<PostgreSQL数据库内核分析>之第二章:PostgreSQL的体系结构
·
文章目录
一、PostgreSQL安装和数据库命令
1.安装
初始化数据库集簇
cd postgres-master
在拥有configure目录下执行:
chmod +x ./configure
make;make install
cd /usr/local/pgsql
mkdir data/-----数据库文件的存放目录
useradd postgres
passwd postgres
chown postgres:postgres data
su - postgres
cd /usr/local/pgsql/bin
启动数据库服务器
./pg_ctl start -D ../data
创建和访问数据库test
./createdb test
./psql test
2.PG的数据库命令
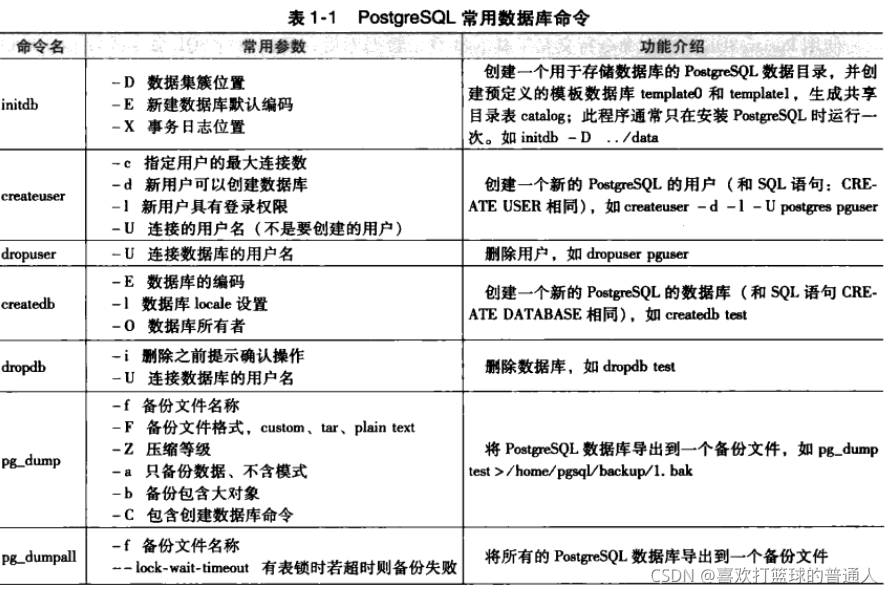
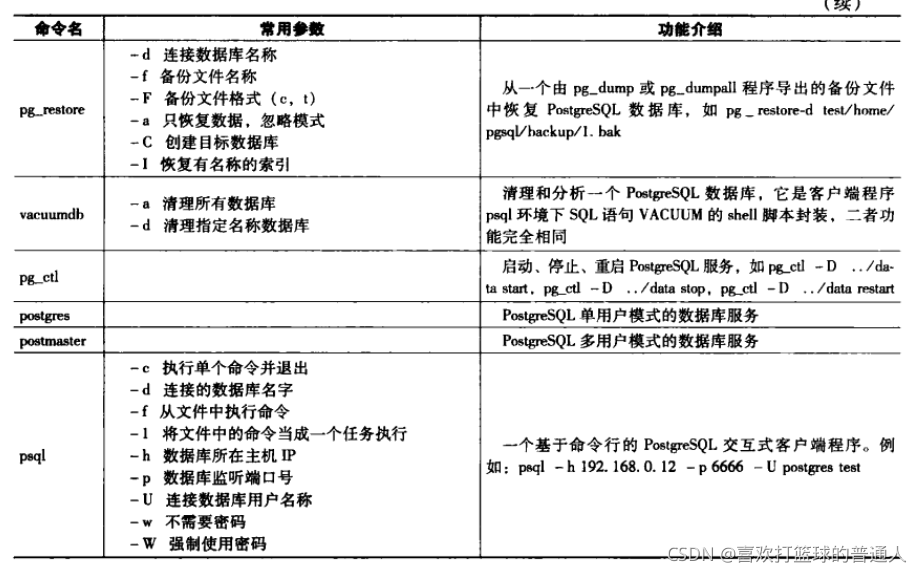
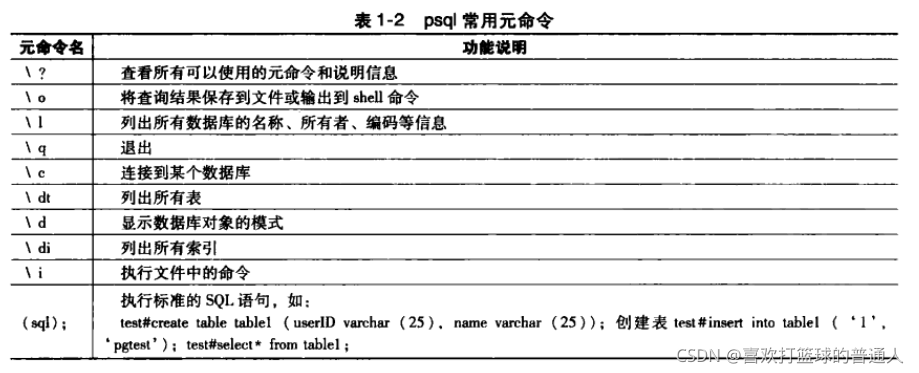
3.PG源代码的组织结构
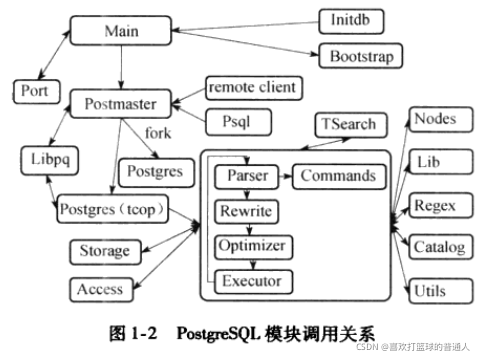
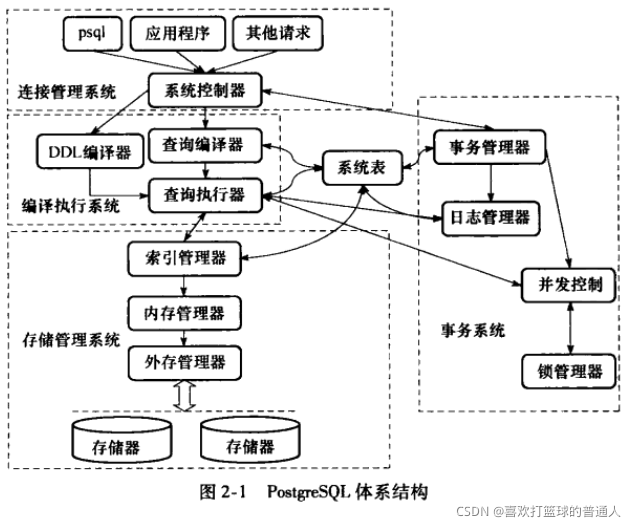
二、PG体系结构
系统表是PG数据库的元信息管理中心
- 包括数据库对象信息和数据库管理控制信息
- 系统表管理元数据信息,将PG数据库的各个模块有机地连接在一起,形成一个有效的DBS
1.系统表
SQL命令关联的系统表操作会自动维护系统表信息
- eg:CREATEDATABASE会向pg_database系统表中插入一行,且在磁盘上创建数据库
- PG的每一个数据库中都有自己的一套系统表,大多数都是在数据库创建时从从模板数据库中拷贝过来的,所以这些系统表里的数据都是与所属数据库相关的
- 少数系统表是所有数据库共享的,eg:pg_database,这些系统表里的数据都是关于所有数据库的
为了提高系统表的系统性能,在内存中建立了共享的系统表CACHE,使用Hash函数和Hash表提高了查询效率。
pg_namespace
- 系统表pg_namespace存储命名空间
- 每个名字空间有独立的关系、类型等集合,但并不会相互冲突
- pg_namespace中每一个元组都对应一个名字空间,每一个名字空间都被分配一个OID
pg_tablespace
- pg_tablespace存储表空间信息,pg_tablespace在整个数据集簇中只有一份,即:同一个数据集簇内的所有数据库共享一个pg_tablespace表,而不是每个数据库都有自己的pg_tablespace表
- DBA通过控制pg_tablespace存储表中,可以在文件系统里定义代表数据库对象的文件的存储位置,通过使用表空间,管理员可以控制PG中数据的磁盘布局,即可以通过表空间将PG系统的数据分布在不同的磁盘位置上。
pg_database
- pg_database中存放了当前数据集簇中的数据库的信息。
- 该表中每一个元组就表示集簇中的一个数据库。
pg_class
- pg_class存储表及与表类似结构的数据库对象信息,包含索引、序列、视图、复合数据类型、TOAST表
- 每一个对象都在pg_class中表示为一个元组
pg_type
- pg_type存储数据类型信息
- 基本数据类型和枚举类型由CREATE TYPE创建,域类型由CREATE DOMAIN创建,复合数据类型在表创建时自动创建
pg_ttribute
- pg_ttribute存储表的属性信息
- 数据库中表的每个属性都有一个元组
pg_index
- pg_index存储索引的具体信息
关键系统表之间存在的相互依赖关系如下: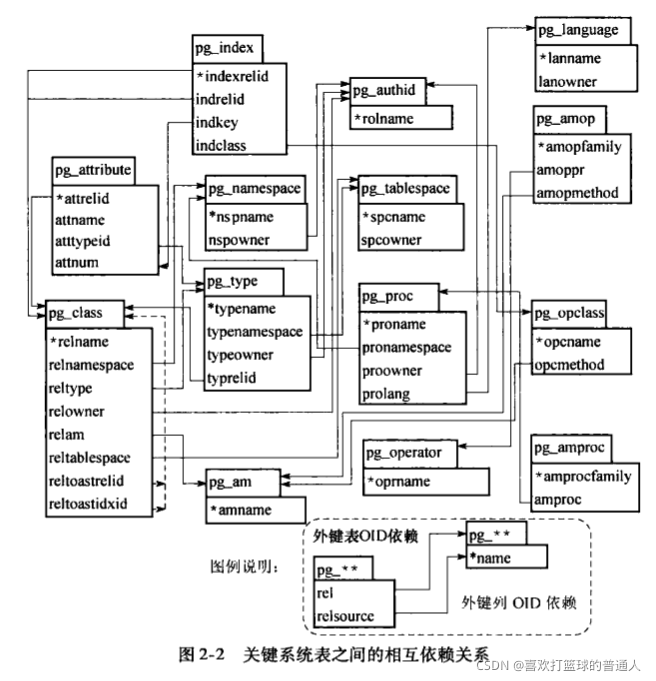
2.系统视图
系统视图提供了查询系统表和访问数据库内部状态的方法。
3.系统表小结
系统表是PG数据库系统运行控制信息的来源,是数据库系统的核心组成部分
- PG数据库安装后,系统表产生:需要先进行初始化数据库操作initdb,生成模板数据库和相应的目录、文件信息
- 用户数据库及其系统表都是从模板数据库进行复制而来
4.数据集簇
PG管理的用户数据库以及系统数据库总称为:数据集簇
- PG中的数据库就是磁盘上一些文件的集合
- PG的所有数据都存储在数据目录PGDATA中(数据目录通过会用环境变量PGDATA引用)
- PG中的对象标识符OID用来在整个数据集簇中唯一地标识一个数据库对象,对象可以是:数据库、表、索引、视图、元组、类型等
(1)数据集簇中每一个数据都对应于系统表pg_database中的一个元组,该元组OID属性中记录的就是分配给该数据库的OID
(2)数据库中的对象如:表、索引、视图、类型等,也对应于系统表pg_class中的一个元组,这个元组的OID属性中记录的OID就是该对象所分配的OID
(3)对于用户表的元组而言,若在CRERATE TABLE语句中使用了WITH OIDS选项,则该用户表中插入的每一个元组都将分配一个OID
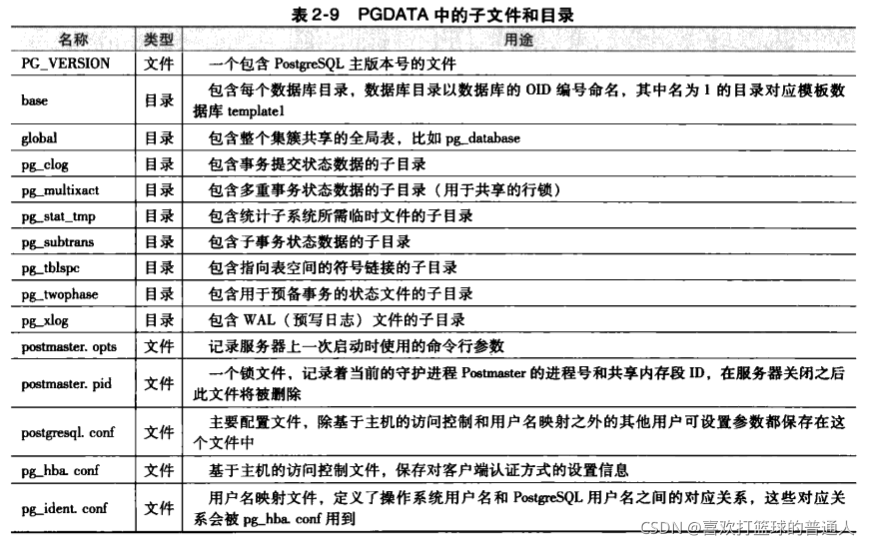
/usr/local/pgsql/data目录大概含义如下:
- 对于某个数据库而言,在base里都有一个子目录,子目录的名字是该数据库在系统表pg_database中的OID
- 每个表和索引都存储在其所属数据库目录下的独立文件里,以该表或者该索引的filenode号命名,该号码记录在该表或者索引对应的系统表pg_class中对应元组的relfilenode属性中
- 当一个表或者索引超过1GB之后,就被分裂成多个1GB的大小的段,第一个段的文件和filenode相同,随后的段命名为:filenode.1,filenode.2
- 若一个表的某些属性要存储相当大的数据,那么就会有个与之相关联的TOAST表,用于存储无法在数据行中放置的超大外置数据
[postgres@host226 data]$ ll
total 64
drwx------ 6 postgres postgres 54 Nov 26 00:26 base
drwx------ 2 postgres postgres 4096 Nov 26 00:26 global
drwx------ 2 postgres postgres 6 Nov 26 00:25 pg_commit_ts
drwx------ 2 postgres postgres 6 Nov 26 00:25 pg_dynshmem
-rw------- 1 postgres postgres 4789 Nov 26 00:25 pg_hba.conf
-rw------- 1 postgres postgres 1636 Nov 26 00:25 pg_ident.conf
drwx------ 4 postgres postgres 68 Nov 26 00:36 pg_logical
drwx------ 4 postgres postgres 36 Nov 26 00:25 pg_multixact
drwx------ 2 postgres postgres 6 Nov 26 00:25 pg_notify
drwx------ 2 postgres postgres 6 Nov 26 00:25 pg_replslot
drwx------ 2 postgres postgres 6 Nov 26 00:25 pg_serial
drwx------ 2 postgres postgres 6 Nov 26 00:25 pg_snapshots
drwx------ 2 postgres postgres 6 Nov 26 00:25 pg_stat
drwx------ 2 postgres postgres 84 Nov 26 18:54 pg_stat_tmp
drwx------ 2 postgres postgres 18 Nov 26 00:25 pg_subtrans
drwx------ 2 postgres postgres 6 Nov 26 00:25 pg_tblspc
drwx------ 2 postgres postgres 6 Nov 26 00:25 pg_twophase
-rw------- 1 postgres postgres 3 Nov 26 00:25 PG_VERSION
drwx------ 3 postgres postgres 60 Nov 26 00:25 pg_wal
drwx------ 2 postgres postgres 18 Nov 26 00:25 pg_xact
-rw------- 1 postgres postgres 88 Nov 26 00:25 postgresql.auto.conf
-rw------- 1 postgres postgres 28975 Nov 26 00:25 postgresql.conf
-rw------- 1 postgres postgres 45 Nov 26 00:25 postmaster.opts
-rw------- 1 postgres postgres 95 Nov 26 00:25 postmaster.pid
[postgres@host226 data]$ cat PG_VERSION
15
[postgres@host226 data]$ pwd
/usr/local/pgsql/data
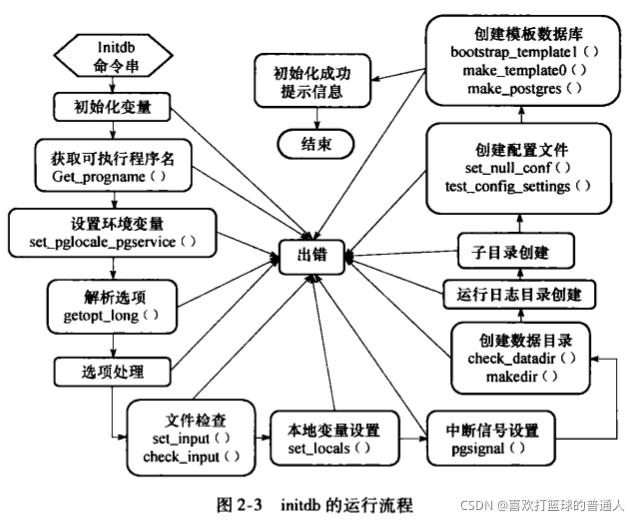
initdb
- 使用PG之前用于初始化数据集簇的程序,负责常见数据库目录、系统表、模板数据库
- 语法:

- 执行流程:
initdb将用户选项转换成对应参数,调用执行postgres程序。
postgres程序在这种方式下bootstrap模式下创建数据集簇,读取后端接口postgres.bki文件来创建模板数据库;
postgres.bki文件
- 在整个源代码被编译时,src\backend\catalog\genbki.pl脚本会被调用,然后读取src\include\catalog目录下的所有.h文件(这些.h文件包括:系统表定义、系统表的初始化数据、系统表上的索引信息等),将其转换为对应的BKI命令,最后将所有的BKI命令写入到postgres.bki文件中
- pg_*.h:每一个这样的头文件对应一个系统表的结构定义
- BKI文件仅仅用于初始化数据集簇,模板数据库template1是通过运行在bootstrap模式的postgres程序读取postgre.bki文件创建的。
initdb的执行过程
- initdb是PG中一个独立的程序,它的主要工作就是对数据集簇进行初始化,创建模板数据库和系统表,并向系统表中插入初始元组。
- 此后,用户创建各种数据库、表、视图、索引等数据库对象和其他操作时,都是在模板数据库和系统表的基础上进行的
系统数据库
- 创建完数据集簇后,集簇中默认包含三个数据库:template1,template0(两者用于创建数据库),postgres
- 不带-T选项的数据库是来自template1,如果对template1进行了修改,那么在修改之后创建的用户数据库也能体现在这些修改的结果中,template1就是一个自定义的模板数据库
- template0是作为模板生成的干净的数据库
- 初始数据库postgres用于给初始用户提供一个可连接的数据库,如Linux系统中一个用户的主目录
5.PG进程结构
PG系统主要功能都几种在postgres程序
- postmaster和postgres都是通过载入postgres程序而形成的进程
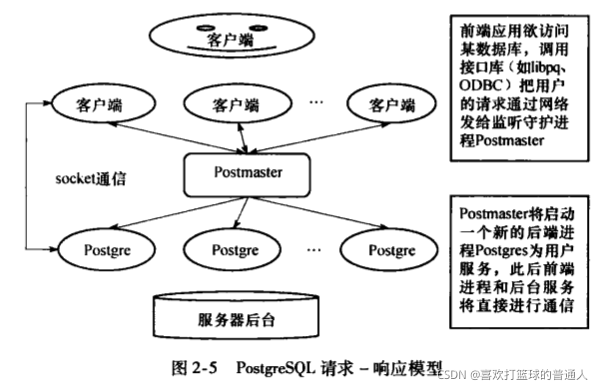
- 守护进程postmaster负责整个系统的启动和关闭,它监听并接受客户端的连接请求(eg:ODBS、libpq),为其分配服务进程postgres,此后前端进程和postmastr不再通信而直接与postgres进行通信
- 服务进程postgres接受并执行客户端发送的命令,它在底层模块(存储、事务管理、索引等)之上调用各个主要的功能模块(编译器、优化器、执行器),完成客户端的各种数据库操作,并返回执行结果
- PG采用C/S模式,系统为每一个客户端分配一个服务进程。
- 系统辅助进程:SysLogger(系统日志进程)、PgStat(统计数据收集进程)、AutoVacuum(系统自动清理进程)、BgWriter(后台写进程)、WalWriter(预写式日志进程)、PgArch(预写式日志归档进程)
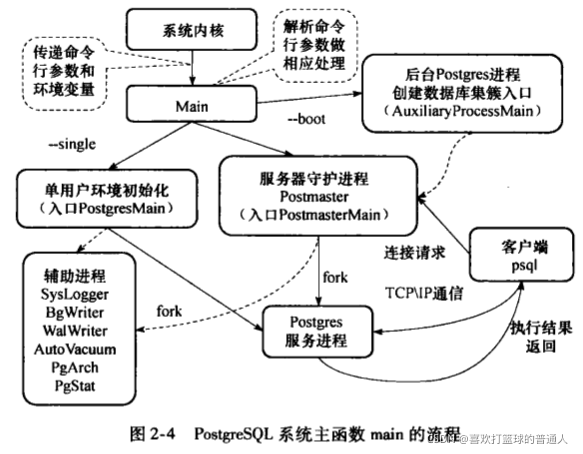
6.守护进程postmaster
数据集簇初始化之后,用户可以启动一个数据库实例来运行数据库管理系统
- 多用户模式下,一个数据库实例由数据库服务器守护进程postmaster来管理
- postmaster及其子进程的通信是通过共享内存和信号来实现的
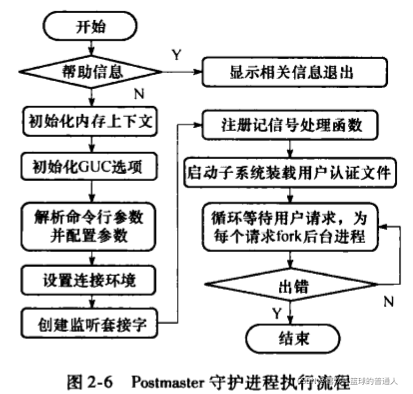
postmaster守护进程执行流程
- 入口:src\backend\postmaster\postmaster.c下的PostmasterMain()
7.辅助进程
在监听循环ServerLoop中,每一次循环时都会检查各个辅助进程号对应的全局变量是否为0,并根据系统中进程运行状态机标志变量pmStste的状态来启动相应的辅助进程。
SysLogger系统日志进程
- postmaster创建pip一个管道,用dup2将stdout和stderr重定向到日志管道的写入端,然后fork一个子进程来运行syslogger
- syslogger调用select监听日志管道的读取端,当监听到发生了数据读取事件时,调用pipread函数从日志管道的读取端中读取一定长度的数据到临时缓冲区logbuffer中
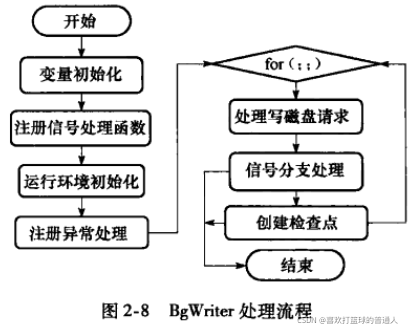
BgWriter后台写进程
- 在后台将脏页写出到磁盘,
作用:BgWriter定期写出缓冲区中的部分脏页到磁盘中,降低查询处理被阻塞的可能性;
由于PG定期做检查点时要把脏页写出到磁盘,BgWriter可以预先写出一些脏页,降低IO。 - BgWriter从后向前扫描缓冲区的LRU链表,写出至多bgwriter_lru_multiplier*N个脏页,且<=bgwriter_lru_maxpages,N是BgWriter运行期间系统新申请的缓冲页数。
- BgWriter处理流程
- 检查点的创建流程
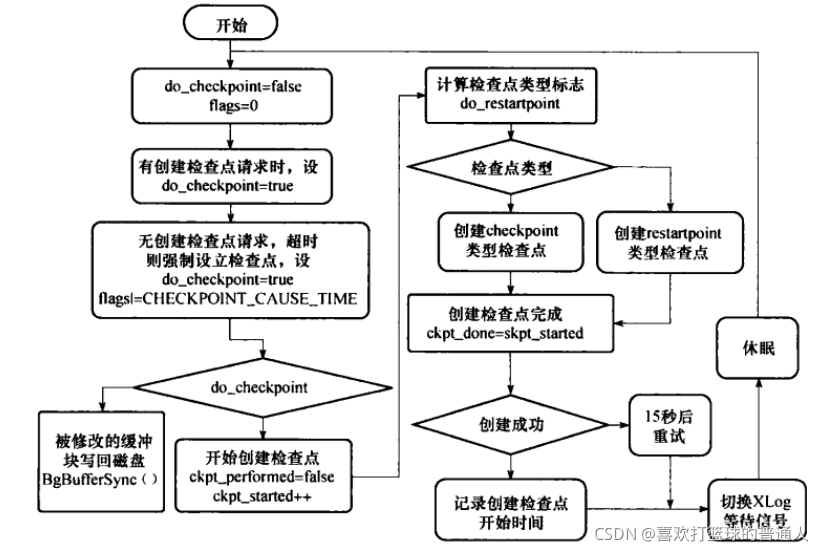
- BgWriter后台写进程最理想的情况是后台写进程负责刷回所有的缓冲区,但是,若后后台写进程不能保证有足够多干净的缓冲区情况下,那么常规后台进程仍然有权刷回缓冲区。
WalWriter预写式日志写进程
- 预写式日志WAL(Write Ahead Log,也称之为Xlog),其中心思想是:对数据文件的修改必须是只能发生在这些修改已经提交到日志之后,即:先写日志后写数据。
- 事务提交记录不是在提交时间同步地写入磁盘,而是在一个已知的预先设置的时间异步地写入。同BgWriter,其他服务进程在WalWriter出错时也允许直接进行预写日志的写操作
- WAL的缓冲区和控制结构在共享内存里,他们用轻量级锁来保护。
- WalWriter流程
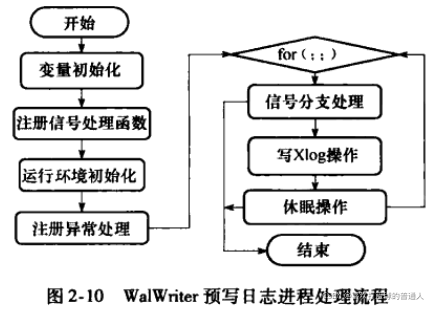
- WalWriter定期写磁盘的是存放预写式日志的WAL缓冲区,Bgwriter定期写入的是存放普通数据的共享缓冲区
PgArch预写式日志归档进程
- PITR(Point-In-Time-Recovery)技术:支持将数据库恢复到其运行历史中任意一个有记录的时间点。
- 为实现PITR,需要在WAL段文件被重用时进行归档备份操作,把将被重用的WAL段中的记录保存到其他位置,这样归档日志加上当前日志就可以形成连续的WAL日志记录
- PgArch流程
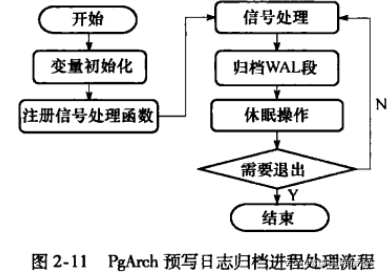
- WAL的日志归档的数据库备份策略:组合了文件系统备份和WAL文件备份,在开始时并不需要一个非常完美的一致性备份,任何备份内部的不一致都会被日志的重放动作修改正确。
AutoVacuum系统自动清理进程
- PG中,对表元组的UPDATE或者DELETE操作并未立即删除旧版本的数据,表中的旧元组只是被标识为删除状态,并未立即释放空间,AutoVacuum会自动执行VACUUM和ANALYZE命令,回收被标识为删除状态记录的空间
- 在系统进行自动清理的同时,用户可以使用vacuumdb(清理数据库并对数据库执行分析)和vacuumlo对数据进行手动清理(清理数据库中无效的大对象)
PgStat统计数据收集进程
- 负责收集数据库系统运行中的统计信息:如在一个表和索引上进行了多少次插入与更新操作、磁盘块的数量和元组的数量、每个表上最近一次执行清理和分析操作的时间,统计每个用户自定义函数调用执行的时间等。
- PgStat辅助进程收集的统计信息主要用于:查询优化时的代价估算
(1)在PG的查询优化过程中,查询请求的不同执行方案是通过建立不同的路径PATH来表达的。在生成了许多符合条件的路径之后,从中选择代价最小的路径转化为一个计划。这个计划被传递给执行器执行。
(2)所以,优化器的核心工作就是:建立许许多多的路径,然后从中找出最优的路径。
(3)造成查询请求有不同路径的主要原因是:
表不同的访问方式:eg:顺序访问Sequential Access、索引访问Index Access,PG中还可能使用TID直接访问元组;
表间不同的连接方式:eg:嵌套循环连接Nest-loop join、归并连接Merge join、hash连接Hash join;
表间不同的连接顺序:eg:左连接left join、右连接right join、布希连接bushy join; - pgstatCollectorMain处理流程如下:
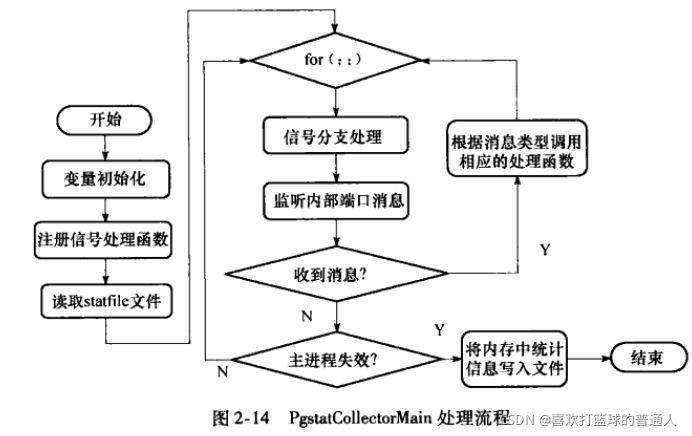
8.服务进程Postgres
Postgres进程是实际的接受查询请求并调用相应模块处理查询的PG服务进程。
- 它接受用户的命令进行编译执行,并将结果返回给用户,直到用户断开连接
- 用户命令分为两种:
查询命令:插入、删除、更新和选择
非查询命令:创建/删除表、视图、索引等 - PostgresMain流程如下:
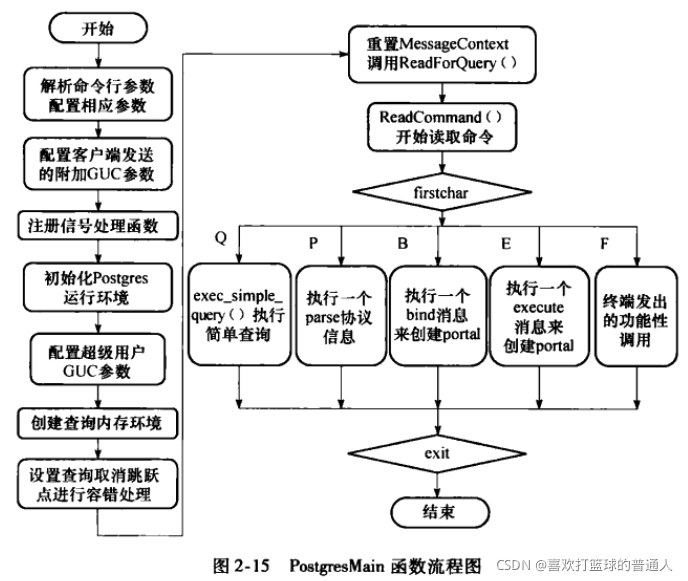
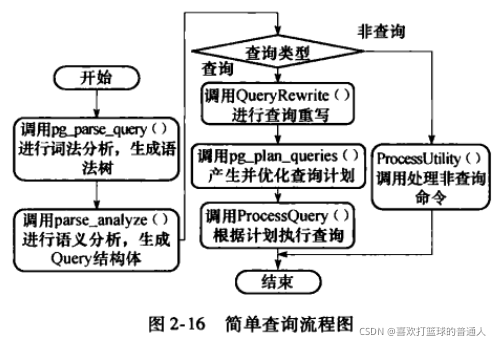
简单查询的执行流程
- 一般的数据操作语言DML命令都是作为简单查询来处理的
- exec_simple_query执行流程大致如下:包括:编译器、分析器、优化器和执行器
- postgres进程在系统中扮演着一个工作执行者的角色,在单用户或者多用户模式下,客户端请求通过认证后,将直接与服务进程postgres进程通信,而无需守护进程干预,只在客户端对应的后台进程出现问题时,由守护进程执行容错恢复工作。
- PG和用户进程交互,执行客户端提交的查询请求和命令,并将执行结果通过网络返回给用户。
- PG后台进程的运行实现了PG的多任务并发执行。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)