Python机器学习三大模块的学习
一、numpy模块快速入门
1.对numpy的了解
NumPy 是 Python 中科学计算的基础包。它是一个 Python 库,提供多维数组对象、各种派生对象(例如掩码数组和矩阵)以及各种用于快速数组操作的例程,包括数学、逻辑、形状操作、排序、选择、I/O 、离散傅里叶变换、基本线性代数、基本统计运算、随机模拟等等。
NumPy 包的核心是ndarray对象。这封装了同质数据类型的n维数组,许多操作在编译代码中执行以提高性能。 NumPy 数组和标准 Python 序列之间有几个重要的区别:
-
与 Python 列表(可以动态增长)不同,NumPy 数组在创建时具有固定大小。更改ndarray的大小将创建一个新数组并删除原始数组。
-
NumPy 数组中的元素都必须具有相同的数据类型,因此在内存中的大小也相同。例外:可以拥有(Python,包括 NumPy)对象的数组,从而允许不同大小元素的数组。
-
NumPy 数组有助于对大量数据进行高级数学和其他类型的运算。通常,与使用 Python 的内置序列相比,此类操作的执行效率更高,并且代码更少。
2.arange函数测试环境安装
import nunmpy as np
a=np.arange(10)
print(a)生成的是0-9的一维数组
import numpy as np
result=np.arange(10)
print(result)
注意:在pycharm中需要有一个变量接受。
3.数组创建
1.使用array函数从Python列表或元组创建数组
import numpy as np
>>> a = np.array([2, 3, 4])
>>> a
array([2, 3, 4])
>>> a.dtype
dtype('int64')
>>> b = np.array([1.2, 3.5, 5.1])
>>> b.dtype
dtype('float64')
2.该函数zeros创建一个全是 0 的数组,该函数 ones创建一个全是 1 的数组,该函数empty 创建一个初始内容是随机的且取决于内存状态的数组。默认情况下,创建的数组的数据类型是 float64,但可以通过关键字参数 指定dtype。
np.zeros((3, 4))
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
np.ones((2, 3, 4), dtype=np.int16)
array([[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]]], dtype=int16)
np.empty((2, 3))
array([[3.73603959e-262, 6.02658058e-154, 6.55490914e-260], # may vary
[5.30498948e-313, 3.14673309e-307, 1.00000000e+000]])
4.打印数组
布局:
-
最后一个轴从左到右打印,
-
倒数第二个从上到下打印,
-
其余部分也从上到下打印,每个切片与下一个切片之间用空行分隔。
然后,一维数组打印为行,二维数组打印为矩阵,三维数组打印为矩阵列表。
a = np.arange(6) # 1d array
print(a)
[0 1 2 3 4 5]
>>>
b = np.arange(12).reshape(4, 3) # 2d array
print(b)
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
>>>
c = np.arange(24).reshape(2, 3, 4) # 3d array
print(c)
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]5.numpy基本操作
1.数组上的算术运算符按元素应用。创建一个新数组并用结果填充。
a = np.array([20, 30, 40, 50])
b = np.arange(4)
b
array([0, 1, 2, 3])
c = a - b
c
array([20, 29, 38, 47])
b**2
array([0, 1, 4, 9])
10 * np.sin(a)
array([ 9.12945251, -9.88031624, 7.4511316 , -2.62374854])
a < 35
array([ True, True, False, False])2.乘积运算*符在 NumPy 数组中按元素进行运算。矩阵乘积可以使用@运算符(在 python >=3.5 中)或dot函数或方法来执行。、
3.某些操作(例如+=和*=)会就地修改现有数组,而不是创建新数组。
6.通用函数
NumPy 提供熟悉的数学函数,例如 sin、cos 和 exp。在 NumPy 中,这些称为“通用函数”( ufunc)。在 NumPy 中,这些函数按元素对数组进行操作,生成数组作为输出。
B = np.arange(3) >>> B array([0, 1, 2]) >>> np.exp(B) array([1. , 2.71828183, 7.3890561 ]) >>> np.sqrt(B) array([0. , 1. , 1.41421356]) >>> C = np.array([2., -1., 4.]) >>> np.add(B, C) array([2., 0., 6.])
解释:
np.arange(3):生成一个包含[0, 1, 2]的数组。np.exp(B):对数组B中的每个元素计算指数函数 \(e^x\)。np.sqrt(B):计算数组B中每个元素的平方根。np.array([2., -1., 4.]):创建一个包含浮点数的数组C。np.add(B, C):将数组B和C对应元素相加(等价于B + C)。
7.索引、切片和迭代
1.多维数组的每个轴可以有一个索引。这些索引以逗号分隔的元组形式给出
array([[ 0, 1, 2, 3], [10, 11, 12, 13], [20, 21, 22, 23], [30, 31, 32, 33], [40, 41, 42, 43]]
2.单元素索引:
b[2,3] 表示第三行(索引从0开始)、第四列的元素
3.切片操作:
b[0:5,1] #输出array([1,11,21,31,41])
0:5表示行范围(从第 0 行到第 4 行,包含第 4 行)1表示第 2 列(索引为 1)- 结果是第二列的所有元素
4.多维数组的迭代是相对于第一个轴完成的:
for row in b: ... print(row) ... [0 1 2 3] [10 11 12 13] [20 21 22 23] [30 31 32 33] [40 41 42 43]
flat属性是数组所有元素的迭代器。
4.总结:
NumPy 数组的索引规则:
- 使用
[行, 列]的格式 - 索引从 0 开始
- 切片使用
start:stop:step的格式 - 省略号
:表示整个维度 - 负数索引表示从后往前数(如
-1表示最后一行)
8. 形状操纵
1.改变数组的形状
数组的形状沿每个轴的元素数量给出:
a = np.floor(10 * rg.random((3, 4)))
a
array([[3., 7., 3., 4.],
[1., 4., 2., 2.],
[7., 2., 4., 9.]])
a.shape
(3, 4)三个命令更改数组形状
a.ravel() # returns the array, flattened
array([3., 7., 3., 4., 1., 4., 2., 2., 7., 2., 4., 9.])
a.reshape(6, 2) # returns the array with a modified shape
array([[3., 7.],
[3., 4.],
[1., 4.],
[2., 2.],
[7., 2.],
[4., 9.]])
a.T # returns the array, transposed
array([[3., 1., 7.],
[7., 4., 2.],
[3., 2., 4.],
[4., 2., 9.]])
a.T.shape
(4, 3)
a.shape
(3, 4) 产生的数组中元素的顺序ravel通常是“C 风格”,即最右边的索引“变化最快”,因此后面的元素是。如果数组被重新调整为其他形状,则该数组将再次被视为“C 样式”。 NumPy 通常创建按此顺序存储的数组,因此通常不需要复制其参数,但如果该数组是通过另一个数组的切片创建的或使用异常选项创建的,则可能需要复制它。还可以使用可选参数指示函数和使用 FORTRAN 样式的数组,其中最左边的索引变化最快。
reshape函数以修改后的形状返回其参数,而 ndarray.resize方法则修改数组本身:
a
array([[3., 7., 3., 4.],
[1., 4., 2., 2.],
[7., 2., 4., 9.]])
a.resize((2, 6))
a
array([[3., 7., 3., 4., 1., 4.],
[2., 2., 7., 2., 4., 9.]])2.将不同的数组堆叠在一起
多个数组可以沿着不同的轴堆叠在一起:
a = np.floor(10 * rg.random((2, 2)))
a
array([[9., 7.],
[5., 2.]])
b = np.floor(10 * rg.random((2, 2)))
b
array([[1., 9.],
[5., 1.]])
np.vstack((a, b))
array([[9., 7.],
[5., 2.],
[1., 9.],
[5., 1.]])
np.hstack((a, b))
array([[9., 7., 1., 9.],
[5., 2., 5., 1.]])对于二维以上的数组, hstack沿其第二个轴堆叠,vstack沿其第一个轴堆叠,并concatenate 允许可选参数给出应沿其进行串联的轴的编号。
在复杂的情况下,r_和c_对于通过沿一个轴堆叠数字来创建数组非常有用。它们允许使用范围文字:。
3.将一个数组分成几个较小的数组
(1)使用hsplit沿着水平轴进行分割,方法是指定要返回的形状相同的数组的数量,或者指定应在其后进行分割的列
(2)vsplit沿垂直轴分割,并array_split允许指定沿哪一个轴分割
9.副本和视图
操作数组时,他们的数据有时会被复制到新的数组中,有时不会。
三种情况:
1.根本没有副本:简单的赋值不会复制对象或其数据
a = np.array([[ 0, 1, 2, 3], ... [ 4, 5, 6, 7], ... [ 8, 9, 10, 11]]) >>> b = a # no new object is created >>> b is a # a and b are two names for the same ndarray object True
python将可变对象作为引用传递,因此函数调用不会复制。
2.查看和浅复制:不同的数组对象可以共享相同的数据。该view方法创建一个查看相同数据的新数组对象
3.深度复制:该copy方法制作数组及其数据的完整副本
二、pandas快速入门
1.pandas中的基本数据结构
pandas提供了两种用于处理数据的类
1.:一维标签数组,可容纳任何类型的数据
例如:整数、字符串、Python等
2.:二维数据结构,像二维数组或带有行和列的表格一样容纳数据。
2.对象创建
1.通过传递值列表来创建 Series,让 pandas 创建默认的 RangeIndex
In [3]: s = pd.Series([1, 3, 5, np.nan, 6, 8])
In [4]: s
Out[4]:
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
2.通过传递带有使用 date_range() 创建的日期时间索引和标签列的 NumPy 数组来创建 DataFrame
In [5]: dates = pd.date_range("20130101", periods=6)
In [6]: dates
Out[6]:
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
In [7]: df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD"))
In [8]: df
Out[8]:
A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
2013-01-06 -0.673690 0.113648 -1.478427 0.5249883. 通过传递一个对象字典来创建 DataFrame,其中建是列标签,值是列值。
3.查看数据
(1)使用 DataFrame.head() 和 DataFrame.tail() 分别查看框架的顶部和底部行。
(2)使用 DataFrame.to_numpy() 返回底层数据的 NumPy 表示形式,不包含索引或列标签。
(3)使用 describe() 显示数据的快速统计摘要。
(4)使用 DataFrame.sort_index() 按轴排序。
(5)使用 DataFrame.sort_values() 按值排序。
4.选取
1.Getitem([])
对于一个pandas.DataFrame ,传递单个标签会选择一列,并产生一个与 等效的
pandas.Series df.A
2.按标签选取
使用 DataFrame.loc() 或 DataFrame.at()
1.选取与标签匹配的行:
In [27]: df.loc[dates[0]]
Out[27]:
A 0.469112
B -0.282863
C -1.509059
D -1.135632
Name: 2013-01-01 00:00:00, dtype: float642. 选取所有行 () 以及选定的列标签:
In [28]: df.loc[:, ["A", "B"]]
Out[28]:
A B
2013-01-01 0.469112 -0.282863
2013-01-02 1.212112 -0.173215
2013-01-03 -0.861849 -2.104569
2013-01-04 0.721555 -0.706771
2013-01-05 -0.424972 0.567020
2013-01-06 -0.673690 0.1136483.选取单个行和列标签会返回一个标量
In [30]: df.loc[dates[0], "A"]
Out[30]: 0.4691122999071863
3.按位置选取
1.使用 DataFrame.iloc() 或 DataFrame.iat()
df.iloc[]:通过整数位置选取数据,支持多种输入格式,如单个整数、整数列表、整数切片等。
df.iat[]:用于快速访问单个标量值,只能接受整数位置参数。
2.基本用法:
1.选取单行/单列:
# 获取第3行(index=2)
row = df.iloc[2]
# 获取第2列(index=1)
col = df.iloc[:, 1] 2.选取多行/多列 :
# 获取第2到第4行(index=1~3)
rows = df.iloc[1:4]
# 获取第1列和第3列
cols = df.iloc[:, [0, 2]] 3.同时选取行列
# 获取第2行第3列的值(index=1,2)
value = df.iloc[1, 2]
# 获取第1到3行,第2到4列的数据
subset = df.iloc[0:3, 1:4]
3.注意事项:
- 索引从 0 开始,与 Python 列表一致。
- 切片时,行切片包含终止位置(与 Python 原生切片不同),例如
df.iloc[0:3]会选取第 0、1、2 行。 - 避免在循环中频繁使用
iloc修改数据,可考虑先选取后批量操作。
4.布尔索引:
1.选取大于的行。df[df["A”]>0]
In [39]: df[df["A"] > 0]
Out[39]:
A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-04 0.721555 -0.706771 -1.039575 0.2718602.isin()方法筛选特定值
# 筛选 Name 为 'Alice' 或 'Charlie' 的行
selected_names = df[df['Name'].isin(['Alice', 'Charlie'])]
# 筛选 Score 不在 [80, 90] 范围内的行
outliers = df[~df['Score'].isin(range(80, 91))]3.使用 pd.isna() 或 pd.notna() 筛选包含或不包含空值的行
5.缺失数据
(1)Reindexing 允许在指定的轴上更改/添加/删除索引
1.使用 DataFrame.dropna() 丢弃任何含有缺失数据的行。
2.使用 DataFrame.fillna() 填充缺失数据。
3.使用pandas.isna获取值为的布尔掩码nan
(2)操作
例:计算每列的平均值
In [61]: df.mean()
Out[61]:
A -0.004474
B -0.383981
C -0.687758
D 5.000000
F 3.000000
dtype: float64
(3)用户定义函数
使用 DataFrame.agg() 和 DataFrame.transform() 应用用户定义函数,分别对结果进行聚合或广播。
6.合并
1.拼接
使用 concat() 将 pandas 对象按行拼接在一起
2.连接
使用 merge() 可以在特定列上实现 SQL 风格的连接类型
7.分组
1.按列标签分组,选择列标签,然后将 DataFrameGroupBy.sum() 函数应用到结果分组
2. 按多个列标签分组会形成 MultiIndex。
8.重塑
1.堆叠(stack)
stack() 方法会“压缩” DataFrame 列中的一个层级
2.透视表
9.时间序列
1.使用 Series.tz_localize() 将时间序列本地化到某个时区
2.使用 Series.tz_convert() 将时区感知的时间序列转换为另一个时区
3.向时间序列添加非固定时长(BusinessDay)
10.绘图
1.plt.close方法用于关闭图形窗口
2.使用 plot() 绘制所有列
11.导入和导出数据
1.写入csv文件:使用pandas.DataFrame.to_csv — pandas 2.2.3 documentation
2.从csv文件读取:使用pandas.DataFrame.to_csv — pandas 2.2.3 documentation
3.胜过
使用 DataFrame.to_excel() 写入 Excel 文件
使用 read_excel() 从 Excel 文件读取
三、matplotlib模块快速入门
1.Figure的组成成分
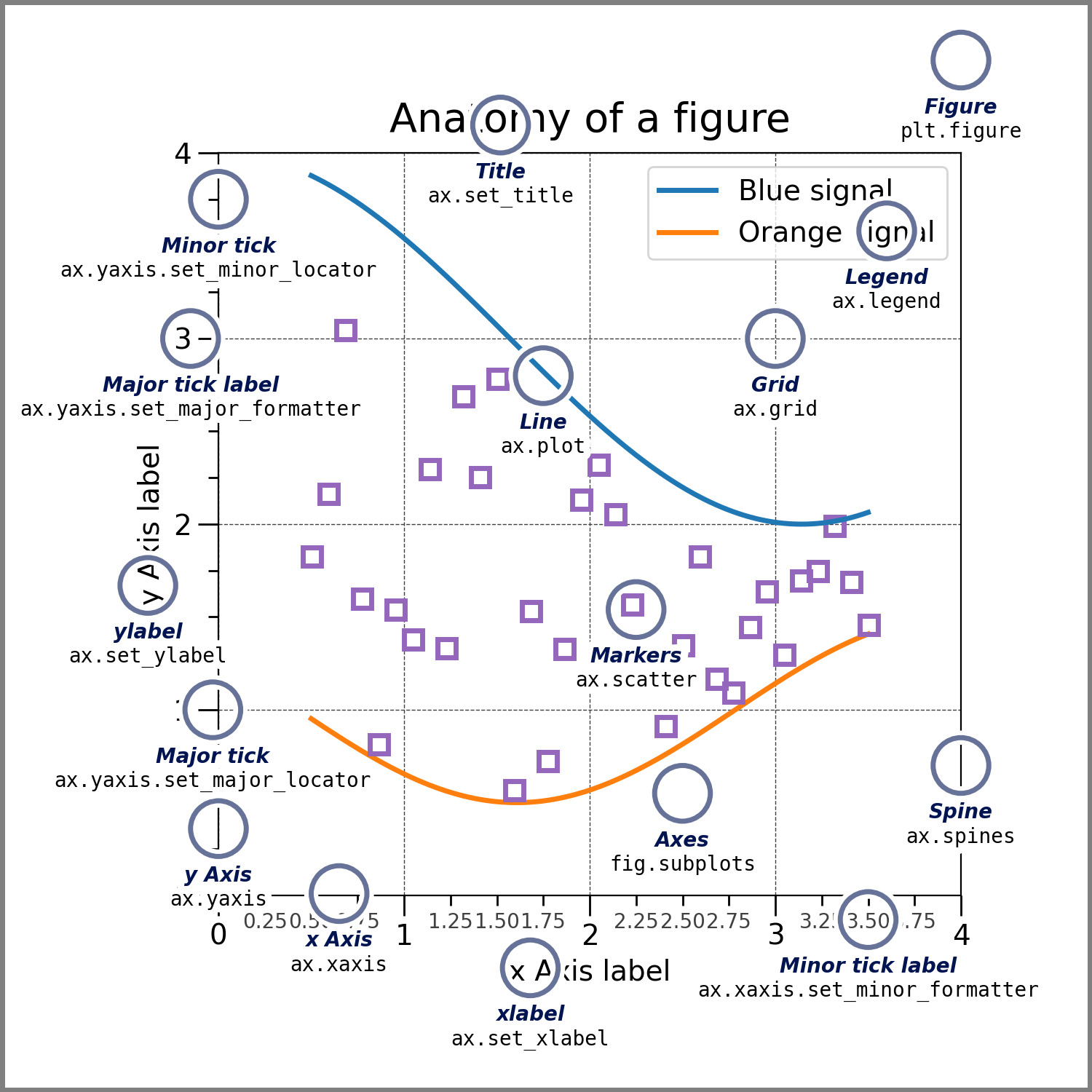
1.数字
2.轴:轴是附加到 Figure 的 Artist,其中包含 绘制数据,通常包括两个(或 3D 情况下为三个)
3.艺术家:基本上,Figure 上可见的所有内容都是 Artist,渲染 Figure 时,所有 艺术家被吸引到画布上。大多数 Artist 都与 Axes 绑定;这样 一个 Artist 不能由多个 Axes 共享,也不能从一个 Axes 移动到另一个 Axes。
2.编码样式
显式接口和隐式接口
-
显式创建 Figures 和 Axes,并对它们调用方法( “面向对象 (OO) 样式”)。
-
依靠 pyplot 隐式创建和管理 Figures 和 Axes,以及 使用 Pyplot 函数进行绘图。
3.创建辅助函数
def my_plotter(ax, data1, data2, param_dict):
"""
A helper function to make a graph.
"""
out = ax.plot(data1, data2, **param_dict)
return out4.造型艺术家
1.颜色
Matplotlib 有一个非常灵活的颜色数组,一些艺术家会采用多种颜色。即 for 一个matplotlib.axes.Axes.scatter — Matplotlib 3.10.3 documentation图,边上的标记可以是不同的颜色 从内部来看:
fig, ax = plt.subplots(figsize=(5, 2.7))
ax.scatter(data1, data2, s=50, facecolor='C0', edgecolor='k')
2.线宽、线型和标记大小
1.线宽通常以排版点为单位 (1 pt = 1/72 inch) 和 适用于具有描边线条的艺术家。同样,描边线条 可以具有 linestyle
2.标记大小取决于使用的方法
5.标记图
1.轴标签和文本
2.在文本中使用数学表达式
Matplotlib 在任何文本表达式中接受 TeX 方程表达式
3.附注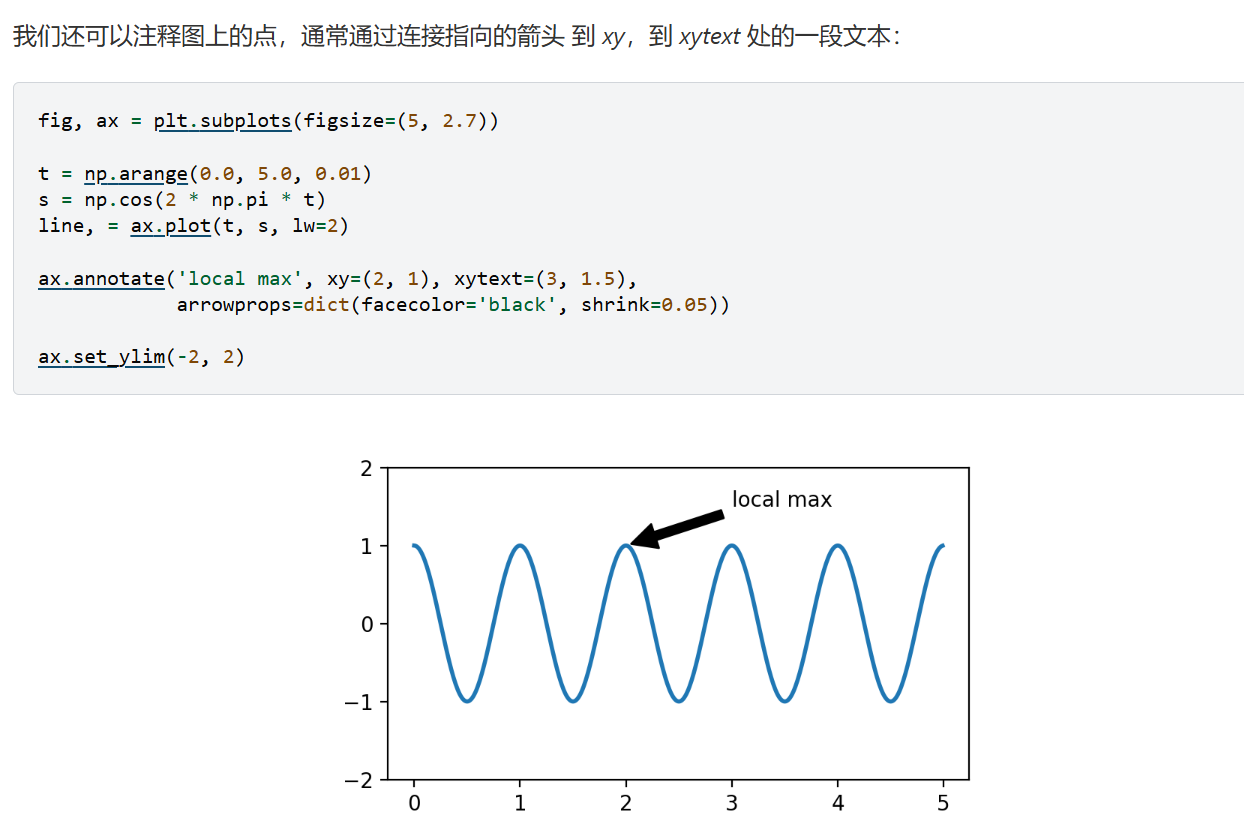
6.轴刻度与刻度
import matplotlib.pyplot as plt
import numpy as np
# 创建示例数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 创建图形和子图
fig, ax = plt.subplots(figsize=(10, 6))
# 绘制数据
ax.plot(x, y)
# 设置x轴和y轴的刻度位置
ax.set_xticks([0, 2, 4, 6, 8, 10])
ax.set_yticks([-1, -0.5, 0, 0.5, 1])
# 设置刻度标签的格式
ax.set_xticklabels(['zero', 'two', 'four', 'six', 'eight', 'ten'], rotation=45)
# 添加网格线
ax.grid(True, linestyle='--', alpha=0.7)
# 设置轴标签和标题
ax.set_xlabel('X Values')
ax.set_ylabel('Y Values')
ax.set_title('Customizing Ticks and Tick Labels')
plt.tight_layout()
plt.show()轴刻度是图表中坐标轴上的标记,用于表示数据的位置。刻度标签则是与这些刻度关联的文本,用于显示具体的数值或类别。Matplotlib 提供了灵活的 API 来控制它们的位置、格式和外观。
7.颜色映像数据
import matplotlib.pyplot as plt
import numpy as np
# 创建示例数据
x = np.linspace(0, 10, 100)
y = np.linspace(0, 10, 100)
X, Y = np.meshgrid(x, y)
Z = np.sin(X) * np.cos(Y)
# 创建图形和子图
fig, ax = plt.subplots(figsize=(10, 8))
# 使用pcolormesh绘制带颜色映射的二维数据
im = ax.pcolormesh(X, Y, Z, cmap='viridis')
# 添加颜色条
cbar = fig.colorbar(im, ax=ax)
cbar.set_label('Intensity')
# 设置轴标签和标题
ax.set_xlabel('X Axis')
ax.set_ylabel('Y Axis')
ax.set_title('Color Mapping with Viridis Colormap')
plt.tight_layout()
plt.show()颜色映射是将数据值映射到颜色的过程,在可视化多维数据时特别有用

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)