Nvidia联合多所大学首个能自我Debug、经验传代的机器人框架ASPIRE来了!
过去我们常说,传统的机器人编程或模型微调极其消耗算力和人力,一旦环境改变就容易“抓瞎”。但就在最近,NVIDIA 联合多所高校推出的 ASPIRE 框架]直接打破了这个僵局,实现了高达 31% 的零样本长任务成功率!
作为一个长期泡在算法一线的搬砖人,看完这篇论文后我连夜做了拆解。这个技术背后的演进逻辑、闭环设计到底妙在哪里?对我们未来的AI落地又有什么深远影响?今天这篇硬核干货,带你一探究竟!
文章链接:ASPIRE: Agentic /Skills Discovery for Robotics
传统的机器人编程难以扩展。它需要手动协调多模态感知、物理接触动态、各种配置以及执行故障。而“代码即策略(Code-as-Policy)”系统则允许语言模型将这些因素组合成可执行的机器人程序。这使得机器人行为可检查、可编辑和可调试。
但现有的机器人编码代理运行在较为简陋的执行环境中。它们只能接收到粗略的、任务级别的反馈。一次失败的部署仅仅表明任务失败,而没有揭示失败的原因。根本原因可能在于感知、运动规划、抓取、接触动力学或长距离协调等方面。此外,这些系统在任务结束后还会丢弃已修复的代码。因此,即使代理完成了第一百次任务,其经验也并不比第一次任务时丰富。
由英伟达(NVIDIA)、密歇根大学、伊利诺伊大学香槟分校、加州大学伯克利分校和卡内基梅隆大学的研究团队推出了 ASPIRE(通过迭代机器人探索实现智能体技能编程)。它是一个持续学习系统,能够编写和改进机器人控制程序。它还能将经过验证的修复方案提炼成一个可重用、可迁移的技能库。
ASPIRE 的工作原理
ASPIRE 运行一个包含三个组件的开放式学习循环。它采用协调器-执行器(Coordinator-Executor)架构。中央协调器管理共享技能库,并将执行器编码代理派往各个任务。执行器之间不交换完整的聊天记录或原始轨迹,只交换精简后的技能。
- 闭环机器人执行引擎:它用基于基本单元的多模态轨迹取代了粗略的滚动反馈。对于每次感知、规划和控制调用,它都会存储输入、输出和返回状态。此外,它还会存储 RGB 关键帧、叠加层、抓取候选对象、物体姿态和运动规划结果。智能体仅检查与故障相关的调用。然后,它定位故障并通过重新执行来验证修复效果。
- 技能库:可重用知识很少是完整的任务程序。因此,技能库存储各种异构的修复方案。这些方案包括定位启发式方法、感知提示、抓取约束、运动基元和调试工作流程。每个技能都是简洁的上下文指导。它包含故障特征、应用条件、修复策略,通常还包含代码草图。协调器只允许通过调试验证和 API 策略检查的模式通过。
- 进化搜索:仅靠跟踪引导的调试可能会陷入局部修复循环。智能体会不断地修补同一个失败的策略。为了扩大探索范围,ASPIRE 每轮都会提出 K 个候选程序。候选程序基于之前表现最佳的程序及其剩余的故障跟踪信息。下一轮将探索不同的策略,而不是改进某个解决方案。
在模拟中,编码代理是 Claude Code,使用 Claude Opus 4.6 和 100 万个令牌(Tokens)的上下文窗口。程序使用 CaP-X 编写,这是一个基于 MuJoCo Playground 构建的开源“代码即策略”框架。该代理无法读取模拟器的真实数据。读取物理引擎状态或资源文件(例如 .py、.bddl、.xml 或 .urdf)是被禁止的。规则很简单:如果一个带有摄像头的真实机器人可以做到,那么它就可以做到。
交互式讲解器
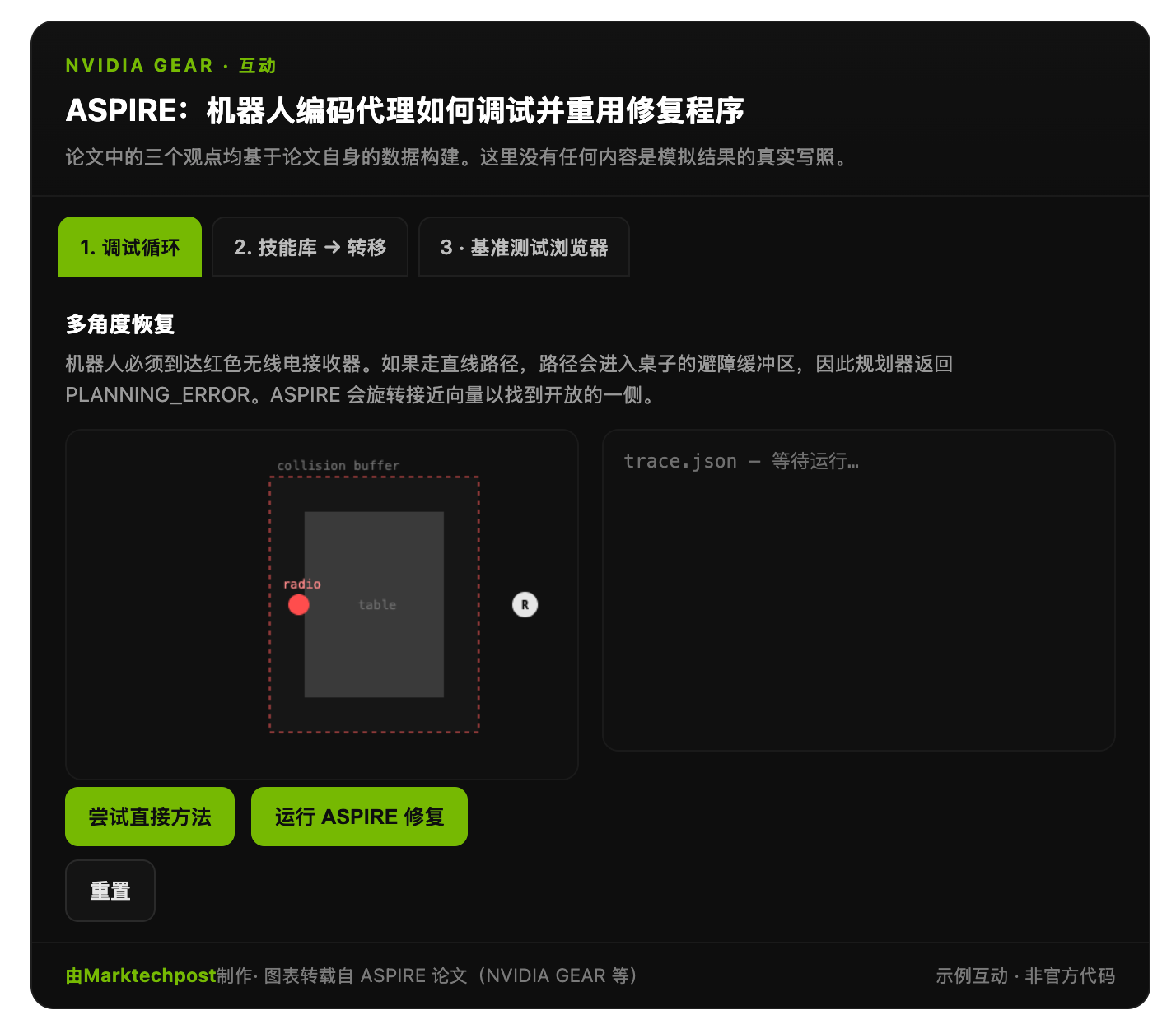

一个实际案例:多角度方法技能
考虑一个 BEHAVIOR-1K 任务,机器人必须从桌子附近拾取一个收音机。感知器返回了收音机的位姿,但重复调用 navigate_to_pose 失败。生成的目标位置距离桌子边缘约 20 厘米。这落在了桌子的避障缓冲区内,cuRobo 返回 PLANNING_ERROR 错误。
代理读取轨迹并定位故障原因。故障原因是目标不可行,而非感知或抓取失败。然后,它编写一个修复程序,对无线电设备周围的各种对峙姿态(Standoff Poses)进行采样。
# radio_pos, safe_navigate() and dist_to() are provided by ASPIRE's robot API
for angle_deg in [180, -90, 90, -45, 45]:
angle = np.radians(angle_deg)
tx = radio_pos[0] + 0.7 * np.cos(angle) # standoff 0.7 m from the radio
ty = radio_pos[1] + 0.7 * np.sin(angle)
face_yaw = np.arctan2(radio_pos[1] - ty, radio_pos[0] - tx)
moved = safe_navigate([tx, ty, face_yaw], f"ang_{angle_deg}")
if moved and dist_to(radio_pos[:2]) < 0.8: # reached a pose within 0.8 m
break
每个角度都将目标置于物体的不同侧面。当一侧被遮挡时,另一侧通常畅通无阻。此处,180 度姿态可以清除缓冲区。经验证的定位方法被认为是一种可重复使用的导航恢复技能。
基准测试和结果
ASPIRE 在三个基准测试集上进行评估。LIBERO-Pro 测试在物体、目标和空间扰动下的短期鲁棒性。Robosuite 涵盖了接触丰富的单臂和双臂操作。BEHAVIOR-1K 涵盖了长期家庭移动设备操作。主要的编码代理基线是 CaP-Agent0。它使用视觉差分、预定义的技能库以及每次测试的重试机制。比较还包括端到端的视觉-语言-动作(VLA)策略:OpenVLA、 π 0 \pi_0 π0 和 π 0.5 \pi_{0.5} π0.5。
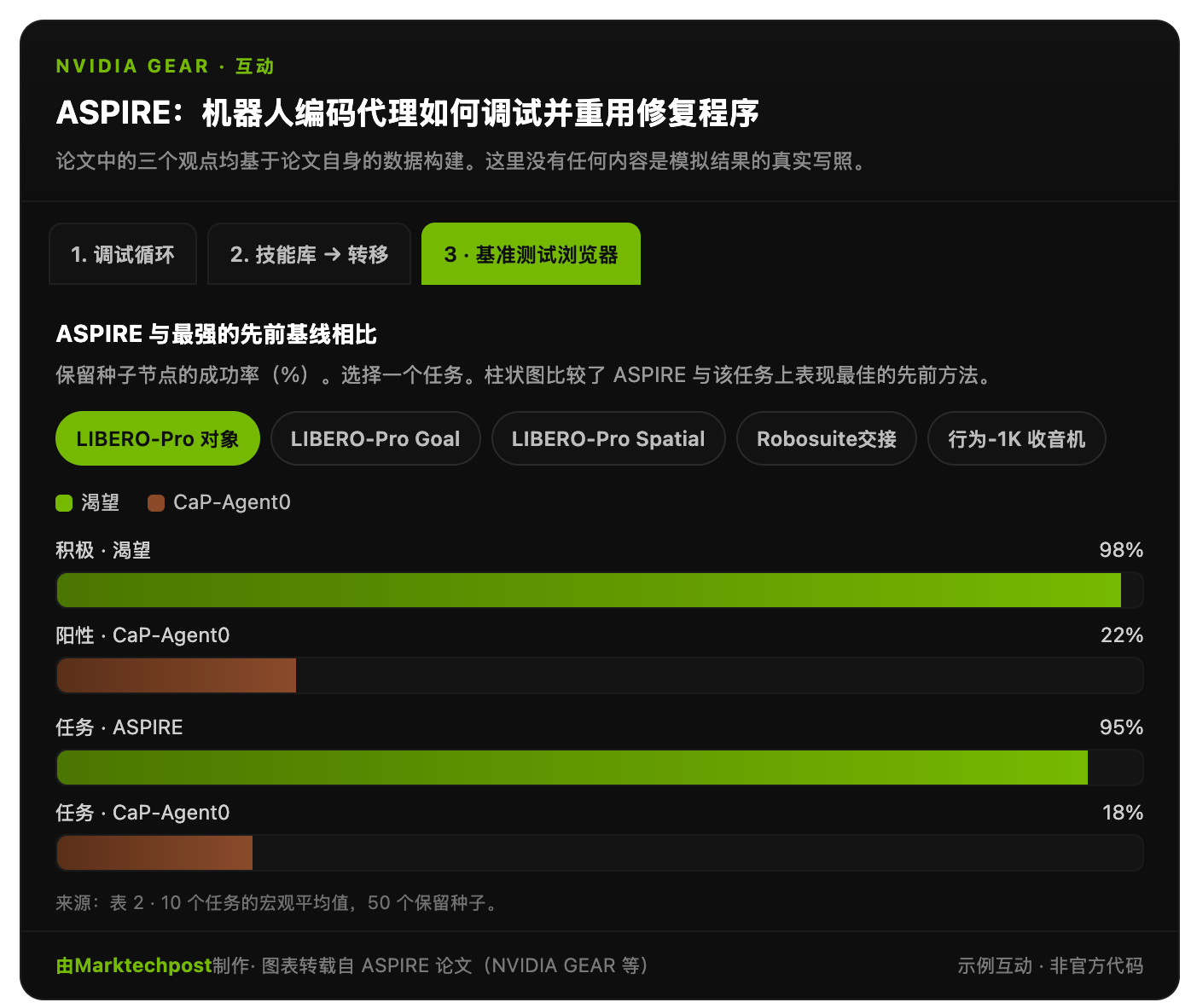
在 LIBERO-Pro 测试中,ASPIRE 在物体任务组上最多可提升 77 分(该数值是相对于最强基线在两个扰动轴上的平均值)。它在目标任务上也提升了 41.5 分,在空间任务上提升了 42.5 分。在 Robosuite 测试中,双手动交接的成功率从 20% 提升至 92%。在 BEHAVIOR-1K 测试中,无线电拾取任务的成功率从 56% 提升至 88%。
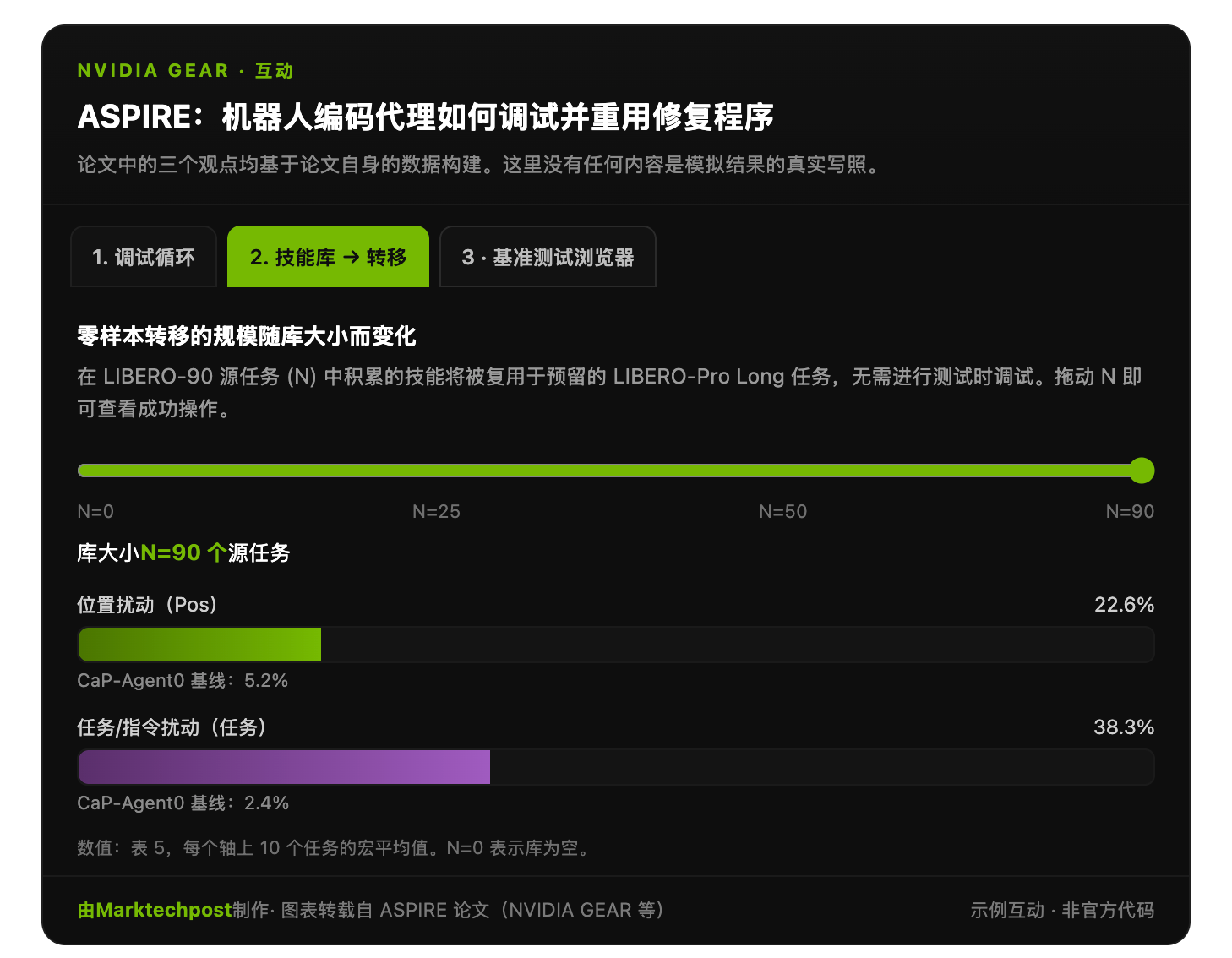
零样本(Zero-shot)结果令人瞩目。ASPIRE 能够重用在 LIBERO-90 任务中积累的技能,在保留的 LIBERO-Pro Long 任务中达到约 31% 的准确率。而以往方法的准确率则接近 4%。
| 方面 | 端到端 VLA(OpenVLA、 π 0 \pi_0 π0、 π 0.5 \pi_{0.5} π0.5) | CaP-Agent0 | ASPIRE |
|---|---|---|---|
| 范例 | 学习权重策略 | 代码即策略代理 | 代码即策略代理 |
| 跨任务经验 | 无(冻结权重) | 每次任务完成后丢弃 | 提炼成技能库 |
| 失败反馈 | 测试时未发现 | 粗略的场景级概要 | 每个原始多模态轨迹 |
| 测试时间策略 | 直接推断 | 基于种子值的推理 + 重试 | 每个任务一个程序 |
| LIBERO-Pro 总体 | 0–13% | 18% | 72% |
| LIBERO-Pro 长零样本 | 0-5% | 约 4% | 约 31% |
真实机器人技能转移
研究团队在一台真实的双手动 YAM 工作站上测试了三项通过模拟发现的技能。该真实机器人的编码代理是 OpenAI Codex GPT-5.5。其具体实现和 API 与模拟环境有所不同。
迁移技能显著降低了调试成本。例如:
- 在减少约 10 倍 Token 消耗的情况下,拿起汽水罐的成功率从 13/20 提高到 19/20。
- 打开抽屉的成功率从 0/20 提高到 11/20,而未掌握技能的基线模型从未成功打开过抽屉。
要点总结
- ASPIRE 编写和调试机器人程序,然后将经过验证的修复程序保存为可重用的上下文技能。
- 每个原始多模态轨迹使代理能够定位故障,而不是根据部署结果进行瞎猜。
- 它在 LIBERO-Pro 上最多可获得 77 分的提升,并将 Robosuite 双手交接成功率从 20% 提高到 92%。
- LIBERO-Pro Long 的零样本转移率达到约 31%,而之前的方法仅约为 4%。
- 通过仿真发现的技能,降低了在不同实现方式和 API 下真实机器人的调试成本。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)