5个开源数字人模型部署推荐:Heygem镜像免配置一键启动指南
5个开源数字人模型部署推荐:Heygem镜像免配置一键启动指南
1. 前言:为什么选择Heygem数字人系统?
如果你正在寻找一个能快速上手、功能强大,而且完全免费开源的数字人视频生成工具,那么Heygem数字人视频生成系统绝对值得你关注。
想象一下这样的场景:你有一段重要的产品介绍音频,需要为不同地区的市场制作多个版本的数字人讲解视频。传统方法需要找专业团队,花费数天时间和不菲的费用。而现在,有了Heygem,你只需要上传一段音频和几个不同的数字人视频模板,系统就能自动为你生成多个口型完全同步的讲解视频,整个过程可能只需要喝杯咖啡的时间。
这个由科哥二次开发构建的系统,最大的特点就是"简单"。它提供了WebUI界面,你不需要懂复杂的命令行,不需要配置繁琐的环境,甚至不需要了解背后的AI模型原理。就像使用一个普通的网站一样,上传文件、点击按钮,就能获得专业级的数字人视频。
今天我要介绍的,就是如何通过CSDN星图镜像广场提供的Heygem镜像,实现真正的"免配置一键启动",让你在几分钟内就能开始制作自己的数字人视频。
2. 5个值得尝试的开源数字人模型
在深入介绍Heygem之前,我们先来看看目前开源社区中几个优秀的数字人模型。了解这些选项,能帮助你更好地理解Heygem的技术背景和适用场景。
2.1 Wav2Lip:口型同步的经典选择
Wav2Lip可以说是开源数字人领域的"元老级"模型了。它的核心功能非常专一:让任意视频中的人物口型与你提供的音频完美同步。
适合场景:
- 为现有的教学视频重新配音
- 修复影视作品中的口型不同步问题
- 制作多语言版本的讲解视频
特点:
- 模型轻量,运行速度快
- 对硬件要求相对较低
- 社区活跃,教程资源丰富
不过Wav2Lip主要专注于口型,对于面部表情、头部姿态的调整能力有限。
2.2 SadTalker:表情更自然的进阶方案
如果你觉得单纯的口型同步还不够,希望数字人的表情也能更加生动自然,那么SadTalker值得一试。
核心优势:
- 不仅能同步口型,还能生成自然的头部动作和面部表情
- 支持从单张图片生成动态视频
- 输出效果更加流畅自然
适合场景:
- 虚拟主播内容制作
- 个性化生日祝福视频
- 企业形象代言人视频
SadTalker的效果更好,但相应的对计算资源的要求也更高一些。
2.3 GeneFace:高保真度的专业之选
GeneFace在学术界和工业界都备受关注,它最大的特点是能够生成极高保真度的数字人视频。
技术亮点:
- 基于3D人脸模型,生成效果更加真实
- 支持高分辨率输出
- 口型同步的准确度很高
适合场景:
- 影视级数字人内容制作
- 高端产品演示视频
- 对画质要求极高的应用
GeneFace的部署和运行相对复杂,适合有一定技术背景的用户。
2.4 DreamTalk:一站式解决方案
DreamTalk的目标是提供一个完整的数字人生成解决方案,从文本到语音再到视频,一站式搞定。
功能特色:
- 支持从文本直接生成带语音的数字人视频
- 内置多种语音合成选项
- 提供完整的端到端工作流
适合场景:
- 快速制作营销视频
- 教育培训内容批量生产
- 没有现成音频素材的情况
如果你连音频都不想自己录制,DreamTalk可能是更好的选择。
2.5 Heygem:简单易用的生产力工具
最后就是我们今天的主角——Heygem数字人视频生成系统。它基于成熟的数字人技术,但重点放在了"易用性"和"批量处理"上。
为什么选择Heygem:
- WebUI界面:完全图形化操作,零学习成本
- 批量处理:一次处理多个视频,效率提升明显
- 免配置部署:通过镜像一键启动,省去所有环境配置
- 持续更新:科哥团队持续维护和优化
最适合的场景:
- 企业需要批量制作产品介绍视频
- 教育机构制作多版本教学视频
- 内容创作者需要快速产出数字人内容
- 任何希望快速上手、立即见效的用户
3. Heygem镜像一键部署实战
了解了各个模型的特点后,我们来看看如何快速部署Heygem系统。通过CSDN星图镜像广场,整个过程变得异常简单。
3.1 准备工作:你需要什么?
在开始之前,确保你具备以下条件:
硬件要求:
- CPU:4核以上(推荐8核)
- 内存:16GB以上(推荐32GB)
- 存储:至少50GB可用空间
- GPU:可选,有GPU会大幅提升处理速度(推荐NVIDIA显卡,8GB显存以上)
软件环境:
- 一个现代浏览器(Chrome、Edge、Firefox都可以)
- 稳定的网络连接
- CSDN星图平台的账号
文件准备:
- 音频文件:准备好需要合成的音频(支持wav、mp3、m4a等格式)
- 视频文件:准备好数字人模板视频(支持mp4、avi、mov等格式)
3.2 三步完成部署
第一步:获取Heygem镜像
- 访问CSDN星图镜像广场
- 搜索"Heygem数字人视频生成系统"
- 找到科哥发布的镜像版本
- 点击"一键部署"
第二步:启动系统
部署完成后,系统会自动启动。你只需要执行一个简单的命令:
bash start_app.sh
等待片刻,看到类似下面的提示,就说明启动成功了:
Running on local URL: http://0.0.0.0:7860
第三步:访问Web界面
在浏览器中输入:
http://你的服务器IP:7860
或者如果是在本地运行:
http://localhost:7860
看到类似下面的界面,就说明一切准备就绪了:
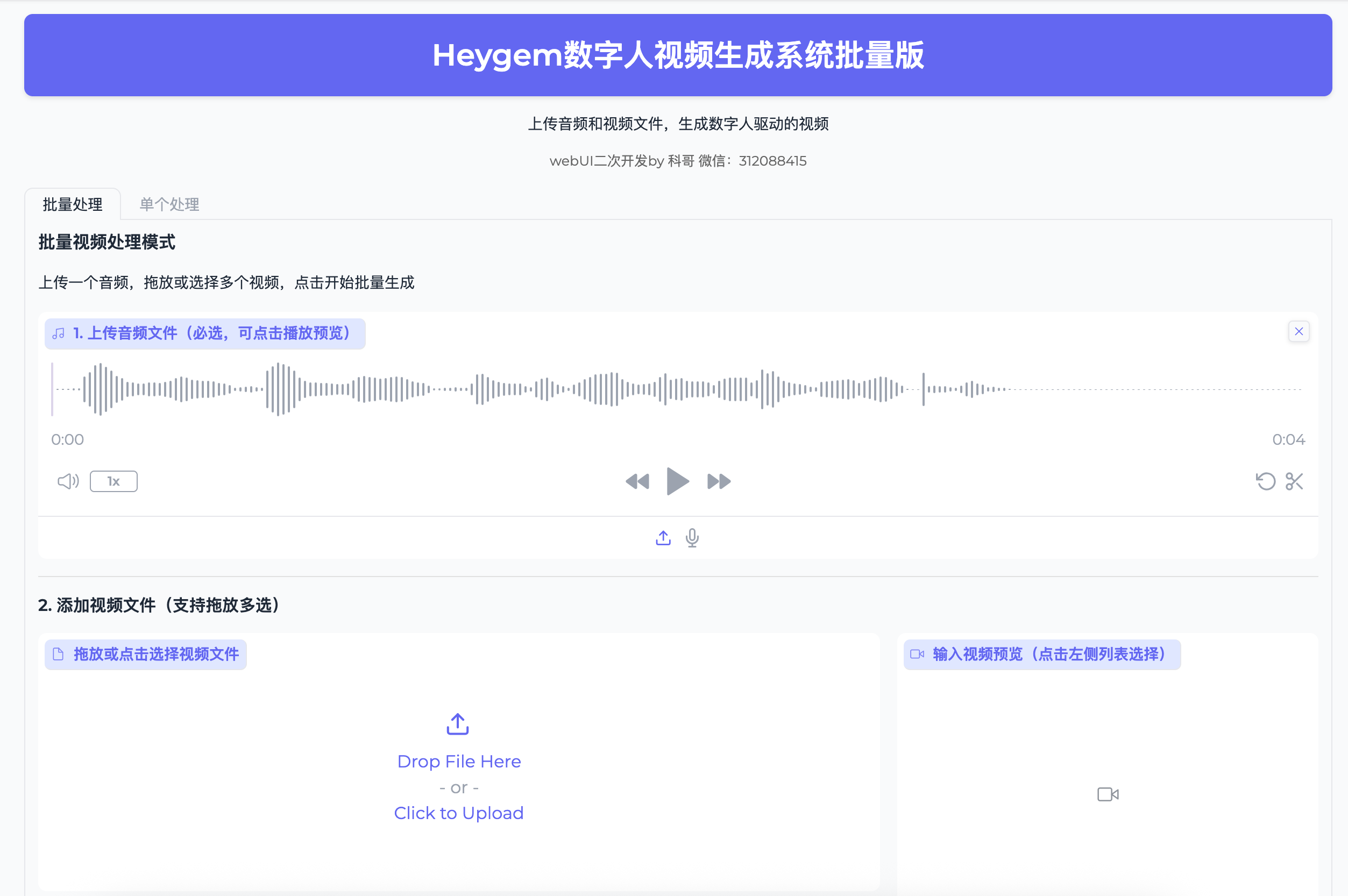
3.3 常见问题解决
如果在部署过程中遇到问题,可以尝试以下方法:
问题1:端口被占用
# 查看7860端口是否被占用
netstat -tlnp | grep 7860
# 如果被占用,可以修改启动脚本中的端口号
# 编辑start_app.sh,将7860改为其他端口,如7861
问题2:依赖包缺失
# 进入项目目录
cd /root/workspace
# 查看日志文件
tail -f 运行实时日志.log
# 根据日志提示安装缺失的包
pip install 缺失的包名
问题3:GPU无法识别
# 检查GPU状态
nvidia-smi
# 如果显示正常但系统未使用,尝试重新安装CUDA相关驱动
大多数情况下,通过镜像部署都能避免这些问题,因为所有依赖都已经预先配置好了。
4. Heygem系统功能详解与使用技巧
现在系统已经运行起来了,让我们深入了解一下Heygem的具体功能和使用方法。
4.1 两种处理模式如何选择?
Heygem提供了两种工作模式,适合不同的使用场景:
批量处理模式(推荐给大多数用户)
- 适合:需要用同一段音频生成多个不同数字人视频
- 例子:一段产品介绍音频,需要生成中文版、英文版、日文版三个数字人讲解视频
- 优势:一次上传,批量生成,效率最高
单个处理模式
- 适合:快速测试效果,或者只需要生成单个视频
- 例子:制作一个生日祝福视频,只需要一个数字人版本
- 优势:操作简单,快速验证想法
4.2 批量处理完整流程
让我们通过一个实际案例,看看批量处理的完整流程:
案例背景:某在线教育机构需要为同一门课程制作5个不同讲师风格的数字人讲解视频。
步骤1:准备素材
- 音频:录制好的课程讲解音频(30分钟,mp3格式)
- 视频:5位不同讲师的形象视频(每人1分钟,mp4格式)
步骤2:上传文件
- 在批量处理页面,点击"上传音频文件"
- 选择课程讲解音频,上传后可以点击播放按钮预览
- 点击"拖放或点击选择视频文件",一次性选择5个讲师视频
- 视频会自动出现在左侧列表中
步骤3:预览和调整
- 点击列表中的每个视频名称,右侧会显示预览
- 确认每个视频都符合要求(人物正面、光线良好、背景干净)
- 如果有不需要的视频,可以选中后点击"删除选中"
步骤4:开始生成
- 点击"开始批量生成"按钮
- 系统会显示实时进度:
- 当前处理的视频:讲师1.mp4
- 进度:1/5
- 进度条:20%
- 状态:正在合成口型...
步骤5:查看结果
- 所有视频处理完成后,结果会显示在"生成结果历史"区域
- 点击任意缩略图,可以在右侧播放器中预览
- 如果对某个视频不满意,可以重新调整后再次生成
步骤6:下载成果
- 单个下载:选中视频,点击下载按钮
- 批量下载:点击"一键打包下载",系统会将5个视频打包成ZIP文件
- 下载后可以在本地查看最终效果
4.3 实用技巧与最佳实践
根据我的使用经验,分享几个提升效果的小技巧:
音频处理技巧:
# 如果你有Python环境,可以先用这个脚本优化音频
import librosa
import soundfile as sf
# 加载音频
audio, sr = librosa.load('input.mp3', sr=22050)
# 降噪处理(简单版本)
import noisereduce as nr
audio_denoised = nr.reduce_noise(y=audio, sr=sr)
# 标准化音量
import pyloudnorm as pyln
meter = pyln.Meter(sr)
loudness = meter.integrated_loudness(audio_denoised)
audio_normalized = pyln.normalize.loudness(audio_denoised, loudness, -20.0)
# 保存处理后的音频
sf.write('output_optimized.wav', audio_normalized, sr)
视频准备建议:
- 人物位置:人物最好在画面中央,正面朝向摄像头
- 光线条件:光线均匀,避免过暗或过曝
- 背景简洁:纯色或简单背景效果更好
- 视频长度:建议1-3分钟,过长的视频处理时间会显著增加
- 分辨率:720p或1080p是最佳选择,4K虽然清晰但处理速度慢
批量处理优化:
- 如果有很多视频要处理,可以按批次进行,每批10-20个
- 处理过程中可以关闭预览功能,减少资源占用
- 夜间或空闲时间处理大任务,避免影响其他工作
5. 性能优化与问题排查
即使系统运行正常,了解一些优化技巧和问题排查方法,也能让你的使用体验更上一层楼。
5.1 提升处理速度的方法
硬件层面优化:
- 使用GPU:如果有NVIDIA显卡,确保CUDA驱动正确安装
- 增加内存:处理高清视频时,16GB内存是基础,32GB会更流畅
- 使用SSD:固态硬盘能显著提升文件读写速度
软件层面优化:
# 调整系统参数,提升性能
# 编辑启动脚本,添加以下参数
export CUDA_VISIBLE_DEVICES=0 # 指定使用哪块GPU
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128 # 优化GPU内存使用
# 对于没有GPU的环境,可以尝试使用CPU优化版本
# 但注意,纯CPU处理速度会慢很多
使用技巧优化:
- 视频预处理:提前将视频裁剪到合适长度
- 分辨率调整:如果不是特别需要,使用720p而非1080p
- 批量处理:尽量使用批量模式,避免频繁启停
5.2 常见问题与解决方案
问题:口型同步不准确
-
可能原因1:音频质量差,有噪音或回声
-
解决方案:使用音频编辑软件降噪,或者用上面提供的Python脚本处理
-
可能原因2:视频中人物面部有遮挡(眼镜、口罩、手等)
-
解决方案:选择面部清晰无遮挡的视频素材
-
可能原因3:视频帧率与音频不匹配
-
解决方案:用FFmpeg统一帧率
# 将视频转换为25fps
ffmpeg -i input.mp4 -r 25 output.mp4
问题:处理速度太慢
- 检查点1:查看系统资源使用情况
# 查看CPU和内存使用
top
# 查看GPU使用情况(如果有)
nvidia-smi
- 检查点2:查看日志文件
tail -f /root/workspace/运行实时日志.log
- 可能原因:视频太长或分辨率太高
- 解决方案:将长视频分段处理,或降低分辨率
问题:生成的视频有卡顿
-
可能原因1:原始视频本身有卡顿
-
解决方案:检查原始视频的流畅度
-
可能原因2:系统资源不足
-
解决方案:关闭其他占用资源的程序,或升级硬件
-
可能原因3:输出编码问题
-
解决方案:尝试不同的输出格式和编码参数
5.3 监控与维护
为了确保系统稳定运行,建议定期进行一些维护工作:
日志管理:
# 定期清理旧日志
# 保留最近7天的日志
find /root/workspace -name "*.log" -mtime +7 -delete
# 或者将日志归档
tar -czf logs_$(date +%Y%m%d).tar.gz /root/workspace/*.log
存储空间管理:
# 查看存储使用情况
df -h
# 清理旧的输出文件
# 保留最近30天的输出
find /root/workspace/outputs -type f -mtime +30 -delete
性能监控: 可以创建一个简单的监控脚本:
#!/bin/bash
# monitor_system.sh
echo "=== 系统监控 $(date) ==="
echo "CPU使用率: $(top -bn1 | grep "Cpu(s)" | awk '{print $2}')%"
echo "内存使用: $(free -h | grep Mem | awk '{print $3"/"$2}')"
echo "磁盘使用: $(df -h / | tail -1 | awk '{print $5}')"
if command -v nvidia-smi &> /dev/null; then
echo "GPU使用:"
nvidia-smi --query-gpu=utilization.gpu --format=csv,noheader
fi
echo "Heygem进程状态:"
ps aux | grep heygem | grep -v grep
6. 总结:Heygem的价值与未来展望
经过详细的介绍和实际操作演示,相信你对Heygem数字人视频生成系统有了全面的了解。让我们最后总结一下这个工具的核心价值,并展望一下数字人技术的未来发展方向。
6.1 为什么Heygem值得推荐?
回顾整个使用过程,Heygem的几个核心优势非常明显:
第一,极低的入门门槛
- 不需要AI专业知识
- 不需要编程技能
- 不需要复杂的环境配置
- 真正的"一键启动,开箱即用"
第二,强大的批量处理能力
- 一次处理多个视频,效率提升显著
- 统一的Web界面管理所有任务
- 支持批量下载和打包
第三,持续的更新维护
- 科哥团队积极响应用户反馈
- 定期更新功能和修复问题
- 活跃的用户社区支持
第四,完全免费开源
- 无任何使用费用
- 代码完全开放
- 可以自由修改和定制
6.2 实际应用场景扩展
除了我们演示的教育培训场景,Heygem还可以在很多领域发挥作用:
企业宣传:
- 制作多语言版本的企业介绍视频
- 为不同产品线制作专属数字人讲解
- 批量生成产品使用教程
内容创作:
- YouTuber可以用不同数字人形象发布内容
- 知识付费平台快速制作课程视频
- 自媒体批量生产短视频内容
客户服务:
- 制作常见问题解答视频
- 多语言客户支持材料
- 个性化营销视频
个人应用:
- 制作个性化的生日祝福视频
- 创建虚拟形象用于社交平台
- 学习视频制作和AI技术
6.3 数字人技术的未来趋势
随着AI技术的快速发展,数字人领域也在不断演进。我认为未来会有几个重要趋势:
技术层面:
- 更高的真实度:表情、动作、口型同步更加自然
- 实时生成:从现在的分钟级处理到秒级甚至实时生成
- 多模态融合:结合语音、文本、图像的多模态理解
应用层面:
- 个性化定制:根据用户需求快速生成专属数字人
- 交互式体验:数字人能够实时响应用户交互
- 跨平台部署:在手机、AR/VR设备等多种终端运行
生态层面:
- 开源社区壮大:更多优秀的开源项目涌现
- 工具链完善:从生成到编辑的完整工具链
- 标准化发展:行业标准逐渐形成
6.4 给初学者的建议
如果你刚刚接触数字人技术,我有几个建议:
第一步:从简单开始 不要一开始就追求完美效果。先用Heygem这样的简单工具做出第一个数字人视频,感受整个流程。
第二步:理解原理 在会用之后,可以适当了解背后的技术原理。知道Wav2Lip、SadTalker这些模型的工作原理,能帮助你更好地使用工具。
第三步:实践积累 数字人效果的好坏,很大程度上取决于素材质量和参数调整。多尝试不同的音频、视频组合,积累经验。
第四步:关注发展 这个领域发展很快,新的模型和技术不断出现。保持学习,及时了解最新进展。
最后也是最重要的:不要被技术吓倒。像Heygem这样的工具出现,就是为了让更多人能够轻松使用AI技术。现在就开始动手,制作你的第一个数字人视频吧!
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 7
7 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)