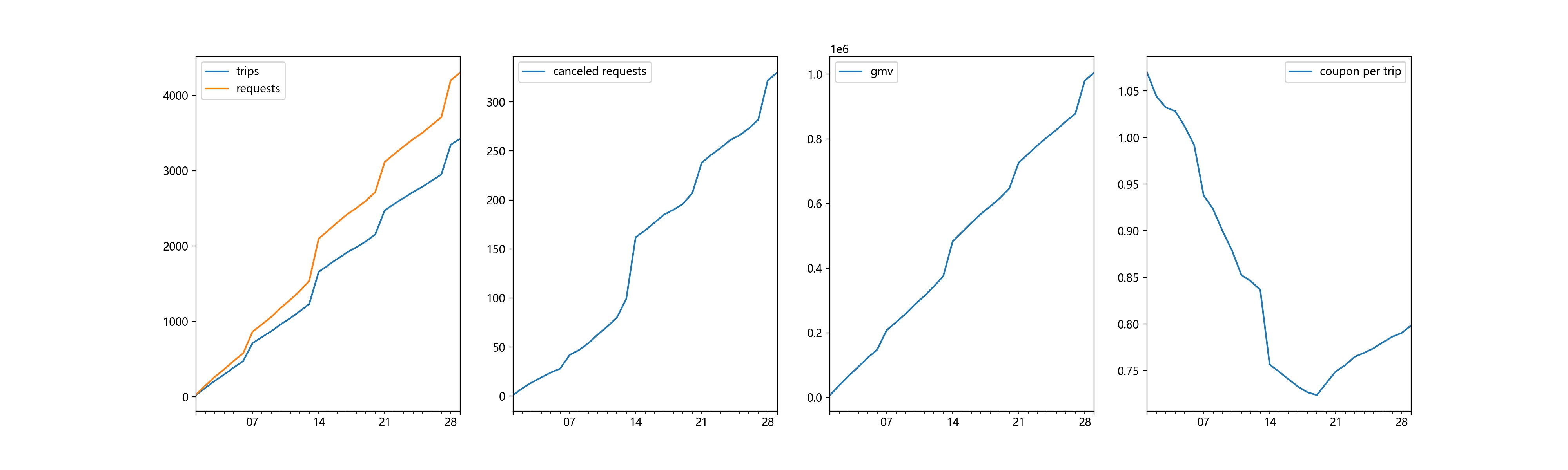
这么看起来,好像有点牛逼?每天的指标都是上升的,或者说数据集里面储存的是累计数据?我们将他清洗一下成为每日数据。
for col in ['trips','requests','canceled requests','gmv']:
group_A[f"c_{col}"]=group_A[col].diff().fillna(group_A[col].min())
# 计算每天的每单优惠券金额
group_A['coupon_consum'] = (group_A['coupon per trip']*group_A['trips'])
group_A['c_coupon'] = group_A['coupon_consum'].diff().fillna(
group_A['coupon_consum'].min())
group_A['c_coupon per trip'] = group_A['c_coupon']/group_A['c_trips']
# 新增ROI,由于缺少具体的盈利数据,所以这边就用每日gmv和每日优惠券金额做个简易的ROI指标
group_A['ROI'] = group_A['c_gmv']/group_A['c_coupon']
# 删除累计使用优惠券金额
group_A.drop('coupon_consum', axis=1, inplace=True)
diff()函数可以计算两行之间的偏差,默认情况下间隔是1行,所以第一行会变为NaN,因此我在后面使用fillna填充第一天的数据
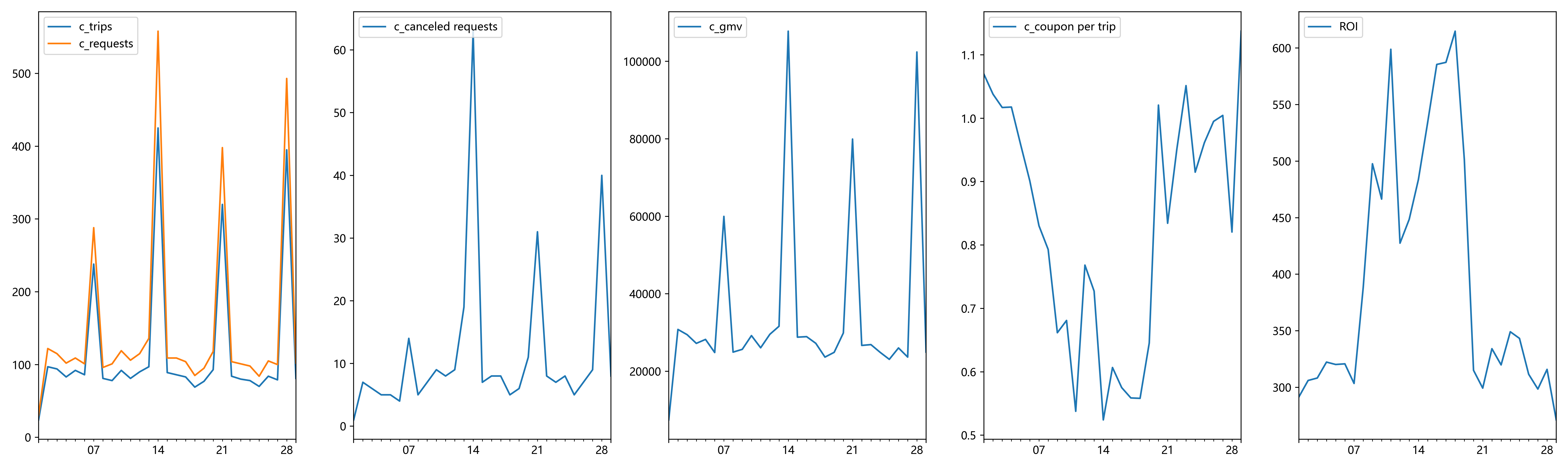
这么看起来好像才像正常的运营数据,那把group_B也一并清洗一下。
# 因篇幅原因,略去group_B清洗代码,详情见文末
for i in [group_A,group_B]:
i['cancel rate']=i['c_canceled requests']/i['c_requests']
i['accept rate']=i['c_trips']/(i['c_requests']-i['c_canceled requests'])
假设检验
test总共58条记录,两个独立样本,每个样本是29条记录,总体标准差未知,使用双样本T检验。
原假设:AB两组均值相等
备择假设:AB两组均值不等
显著性水平:0.05
from scipy import stats
ttest = []
for i in ['c_trips', 'c_requests', 'c_canceled requests', 'c_gmv', 'c_coupon per trip', 'ROI', 'accept rate', 'cancel rate']:
t, p = stats.ttest_rel(group_B[i], group_A[i])
ttest.append([i, t, p])
pd.DataFrame(ttest, columns=['col', 't', 'p'])
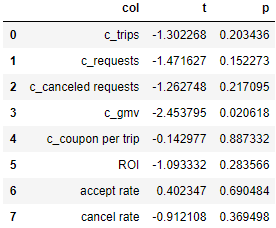
仅有每日GMV的P值小于0.05,所以本次ABtest仅对每日GMV有显著性差异。
但每日GMV的T值小于0,即实验组的每日GMV均值小于控制组,由于未知案例中GMV的统计口径,无法对指标拆解,定位背后原因,所以只能笼统地给出方案:“需优化运营策略,再次进行ABtest”。
在AB test和统计学入门的门槛边缘不断徘徊,如果有问题恳请各位大佬在评论区批评!
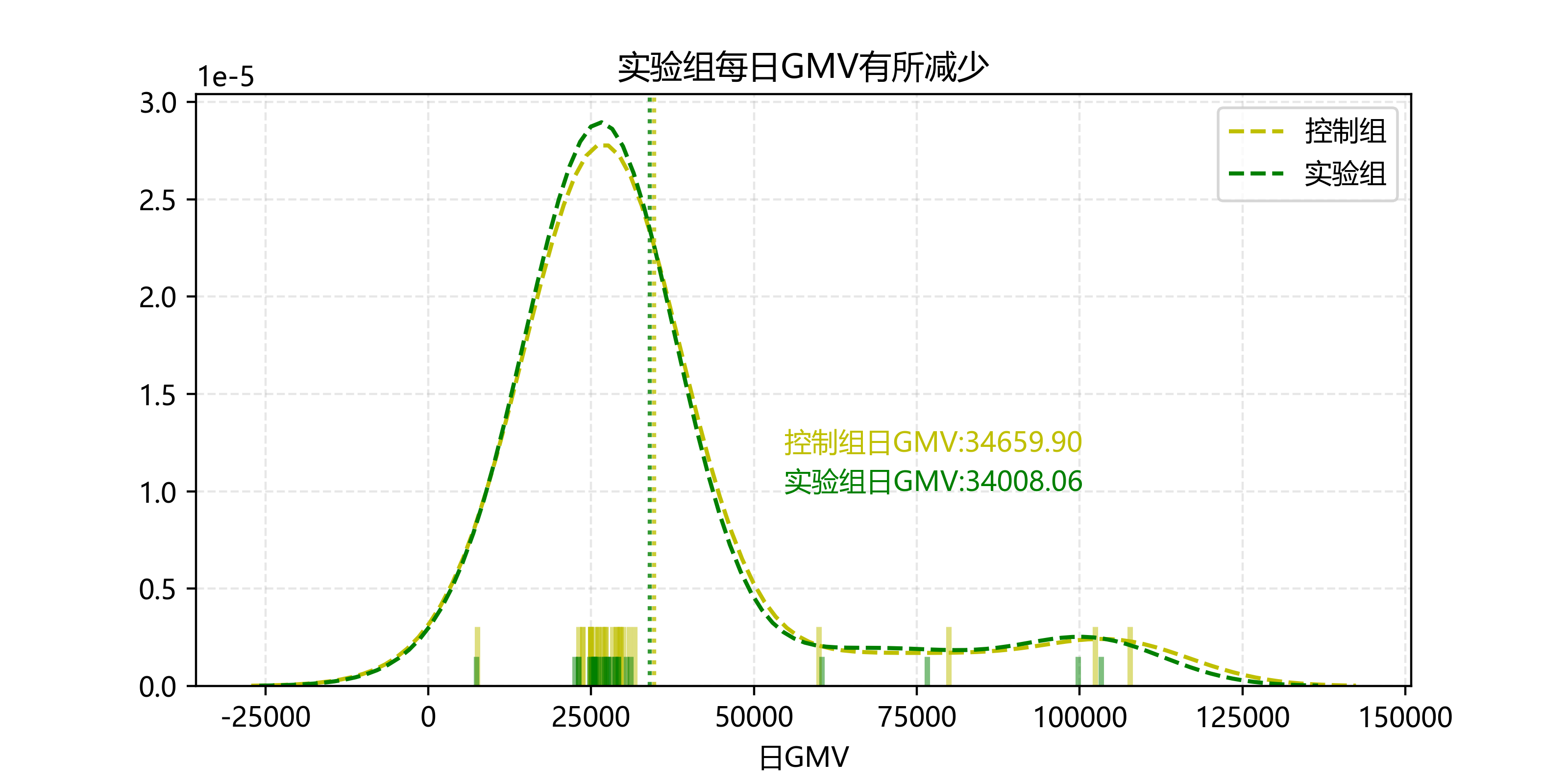
可以看出实验组和控制组的GMV分布几乎无差,实验组略低于控制组。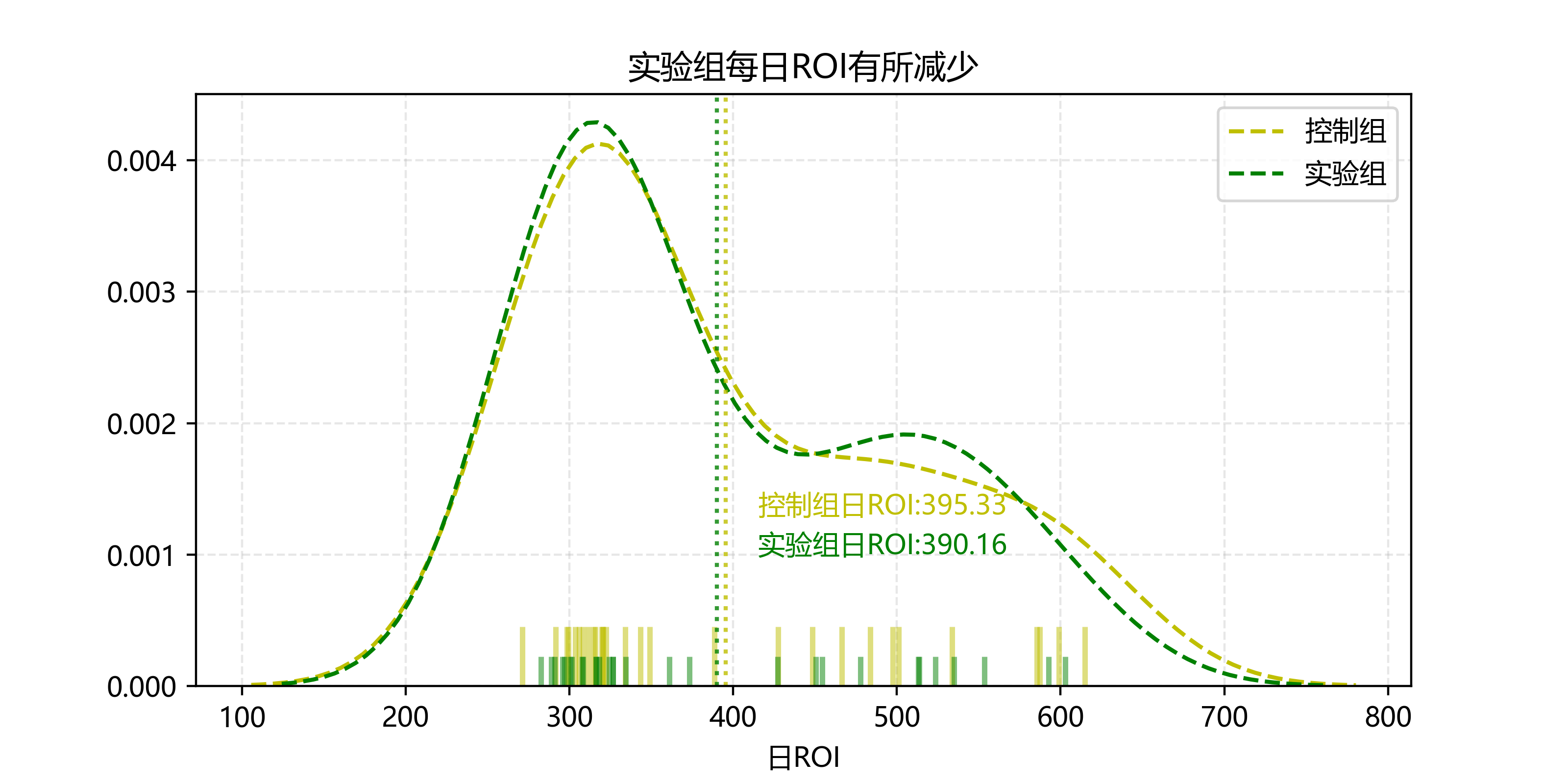
实验组每日ROI均值低于控制组。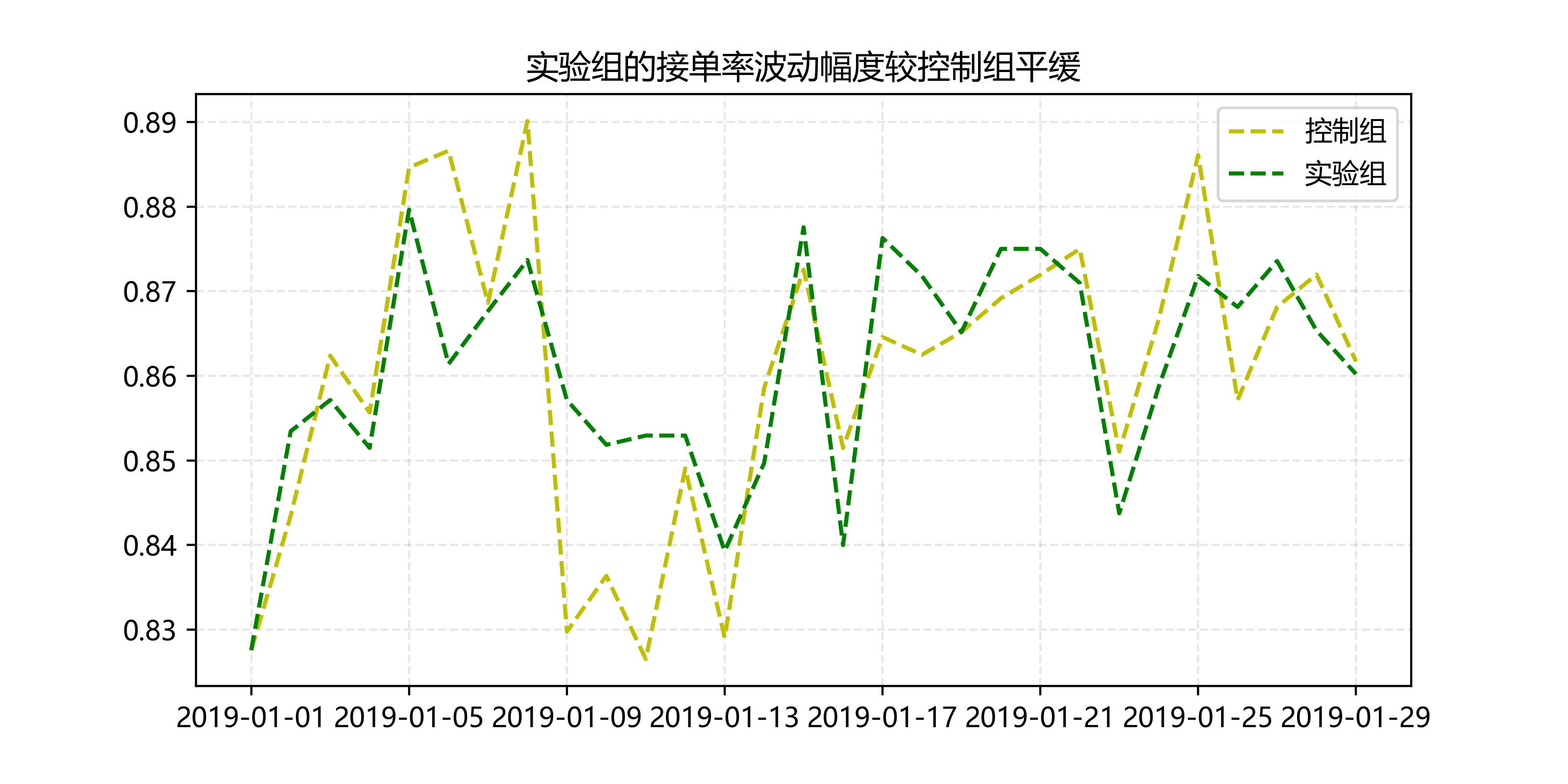
两组的接单率相差不大,但是实验组的振幅较小。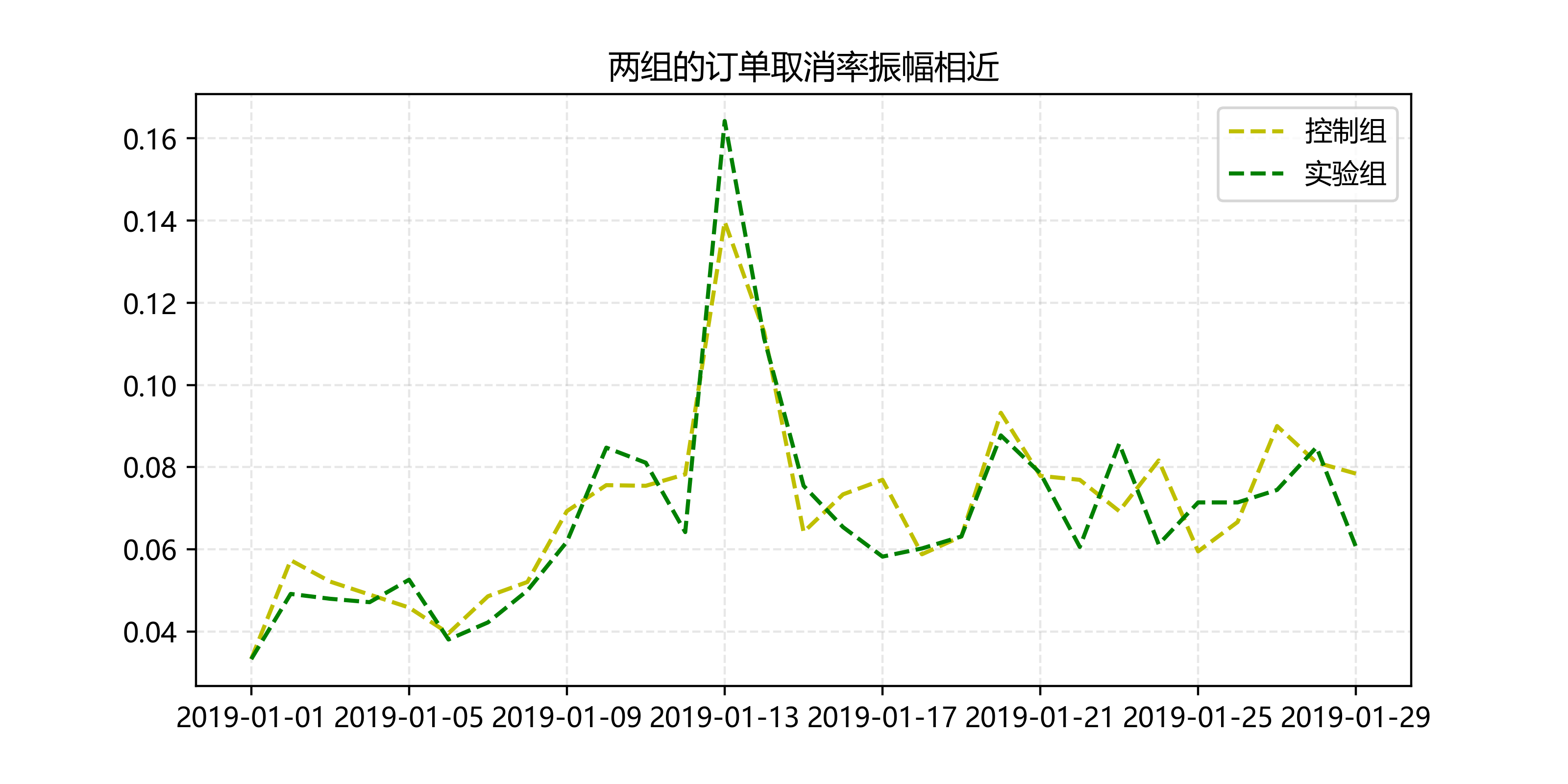
两组的订单取消率无显著差异。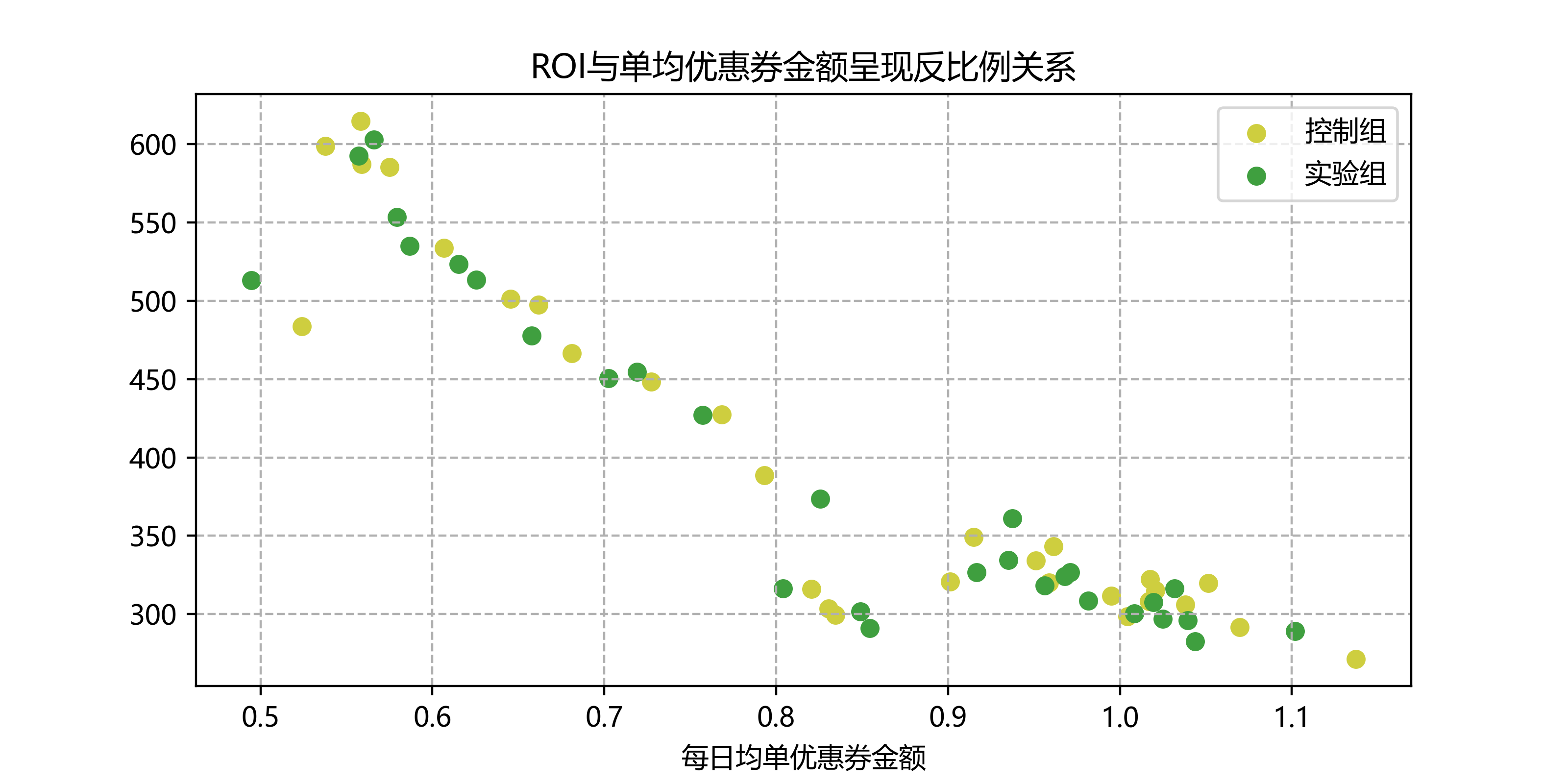
这个嘛,为什么ROI会和每日均单优惠券金额呈现反比关系呢,合着意思是不花钱ROI能最高?
城市运营情况分析
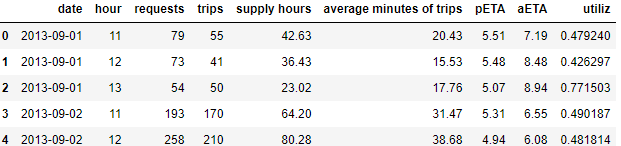
根据已给定的维度,我们来考虑一下可以从那几个角度来分析呢:
- 时间角度:每日、每时段、周内周末指标对比,周、月同环比
- 司机角度:接单率、平均订单时长、可服务时长、在忙率
- 用户角度:请求量、取消率、等待时长
根据上面几个角度,暂且提出以下问题:
- 给定数据统计范围内的运营情况走势如何
- 乘客用车高峰期是那个时期,运力能否满足乘客需求
- 顾客预计与等待时间的差异
- 均单时长分布
请求数与订单数呈周期性变化,订单数少于请求数
初步猜测峰值部分应该是周末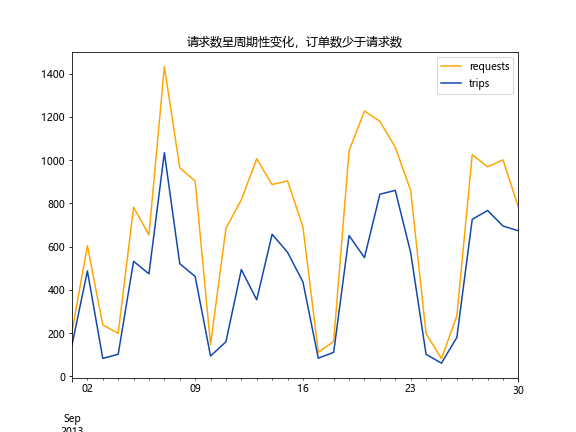
12点的订单请求数最多,接单率稳步下跌,运力不足
- 中午12点客户的订单请求数最多
- 司机的接单率在11-13点这个时间段内呈现下跌趋势
- 13点的接单率低至47%,即半数多的订单都没有接受,考虑是否是因为司机午休或者在忙,所以导致实际可载客的车辆较少
初步认为在11-13点这个时间段内运力是明显不足的,如果有地理信息的话,可以确定这个时段在哪一个区域急需增加运力。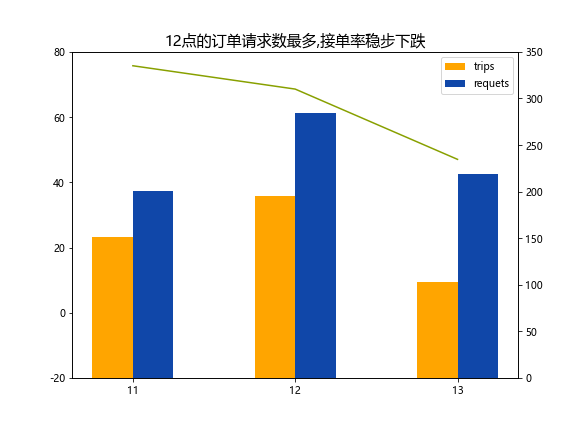
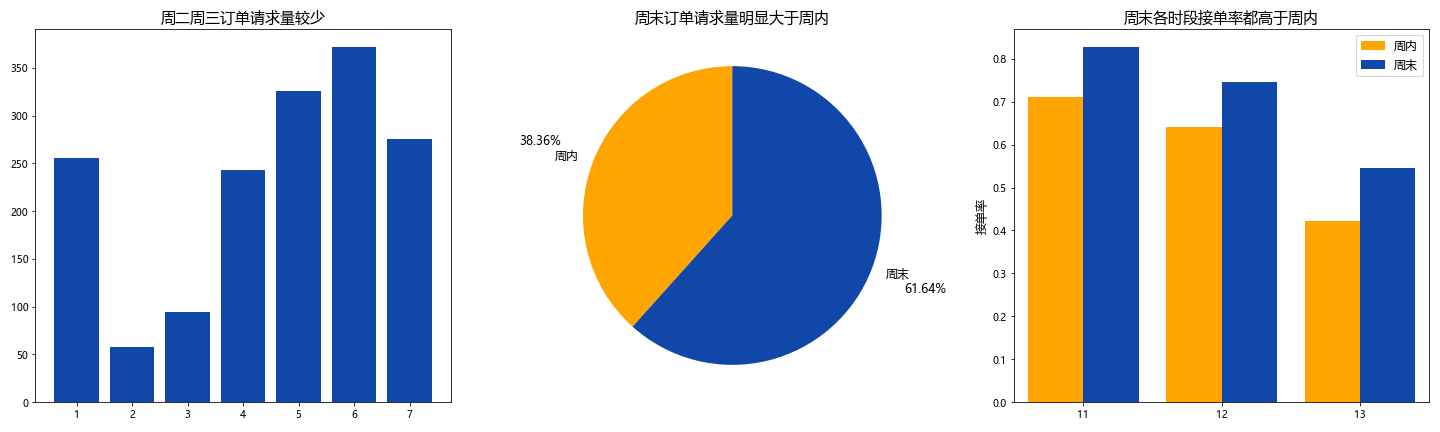
周末请求数远高于周内,周六是用车高峰
- 周二周三的订单请求量最少,其余各天请求量相差不大,周五周六请求量最多
- 周末的请求量明显大于周内
- 周末各时段司机接单率都高于周内
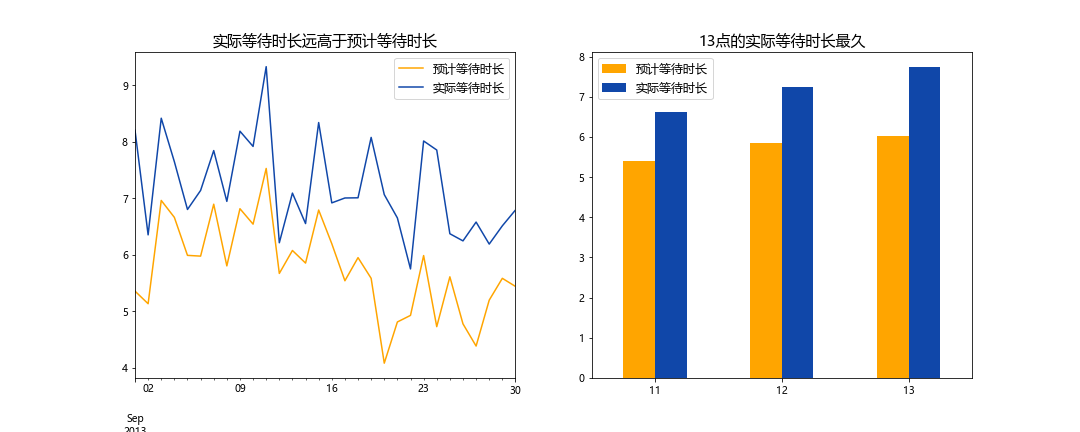
实际等待时长远高于预计等待时长
- 统计时段内顾客实际等待时长逐渐减少,可能是配送车辆增加,优化了路线
- 11-13点这段时间内实际等待时长逐渐增加,13点的实际等待时长最久
- 预计等待时长与实际等待时长相差过大,仍需要迭代更新时间预估模块,优化派单逻辑
- 实际等待时间长可能是司机都在忙,运力不足
12点均单时长最长
11、13点这两个时段的均单时长较短,12点的均单时长最长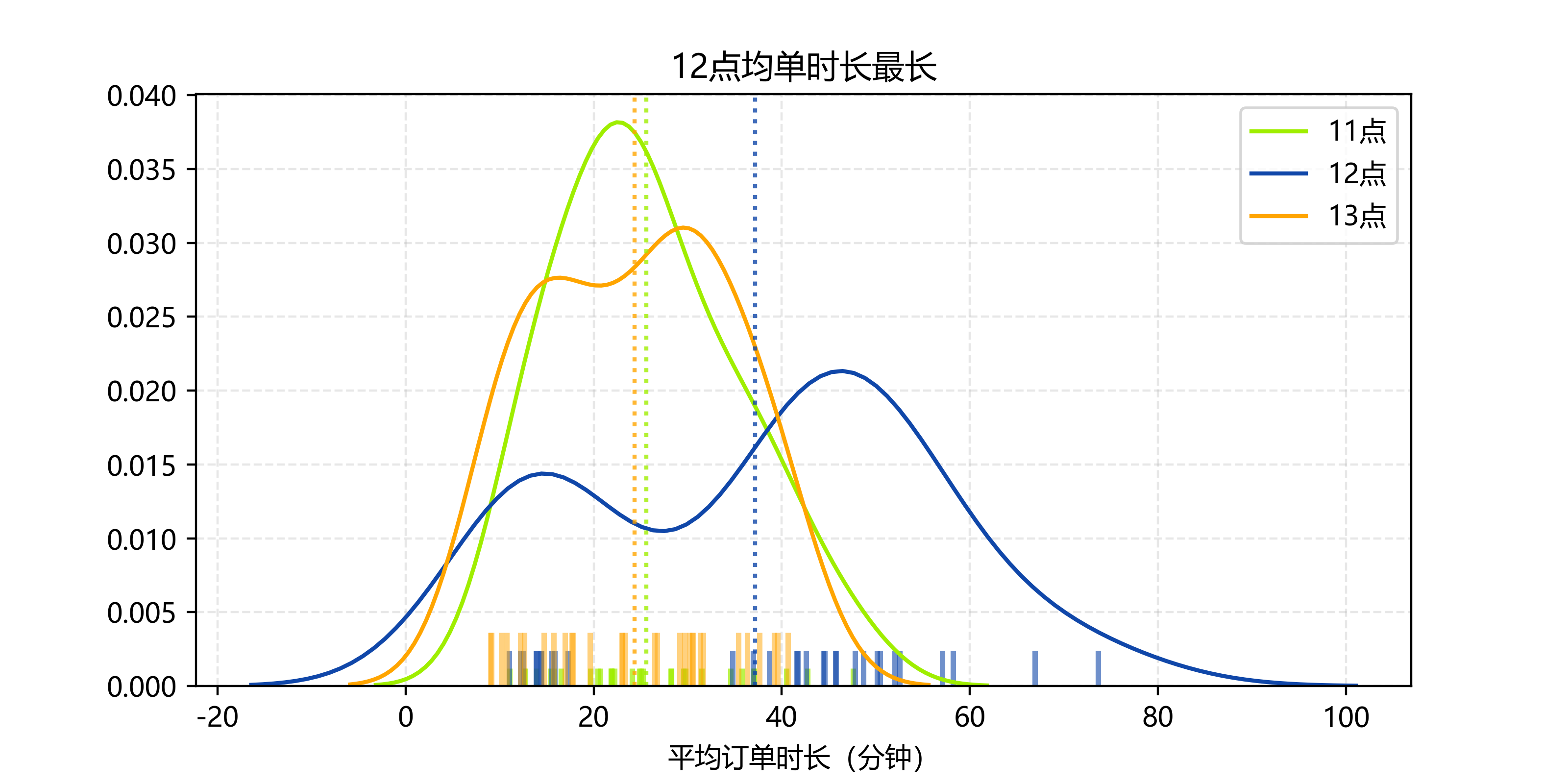
12、13点司机在忙率较高
可以认为是12、13点司机在忙率较高,所以导致了12、13点的接单率下降,顾客实际等待时间增加。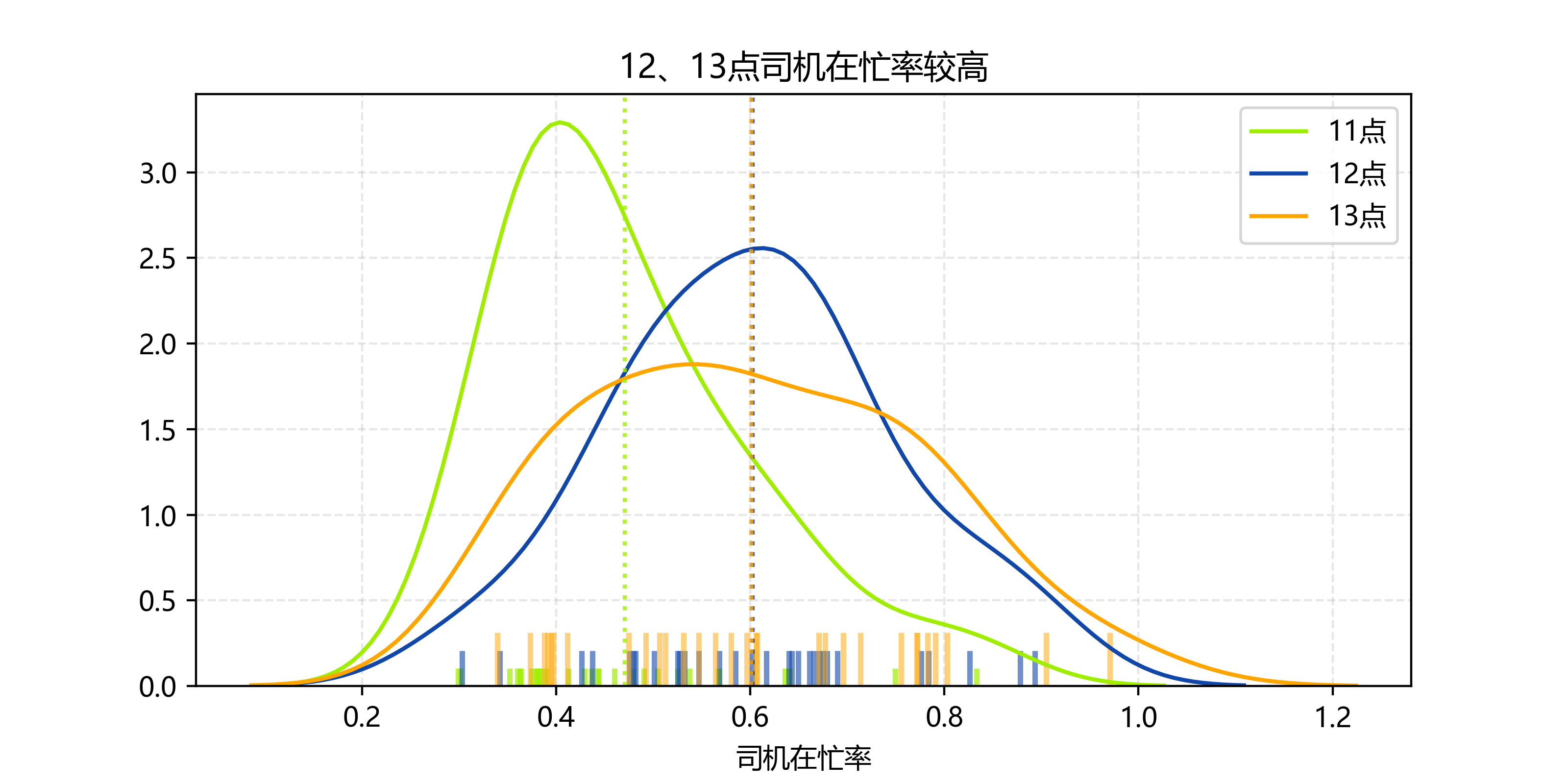
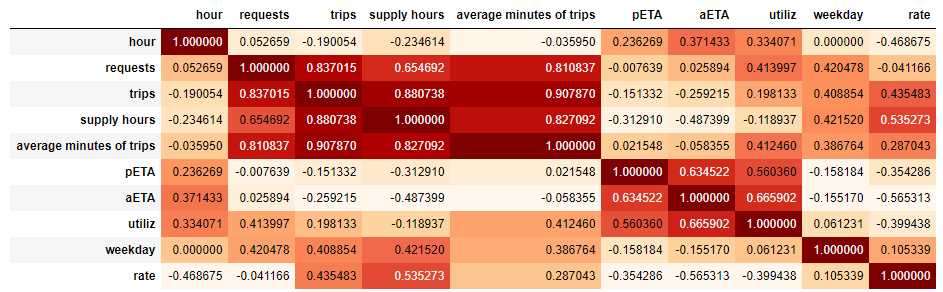
相关性检测
city['rate']=city.trips/city.requests
city.corr().style.background_gradient('OrRd')
可服务时长与订单数呈正相关性
因为滴滴有防疲劳驾驶的限制,所以这两个维度的正相关性是很容易理解的。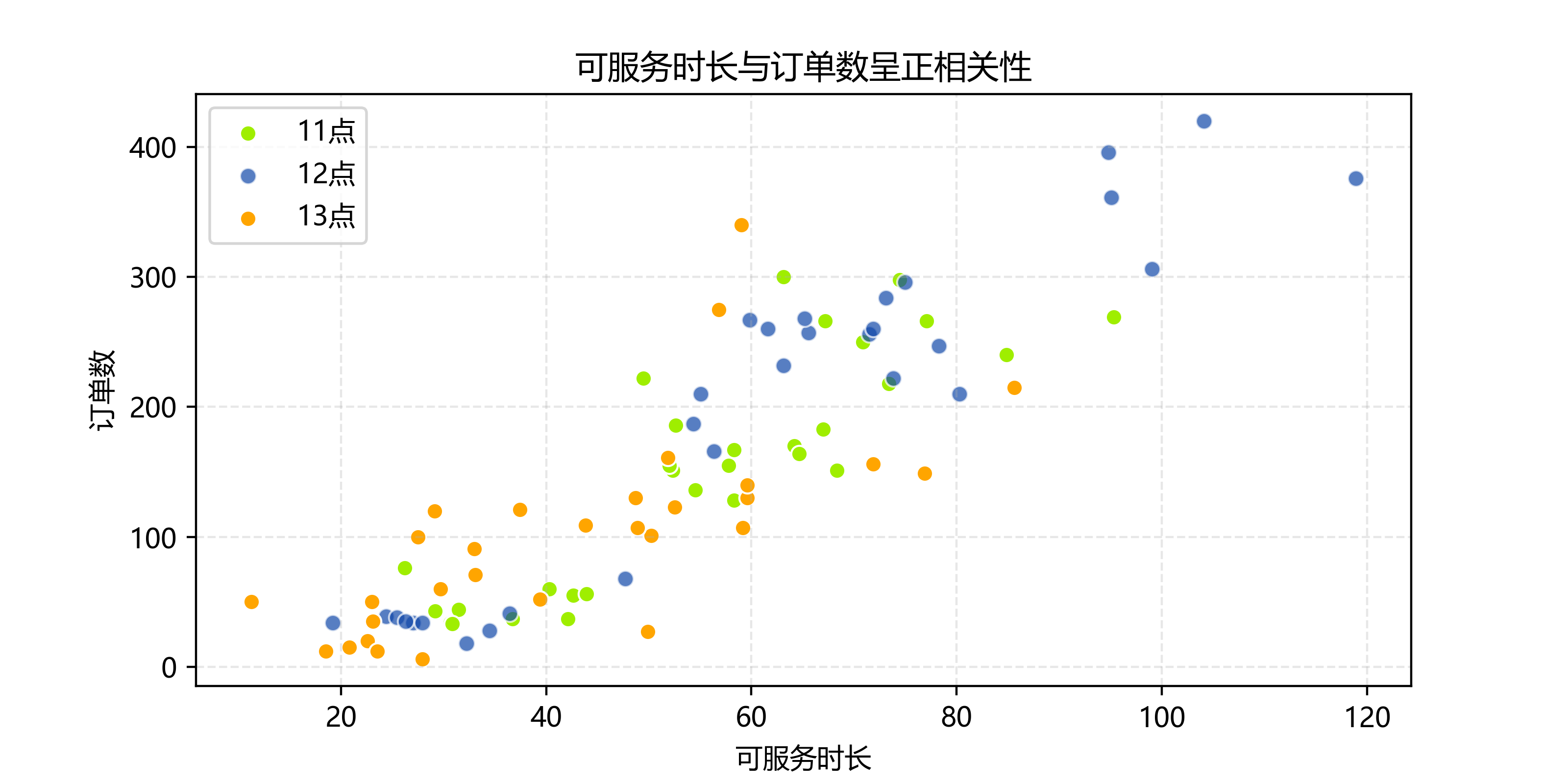
总结
- 统计周期内的运营情况呈现周期性波动,周末的订单请求数较多,周二周三的订单量较少,中午12点的请求量最多
- 周末各时段接单率都高于周内,但仍随着时间推移接单率下降
- 预计等待时长与实际等待时长存在一定差异,实际等待时长随着时间推移而增加,13点的实际等待时长最久
- 12点均单时长最长,接单率下降幅度较少,11点的均单时长稍长于13点,但接单率远高于13点。
- 司机在忙率的提高导致接单率下降,顾客等待时长增加。
建议
- 提高运力,增加司机及配车,减少高峰时段的运营压力
- 优化时间预计算法,提高用户体验,优化订单分配及路线规划算法,提高司机的抢单及接送速度
- 适当发放限时优惠券,限定在12点之前使用,减少12、13点的接单压力
- 适当增加12、13点时间段内对于司机的补贴,加快接单速度,提高运营效率
关注一波吧!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)