【高中生讲机器学习】26. 梯度提升树 GBDT 超详细讲解!
创建时间:2024-11-18
首发时间:2024-11-19
最后编辑时间:2024-11-19
作者:Geeker_LStar
你好呀~这里是 Geeker_LStar 的人工智能学习专栏,很高兴遇见你~
我是 Geeker_LStar,一名高一学生,热爱计算机和数学,我们一起加油~!
⭐(●’◡’●) ⭐
heeeey! 你好呀~
上一篇我们讲了集成学习之 boosting 中的一个经典算法——adaboost。今天我们来讲第二个经典算法——梯度提升树 GBDT!
在此之前,你或许需要先对前向分步算法有所了解,你可以在上一篇文章中找到对应内容:
【高中生讲机器学习】25. AdaBoost 算法详解+推导来啦!
GBDT,全程 gradient boosting decision tree,是机器学习中性能最好的算法之一,大名鼎鼎的 XGBoost 就是它的进化版。
话不多说,GBDT 启动!
文章目录
主要思想
首先还是先讲讲 GBDT 算法的大致思想。
和 adaboost 一样,GBDT 也属于 boosting 家族,so 它也会有 boosting 家族算法的共性——串行组合多个基学习器(如果你读过上一篇 adaboost 的话,对这个点应该已经有了蛮深的体会了)。
那么,GBDT 到底是怎么串行组合的呢?我们或许可以从 GBDT 的英文全称中发现一些有趣的事情…
GBDT 的英文全称是 gradient boosting decision tree。后面的三个词都好理解,重点就是前面那个 G,也就是 gradient 梯度。
其实这就是 GBDT 的核心啦!
先放结论,在 GBDT 中,除了从根节点展开的树之外,每棵树拟合的都是其父节点的负梯度。
哎哎哎等等等,这句话信息量好大,什么父节点负梯度的…???
好好好我会慢慢说的(((怎么感觉我这么喜欢自言自语啊不是
well,我们先抛开负梯度这个词,这词听起来就很复杂(em 其实并没有,但是不好举例)。
我们考虑残差(a 其实后面你会发现,考虑残差也是有那么一点道理的。
当然,我还是得强调一下,这里考虑残差只是做一个近似,因为残差比负梯度好举例。但实际的 GBDT 考虑的是负梯度,不是残差,不要搞混了。
嗯,和 adabooooooooost 一样(咳),GBDT 的使用没什么局限性,分类问题和回归问题都能用,改变一下损失函数就可以(后面你就明白为什么了),在这里我们使用回归作为例子。
【note:下面这个例子非常不严谨,仅仅是给出一点 sense,更严谨的例子在下一个部分。】
现在有 4 个人,他们的年龄分别是 24, 26, 14, 16,有三个特征:收入、上网时长和睡眠时间 (这都哪跟哪啊) ,详细数据如下:
| 年龄 | 24 | 26 | 14 | 16 |
|---|---|---|---|---|
| 收入/r | 9000 | 12000 | 0 | 500 |
| 上网时间/h | 4 | 6 | 4 | 6 |
| 睡眠时长/h | 7 | 6.5 | 7.5 | 6.5 |
我们希望训练一个 GBDT 来预测他们每个人的年龄。
首先需要初始化,或者说给 GBDT 一个根节点。我们以这 4 个人的年龄的平均值也就是 20 作为根节点,这是一个比较好的开头。
计算当前的残差,分别是 4,6,-6,-4.
然后,现在我们根据收入进行第一次预测,对于月收入大于 1000 的人,我们预测其年龄为 20+5 岁(到了下一个部分你会发现,这样预测是有道理的,因为残差 4 和 6 的均值为 5),否则为 20-5 岁。画图如下:
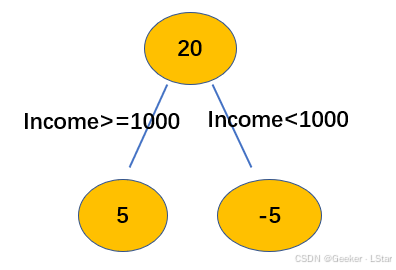
也就是说,根节点的两个分支(新拟合的子树)拟合的是根节点给出的数值和实际值之间的残差。
换言之,在进行子树的拟合的时候,我们拟合不再是原有的年龄数据(24、26、14、16),而是这些年龄数据和根节点已经给出的预测值(20)之间的残差。
在我们预测出残差 5 和 -5 之后,我们将它们和根节点的预测数值 20 相加,得到两个分支上的预测数值分别为 25 和 15,现在的残差分别是 -1,1,-1,1。
嗯,接下来就是拟合这些残差。我们不妨选择上网时长作为预测指标(emm 用什么实际的指标无所谓的,这个例子只是为了更好地理解 GBDT 的工作原理)。
上网时长大于 5h 的,预测为 +1,否则为 -1,画出图来:
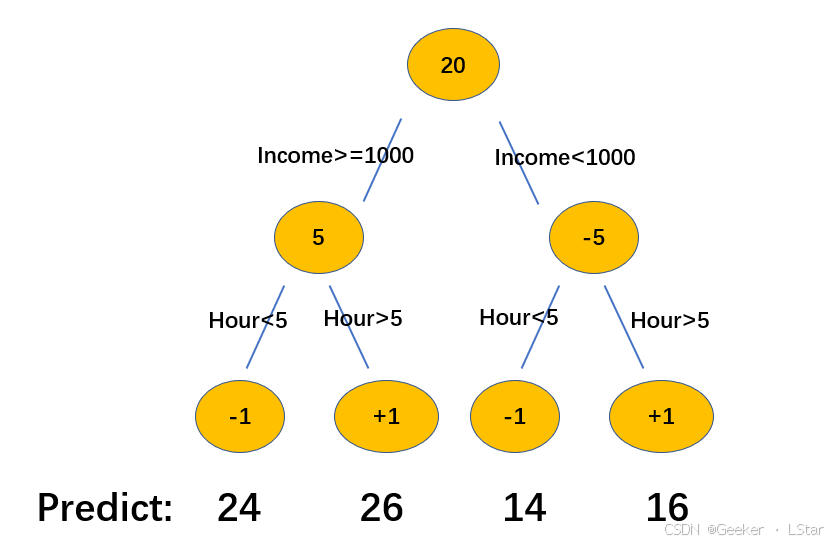
okaaaaay!!现在残差为 0,小于阈值,GBDT 拟合结束。
好耶!我大概来概括一下。在这个例子中,我们首先选择了一个特征(收入)进行回归。虽然在这里没太体现出来,但在实际中我们会选择使得损失函数最小的特征 / 分裂点进行回归(或使得损失函数最小的特征进行分类)。
然后,对于第一次回归的结果,我们计算当前的两个叶子节点上的值和实际值的差值(残差),并把这个差值作为拟合下一棵树的拟合目标。注意,在这里,我们需要分别对两个叶子节点拟合一棵树。
然后,对于两个叶子节点,我们依然是找到最佳的回归特征,不过这里的最佳特征是对于残差来说的。换言之,我们需要找到能够最好地拟合残差的特征。
这个例子到这里就结束了,因为此时的残差已经是 0 了。但在其它一些情况中,如果还没有达到停止条件,在继续拟合的时候,需要对现有的四个叶子节点分别拟合一棵树。
嗯当然,这个例子并不怎么严谨,后面在梯度提升回归树的部分我会给出一个更严谨的例子。
weeeell 再提醒一下,这里用残差只是一个近似,或者说是为了好举例子,GBDT 实际上拟合的是损失函数的负梯度,而非残差。
(回顾一下,如果是 adaboost,它会先把在第一次回归中和实际值差距大的数据点的权重增加,然后再选择让这些加权后的数据回归损失最小的特征 / 分裂点进行第二次分类。此处就是 GBDT 和 adaboost 的区别。
em,说一个比较形象化的理解,你可以认为 adaboost 是 “横向” 的,即它的每一棵树之间没有层级关系;而 GBDT 是 “纵向” 的,即后面的树都可以看作前面的树的子树(因为它们都是在前面的树的残差的基础上拟合的)。
下面这张图或许会更清晰一点(噗哈哈哈我的画图技术简直太…一言难尽):
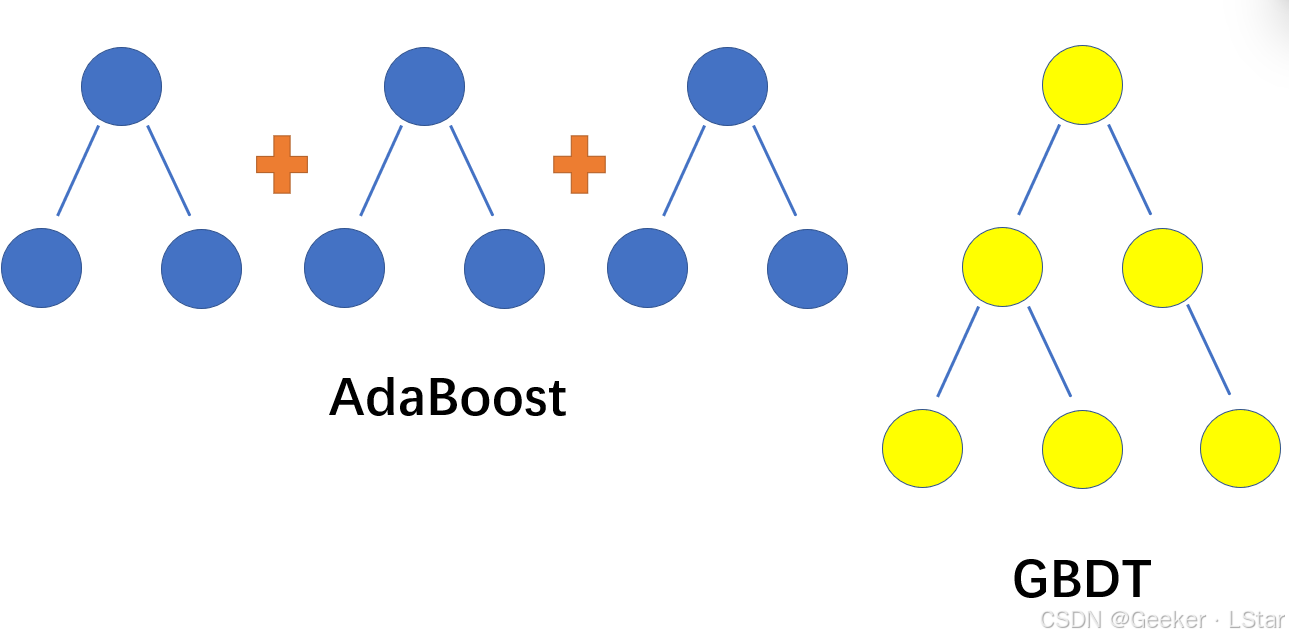
可以看到,在 adaboost 中,树的加权组合是横向的。换言之,每一棵树的拟合都是独立的,当然这建立在根据上一棵树的拟合情况对样本权重做出改变的基础上。而在 GBDT 中,树的组合是纵向的,对于每一个节点(除了叶子节点),都会有一棵子树去拟合这个节点的负梯度。
另外,注意,虽然图中每个节点只有两个分支,但实际上并没有这种限制,无论是在 GBDT 还是 adaboost 中。(em 这里画两个只是因为多个画不下,,而且下面的例子当中也是两个分支,但其实几个都可以啦~
嗯,干说很难说清楚,我们来看一个实际的例子吧!——梯度提升回归树 GBRT(gradient decision regression tree)。
特例:梯度提升回归树
在上一篇 adaboost 中,我们已经讲完了前向分步算法。在那篇文章中我埋了一个小小的彩蛋(什么逆天动词《埋》)——当前向分步算法的损失函数为平方损失的时候,会发生什么有趣的事情…
嘿嘿这不就来了嘛!
我们先回顾一下前向分步算法的形式。
f m = f m − 1 ( x ) + α G ( x ) f_m =f_{m-1}(x)+\alpha G(x) fm=fm−1(x)+αG(x)
我们要找的就是后面这个 α G ( x , θ ) \alpha G(x,\theta) αG(x,θ)(注意因为前向分步算法的很多细节都在上一篇中说过了,so 这里会过的很快,不清楚的话可以去看一下上一篇~) 。
我们考虑当损失函数是平方损失的时候,即:
Loss = ∑ i = 1 N L ( y i , f m ( x ) ) = ∑ i = 1 N ( y i − f m ( x i ) ) 2 = ∑ i = 1 N ( y i − f m − 1 ( x i ) − α G ( x i ) ) 2 = ∑ i = 1 N ( r − α G ( x i ) ) 2 \text{Loss}=\sum_{i=1}^N L(y_i, f_{m}(x))=\sum_{i=1}^N(y_i-f_{m}(x_i))^2 \\ =\sum_{i=1}^N(y_i-f_{m-1}(x_i)-\alpha G(x_i))^2 \\ =\sum_{i=1}^N(r-\alpha G(x_i))^2 Loss=i=1∑NL(yi,fm(x))=i=1∑N(yi−fm(xi))2=i=1∑N(yi−fm−1(xi)−αG(xi))2=i=1∑N(r−αG(xi))2
我们想让平方损失函数最小化,相当于让 ∑ i = 1 N ( r − α G ( x i ) ) 2 \sum_{i=1}^N(r-\alpha G(x_i))^2 ∑i=1N(r−αG(xi))2 最小化。那么,我们只需要让 α G ( x i ) \alpha G(x_i) αG(xi) 尽可能接近 r r r,或者说 y i y_i yi 和 f m − 1 f_{m-1} fm−1 也就是残差,就可以了呀!
那么,这不就好办了?我们只需要找到一棵新的树,让这棵树来拟合这个残差就可以了呀!
按照这个思路,我们可以无限套娃下去。对于每个节点,都训练一棵树来拟合损失函数在这个节点的残差,直到残差小于阈值或树的深度达到最大值(还记得我们前面说的 GBDT 的 “纵向结构” 吗?从它出发,这里的 “深度” 就很好理解了。(后面有两张图也很直观((
em 为了更好的理解,在这里给出一个例子。
使用下面这 10 个数据拟合一棵梯度提升回归树,使用平方损失作为损失函数。
| x x x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y y y | 3.2 | 2.8 | 4.5 | 3.6 | 5.0 | 6.1 | 5.5 | 7.2 | 6.8 | 8.0 |
首先,第一步,我们需要一个根节点,这被称为初始化。根节点的值就是让损失函数最小的常数值。
让平方损失函数 L = ∑ i = 1 10 ( y i , f ( x i ) ) L=\sum_{i=1}^{10} (y_i, f(x_i)) L=∑i=110(yi,f(xi)) 最小的常数值就是所有 y i y_i yi 的平均值,在这里这个均值是 5.37。
也就是说,我们的初始模型 f 0 ( x ) f_0(x) f0(x) 就等于 5.37.
f 0 ( x ) = 5.37 f_0(x)=5.37 f0(x)=5.37
好的,按照步骤,接下来我们计算每个 y i y_i yi 相对于根节点 5.37 的残差,如下。
| x x x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y y y | -2.17 | -2.57 | -0.87 | -1.77 | -0.37 | 0.73 | 0.13 | 1.83 | 1.43 | 2.63 |
我们对这个残差拟合一棵二叉回归树。
也就是说,我们需要找到一个最优切分点 s s s,它满足:将原始数据集以 s s s 为切分点分成两个部分 R 1 < s , R 2 ≥ s R_1 < s, R_2 \ge s R1<s,R2≥s; c 1 , c 2 c_1, c_2 c1,c2 是使得这两个部分各自内部的损失最小的常数(其实就是这两个部分各自 y i y_i yi 的均值);那么 c 1 + c 2 c_1+c_2 c1+c2 最小。
简单来说,我们要找使得分割后每部分的最小残差之和最小的分割点 s s s.
写成数学语言就是:
min s [ min c 1 ∑ x ∈ R 1 ( y i − c 1 ) 2 + min c 2 ∑ x ∈ R 2 ( y i − c 2 ) 2 ] \min_s\bigg[\min_{c_1}\sum_{x \in R_1}(y_i-c_1)^2+\min_{c_2}\sum_{x \in R_2}(y_i-c_2)^2\bigg] smin[c1minx∈R1∑(yi−c1)2+c2minx∈R2∑(yi−c2)2]
嗯,最小最小问题,还算好处理。
首先我们找到可能的切分点。决策树那篇讲过,找可能切分点的时候,首先把所有样本按照自变量取值大小排序,然后计算相邻两个 x x x 的均值,最终得到的所有的两两之间的均值就是可能的切分点。
按照这个做法,在这个例子中,可能的切分点就是:1.5、2.5、… 9.5。
然后,我们列出在以这些数值作为切分点( s s s)的时候,分割出的两个区域 R 1 , R 2 R_1, R_2 R1,R2 中包含的样本点。
| s s s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|---|---|---|---|---|---|---|---|---|
| R 1 R_1 R1 | 1 | 1,2 | 1~3 | 1~4 | 1~5 | 1~6 | 1~7 | 1~8 | 1~9 |
| R 2 R_2 R2 | 2~10 | 3~10 | 4~10 | 5~10 | 6~10 | 7~10 | 8~10 | 9~10 | 10 |
嗯,接着我们计算在每个分割点的情况下, R 1 , R 2 R_1, R_2 R1,R2 内部的最小损失。
换言之,在这一步,我们要分别在 R 1 , R 2 R_1, R_2 R1,R2 中选出一个常数,记作 c 1 , c 2 c_1, c_2 c1,c2。 c 1 c_1 c1 使得 R 1 R_1 R1 中所有值和它的差的平方的和最小, c 2 c_2 c2 同理。
我们可以通过求解偏导得到, c 1 , c 2 c_1, c_2 c1,c2 各自等于 R 1 , R 2 R_1, R_2 R1,R2 中所有 y i y_i yi 的平均数。这一步的证明很简单,在这里就不赘述了。
经过简单的计算,我们得到了在不同的 s s s(即不同的 R 1 , R 2 R_1, R_2 R1,R2)下, c 1 , c 2 c_1, c_2 c1,c2 的值。
| s s s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|---|---|---|---|---|---|---|---|---|
| R 1 R_1 R1 | 1 | 1,2 | 1~3 | 1~4 | 1~5 | 1~6 | 1~7 | 1~8 | 1~9 |
| c 1 c_1 c1 | -2.17 | -2.37 | -1.87 | -1.845 | -1.75 | -1.35 | -0.98 | -0.69 | -0.686 |
| R 2 R_2 R2 | 2~10 | 3~10 | 4~10 | 5~10 | 6~10 | 7~10 | 8~10 | 9~10 | 10 |
| c 2 c_2 c2 | 0.057 | 0.296 | 0.536 | 1.09 | 1.13 | 1.255 | 1.96 | 2.03 | 2.63 |
接下来就是计算每个 s s s 下 R 1 , R 2 R_1, R_2 R1,R2 内部的平方损失,即 ∑ x ∈ R 1 ( y i − c 1 ) 2 \sum_{x \in R_1}(y_i-c_1)^2 ∑x∈R1(yi−c1)2 和 ∑ x ∈ R 2 ( y i − c 2 ) 2 \sum_{x \in R_2}(y_i-c_2)^2 ∑x∈R2(yi−c2)2。结果如下。
| $s$ | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|---|---|---|---|---|---|---|---|---|
| Loss ( R 1 ) \text{Loss}(R_1) Loss(R1) | 0.00 | 0.04 | 0.23 | 0.30 | 0.43 | 0.49 | 0.56 | 0.57 | 0.59 |
| Loss ( R 2 ) \text{Loss}(R_2) Loss(R2) | 1.89 | 1.60 | 1.05 | 0.28 | 0.21 | 0.06 | 0.17 | 0.04 | 0.00 |
| Loss ( R 1 ) + Loss ( R 2 ) \text{Loss}(R_1) + \text{Loss}(R_2) Loss(R1)+Loss(R2) | 1.89 | 1.64 | 1.28 | 0.58 | 0.64 | 0.55 | 0.73 | 0.61 | 0.59 |
回到我们上面的公式,我们已经得到了:
min c 1 ∑ x ∈ R 1 ( y i − c 1 ) 2 + min c 2 ∑ x ∈ R 2 ( y i − c 2 ) 2 \min_{c_1}\sum_{x \in R_1}(y_i-c_1)^2+\min_{c_2}\sum_{x \in R_2}(y_i-c_2)^2 c1minx∈R1∑(yi−c1)2+c2minx∈R2∑(yi−c2)2
那么接下来就是找让这个值最小的 s s s 了。
根据表格, s = 6.5 s=6.5 s=6.5 的时候上式取到最小值,即这一步中的最优分割点就是 s = 6.5 s=6.5 s=6.5.
嗯,我们找到 s = 6.5 s=6.5 s=6.5 的时候的 c 1 , c 2 c_1, c_2 c1,c2,它们即为根节点的两个分支。
c 1 = − 1.35 c_1=-1.35 c1=−1.35,说明对于 x < 6.5 x<6.5 x<6.5 的分支(即 R 1 R_1 R1),使得它内部平方损失最小的常数是 − 1.35 -1.35 −1.35; c 2 = 1.255 c_2=1.255 c2=1.255,说明对于 x ≥ 6.5 x \ge 6.5 x≥6.5 的分支,使得它内部平方损失最小的常数是 1.255 1.255 1.255。
那么,现在的 GBRT 就可以表示为:
f 1 ( x ) = { 5.73 − 1.35 = 4.38 , x < 6.5 5.73 + 1.255 = 6.985 , x ≥ 6.5 f_1(x)=\begin{cases} 5.73-1.35= 4.38, \ x<6.5 \\ 5.73+1.255= 6.985, \ x \ge 6.5 \end{cases} f1(x)={5.73−1.35=4.38, x<6.55.73+1.255=6.985, x≥6.5
画成图就是:
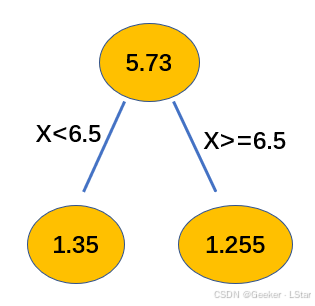
nice!! 我觉得现在你应该明白 GBRT 中的 “拟合残差” 是什么意思啦!
接下来,我们计算新的残差,即当前 GBRT 给出的预测值和真实值之间的残差,然后再为新的残差拟合一棵子树,并把子树加到现有的两个叶结点上。
well,重复上述流程,直到损失函数(残差的平方的和)小于阈值,或达到树的最大深度。
嗯…这里涉及到一个系数的问题——对于每个新添加的决策树 T m ( x , θ ) T_m(x, \theta) Tm(x,θ),我们是直接在原有的 f m − 1 f_{m-1} fm−1 的基础上加 T m T_m Tm(就像上面例子中那样),还是像 adaboost 一样在每个新添加的子树前面都加上一个系数?
well,GBDT 并不强求这件事情,实际上你使用哪种方式都可以。这里的 “系数” 其实就近似于梯度下降中的学习率(下一部分会说明这个 “梯度下降” 是哪来的),通常是人为指定(而不是像 adaboooooost 那样通过分类错误率客观决定),当然也可以通过一些自适应学习率算法比如 adam 来为被加入顺序不同的决策树提供不同的学习率(或者说系数)。
emmm 怎么感觉有点深度学习的感觉了哈哈哈。
okay,到现在为止,我们已经完整地过了一遍 GBDT 算法的流程!!!
but,你可能会发现,诶 GBDT 不是叫梯度提升决策树吗?可是这部分里貌似完全没有说到和梯度有关的任何事情诶…?这里用的一直是残差。
well,别着急,一般化的数学推导马上就来! 你很快就会发现…原来这里的残差只是负梯度的一种特殊情况而已!
let us go!
一般化数学表示
在上一个部分,我讲了在 GBDT 中,当损失函数是平方损失,或者说,当我们拟合的模型是回归树的时候的数学公式。但那其实只是一种特殊情况,“拟合残差” 也只是一个非常碰巧的特例。
在这一部分,我会给出 GBDT 更一般化的数学推导。如果你对前面回归树的部分有疑惑,或许这一部分能够解决你的疑惑。
回归树部分我们说过,GBDT 也是前向分步算法的一种形式,so 在下面我们也把它写成前向分步算法的形式。
f m ( x ) = f m − 1 ( x ) + μ T ( x , θ ) f_m(x)=f_{m-1}(x)+\mu T(x, \theta) fm(x)=fm−1(x)+μT(x,θ)
其中 f m ( x ) f_m(x) fm(x) 是第 m m m 轮迭代后得到的 GBDT, f m − 1 ( x ) f_{m-1}(x) fm−1(x) 是现有的 GBDT, T ( x , θ ) T(x, \theta) T(x,θ) 是在第 m m m 步新添加的子树,它会被添加到 f m − 1 ( x ) f_{m-1}(x) fm−1(x) 的每一个分支上, μ \mu μ 是学习率,可以有也可以没有,用于控制新加入的子树对整棵 GBDT 的贡献,可以防止过拟合。
接下来我们来看看 GBDT 算法的一般流程。这次的配置还是 N N N 个数据点, M M M 个模型。我们以 J J J 叉树为例,不区分分类和回归算法(因而没有具体的损失函数),损失函数统一记作 L L L,不考虑权重 μ \mu μ(即所有加入的树的权重都是 1)。
主打一个通用!
(实际上,在大多数时候,GBDT 都是用于拟合回归树的(对应的,adaboost 常用于拟合分类树),且每个节点最多有两个分支,即二叉树。)
首先是初始化,我们选择一个使得损失函数最小的常数作为 GBDT 的根节点,后面的拟合就从这个根节点开始。我们把此时的模型记作 f 0 ( x ) f_0(x) f0(x),即:
f 0 ( x ) = arg min x L ( y i , f 0 ( x ) ) f_0(x) = \argmin_x L(y_i, f_0(x)) f0(x)=xargminL(yi,f0(x))
豪德,现在我们要找的是根节点下面的 J J J 个分支。
对于每个样本 x i x_i xi,我们都计算它的预测值 y i y_i yi 在损失函数上的负梯度,即:
r 1 i = − [ ∂ L ( y i , f ( x i ) ) ∂ f ( x i ) ] f ( x ) = f 0 ( x ) r_{1i}=-\bigg[\frac{\partial L(y_i, f(x_i))}{\partial f(x_i)}\bigg]_{f(x)=f_{0}(x)} r1i=−[∂f(xi)∂L(yi,f(xi))]f(x)=f0(x)
这样,我们就得到了 N N N 个负梯度。接下来我们对所有这些负梯度拟合 J J J 个分支,即寻找 T 1 ( x , θ ) T_1(x, \theta) T1(x,θ),其中 θ = { ( R 11 , c 11 ) , ( R 12 , c 12 ) , . . . , ( R 1 J , c 1 J ) } \theta=\{(R_{11}, c_{11}), (R_{12}, c_{12}),..., (R_{1J}, c_{1J})\} θ={(R11,c11),(R12,c12),...,(R1J,c1J)}。
在这里我们给出一般化的叙述,对于每一个分支 R 1 j , j ∈ ( 1 , 2 , . . . , J ) R_{1j}, j \in(1, 2, ..., J) R1j,j∈(1,2,...,J),我们都找出使得这个分支的损失函数最小的常数,也就是 c 1 j c_{1j} c1j,用数学语言表示就是:
c 1 j = arg min c ∑ x i ∈ R 1 j L ( y i , f 0 ( x ) + c ) c_{1j}=\argmin_c \sum_{x_i \in R_{1j}}L(y_i, f_0(x)+c) c1j=cargminxi∈R1j∑L(yi,f0(x)+c)
emmm 因为没有确切的损失函数,所以这里没有办法展示对负梯度拟合树的过程,但是其实上一节当中已经给出当损失函数是平方损失时候的例子了。
em 现在假设我们已经找到了使得损失函数最小化的 T 1 ( x , θ ) T_1(x, \theta) T1(x,θ),那么新的 GBDT f 1 ( x ) f_1(x) f1(x) 就等于 f 0 ( x ) + T 1 ( x , θ ) f_0(x)+T_1(x, \theta) f0(x)+T1(x,θ),即:
f 1 ( x ) = f 0 ( x ) + T 1 ( x , θ ) = f 0 ( x ) + ∑ j = 1 J c 1 j I ( x ∈ R 1 j ) f_1(x)=f_0(x)+T_1(x, \theta)=f_0(x)+\sum_{j=1}^Jc_{1j}I(x \in R_{1j}) f1(x)=f0(x)+T1(x,θ)=f0(x)+j=1∑Jc1jI(x∈R1j)
注意,在这一步,拟合出来的新的子树会被加到原来的树的【每个叶节点】下面(当然,因为 f 0 ( x ) f_0(x) f0(x) 只是一个根节点,所以这一步并不涉及到这个这件事情)。
嗯,现在我们就得到了深度为 2 的 GBDT 了,如果取 J = 3 J=3 J=3 的话,画出来大概是这个样子:
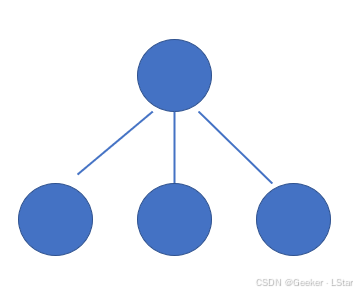
接下来,我们按照类似的步骤继续迭代进行。我们给出当前迭代轮数 m m m,则系列公式如下(呃其实就是把上面说的 m = 1 m=1 m=1 时候的公式扩展了一下啦~):
首先是计算目前的负梯度 r m i r_{mi} rmi:
r m i = − [ ∂ L ( y i , f ( x i ) ) ∂ f ( x i ) ] f ( x ) = f m − 1 ( x ) r_{mi}=-\bigg[\frac{\partial L(y_i, f(x_i))}{\partial f(x_i)}\bigg]_{f(x)=f_{m-1}(x)} rmi=−[∂f(xi)∂L(yi,f(xi))]f(x)=fm−1(x)
然后根据负梯度拟合模型,计算代表每个区域的常数值 c m j c_{mj} cmj:
c m j = arg min c ∑ x i ∈ R m j L ( y i , f 0 ( x ) + c ) c_{mj}=\argmin_c \sum_{x_i \in R_{mj}}L(y_i, f_0(x)+c) cmj=cargminxi∈Rmj∑L(yi,f0(x)+c)
最终将新得到的 J J J 个区域(新的子树)添加到原来的树的所有叶子节点上。
f m ( x ) = f 0 ( x ) + ∑ j = 1 J c 1 j I ( x ∈ R 1 j ) f_m(x)=f_0(x)+\sum_{j=1}^Jc_{1j}I(x \in R_{1j}) fm(x)=f0(x)+j=1∑Jc1jI(x∈R1j)
其实就这么几步嘿嘿嘿。
第二次迭代结束后,GBDT 看起来大概长这个样子,深度为 3:
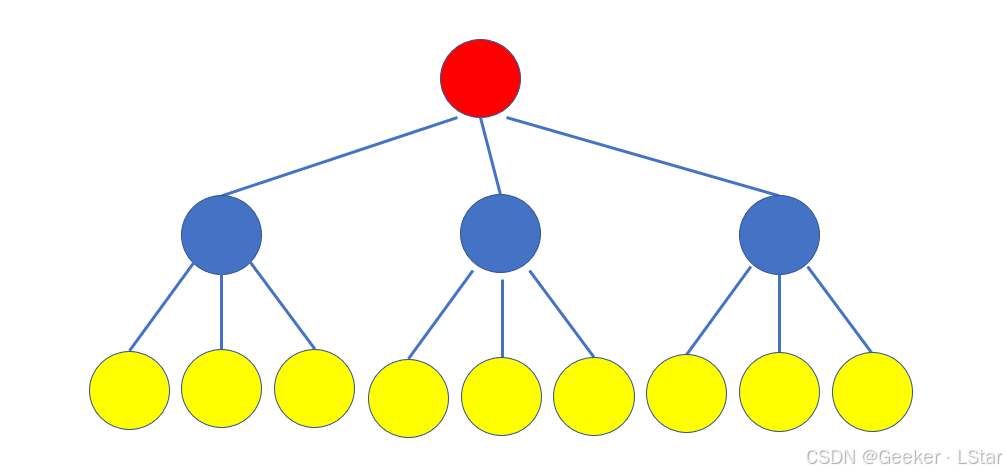
注意,被加到第二层的三个蓝色的点上的新子树(黄色部分)是完全相同的。这一点从公式 f m ( x ) = f m − 1 ( x ) + ∑ j = 1 J c m j I ( x ∈ R m j ) f_m(x)=f_{m-1}(x)+\sum_{j=1}^Jc_{mj}I(x \in R_{mj}) fm(x)=fm−1(x)+∑j=1JcmjI(x∈Rmj) 中也可以看出来。
如果你对这个有些抽象的过程不太理解,可以去看看上一节中的例子。
哦对了,说到上一节中的例子,我们来看看上一节中拟合的残差和这一节中说到的负梯度之间的关系吧!
在损失函数为平方损失,即:
L = ( y i − f m ( x i ) ) 2 = ( r − α G ( x ) ) 2 L=(y_i-f_{m}(x_i))^2=(r-\alpha G(x))^2 L=(yi−fm(xi))2=(r−αG(x))2
的时候,负梯度(负偏导数)是:
− ∂ ( r − α G ( x ) ) 2 ∂ α G ( x ) = − ∂ ( r 2 − 2 r α G ( x ) + α G ( x ) 2 ) ∂ α G ( x ) = − ( − 2 r + 2 α G ( x ) 2 ) = 2 r − 2 α G ( x ) -\frac{\partial (r-\alpha G(x))^2}{\partial \alpha G(x)}=-\frac{\partial(r^2-2r\alpha G(x)+\alpha G(x)^2)}{\partial \alpha G(x)} \\ =-(-2r+2\alpha G(x)^2)=2r-2\alpha G(x) −∂αG(x)∂(r−αG(x))2=−∂αG(x)∂(r2−2rαG(x)+αG(x)2)=−(−2r+2αG(x)2)=2r−2αG(x)
嗯!! 我们拟合负梯度,实际上就是拟合 2 r − 2 α G ( x ) 2r-2\alpha G(x) 2r−2αG(x),这等价于拟合 r − α G ( x ) r-\alpha G(x) r−αG(x),即残差。
也就是说,其实 GBRT 中的残差只是负梯度的一种特殊情况~! 在损失函数为平方损失的时候,负梯度就是残差!
豪德,这一篇的数学不多(而且很简单),到这里差不多所有数学的部分就都结束了,接下来我们来敲一敲黑板…(((
记住,记住,记住,下面的内容很重要。
在 GBDT 中,我们拟合的从来都是【负梯度】,而不是【残差】!残差只是负梯度的一种特例,具体来说,残差只是当损失函数为平方损失的时候负梯度的特例。
(这块真的很容易搞混 errrr 我看到网上好多(甚至 GPT)都说拟合的是残差,还有说用负梯度近似残差的,其实都不准确!!)
还有很重要的一点是,非参数模型 GBDT 中的 “梯度下降” 和我们前面遇到的参数模型求解参数时用的 “梯度下降” 有着不同的目的。
GBDT 求出前一个模型的在损失函数上的负梯度,是为了让下一个模型拟合这些负梯度,而不是利用这些负梯度去更新模型参数。而在我们前面遇到的参数模型(比如线性回归)中,计算出来的梯度是用于更新参数的。
注意,这点非常重要!本质上还是因为决策树是一种非参数模型。就像我们在集成学习概述那篇中说的一样,决策树的学习空间不是参数空间,而是函数空间;它没有需要更新的 “参数”,所以这里得到的负梯度不是用于更新参数的,而是用于找到下一个合适的函数,也就是下一棵决策树的。
嗯!黑板敲得差不多了)))到现在,本篇的主要内容就结束啦!我们来总结一下吧!
总结
okkkkkaaay! 现在所有的内容都讲完了,我们来总结一下 GBDT 吧!
GBDT,中文梯度提升决策树,是 Boosting 家族的一员,可以用于分类或回归任务。GBDT 的核心思想是让后一棵树拟合前一棵树的损失函数的负梯度,进而逐步改进模型的性能。GBDT 可以看作一种 “纵向” 的组合。
GBRT(梯度提升回归树)是 GBDT 在损失函数为平方损失时的特例,GBRT 拟合的是残差。
在 GBDT 中,我们拟合的始终是负梯度,残差只是负梯度的一个特例;GBDT 的学习是在函数空间而非参数空间进行的,它没有显式可学习的参数。
以上就是 GBDT 的全部内容啦!!撒花!!
en!!! 那这篇就到这里啦!!!! 我们下一篇见!!!
这篇文章详细讲解了 GBDT 梯度提升树算法,希望对你有所帮助!⭐
欢迎三连!!一起加油!🎇
——Geeker_LStar

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)