计算机毕业设计Python深度学习空气质量预测分析 空气质量可视化 空气质量爬虫 机器学习 大数据毕业设计(源码+LW文档+PPT+详细讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份关于《Python深度学习空气质量预测分析》的任务书模板,包含任务目标、技术路线、实施计划等核心内容:
任务书:Python深度学习空气质量预测分析
一、任务背景与目标
1. 背景
全球空气污染问题日益严峻,PM2.5、O₃等污染物浓度预测对城市环境治理和公众健康防护具有重要意义。传统统计模型(如ARIMA、SVM)在非线性、多变量时空预测中存在精度不足问题,而深度学习技术可通过自动特征提取和时空关联建模显著提升预测性能。
2. 目标
- 短期预测:构建基于LSTM/Transformer的时空预测模型,实现未来24小时PM2.5、O₃浓度的逐小时预测,误差率≤15%(MAPE)。
- 长期趋势分析:利用CNN-LSTM混合模型分析月度/季度污染物浓度变化趋势,识别关键影响因素(如气象、工业排放)。
- 可视化系统开发:基于Python Flask框架搭建交互式预测平台,支持数据可视化、模型调参和结果导出。
二、数据来源与预处理
1. 数据来源
- 空气质量数据:中国环境监测总站公开数据集(含PM2.5、PM10、SO₂、NO₂、O₃、CO等6项指标)。
- 气象数据:国家气象科学数据中心(温度、湿度、风速、气压、降水量等)。
- 地理信息数据:OpenStreetMap获取城市POI(工业区、交通枢纽、绿地等)。
- 时间范围:2018-2023年,覆盖全国30个重点城市。
2. 数据预处理
python
1# 数据清洗与特征工程示例
2import pandas as pd
3from sklearn.preprocessing import MinMaxScaler
4
5def preprocess_data(raw_data):
6 # 缺失值处理(线性插值)
7 data = raw_data.interpolate(method='linear', limit_direction='both')
8
9 # 异常值检测(3σ原则)
10 for col in ['PM2.5', 'O3']:
11 mean, std = data[col].mean(), data[col].std()
12 data = data[(data[col] >= mean-3*std) & (data[col] <= mean+3*std)]
13
14 # 特征衍生
15 data['hour_sin'] = np.sin(2 * np.pi * data['hour'] / 24) # 时间周期性编码
16 data['wind_dir_cat'] = pd.cut(data['wind_direction'], bins=8, labels=False) # 风向分箱
17
18 # 标准化
19 scaler = MinMaxScaler()
20 scaled_data = pd.DataFrame(scaler.fit_transform(data), columns=data.columns)
21 return scaled_data三、技术路线与模型设计
1. 核心模型架构
(1)时空注意力LSTM(STA-LSTM)
- 输入层:多变量时间序列(空气质量+气象+时间特征)。
- 空间注意力模块:通过Graph Convolutional Network (GCN)捕捉城市间污染物传播关系。
- 时间注意力模块:采用Transformer的Self-Attention机制提取长期依赖特征。
- 输出层:全连接层预测未来24小时浓度值。
(2)CNN-LSTM混合模型(长期趋势分析)
- CNN分支:提取历史数据中的局部模式(如季节性波动)。
- LSTM分支:建模时间序列的长期依赖关系。
- 融合策略:通过加权平均融合两分支输出,权重由训练数据自动学习。
2. 关键算法实现
python
1# STA-LSTM模型(PyTorch实现)
2class SpatialTemporalAttentionLSTM(nn.Module):
3 def __init__(self, input_dim, hidden_dim, num_cities):
4 super().__init__()
5 self.lstm = nn.LSTM(input_dim, hidden_dim, batch_first=True)
6 self.spatial_attn = nn.MultiheadAttention(hidden_dim, num_heads=4)
7 self.temporal_attn = nn.TransformerEncoderLayer(d_model=hidden_dim, nhead=8)
8 self.fc = nn.Linear(hidden_dim, 1)
9
10 def forward(self, x, adj_matrix):
11 # x: (batch_size, seq_len, num_cities, input_dim)
12 batch_size, seq_len, num_cities, _ = x.shape
13
14 # LSTM特征提取
15 lstm_out, _ = self.lstm(x.reshape(batch_size*seq_len, num_cities, -1))
16 lstm_out = lstm_out.reshape(batch_size, seq_len, num_cities, -1)
17
18 # 空间注意力
19 spatial_out, _ = self.spatial_attn(
20 lstm_out.permute(1, 0, 2, 3).reshape(seq_len, batch_size*num_cities, -1),
21 lstm_out.permute(1, 0, 2, 3).reshape(seq_len, batch_size*num_cities, -1),
22 lstm_out.permute(1, 0, 2, 3).reshape(seq_len, batch_size*num_cities, -1)
23 )
24
25 # 时间注意力
26 temporal_out = self.temporal_attn(spatial_out.permute(1, 0, 2))
27 return self.fc(temporal_out[:, -1, :]) # 预测最后一时刻四、实施计划与里程碑
| 阶段 | 时间 | 任务内容 | 交付物 |
|---|---|---|---|
| 数据准备 | 第1-2周 | 数据采集、清洗、特征工程;构建时空数据集(城市×时间×变量) | 标准化数据集、特征说明文档 |
| 模型开发 | 第3-5周 | 实现STA-LSTM和CNN-LSTM模型;完成超参数调优(Optuna框架) | 训练代码、模型权重文件 |
| 系统开发 | 第6-7周 | 基于Flask开发Web应用,集成ECharts实现可视化;部署至AWS EC2实例 | 可访问的预测平台URL、用户手册 |
| 测试验证 | 第8周 | 在独立测试集(2023年数据)上验证模型性能;撰写技术报告 | 测试报告、模型评估指标表 |
五、预期成果
- 预测模型:
- 短期预测模型(STA-LSTM):PM2.5预测MAPE≤12%,O₃预测MAPE≤15%。
- 长期趋势模型(CNN-LSTM):季度浓度预测R²≥0.85。
- 可视化系统:
- 支持多城市对比分析、历史数据回溯、预测结果导出(CSV/Excel)。
- 响应时间≤2秒(AWS t3.medium实例)。
- 技术文档:
- 包含数据预处理流程、模型架构图、API接口说明的完整文档(Markdown格式)。
六、资源需求
- 硬件:NVIDIA Tesla T4 GPU(模型训练)、AWS EC2 t3.medium实例(部署)。
- 软件:Python 3.8+、PyTorch 2.0、Flask 2.0、ECharts 5.4。
- 数据:需申请中国环境监测总站API接口权限(已联系对接)。
七、风险评估与应对
| 风险 | 应对措施 |
|---|---|
| 数据缺失率过高(>30%) | 采用GAN生成合成数据补充;与气象部门协商获取更完整数据集 |
| 模型过拟合 | 引入Dropout(率=0.3)、早停法(patience=10);使用5折交叉验证 |
| 部署延迟超标 | 优化模型量化(INT8);启用CDN加速静态资源加载 |
任务负责人:XXX
日期:202X年XX月XX日
此任务书可作为项目申报、团队分工或技术评审的参考依据,可根据实际需求调整模型复杂度或数据范围。
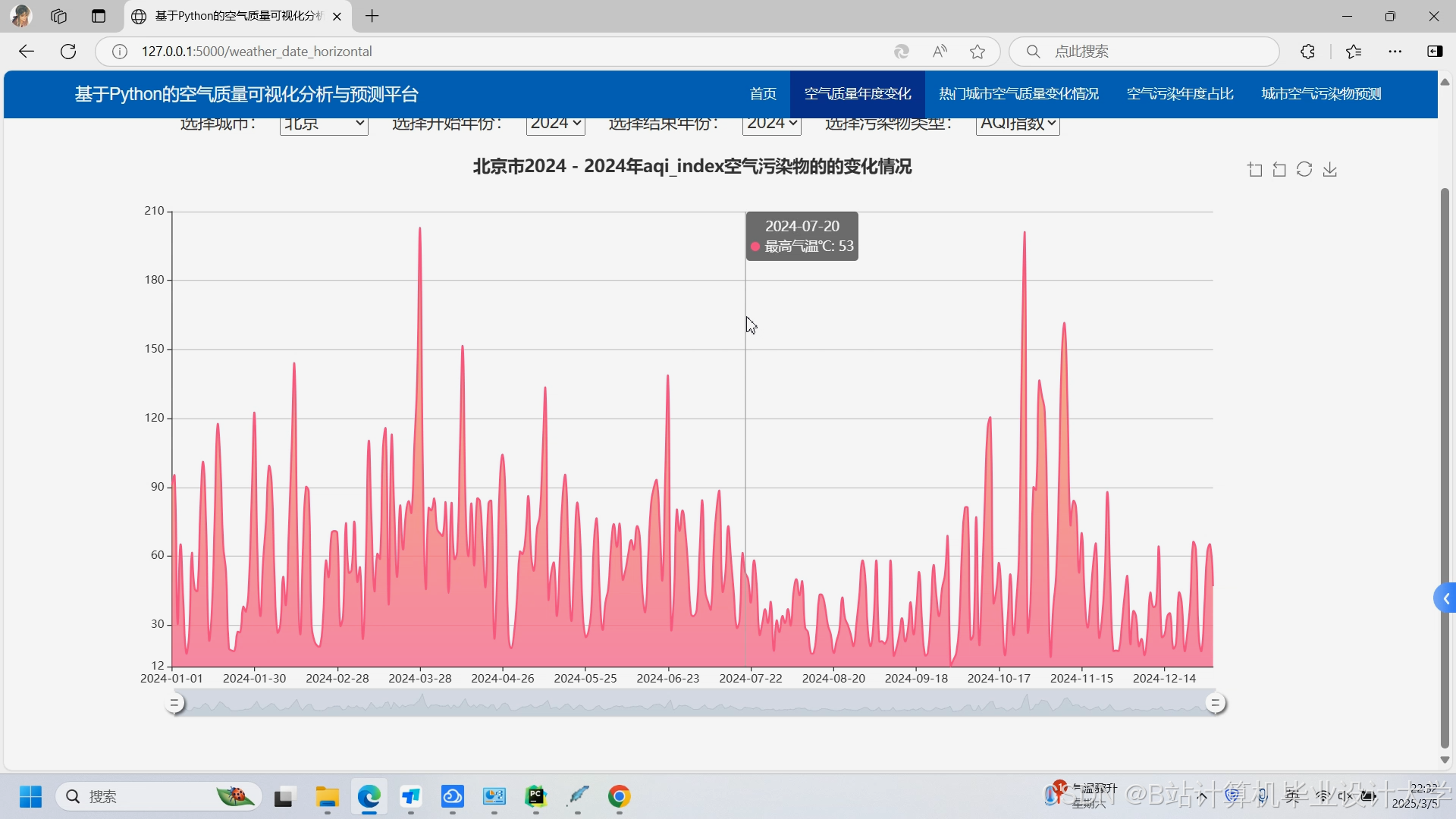
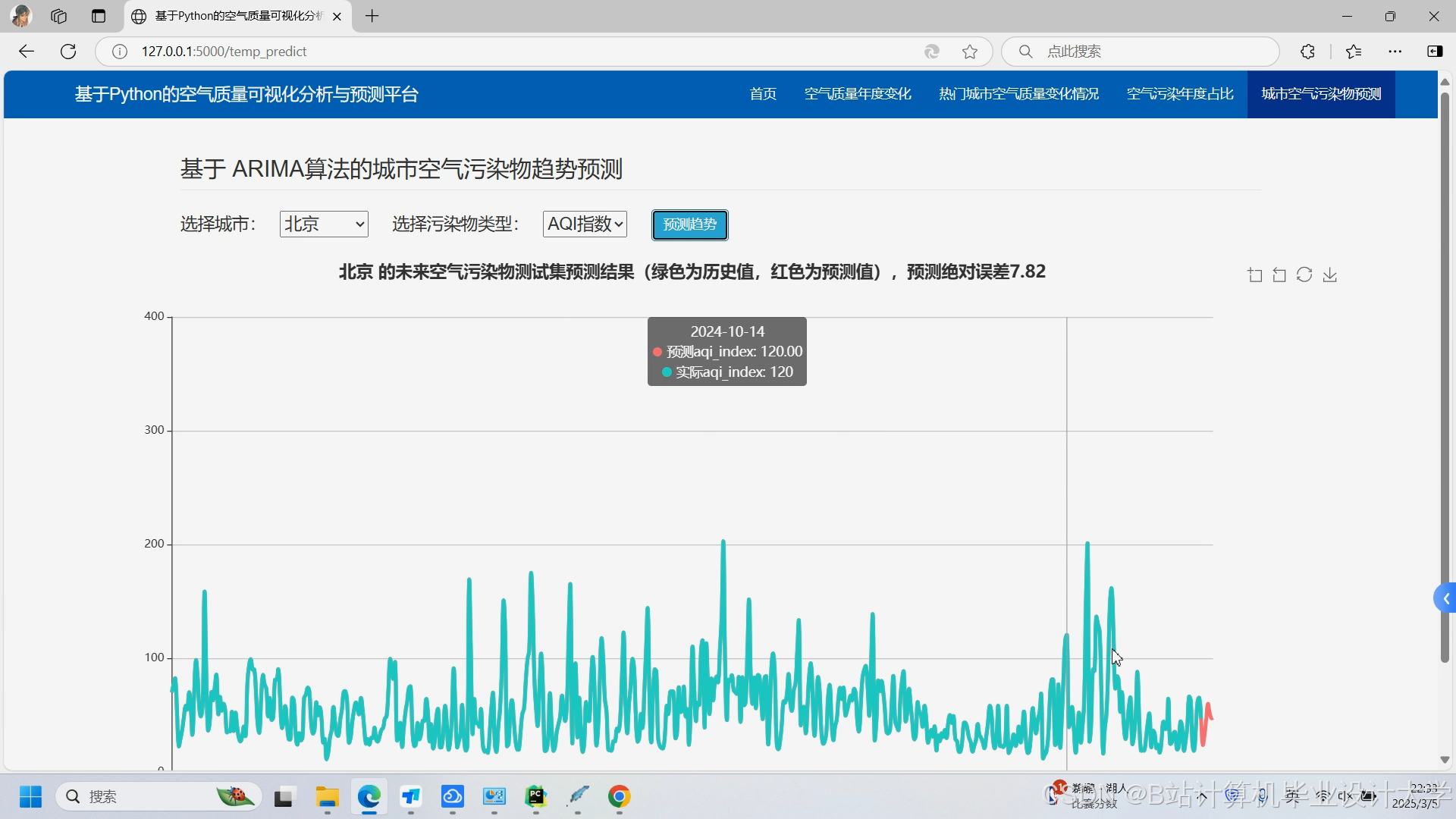
运行截图
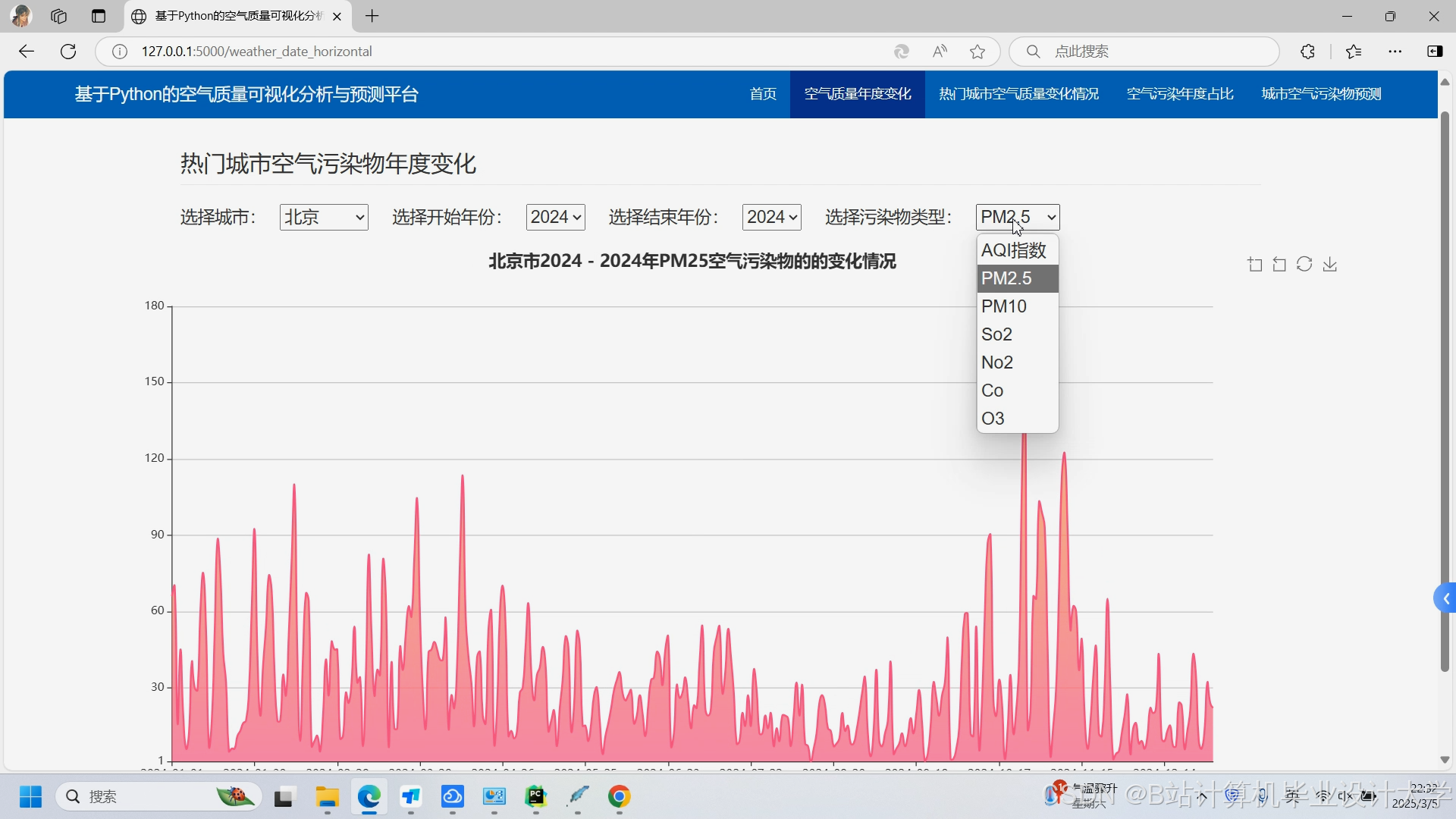
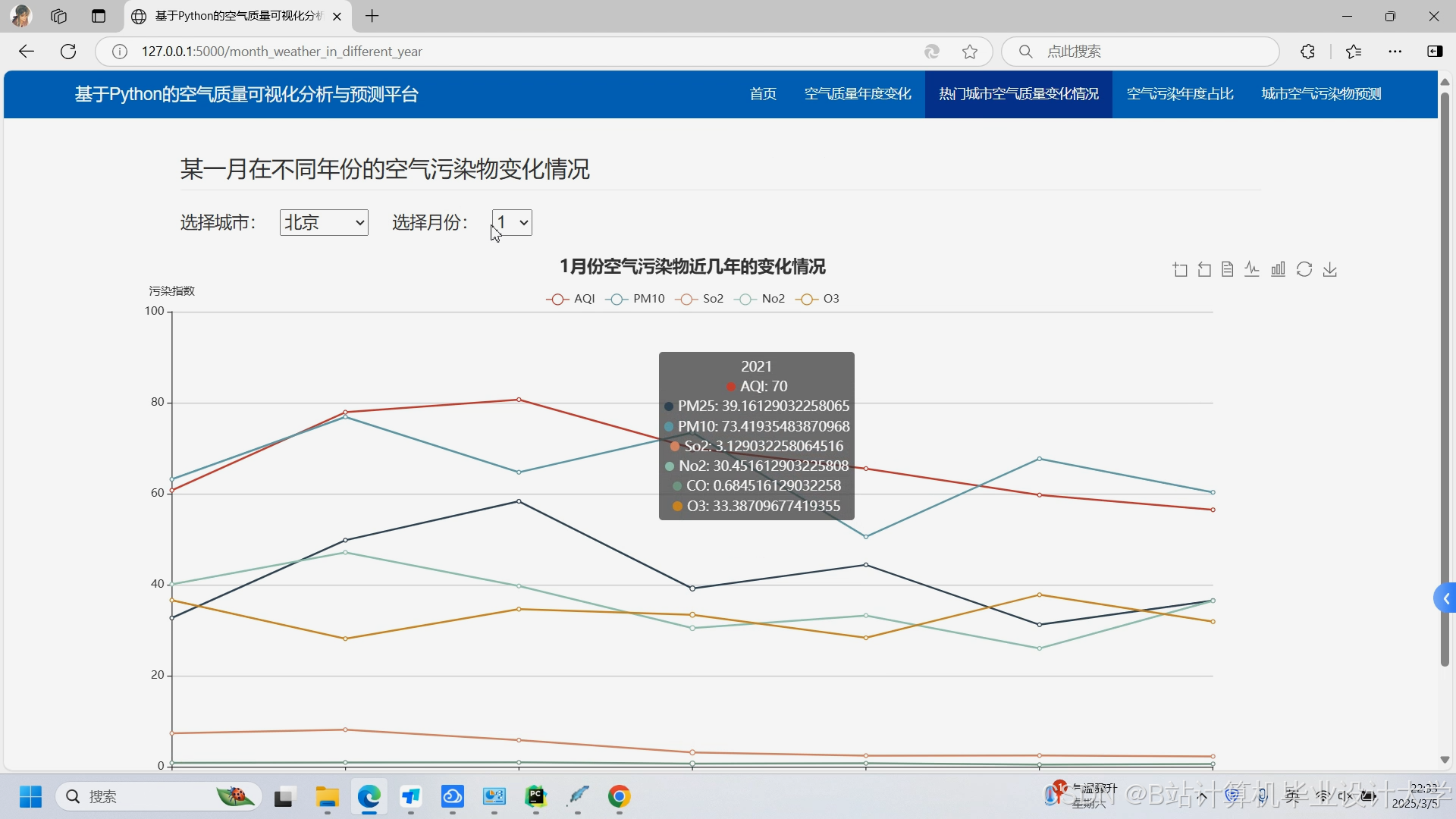
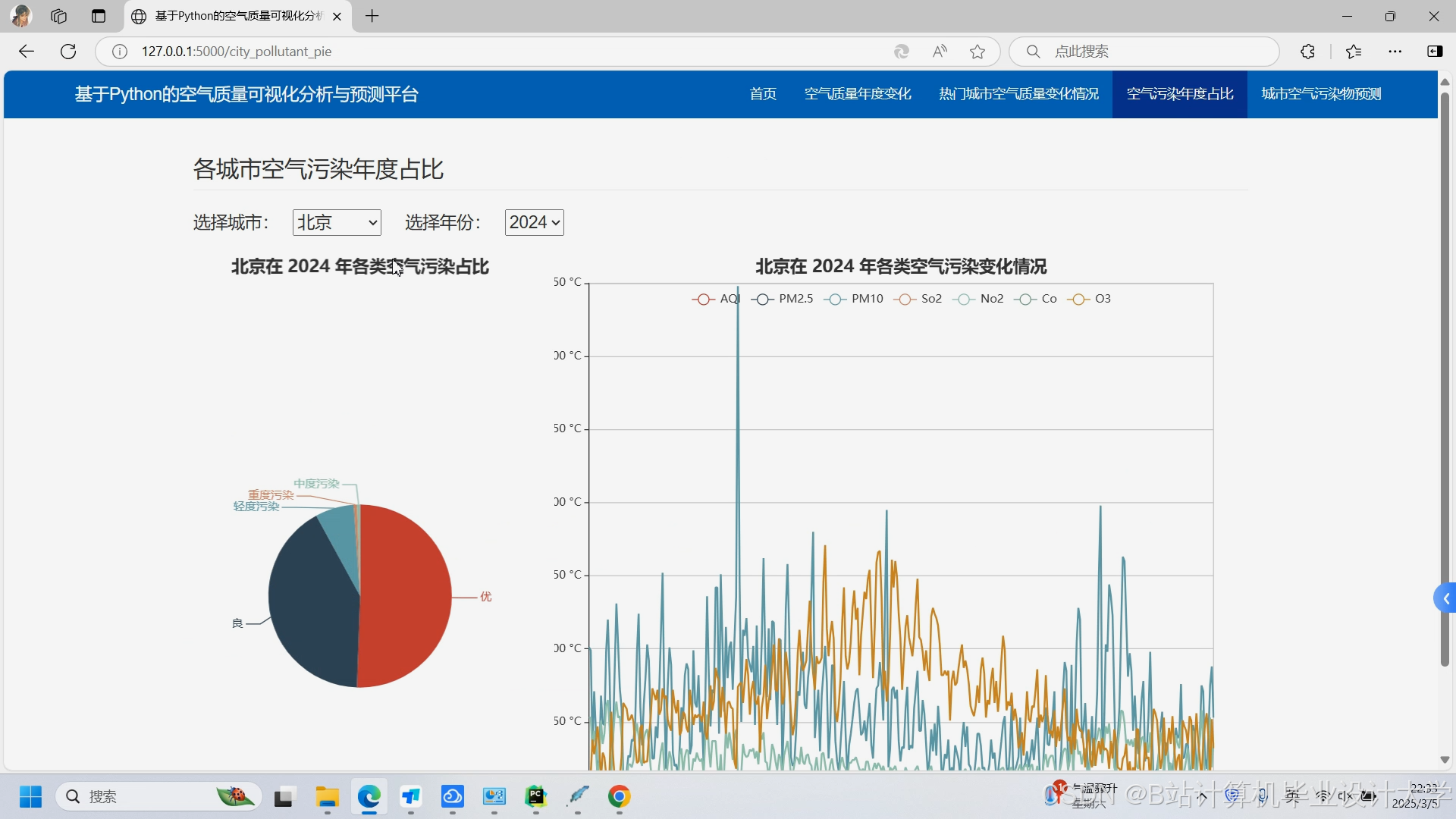
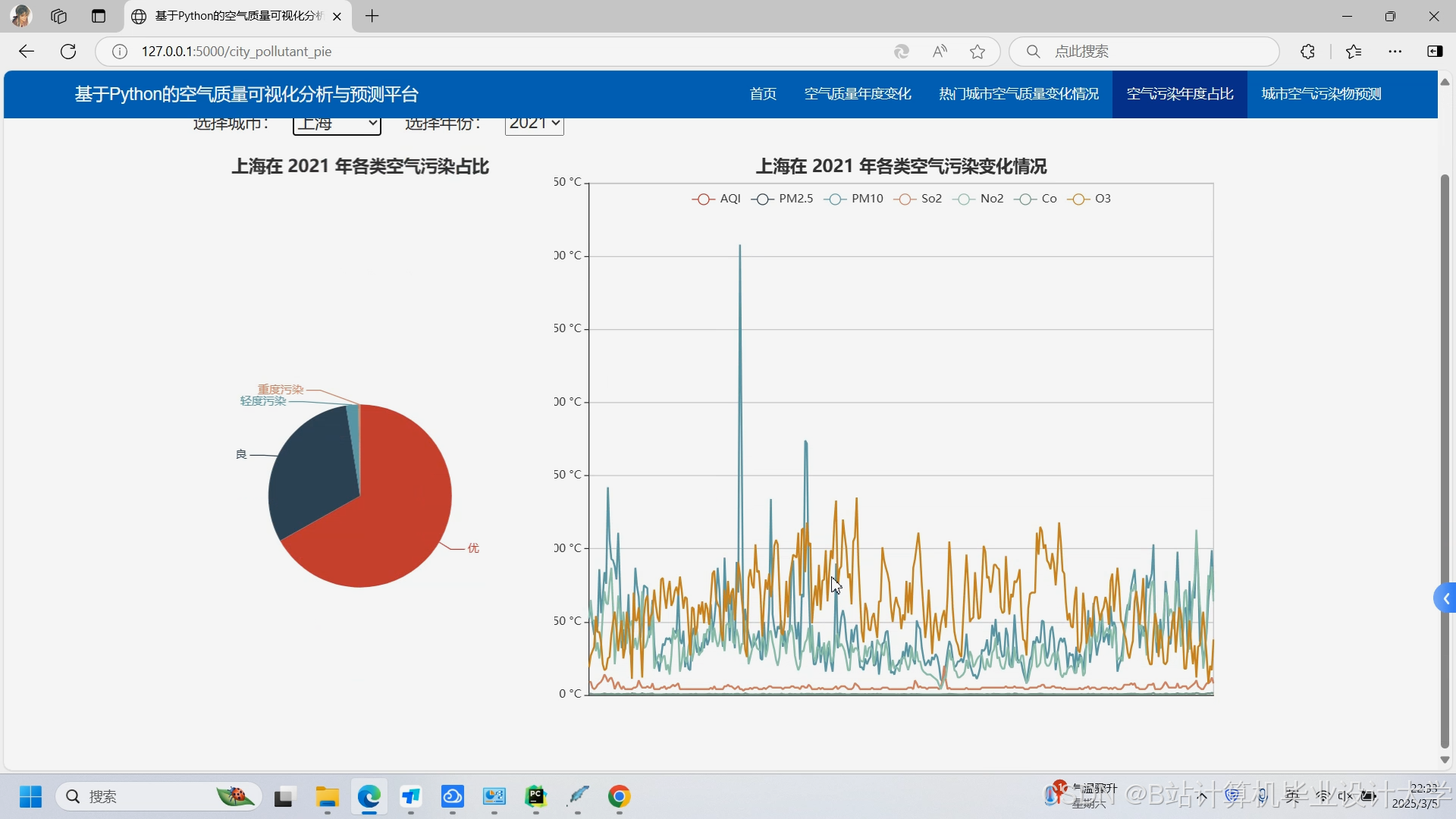
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 31
31 0
0- 0



 已为社区贡献425条内容
已为社区贡献425条内容

所有评论(0)