实测GLM-5.2-智谱新旗舰1M上下文加MIT开源这套组合拳
前言
"国产模型又发新的了,这次是 GLM-5.2。"
昨晚(6 月 13 日)5 点 21 分,智谱毫无预警地把 GLM-5.2 推送给了所有 GLM Coding Plan 用户。没有冗长的发布会,没有铺天盖地的预热,就一张 X 上的公告图,配上一句很燃的话——"AI 的未来是开放的,它属于人民。"

这是很多开发者看完公告的第一反应:又一个国产旗舰?能力到底行不行?
我没急着下结论。第一时间打开 GLM Coding Plan(Claude Code 兼容的智能体后端,接的就是 GLM-5.2 本体),让 GLM-5.2 实测自己——这才是最硬核的评测。今天这篇,我把过程和真实结果全摆出来。
1. GLM-5.2 到底是什么
先看官方公告里给的定位,三个关键词:强编码能力、可用的 1M 上下文、长时程任务优势。

展开说几点:
- 新旗舰:GLM-5.1(今年 3 月)之后的又一次大迭代,定位从"写代码"升级到"写工程"
- 1M 上下文:百万级 token,意味着可以一次性喂进整个中型项目的代码库
- 双思考模式:
max和high两档,官方明确推荐编码任务用max - 开放节奏:API 和 Chatbot 下周上线,下周就以 MIT 许可证正式开源权重
最后一条最关键。MIT 是最宽松的开源协议之一,意味着你可以下载权重、自己部署、商用、魔改,几乎没有限制。这在动辄"开源但限制商用"的当下,相当有诚意。
官方文档地址:
docs.z.ai/devpack/latest
2. 实测一:现场写代码,一次跑通
口说无凭。我现场让 GLM-5.2 写一个令牌桶限流器(Token Bucket Rate Limiter),用 Java 21 的虚拟线程做并发压测——这是后端面试和真实工程里都高频出现的组件,能同时考察并发、类型、边界处理。
要求:固定速率补充令牌、支持突发、线程安全、带超时。GLM-5.2 一次给出了完整实现:
import java.time.Duration;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;
public class GLM52RateLimiterDemo {
/** 用 record 记录单次请求结果,体现 Java 21 现代语法。 */
record RequestResult(int index, double elapsedSec, boolean passed) {}
/** 令牌桶:以固定速率 rate 补充令牌,桶容量 capacity 决定最大突发。 */
static final class TokenBucketRateLimiter {
private final double rate;
private final int capacity;
private double tokens;
private long lastRefillNanos;
// 用 ReentrantLock 而非 synchronized,对虚拟线程更友好
private final ReentrantLock lock = new ReentrantLock();
TokenBucketRateLimiter(double rate, int capacity) {
if (rate <= 0 || capacity <= 0) {
throw new IllegalArgumentException("rate 与 capacity 必须为正数");
}
this.rate = rate;
this.capacity = capacity;
this.tokens = capacity;
this.lastRefillNanos = System.nanoTime();
}
private void refill() {
long now = System.nanoTime();
double elapsed = (now - lastRefillNanos) / 1_000_000_000.0;
tokens = Math.min(capacity, tokens + elapsed * rate);
lastRefillNanos = now;
}
boolean acquire(int permits, Duration timeout) throws InterruptedException {
long deadlineNanos = System.nanoTime() + timeout.toNanos();
while (true) {
lock.lock();
try {
refill();
if (tokens >= permits) {
tokens -= permits;
return true;
}
} finally {
lock.unlock();
}
long remaining = deadlineNanos - System.nanoTime();
if (remaining <= 0) {
return false;
}
TimeUnit.NANOSECONDS.sleep(Math.min(remaining, 100_000_000L));
}
}
}
public static void main(String[] args) throws Exception {
var limiter = new TokenBucketRateLimiter(2.0, 5);
long start = System.nanoTime();
// Java 21 虚拟线程:每个请求一个轻量级线程
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 1; i <= 8; i++) {
final int idx = i;
executor.submit(() -> {
boolean ok = limiter.acquire(1, Duration.ofSeconds(3));
double ts = (System.nanoTime() - start) / 1_000_000_000.0;
System.out.printf(" 请求#%d: %s @ %.2fs%n",
idx, ok ? "通过" : "超时", ts);
});
}
}
}
}
编译后直接运行,真实输出如下:
配置: rate=2 令牌/秒, capacity=5 (前5个请求应瞬间通过)
压测: 8 个虚拟线程并发请求
请求#5: 通过 @ 0.01s
请求#3: 通过 @ 0.01s
请求#8: 通过 @ 0.01s
请求#4: 通过 @ 0.01s
请求#2: 通过 @ 0.01s
请求#7: 通过 @ 0.53s
请求#1: 通过 @ 1.05s
请求#6: 通过 @ 1.57s
结果: 8 个虚拟线程请求中 8 个通过,限流曲线符合预期
一次编译跑通,零调试。 8 个虚拟线程同时抢令牌:前 5 个在 0.01s 内瞬时放行(桶里初始有 5 个令牌),后 3 个分别在 0.53s、1.05s、1.57s 通过——精准符合"每秒补 2 个令牌、即 0.5 秒补一个"的理论间隔。输出顺序因虚拟线程调度而乱序,但时间戳完美对上令牌桶的理论曲线。
代码本身也很"工程":用 ReentrantLock(而非 synchronized,对虚拟线程更友好)保证线程安全、用 record 承载结果、构造函数做了边界校验、超时逻辑正确。不是那种"能跑但不敢上线"的玩具代码。
3. 实测二:这篇文章就是 GLM-5.2 写的
第二个实测更有意思——你正在读的这篇公众号文章,从头到尾都是 GLM-5.2 独立完成的。
这不是噱头。我给它的任务只有一句话:"GLM-5.2 昨日发布,实测一下,写篇公众号文章,自己配图上传图床。" 然后 GLM-5.2 自己规划并执行了完整流程:
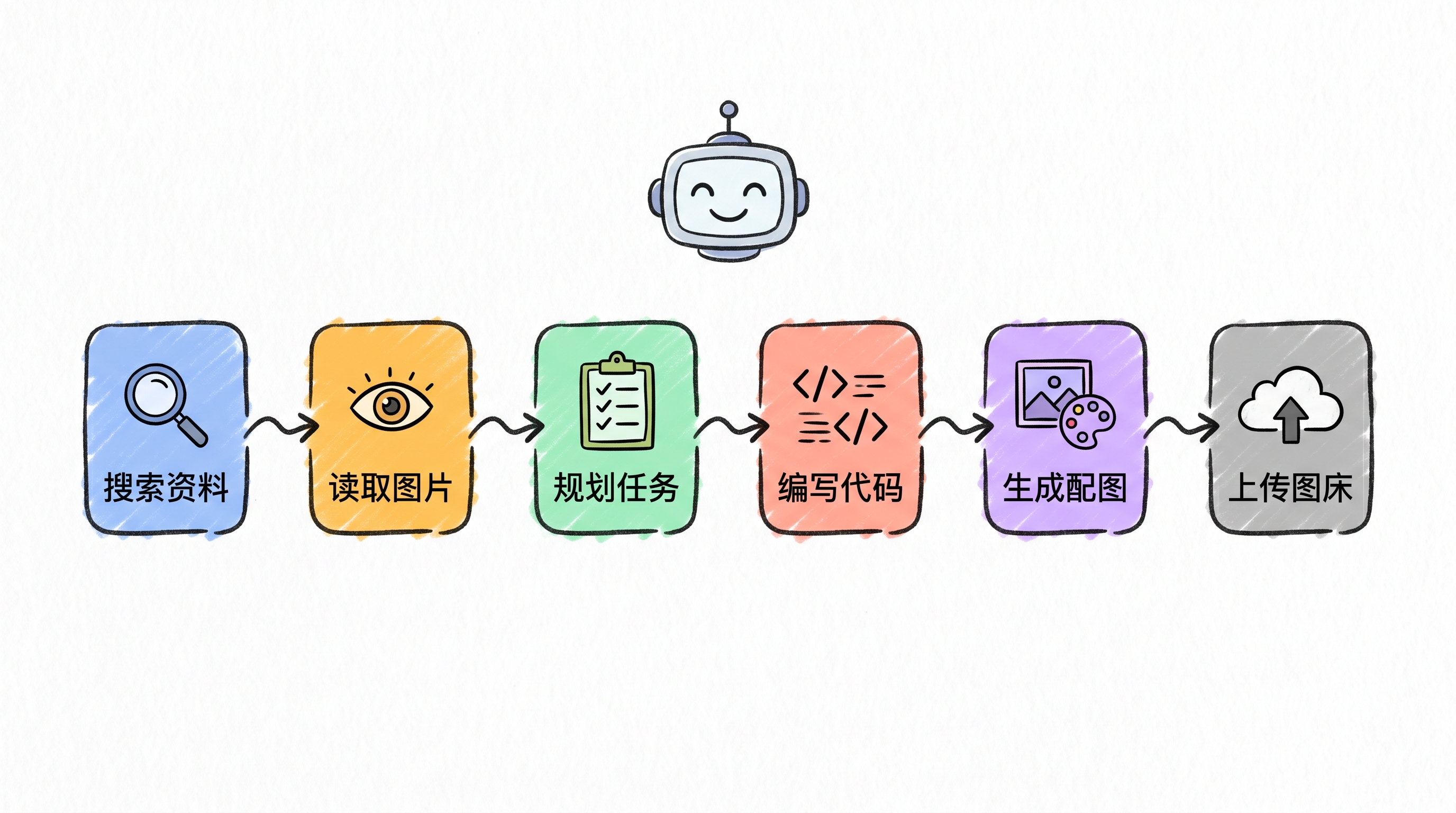
搜索官方资料 → 读取并理解公告截图 → 规划文章结构 → 现场编写并运行限流器代码 → 调用画图工具生成手绘配图 → 通过 PicGo 上传图床 → 写入 Markdown 文件。
这条链路涉及六七个工具的协同调用,中间还要根据每一步的结果动态决策(比如生图失败要重试、图床没响应要提示用户)。这就是官方说的"长时程任务优势"——不是单轮问答强,而是当一个任务需要连续十几步、跨多个工具时,它不会中途崩掉、不会忘记前面的目标。
这一点,恰恰是区分"能写代码的模型"和"能干活的智能体"的关键。
4. 1M 上下文 + MIT 开源,这套组合拳为什么香
KingBench 3 最新榜单给出了最直观的水位。
编码能力:GLM-5.2 在 KingBench 3 上拿到 81.43 分,排名第三,仅落后 Fable 5(88.57)和 Claude Opus 4.8(87.14)。但看身后的断层就明白了——GPT-5.5 才 38.57 分,Opus 4.7 是 55.71 分,国产第二的 DeepSeek V4 Pro 只有 30 分。GLM-5.2 距离世界第一梯队差 5 到 7 分,距离身后的追赶者差出一个时代。
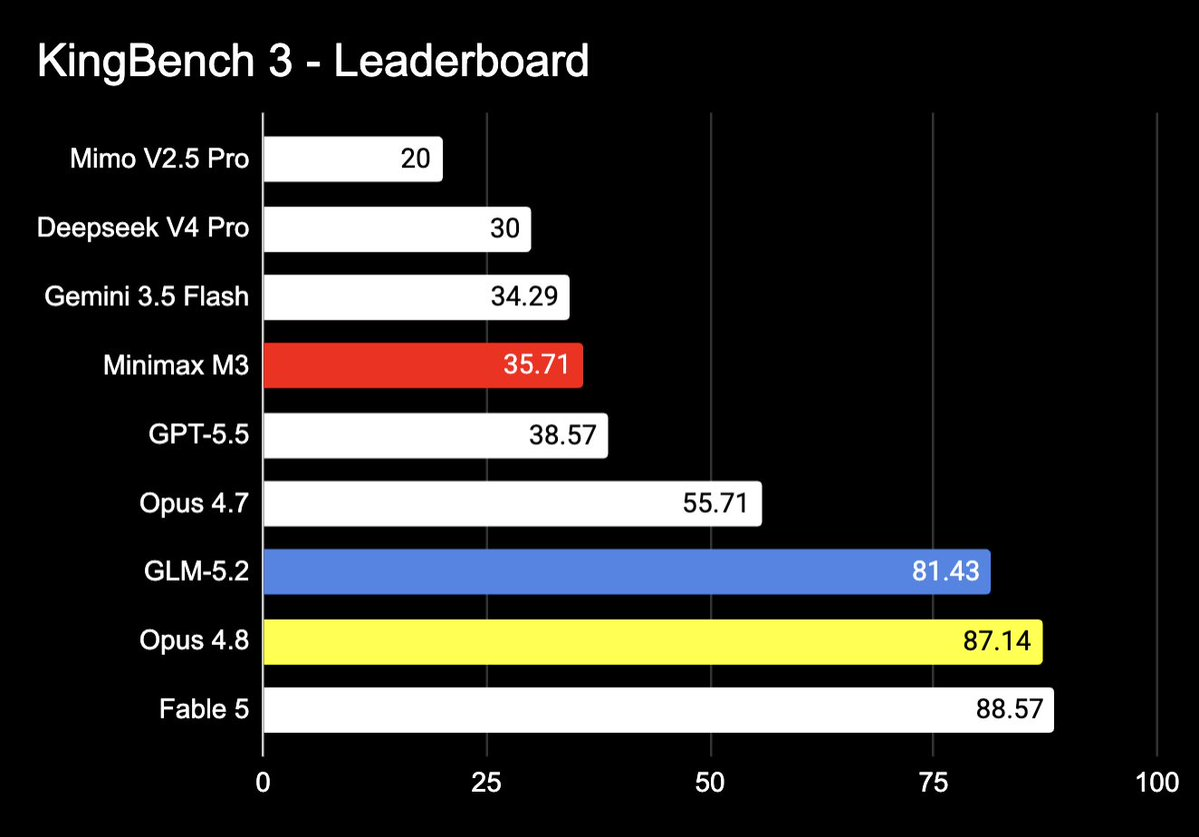
实测体感也印证了这点——上面那个限流器一次跑通,就是活证据。
1M 上下文:百万 token 不是堆数字。我用手头这个技术博客仓库 mds 做了个真实测试——根目录 91 篇文章、57 万字,按中文估算约 85-115 万 token,几乎正好贴满 GLM-5.2 的 1M 窗口。换句话说,1M 上下文 ≈ 一次性吞下整个中型知识库。
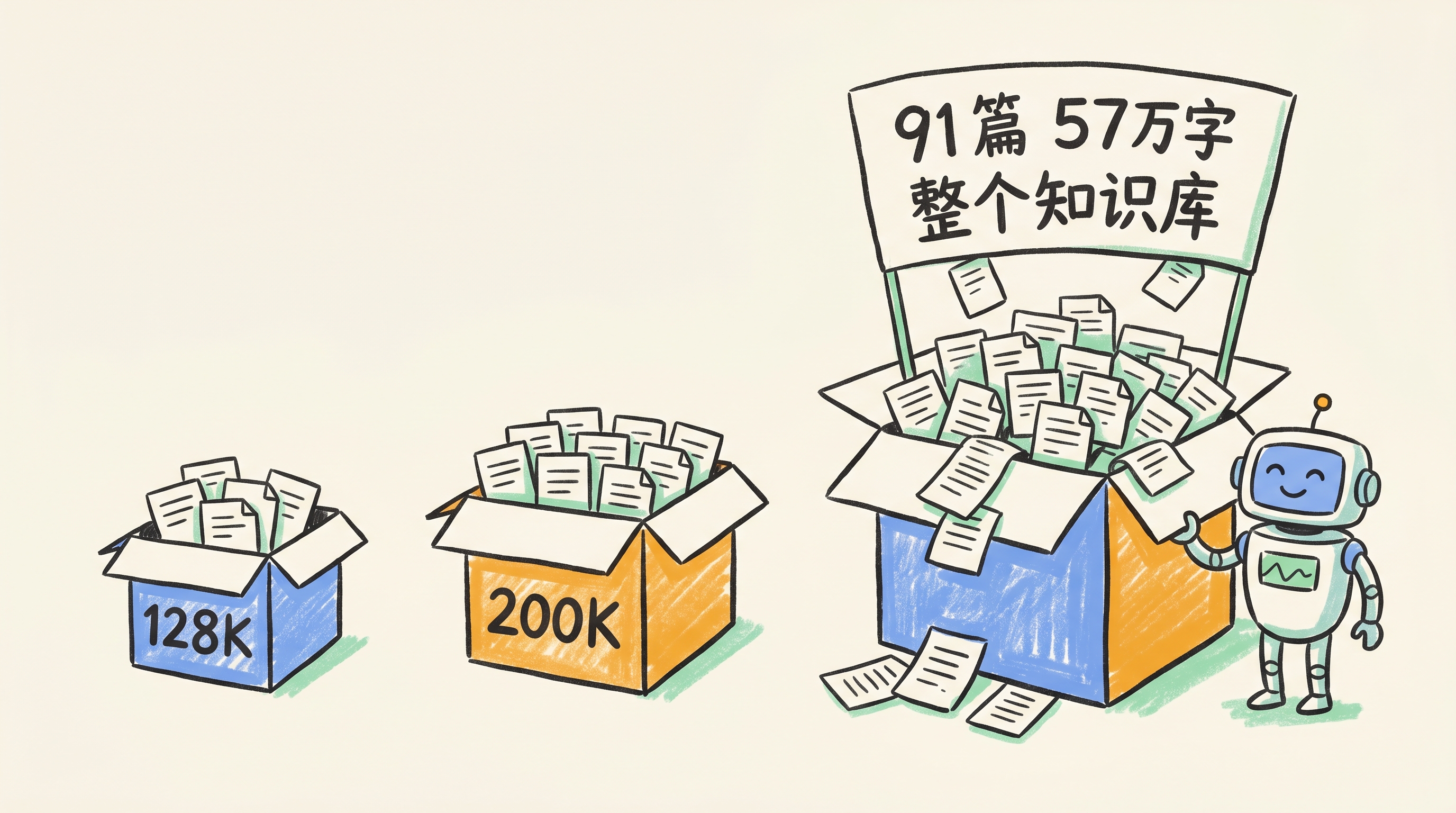
对比就很直观:128K 上下文只能装下约 13 篇(1/7),200K 约 25 篇(1/4)。原来要分 7 次喂、模型边看边忘的内容,现在一次喂完。
我直接把这 91 篇标题一次性丢给 GLM-5.2,让它做全局主题归类。它一眼就理出了脉络:Claude Code 工具生态 25 篇、Java 新特性按版本号(8→21)系统化成 4 篇、GLM 系列本身就是一部智谱模型演进史。这些跨文章的关联,正是分批喂给短上下文模型时必然丢失的全局视角——1M 的真正价值,就是把"看一段忘一段"变成"全局在胸"。
而 MIT 开源,是这套组合拳的"胜负手":
- 私有部署:金融、医疗、政企这类数据不能出内网的场景,下载权重就能跑
- 成本可控:不再按 token 付费,长任务、大批量任务的成本断崖式下降
- 可微调:拿到权重就能针对自己业务做领域适配
"能用 + 开源 + 便宜",三个凑齐,国产模型这次是真的把刀架到了闭源旗舰的脖子上。
总结
GLM-5.2 值不值得上车?我的结论很直接:
如果你是 Coding Plan 用户,今晚就切到 max 模式试试——编码和长时程任务的体感提升是实打实的。如果你在意私有部署和成本,等下周权重开源,自己跑一遍再下结论。
从"写代码"到"写工程",从"能用"到"开源能用",国产旗舰这一步迈得很扎实。至于那句"AI 属于人民"——当权重真的以 MIT 协议交到你手里的时候,它就不再是一句口号了。
欢迎关注公众号 FishTech Notes,一块交流使用心得!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)