PyTorch 深度学习实践——逻辑斯蒂回归
·
学习笔记|B 站 UP 主 刘二大人 《PyTorch深度学习实践》视频知识点总结
传送门 PyTorch深度学习实践——逻辑斯蒂回归
视频中截图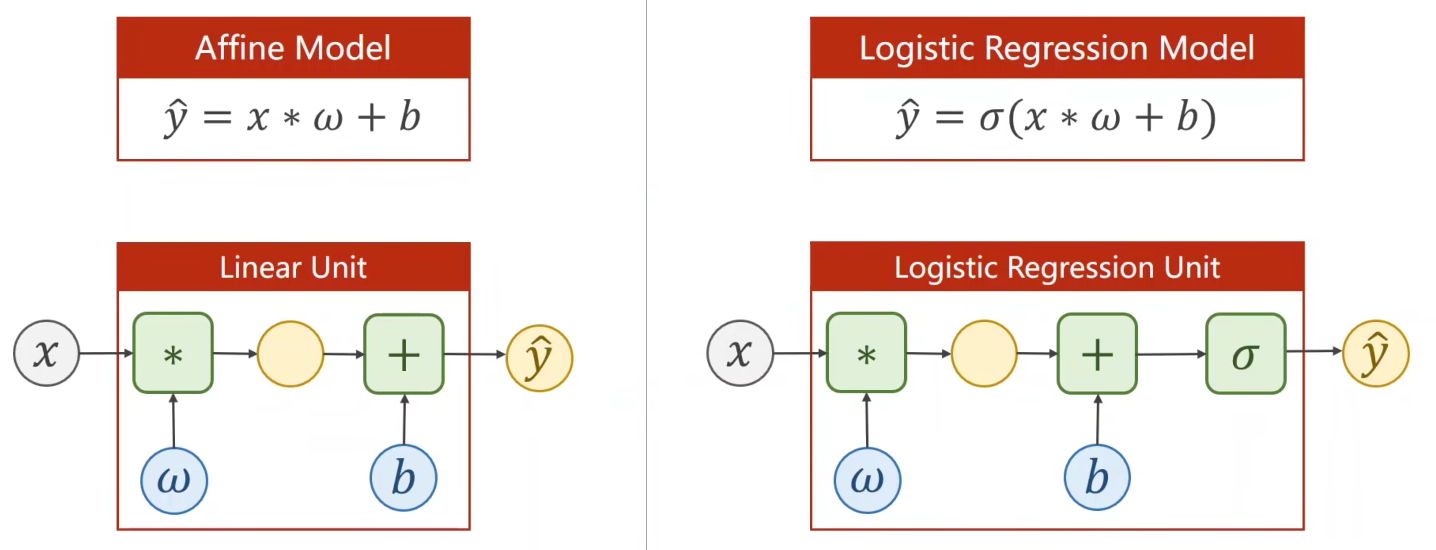
- 逻辑斯蒂回归和线性模型的明显区别是在线性模型的后面,添加了激活函数(非线性变换)
- 分布的差异:KL散度,cross-entropy交叉熵
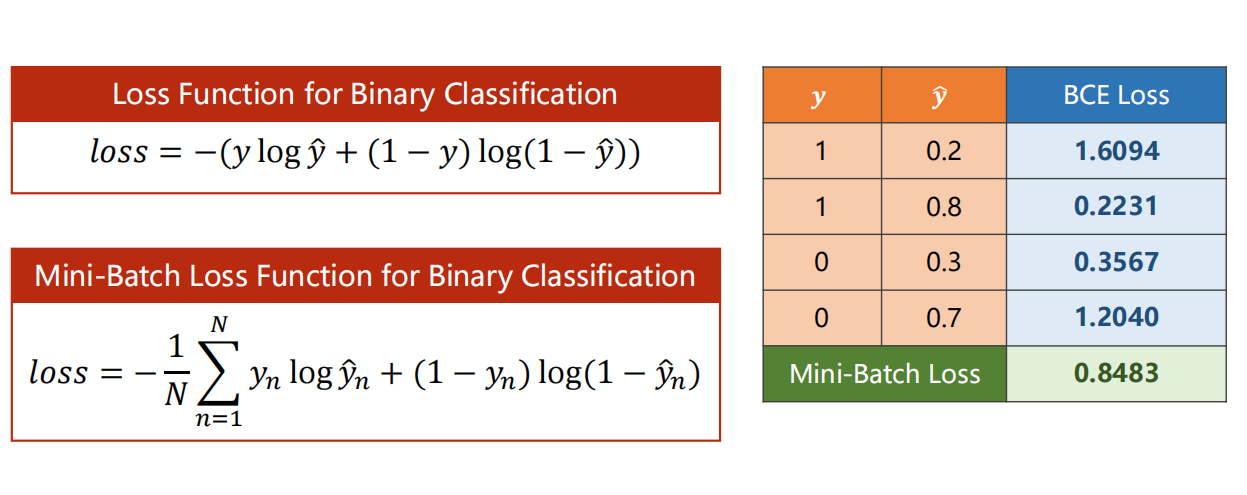
预测与标签越接近,BCE损失越小。
1. 核心原理回顾
1.1 模型结构
逻辑斯蒂回归在线性模型基础上引入Sigmoid 激活函数,解决二分类问题:
- 线性部分: z = w x + b z = wx + b z=wx+b(与线性回归一致, w w w 为权重, b b b 为偏置);
- 非线性映射(Sigmoid): y p r e d = σ ( z ) = 1 1 + e − z y_{pred} = \sigma(z) = \frac{1}{1+e^{-z}} ypred=σ(z)=1+e−z1,输出值代表样本属于正类的概率(0 ≤ y p r e d y_{pred} ypred ≤ 1)。
1.2 损失函数
分类任务不再使用均方误差,而是采用交叉熵损失(Binary Cross Entropy, BCE),更适配概率分布的优化:
L o s s = − 1 n ∑ i = 1 n [ y t r u e ⋅ log ( y p r e d ) + ( 1 − y t r u e ) ⋅ log ( 1 − y p r e d ) ] Loss = -\frac{1}{n}\sum_{i=1}^n [y_{true} \cdot \log(y_{pred}) + (1-y_{true}) \cdot \log(1-y_{pred})] Loss=−n1i=1∑n[ytrue⋅log(ypred)+(1−ytrue)⋅log(1−ypred)]
其中 y t r u e ∈ { 0 , 1 } y_{true} \in \{0,1\} ytrue∈{0,1} 是真实标签,损失越小代表预测概率与真实标签越匹配。
1.3 反向传播与参数更新
- 前向传播:输入数据 → 计算线性输出 z z z → Sigmoid 映射得到 y p r e d y_{pred} ypred → 计算交叉熵损失;
- 反向传播:以损失值为起点,通过链式法则反向推导,求解 Loss 对 w w w 和 b b b 的梯度:
- 先求 Loss 对 y p r e d y_{pred} ypred 的梯度: ∂ L o s s ∂ y p r e d = − y t r u e y p r e d + 1 − y t r u e 1 − y p r e d \frac{\partial Loss}{\partial y_{pred}} = -\frac{y_{true}}{y_{pred}} + \frac{1-y_{true}}{1-y_{pred}} ∂ypred∂Loss=−ypredytrue+1−ypred1−ytrue;
- 再求 y p r e d y_{pred} ypred 对 z z z 的梯度(Sigmoid 导数特性): ∂ y p r e d ∂ z = y p r e d ⋅ ( 1 − y p r e d ) \frac{\partial y_{pred}}{\partial z} = y_{pred} \cdot (1-y_{pred}) ∂z∂ypred=ypred⋅(1−ypred);
- 最后结合链式法则,得到 Loss 对 w w w 和 b b b 的梯度:
∂ L o s s ∂ w = 1 n ∑ i = 1 n ( y p r e d − y t r u e ) ⋅ x i \frac{\partial Loss}{\partial w} = \frac{1}{n}\sum_{i=1}^n (y_{pred} - y_{true}) \cdot x_i ∂w∂Loss=n1i=1∑n(ypred−ytrue)⋅xi
∂ L o s s ∂ b = 1 n ∑ i = 1 n ( y p r e d − y t r u e ) \frac{\partial Loss}{\partial b} = \frac{1}{n}\sum_{i=1}^n (y_{pred} - y_{true}) ∂b∂Loss=n1i=1∑n(ypred−ytrue)
- 参数更新:利用梯度下降优化器,沿梯度反方向调整 w w w 和 b b b,最小化交叉熵损失。
2. 实现逻辑斯蒂回归
2.1 完整代码实现
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
# 1. 生成二分类模拟数据
torch.manual_seed(42) # 固定随机种子
x = torch.randn(200, 2) # 200个样本,2维特征
# 构造线性决策边界:3x1 + 2x2 - 1 = 0,生成标签
z = 3 * x[:, 0] + 2 * x[:, 1] - 1
y_true = (torch.sigmoid(z) > 0.5).float().unsqueeze(1) # 转为0/1标签,shape=(200,1)
# 2. 定义逻辑斯蒂回归模型
class LogisticRegression(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(2, 1) # 2维输入,1维输出(概率)
def forward(self, x):
z = self.linear(x) # 线性部分:z = wx + b
y_pred = torch.sigmoid(z) # Sigmoid映射到0-1区间
return y_pred
model = LogisticRegression()
# 3. 定义损失函数和优化器
criterion = nn.BCELoss() # 二分类交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.1) # 梯度下降,学习率0.1
# 4. 数据加载(批量训练)
dataset = TensorDataset(x, y_true)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 5. 训练模型
epochs = 100
for epoch in range(epochs):
total_loss = 0.0
for batch_x, batch_y in dataloader:
# 前向传播
batch_pred = model(batch_x)
loss = criterion(batch_pred, batch_y)
# 反向传播 + 参数更新
optimizer.zero_grad() # 清空梯度(关键!避免累加)
loss.backward() # 自动反向传播计算梯度
optimizer.step() # 更新参数
total_loss += loss.item()
# 打印训练过程
if (epoch + 1) % 20 == 0:
avg_loss = total_loss / len(dataloader)
print(f"Epoch [{epoch+1}/{epochs}], Avg Loss: {avg_loss:.4f}")
# 6. 模型评估(预测概率→分类结果)
with torch.no_grad(): # 评估时关闭梯度计算
y_pred_prob = model(x)
y_pred_label = (y_pred_prob > 0.5).float()
accuracy = (y_pred_label == y_true).float().mean()
print(f"\n模型准确率:{accuracy.item():.4f}")
2.2 关键函数解析
nn.BCELoss():PyTorch 内置二分类交叉熵损失,需输入未经过Sigmoid的原始输出(若模型最后用了Sigmoid),或使用nn.BCEWithLogitsLoss()(内置Sigmoid,更稳定);torch.sigmoid(z):将线性输出映射为概率,是逻辑斯蒂回归的核心非线性变换;optimizer.zero_grad():每次迭代/批量训练前清空梯度,避免梯度累加导致参数更新错误;(y_pred_prob > 0.5).float():将概率转换为 0/1 分类标签,是逻辑斯蒂回归的预测逻辑。
2.3 运行结果说明
训练完成后,平均损失会持续下降,模型准确率接近 1.0(因数据是人工生成的线性可分数据),说明模型成功学习到二分类的决策边界。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)