刘二大人-Pytorch深度学习实践-反向传播-笔记与作业04
反向梯度传播算法
上述的全连接神经网络,有好几百个权重,如果每个都采用先写解析式是很困难的,而且每层之间都是复合函数,这是个相当复杂的工作量。
故此考虑,把这样一个复杂的神经网络,看作一个图,通过图来传播梯度,根据链式法则求取梯度,这就叫反向梯度传播算法。
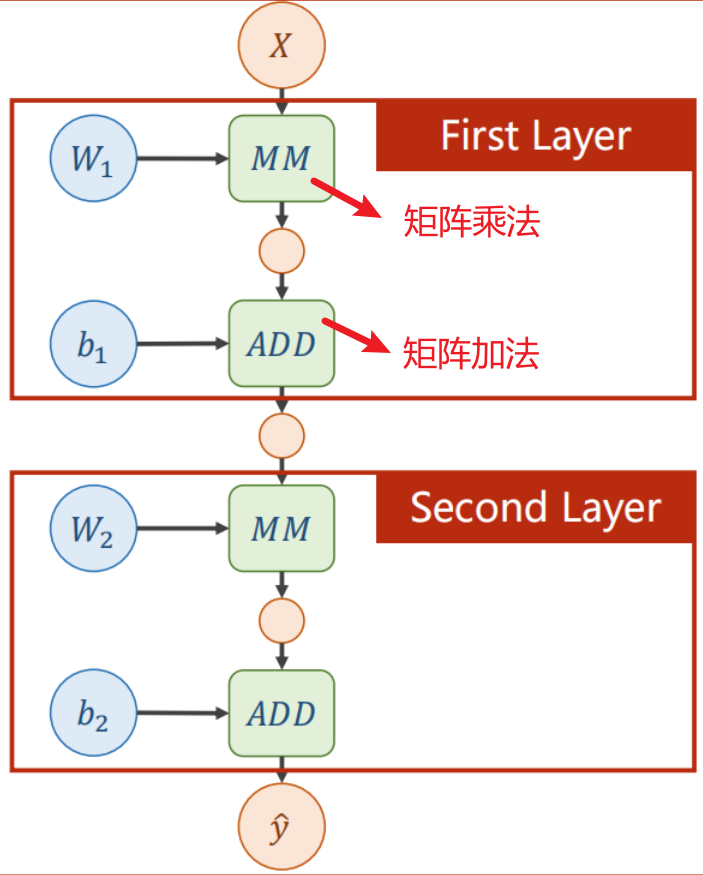
两层简单图
-
每一层的结构都是一样的
-
权重矩阵 W 与输入矩阵相乘,得到一个新的矩阵
-
新的矩阵与偏置值矩阵 b 相加,得到输出结果
-
当前层的输出作为下一层的输入
-
最终得到预测解析式,类似于迭代套娃

-
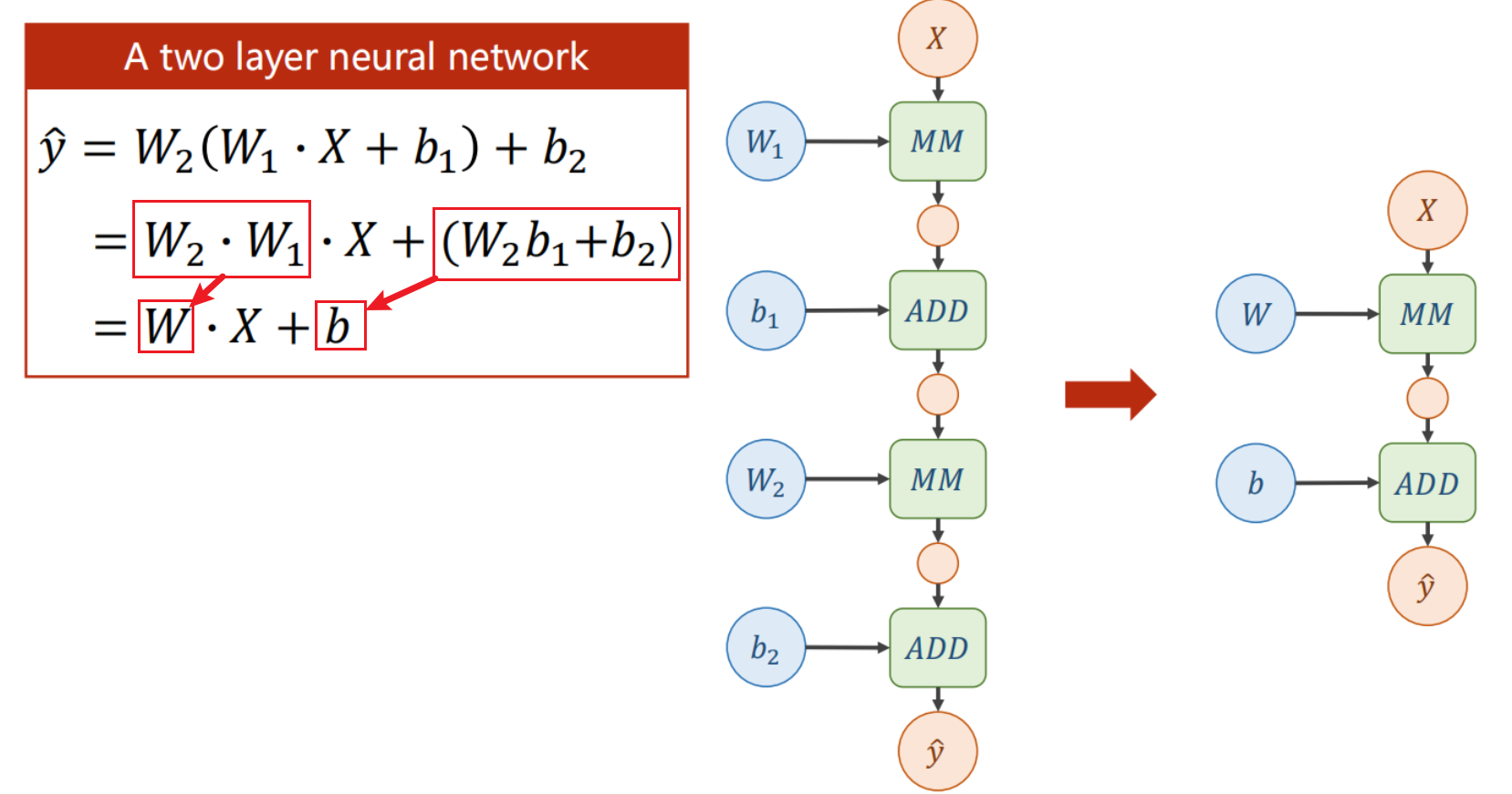
但是这样建立模型会有一个问题,因为不管你套娃多少层,都可以通过计算展开成单层模型的样子(又回到最初的起点),不管多少层都变成单一线性的,如下图
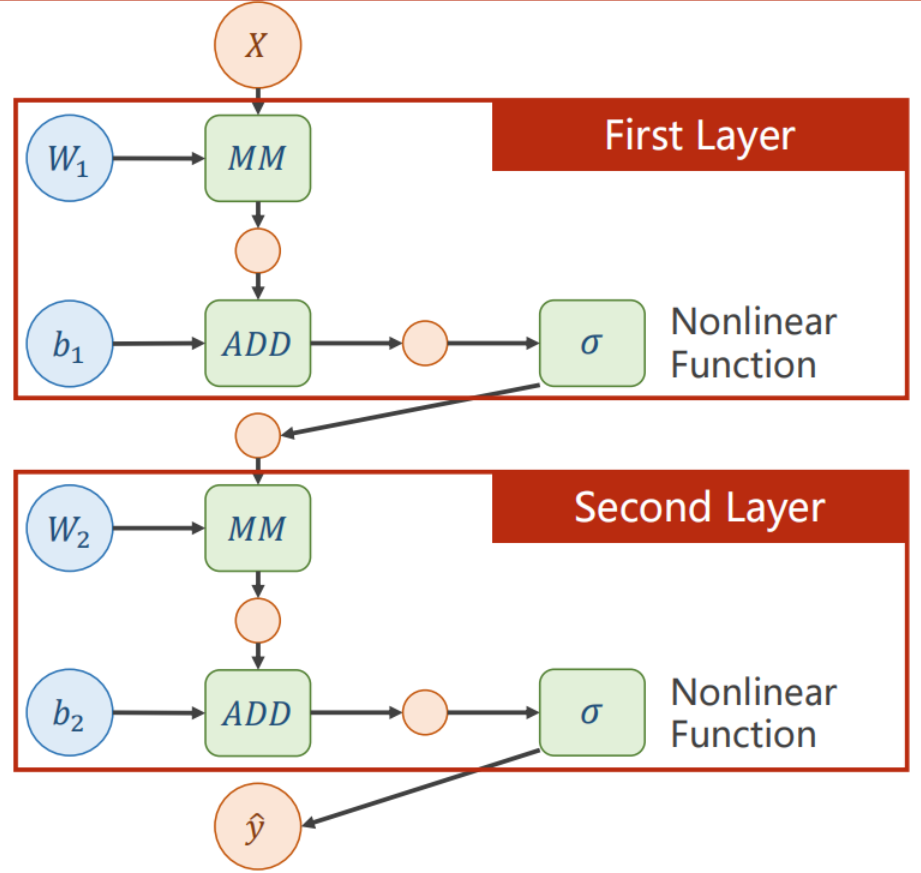
激活函数
-
解决方法也很简单,即在每一层的输入之前,对上一层的输出加上一个非线性的变化函数,整个函数也叫做激活函数,这样就不能对迭代式子进行展开了
手算最小简单图
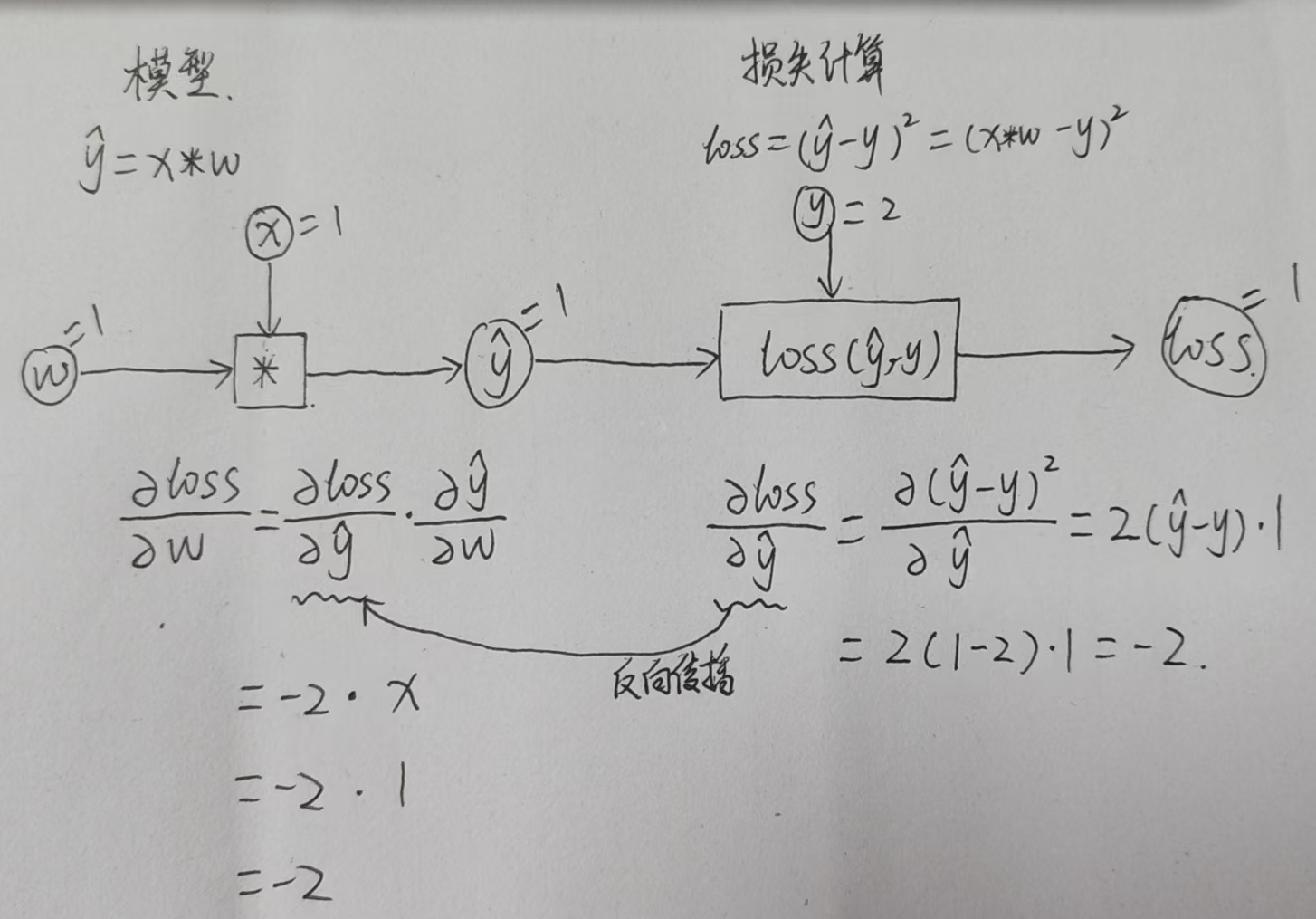
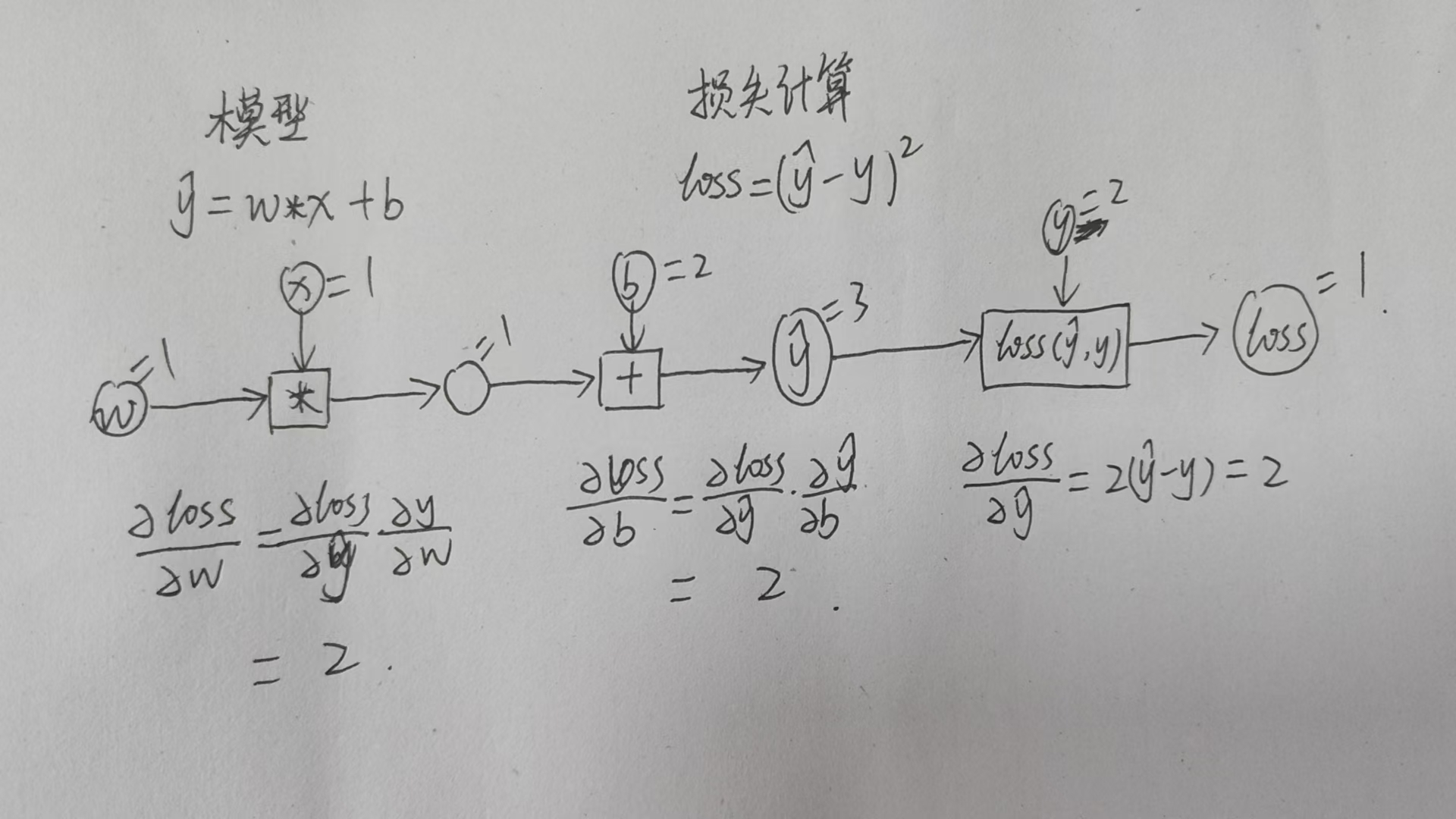
Tensor的作用
Tensor 是一个多维数组,可以用来存储标量(0 维)、向量(1 维)、矩阵(2 维)乃至更高维度的数据。
- 存储所有数据类型:在 PyTorch 中,无论是模型的输入数据(如图像的像素值、文本的词向量),模型的参数(权重 W 和偏置 b),还是中间计算结果,一切皆为 Tensor。
Tensor是 PyTorch 框架中动态计算图的基石,负责存储数据和梯度
- Tensor 是构建计算图的基本单元。在一个深度学习模型中,所有运算(如加、乘、矩阵乘法等)都是 Tensor 之间的操作
- 动态 (Dynamic):这是 PyTorch 的关键特性。计算图是在运行时(即每次前向传播时)动态构建的。这意味着图的结构可以根据输入数据的不同或程序逻辑(如条件判断)而改变。
- Tensor 内部存储了两个至关重要的数值
- 数据 (Data):主体部分,即节点的值,用于存储实际的输入数据、模型参数(权重 W、b)以及前向传播过程中的所有中间结果。
- 梯度 (Grad):Tensor 的
.grad属性,存储了梯度值 (gradient),这个值代表了损失函数 (loss) 对该 Tensor 的导数
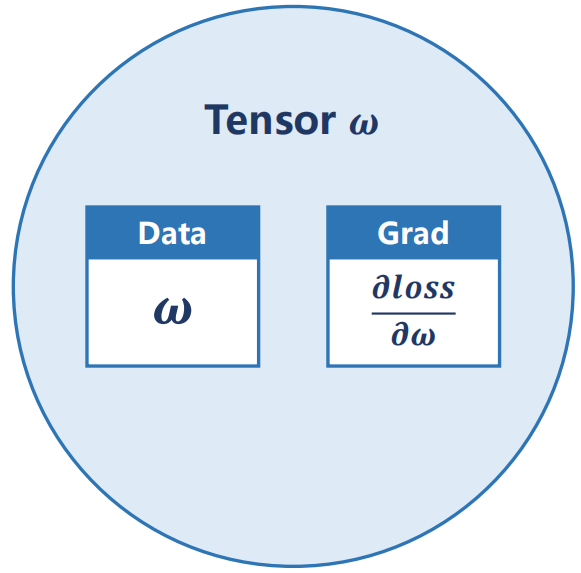
使用Tensor实现反向传播
关键代码详解:
loss_val.backward()执行后,具体哪些对象及其值会发生改变?- 唯一会发生实质性改变的对象是具有
requires_grad=True属性的叶子 Tensor,在本例中就是您的权重 w - w.grad:值被累加
- w:值保持不变(w的值默认表示data)
- 其他中间 Tensor:值保持不变(
forward()过程中产生的中间 Tensor(如y_pred)的值保持不变,它们所包含的梯度历史信息会被用于反向传播,然后通常会被释放。)
- 唯一会发生实质性改变的对象是具有
- 为什么要使用 with torch.no_grad(): 包裹更新权重的代码?
- 防止构建计算图:梯度下降的目标是修改权重
w的值,而不是将这个修改过程作为一次可微分的计算。torch.no_grad()告诉 PyTorch:“以下操作只是数据管理,不要追踪。” - 避免循环依赖和错误:如果没有
no_grad(),PyTorch 会将w_new = w_old - a * w.grad这个操作记录到计算图中。
- 防止构建计算图:梯度下降的目标是修改权重
- 为什么梯度要使用
w.grad.zero_()置零,以及为什么它不用被torch.no_grad()包裹?backward()方法的机制是累加梯度,除非确实需要累加,否则要显示的使用.zero_()置零w.grad存储的是上一次计算的结果,它是一个非活跃的 Tensor。我们并不需要对梯度本身求梯度。PyTorch 已经明确地将对.grad属性执行的原地操作(如zero_())视为纯粹的数据管理,并默认允许它绕过梯度追踪系统。
import torch
import matplotlib.pyplot as plt
# 定义数据集
x_data = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float32)
y_data = torch.tensor([2.0, 4.0, 6.0], dtype=torch.float32)
a = 0.01
# 创建一个权重tensor,将值用[]框起来
w = torch.tensor([1.0])
# 启动自动计算loss对w的梯度,默认关闭
w.requires_grad_(True)
def forward(x):
# 这里刚开始 w 是个tensor,x 是个数
# 当他俩相乘时,乘号*会自动重载,把x也化为一个tensor对象
# 最终做乘法返回一个tensor
return x * w
# 每调用一次loss函数,就动态的构建了计算图
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
# 轮次列表 与 轮次的平均损失列表
epochs_list = []
costs_list = []
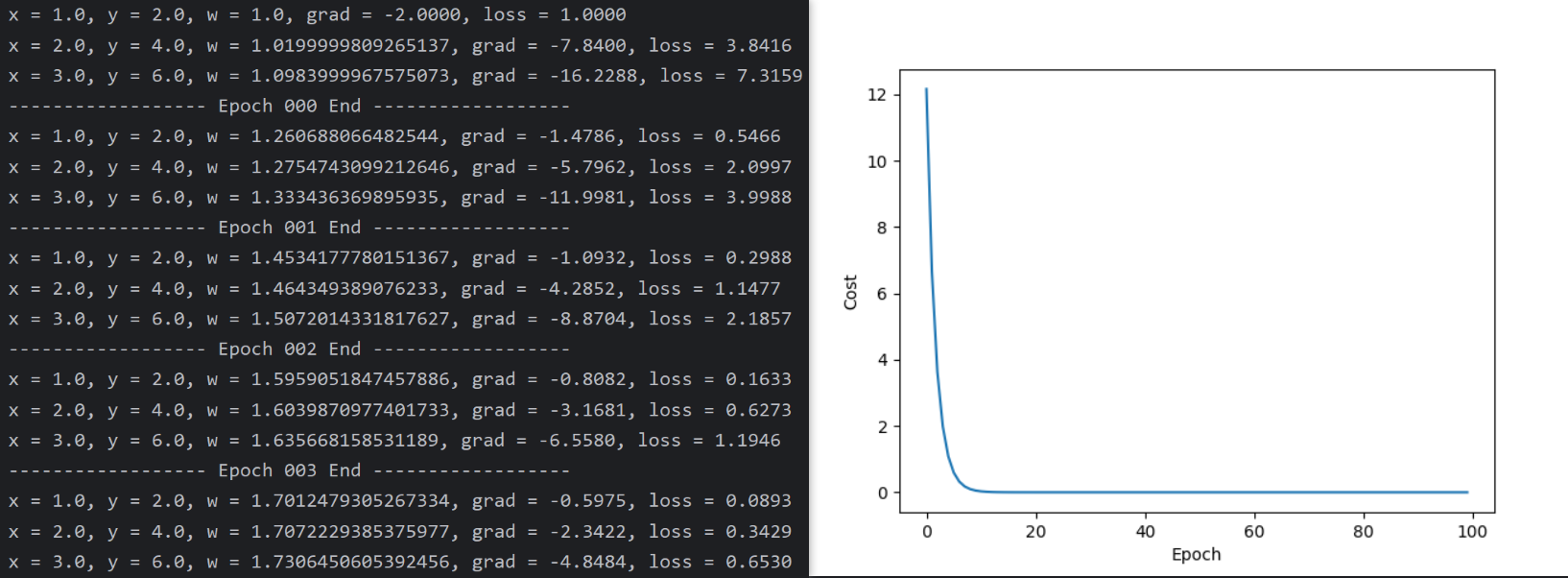
print('训练前的预测值 x =', 4, 'y =', forward(4).item())
for epoch in range(100):
for x_val, y_val in zip(x_data, y_data):
loss_val = loss(x_val, y_val)
loss_val.backward() # 将梯度反向传播至w的tensor,并且与该样本相关的计算图就会被释放
print(f"x = {x_val}, y = {y_val}, w = {w.item()}, grad = {w.grad.item():.4f}, loss = {loss_val.item():.4f}")
with torch.no_grad():
w -= a * w.grad # 使用no_grad()包裹,使tensor只更新data值,不生成计算图
w.grad.zero_() # 更新完成后,将梯度置零,防止累加
with torch.no_grad():
# 计算整个数据集的均方误差 (MSE)
final_epoch_loss = torch.mean(loss(x_data, y_data)).item()
print(f"------------------ Epoch {epoch:03d} End ------------------")
epochs_list.append(epoch)
costs_list.append(final_epoch_loss)
print('训练后的预测值 x = 4, y =', forward(4).item())
# 绘制损失曲线
plt.plot(epochs_list, costs_list)
plt.ylabel('Cost')
plt.xlabel('Epoch')
plt.show()
课后作业:二维权重计算题手算与代码实现
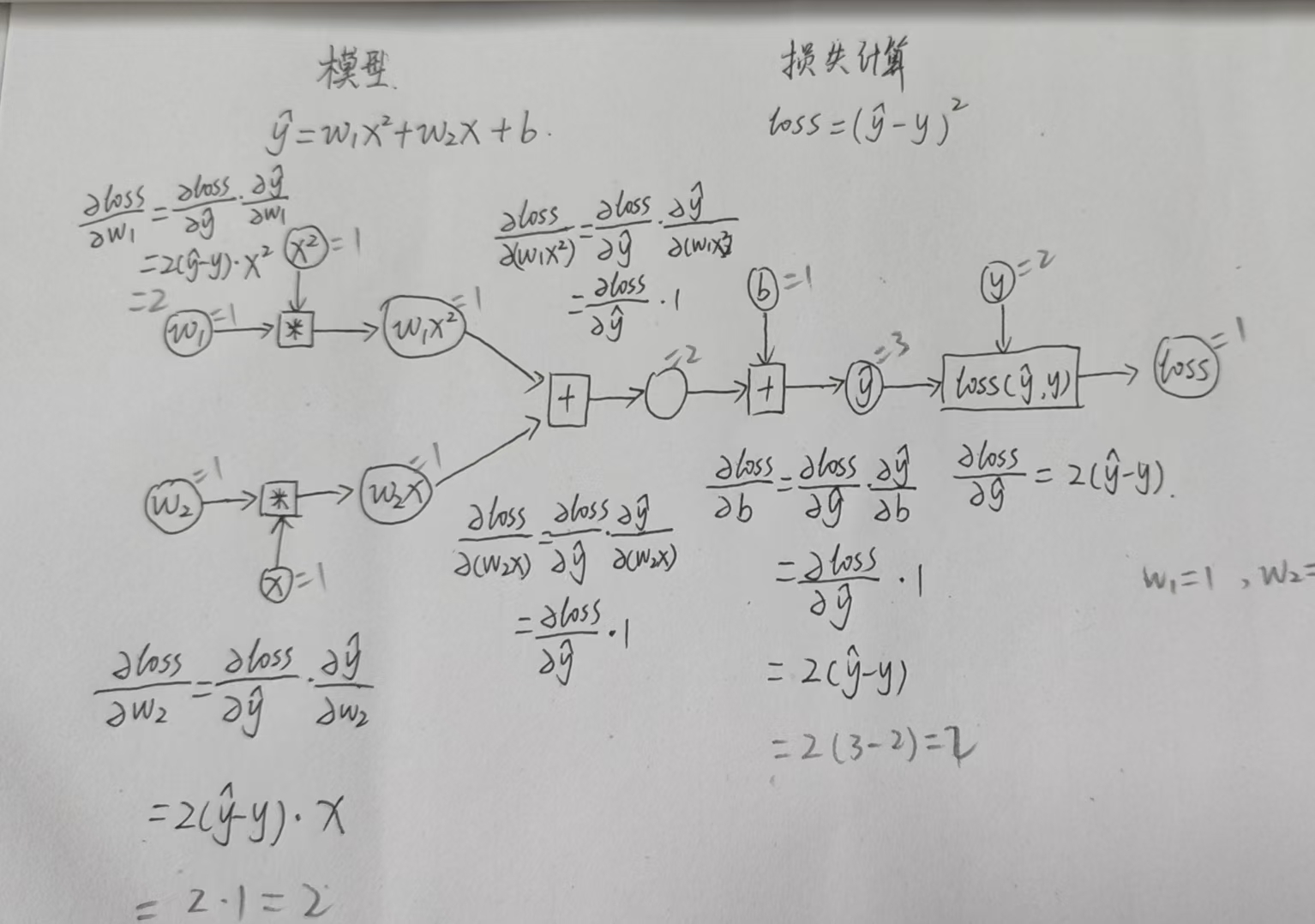
import numpy as np
import torch
import matplotlib.pyplot as plt
# 定义数据集
x_data = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float32)
y_data = torch.tensor([2.0, 4.0, 6.0], dtype=torch.float32)
a = 0.01
w1 = torch.tensor([1.0])
w2 = torch.tensor([1.0])
b = torch.tensor([1.0])
w1.requires_grad_(True)
w2.requires_grad_(True)
b.requires_grad_(True)
def forward(x):
return w1 * x ** 2 + w2 * x + b
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
# 轮次列表 与 轮次的平均损失列表
epochs_list = []
costs_list = []
print('训练前的预测值 x =', 4, 'y =', forward(4).item())
for epoch in range(5000):
for x_val, y_val in zip(x_data, y_data):
loss_val = loss(x_val, y_val)
loss_val.backward()
with torch.no_grad():
w1 -= a * w1.grad
w2 -= a * w2.grad
b -= a * b.grad
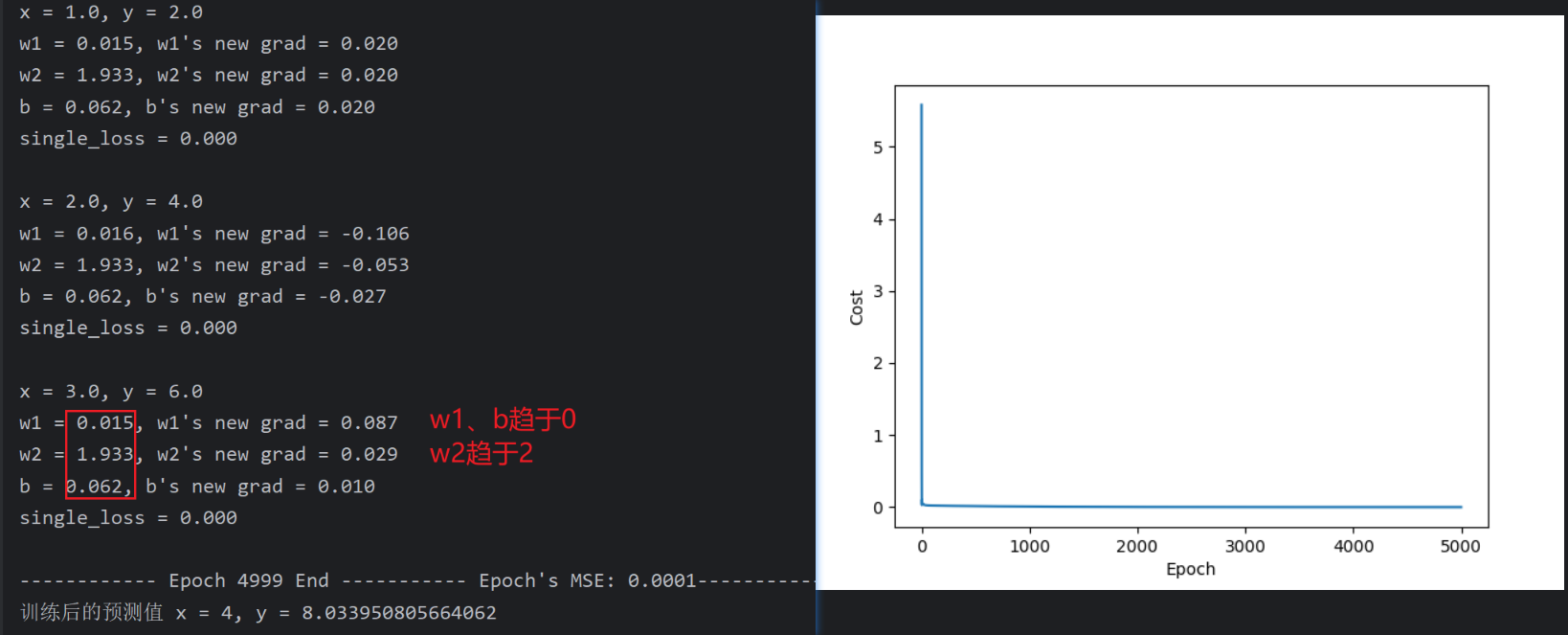
print(f"x = {x_val}, y = {y_val}\n"
f"w1 = {w1.item():.3f}, w1's new grad = {w1.grad.item():.3f}\n"
f"w2 = {w2.item():.3f}, w2's new grad = {w2.grad.item():.3f}\n"
f"b = {b.item():.3f}, b's new grad = {b.grad.item():.3f}\n"
f"single_loss = {loss_val.item():.3f}\n")
w1.grad.zero_()
w2.grad.zero_()
b.grad.zero_()
with torch.no_grad():
# 计算整个数据集的均方误差 (MSE)
final_epoch_loss = torch.mean(loss(x_data, y_data)).item()
print(f"------------ Epoch {epoch:03d} End ----------- Epoch's MSE: {final_epoch_loss:.4f}-----------")
epochs_list.append(epoch)
costs_list.append(final_epoch_loss)
print('训练后的预测值 x = 4, y =', forward(4).item())
# 绘制损失曲线
plt.plot(epochs_list, costs_list)
plt.ylabel('Cost')
plt.xlabel('Epoch')
plt.show()
阶段小结
SGD与Mini-BGD、BGD的区别
-
在 Mini-batch 梯度下降 (MBGD) 中,梯度计算和 权重更新 都是基于当前批次的平均值。
-
SGD 的标准定义是:在每一次权重更新时,只使用一个样本的梯度。就算他是每个都算,并且按顺序算,但是他更新权重的时机是在单一样本后的。
- 一个样本更新一次w
-
BGD(Batch Gradient Descent,批量梯度下降)的定义是:在进行一次权重更新时,必须使用整个数据集的平均梯度。
- N个样本更新一次w
-
Mini-BGD,梯度计算和 权重更新 都是基于当前批次的平均值
计算当前Epoch的时机
- 不管采用哪种梯度下降算法(BGD、MBGD、SGD),计算并记录当前 Epoch 的最终性能指标(Cost 或 Loss)时,都遵循,使用更新后的权重 w,对整个数据集取 MSE(或平均损失)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)