基于face_recognition实现人脸识别(python)
一.前言
1.本项目是基于face_recognition(底层为dlib机器学习库)开发的,需要具备一定的python基础,对使用到的相关库内置函数有简单的了解(无需深度了解),本项目内容仅为个人观点。(各位可在评论区表达自己看法,并指出错误,谢谢!
2.需要了解face_recognition,可去face_recognition官网,https://face-recognition.readthedocs.io/en/latest/modules.html
二.项目介绍
这个是基于face_recognition(封装了dlib)实现的人脸识别项目,通过对已知人脸图片和未知人脸图片进行编码,把人脸转化为 128 维数字特征向量,不对比图片像素,只对比人脸特征的相似度,相似度达标就判定为同一个人,最终识别出人脸图片。
三.核心思路
1.构建已知人脸特征库
遍历存放已知照片的文件夹,对每张照片:检测人脸 → 生成 128 维人脸特征 → 把特征和姓名 一一对应保存。
2.处理待识别图片
读取要识别的测试图,转换色彩空间,定位图中所有人脸的坐标位置,根据检测到的人脸位置,给测试图里的每张人脸,同样生成128 维特征向量。
3.特征匹配 + 结果标注
拿测试人脸特征和人脸库里特征逐一比对,相似度(欧式距离)小于设定阈值(0.5)→匹配成功,对应人名都不匹配 → 标记为 unknown,最后给人脸画框、标注姓名,展示结果。
四.具体步骤(含代码)
1.项目目录(pycharm为例)
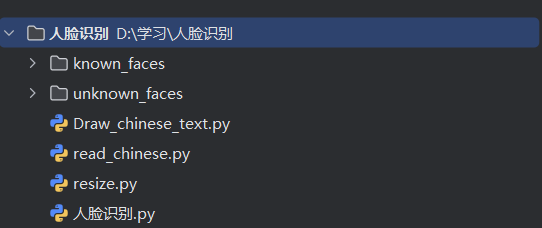
大家可以按照我的格式来,也可以按照自己的。knowns_faces用于装已知人脸照片,图片命名为‘名字’+‘拓展名’,unknown——faces用于未知人脸照片,图片命名可以‘随意’+‘拓展名’,如下:
2.环境配置(强烈建议使用Anaconda或者miniconda去配置环境)
python3.9及以上都可以,如果有Anaconda或者miniconda,去对应环境依次执行,conda install -c conda-forge dlib,pip install face_recognition opencv-python,库版本自行决定,建议使用清华源https://pypi.tuna.tsinghua.edu.cn/simple
3.导入相关库
import cv2 #OpenCV,用于图像读取、显示、画框等
import face_recognition #人脸识别库,封装了dlib的检测和编码功能
import os #操作系统接口,拼接文件路径和遍历文件夹
import resize as rs #调整显示图片大小
import read_chinese as rc #中文路径读取图片
import Draw_chinese_text as Dr #显示中文在图片上cv2,face_recognition,os库是配置的,resize,read_chinese,Draw_chinese_text是自己写的。
resize:
import cv2
def resize_display(img, max_width=800, max_height=600):
h, w = img.shape[:2]
scale = min(max_width / w, max_height / h, 1.0) # 仅缩小,不放大
if scale < 1.0:
new_w = int(w * scale)
new_h = int(h * scale)
img = cv2.resize(img, (new_w, new_h), interpolation=cv2.INTER_AREA)
return img这个是用于控制输出图片大小的。
read_chinese:
import os
import cv2
import numpy as np
def imread_chinese(path):
if not os.path.exists(path):
print(f"文件不存在: {path}")
return None
with open(path, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8)
return cv2.imdecode(data, cv2.IMREAD_COLOR)这个可以读取含中文的文件路径。
Draw_chinese_text:
from PIL import ImageFont, ImageDraw, Image
import numpy as np
import cv2
def draw_chinese_text(img, text, position, font_path, font_size=30, color=(0, 255, 0)):
#将OpenCV的BGR转为PillowRGB
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
font = ImageFont.truetype(font_path, font_size)
#Pillow使用(R,G,B)颜色,所以要把BGR倒过来
draw.text(position, text, font=font, fill=(color[2], color[1], color[0]))
#转回OpenCV的BGR格式
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)这个是用来在图片上显示中文的,如果直接显示会乱码。
4.对已知人脸照片进行处理
#===================对已知人脸照片进行处理==================
#存储每个人脸的128维特征向量
known_face_encodings = []
#存储对应的姓名
known_face_names = []known_face_encodings是用来储存已知人脸128维特征向量的,用于后续与未知人脸128维特征向量进行比对的,known_face_names则是用来储存对应姓名的,用于匹配成功之后所用的人名。
#已知人脸照片的存放文件夹
known_faces_dir = r"known_faces"
#遍历文件夹内所有文件
for filename in os.listdir(known_faces_dir):
#常见图片格式
if filename.lower().endswith(('.jpg', '.png')):
#拼接完整路径
img_path = os.path.join(known_faces_dir, filename)
#face_recognition加载图片
img = face_recognition.load_image_file(img_path)
#提取每张图里的人脸编码
encodings = face_recognition.face_encodings(img)
#检测到了人脸
if encodings:
#保存脸的编码
known_face_encodings.append(encodings[0])
#文件名去掉扩展名后作为人名
known_face_names.append(os.path.splitext(filename)[0]) os.listdir(known_faces_dir)列出 known_faces_dir这个文件夹里的所有文件和子文件夹名称,返回一个列表,通过for循环去遍历这个列表,endswith(('.jpg', '.png'))则是用来检查是否以jpg.png结尾的,因为filename路径并不完整,因此需要用join拼接一下路径,之后需要加载图片,并且给人脸生成128维特征向量,如果存在人脸,我们就储存人脸的特征向量到known_face_encodings,之所以是encodings[0],是因为face_recognition.face_encodings(img)会对传入的图片进行人脸检测(返回值是列表),然后为检测到的每一张脸生成一个128维的特征向量,也就是说,当一张图片只有一个人脸的时候,就会只有一个人脸编码,当一张图片有两个人的时候就会有两个人的人脸编码,我提供的每张图片只有一张人脸,因此也就只有一个128维的特征向量,因此encodings这个列表只有一个特征向量,之后用os.path.splitext()[0]获取人名。
5.对未知人脸照片进行处理
#===================对未知人脸照片进行处理==================
#测试图片路径
test_path = r"unknown_faces/彭于晏.png"
#调用自定义函数读取图片
test_img = rc.imread_chinese(test_path)
#当图片读取失败
if test_img is None:
print("无法读取测试图片,程序退出")
exit()这一段主要是用来读取图片的。
#将BGR转换为RGB(face_recognition需要RGB)
test_img1 = cv2.cvtColor(test_img, cv2.COLOR_BGR2RGB)颜色转换。
#定位所有人脸的位置(返回列表(top, right, bottom, left))
face_locations = face_recognition.face_locations(test_img1)
#根据位置提取每张人脸的128维特征编码
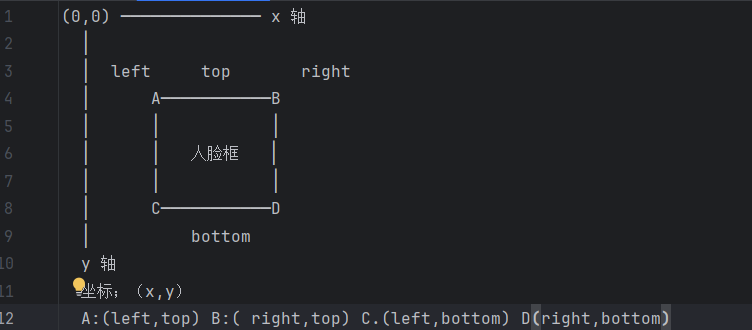
face_encodings = face_recognition.face_encodings(test_img1, face_locations)用来对未知人脸生成128维特征向量,之所以要定位所有人脸位置,是因为一张图片,可能不止有一张人脸,有人可能不太理解列表(top, right, bottom, left),这里给大家展示一下:
6.已知与未知进行对比
#将每张人脸的位置和编码打包,逐个处理
for (top, right, bottom, left), face_encoding in zip(face_locations, face_encodings):
#与已知人脸库比对,返回布尔值列表,表示与每个已知人的相似情况
matches = face_recognition.compare_faces(known_face_encodings, face_encoding, tolerance=0.5)
#默认标为“未知”
name = "Unknown"
#当匹配成功
if True in matches:
#找到第一个匹配的索引
first_match_index = matches.index(True)
#取出对应的人名
name = known_face_names[first_match_index]zip(face_locations, face_encodings)把位置信息和特征编码“配对”起来,然后逐个人脸进行处理face_recognition.compare_faces则是用于未知和已知进行对比,当小于阈值时,就是说明相似度高,之所以要小于,是因为相似度比对,实际上就是计算欧式距离,距离自然是越近越好,越近相似度越高,之后通过索引去找寻名字。
7.画框和显示名字
#画框
cv2.rectangle(test_img, (left, top), (right, bottom), (0, 255, 0), 2)
#显示名字
font_path = "C:/Windows/Fonts/msyh.ttc" # 微软雅黑,确保路径正确
test_img = Dr.draw_chinese_text(test_img, name, (left, top - 30), font_path, font_size=25, color=(0, 255, 0))在人脸图片上,画框和显示名字,font_path是字体的路径。
8.剩余操作
#调整图片尺寸
test_img = rs.resize_display(test_img, max_width=800, max_height=600)
#显示图片
cv2.imshow('Face Recognition', test_img)
# 等待用户按下任意键,退出
cv2.waitKey(0)
#销毁窗口
cv2.destroyAllWindows()修改图片大小,之后显示图片,用户任意按键则退出,最后再销毁窗口,释放资源。
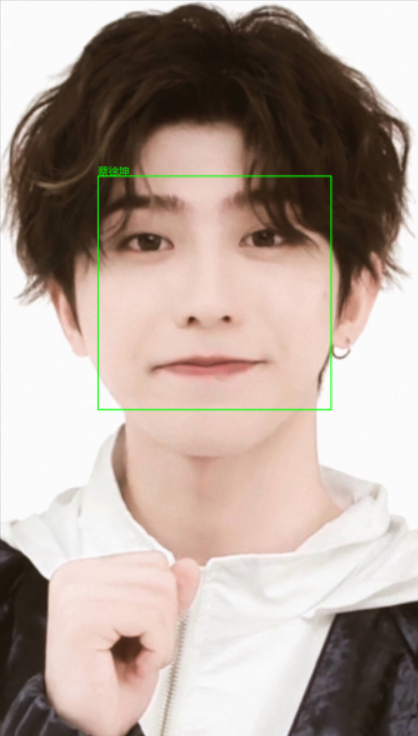
五.效果展示
单人:
多人:

总体效果还是不错的。
六.完整代码
1.主程序
import cv2 #OpenCV,用于图像读取、显示、画框等
import face_recognition #人脸识别库,封装了dlib的检测和编码功能
import os #操作系统接口,拼接文件路径和遍历文件夹
import resize as rs #调整显示图片大小
import read_chinese as rc #中文路径读取图片
import Draw_chinese_text as Dr #显示中文在图片上
#===================对已知人脸照片进行处理==================
#存储每个人脸的128维特征向量
known_face_encodings = []
#存储对应的姓名
known_face_names = []
#已知人脸照片的存放文件夹
known_faces_dir = r"D:\学习\人脸识别\known_faces"
#遍历文件夹内所有文件
for filename in os.listdir(known_faces_dir):
#常见图片格式
if filename.lower().endswith(('.jpg', '.png')):
#拼接完整路径
img_path = os.path.join(known_faces_dir, filename)
#face_recognition加载图片
img = face_recognition.load_image_file(img_path)
#提取每张图里的人脸编码
encodings = face_recognition.face_encodings(img)
#检测到了人脸
if encodings:
#保存脸的编码
known_face_encodings.append(encodings[0])
#文件名去掉扩展名后作为人名
known_face_names.append(os.path.splitext(filename)[0])
#输出已录入的所有人名,方便核对
print("已录入:", known_face_names)
#===================对未知人脸照片进行处理==================
#测试图片路径
test_path = r"unknown_faces/周杰伦和邓紫棋.png"
#调用自定义函数读取图片
test_img = rc.imread_chinese(test_path)
#当图片读取失败
if test_img is None:
print("无法读取测试图片,程序退出")
exit()
#将BGR转换为RGB(face_recognition需要RGB)
test_img1 = cv2.cvtColor(test_img, cv2.COLOR_BGR2RGB)
#定位所有人脸的位置(返回列表(top, right, bottom, left))
face_locations = face_recognition.face_locations(test_img1)
#根据位置提取每张人脸的128维特征编码
face_encodings = face_recognition.face_encodings(test_img1, face_locations)
#将每张人脸的位置和编码打包,逐个处理
for (top, right, bottom, left), face_encoding in zip(face_locations, face_encodings):
#与已知人脸库比对,返回布尔值列表,表示与每个已知人的相似情况
matches = face_recognition.compare_faces(known_face_encodings, face_encoding, tolerance=0.5)
#默认标为“未知”
name = "Unknown"
#当匹配成功
if True in matches:
#找到第一个匹配的索引
first_match_index = matches.index(True)
#取出对应的人名
name = known_face_names[first_match_index]
#画框
cv2.rectangle(test_img, (left, top), (right, bottom), (0, 255, 0), 2)
#显示名字
font_path = "C:/Windows/Fonts/msyh.ttc" # 微软雅黑,确保路径正确
test_img = Dr.draw_chinese_text(test_img, name, (left, top - 30), font_path, font_size=25, color=(0, 255, 0))
#调整图片尺寸
test_img = rs.resize_display(test_img, max_width=800, max_height=600)
#显示图片
cv2.imshow('Face Recognition', test_img)
# 等待用户按下任意键,退出
cv2.waitKey(0)
#销毁窗口
cv2.destroyAllWindows()2.resize
import cv2
def resize_display(img, max_width=800, max_height=600):
h, w = img.shape[:2]
scale = min(max_width / w, max_height / h, 1.0) # 仅缩小,不放大
if scale < 1.0:
new_w = int(w * scale)
new_h = int(h * scale)
img = cv2.resize(img, (new_w, new_h), interpolation=cv2.INTER_AREA)
return img3.read_chinese
import os
import cv2
import numpy as np
def imread_chinese(path):
if not os.path.exists(path):
print(f"文件不存在: {path}")
return None
with open(path, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8)
return cv2.imdecode(data, cv2.IMREAD_COLOR)4.Draw_chinese_text
from PIL import ImageFont, ImageDraw, Image
import numpy as np
import cv2
def draw_chinese_text(img, text, position, font_path, font_size=30, color=(0, 255, 0)):
#将OpenCV的BGR转为PillowRGB
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
font = ImageFont.truetype(font_path, font_size)
#Pillow使用(R,G,B)颜色,所以要把BGR倒过来
draw.text(position, text, font=font, fill=(color[2], color[1], color[0]))
#转回OpenCV的BGR格式
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)七.补充
本项目代码中的参数,需根据具体情况进行调整,代码内容仅供参考。需要图片的,可以私聊
,或者去网上也可以找到。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)