深度学习项目训练环境低成本部署:在24G显存消费级显卡上稳定运行大型模型训练
深度学习项目训练环境低成本部署:在24G显存消费级显卡上稳定运行大型模型训练
1. 引言
如果你正在为深度学习项目寻找一个稳定、开箱即用的训练环境,特别是手头只有一块24G显存的消费级显卡(比如RTX 4090),那么这篇文章就是为你准备的。
很多朋友在开始深度学习项目时,最头疼的就是环境配置。从CUDA版本、PyTorch安装,到各种依赖库的兼容性问题,往往要折腾好几天才能把环境跑起来。更不用说在消费级显卡上训练大型模型时,经常会遇到显存不足、训练不稳定的情况。
今天我要分享的这个深度学习训练环境镜像,就是专门为解决这些问题而设计的。它基于我的《深度学习项目改进与实战》专栏,预装了完整的开发环境,你只需要上传训练代码和数据集,就能立即开始训练。更重要的是,这个环境经过优化,能够在24G显存的消费级显卡上稳定运行大型模型训练,让你用有限的硬件资源也能做有深度的研究。
2. 环境配置与核心优势
2.1 环境说明
这个镜像已经为你配置好了深度学习训练所需的所有基础环境:
- 核心框架:PyTorch 1.13.0
- CUDA版本:11.6(完美支持RTX 40系列显卡)
- Python版本:3.10.0
- 主要依赖库:
- torchvision==0.14.0
- torchaudio==0.13.0
- cudatoolkit=11.6
- numpy、opencv-python、pandas
- matplotlib、tqdm、seaborn等常用工具
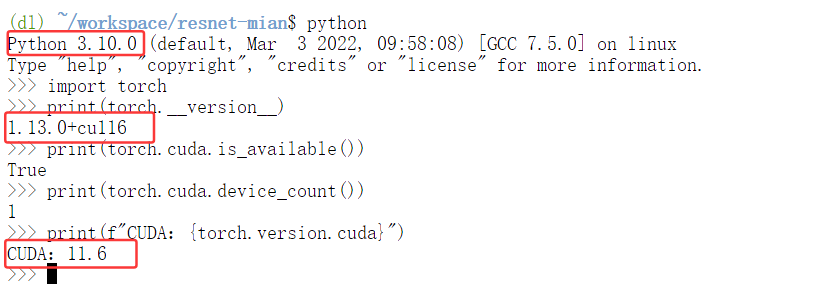
所有这些都是预装好的,你不需要再一个个安装,省去了大量的配置时间。
2.2 为什么选择这个环境?
你可能会有疑问:网上那么多深度学习环境教程,为什么还要用这个镜像?我总结了几点核心优势:
开箱即用,零配置成本 传统的环境搭建需要你手动安装CUDA、配置环境变量、安装PyTorch和各种依赖库。这个过程不仅耗时,还容易出错。这个镜像把这些步骤都提前做好了,你拿到手就能用。
针对消费级显卡优化 很多官方教程都是基于服务器级显卡(比如A100、V100)来写的,在消费级显卡上直接套用可能会遇到各种问题。这个环境专门针对24G显存的消费级显卡做了优化,包括:
- 内存使用优化,避免显存溢出
- 训练稳定性增强
- 混合精度训练配置
完整的训练工具链 不仅仅是训练环境,还包括了模型验证、剪枝、微调等全套工具。你可以在同一个环境中完成从训练到优化的整个流程,不需要在不同环境间切换。
灵活可扩展 虽然基础环境已经配置好了,但如果你需要额外的库,可以随时安装。环境基于Conda管理,添加新库非常方便。
3. 快速上手:从零开始训练你的第一个模型
3.1 环境激活与准备工作
启动镜像后,你会看到这样的界面:
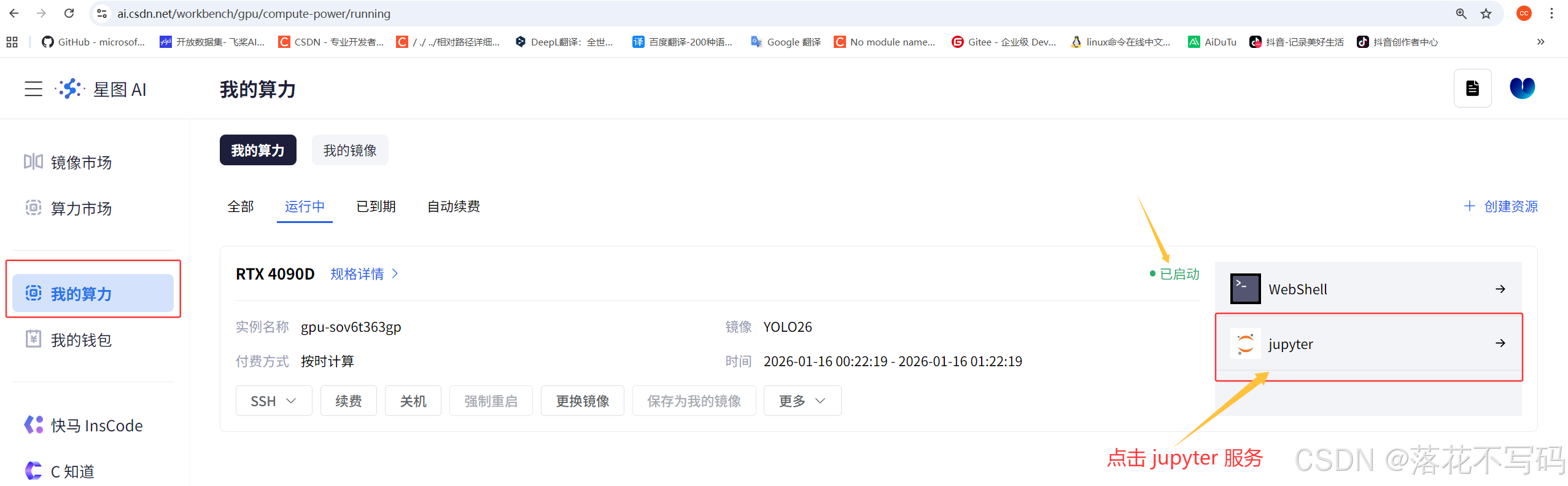
启动完成后是这样的:
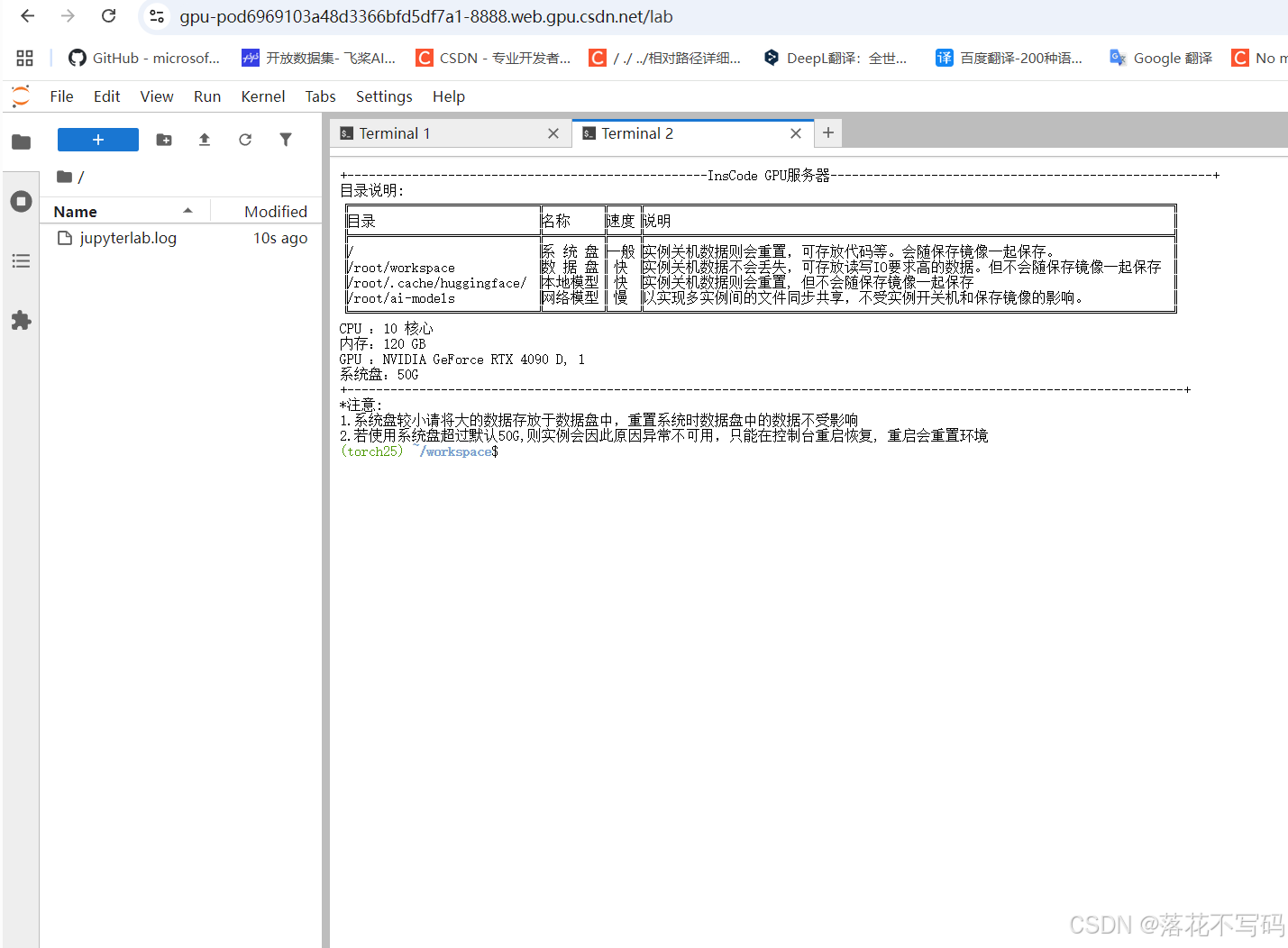
第一步:激活Conda环境
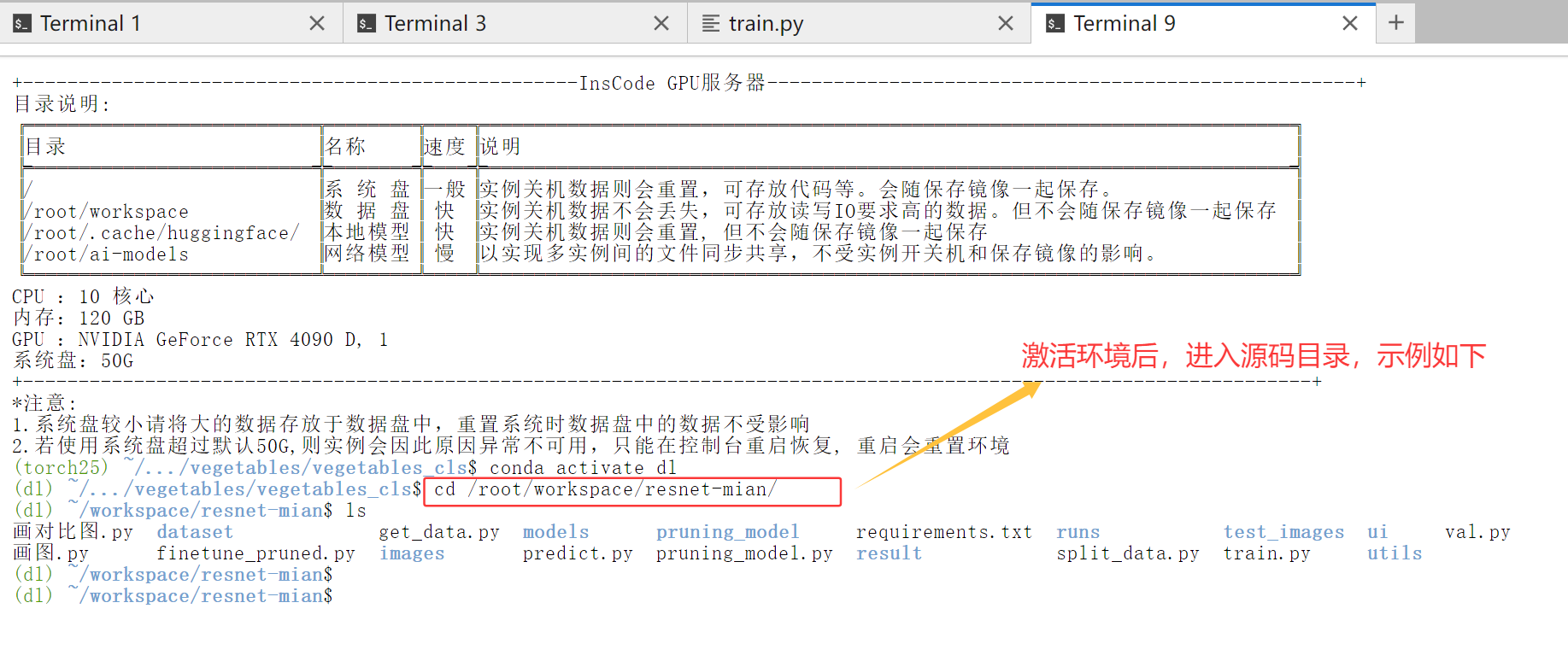
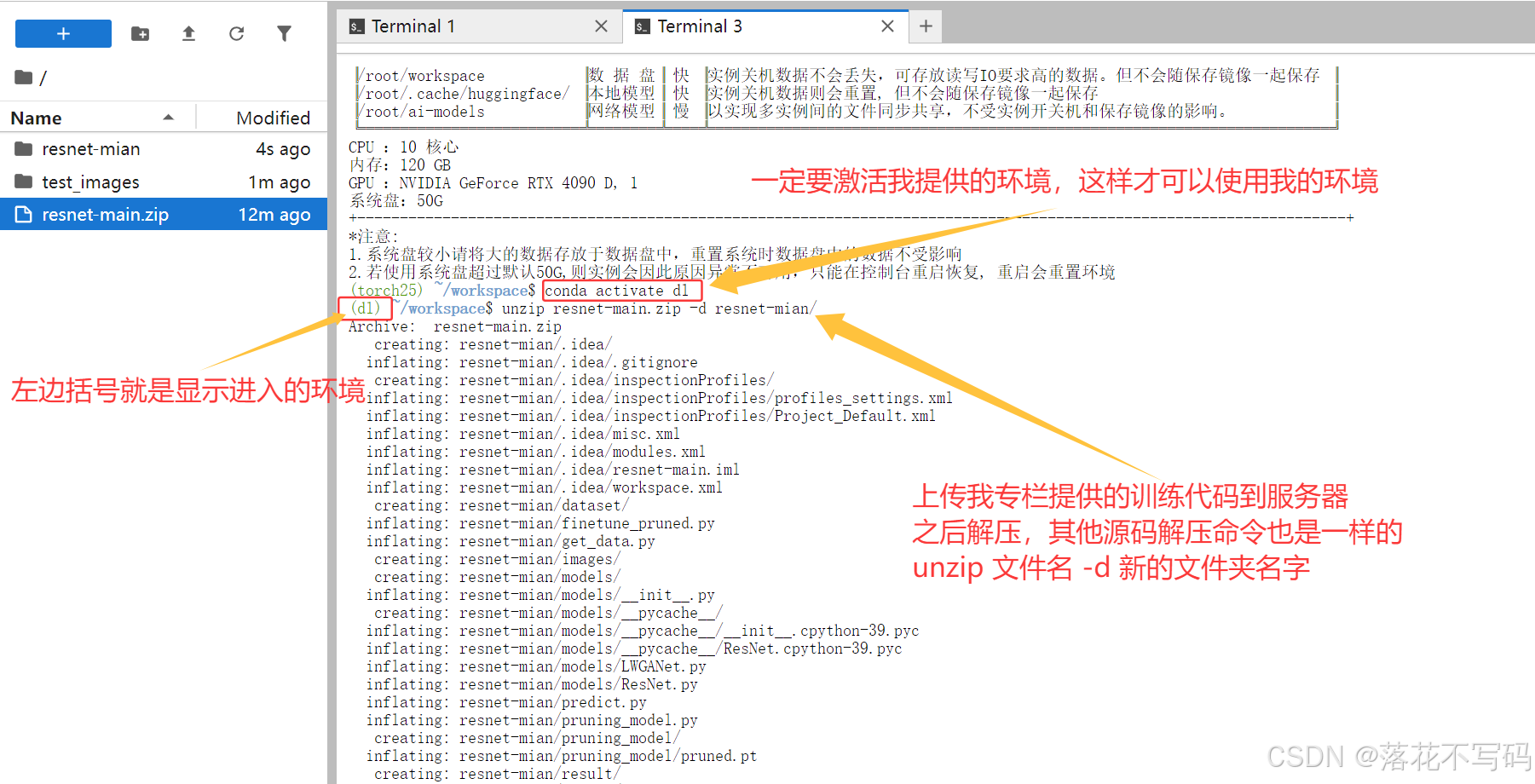
镜像里已经配置好了一个名为dl的Conda环境,里面包含了所有必要的依赖。使用前需要先激活这个环境:
conda activate dl
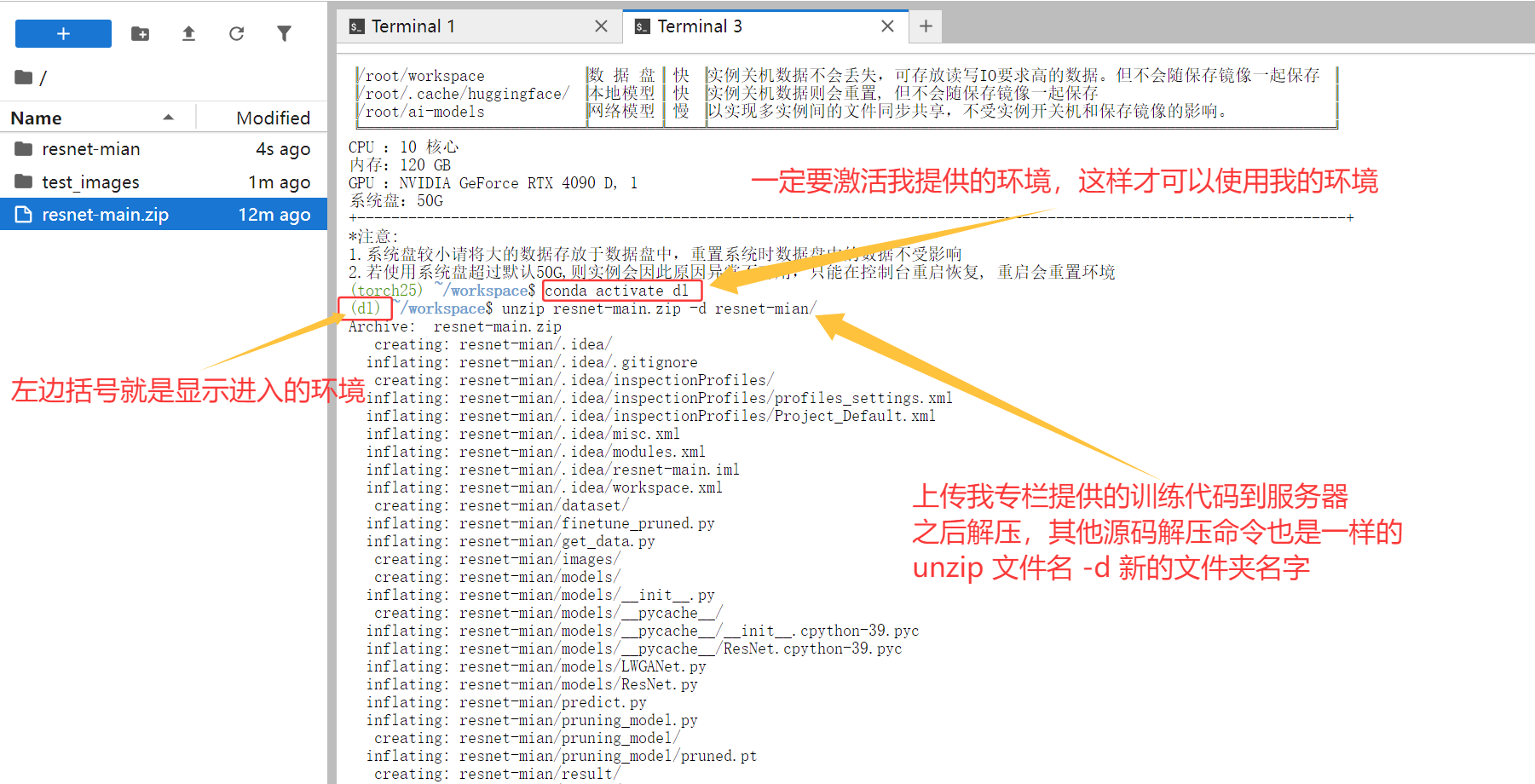
看到命令行前面出现(dl)就说明环境激活成功了。
第二步:上传代码和数据
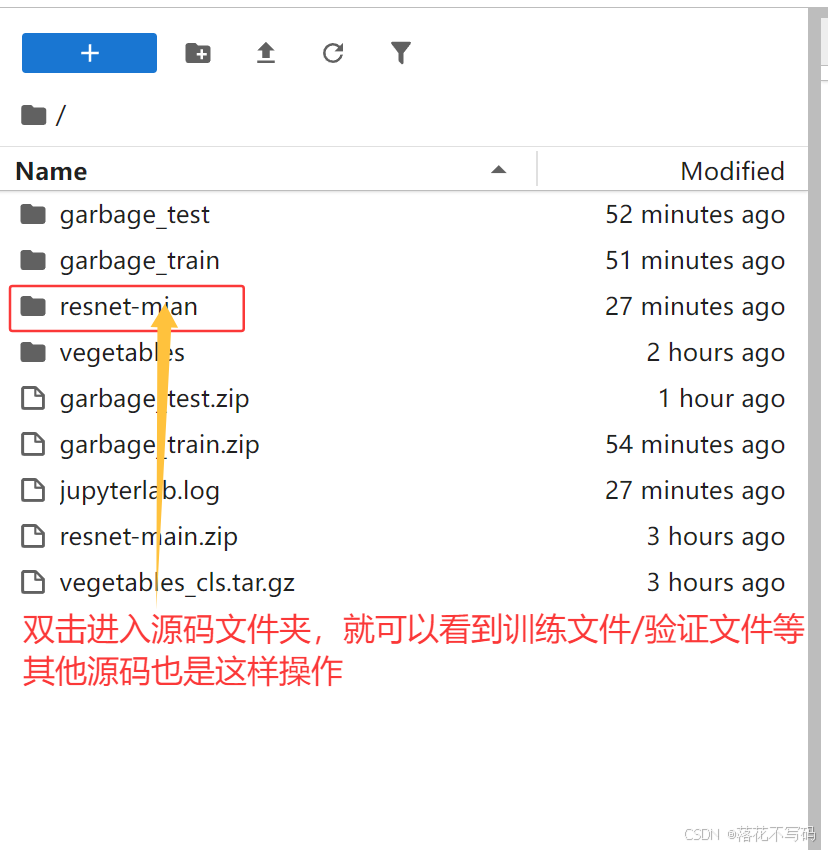
我建议使用Xftp这样的工具来上传文件。把专栏提供的训练代码和你自己的数据集上传到数据盘(这样即使容器重启,数据也不会丢失)。
上传完成后,进入你的代码目录:
cd /root/workspace/你的代码文件夹名称
3.2 数据集准备与解压
深度学习项目离不开数据。这里给你介绍两种常见压缩格式的解压方法:
解压.zip文件:
unzip 文件名.zip -d 目标文件夹
例如,如果你有一个dataset.zip文件,想解压到data文件夹:
unzip dataset.zip -d ./data
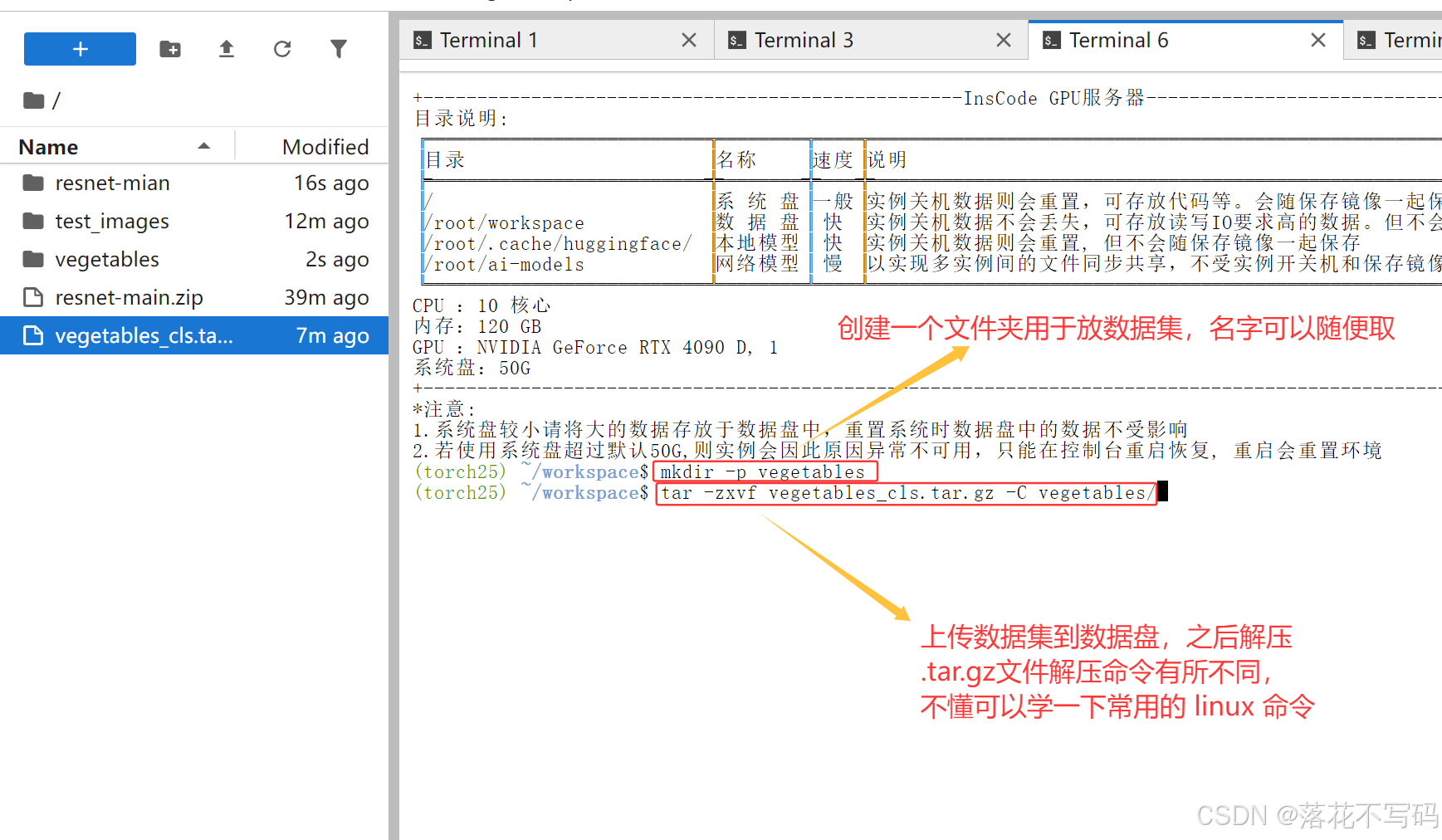
解压.tar.gz文件:
解压到当前目录:
tar -zxvf vegetables_cls.tar.gz
解压到指定目录:
tar -zxvf vegetables_cls.tar.gz -C /home/user/data/
3.3 开始模型训练
数据集准备好之后,就可以开始训练了。以分类任务为例,你需要修改train.py文件中的一些参数,主要是数据路径和训练配置。
这是我的一个训练文件示例:
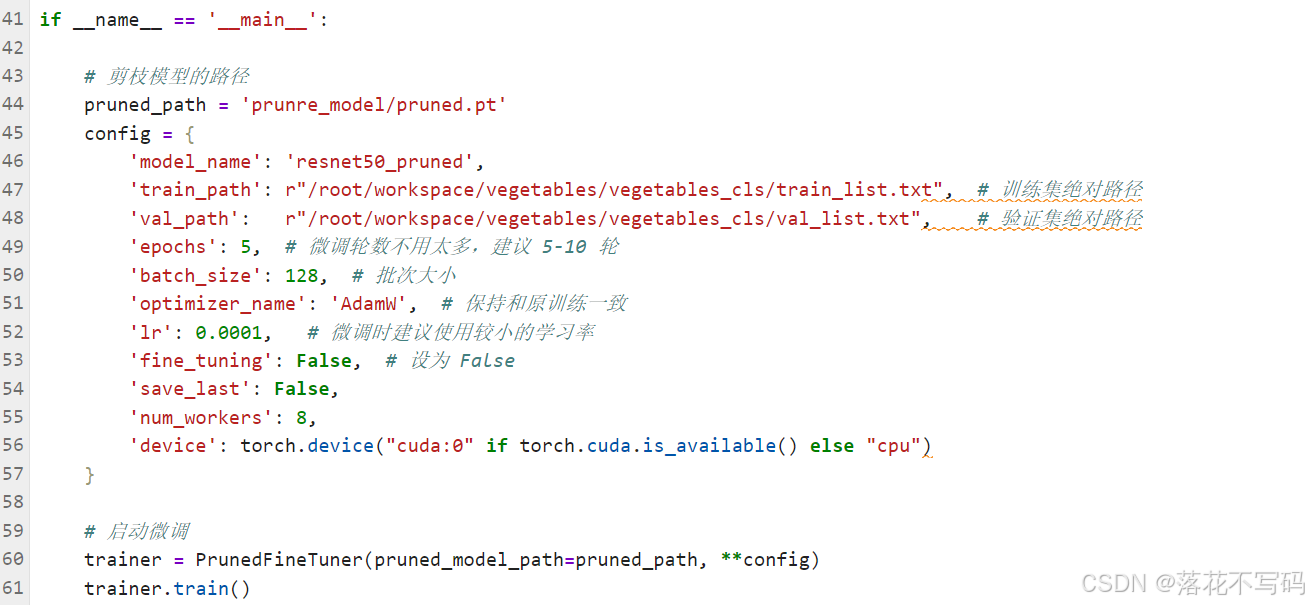
关键参数通常包括:
data_path:数据集路径batch_size:批大小(根据显存调整)epochs:训练轮数learning_rate:学习率
修改完成后,在终端运行:
python train.py
训练过程会实时显示损失、准确率等指标:

训练完成后,模型权重会自动保存。你可以用提供的画图代码可视化训练过程:

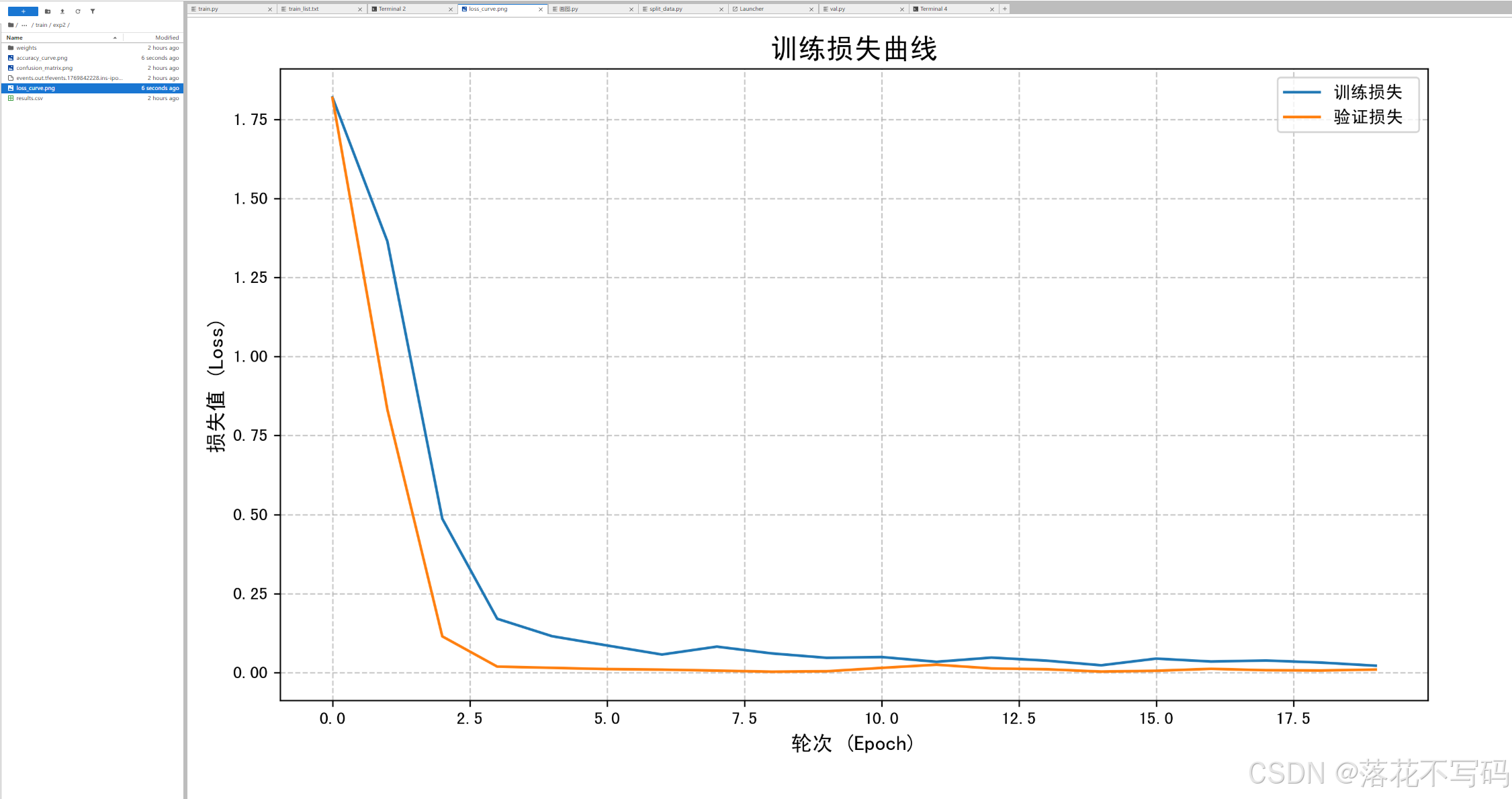
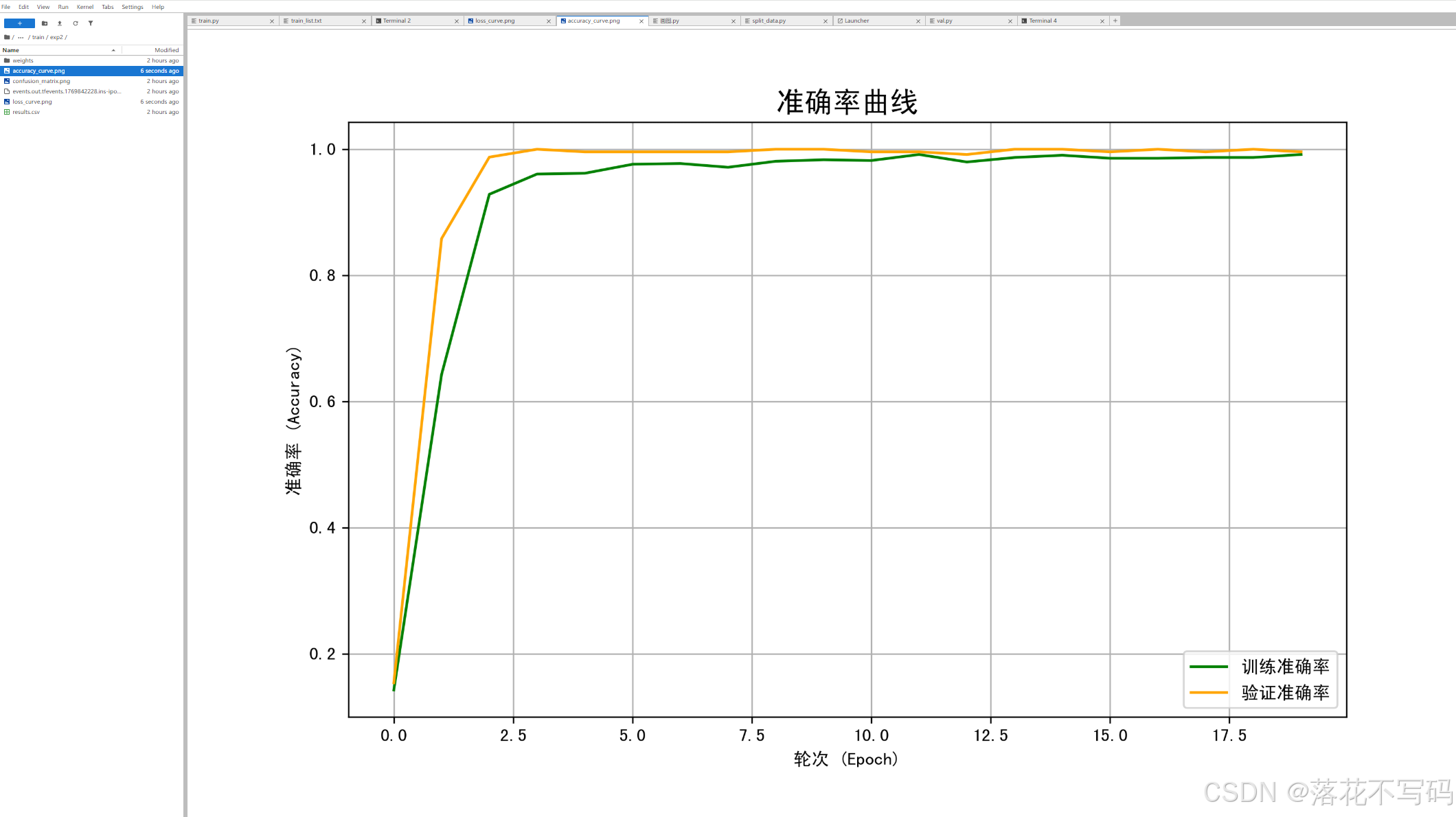
这些可视化结果能帮你更好地理解模型的学习过程。
3.4 模型验证与测试
训练好的模型需要验证效果。修改val.py文件,指定测试集路径和模型权重路径:

然后运行验证:
python val.py
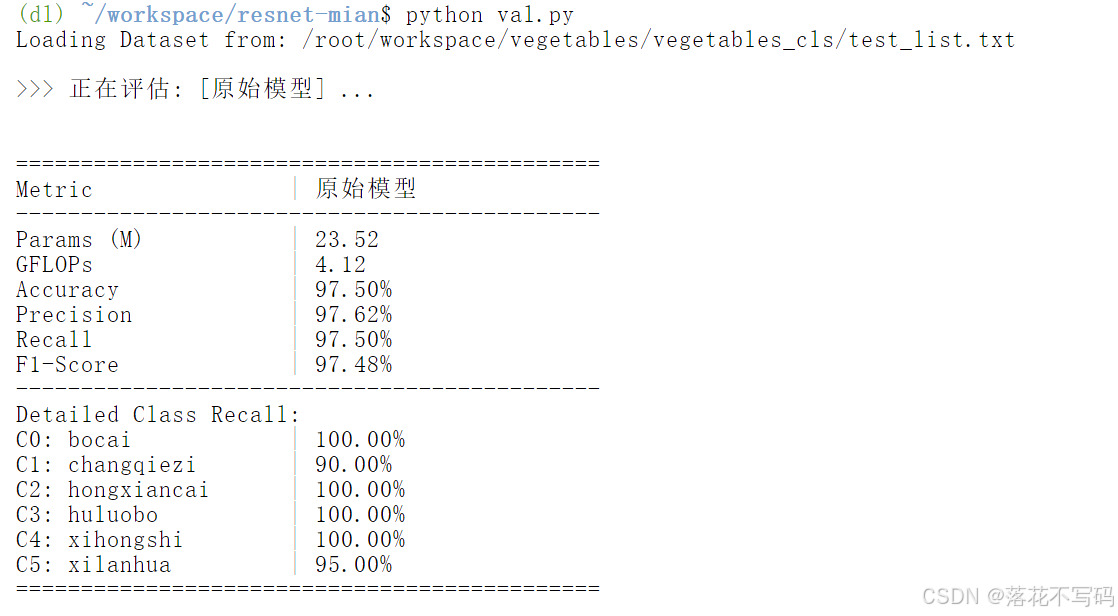
终端会显示模型的准确率、召回率、F1分数等指标,让你对模型性能有个直观的了解。
4. 进阶功能:模型优化与部署
4.1 模型剪枝
如果你的模型太大,在消费级显卡上推理速度慢,可以考虑模型剪枝。这个环境也提供了剪枝工具:

剪枝可以在保持模型性能的同时,大幅减少参数量和计算量,让模型在资源有限的设备上也能快速运行。
4.2 模型微调
有时候你不需要从头训练一个模型,而是在预训练模型的基础上进行微调。这样既能利用大模型学到的通用特征,又能适应你的特定任务:
微调通常比从头训练快得多,而且效果往往更好,特别是在数据量不大的情况下。
4.3 结果下载与使用
训练完成后,你需要把模型权重下载到本地。使用Xftp工具,直接从右边拖拽文件或文件夹到左边即可:
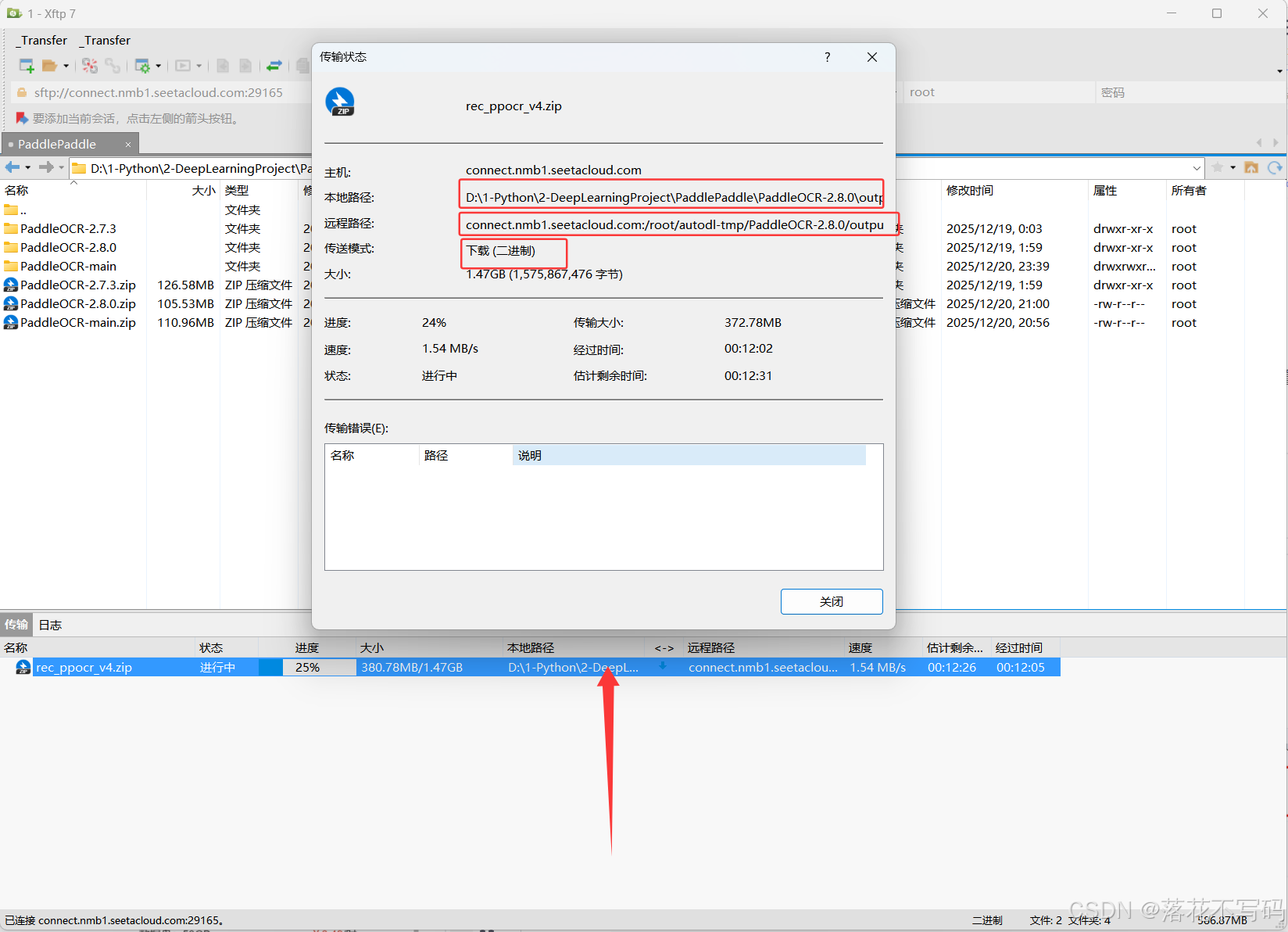
小技巧:如果数据集或模型文件比较大,建议先压缩再下载,能节省不少时间。下载完成后,你就可以在本地使用训练好的模型了。
5. 常见问题与解决方案
在实际使用中,你可能会遇到一些问题。这里我总结了一些常见情况:
数据集路径问题 这是最常见的问题。请确保:
- 数据集按照分类格式组织(每个类别一个文件夹)
- 在训练文件中正确修改了数据路径
- 路径中不要有中文或特殊字符
环境激活问题 镜像启动后默认可能不在dl环境,请务必执行:
conda activate dl
如果提示环境不存在,可以尝试:
source activate dl
显存不足问题 在24G显存上训练大型模型时,如果遇到显存不足:
- 减小
batch_size - 使用梯度累积(accumulate gradients)
- 启用混合精度训练(这个环境已经配置好了)
- 使用模型并行或数据并行
训练速度慢 如果觉得训练速度不够快:
- 检查是否使用了GPU(
nvidia-smi查看GPU使用情况) - 增大
batch_size(在显存允许范围内) - 使用更高效的数据加载方式
依赖库缺失 虽然基础环境已经配置好了,但如果你需要额外的库:
pip install 库名
或者通过Conda安装:
conda install 库名
6. 总结
通过这个深度学习训练环境镜像,你可以在24G显存的消费级显卡上快速搭建起一个稳定、高效的训练平台。无论是学术研究还是工业应用,这个环境都能满足大部分深度学习项目的需求。
主要优势总结:
- 零配置上手:所有环境一键部署,省去繁琐的配置过程
- 消费级显卡友好:专门针对24G显存优化,训练稳定不报错
- 功能完整:从训练、验证到剪枝、微调,全套工具链
- 灵活可扩展:基础环境稳定,同时支持自定义扩展
- 学习成本低:即使你是深度学习新手,也能快速开始项目
给初学者的建议:
如果你是第一次接触深度学习项目,我建议:
- 先从简单的分类任务开始,熟悉整个流程
- 使用小规模数据集进行测试,快速验证环境
- 理解每个参数的含义,不要盲目调整
- 多查看训练日志和可视化结果,了解模型学习过程
- 遇到问题先看常见问题部分,大部分问题都有解决方案
深度学习项目的环境搭建往往是最耗时、最令人沮丧的部分。通过这个预配置的环境,我希望能够帮你跳过这个障碍,把更多时间花在模型设计和算法优化上,真正享受深度学习的乐趣。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 1
1 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)