PyTorch深度学习实战:图神经网络
- PyTorch基础与异或问题实践
- 激活函数与神经网络优化
- 数据预处理与模型优化:FashionMNIST实验
- 经典CNN架构与PyTorch Lightning实践
- Transformers与多头注意力机制实战
- 深度能量模型与PyTorch实践
- 图神经网络
- 自编码器与神经网络应用
- 深度归一化流图像建模与实践
- 自回归图像建模与像素CNN实现
- Vision Transformers with PyTorch Lightning on昇腾
- ProtoNet与ProtoMAML元学习算法实践
- SimCLR与Logistic回归在自我监督学习中的应用
图神经网络
学习目标
在本课程中,学员将深入探究图神经网络(GNN)的构建与应用。本课程将从图的表示方法入手,学习如何用邻接矩阵或边列表高效表示图结构,并理解其在矩阵运算中的应用。重点掌握图卷积网络(GCN)和图注意力网络(GAT)的原理与实现,包括它们的消息传递机制、参数共享方式以及如何通过代码实现这些图层。此外,将学习利用 PyTorch Geometric 等库优化 GNN 的实现,尤其针对大型图数据。同时会通过实验掌握 GNN 在节点级(如半监督节点分类)、边级(如链接预测)和图级(如图分类)任务中的应用,学习如何构建模型、训练过程以及评估模型性能。最终目标是理解如何将图信息融入预测模型中以提升性能,并探索 GNN 在各领域的应用潜力。
相关知识点
- 图神经网络
学习内容
1 图神经网络
1.1 背景介绍
图神经网络(Graph Neural Networks, GNNs)是一类用于处理图结构数据的深度学习模型。图结构数据由节点(顶点)和边(连接关系)组成,能够自然地表示实体之间的复杂关系。图神经网络(GNNs)在应用和研究领域都越来越受欢迎,包括社交网络、知识图谱、推荐系统和生物信息学等领域。虽然 GNN 背后的理论和数学可能一开始看起来很复杂,但这些模型的实现却相当简单,有助于理解其方法。因此,本课程将讨论 GNN 的基本网络层的实现,即图卷积和注意力层。最后,将 GNN 应用于节点级、边级和图级任务。
下面,将开始导入依赖模块,使用 PyTorch Lightning。
1.2 环境依赖和数据集准备
%pip install wheel==0.44.0
%pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 torch-npu==2.2.0 seaborn==0.13.2 ipdb==0.13.13
%pip install pytorch-lightning==2.4.0
%pip install torch-geometric==2.3.1 lightning[extra]
备注:如果没有NPU,也可以采用GPU或CPU的方式学习。
GraphLevelGraphConv.ckpt 是基于图卷积网络(GCN)的图级分类模型,用于对整个图结构(如分子或社交网络)进行预测,依赖图的全局拓扑信息;NodeLevelGNN.ckpt 是节点级图神经网络(GNN)模型,通过捕捉节点局部邻域结构进行节点分类(如用户标签预测),融合了图结构与节点特征;NodeLevelMLP.ckpt 则是基于多层感知机(MLP)的节点分类模型,仅利用节点自身属性进行预测,忽略图结构信息,适用于计算效率优先且无需结构依赖的场景。三者的核心差异在于任务层级(图级 vs. 节点级)和是否利用图结构,需根据具体需求(如数据特性、计算资源)选择适用模型。
!wget --no-check-certificate https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_models/74416a1c44fb11f0a4c4fa163edcddae/saved_models.zip
!unzip saved_models.zip
Cora数据集是图神经网络(GNN)领域广泛使用的基准数据集,包含2708篇科学论文,每篇论文通过引用关系构成图结构(共5429条有向边),每篇具有1433维二进制词袋特征(基于词频统计)和1个主题标签(7个类别,如神经网络、遗传算法等)。其核心任务是节点分类:在仅使用部分标签(通常每个类别20个样本)的半监督设置下,通过图结构和文本特征预测未标注节点的类别,常用于评估GNN模型在同构图上的学习能力及对节点特征与拓扑关系的联合建模效果。
MUTAG数据集是图分类任务的经典基准数据集,每个图平均包含 188 个图,每个图有 18 个节点和 20 条边。每个图代表一种化合物的结构,节点表示原子(7维二进制属性,如原子类型:碳、氧等),边表示化学键(无属性特征,为无向边)。其任务是二元分类:预测分子是否具有抗原性(Mutagenicity,即是否能诱发基因突变),常用于评估图神经网络(GNN)在分子属性预测等图级任务中的性能,因其小规模特性(仅188个图)而成为算法调试和基准测试的常用选择,但也因数据量有限可能引发过拟合问题。
!wget --no-check-certificate https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_datasets/9206488e44ff11f0a4c4fa163edcddae/data.zip
!unzip -q data.zip
需要下载ascend_npu_for_pytorch_lightning代码库,该代码库适配pytorch-lightning 2.4,以支持NPU的训练。
注:如果没有NPU,下列步骤可以跳过。可以使用CPU或GPU替代计算。
起跳:
!wget --no-check-certificate https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_codes/7f52f39e594111f09ca4fa163edcddae/ascend_npu_for_pytorch_lightning.zip
!unzip ascend_npu_for_pytorch_lightning.zip
%cd ascend_npu_for_pytorch_lightning
切换到ascend_npu_for_pytorch_lightning库目录下执行后续步骤:
导入相关依赖,包括导入数据处理、绘图、PyTorch及Lightning相关库,设置数据集和模型保存路径,固定随机种子以确保可复现性,检查并使用 NPU(若可用)。
# 导入标准库和工具
import os
import json
import math
import numpy as np
import time
# 导入绘图工具
import matplotlib.pyplot as plt
%matplotlib inline
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('svg', 'pdf')
from matplotlib.colors import to_rgb
import matplotlib
matplotlib.rcParams['lines.linewidth'] = 2.0
import seaborn as sns
sns.reset_orig()
sns.set()
from tqdm.notebook import tqdm
# 导入PyTorch相关模块
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import torch.optim as optim
import torch_npu
import torchvision
from torchvision.datasets import CIFAR10
from torchvision import transforms
try:
import pytorch_lightning as pl
except ModuleNotFoundError:
%pip install --quiet pytorch-lightning>=1.4
import pytorch_lightning as pl
from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint
DATASET_PATH = "../data"
CHECKPOINT_PATH = "../"
pl.seed_everything(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
if torch_npu.npu.is_available():
device = torch.device("npu:0") # 指定使用第一个 NPU 设备
print("Using NPU device.")
else:
device = torch.device("cpu") # 如果 GPU 和 NPU 都不可用,使用 CPU
print("Using CPU device.")
上岸:
切换到anaconda的虚拟环境目录(如:torch_env)下执行后续步骤:
下列是我对Mac book pro 2019的MPS的适配,最后发现lightning不匹配,最终还是换成了CPU方式,所以,只要你有CPU就可以学着玩。
# 导入标准库和工具
import os
import json
import math
import numpy as np
import time
# 导入绘图工具
import matplotlib.pyplot as plt
from matplotlib.colors import to_rgb
import matplotlib
matplotlib.rcParams['lines.linewidth'] = 2.0
import seaborn as sns
sns.reset_orig()
sns.set()
from tqdm.notebook import tqdm
# 导入PyTorch相关模块
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import torch.optim as optim
import torchvision
from torchvision.datasets import CIFAR10
from torchvision import transforms
import pytorch_lightning as pl
DATASET_PATH = "data"
CHECKPOINT_PATH = "./"
pl.seed_everything(42)
torch.backends.cudnn.benchmark = False
# 此处GPU自行添加判断,增强动手能力,我就不写了。
if torch.backends.mps.is_available():
device = torch.device("mps") # 指定使用第一个 NPU 设备
print("Using MPS device.")
else:
device = torch.device("cpu") # 如果 GPU 和 NPU 都不可用,使用 CPU
print("Using CPU device.")
1.3 图表示
在开始讨论图上的特定神经网络操作之前,应该考虑如何表示一个图。从数学上讲,一个图 G \mathcal{G} G被定义为一个节点/顶点集 V V V和一个边/链接集合 E E E的元组: G = ( V , E ) \mathcal{G}=(V,E) G=(V,E)。每条边是两个顶点的对,表示它们之间的连接。例如,可以观察下面的这个图:
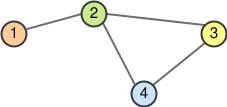
图1: 图示例
顶点是 V = { 1 , 2 , 3 , 4 } V=\{1,2,3,4\} V={1,2,3,4},边是 E = { ( 1 , 2 ) , ( 2 , 3 ) , ( 2 , 4 ) , ( 3 , 4 ) } E=\{(1,2), (2,3), (2,4), (3,4)\} E={(1,2),(2,3),(2,4),(3,4)}。请注意,为了简化,假设图是无向的,因此不会添加镜像对如 (2,1)。在实际应用中,顶点和边通常具有特定的属性,边甚至可以是定向的。问题在于如何以高效的方式表示这种多样性来进行矩阵运算。通常,对于边,将会在两种变体之间做出选择:邻接矩阵,或顶点索引对的列表。
邻接矩阵 A A A是一个方阵,其元素表示顶点对是否相邻,即是否连接。在最简单的情况下, A i j A_{ij} Aij 如果从节点 i i i 连接到 j j j。则为 1,否则为 0。如果有边的属性或图中不同类别的边,这些信息也可以添加到矩阵中。对于无向图,请记住 A A A是一个对称矩阵( A i j = A j i A_{ij}=A_{ji} Aij=Aji)。对于上面的示例图,有以下邻接矩阵:
A = [ 0 1 0 0 1 0 1 1 0 1 0 1 0 1 1 0 ] A = \begin{bmatrix} 0 & 1 & 0 & 0\\ 1 & 0 & 1 & 1\\ 0 & 1 & 0 & 1\\ 0 & 1 & 1 & 0 \end{bmatrix} A= 0100101101010110
将图表示为边列表在内存和(可能)计算方面更高效,但使用邻接矩阵更直观且更容易实现。在实现中,将依赖邻接矩阵以保持代码简洁。然而,常见库使用边列表。或者,也可以使用边列表来定义稀疏邻接矩阵,这样可以像处理密集矩阵一样处理它,但允许更内存高效的运算。PyTorch 通过子包torch.sparse支持这一点,但它仍然处于 beta 阶段(API 可能在将来发生变化)。
1.4 图卷积
图卷积网络由 Kipf 等人于 2016 年在阿姆斯特丹大学提出。GCN 在图像卷积方面是相似的,因为"滤波器"参数通常在图的所有位置上共享。同时,GCN 依赖于消息传递方法,这意味着顶点与邻居交换信息,并向彼此发送"消息"。在查看数学内容之前,可以尝试通过视觉来理解 GCN 的工作原理。第一步是每个节点创建一个特征向量,该向量代表它想要发送给所有邻居的消息。第二步,消息被发送到邻居,这样每个节点都会接收到每个相邻节点的一条消息。下面的示例图可视化了这两个步骤。

图2: GCN消息传递
如果想用更数学的方式来表述,首先需要决定如何组合节点接收到的所有信息。由于不同节点的信息数量不同,需要一个适用于任何数量的操作。因此,通常的方法是求和或取平均值。根据节点和 H ( l ) H^{(l)} H(l)的先前特征,GCN 层定义如下:
H ( l + 1 ) = σ ( D ^ − 1 / 2 A ^ D ^ − 1 / 2 H ( l ) W ( l ) ) H^{(l+1)} = \sigma\left(\hat{D}^{-1/2}\hat{A}\hat{D}^{-1/2}H^{(l)}W^{(l)}\right) H(l+1)=σ(D^−1/2A^D^−1/2H(l)W(l))
W ( l ) W^{(l)} W(l)是用于将输入特征转换为消息( H ( l ) W ( l ) H^{(l)}W^{(l)} H(l)W(l))。在邻接矩阵 A A A中,添加单位矩阵,以便每个节点也向自身发送自己的消息: A ^ = A + I \hat{A}=A+I A^=A+I。最后,为了取平均值而不是求和,计算矩阵 D ^ \hat{D} D^,它是一个对角矩阵,其中 D i i D_{ii} Dii表示节点 i i i的邻居数量。 σ \sigma σ表示任意激活函数,而不一定是sigmoid(在 GNN 中通常使用基于 ReLU 的激活函数)。
在 PyTorch 中实现 GCN 层时,可以利用张量的灵活操作。不必定义一个矩阵 D ^ \hat{D} D^,而是可以在之后将汇总的消息除以邻居的数量。此外,将权重矩阵替换为线性层,这还允许添加偏置。以 PyTorch 模块的形式编写,GCN 层定义如下:
class GCNLayer(nn.Module):
def __init__(self, c_in, c_out):
super().__init__()
self.projection = nn.Linear(c_in, c_out)
def forward(self, node_feats, adj_matrix):
"""
Inputs:
node_feats - Tensor with node features of shape [batch_size, num_nodes, c_in]
adj_matrix - Batch of adjacency matrices of the graph. If there is an edge from i to j, adj_matrix[b,i,j]=1 else 0.
Supports directed edges by non-symmetric matrices. Assumes to already have added the identity connections.
Shape: [batch_size, num_nodes, num_nodes]
"""
# 相邻边数等于传入边数
num_neighbours = adj_matrix.sum(dim=-1, keepdims=True)
node_feats = self.projection(node_feats)
node_feats = torch.bmm(adj_matrix, node_feats)
node_feats = node_feats / num_neighbours
return node_feats
为了进一步理解 GCN 层,可以将其应用于上面的示例图。首先,需要指定一些节点特征和添加了自连接的邻接矩阵:
node_feats = torch.arange(8, dtype=torch.float32).view(1, 4, 2)
adj_matrix = torch.Tensor([[[1, 1, 0, 0],
[1, 1, 1, 1],
[0, 1, 1, 1],
[0, 1, 1, 1]]])
print("Node features:\n", node_feats)
print("\nAdjacency matrix:\n", adj_matrix)
接下来,向其应用一个 GCN 层。为简化起见,将线性权重矩阵初始化为单位矩阵,以便输入特征等于消息。这可以更容易验证消息传递操作。
layer = GCNLayer(c_in=2, c_out=2)
layer.projection.weight.data = torch.Tensor([[1., 0.], [0., 1.]])
layer.projection.bias.data = torch.Tensor([0., 0.])
with torch.no_grad():
out_feats = layer(node_feats, adj_matrix)
print("Adjacency matrix", adj_matrix)
print("Input features", node_feats)
print("Output features", out_feats)
第一个节点的输出值是它自己和第二个节点的平均值。类似地,可以验证所有其他节点。然而,在图神经网络(GNN)中,也希望能允许节点之间进行特征交换,而不仅仅是其邻居之间。这可以通过应用多个图卷积网络(GCN)层来实现,从而得到图神经网络的最终布局。图神经网络可以通过一系列 GCN 层和非线性函数(如 ReLU)构建而成。
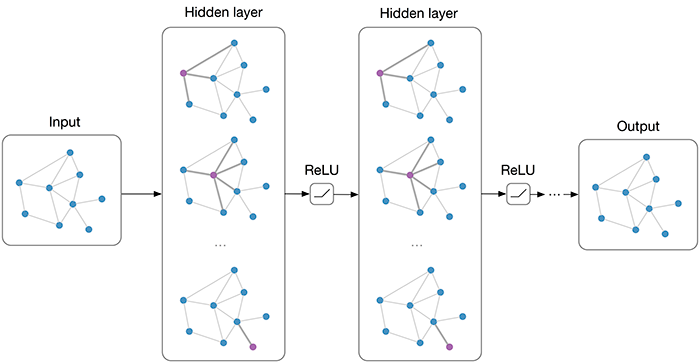
图3: 图神经网络示例
然而,从上面的例子中可以看到一个问题:节点 3 和节点 4 的输出特征相同,因为它们有相同的相邻节点(包括自身)。因此,如果只是对所有消息取平均值,GCN 层可能会使网络忘记节点特定的信息。已经提出了多种可能的改进方案。虽然最简单的选项可能是使用残差连接,但更常见的方法是要么提高自连接的权重,要么为自连接定义一个单独的权重矩阵。或者,可以重新审视注意力。
1.5 图注意力
注意力机制描述了多个元素的加权平均值,权重根据输入查询和元素键动态计算。这个概念可以类似地应用于图,其中之一是图注意力网络。类似于 GCN,图注意力层使用线性层/权重矩阵为每个节点创建消息。在注意力部分,它将节点自身的消息作为查询,将需要平均的消息作为键和值(请注意,这也包括消息本身)。评分函数 f a t t n f_{attn} fattn被实现为将查询和键映射到一个值的单层 MLP。
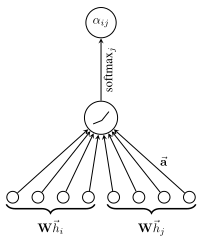
图4: MLP
h i h_i hi和 h j h_j hj分别是节点 i i i和 j j j的原始特征,代表该层的信息,权重矩阵为 W \mathbf{W} W。 a \mathbf{a} a 是 MLP 的权重矩阵,形状为 [ 1 , 2 × d message ] [1,2\times d_{\text{message}}] [1,2×dmessage], α i j \alpha_{ij} αij 是节点 i i i到 j j j的最终注意力权重。计算过程如下:
α i j = exp ( LeakyReLU ( a [ W h i ∣ ∣ W h j ] ) ) ∑ k ∈ N i exp ( LeakyReLU ( a [ W h i ∣ ∣ W h k ] ) ) \alpha_{ij} = \frac{\exp\left(\text{LeakyReLU}\left(\mathbf{a}\left[\mathbf{W}h_i||\mathbf{W}h_j\right]\right)\right)}{\sum_{k\in\mathcal{N}_i} \exp\left(\text{LeakyReLU}\left(\mathbf{a}\left[\mathbf{W}h_i||\mathbf{W}h_k\right]\right)\right)} αij=∑k∈Niexp(LeakyReLU(a[Whi∣∣Whk]))exp(LeakyReLU(a[Whi∣∣Whj]))
操作符 ∣ ∣ || ∣∣表示拼接,而 N i \mathcal{N}_i Ni表示节点 i i i的邻居索引。请注意,与常规做法不同,在对元素进行 softmax 之前应用了非线性(此处为 LeakyReLU)。虽然乍一看这似乎是一个微小的变化,但它对于注意力依赖于原始输入至关重要。具体来说,可以暂时移除非线性,尝试简化表达式:
α i j = exp ( a [ W h i ∣ ∣ W h j ] ) ∑ k ∈ N i exp ( a [ W h i ∣ ∣ W h k ] ) = exp ( a : , : d / 2 W h i + a : , d / 2 : W h j ) ∑ k ∈ N i exp ( a : , : d / 2 W h i + a : , d / 2 : W h k ) = exp ( a : , : d / 2 W h i ) ⋅ exp ( a : , d / 2 : W h j ) ∑ k ∈ N i exp ( a : , : d / 2 W h i ) ⋅ exp ( a : , d / 2 : W h k ) = exp ( a : , d / 2 : W h j ) ∑ k ∈ N i exp ( a : , d / 2 : W h k ) \begin{split} \alpha_{ij} & = \frac{\exp\left(\mathbf{a}\left[\mathbf{W}h_i||\mathbf{W}h_j\right]\right)}{\sum_{k\in\mathcal{N}_i} \exp\left(\mathbf{a}\left[\mathbf{W}h_i||\mathbf{W}h_k\right]\right)}\\[5pt] & = \frac{\exp\left(\mathbf{a}_{:,:d/2}\mathbf{W}h_i+\mathbf{a}_{:,d/2:}\mathbf{W}h_j\right)}{\sum_{k\in\mathcal{N}_i} \exp\left(\mathbf{a}_{:,:d/2}\mathbf{W}h_i+\mathbf{a}_{:,d/2:}\mathbf{W}h_k\right)}\\[5pt] & = \frac{\exp\left(\mathbf{a}_{:,:d/2}\mathbf{W}h_i\right)\cdot\exp\left(\mathbf{a}_{:,d/2:}\mathbf{W}h_j\right)}{\sum_{k\in\mathcal{N}_i} \exp\left(\mathbf{a}_{:,:d/2}\mathbf{W}h_i\right)\cdot\exp\left(\mathbf{a}_{:,d/2:}\mathbf{W}h_k\right)}\\[5pt] & = \frac{\exp\left(\mathbf{a}_{:,d/2:}\mathbf{W}h_j\right)}{\sum_{k\in\mathcal{N}_i} \exp\left(\mathbf{a}_{:,d/2:}\mathbf{W}h_k\right)}\\ \end{split} αij=∑k∈Niexp(a[Whi∣∣Whk])exp(a[Whi∣∣Whj])=∑k∈Niexp(a:,:d/2Whi+a:,d/2:Whk)exp(a:,:d/2Whi+a:,d/2:Whj)=∑k∈Niexp(a:,:d/2Whi)⋅exp(a:,d/2:Whk)exp(a:,:d/2Whi)⋅exp(a:,d/2:Whj)=∑k∈Niexp(a:,d/2:Whk)exp(a:,d/2:Whj)
可以看到,如果没有非线性, h i h_i hi的注意力项实际上会相互抵消,导致注意力与节点本身无关。因此,会遇到与 GCN 相同的问题,即对于具有相同邻居的节点创建相同的输出特征。这就是为什么 LeakyReLU 至关重要,并且为注意力添加了对 h i h_i hi的依赖。
一旦获得所有注意力因子,可以通过执行加权平均来计算每个节点的输出特征:
h i ′ = σ ( ∑ j ∈ N i α i j W h j ) h_i'=\sigma\left(\sum_{j\in\mathcal{N}_i}\alpha_{ij}\mathbf{W}h_j\right) hi′=σ j∈Ni∑αijWhj
σ \sigma σ是另一种非线性,类似于 GCN 层。在视觉上,可以将注意力层中的完整消息传递表示如下:
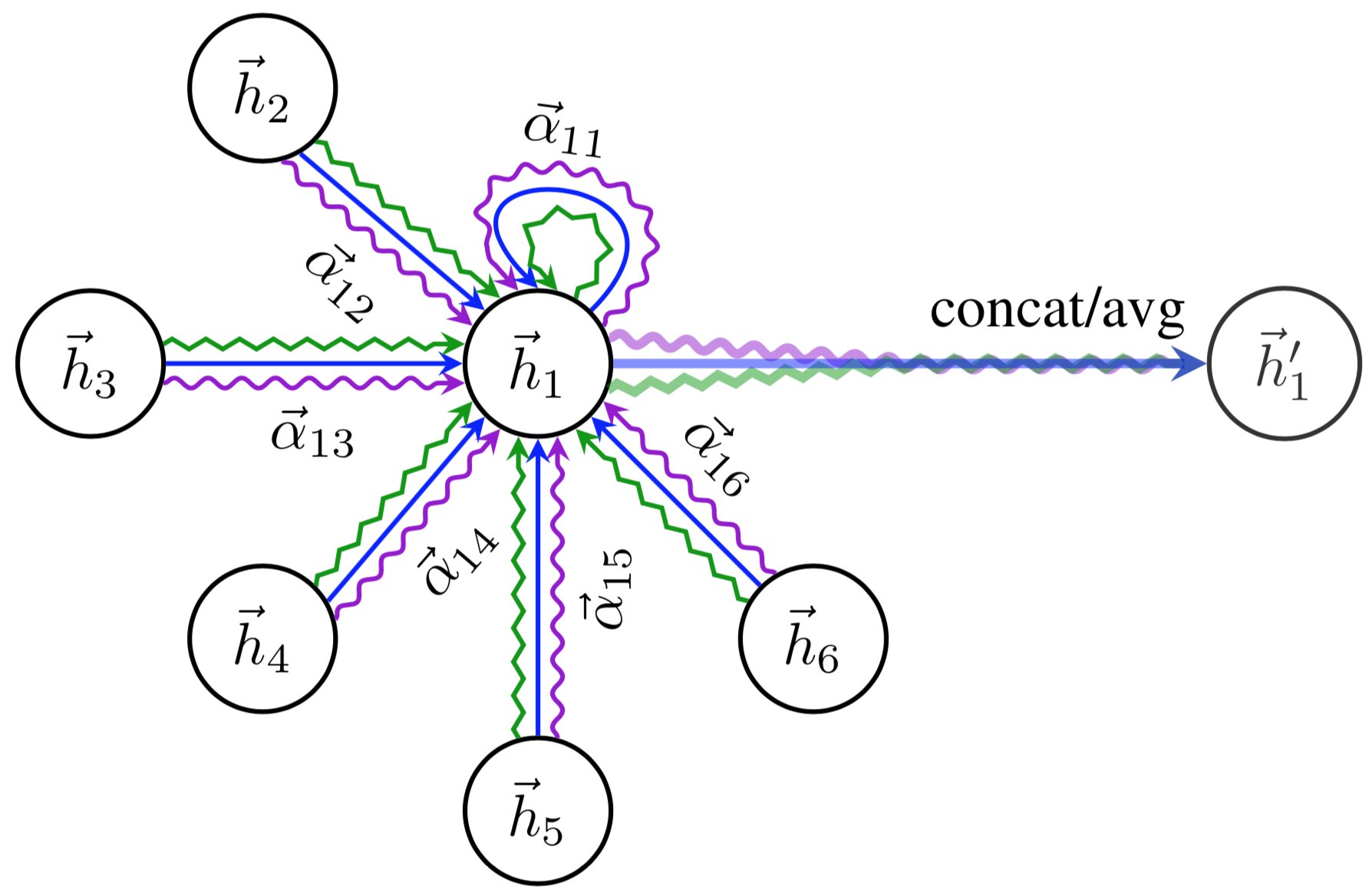
图5: 注意力层消息传递
为了提高图注意力网络的表达能力,类似于 Transformer 中的多头注意力模块。这导致 N N N注意力层并行应用。在上述图像中,它被可视化为三种不同颜色的箭头(绿色、蓝色和紫色),之后被连接在一起。平均值仅在网络的最终预测层应用。
在详细讨论了图注意力层之后,可以在下面实现它:
class GATLayer(nn.Module):
def __init__(self, c_in, c_out, num_heads=1, concat_heads=True, alpha=0.2):
"""
Inputs:
c_in - Dimensionality of input features
c_out - Dimensionality of output features
num_heads - Number of heads, i.e. attention mechanisms to apply in parallel. The
output features are equally split up over the heads if concat_heads=True.
concat_heads - If True, the output of the different heads is concatenated instead of averaged.
alpha - Negative slope of the LeakyReLU activation.
"""
super().__init__()
self.num_heads = num_heads
self.concat_heads = concat_heads
if self.concat_heads:
assert c_out % num_heads == 0, "Number of output features must be a multiple of the count of heads."
c_out = c_out // num_heads
# 层中所需的子模块和参数
self.projection = nn.Linear(c_in, c_out * num_heads)
self.a = nn.Parameter(torch.Tensor(num_heads, 2 * c_out))
self.leakyrelu = nn.LeakyReLU(alpha)
# 从原始实现进行初始化
nn.init.xavier_uniform_(self.projection.weight.data, gain=1.414)
nn.init.xavier_uniform_(self.a.data, gain=1.414)
def forward(self, node_feats, adj_matrix, print_attn_probs=False):
"""
Inputs:
node_feats - Input features of the node. Shape: [batch_size, c_in]
adj_matrix - Adjacency matrix including self-connections. Shape: [batch_size, num_nodes, num_nodes]
print_attn_probs - If True, the attention weights are printed during the forward pass (for debugging purposes)
"""
batch_size, num_nodes = node_feats.size(0), node_feats.size(1)
# 应用线性图层并按头部对节点进行排序
node_feats = self.projection(node_feats)
node_feats = node_feats.view(batch_size, num_nodes, self.num_heads, -1)
edges = adj_matrix.nonzero(as_tuple=False) # 返回邻接矩阵不为 0的索引
node_feats_flat = node_feats.view(batch_size * num_nodes, self.num_heads, -1)
edge_indices_row = edges[:,0] * num_nodes + edges[:,1]
edge_indices_col = edges[:,0] * num_nodes + edges[:,2]
a_input = torch.cat([
torch.index_select(input=node_feats_flat, index=edge_indices_row, dim=0),
torch.index_select(input=node_feats_flat, index=edge_indices_col, dim=0)
], dim=-1) # Index select 返回一个张量,其中 node_feats_flat 沿 dim=0 在所需位置进行索引
attn_logits = torch.einsum('bhc,hc->bh', a_input, self.a)
attn_logits = self.leakyrelu(attn_logits)
# 将注意力值列表映射回矩阵
attn_matrix = attn_logits.new_zeros(adj_matrix.shape+(self.num_heads,)).fill_(-9e15)
attn_matrix[adj_matrix[...,None].repeat(1,1,1,self.num_heads) == 1] = attn_logits.reshape(-1)
attn_probs = F.softmax(attn_matrix, dim=2)
if print_attn_probs:
print("Attention probs\n", attn_probs.permute(0, 3, 1, 2))
node_feats = torch.einsum('bijh,bjhc->bihc', attn_probs, node_feats)
if self.concat_heads:
node_feats = node_feats.reshape(batch_size, num_nodes, -1)
else:
node_feats = node_feats.mean(dim=2)
return node_feats
接下来可以将图注意力层应用于上面示例图,以更好地理解其动态。与之前一样,输入层被初始化为单位矩阵,但设置 a \mathbf{a} a为任意数的向量以获得不同的注意力值。可以使用两个头(heads)来展示层中并行、独立的注意力机制。
layer = GATLayer(2, 2, num_heads=2)
layer.projection.weight.data = torch.Tensor([[1., 0.], [0., 1.]])
layer.projection.bias.data = torch.Tensor([0., 0.])
layer.a.data = torch.Tensor([[-0.2, 0.3], [0.1, -0.1]])
with torch.no_grad():
out_feats = layer(node_feats, adj_matrix, print_attn_probs=True)
print("Adjacency matrix", adj_matrix)
print("Input features", node_feats)
print("Output features", out_feats)
建议学员自己尝试计算至少一个头和一个节点的注意力矩阵。在和 i i i以及和 j j j之间不存在边的地方,条目为 0。对于其他情况,能看到一系列不同的注意力概率。此外,尽管节点3和4有相同的邻居,但它们的输出特征现在不同。
1.6 PyTorch Geometric
使用邻接矩阵实现图网络简单直接,但对于大型图来说可能计算成本很高。许多现实世界的图可以超过 20 万个节点,基于邻接矩阵的实现会失败。在实现 GNN 时有很多优化方法,幸运的是,存在提供这些层的包。PyTorch 中最流行的包是 PyTorch Geometric 和深度图库(后者实际上是框架无关的)。选择哪个取决于你计划的项目和个人喜好。在这个实验中,将作为 PyTorch 家族的一部分来看 PyTorch Geometric。
import torch_geometric
import torch_geometric.nn as geom_nn
import torch_geometric.data as geom_data
PyTorch Geometric提供了一套常见的图层,包括上面实现的 GCN 和 GAT 层。此外,类似于 PyTorch 的 torchvision,它还提供了常见的图数据集及其上的变换,以简化训练。与上面的实现相比,PyTorch Geometric 使用索引对列表来表示边。
在以下任务中,为能够从多种图层中进行选择。因此,再次定义一个字典,以便使用字符串来访问这些图层:
gnn_layer_by_name = {
"GCN": geom_nn.GCNConv,
"GAT": geom_nn.GATConv,
"GraphConv": geom_nn.GraphConv
}
除了 GCN 和 GAT,还添加了层 geom_nn.GraphConv。GraphConv 是一个具有独立自连接权重矩阵的 GCN。数学上,这可以表示为:
x i ( l + 1 ) = W 1 ( l + 1 ) x i ( l ) + W 2 ( ℓ + 1 ) ∑ j ∈ N i x j ( l ) \mathbf{x}_i^{(l+1)} = \mathbf{W}^{(l + 1)}_1 \mathbf{x}_i^{(l)} + \mathbf{W}^{(\ell + 1)}_2 \sum_{j \in \mathcal{N}_i} \mathbf{x}_j^{(l)} xi(l+1)=W1(l+1)xi(l)+W2(ℓ+1)j∈Ni∑xj(l)
在这个公式中,邻居节点的消息是相加而不是取平均。然而,PyTorch Geometric 提供了参数aggr来在求和、取平均和最大池化之间切换。
1.7 关于图结构的实验
在图结构数据上的任务可以分为三类:节点级、边级和图级。下面将更详细地讨论这三种类型。
1.7.1 节点级任务:半监督节点分类
节点级任务的目标是对图中的节点进行分类。通常,有一个包含超过 1000 个节点的单个大型图,其中一定数量的节点被标记。在训练过程中学习对这些标记样本进行分类,并尝试推广到未标记的节点。
在本课程中,将使用一个流行的例子——Cora 数据集。Cora 包含 2708 篇科学出版物,它们之间的链接表示一篇论文对另一篇论文的引用。任务是将每篇出版物分类到七个类别中的一个。每篇出版物都由一个词袋向量表示。这意味着每篇出版物都有一个包含 1433 个元素的向量,其中特征 𝑖 中的 1 表示预定义字典中的第 𝑖 个词出现在文章中。当需要非常简单的编码,并且已经对网络中可能出现的词有直观理解时,通常使用二进制词袋表示。
下面将加载数据集:
import torch
from torch_geometric.data import Data
# 假设你已经有了以下文件:cora.x, cora.y, cora.edge_index
x = DATASET_PATH + '/Cora/ind.cora.x'
y = DATASET_PATH + '/Cora/ind.cora.y'
edge_index = DATASET_PATH + '/Cora/ind.cora.test.index'
# 创建一个 Data 对象
cora_dataset = Data(x=x, y=y, edge_index=edge_index)
# 现在可以像使用任何 torch_geometric.data.Dataset 返回的对象一样使用这个 data 对象
cora_dataset = torch_geometric.datasets.Planetoid(root=DATASET_PATH ,name="Cora")
下面将展示PyTorch Geometric如何表示图数据。请注意,尽管只有一个图,但 PyTorch Geometric 会返回一个数据集,以与其他数据集保持兼容性。
cora_dataset[0]
图由一个Data对象表示,可以像标准 Python 命名空间一样访问它。边索引张量是图中边的列表,并且对于无向图,它包含每条边的镜像版本。train_mask, val_mask和test_mask是布尔掩码,指示应该使用哪些节点进行训练、验证和测试。x张量是2708篇出版物的特征张量,而y是所有节点的标签。
在查看数据后,可以实现一个简单的图神经网络。图神经网络应用一系列图层(GCN、GAT 或 GraphConv),ReLU 作为激活函数,并使用 dropout 进行正则化。
class GNNModel(nn.Module):
def __init__(self, c_in, c_hidden, c_out, num_layers=2, layer_name="GCN", dp_rate=0.1, **kwargs):
"""
Inputs:
c_in - Dimension of input features
c_hidden - Dimension of hidden features
c_out - Dimension of the output features. Usually number of classes in classification
num_layers - Number of "hidden" graph layers
layer_name - String of the graph layer to use
dp_rate - Dropout rate to apply throughout the network
kwargs - Additional arguments for the graph layer (e.g. number of heads for GAT)
"""
super().__init__()
gnn_layer = gnn_layer_by_name[layer_name]
layers = []
in_channels, out_channels = c_in, c_hidden
for l_idx in range(num_layers-1):
layers += [
gnn_layer(in_channels=in_channels,
out_channels=out_channels,
**kwargs),
nn.ReLU(inplace=True),
nn.Dropout(dp_rate)
]
in_channels = c_hidden
layers += [gnn_layer(in_channels=in_channels,
out_channels=c_out,
**kwargs)]
self.layers = nn.ModuleList(layers)
def forward(self, x, edge_index):
"""
Inputs:
x - Input features per node
edge_index - List of vertex index pairs representing the edges in the graph (PyTorch geometric notation)
"""
for l in self.layers:
# 对于图层,需要添加 “edge_index” 张量作为附加输入
# 所有 PyTorch 几何图层都继承了 “MessagePassing” 类,因此
# 可以简单地检查类类型。
if isinstance(l, geom_nn.MessagePassing):
x = l(x, edge_index)
else:
x = l(x)
return x
在节点级任务中,好的做法是为每个节点独立创建一个 MLP 基线模型。这样就能验证是否将图信息添加到模型中确实能提高预测效果,或者并非如此。也可能每个节点的特征已经足够表达,能够明确指向特定类别。为了检查这一点,下面实现了一个简单的 MLP。
class MLPModel(nn.Module):
def __init__(self, c_in, c_hidden, c_out, num_layers=2, dp_rate=0.1):
"""
Inputs:
c_in - Dimension of input features
c_hidden - Dimension of hidden features
c_out - Dimension of the output features. Usually number of classes in classification
num_layers - Number of hidden layers
dp_rate - Dropout rate to apply throughout the network
"""
super().__init__()
layers = []
in_channels, out_channels = c_in, c_hidden
for l_idx in range(num_layers-1):
layers += [
nn.Linear(in_channels, out_channels),
nn.ReLU(inplace=True),
nn.Dropout(dp_rate)
]
in_channels = c_hidden
layers += [nn.Linear(in_channels, c_out)]
self.layers = nn.Sequential(*layers)
def forward(self, x, *args, **kwargs):
"""
Inputs:
x - Input features per node
"""
return self.layers(x)
最后,可以将模型合并为一个 PyTorch Lightning 模块,该模块将处理训练、验证和测试。
class NodeLevelGNN(pl.LightningModule):
def __init__(self, model_name, **model_kwargs):
super().__init__()
# 保存超参数
self.save_hyperparameters()
if model_name == "MLP":
self.model = MLPModel(**model_kwargs)
else:
self.model = GNNModel(**model_kwargs)
self.loss_module = nn.CrossEntropyLoss()
def forward(self, data, mode="train"):
x, edge_index = data.x, data.edge_index
x = self.model(x, edge_index)
# 仅计算与掩码对应的节点上的损失
if mode == "train":
mask = data.train_mask
elif mode == "val":
mask = data.val_mask
elif mode == "test":
mask = data.test_mask
else:
assert False, f"Unknown forward mode: {mode}"
loss = self.loss_module(x[mask], data.y[mask])
acc = (x[mask].argmax(dim=-1) == data.y[mask]).sum().float() / mask.sum()
return loss, acc
def configure_optimizers(self):
# 在这里使用 SGD,但 Adam 也有效
optimizer = optim.SGD(self.parameters(), lr=0.1, momentum=0.9, weight_decay=2e-3)
return optimizer
def training_step(self, batch, batch_idx):
loss, acc = self.forward(batch, mode="train")
self.log('train_loss', loss)
self.log('train_acc', acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self.forward(batch, mode="val")
self.log('val_acc', acc)
def test_step(self, batch, batch_idx):
_, acc = self.forward(batch, mode="test")
self.log('test_acc', acc)
除了 Lightning 模块,下面定义了一个训练函数。由于只有一个图,因此数据加载器使用1的批处理大小,并且训练、验证和测试集共享同一个数据加载器(掩码在 Lightning 模块内部选择)。此外,将参数enable_progress_bar设置为 False,因为它通常显示每个 epoch 的进度,但一个 epoch 只包含一个步骤。
def train_node_classifier(model_name, dataset, **model_kwargs):
pl.seed_everything(42)
node_data_loader = geom_data.DataLoader(dataset, batch_size=1)
root_dir = os.path.join(CHECKPOINT_PATH, "NodeLevel" + model_name)
print("device: ", device)
os.makedirs(root_dir, exist_ok=True)
trainer = pl.Trainer(default_root_dir=root_dir,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc")],
accelerator="npu" if str(device).startswith("npu:0") else "cpu",
devices=[0],
max_epochs=200,
enable_progress_bar=False) # False,因为 epoch 大小为 1
trainer.logger._default_hp_metric = None # 不需要的可选 logging 参数
pretrained_filename = os.path.join(CHECKPOINT_PATH, f"NodeLevel{model_name}.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model, loading...")
print("pretrained_filename: ", pretrained_filename)
model = NodeLevelGNN.load_from_checkpoint(pretrained_filename).to(device)
print("NodeLevelMLP finish!")
else:
pl.seed_everything()
model = NodeLevelGNN(model_name=model_name, c_in=dataset.num_node_features, c_out=dataset.num_classes, **model_kwargs)
trainer.fit(model, node_data_loader, node_data_loader)
model = NodeLevelGNN.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
test_result = trainer.test(model, node_data_loader, verbose=False)
batch = next(iter(node_data_loader))
batch = batch.to(model.device)
_, train_acc = model.forward(batch, mode="train")
_, val_acc = model.forward(batch, mode="val")
result = {"train": train_acc,
"val": val_acc,
"test": test_result[0]['test_acc']}
return model, result
OR CPU python命令行方式:
# CPU版
def train_node_classifier(model_name, dataset, **model_kwargs):
pl.seed_everything(42)
# 兼容新旧版本的 DataLoader
try:
node_data_loader = geom_data.loader.DataLoader(dataset, batch_size=1)
except AttributeError:
node_data_loader = geom_data.DataLoader(dataset, batch_size=1)
root_dir = os.path.join(CHECKPOINT_PATH, "NodeLevel" + model_name)
print("device: cpu") # 明确使用 CPU
os.makedirs(root_dir, exist_ok=True)
# 完全基于 CPU 配置 Trainer,不涉及 MPS
trainer = pl.Trainer(
default_root_dir=root_dir,
accelerator="cpu", # 强制 CPU
devices="auto", # 自动使用所有 CPU 核心
max_epochs=200,
strategy="auto", # CPU 模式下自动选择策略
enable_progress_bar=False
)
pretrained_filename = os.path.join(CHECKPOINT_PATH, f"NodeLevel{model_name}.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model, loading...")
model = NodeLevelGNN.load_from_checkpoint(pretrained_filename).to("cpu") # 模型到 CPU
else:
pl.seed_everything()
model = NodeLevelGNN(
model_name=model_name,
c_in=dataset.num_node_features,
c_out=dataset.num_classes,** model_kwargs
).to("cpu") # 模型到 CPU
# 训练数据也保持在 CPU
trainer.fit(model, node_data_loader, node_data_loader)
model = NodeLevelGNN.load_from_checkpoint(
trainer.checkpoint_callback.best_model_path
).to("cpu")
# 测试阶段同样使用 CPU
test_result = trainer.test(model, node_data_loader, verbose=False)
batch = next(iter(node_data_loader)).to("cpu")
_, train_acc = model.forward(batch, mode="train")
_, val_acc = model.forward(batch, mode="val")
result = {
"train": train_acc,
"val": val_acc,
"test": test_result[0]['test_acc']
}
return model, result
最后,可以训练模型。首先,先训练简单的 MLP:
# 打印测试分数
def print_results(result_dict):
if "train" in result_dict:
print(f"Train accuracy: {(100.0*result_dict['train']):4.2f}%")
if "val" in result_dict:
print(f"Val accuracy: {(100.0*result_dict['val']):4.2f}%")
print(f"Test accuracy: {(100.0*result_dict['test']):4.2f}%")
node_mlp_model, node_mlp_result = train_node_classifier(model_name="MLP",
dataset=cora_dataset,
c_hidden=16,
num_layers=2,
dp_rate=0.1)
print_results(node_mlp_result)
Out:
Train accuracy: 100.00%
Val accuracy: 52.00%
Test accuracy: 59.40%
尽管由于高维输入特征 MLP 可能会在训练数据集上过拟合,但它在对测试集的表现并不太好。可以查看本课程所使用的图网络能否超越这个分数:
node_gnn_model, node_gnn_result = train_node_classifier(model_name="GNN",
layer_name="GCN",
dataset=cora_dataset,
c_hidden=16,
num_layers=2,
dp_rate=0.1)
print_results(node_gnn_result)
Train accuracy: 99.29%
Val accuracy: 76.80%
Test accuracy: 81.10%
正如所期望的,GNN 模型在 MLP 上取得了显著的性能优势。这表明使用图信息确实提高了预测能力,并且能够更好地泛化。
模型中的超参数已被选择以创建一个相对较小的网络。这是因为输入维度为 1433 的第一层对于大型图来说可能相对昂贵。通常,GNN 对于非常大的图可能会变得相对昂贵。这就是为什么这类 GNN 要么具有较小的隐藏大小,要么使用特殊的批处理策略,其中从原始的大图中采样一个连通子图。
1.7.2 边缘级任务:链接预测
在某些应用中,可能需要在边缘级别而不是节点级别进行预测。图神经网络中最常见的边缘级别任务是链接预测。链接预测是指给定一个图,想要预测两个节点之间是否存在/应该存在一条边。图级别信息对于执行这项任务至关重要。预测输出通常通过对节点特征对进行相似度度量来完成,如果应该存在链接,则结果为 1,否则接近 0。
1.7.3 图级任务:图分类
最后,在本课程的这一部分,将更详细地探讨如何将 GNN 应用于图分类任务。目标是分类整个图,而不是单个节点或边。因此,也获得了一个包含多个图的数据集,需要根据一些结构图属性对其进行分类。图分类最常见的任务是分子性质预测,其中分子被表示为图。每个原子连接到一个节点,图中的边是原子之间的键。例如,看看下面的图。
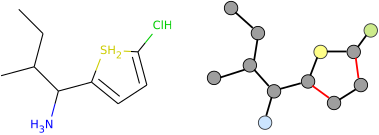
图6: 分子结构图和分子结构图表示
左侧是一个任意的、小分子,包含不同的原子,而图像的右侧显示了图的表示。原子类型被抽象为节点特征(例如一个 one-hot 向量),不同的键类型被用作边特征。
下面将使用的数据集称为 MUTAG 数据集。它是一个常见的图分类算法的小型基准,每个图平均包含 188 个图,每个图有 18 个节点和 20 条边。图节点有 7 种不同的标签/原子类型,二进制图标签表示“它们对特定革兰氏阴性细菌的致突变效应”(标签的具体含义在这里并不重要)。该数据集是名为TUDatasets的大型不同图分类数据集集合的一部分,可以通过 PyTorch Geometric 中的torch_geometric.datasets.TUDataset访问。可以在下面加载该数据集。
tu_dataset = torch_geometric.datasets.TUDataset(root=DATASET_PATH, name="MUTAG")
以下代码块查看有关数据集的统计数据:
print("Data object:", tu_dataset.data)
print("Length:", len(tu_dataset))
print(f"Average label: {tu_dataset.data.y.float().mean().item():4.2f}")
out:
Data object: Data(x=[3371, 7], edge_index=[2, 7442], edge_attr=[7442, 4], y=[188])
Length: 188
Average label: 0.66
第一行展示了数据集如何存储不同的图。每个图的节点、边和标签被连接成一个张量,数据集存储了相应张量分割的索引。数据集的长度是拥有的图的数量,"平均标签"表示标签为 1 的图的比例。只要比例在 0.5 的范围内,就有相对平衡的数据集。图数据集非常不平衡的情况很常见,因此检查类别平衡总是个好主意。
接下来,将数据集分成训练集和测试集。请注意,由于数据集规模较小,这次不使用验证集。因此,模型可能会因为评估的噪声在验证集上略微过拟合,但仍然可以得到未经训练数据的性能估计。
torch.manual_seed(42)
tu_dataset.shuffle()
train_dataset = tu_dataset[:150]
test_dataset = tu_dataset[150:]
在使用数据加载器时,本课程遇到一个关于批处理 N N N图的问题。批次中的每个图可以有不同的节点数和边数,因此需要大量的填充才能得到一个单一的张量。Torch geometric 使用了一种不同且更高效的方法:可以将批次中的 N N N图视为一个具有连接的节点和边列表的大型图。由于这些图之间没有边,在大型图上运行 GNN 层与分别在每个图上运行 GNN 得到的输出相同。
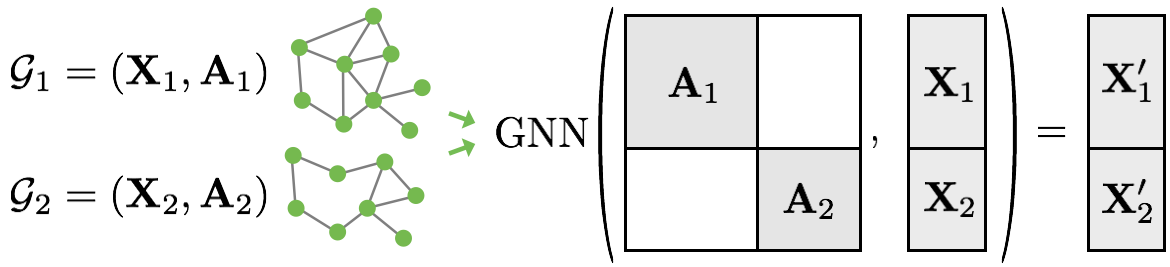
图7: 𝑁图批处理策略
对于来自不同图中的节点,邻接矩阵为零,否则根据单个图的邻接矩阵。幸运的是,这种策略已经在 torch geometric 中实现,因此可以使用相应的数据加载器:
graph_train_loader = geom_data.DataLoader(train_dataset, batch_size=64, shuffle=True)
graph_val_loader = geom_data.DataLoader(test_dataset, batch_size=64)
graph_test_loader = geom_data.DataLoader(test_dataset, batch_size=64)
以下代码加载一批数据来观察批处理的效果:
batch = next(iter(graph_test_loader))
print("Batch:", batch)
print("Labels:", batch.y[:10])
print("Batch indices:", batch.batch[:40])
out:
Batch: DataBatch(edge_index=[2, 1512], x=[687, 7], edge_attr=[1512, 4], y=[38], batch=[687], ptr=[39])
Labels: tensor([1, 1, 1, 0, 0, 0, 1, 1, 1, 0])
Batch indices: tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2])
测试数据集有 38 个图堆叠在一起。存储在batch中的批次索引显示,前 12 个节点属于第一个图,接下来的 22 个节点属于第二个图,以此类推。这些索引对于执行最终预测非常重要。要对整个图进行预测,通常在运行 GNN 模型后对所有节点执行池化操作。在这种情况下,将使用平均池化。因此,需要知道哪些节点应该包含在哪个平均池中。使用这种池化方法,就可以创建下面的图网络。具体来说,可以重用之前的类GNNModel,并简单地添加一个平均池化和一个线性层来完成图预测任务。
class GraphGNNModel(nn.Module):
def __init__(self, c_in, c_hidden, c_out, dp_rate_linear=0.5, **kwargs):
"""
Inputs:
c_in - Dimension of input features
c_hidden - Dimension of hidden features
c_out - Dimension of output features (usually number of classes)
dp_rate_linear - Dropout rate before the linear layer (usually much higher than inside the GNN)
kwargs - Additional arguments for the GNNModel object
"""
super().__init__()
print(f"c_hidden feature shape:", c_hidden)
print(f"c_out feature shape:", c_out)
self.GNN = GNNModel(c_in=c_in,
c_hidden=c_hidden,
c_out=c_hidden, # 还不是预测输出!
**kwargs)
self.head = nn.Sequential(
nn.Dropout(dp_rate_linear),
nn.Linear(c_hidden, c_out)
)
def forward(self, x, edge_index, batch_idx):
"""
Inputs:
x - Input features per node
edge_index - List of vertex index pairs representing the edges in the graph (PyTorch geometric notation)
batch_idx - Index of batch element for each node
"""
x = self.GNN(x, edge_index)
x = geom_nn.global_mean_pool(x, batch_idx) # 平均池化
print(f"Input feature shape: {x.shape}")
x = self.head(x)
print(f"Output shape: {x.shape}")
return x
最后,可以创建一个 PyTorch Lightning 模块来处理训练。它与之前看到的模块类似,在训练方面并没有什么出奇之处。由于本课程有一个二元分类任务,因此使用二元交叉熵损失。
class GraphLevelGNN(pl.LightningModule):
def __init__(self, **model_kwargs):
super().__init__()
self.save_hyperparameters()
self.model = GraphGNNModel(**model_kwargs)
self.loss_module = nn.BCEWithLogitsLoss() if self.hparams.c_out == 1 else nn.CrossEntropyLoss()
def forward(self, data, mode="train"):
x, edge_index, batch_idx = data.x, data.edge_index, data.batch
x = self.model(x, edge_index, batch_idx)
x = x.squeeze(dim=-1)
if self.hparams.c_out == 1:
preds = (x > 0).float()
data.y = data.y.float()
else:
preds = x.argmax(dim=-1)
loss = self.loss_module(x, data.y)
acc = (preds == data.y).sum().float() / preds.shape[0]
return loss, acc
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(), lr=1e-2, weight_decay=0.0)
return optimizer
def training_step(self, batch, batch_idx):
loss, acc = self.forward(batch, mode="train")
self.log('train_loss', loss)
self.log('train_acc', acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self.forward(batch, mode="val")
self.log('val_acc', acc)
def test_step(self, batch, batch_idx):
_, acc = self.forward(batch, mode="test")
self.log('test_acc', acc)
下面在数据集上训练模型。它类似于之前看到的典型训练函数。
- NPU方式
def train_graph_classifier(model_name, **model_kwargs):
pl.seed_everything(42)
root_dir = os.path.join(CHECKPOINT_PATH, "GraphLevel" + model_name)
os.makedirs(root_dir, exist_ok=True)
trainer = pl.Trainer(default_root_dir=root_dir,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc")],
accelerator="npu" if str(device).startswith("npu:0") else "cpu",
devices=[0],
max_epochs=500,
enable_progress_bar=False)
trainer.logger._default_hp_metric = None # 不需要的可选 logging 参数
pretrained_filename = os.path.join(CHECKPOINT_PATH, f"GraphLevel{model_name}.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model, loading...")
print("pretrained_filename: ", pretrained_filename)
model = GraphLevelGNN.load_from_checkpoint(pretrained_filename).to(device)
else:
pl.seed_everything(42)
model = GraphLevelGNN(c_in=tu_dataset.num_node_features,
c_out=1 if tu_dataset.num_classes==2 else tu_dataset.num_classes,
**model_kwargs)
trainer.fit(model, graph_train_loader, graph_val_loader)
model = GraphLevelGNN.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
print("device: ", device)
train_result = trainer.test(model, graph_train_loader, verbose=False)
test_result = trainer.test(model, graph_test_loader, verbose=False)
result = {"test": test_result[0]['test_acc'], "train": train_result[0]['test_acc']}
return model, result
- OR 用CPU:
def train_graph_classifier(model_name, **model_kwargs):
pl.seed_everything(42)
root_dir = os.path.join(CHECKPOINT_PATH, "GraphLevel" + model_name)
os.makedirs(root_dir, exist_ok=True)
trainer = pl.Trainer(
default_root_dir=root_dir,
accelerator="cpu", # 强制 CPU
devices="auto", # 自动使用所有 CPU 核心
max_epochs=500,
strategy="auto", # CPU 模式下自动选择策略
enable_progress_bar=False
)
trainer.logger._default_hp_metric = None # 不需要的可选 logging 参数
pretrained_filename = os.path.join(CHECKPOINT_PATH, f"GraphLevel{model_name}.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model, loading...")
print("pretrained_filename: ", pretrained_filename)
model = GraphLevelGNN.load_from_checkpoint(pretrained_filename).to(device)
else:
pl.seed_everything(42)
model = GraphLevelGNN(c_in=tu_dataset.num_node_features,
c_out=1 if tu_dataset.num_classes==2 else tu_dataset.num_classes,
**model_kwargs)
trainer.fit(model, graph_train_loader, graph_val_loader)
model = GraphLevelGNN.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
print("device: ", device)
train_result = trainer.test(model, graph_train_loader, verbose=False)
test_result = trainer.test(model, graph_test_loader, verbose=False)
result = {"test": test_result[0]['test_acc'], "train": train_result[0]['test_acc']}
return model, result
最后,进行训练和测试。可以自由尝试不同的 GNN 层、超参数等。
model, result = train_graph_classifier(model_name="GraphConv",
c_hidden=256,
layer_name="GraphConv",
num_layers=3,
dp_rate_linear=0.5,
dp_rate=0.0)
print(f"Train performance: {100.0*result['train']:4.2f}%")
print(f"Test performance: {100.0*result['test']:4.2f}%")
out:
Train performance: 96.40%
Test performance: 84.21%
Test performance: 84.21%
测试性能表明在数据集的未见过部分获得了相当不错的分数。需要注意的是,由于一直使用测试集进行验证,可能对这个集合并略微过拟合了。尽管如此,实验表明 GNNs 确实能够有效地预测图和/或分子的性质。
1.8 结论
在这个实验中,可以看到神经网络在图结构中的应用。本课程研究了图如何表示(邻接矩阵或边列表),并讨论了常见图层的实现:GCN 和 GAT。这些实现展示了图层的实际应用,通常比理论更容易。最后,尝试了不同任务,包括节点级、边级和图级。总的来说,发现将图信息纳入预测对于实现高性能至关重要。有很多应用可以从 GNN 中受益,并且这些网络的重要性在未来几年可能会增加。
- PyTorch基础与异或问题实践
- 激活函数与神经网络优化
- 数据预处理与模型优化:FashionMNIST实验
- 经典CNN架构与PyTorch Lightning实践
- Transformers与多头注意力机制实战
- 深度能量模型与PyTorch实践
- 图神经网络
- 自编码器与神经网络应用
- 深度归一化流图像建模与实践
- 自回归图像建模与像素CNN实现
- Vision Transformers with PyTorch Lightning on昇腾
- ProtoNet与ProtoMAML元学习算法实践
- SimCLR与Logistic回归在自我监督学习中的应用

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 18
18 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)