Mamba+时序预测,超越传统刷爆SOTA!
🧀Mamba在性能和效率上的优势大家都有目共睹,因此最近越来越多研究也开始关注Mamba+时间序列预测。
🧀在时间序列预测中,数据的长期依赖性是一个核心的挑战。与Transformer等模型相比,Mamba在训练阶段和推理阶段都具有随序列长度线性增长的时间复杂度,这显著提高了运算效率。同时,Mamba的架构相对简单,去除了传统的注意力和MLP块,也提供了更好的可扩展性和性能。
🧀如SiMBA等多个基于Mamba的时间序列预测实践案例证明了这一方法的有效性,在实现SOTA的同时还能保持较低的计算开销。
🧀为帮大家梳理Mamba时间序列预测的最新进展,我整理了2024新发表的11篇高质量工作,可参考的创新点都提炼好了,开源代码已附。
论文1
标题:
Bi-Mamba+: Bidirectional Mamba for Time Series Forecasting
Bi-Mamba+:用于时间序列预测的双向 Mamba
方法:
-
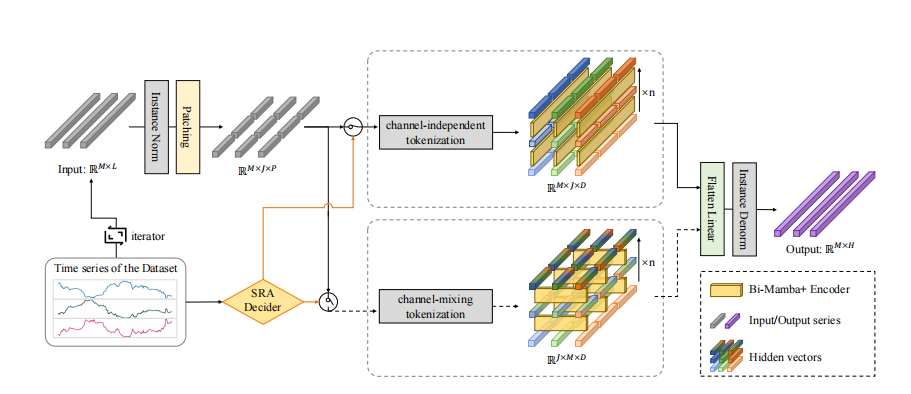
Mamba+模块:在 Mamba 的基础上增加了遗忘门,选择性地将新特征与历史特征以互补的方式结合,从而在更长的范围内保留历史信息。
-
双向结构:设计了双向 Mamba+编码器,分别从正向和反向对多变量时间序列数据进行建模,增强模型对时间序列元素之间交互的捕捉能力。
-
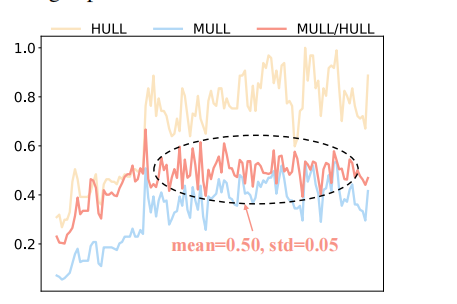
序列关系感知决策器(SRA):根据数据集中变量对之间的相关性比例自动选择通道独立或通道混合的标记化策略,以适应不同数据集对内序列依赖和跨序列依赖的不同关注程度。
-
分块处理:将输入时间序列划分为多个分块,并基于选择的标记化策略生成分块标记,使模型能够更细粒度地捕捉时间序列的长期依赖关系。
创新点:
-
Mamba+模块:通过增加遗忘门,有效解决了 Mamba 在长期时间序列预测中可能存在的信息丢失问题,提升了模型对历史信息的保留能力,从而提高了预测精度。
-
双向结构:双向 Mamba+编码器能够更全面地捕捉时间序列中的复杂进化模式,与单向 Mamba 相比,在多个真实世界数据集上的预测误差(MSE 和 MAE)平均降低了 4.72% 和 2.60%。
-
序列关系感知决策器(SRA):自动根据数据集的特性选择合适的标记化策略,避免了手动选择的主观性和局限性,进一步提升了模型在不同数据集上的适应性和预测性能。
-
分块处理:分块策略不仅降低了计算复杂度,还使模型能够更有效地提取时间序列的语义信息,增强了对长期依赖关系的建模能力,与直接对整个序列进行建模的方法相比,显著提高了预测的准确性。
论文2
标题:
CMamba: Channel Correlation Enhanced State Space Models for Multivariate Time Series Forecasting
CMamba:增强通道相关性的状态空间模型用于多变量时间序列预测
方法:
-
M-Mamba模块:对 Mamba 模块进行改进,用于更好地建模时间依赖性,包括移除卷积操作、采用特征无关的转移矩阵 A 和数据依赖的跳跃连接矩阵 D。
-
全局数据依赖的 MLP(GDD-MLP):提出 GDD-MLP 模块,通过数据依赖的权重和偏置来有效捕捉通道依赖性,解决了传统 MLP 在多变量时间序列预测中的不足。
-
通道混合机制:引入通道混合机制,在训练期间通过线性组合混合不同通道,创建包含多个通道特征的虚拟通道,以减轻过拟合问题并提高模型的泛化能力。
-
分块处理:将输入的多变量时间序列划分为多个分块,作为模型的输入,以丰富标记的语义信息和局部感受野。
创新点:
-
M-Mamba模块:通过简化 Mamba 的结构和引入数据依赖机制,使其更适合多变量时间序列预测任务,与原始 Mamba 相比,在多个数据集上取得了更低的预测误差。
-
GDD-MLP模块:GDD-MLP 通过数据依赖的方式动态调整权重和偏置,能够更有效地捕捉通道之间的相关性,与传统 MLP 相比,显著提升了模型的预测性能,平均 MSE 和 MAE 分别降低了 17.8% 和 10.2%。
-
通道混合机制:通道混合机制通过在训练过程中混合通道,有效地提高了模型对通道依赖性的建模能力,同时减轻了过拟合问题,使模型在测试集上的性能更加稳定。
-
分块处理:分块策略不仅降低了计算复杂度,还使模型能够更有效地提取时间序列的语义信息,增强了对长期依赖关系的建模能力,与直接对整个序列进行建模的方法相比,显著提高了预测的准确性。
论文3
标题:
MambaStock: Selective state space model for stock prediction
MambaStock:用于股票预测的选择性状态空间模型
方法:
-
结构化状态空间序列模型(S4):利用状态空间表示来捕捉序列数据的动态变化,通过结构化矩阵参数化状态空间,实现高效的时间序列建模。
-
Mamba模型:引入选择机制和扫描模块(S6),使模型能够动态选择输入序列中与预测相关的部分,提高模型的泛化能力和预测性能。
-
MambaStock模型:基于 Mamba 框架,利用多种金融指标(如开盘价、最高价、最低价、交易量等)作为输入特征,通过 Mamba 模型提取时间依赖性和相关信息,预测未来股票价格变动率。
-
超双曲正切激活函数(tanh):对 Mamba 模型的输出应用超双曲正切激活函数,确保预测的股票价格变动率在 (-1,1) 区间内。
创新点:
-
Mamba模型:通过选择机制和扫描模块,Mamba 能够动态适应不同数据模式和结构,有效挖掘序列数据中的非线性模式,与传统时间序列模型(如 ARIMA)相比,在股票价格预测任务上取得了更高的预测精度。
-
MambaStock模型:MambaStock 模型无需复杂的特征工程或大量的预处理步骤,直接利用历史市场数据进行预测,简化了股票预测的流程。在多个股票数据集上的实证研究表明,MambaStock 的预测精度显著高于其他传统方法,平均 MSE 和 MAE 分别降低了 15.1% 和 10.4%。
-
超双曲正切激活函数:通过限制输出范围,超双曲正切激活函数确保了模型预测的股票价格变动率在合理区间内,提高了模型的稳定性和可靠性。
论文4
标题:
Mamba or Transformer for Time Series Forecasting? Mixture of Universals (MoU) Is All You Need
Mamba 或 Transformer 用于时间序列预测?万能混合(MoU)才是你需要的
方法:
-
混合特征提取器(MoF):提出 MoF 作为自适应特征提取器,针对时间序列补丁的不同上下文信息调整网络参数,生成更具信息量的表示,以增强短期依赖的表示。
-
混合架构(MoA):提出 MoA 作为长期依赖建模的混合编码器,层次化地整合 Mamba、前馈、卷积和自注意力架构,从局部到全局逐步扩展视角,以高效建模长期依赖。
-
分块策略:采用分块策略对时间序列进行预处理,将原始时间序列划分为多个补丁标记,保留局部语义信息。
-
线性投影:对 MoA 的输出进行扁平化处理,并应用线性投影以获得最终预测结果。
创新点
-
混合特征提取器(MoF):MoF 通过稀疏激活机制,根据输入补丁的上下文信息选择性地激活子提取器,有效捕捉不同补丁的上下文语义,与传统的均匀线性变换方法相比,显著提高了短期依赖的表示能力,平均 MSE 和 MAE 分别降低了 22.6% 和 15.6%。
-
混合架构(MoA):MoA 的层次化设计从局部依赖逐步扩展到全局依赖,有效平衡了计算效率和长期依赖建模能力。与仅使用 Mamba 或 Transformer 的模型相比,MoA 在多个数据集上取得了更低的预测误差,平均 MSE 和 MAE 分别降低了 17.2% 和 9.5%。
-
分块策略:分块策略不仅保留了局部语义信息,还降低了计算复杂度,使模型能够更高效地处理大规模时间序列数据,显著提高了模型的计算效率和预测性能。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)