深度学习入门:【《动手学深度学习》之day2】从线性神经网络开始01线性回归+02softmax回归+03保存模型
目录
- 机器学习模型中的关键要素是训练数据、损失函数、优化算法,还有模型本身。
- 经典统计学习技术中的线性回归和softmax回归均为单层线性神经网络。
- 最小化损失函数等价于执行极大似然估计(似然估计是统计学习中的概念)。
- 能控制的有两个点:负梯度方向(损失函数)和学习率,这两个不同导致每次更新梯度的步伐不一致。
建议先看基础后本篇:
深度学习入门:【基本概念】![]() https://blog.csdn.net/weixin_51929697/article/details/149131379?spm=1011.2415.3001.5331
https://blog.csdn.net/weixin_51929697/article/details/149131379?spm=1011.2415.3001.5331
一.线性回归
- 单层神经网络,属于回归问题。回归估计输出单连续值。
- 损失函数:真实值与预测值均方损失(L2 loss)
- 优化模型:小批量随机梯度下降算法
线性回归模型用平方损失来衡量预测值和真实值差异,是对n维输入的加权,是深度学习模型研究中有显示解、凸的唯一。下面简单的线性模型可视为一个单层的神经网络。

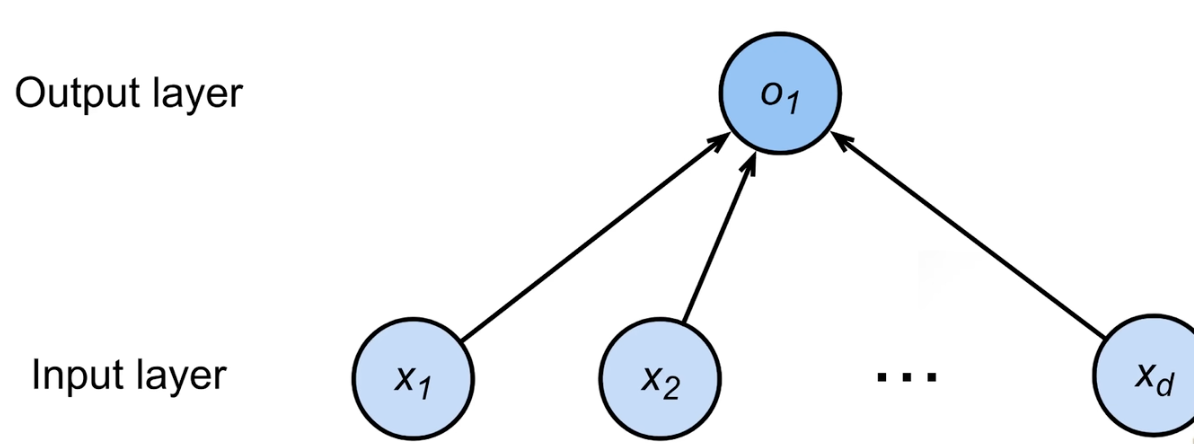
![]()
当预测值和真实值比较远,又不想更新太大时,考虑用L1 Loss,优点是梯度是 -1 or 1 的常数,缺点是零点处不可导,且出现正负数变化较大,不平衡性导致当预测值和真实值比较近时,即优化到末期时,变得不稳定。
![]()
还有一类常见的损失函数Huber's 鲁棒性损失:
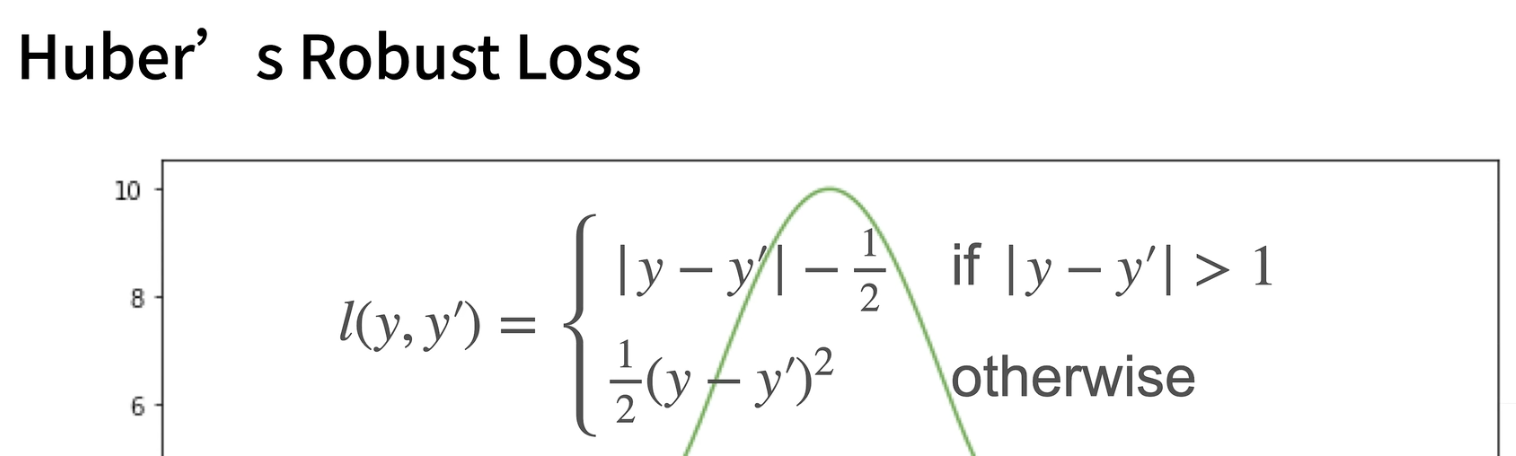
矢量加速:

梯度下降:梯度是上升最快的向量,负梯度就是下降最快的向量。下图中公式表示前一个w减去标量*损失函数。沿着反梯度方向下降,并更新参数。
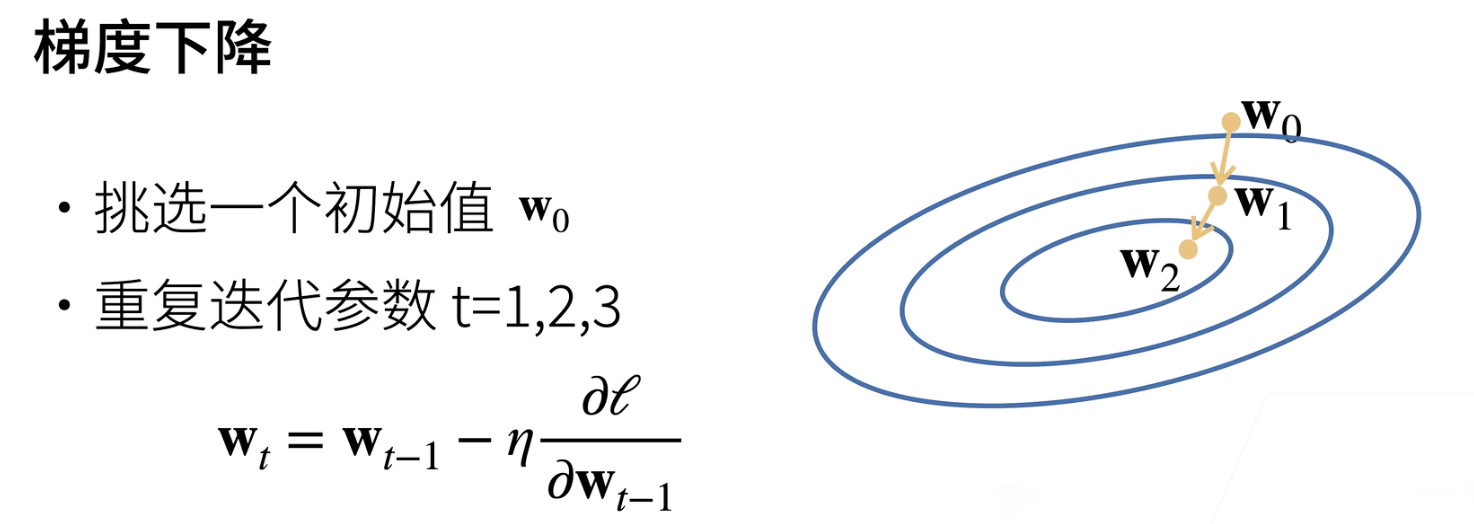
深度学习默认的求解方法: 小批量随机梯度下降。
批量大小是第一个超参数,学习率是第二个超参数。 梯度是求导中计算最贵的部分,所以要少走。学习率不能太大,也不能太小。 超参数的选择是重要问题,在优化算法那一节讲如何快速找到一个合适的区间。
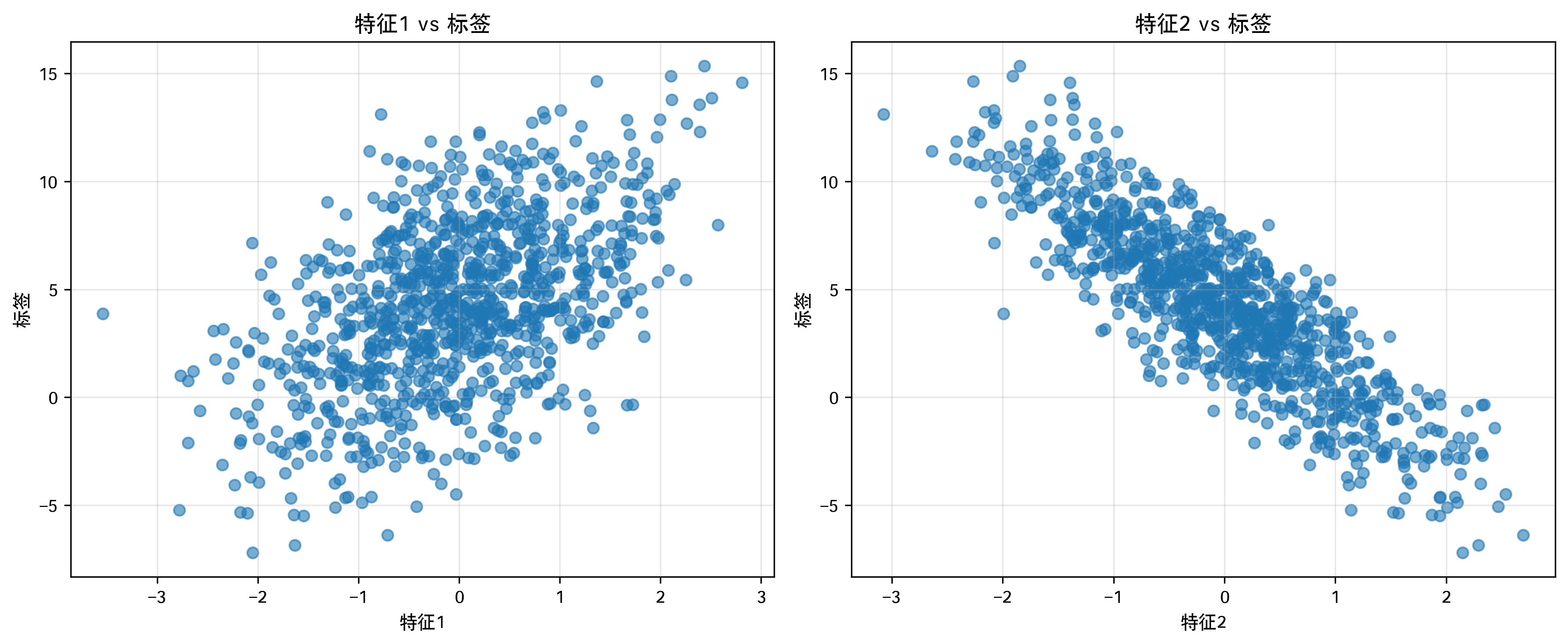
生成数据集,下图是前两个特征和标签。
- 关于参数更新时减去的梯度是除以batch_size后的平均值:
def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size #更新参数,除以batch_size来得到平均值,因为梯度是batch_size个样本的和,所以需要除以batch_size。如果不在这除,就把学习率除以batch_size
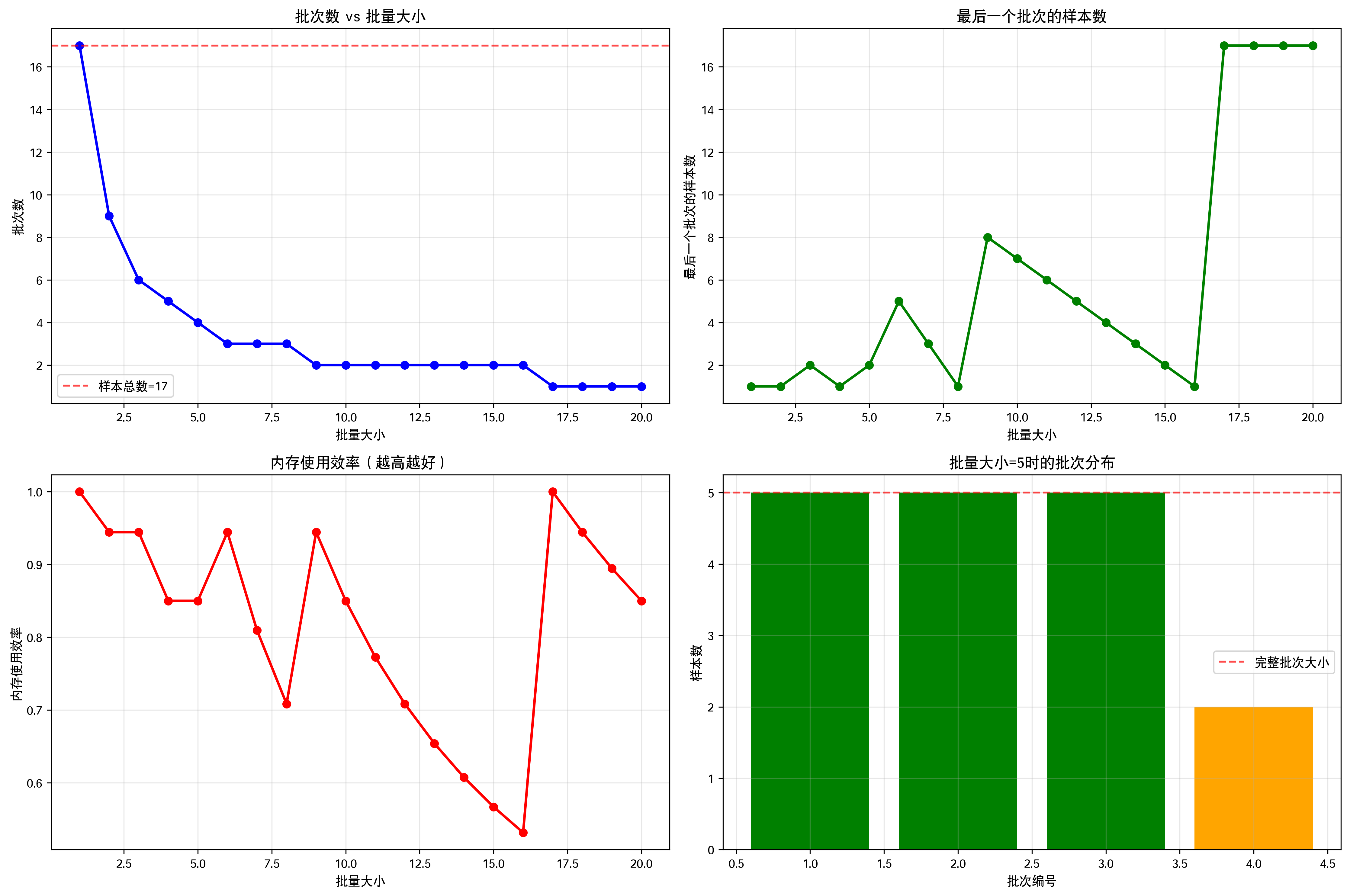
param.grad.zero_() #清空梯度- (课程练习)如果样本个数不能被批量大小整除,
data_iter函数的行为会有什么变化?
以样本数量17为例,批量取3、4、5、8、17:
总样本数: 17
特征形状: torch.Size([17, 2])
标签形状: torch.Size([17, 1])
回答:
1. 当样本数不能被批量大小整除时,最后一个批次会包含较少的样本
2. 这不会影响训练的正确性,但可能影响训练效率
3. 较大的批量大小通常有更好的内存使用效率
4. 较小的批量大小提供更多的梯度更新机会
5. 在实际应用中,这种不完整批次是正常且常见的
- 线性回归的简洁实现(略)
以上部分只运用了: (1)通过张量来进行数据存储和线性代数; (2)通过自动微分来计算梯度。 实际上,由于数据迭代器、损失函数、优化器和神经网络层很常用, 现代深度学习库也为我们实现了这些组件。
二.softmax回归(*后续所有深度学习的基础)
- 单层神经网络,分类预测输出多离散类别:softmax名义上是回归,其实是分类问题,如区分cat和dog的图片,是离散的。不是问“多少”,而是问“哪一个”:
- 某个电子邮件是否属于垃圾邮件文件夹?
- 某个用户可能注册或不注册订阅服务?
- 某个图像描绘的是驴、狗、猫、还是鸡?
- 某人接下来最有可能看哪部电影?
- 向量表达:
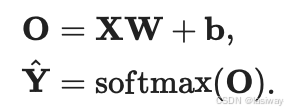
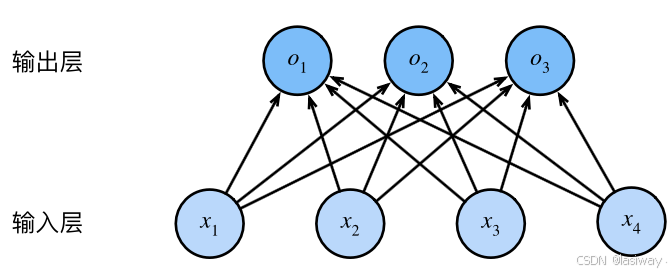
每个输出由所有的输入共同决定,因此虽然softmax()函数是非线性的,但softmax回归属于线性回归,且回归的输出层属于全连接层。
- softmax()函数的最大贡献是:将未规范化的预测变换为非负数并且总和为1,同时让模型保持可导,即关心正确类别置信度远远大于其他非正确类的置信度。
采用独热编码(one-hot encoding),即正确分类为1,其余非正确项均为0。
首先对每个未规范化的预测求幂,这样可以确保输出非负。 为了确保最终输出的概率值总和为1,我们再让每个求幂后的结果除以它们的总和。

- 损失函数:交叉熵损失(cross-entropy loss)为损失函数,只关心正确类别的预测概率值大小,而不关心其他非正确分类。
- 为了提高计算效率并且充分利用GPU,我们通常会对小批量样本的数据执行矢量计算。
假设我们读取了一个批量的样本, 其中特征维度(输入数量)为
,批量大小为n。 此外,假设我们在输出中有
个类别。 那么小批量样本的特征为
, 权重为
, 偏置为
。 softmax回归的矢量计算表达式为:

- 模型预测与评估
在训练softmax回归模型后,给出任何样本特征,我们可以预测每个输出类别的概率。 通常我们使用预测概率最高的类别作为输出类别。 如果预测与实际类别(标签)一致,则预测是正确的。 在接下来的实验中使用精度(accuracy)来评估模型的性能。精度等于正确预测数与预测总数之间的比率。
- 例子:Fashion-MNIST数据集
Fashion-MNIST由10个类别的图像组成, 每个类别由训练数据集(train dataset)中的6000张图像 和测试数据集(test dataset)中的1000张图像组成。 因此,训练集和测试集分别包含60000和10000张图像。 测试数据集不会用于训练,只用于评估模型性能。
定义load_data_fashion_mnist函数(详见本地http://localhost:8888/notebooks/chapter_linear-networks/image-classification-dataset.ipynb)
原始数据集中的每个样本都是的图像。 本节[将展平每个图像,把它们看作长度为784的向量。]
ps*:输入必须是一个向量,所以要把图片拉长(展评),但是损失空间信息(卷积神经网络中再学习)
定义softmax(): (用例子说明,数学上是成立的)
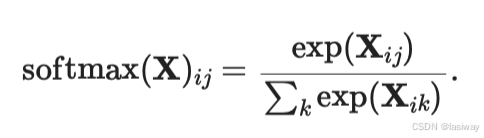
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition # 这里应用了广播机制
#例子
X = torch.normal(0, 1, (2, 5))
X_prob = softmax(X)
X_prob, X_prob.sum(1)
#输出:(tensor([[0.3255, 0.3890, 0.0672, 0.0787, 0.1396],
[0.0789, 0.0136, 0.2172, 0.4900, 0.2003]]),
tensor([1.0000, 1.0000]))定义损失函数:
这里需要理解。回顾一下,交叉熵采用真实标签的预测概率的负对数似然。 这里我们不使用Python的for循环迭代预测(这往往是低效的), 而是通过一个运算符选择所有元素(本文中搜索“矢量加速”)。
[创建一个数据样本y_hat,其中包含2个样本在3个类别的预测概率, 以及它们对应的标签y。]
#ps*:有了y,我们知道在第一个样本中,第一类是正确的预测;
#而在第二个样本中,第三类是正确的预测。
#然后(使用y作为y_hat中概率的索引), 选择第一个样本中第一个类的概率和第二个样本中第三个类的概率。
y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
print(y_hat[[0, 1], y])
#输出:tensor([0.1000, 0.5000])
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
print(cross_entropy(y_hat, y))
#输出:tensor([2.3026, 0.6931])模型实现过程(本地http://localhost:8888/notebooks/chapter_linear-networks/softmax-regression-scratch.ipynb)
优化模型:小批量随机梯度下降算法
迭代周期(num_epochs)和学习率(lr)都是可调节的超参数。 通过更改它们的值,我们可以提高模型的分类精度。
(万众瞩目的)实验结果:[训练模型30个迭代周期,学习率0.1]
(1)用本机CPU跑:
原书是10个迭代周期,用原书代码改为30个迭代周期,结果:
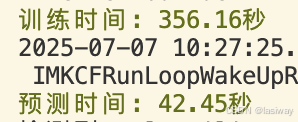
为了跑GPU,数据/模型/参数需要迁移到GPS devices,改了代码后,训练了2遍:


(2)用本机GPU 跑:
这里就要用到在之前《深度学习环境安装MACOS完整版(python版本过高不兼容d2l的问题解决)》中提到的验证方法二:GPU加速。


小结:
- 虽然准确率都只有80%,但是还是正确预测了,准确率是一个提升空间!
- GPU方面,本次没有惊喜,也是一个提升空间!
三.关于保存模型
这里介绍一个非常有用的经验之谈,保存训练好的模型,以防止……懂的都懂……无尽的等待。
目标:在后续使用时,快速加载和使用模型,不用从头训练。为模型的迁移学习、部署和共享提供便利。
保存模型的三种方法:
(原文链接,感谢博主贡献:https://blog.csdn.net/m0_69722969/article/details/147018326)
(1)使用 torch.save() 保存完整模型:将模型对象直接传递给 torch.save() 函数,加载使用 torch.load() 函数。
import torch
import torch.nn as nn
# 定义一个简单的神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc = nn.Linear(10, 2)
def forward(self, x):
return self.fc(x)
# 创建模型实例并训练(假设已经训练完成)
model = SimpleNet()
# 保存整个模型
torch.save(model, 'whole_model.pth')
# 加载整个模型
loaded_model = torch.load('whole_model.pth')
# 测试模型
input_data = torch.randn(1, 10)
output = loaded_model(input_data)
print(output)
(2)使用 model.state_dic() 提取模型参数,只保存模型参数(state_dict)。方便地将参数迁移到其他模型结构中。加载参数时,需要先定义模型结构,然后将参数加载到模型中。
# 提取并保存模型参数
torch.save(model.state_dict(), 'model_params.pth')
# 定义相同的模型结构
loaded_model = SimpleNet()
# 加载参数
loaded_model.load_state_dict(torch.load('model_params.pth'))
# 测试模型
input_data = torch.randn(1, 10)
output = loaded_model(input_data)
print(output) (3)使用 model.state_dic() 保存模型参数和模型训练状态(优化器的状态(如学习率、动量等))。这在需要从中断处继续训练时非常有用,加载训练状态时,可以从中断处继续训练。
# 定义模型和优化器
model = SimpleNet()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 假设已经训练了几轮
for epoch in range(10):
# 训练代码
pass
# 保存训练状态
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}, 'training_state.pth')
# 加载训练状态
checkpoint = torch.load('training_state.pth')
# 定义相同的模型和优化器
model = SimpleNet()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 加载状态
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch'] + 1
# 继续训练
for epoch in range(start_epoch, 20):
# 训练代码
pass遇到的问题及解决:
设备兼容性:保存的模型在加载时可能会遇到设备(CPU/GPU)不匹配的问题。可以通过 map_location 参数指定加载到的设备。
loaded_model = torch.load('model_params.pth', map_location=torch.device('cpu'))模型结构一致性:只保存参数时,加载时必须确保模型结构与保存时一致,否则会报错。
文件格式:PyTorch 默认使用 .pth 或 .pt 作为保存文件的扩展名,但你可以根据需要选择其他扩展名。
定期保存:在长时间训练中,建议定期保存模型状态,以防止因意外中断导致的训练成果丢失。
小结:
-
保存整个模型:适合简单的场景,但不够灵活。
-
只保存模型参数:推荐的方法,灵活且高效。
-
保存训练状态:适合需要从中断处继续训练的场景。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)