深入骨髓级解析OpenCV光流跟踪:从Lucas-Kanade原理到逐行源码实战,万字长文吃透稀疏光流
深入骨髓级解析OpenCV光流跟踪:从Lucas-Kanade原理到逐行源码实战,万字长文吃透稀疏光流
摘要
在计算机视觉领域,目标跟踪是最具工业落地价值的核心方向之一,而Lucas-Kanade(简称LK)金字塔光流法则是稀疏光流跟踪的经典标杆。凭借轻量高效、无需训练、易工程落地的优势,它被广泛应用于视频电子稳像、动作捕捉、自动驾驶运动估计、实时目标跟踪等场景。
很多开发者能够直接调用OpenCV接口跑通光流代码,却对背后的数学原理、参数设计逻辑、调优技巧一知半解,遇到跟踪漂移、特征点丢失、性能卡顿等问题时无从下手。本文将从光流的基础理论出发,完整推导LK光流的数学公式,深入解析金字塔光流破解大位移问题的核心思想,并对一份工业界通用的LK光流跟踪标准代码进行逐行拆解,同时覆盖调参指南、常见踩坑、进阶优化与多场景应用拓展,帮助你从“调包侠”真正进阶为懂原理、能调优的计算机视觉开发者。
本文所有解析均基于下方原始源码,不修改任何核心逻辑,只做深度原理拆解与工程化拓展。
一、写在前面:为什么我们要吃透光流法?
在计算机视觉的技术体系中,目标跟踪是衔接“图像检测”与“视频时序分析”的关键技术。从手机的视频防抖、短视频的人脸贴纸追踪,到自动驾驶的障碍物运动预测、工业机器人的视觉跟随,背后都有光流法的身影。
在深度学习席卷CV领域的今天,传统光流算法依然拥有不可替代的价值:
- 极致轻量:无需庞大的模型参数,纯数值计算即可实现,在端侧、嵌入式设备上也能实时运行;
- 无数据依赖:不需要标注数据训练,开箱即用,非常适合快速落地的小场景;
- 可解释性强:每一步计算都有明确的数学意义,参数调整有明确的物理含义,调试成本远低于深度学习模型;
- 是高级视频算法的基础:视频插帧、动作识别、三维重建等高端视觉任务,都将光流作为核心特征输入。
而Lucas-Kanade金字塔光流,是所有光流算法中最经典、最常用的入门与落地首选。本文将带着你从最底层的光流约束方程开始,一步步推导出LK算法,再对应到源码的每一行代码,让你不仅知道“怎么写”,更知道“为什么这么写”。
二、光流的本质:从运动场到光流场
2.1 什么是光流?
光流(Optical Flow)的概念最早由心理学家Gibson于1950年提出,它描述的是空间中运动的物体,在成像平面上像素运动的瞬时速度。
我们需要区分两个容易混淆的概念:
- 运动场:三维空间中物体的真实运动,投影到二维成像平面上形成的速度场,反映了物体真实的运动状态;
- 光流场:图像灰度模式变化形成的瞬时速度场,是像素亮度变化的直观表现。
理想情况下,光流场与运动场完全一致——物体运动导致像素亮度变化,亮度变化的速度等于物体运动的速度。但在真实场景中,光照变化、阴影、反光、镜面反射等都会导致像素亮度变化,此时光流场就会偏离真实的运动场,这也是光流算法的核心误差来源之一。
2.2 光流法的三大核心假设
所有光流算法的推导,都建立在三个基础假设之上。这是光流成立的前提,也是后续所有算法局限性的根源:
- 亮度恒定假设
同一个像素点,在相邻帧之间的亮度(灰度值)保持不变。这是光流最核心的假设,后续的光流约束方程完全基于此推导。 - 时间连续性(小运动)假设
像素的运动随时间缓慢变化,相邻帧之间位移很小,不会发生突变。这是泰勒展开近似的数学前提。 - 空间一致性假设
同一局部邻域内的像素,属于同一个物体,具有相同的运动。这是求解光流方程的关键约束。
2.3 光流约束方程的完整推导
基于亮度恒定假设,我们可以推导出光流领域最基础的方程——光流约束方程。
设 t 时刻,像素点 (x,y) 处的灰度值为 I(x,y,t)。经过 dt 时间后,该像素运动到了 (x+dx, y+dy) 位置,此时灰度值为 I(x+dx, y+dy, t+dt)。
根据亮度恒定假设,同一像素运动前后灰度值不变:
I(x,y,t)=I(x+dx,y+dy,t+dt)I(x,y,t) = I(x+dx, y+dy, t+dt)I(x,y,t)=I(x+dx,y+dy,t+dt)
对右侧进行泰勒一阶展开:
I(x+dx,y+dy,t+dt)=I(x,y,t)+∂I∂xdx+∂I∂ydy+∂I∂tdt+εI(x+dx, y+dy, t+dt) = I(x,y,t) + \frac{\partial I}{\partial x}dx + \frac{\partial I}{\partial y}dy + \frac{\partial I}{\partial t}dt + \varepsilonI(x+dx,y+dy,t+dt)=I(x,y,t)+∂x∂Idx+∂y∂Idy+∂t∂Idt+ε
其中 ε\varepsilonε 是高阶无穷小项,小位移下可以忽略。将两式联立,两边减去 I(x,y,t),再除以 dt,整理可得:
∂I∂x⋅dxdt+∂I∂y⋅dydt+∂I∂t=0\frac{\partial I}{\partial x} \cdot \frac{dx}{dt} + \frac{\partial I}{\partial y} \cdot \frac{dy}{dt} + \frac{\partial I}{\partial t} = 0∂x∂I⋅dtdx+∂y∂I⋅dtdy+∂t∂I=0
我们令:
- Ix=∂I∂xI_x = \frac{\partial I}{\partial x}Ix=∂x∂I:图像在x方向的空间梯度
- Iy=∂I∂yI_y = \frac{\partial I}{\partial y}Iy=∂y∂I:图像在y方向的空间梯度
- It=∂I∂tI_t = \frac{\partial I}{\partial t}It=∂t∂I:图像在时间维度的梯度
- u=dxdtu = \frac{dx}{dt}u=dtdx:像素在x方向的光流速度
- v=dydtv = \frac{dy}{dt}v=dtdy:像素在y方向的光流速度
最终得到经典的光流约束方程:
Ix⋅u+Iy⋅v+It=0I_x \cdot u + I_y \cdot v + I_t = 0Ix⋅u+Iy⋅v+It=0
2.4 孔径问题:一个方程解不出两个未知数
光流约束方程只有1个,但我们要求解的未知数有 u 和 v 两个,这意味着方程有无穷多组解,这就是著名的孔径问题。
你可以想象透过一个小孔观察一条移动的直线:你只能看到直线在垂直于自身方向的运动,无法判断它沿着自身方向的运动。对应到图像中,边缘区域的像素只能得到垂直于边缘方向的速度,无法得到完整的运动向量。
要解决孔径问题,就必须引入额外的约束条件。而Lucas-Kanade算法,就是通过“空间一致性假设”,引入邻域像素的约束,构建超定方程组来求解唯一解。
三、Lucas-Kanade光流算法:从核心思想到数学推导
3.1 LK算法的核心思想
1981年,Bruce D. Lucas 和 Takeo Kanade 提出了Lucas-Kanade光流算法,其核心设计思路就是利用空间一致性假设:
在一个很小的局部邻域窗口内,所有像素的运动是相同的,即拥有相同的光流向量 (u,v)。
基于这个假设,我们可以取一个 m×m 的邻域窗口(比如3×3、5×5、15×15),窗口内的每一个像素都可以列出一个光流约束方程。n个像素就能得到n个方程,构建出超定方程组,再用最小二乘法求解,就能得到唯一的 (u,v) 解。
3.2 方程组的构建与最小二乘求解
对于窗口内的第 i 个像素,光流约束方程为:
Ixi⋅u+Iyi⋅v=−ItiI_{x_i} \cdot u + I_{y_i} \cdot v = -I_{t_i}Ixi⋅u+Iyi⋅v=−Iti
将窗口内所有像素的方程写成矩阵形式:
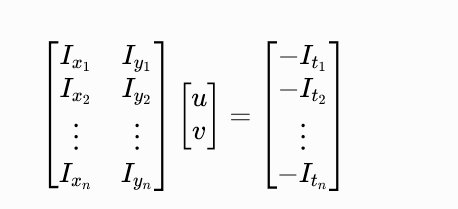
我们记为:
A⋅[uv]=bA \cdot \begin{bmatrix} u \\ v \end{bmatrix} = bA⋅[uv]=b
其中 A 是 n×2 的梯度矩阵,b 是 n 维的时间梯度向量。这是一个超定方程组(方程数大于未知数),使用最小二乘法求解:
[uv]=(ATA)−1ATb\begin{bmatrix} u \\ v \end{bmatrix} = (A^T A)^{-1} A^T b[uv]=(ATA)−1ATb
展开后得到:
[uv]=[∑Ix2∑IxIy∑IxIy∑Iy2]−1[−∑IxIt−∑IyIt] \begin{bmatrix} u \\ v \end{bmatrix} = \begin{bmatrix} \sum I_x^2 & \sum I_x I_y \\ \sum I_x I_y & \sum I_y^2 \end{bmatrix}^{-1} \begin{bmatrix} -\sum I_x I_t \\ -\sum I_y I_t \end{bmatrix} [uv]=[∑Ix2∑IxIy∑IxIy∑Iy2]−1[−∑IxIt−∑IyIt]
3.3 解的稳定性与角点的意义
从上面的公式可以看出,光流能否稳定求解,关键在于矩阵 M=ATAM = A^T AM=ATA 是否可逆,以及逆矩阵的数值稳定性。
根据矩阵特征值的性质:
- 如果两个特征值都很小,说明窗口内是平坦区域,梯度几乎为0,解非常不稳定;
- 如果一个特征值大、一个特征值小,说明窗口内是边缘,依然存在孔径问题,解不稳定;
- 如果两个特征值都很大且接近,说明窗口内是角点(两个方向都有明显梯度),矩阵可逆性好,解最稳定。
这就是为什么光流跟踪一定要用角点作为特征点——只有角点才能给出稳定可靠的光流解。平坦区域和边缘区域的跟踪误差极大,没有实用价值。这也同时解释了,为什么源码中第一步要先做角点检测。
3.4 标准LK算法的固有局限性
标准的LK光流算法虽然优雅,但存在三个明显的短板:
- 只能处理小位移
推导中我们做了泰勒一阶展开近似,这个近似只有在位移很小的时候才成立。如果物体运动很快,相邻帧位移大,高阶项不能忽略,计算误差会急剧上升,甚至完全跟踪失败。 - 对光照变化敏感
一旦场景光照发生变化,亮度恒定假设被打破,光流计算结果会出现明显偏差。 - 无法处理遮挡
如果邻域内的像素被遮挡,空间一致性假设不成立,方程组的解会出现严重错误。
3.5 金字塔光流:破解大位移难题
为了解决大位移跟踪问题,研究者在标准LK算法的基础上引入了图像金字塔,形成了金字塔Lucas-Kanade光流,也就是我们源码中使用的算法。
3.5.1 核心思路:多尺度逐层细化
图像金字塔就是对原图进行多次下采样,形成从大到小的多层图像,堆叠起来像金字塔一样。底层是原图,分辨率最高;顶层分辨率最低,物体尺寸最小。
大位移在高分辨率原图上很明显,但在低分辨率的顶层图像中,位移会按比例缩小,就满足了“小运动”的假设。
金字塔光流的计算逻辑是由粗到精:
- 先在最顶层的低分辨率图像上计算光流,得到粗略的运动估计;
- 将粗略估计的结果作为初始值,传递到下一层更高分辨率的图像上,做进一步的细化修正;
- 逐层向下传递,直到最底层的原图,得到最终的精确光流。
3.5.2 为什么能处理大位移?
举个直观的例子:
假设原图上物体位移了16像素,这属于大位移,标准LK算法肯定跟踪失败。
如果我们构建4层金字塔,每层长宽下采样1/2,那么顶层图像是原图的1/8大小,16像素的位移在顶层就变成了2像素,完全满足小运动假设。
我们在顶层算出2像素的光流,传到下一层时放大一倍作为初始值,再计算增量修正,以此类推,最终在原图上就能得到准确的16像素位移。
这就是金字塔光流的精髓:通过多尺度分解,把大位移拆解成多层小位移,逐层求解,既保留了LK算法的高效,又解决了大位移跟踪难题。
源码中的 maxLevel 参数,就是控制金字塔的层数,层数越多,能处理的位移越大,但计算量也成倍增加。
四、环境搭建与项目准备
在进入源码解析之前,我们先把运行环境准备好,确保你能跟着文章一步步跑通效果。
4.1 开发环境说明
- Python 版本:3.7 及以上均可,推荐 3.9/3.10 稳定版
- 核心依赖库:
opencv-python:OpenCV的Python接口,提供图像处理与光流计算APInumpy:数值计算基础库,用于矩阵运算与图像数据存储
4.2 依赖库一键安装
打开终端执行以下命令即可完成安装:
pip install opencv-python numpy
补充说明:如果需要更多高级视觉算法,可以安装
opencv-contrib-python,但本文用到的接口都在主库中,无需额外安装。如果遇到视频解码问题,可以安装opencv-python-headless提升编码兼容性。
4.3 测试素材准备
- 视频文件测试:准备一段AVI格式的视频,文件名改为
test.avi,和代码放在同一目录下。建议选择有明显运动物体的视频(比如行走的人、行驶的车),效果更直观。小提示:OpenCV原生对MJPG编码的AVI兼容性最好,如果MP4视频打不开,大概率是编码问题,用格式工厂转成AVI即可。
- 摄像头实时测试:如果你想用电脑摄像头实时测试,只需要把代码中
cv2.VideoCapture('test.avi')改为cv2.VideoCapture(0),0代表默认摄像头。
五、完整源码:开箱即用的LK金字塔光流跟踪实现
以下是本文解析的原始标准源码,全程不做任何修改,所有解析与拓展均基于此代码展开:
import numpy as np
import cv2
# 打开视频文件
cap = cv2.VideoCapture('test.avi')
# 随机生成颜色,用于绘制轨迹
color = np.random.randint(0, 255, (100, 3))
# 读取视频的第一帧
ret, old_frame = cap.read()
# 将第一帧转换为灰度图像
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# 定义特征点检测参数
feature_params = dict(maxCorners=100, # 最大角点数量
qualityLevel=0.3, # 角点质量的阈值
minDistance=7) # 最小距离,用于分散角点
# 使用角点检测方法找到特征点
# goodFeaturesToTrack(image, maxCorners, qualityLevel, minDistance, corners=None, mask=None, blockSize=None, useHarrisDetector=None, k=None)
# image:输入单通道图像,用灰度图
# maxCorners:设定最大的角点个数,是最有可能的角点数,如果这个参数不大于0,那么表示没有角点数的限制。
# qualityLevel:图像角点的最小可接受参数,质量测量值乘以这个参数就是最小特征值,小于这个数的会被抛弃。
# minDistance:角点之间最小的欧式距离。
# mask:检测区域。如果图像不是空的,它指定检测角的区域。
# 返回所有角点坐标位置:corners
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params) # **:关键字参数解包,用于将字典解包为关键字参数。
# 创建一个与当前帧大小相同的全零掩模,用于绘制轨迹
mask = np.zeros_like(old_frame)
# 定义Lucas-Kanade光流参数
lk_params = dict(winSize=(15, 15), # 窗口大小
maxLevel=2) # 金字塔层数
# 主循环,处理视频的每一帧
while True:
# 读取下一帧
ret, frame = cap.read()
# 检查是否成功读取到帧
if not ret:
break
# 将当前帧转换为灰度图像
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流,获取新的特征点位置和状态
# calcOpticalFlowPyrLK(prevImg, nextImg, prevPts, nextPts, status=None, err=None, winSize=None, maxLevel=None,
# criteria=None, flags=None, minEigThreshold=None)
# prevImg:前一帧图像
# nextImg:当前帧图像
# prevPts:前一帧图像中特征点坐标
# nextPts:当前帧图像中特征点坐标,可以为None
# winSize:搜索窗口的大小
# maxLevel:金字塔层数
# criteria:停止迭代的准则
# 返回值:
# nextPts:在当前帧中估计出的特征点坐标
# status:一个与prevPts一样大小的状态向量,用于表示特征点是否被成功跟踪到。
# err:一个prevPts样大小的误差向量,用于表示估计误差
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, nextPts=None, **lk_params)
# 选择好的点(状态为1的点)
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel() # 获取新点的坐标 或者[a, b] = new
c, d = old.ravel() # 获取旧点的坐标
a, b, c, d = int(a), int(b), int(c), int(d) # 转换为整数
# 在掩模上绘制线段,连接新点和旧点
mask = cv2.line(mask, pt1=(a, b), pt2=(c, d), color=color[i].tolist(), thickness=2)
cv2.imshow(winname='mask', mat=mask)
# 将掩模添加到当前帧上,生成最终图像
img = cv2.add(frame, mask)
# 显示结果图像
cv2.imshow(winname='frame', mat=img)
# 等待150ms,检测是否按下了Esc键(键码为27)
k = cv2.waitKey(150)
if k == 27: # 按下Esc键,退出循环
break
# 更新旧灰度图和旧特征点
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2) # 重新整理特征点为适合下次计算的形状 (38,2)-->(38,1,2)
# 释放资源
cap.release()
cv2.destroyAllWindows()
六、逐行源码深度拆解:每一行都给你讲明白
这是本文的核心章节,我们将把代码拆分成7个模块,逐行讲解每一句代码的作用、原理和设计逻辑,带你彻底读懂这份经典实现。
6.1 模块一:依赖库导入
import numpy as np
import cv2
numpy:Python生态的数值计算基石,OpenCV的图像数据本质上就是numpy多维数组。后续的矩阵运算、坐标处理、掩码生成都依赖numpy。cv2:OpenCV的Python绑定库,封装了所有图像处理、特征检测、光流计算的API,是整个程序的核心工具。
6.2 模块二:视频流初始化与轨迹颜色生成
# 打开视频文件
cap = cv2.VideoCapture('test.avi')
# 随机生成颜色,用于绘制轨迹
color = np.random.randint(0, 255, (100, 3))
第1行:打开视频源
cv2.VideoCapture 是OpenCV的视频捕获类,是所有视频处理任务的入口。它的参数非常灵活:
- 传文件路径:读取本地视频文件,如代码中的
'test.avi'; - 传数字:打开本地摄像头,如
0代表系统默认摄像头; - 传URL:读取网络视频流,如RTSP监控流。
返回的 cap 是一个VideoCapture对象,后续通过它逐帧读取视频。
第2行:生成轨迹颜色
np.random.randint(0, 255, (100, 3)) 生成一个100行3列的整数数组,每个数值在0-255之间。
- 100对应最大角点数量(后续
maxCorners=100),每个特征点对应一个专属颜色; - 3对应BGR三个颜色通道(注意:OpenCV默认通道顺序是BGR,不是RGB)。
随机颜色的目的是让不同特征点的轨迹区分度更高,方便观察每个点的运动路径。
6.3 模块三:初始帧预处理与角点检测
这是跟踪的准备阶段:读取第一帧作为基准,提取初始跟踪特征点。
# 读取视频的第一帧
ret, old_frame = cap.read()
# 将第一帧转换为灰度图像
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# 定义特征点检测参数
feature_params = dict(maxCorners=100,
qualityLevel=0.3,
minDistance=7)
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
读取第一帧
cap.read() 从视频中读取一帧,返回两个值:
ret:布尔值,True表示读取成功,False表示读取失败(视频结束、文件损坏等);old_frame:读取到的图像帧,是形状为(高度, 宽度, 3)的numpy数组,BGR三通道格式。
光流计算需要前后两帧对比,第一帧就是整个跟踪过程的起始基准。
转为灰度图
cv2.cvtColor 是颜色空间转换函数,COLOR_BGR2GRAY 表示将BGR彩色图转为单通道灰度图。
为什么一定要用灰度图?
- 光流的亮度恒定假设基于灰度值,单通道才能计算像素亮度变化;
- 角点检测、梯度计算都是基于灰度图实现的;
- 单通道计算量远小于三通道,大幅提升运行速度。
角点检测参数配置
代码用字典封装了Shi-Tomasi角点检测的三个核心参数,后续通过**解包传入函数,这种写法让参数配置更集中,维护更方便。
三个参数的详细含义:
- maxCorners=100:最大角点数量。算法会对所有检测到的角点按质量从高到低排序,只返回前100个质量最好的。数量越多跟踪点越密,但计算量越大。
- qualityLevel=0.3:角点质量阈值。取值0-1,代表最低可接受的质量比例。比如最佳角点质量分数为100,低于30分的角点会被直接丢弃。值越高,角点质量越好,但数量越少。
- minDistance=7:角点之间的最小欧式距离,单位像素。如果两个角点距离小于7像素,质量低的会被剔除,目的是让角点均匀分布,避免扎堆。
Shi-Tomasi角点检测
cv2.goodFeaturesToTrack 是OpenCV封装的Shi-Tomasi角点检测函数,俗称“好的特征点检测”,是光流跟踪的标准特征提取方案。
- 输入:灰度图、检测掩码、角点参数;
- 输出:检测到的角点坐标
p0,形状为(N, 1, 2),N是角点数量,每个点是(x,y)浮点坐标。
这里有两个关键细节:
- 为什么用Shi-Tomasi而不是Harris角点?
Harris角点评分公式为 R=det(M)−k⋅trace(M)2R = det(M) - k \cdot trace(M)^2R=det(M)−k⋅trace(M)2,依赖经验参数k;而Shi-Tomasi直接取梯度矩阵两个特征值的较小值作为评分 R=min(λ1,λ2)R = min(\lambda_1, \lambda_2)R=min(λ1,λ2),没有额外参数,稳定性更好,在跟踪任务中表现更优。 - 为什么输出形状是(N,1,2)?
这是OpenCV光流计算接口强制要求的输入格式,属于API设计规范,后续计算光流时必须保持这个形状。
6.4 模块四:轨迹掩码与光流参数初始化
# 创建一个与当前帧大小相同的全零掩模,用于绘制轨迹
mask = np.zeros_like(old_frame)
# 定义Lucas-Kanade光流参数
lk_params = dict(winSize=(15, 15),
maxLevel=2)
轨迹掩码
np.zeros_like(old_frame) 生成一个和原图像尺寸、数据类型完全一致的全零数组,也就是一张纯黑的画布。
为什么要用独立的mask画轨迹,而不是直接在原图上画?
因为轨迹是累积的:每一帧我们只画一条短线段,连接特征点的新旧位置。如果直接在原图上画,下一帧原图更新后,之前的轨迹就会消失。用独立的mask画布累积所有线段,最后叠加到原图上,就能看到完整的运动轨迹。
LK光流参数
同样用字典封装了金字塔光流的两个核心参数:
- winSize=(15,15):LK算法的邻域搜索窗口大小,也就是我们前面讲的“局部邻域”尺寸。窗口越大,包含的像素越多,方程组越稳定,抗噪能力越强,但计算量越大,也越容易违反“邻域运动一致”的假设。
- maxLevel=2:金字塔最大层数。0表示不用金字塔(标准LK),数值越大层数越多,能处理的位移越大,但计算量成倍增长。maxLevel=2表示有0、1、2三层,第0层是原图,第2层是下采样两次的图像。
补充:还有两个常用参数代码中使用了默认值:
criteria:迭代停止准则,默认最多迭代30次,或精度达到0.01时停止;minEigThreshold:最小特征值阈值,默认1e-4,梯度矩阵特征值小于该值的点会被判定为跟踪失败。
6.5 模块五:主循环——逐帧光流计算
这是程序的核心循环,逐帧读取视频、计算光流、更新跟踪点。
while True:
# 读取下一帧
ret, frame = cap.read()
# 检查是否成功读取到帧
if not ret:
break
# 将当前帧转换为灰度图像
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
while True开启无限循环,直到视频结束或手动退出;- 每次循环读取一帧新图像,转为灰度图,和前一帧灰度图配对,用于光流计算;
if not ret: break是视频处理的标准容错,读取失败时及时退出,避免空帧报错。
核心:金字塔光流计算
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, nextPts=None, **lk_params)
cv2.calcOpticalFlowPyrLK 就是金字塔Lucas-Kanade光流的计算函数,是整个程序的心脏。
输入参数:
old_gray:前一帧灰度图(基准帧)frame_gray:当前帧灰度图(目标帧)p0:前一帧的特征点坐标,形状(N,1,2)nextPts=None:输出参数,传None表示由函数自动创建结果数组**lk_params:关键字参数解包,传入光流配置
返回值:
p1:当前帧中特征点的估计坐标,形状和p0一致,(N,1,2)浮点型;st:状态向量,形状(N,1),元素为0或1。1表示该点跟踪成功,0表示跟踪失败(移出画面、被遮挡、纹理不足);err:误差向量,形状(N,1),每个元素对应点的跟踪误差,一般为窗口内像素差的均值,用于评估跟踪质量。
筛选有效跟踪点
# 选择好的点(状态为1的点)
good_new = p1[st == 1]
good_old = p0[st == 1]
利用状态向量 st 做掩码筛选,只保留跟踪成功的点。
good_new:当前帧中成功跟踪的点,形状(M, 2),M ≤ N;good_old:前一帧中对应的点,形状和good_new一致。
为什么必须筛选?跟踪失败的点坐标是无效的,如果继续参与绘制和后续计算,会出现乱线、漂移轨迹,甚至导致程序报错。
6.6 模块六:轨迹绘制与结果显示
# 绘制轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel() # 获取新点的坐标
c, d = old.ravel() # 获取旧点的坐标
a, b, c, d = int(a), int(b), int(c), int(d) # 转换为整数
# 在掩模上绘制线段
mask = cv2.line(mask, pt1=(a, b), pt2=(c, d), color=color[i].tolist(), thickness=2)
cv2.imshow(winname='mask', mat=mask)
# 将掩模添加到当前帧上
img = cv2.add(frame, mask)
# 显示结果图像
cv2.imshow(winname='frame', mat=img)
逐点绘制轨迹线
循环遍历每一对成功跟踪的新旧点,在mask画布上画线段:
new.ravel():将形状为(2,)的坐标数组展平,提取x、y坐标。也可以直接用a, b = new解包,效果一致;- 转int:光流计算得到的是浮点坐标,而图像像素坐标是整数,必须转为整型才能正确绘制;
cv2.line:在mask上画线段,连接前一帧位置和当前帧位置,线宽2像素,颜色对应该点的随机颜色;cv2.imshow('mask', mask):单独弹出窗口显示纯轨迹图,方便观察轨迹累积效果。
轨迹叠加与主窗口显示
cv2.add(frame, mask):像素加法,将当前帧和轨迹掩码按像素相加。因为mask大部分区域是黑色(数值为0),相加后只有轨迹线的位置会叠加彩色,原图其他区域保持不变,最终实现“轨迹画在视频上”的效果;cv2.imshow('frame', img):弹出主窗口,显示叠加了运动轨迹的视频画面。
6.7 模块七:交互控制与状态更新
# 等待150ms,检测是否按下Esc键
k = cv2.waitKey(150)
if k == 27:
break
# 更新旧灰度图和旧特征点
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
按键控制
cv2.waitKey(150) 等待键盘输入,参数是超时时间,单位毫秒:
- 150ms内有按键按下,返回按键的ASCII码;超时无按键返回-1;
- 150ms的延时同时控制了视频播放速度,延时越小播放越快,实时摄像头场景一般设为1;
k == 27:Esc键的ASCII码为27,按下Esc键跳出循环,结束程序,这是OpenCV程序的标准退出方式。
状态更新(最容易踩坑的一行)
p0 = good_new.reshape(-1, 1, 2)
这是新手最容易出错的一行代码。
筛选后的 good_new 形状是 (M, 2),而 calcOpticalFlowPyrLK 要求输入的特征点必须是 (M, 1, 2) 的三维格式,所以必须用 reshape 调整维度。
-1表示自动计算该维度大小,这里就是自动匹配点的数量M;- 如果忘记reshape,直接传入二维数组,会直接报维度不匹配的错误。
同时,old_gray = frame_gray.copy() 将当前帧灰度图赋值给旧帧,作为下一循环的基准帧。使用 copy() 是为了避免numpy的浅引用问题,防止后续修改互相影响。
6.8 模块八:资源释放
# 释放资源
cap.release()
cv2.destroyAllWindows()
cap.release():释放视频捕获对象,关闭视频文件或摄像头,释放内存与文件句柄;cv2.destroyAllWindows():销毁所有OpenCV创建的显示窗口。
这是OpenCV程序的标准收尾操作。如果省略,可能出现视频文件被占用、窗口卡死、内存泄漏等问题,属于必须养成的编码习惯。
七、核心API调参指南:改对参数效果翻倍
很多人跑光流代码效果不好,不是算法不行,而是参数没调对。这一节我们把两个核心函数的所有参数讲透,给出不同场景的调参建议。
7.1 goodFeaturesToTrack 完整调参表
| 参数 | 含义 | 默认值 | 调参建议 |
|---|---|---|---|
| maxCorners | 最大角点数量 | 无默认 | 实时场景设50-100,精细跟踪设200-500 |
| qualityLevel | 角点质量阈值 | 无默认 | 纹理丰富场景0.2-0.3,纹理稀疏场景0.05-0.1 |
| minDistance | 角点最小间距(像素) | 无默认 | 低分辨率设5-7,高分辨率设15-20 |
| mask | 检测区域掩码 | None | 只关注特定区域时传入掩码,减少计算量 |
| blockSize | 梯度计算邻域大小 | 3 | 噪声大的画面设5-7,提升角点稳定性 |
| useHarrisDetector | 是否用Harris角点 | False | 保持默认即可,Shi-Tomasi跟踪效果更好 |
| k | Harris角点参数 | 0.04 | 仅开启Harris时生效,一般不用修改 |
7.2 calcOpticalFlowPyrLK 完整调参表
| 参数 | 含义 | 默认值 | 调参建议 |
|---|---|---|---|
| winSize | 搜索窗口尺寸 | (21,21) | 小运动高精度设(11,11),大运动抗噪设(21,21) |
| maxLevel | 金字塔层数 | 3 | 慢速运动设1-2,快速运动设3-4 |
| criteria | 迭代停止准则 | 30次迭代/0.01精度 | 追求速度减到10次,追求精度加到50次 |
| minEigThreshold | 最小特征值阈值 | 1e-4 | 误跟多就调大到1e-3,点太少就调小到1e-5 |
7.3 典型场景参数参考
- 实时摄像头人脸追踪
- 特征点:
maxCorners=50, qualityLevel=0.2, minDistance=10 - 光流:
winSize=(15,15), maxLevel=1
- 特征点:
- 交通监控车辆跟踪
- 特征点:
maxCorners=200, qualityLevel=0.3, minDistance=15 - 光流:
winSize=(21,21), maxLevel=3
- 特征点:
- 高清视频精细分析
- 特征点:
maxCorners=500, qualityLevel=0.1, minDistance=20 - 光流:
winSize=(31,31), maxLevel=4
- 特征点:
八、运行现象解读:为什么会出现这些问题?
跑通代码后,你会观察到一些典型现象,背后都对应着算法的固有特性:
- 特征点越跟踪越少
正常现象。特征点移出画面、被遮挡、纹理变化都会导致跟踪失败,被状态向量过滤掉。原始代码没有补充新特征点的机制,所以点会越来越少,最后可能全部消失。 - 长时间跟踪轨迹慢慢漂移
光流每帧都有微小误差,随着时间推移误差累积,就会出现轨迹漂移。这是所有增量式跟踪算法的共性问题。 - 物体快速移动时轨迹断裂
位移超过了金字塔能处理的范围,跟踪失败,点被剔除。可以通过增加maxLevel、加大winSize来改善。 - 光照突变时大量点丢失
违反了亮度恒定假设,像素亮度突变导致梯度计算失效,跟踪失败。可以通过光照归一化预处理缓解。 - 墙面、天空等区域没有跟踪点
平坦区域没有角点,Shi-Tomasi检测不到特征点,属于正常现象。
九、新手必看:常见踩坑与解决方案
9.1 坑1:视频打不开,ret一直是False
原因:文件路径错误、视频编码不兼容、文件损坏。
解决方案:
- 用绝对路径测试,配合
os.path.exists()确认文件存在; - 将视频转为MJPG编码的AVI格式,兼容性最好;
- 安装ffmpeg依赖,提升OpenCV的解码能力。
9.2 坑2:报错 npoints > 0 异常
原因:所有特征点都跟踪失败了,good_new 是空数组,reshape后传入光流函数,因为点数量为0报错。
解决方案:
- 光流计算前加判断:
if len(good_new) == 0时,重新检测特征点或直接退出; - 每隔固定帧数重新检测一次特征点,补充新鲜点。
9.3 坑3:轨迹画不出来,画面只有原图
原因:坐标未转整型、颜色格式错误、坐标超出图像范围。
解决方案:
- 确认坐标已经转为int类型;
- 颜色用
.tolist()转为Python列表,不要直接传numpy数组; - 打印坐标值,确认在图像宽高范围内。
9.4 坑4:运行卡顿,帧率极低
原因:视频分辨率过高、特征点数量太多、金字塔层数太深、窗口太大。
解决方案:
- 先将图像缩放到640×480再处理;
- 减少maxCorners到100以内;
- 降低maxLevel,缩小winSize。
9.5 坑5:reshape维度错误
原因:筛选后点数量为0,reshape失败;或者维度参数写错。
解决方案:先判断点数量大于0再执行reshape,严格保持 (-1, 1, 2) 的格式。
十、进阶优化:让你的光流跟踪更鲁棒
原始代码是最简实现,适合学习原理。如果要用到实际项目中,可以从以下几个方向优化,大幅提升跟踪稳定性。
10.1 自动补充特征点
每隔N帧重新运行一次角点检测,将新检测到的、与现有跟踪点距离足够远的点补充到跟踪队列中,解决点越跟踪越少的问题。这是工程化落地的必备优化。
10.2 反向光流校验
计算前向光流(前帧→当前帧)后,再反向计算一次光流(当前帧→前帧),如果正反两个方向同一点的位置差超过阈值,就认为跟踪不可靠,直接剔除。这个方法能大幅减少误跟踪点,是工业界常用的鲁棒性提升手段。
10.3 光照归一化预处理
每一帧都做直方图均衡化、灰度归一化,减少光照变化对亮度恒定假设的破坏,提升光照变化场景下的跟踪成功率。
10.4 结合卡尔曼滤波预测
为每个特征点建立卡尔曼滤波模型,预测下一帧的位置,作为光流计算的初始值。既能提升大运动下的跟踪成功率,又能解决短时遮挡的问题。
10.5 特征点均匀化策略
补充新点时做距离判断,和已有点距离过近的不保留,让特征点均匀分布在画面上,避免局部点扎堆浪费算力。
十一、拓展:光流法还能做什么?
光流的能力远不止画轨迹,它是视频分析的万能工具,在很多领域都有核心应用:
- 视频电子稳像:计算全局光流得到相机的运动参数,对图像做反向变换,抵消手持抖动,手机视频防抖的核心原理就是它。
- 运动目标分割:计算稠密光流,对光流向量聚类,区分运动的前景和静止的背景,实现动态相机下的运动检测。
- 动作识别:双流网络的经典架构,一路输入RGB图像,一路输入光流图,融合时空特征做行为识别,是视频理解的基础方案。
- 自动驾驶运动估计:对车辆、行人计算光流,得到它们的运动速度和方向,预测未来轨迹,为避障决策提供依据。
- 视频插帧:通过光流估计像素运动轨迹,生成两帧之间的中间帧,将24fps视频升到60fps甚至更高帧率。
十二、稀疏光流 vs 稠密光流:怎么选?
光流分为两大类,除了本文讲的LK稀疏光流,还有稠密光流(如Farneback、TV-L1)。
- 稀疏光流(LK):只跟踪少数特征点,计算量小、速度快、实时性好;但只能得到离散点的运动,无法得到全运动场。适合目标跟踪、实时端侧场景。
- 稠密光流:计算每个像素的光流,得到完整的光流场;但计算量大、速度慢,对硬件要求高。适合视频分析、运动分割、特征提取场景。
选型时根据你的任务需求选择:追求实时、轻量选稀疏光流;追求完整运动信息选稠密光流。
十三、写在最后
在深度学习飞速发展的今天,很多人觉得传统算法已经过时了。但实际上,在工业落地的真实场景中,像LK光流这样轻量、可靠、可解释的传统算法,依然是很多方案的首选。
读懂原理、吃透源码、掌握调优,才能在面对真实问题时,选出最合适的技术方案,而不是盲目上大模型。
本文从光流的数学本质出发,完整推导了LK算法的来龙去脉,逐行拆解了标准实现的每一行代码,同时覆盖了调参、踩坑、优化与应用拓展。希望这篇万字长文,能帮你真正吃透Lucas-Kanade光流,在计算机视觉的学习路上更进一步。
如果你觉得文章对你有帮助,欢迎点赞收藏,也可以在评论区交流你的光流落地经验。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)