MySQL数据库知识要点归纳和总结
数据库知识要点归纳和总结
阅读之前看这里👉:博主是正在学习数据分析的一员,博客记录的是在学习过程中一些总结,也希望和大家一起进步,在记录之时,未免存在很多疏漏和不全,如有问题,还请私聊博主指正。
博客地址:天阑之蓝的博客,学习过程中不免有困难和迷茫,希望大家都能在这学习的过程中肯定自己,超越自己,最终创造自己。
各知识点总结
1.mysql中的distinct的用法
distinct的作用
在mysql中,distinct关键字的主要作用就是对数据库表中一个或者多个字段重复的数据进行过滤,只返回其中的一条数据给用户,distinct只可以在select中使用。
distinct的使用语法是这样的:
select distinct expression[,expression...] from tables [where conditions];
2.group by 与聚合函数
group by做为分组来使用,后面为条件,可以有多个条件,条件相同的为一组,配合聚合函数进行相关统计。
mysql中一种特殊的函数:聚合函数,SUM, COUNT, MAX, MIN, AVG等。这些函数和其它函数的根本区别就是它们一般作用在多条记录上。例如:
SELECT SUM(score) FROM table
这个sql的意思是查询表table里面所有score列的总和。
接着我们通过一个实例来讲解group by语句中如何使用聚合函数。
book表如下: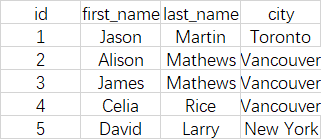
现在我们要对city进行分组查询,并获取每个分组有多少条数据,我们需要count聚合函数。
SELECT *,count(*) FROM book GROUP BY city
结果为: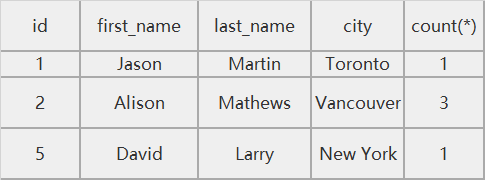
3.limit的用法
limit m,n表示从第m+1行开始取n条数据。
如果取第二高的数据为limit 1,1
limit m, offset n 表示从第n+1行读取m条数据。
比如 limit 2 offset 1
limit后面跟的是2条数据,offset后面是从第1条开始读取,默认为0。limit 1,1 与 limit 1 offset 1 等价。
位置交换了。
再举个例子:
代码示例:
语句1:select * from student limit 9,4
语句2:slect * from student limit 4 offset 9
// 语句1和2均返回表student的第10、11、12、13行
//语句2中的4表示返回4行,9表示从表的第十行开始.
4.left join的用法和理解
关于 “A LEFT JOIN B ON 条件表达式” 的一点提醒:
ON 条件(“A LEFT JOIN B ON 条件表达式”中的ON)用来决定如何从 B 表中检索数据行。
如果 B 表中没有任何一行数据匹配 ON 的条件,将会额外生成一行所有列为 NULL 的数据。
在匹配阶段 WHERE 子句的条件都不会被使用。仅在匹配阶段完成以后,WHERE 子句条件才会被使用。它将从匹配阶段产生的数据中检索过滤。
mysql> CREATE TABLE `product` (
`id` int(10) unsigned NOT NULL auto_increment,
`amount` int(10) unsigned default NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=5 DEFAULT CHARSET=latin1
mysql> CREATE TABLE `product_details` (
`id` int(10) unsigned NOT NULL,
`weight` int(10) unsigned default NULL,
`exist` int(10) unsigned default NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1
mysql> INSERT INTO product (id,amount)
VALUES (1,100),(2,200),(3,300),(4,400);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> INSERT INTO product_details (id,weight,exist)
VALUES (2,22,0),(4,44,1),(5,55,0),(6,66,1);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM product;
+----+--------+
| id | amount |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
| 4 | 400 |
+----+--------+
4 rows in set (0.00 sec)
mysql> SELECT * FROM product_details;
+----+--------+-------+
| id | weight | exist |
+----+--------+-------+
| 2 | 22 | 0 |
| 4 | 44 | 1 |
| 5 | 55 | 0 |
| 6 | 66 | 1 |
+----+--------+-------+
4 rows in set (0.00 sec)
mysql> SELECT * FROM product LEFT JOIN product_details
ON (product.id = product_details.id);
+----+--------+------+--------+-------+
| id | amount | id | weight | exist |
+----+--------+------+--------+-------+
| 1 | 100 | NULL | NULL | NULL |
| 2 | 200 | 2 | 22 | 0 |
| 3 | 300 | NULL | NULL | NULL |
| 4 | 400 | 4 | 44 | 1 |
+----+--------+------+--------+-------+
4 rows in set (0.00 sec)
ON 子句和 WHERE 子句有什么不同?
一个问题:下面两个查询的结果集有什么不同么?
1. SELECT * FROM product LEFT JOIN product_details
ON (product.id = product_details.id)
AND product_details.id=2;
2. SELECT * FROM product LEFT JOIN product_details
ON (product.id = product_details.id)
WHERE product_details.id=2;
用例子来理解最好不过了:
mysql> SELECT * FROM product LEFT JOIN product_details
ON (product.id = product_details.id)
AND product_details.id=2;
+----+--------+------+--------+-------+
| id | amount | id | weight | exist |
+----+--------+------+--------+-------+
| 1 | 100 | NULL | NULL | NULL |
| 2 | 200 | 2 | 22 | 0 |
| 3 | 300 | NULL | NULL | NULL |
| 4 | 400 | NULL | NULL | NULL |
+----+--------+------+--------+-------+
4 rows in set (0.00 sec)
mysql> SELECT * FROM product LEFT JOIN product_details
ON (product.id = product_details.id)
WHERE product_details.id=2;
+----+--------+----+--------+-------+
| id | amount | id | weight | exist |
+----+--------+----+--------+-------+
| 2 | 200 | 2 | 22 | 0 |
+----+--------+----+--------+-------+
1 row in set (0.01 sec)
第一条查询使用 ON 条件决定了从 LEFT JOIN的 product_details表中检索符合的所有数据行。
第二条查询做了简单的LEFT JOIN,然后使用 WHERE 子句从 LEFT JOIN的数据中过滤掉不符合条件的数据行。
再来看一些示例:
mysql>
mysql> SELECT * FROM product LEFT JOIN product_details
ON product.id = product_details.id
AND product.amount=100;
+----+--------+------+--------+-------+
| id | amount | id | weight | exist |
+----+--------+------+--------+-------+
| 1 | 100 | NULL | NULL | NULL |
| 2 | 200 | NULL | NULL | NULL |
| 3 | 300 | NULL | NULL | NULL |
| 4 | 400 | NULL | NULL | NULL |
+----+--------+------+--------+-------+
4 rows in set (0.00 sec)
所有来自product表的数据行都被检索到了,但没有在product_details表中匹配到记录(product.id = product_details.id AND product.amount=100 条件并没有匹配到任何数据)
mysql> SELECT * FROM product LEFT JOIN product_details
ON (product.id = product_details.id)
AND product.amount=200;
+----+--------+------+--------+-------+
| id | amount | id | weight | exist |
+----+--------+------+--------+-------+
| 1 | 100 | NULL | NULL | NULL |
| 2 | 200 | 2 | 22 | 0 |
| 3 | 300 | NULL | NULL | NULL |
| 4 | 400 | NULL | NULL | NULL |
+----+--------+------+--------+-------+
4 rows in set (0.01 sec)
同样,所有来自product表的数据行都被检索到了,有一条数据匹配到了。
5.窗口函数的应用
一、按照功能划分,可以把MySQL支持的窗口函数分为如下几类:
序号函数:row_number() / rank() / dense_rank()
分布函数:percent_rank() / cume_dist()
前后函数:lag() / lead()
头尾函数:first_val() / last_val()
其他函数:nth_value() / nfile()
求和 sum() over
二、窗口函数的基本用法如下:
window_name() over ([partition_defintion]|[order_definition]|[frame_definition])
其中,over是关键字,用来指定函数执行的窗口范围,如果后面括号中什么都不写,则意味着窗口包含满足where条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下四种语法来设置窗口:
(1)window_function_name:给窗口指定一个别名,如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读。
(2)partition子句:窗口按照那些字段进行分组,窗口函数在不同的分组上分别执行。上面的例子就按照用户id进行了分组。在每个用户id上,按照order by的顺序分别生成从1开始的顺序编号。
(3)order by子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号。可以和partition子句配合使用,也可以单独使用。上例中二者同时使用,如果没有partition子句,则会按照所有用户的订单金额排序来生成序号。
(4)frame子句:frame是当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用。比如要根据每个订单动态计算包括本订单和按时间顺序前后两个订单的平均订单金额,则可以设置如下frame子句来创建滑动窗口
1、序号函数:row_number() / rank() / dense_rank()
下图是"班级"表中的内容,记录了每个学生所在班级,和对应的成绩。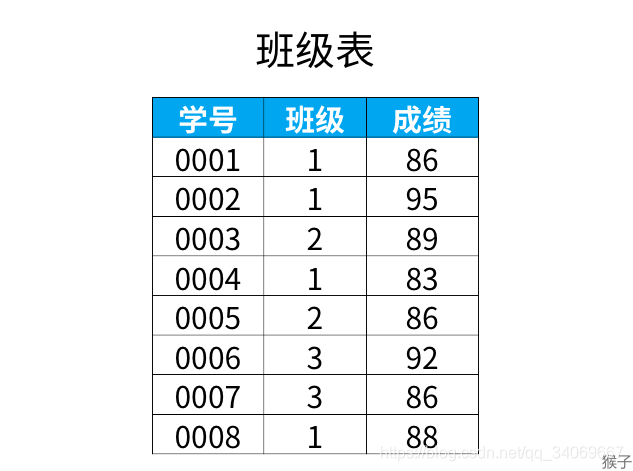
现在需要按成绩来排名,如果两个分数相同,那么排名要是并列的。
正常排名是1,2,3,4,但是现在前3名是并列的名次,排名结果是:1,1,1,2。
【解题思路】
1.涉及到排名问题,可以使用窗口函数
2.专用窗口函数rank, dense_rank, row_number有什么区别呢?
它们的区别我举个例子,你们一下就能看懂:
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级
得到结果: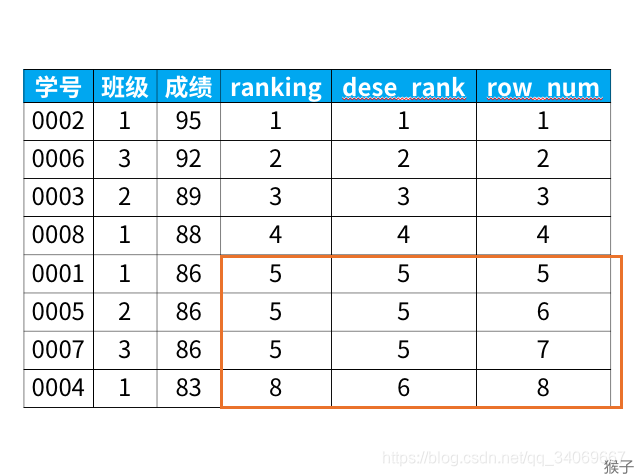
从上面的结果可以看出:
1)rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
2)dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
3)row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
这三个函数的区别如下: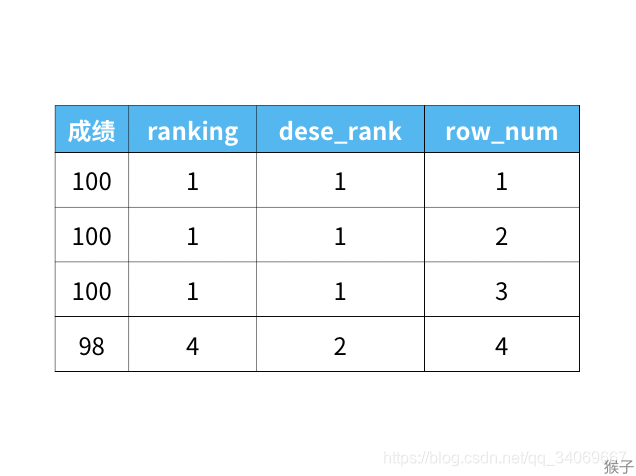
6.排序的自连接方法
还是以具体实例来说明:
首先建立表Products:
CREATE TABLE Products
(name VARCHAR(16) PRIMARY KEY,
price INTEGER NOT NULL);
INSERT INTO Products VALUES('苹果', 50);
INSERT INTO Products VALUES('橘子', 100);
INSERT INTO Products VALUES('葡萄', 50);
INSERT INTO Products VALUES('西瓜', 80);
INSERT INTO Products VALUES('柠檬', 30);
INSERT INTO Products VALUES('香蕉', 50);
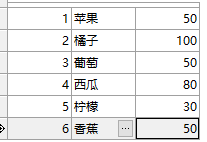
然后排序:
SELECT P1.name,
P1.price,
(SELECT COUNT(P2.price)
FROM Products P2
WHERE P2.price > P1.price)+ 1 AS rank_1
FROM Products P1
ORDER BY rank_1;
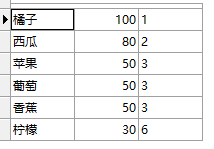
这里123336,如果想要6改为4呢,不跳过位次。
SELECT P1.name,
P1.price,
(SELECT COUNT(distinct P2.price)
FROM Products P2
WHERE P2.price > P1.price)+ 1 AS rank_1
FROM Products P1
ORDER BY rank_1;
只需要改COUNT(distinct P2.price),相当于DENSE_RANK 函数。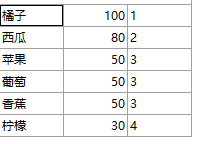
7.EXCEPT、UNION和INTERSECT的用法
定义
EXCEPT 返回两个结果集的差(即从左查询中返回右查询没有找到的所有非重复值)。
INTERSECT 返回 两个结果集的交集(即两个查询都返回的所有非重复值)。
UNION返回两个结果集的并集。
语法:
{ (<SQL-查询语句1>) }
{ EXCEPT | INTERSECT }
{ (<SQL-查询语句2> )}
限制条件
(1)所有查询中的列数和列的顺序必须相同。
(2)比较的两个查询结果集中的列数据类型可以不同但必须兼容。
(3)比较的两个查询结果集中不能包含不可比较的数据类型(xml、text、ntext、image 或非二进制 CLR 用户定义类型)的列。
(4)返回的结果集的列名与操作数左侧的查询返回的列名相同。ORDER BY 子句中的列名或别名必须引用左侧查询返回的列名。
(5)不能与 COMPUTE 和 COMPUTE BY 子句一起使用。
(6)通过比较行来确定非重复值时,两个 NULL 值被视为相等。(EXCEPT 或 INTERSECT 返回的结果集中的任何列的为空性与操作数左侧的查询返回的对应列的为空性相同。)
与表达式中的其他运算符一起使用时的执行顺序
1、括号中的表达式
2、INTERSECT 操作数
3、基于在表达式中的位置从左到右求值的 EXCEPT 和 UNION
如果 EXCEPT 或 INTERSECT 用于比较两个以上的查询集,则数据类型转换是通过一次比较两个查询来确定的,并遵循前面提到的表达式求值规则。
举例:
union 的用法
语法:
UNION 子句的基本语法如下所示:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
例:
select test1_num,test1_address from test1
union
select test2_num,test2_address from test2;
解析:
在使用 UNION 的时候,每个 SELECT 语句必须有相同数量的选中列、相同数量的列表达式、相同的数据类型,并且它们出现的次序要一致,不过长度不一定要相同。
如:两个表查询的都是两列,即select语句有相同的数量的选中列;test1_num和test2_num都是相同的数据类型,且都是在查询的结果中第一个出现,即出现的次序要一致。
union all 的用法
UNION ALL 运算符用于将两个 SELECT 语句的结果组合在一起,重复行也包含在内。
UNION ALL 运算符所遵从的规则与 UNION 一致。
语法:
UNION ALL的基本语法如下:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION ALL
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
except 的用法(同union)
语法:
EXCEPT 子句的基本语法如下所示:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
EXCEPT
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
第一步:建表,插入数据
表 t1
| t1_num | t1_name |
|---|---|
| 4 | a |
| 5 | b |
| 6 | c |
| 7 | null |
表 t2
| t2_num | t2_name |
|---|---|
| 6 | c |
| 7 | null |
| 8 | d |
| 9 | e |
select t1_num,t1_name from t1
except
select t2_num,t2_name from t2;
结果:
| t1_num | t1_name |
|---|---|
| 4 | a |
| 5 | b |
intersect 的用法(同union)
语法:
EXCEPT 子句的基本语法如下所示:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
intersect
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
例:
select t1_num,t1_name from t1
intersect
select t2_num,t2_name from t2;
结果:
| t1_num | t1_name |
|---|---|
| 6 | c |
| 7 | null |
8.DATE日期函数
详情见博主其它文章:数据分析之——MySQL数据库之DATE()日期函数

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)