NumPy 快速入门系列:应用统计学基础概念、相关统计指标与NumPy的实现
NumPy 快速入门系列:应用统计学基础概念、相关统计指标与NumPy的实现
前言:
个人认为数据分析其中一大块内容就是对数据的统计分析,而如何用 Python 进行有效且正确的统计分析,就不仅需要掌握数据分析工具 NumPy 及 Pandas 的使用,也需要对常用的统计学概念及统计学方法有一定的掌握。本篇的博客内容就主要介绍应用统计学中的一些基础概念及相关度量的概念,以及针对一组数据如何用 NumPy 计算出介绍的度量。
统计学导论:
统计学定义:
统计学是:阐述统计工作基本理论和基本方法的科学 ,是对统计工作实践的理论概括和经验总结 。 它以现象总体的数量方面为研究对象 ,阐明统计设计 、统计调查 、统计整理和统计分析的理论与方法 ,是一门方法论科学 。
不列颠百科全书对统计的定义是 :统计学是收集 、分析 、表述和解释数据的科学。
从上面的定义可以看出,NumPy 或 Pandas 主要是在统计学的数据分析阶段中使用;数据的收集工作,通常可以用 python 的爬虫技术来实现;而表述和解释就要应用到一些统计学和所分析数据领域的专业知识了。
统计学分类:
统计方法已广泛应用于自然科学和社会科学的众多领域 ,统计学也发展成为由若干分支组成的学科体系 。 由于出于不同的视角或不同的研究重点 ,人们常对统计学科体系作出不同的分类 。
一般而言 ,有两种基本的分类 :从方法的功能来看 ,统计学可以分成描述统计学和推断统计学 ;从方法研究的重点来看 ,统计学可分为 理论统计学 和 应用统计学 。
理论统计学即数理统计学 ,主要探讨统计学的数学原理和统计公式的来源 。
应用统计学 ,探讨如何运用统计方法去解决实际问题 。
统计学基本概念:
总体与样本:
凡是客观存在 、在某一共同性质基础上结合起来的许多个别事物的整体 ,叫做 统计总体(简称总体) 。
所谓 样本 就是按照一定的概率从总体中抽取并作为总体代表的一部分总体单位的集合体 。
指标与指标体系:
指标(统计指标)是说明现象总体数量特征的概念或范畴 。
例如 ,要表明某地区全部工业企业这个总体的数量特征 ,其数量表现可以有 :该地区 2000 年底工业企业单位数 1.2万个 ,全年工业总产值 100亿元 ,职工人数 200 万人 ,人均产值 5000元 ,总产值比上年增长 10% 等 。 这些都是统计指标 。
通俗来说统计指标就是:对现象总体进行统计分析得出的一个统计结果。
统计指标体系是指:由若干相互联系的统计指标构成的有机整体 。 一个统计指标仅仅从一个侧面反映了总体的特征,总体特征是多方面的 、复杂的 ,要全面 、系统地反映总体特征 ,就必须建立统计指标体系 。
设计指标体系的基本要求是 :
- 科学性 ,即指标体系的设计要符合事物的特点 ,每一个指标的设计都符合统计指标的设计要求 。
- 目的性 ,即指标体系的设计要考虑管理的要求或研究目的 。
- 全面性 ,即指标体系的设计要全面 ,从不同侧面反映事物 。
- 统一性 ,即指标体系的设计要三大核算统一 。
- 可比性 ,即指标体系的设计要不同空间 、不同时期可比 。
- 核心性 ,即指标体系的设计要确定核心指标。
- 可行性 ,即指标体系的设计要保证每一个指标都能取得。
- 互斥性 ,即指标体系的设计要使指标之间相关程度弱 ,注重指标的代表性 。
统计过程:
统计设计: 统计设计是指根据统计研究对象的性质和研究目的 ,对统计工作的各个方面和各个环节所作的全面部署和安排 。
统计设计的最终结果表现为各种标准 、规定 、制度 、方案和办法 ,如统计分类标准 、目录 、统计指标体系 、统计报表制度 、统计调查方案 、普查办法 、统计整理或汇总方案等等 。
统计调查: 统计调查是根据统计方案的要求 ,采用各种调查组织形式和调查方法 ,有组织 、有计划地对所研究总体的各个单位进行观察 、登记 ,准确 、及时 、系统 、完整地搜集统计原始资料的过程 。
统计整理: 统计整理是根据统计研究的目的和任务 ,对统计调查阶段所取得的原始资料进行审核 、分组和汇总 ,将分散的 、零星的反映总体单位特征的资料转化为反映各组和总体数量特征的综合资料的过程 。
统计分析: 统计分析是指在统计调查和统计整理的基础上 ,用科学的分析方法 ,对所研究的现象总体进行全面 、系统的数量分析 ,认识和揭示事物的本质和规律性 ,进而向有关单位和部门提出咨询建议以及进行必要的分析 、预测的统计工作过程 。 统计分析是统计工作的最后阶段 ,也是统计发挥信息 、咨询和监督职能的关键阶段 。
统计指标与NumPy:
统计指标就其具体内容来讲非常多 ,可谓成千上万 ,但从其基本形式看 ,则不外乎总量指标 、相对指标和平均指标三种类型 ,统称统计综合指标 。
用 Python 构造一组数据:
这里用Python构造了一组数据总量数为5000条的某公司职员收入表,构造代码如下:
import numpy as np
import random
# 构造5000个人名
n_1 = list('赵钱孙李周吴郑王冯陈褚卫蒋沈韩杨朱秦尤许何吕施张孔曹严华'
'金魏陶姜戚谢邹喻柏水窦章云苏潘葛奚范彭郎鲁韦昌马苗凤花方')
n_2 = list('兰叶春葳蕤桂华秋皎洁欣欣此生意自尔为佳节'
'谁知林栖者闻风坐相悦草木有本心何求美人折')
n_3 = list('江南有丹桔经冬犹绿林岂伊地气暖自有岁寒心可以荐佳客奈何阻重深'
'徒言树桃李此木岂无阴运命唯所遇循环不可寻')
n = []
for i in range(6000):
n.append(random.choice(n_1)
+random.choice(n_2)+random.choice(n_3))
name = list(set(n))[:5000]
# print(name)
# 构造性别
g = ['男','女','男']
gender = [random.choice(g) for i in range(5000)]
# print(gender)
# 构造部门
p = ['人力','设计','运维','数据','开发','产品','客服','前端',
'开发','产品','客服','前端','开发','产品','客服','前端']
department = [random.choice(p) for i in range(5000)]
# print(department)
# 年龄
a = list(range(20,45))
age = [random.choice(a) for i in range(5000)]
# print(age)
# 构造薪资
m = list(range(5000,30000,10))
salary = [random.choice(m) for i in range(5000)]
# print(salary)
# 入职年月
y = ['2017','2018','2019']
m_ = list(range(1,13))
year_ = [random.choice(y) for i in range(5000)]
print(year_)
month_ = [random.choice(m_) for i in range(5000)]
arr_data = np.array([name,gender,department,age,
salary,year_,month_]).transpose()
print(arr_data)
print(arr_data.shape,arr_data.dtype)
np.savetxt('arr_data.txt',arr_data,fmt=['%s','%s','%s','%s','%s','%s','%s'],
encoding='utf-8',delimiter=',')
经过上述代码,构造出的 arr_data.txt 文件里部分数据截图:
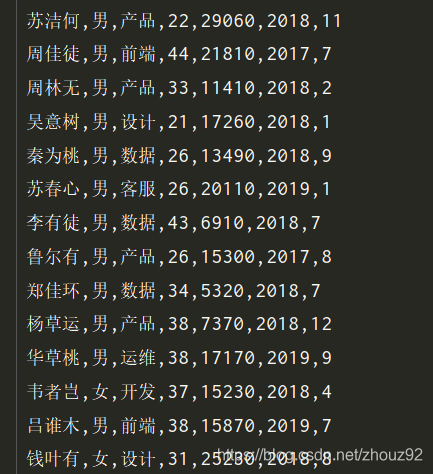
注:因为是随机的,所以每个人得出来的数据都会不一样。
总量指标:
总量指标是反映社会经济现象总体在一定时间 、地点和条件下总规模或总水平的统计指标 。
单位总量指标: 表示总体本身的规模大小 ,是统计总体中总体单位数的合计数 ,简称单位总量。
标志总量: 是反映统计总体中各个单位某个数量标志值总和的总量指标 ,简称标志总量 。
例如 ,要研究某市国有商业企业的经营情况 ,该市全部国有商业企业就是一个统计总体 ,国有商业企业总数是这个总体的单位总量 ,而该市国有商业企业实现的商品销售额 、上缴利税总额 、职工总人数 、职工工资总额等就是这个统计总体的标志总量 。
用 NumPy 计算上述构造数据的单位总量,即为计算该 企业员工数量 :
# 单位总量:
tt_1 = len(data)
# print(tt_1) # 5000
NumPy计算该企业的标志总量指标:女性员工数量、男性员工数量、各岗位人员标志总量。
# 女性员工数量:
fm = data[:,1] == '女'
print(fm)
# [False False False ... False False False]
print(data[fm]) # 布尔数组索引,花式索引
'''
[['韦者岂' '女' '开发' ... '15230' '2018' '4']
['钱叶有' '女' '设计' ... '25230' '2018' '8']
['花为心' '女' '开发' ... '17960' '2017' '5']
...
['秦谁有' '女' '设计' ... '22780' '2018' '12']
['孔自客' '女' '产品' ... '29850' '2019' '8']
['朱坐南' '女' '产品' ... '17870' '2019' '8']]
'''
# 统计数量
tt_2 = np.sum(data[:,1] == '女')
print(tt_2) # 1704
# 男性员工数量:
tt_3 = np.sum(data[:,1] == '男')
print(tt_3) # 3296
# 各岗位人员标志总量:
# 获取岗位集合
post_ = np.unique(data[:,2])
print(post_)
# ['产品' '人力' '前端' '客服' '开发' '数据' '设计' '运维']
# 产品岗位人员数量:
print(np.sum(data[:,2] == '产品'))
# 996
# 统计各岗位人员数量:
tt_4 = []
for tag in post_:
tt_4.append(np.sum(data[:, 2] == tag))
tt_4 = np.array([post_,tt_4]).transpose()
print(tt_4)
'''
[['产品' '996']
['人力' '306']
['前端' '952']
['客服' '874']
['开发' '935']
['数据' '317']
['设计' '291']
['运维' '329']]
'''
相对指标:
相对指标 又称相对数 ,是两个有联系的统计指标的比值 ,用以说明社会经济现象之间的数量对比关系 。如我国 2002年经济增长率为 8.5 % ,人口自然增长率为 7.8 ‰ ,城市每百户家庭拥有固定电话 65 部等 。
作用:
- 反映现象的内部结构 、比例关系 、普遍程度和速度 。
- 使某些不能直接进行对比的统计指标 ,取得可以比较的基础 。
- 确切而有效地反映企业的经济效益 。
分类:
结构相对数: 表明总体内部各个组成部分在总体中所占比重的相对指标 ,也称比重相对数一般用百分数表示 。计算方法:
利用NumPy计算结构相对数:男性,女性员工在全体员工中的比例。
# 男性,女性员工在全体员工中的比例:
rr_1 = tt_2/tt_1 * 100 # 女性比例
print(rr_1) # 34.08
rr_2 = tt_3/tt_1 *100 # 男性比例
print(rr_2) # 65.92
比例相对数: 反映一个统计总体内部各个组成部分之间数量对比关系的相对指标 ,常用系数和倍数表示 。计算公式为 :
利用NumPy计算比例相对数:产品人员数量与人力岗位人员数量的比例。
# 产品人员数量与人力岗位人员数量的比例:
rr_3 = round(float(tt_4[0,1])/float(tt_4[1,1]),2)
print(rr_3) # 3.25
比较相对数: 反映同一时期的同类现象在不同地区 、部门和单位之间数量对比关系的相对指标 。计算公式为 :
利用NumPy计算比较相对数:2017年前端入职人数与运维入职人数的比例 。
# 2017年前端入职人数与运维入职人数的比例:
he_ = data[data[:,2] == '前端'] # 所有前端人员
he_17 = he_[he_[:,5] == '2017'] # 2017年入职的前端人员
om_ = data[data[:,2] == '运维']
om_17 = om_[om_[:,5] == '2017'] # 2017年入职的运维人员
rr_4 = len(he_17)/len(om_17)
print(rr_4) # 2.8521739130434782
强度相对数: 反映两个性质不同但有联系的统计指标之间数量对比关系的相对指标 。计算公式为 :
强度相对数的表现形式一般是复名数 ,由分子指标和分母指标的计算单位组成 。如人均国民生产总值“元 / 人” ,人口密度“人 / 平方千米” ,等等 。有的强度相对数用次数 、倍数 、系数 、百分数或千分数表示 。如高炉利用系数 、资金周转次数表示 、流通费用率 、人口出生率 ,等等 。
本文构造的数据不太适合用强度相对数相关指标,这里就不停供计算实例了。
平均度量:
平均数按其度量的方法不同 ,可以分为 数值平均数 和 位置平均数 。
数值平均数是根据数列中的每一个数值或变量值计算的平均数 ,包括 算术平均数 、调和平均数和几何平均数 ;位置平均数是根据某数值在数列中所处的特殊位置而确定的平均数 ,包括中位数 、众数 、分位数等 。
算术平均数: 也称为均值 ,是全部数据算术平均的结果 。算术平均法是计算平均指标最基本 、最常用的方法 。
利用NumPy计算算术平均数:企业员工的平均工资。
# 平均工资:
salary = data[:,4].astype(np.float)
print(salary.mean())
# 17373.596
几何平均数: 几何平均数是 n 个变量值乘积的 n 次方根 。可分为简单几何平均数和加权几何平均数 ,计算公式分别为: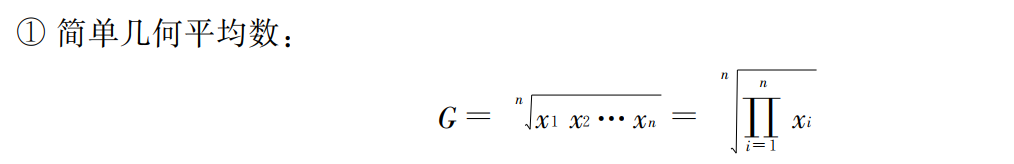
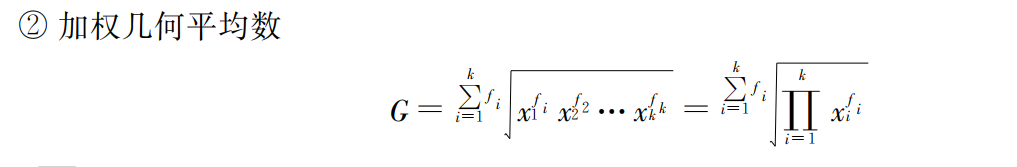
中位数: 是一组数据按从小到大排序后 ,处于中间位置上的变量值 ,用 Me 表示 。
中位数可以反映出一组数据的中心位置 、数据的集中趋势 。当一组数据中含有极端值时 ,用中位数反映该组数据的一般水平可避免极端数值对平均数的影响 。
利用NumPy计算中位数:企业员工工资的中位数。
# 中位数:
print(np.median(salary))
# 17450.0
众数: 一组数据中出现次数最多的变量值 ,用 Mo 表示 。
从变量分布的角度看 ,众数是具有明显集中趋势点的数值 ,一组数据分布的最高峰点所对应的数值即为众数 。
利用NumPy计算中位数:NumPy 中没有直接计算众数的方法,需借助 scipy 模块(需安装)。
# 众数:
from scipy import stats
mode_s = stats.mode(salary)
print(mode_s)
# ModeResult(mode=array([17450.]), count=array([10]))
print(mode_s.mode[0])
# 17450.0
分位数: 中位数是从中间点将全部数据等分为两部分 。与中位数类似的还有四分位数 、十分位数和百分位数等 。它们分别是用 3个点 、9 个点和 99个点将数据四等分 、10 等分和 100等分后各分位点上的值 。
利用NumPy计算四分位数:企业员工工资的四分位数。
# 计算工资的 下四份位,中四分位,上四分位值:
s1,s2,s3 = quartile(salary)
print(s1,s2,s3)
# 10997.5 17450.0 23570.0
变异指标:
通常把一组数值之间的差异程度叫做标志变动度 。测定标志变动度大小的指标叫做标志变异指标 。标志变动度与标志变异指标在数值上成正比 。如果说平均指标说明总体分布的集中趋势的话 ,标志变异指标则说明总体分布的离中趋势 。
异众比率: 非众数组的频数占总频数的比率(Variation Ratio) ,称为异众比率 ,用 V r 表示 。异众比率的计算公式为 :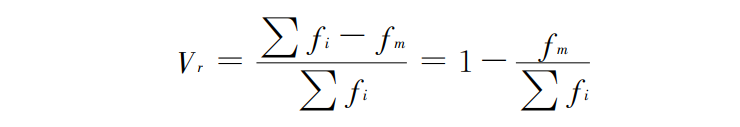
利用NumPy计算异众比率:企业员工工资的异众比率。
mode_count = mode_s.count[0]
dd_1 = 1 - (mode_count / len(salary))
print(dd_1)
# 0.998
四分位差: 上四分位 数与 下四 分位数 之 差 ,称 为四 分位差 ,亦称 为 内距 或 四 分 间 距 (Inter唱Quartile range) ,用 Qd 表示 。四分位差的计算公式为 :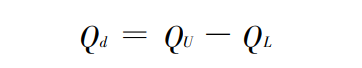
利用NumPy计算四分位差:企业员工工资的四分位差。
# 四分位差:
dd_2 = s3 - s1
print(dd_2)
# 12572.5
全距或极差: 全距又称极差 ,是一组数据的最大值与最小值之差 ,用 R 表示 。计算公式为: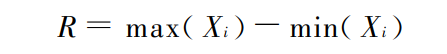
利用NumPy计算全距:企业员工工资的全距。
# 全距:
dd_3 = np.max(salary) - np.min(salary)
print(dd_3)
# 24990.0
平均差: 是各变量值与其算术平均数离差绝对值的平均数 ,用 MD 表示 。
简单平均法: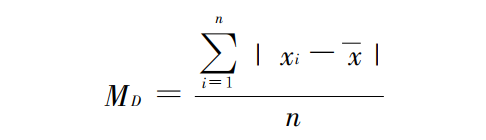
利用NumPy计算平均差:企业员工工资的平均差。
NumPy 中没有直接计算平均差的方法,但是可以用NumPy 中提供的一些基础方法和上面公式很快的计算出平均差:
# 工资的平均差
print(salary)
# [29060. 21810. 11410. ... 25190. 8410. 21130.]
# 构造平均值数组
salary_mean = np.ones_like(salary) * np.mean(salary)
print(salary_mean)
# [17373.596 17373.596 17373.596 ... 17373.596 17373.596 17373.596]
# 计算差值
salary_m_dif = np.abs(salary - salary_mean)
print(salary_m_dif)
# [11686.404 4436.404 5963.596 ... 7816.404 8963.596 3756.404]
# 计算平均差
print(np.mean(salary_m_dif))
# 6274.1054784
方差和标准差: 方差是各变量值与其算术平均数离差平方的算术平均数 。标准差是方差的平方根 。
总体的方差和标准差: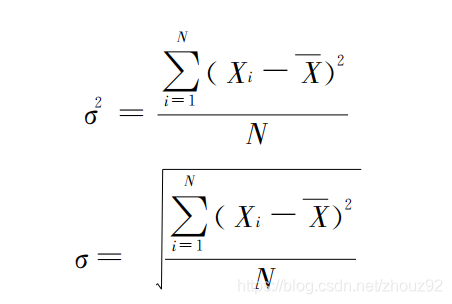
样本的方差和标准差: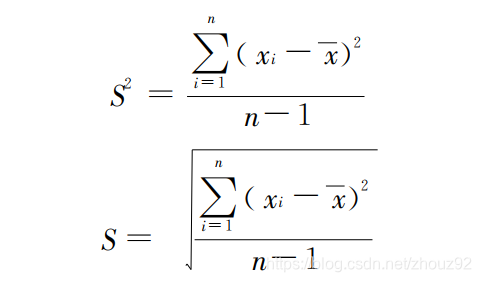
利用NumPy计算方差和标准差:企业员工工资的方差和标准差。
# 方差、标准差(自由度为n):
print(np.var(salary))
# 52776992.988784
print(np.std(salary))
# 7264.777559484117
# 方差、标准差(自由度为 n-1 ):
print(np.var(salary, ddof=1))
# 52787550.49888378
print(np.std(salary,ddof=1))
# 7265.504146229894
结尾:
以上就是本篇博客全部内容了,内容都较为基础,主要是介绍应用统计学的一些常用基础知识点和用 NumPy 模块计算这些基础统计指标。
下一篇的博客将会介绍,如果是范围数据,相关的统计指标应该如何进行计算。
该专栏着重介绍Python的科学计算、数据分析 NumPy 与 Pandas 模块的使用方法,并会结合统计学概念及数据分析相关方法对一些案例进行分析。
感兴趣的朋友,可以点个 关注 或 收藏 。如在博客中遇到任何问题或有一些想法、需求,可留言或私信。
创作不易,你的支持是我最大的动力,感谢 !

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)