数据库统计神器:一句SQL搞定Sqlserver和Mysql全库表行数统计与数据字典生成
·
数据库统计神器:一行SQL搞定全库表行数统计与数据字典生成
在数据库开发和维护过程中,我们经常需要统计数据库中所有表的行数,或者生成数据字典。手动操作不仅效率低下,而且容易出错。今天就给大家分享两个实用的SQL语句,分别适用于MySQL和SQL Server数据库,让您轻松搞定这些任务!
一、MySQL数据库:一键统计全库表行数并生成数据字典
在MySQL中,我们可以通过查询information_schema系统表来获取数据库的元数据信息。以下SQL语句可以一次性统计指定数据库中所有表的行数:
SELECT
t.TABLE_NAME AS '表名',
t.TABLE_COMMENT AS '表注释',
t.ENGINE AS '存储引擎',
t.TABLE_ROWS AS '记录数',
CONCAT(ROUND(t.DATA_LENGTH / 1024 / 1024, 2), ' MB') AS '数据大小',
CONCAT(ROUND(t.INDEX_LENGTH / 1024 / 1024, 2), ' MB') AS '索引大小',
CONCAT(ROUND((t.DATA_LENGTH + t.INDEX_LENGTH) / 1024 / 1024, 2), ' MB') AS '总大小',
t.CREATE_TIME AS '创建时间',
t.UPDATE_TIME AS '更新时间'
FROM
information_schema.TABLES t
WHERE
t.TABLE_SCHEMA = 'your_database_name' -- 替换为你的数据库名
ORDER BY
t.TABLE_ROWS DESC;
使用说明:
- 将
your_database_name替换为您的数据库名称 - 执行后会返回每个表的名称、注释、引擎、记录数、大小等信息
- 按记录数降序排列,方便查看数据量较大的表
数据字典生成扩展版:
如果需要生成更详细的数据字典(包含字段信息),可以使用以下SQL:
SELECT
t.TABLE_NAME AS '表名',
t.TABLE_COMMENT AS '表注释',
c.COLUMN_NAME AS '字段名',
c.COLUMN_TYPE AS '数据类型',
c.IS_NULLABLE AS '是否允许为空',
c.COLUMN_DEFAULT AS '默认值',
c.COLUMN_COMMENT AS '字段注释',
CASE WHEN k.CONSTRAINT_NAME = 'PRIMARY' THEN 'YES' ELSE 'NO' END AS '是否主键'
FROM
information_schema.TABLES t
LEFT JOIN
information_schema.COLUMNS c ON t.TABLE_SCHEMA = c.TABLE_SCHEMA AND t.TABLE_NAME = c.TABLE_NAME
LEFT JOIN
information_schema.KEY_COLUMN_USAGE k ON c.TABLE_SCHEMA = k.TABLE_SCHEMA
AND c.TABLE_NAME = k.TABLE_NAME
AND c.COLUMN_NAME = k.COLUMN_NAME
WHERE
t.TABLE_SCHEMA = 'your_database_name' -- 替换为你的数据库名
ORDER BY
t.TABLE_NAME, c.ORDINAL_POSITION;
二、SQL Server数据库:高效统计全库表行数
在SQL Server中,我们可以通过sys.tables、sys.columns和sys.indexes等系统视图来获取数据库信息。以下是统计SQL Server数据库所有表行数的方法: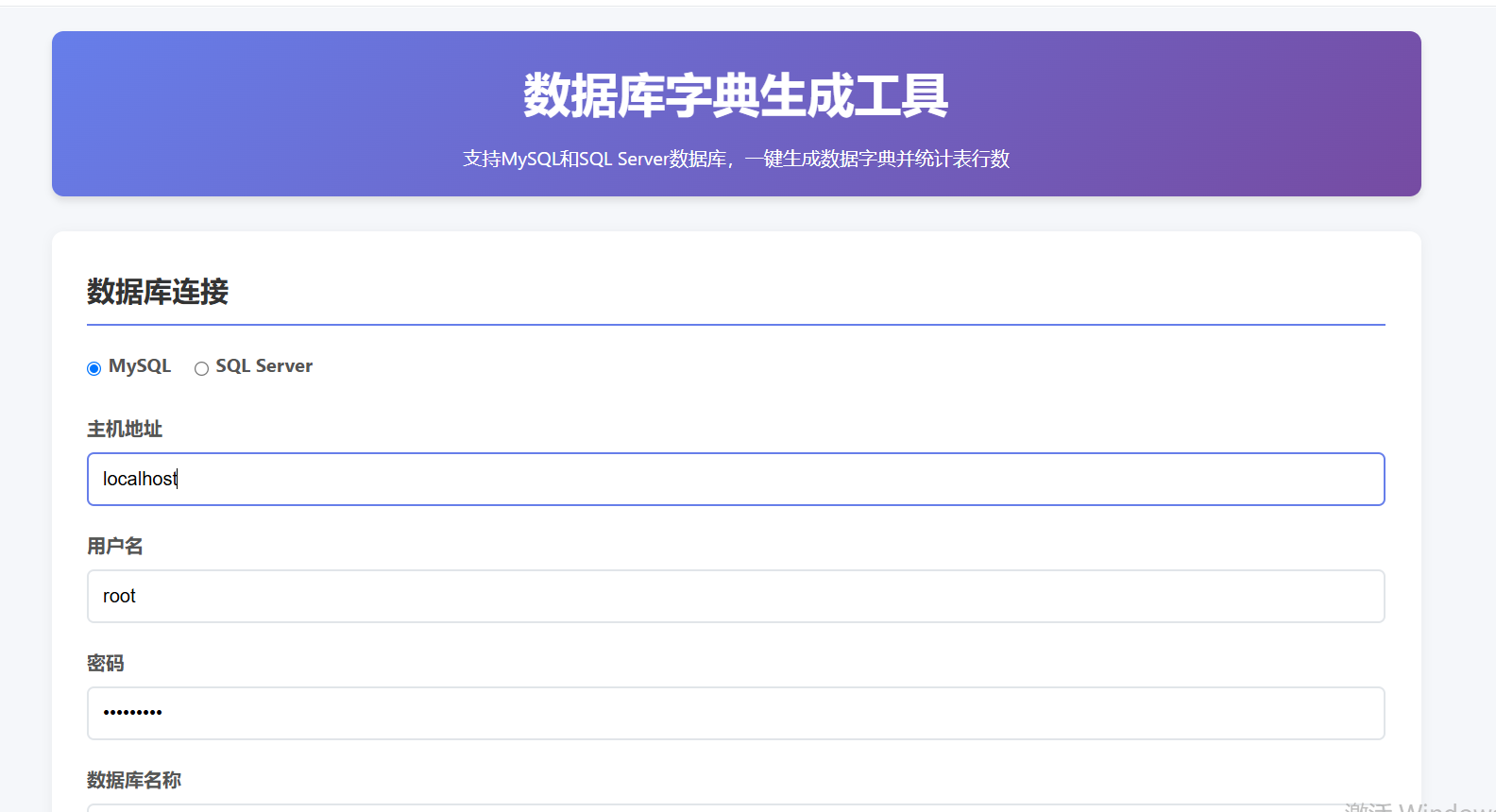
方法一:使用系统存储过程(快速但可能不准确)
EXEC sp_MSforeachtable '
DECLARE @rowcount INT;
SELECT @rowcount = COUNT(*) FROM ?;
PRINT ''表名: '' + OBJECT_NAME(OBJECT_ID(''?'')) + '' - 行数: '' + CAST(@rowcount AS VARCHAR(20));
'
注意: 这种方法虽然简单,但对于大表可能需要较长时间。
方法二:查询系统视图(推荐,更高效)
SELECT
SCHEMA_NAME(t.schema_id) AS '架构名',
t.name AS '表名',
p.rows AS '记录数',
SUM(a.total_pages) * 8 AS '总大小(KB)',
SUM(a.used_pages) * 8 AS '已用大小(KB)',
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS '未用大小(KB)'
FROM
sys.tables t
JOIN
sys.indexes i ON t.object_id = i.object_id
JOIN
sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id
JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
i.index_id IN (0, 1) -- 0=堆表,1=聚集索引
GROUP BY
SCHEMA_NAME(t.schema_id), t.name, p.rows
ORDER BY
p.rows DESC;
方法三:生成详细数据字典
SELECT
SCHEMA_NAME(t.schema_id) AS '架构名',
t.name AS '表名',
p.rows AS '记录数',
c.name AS '字段名',
ty.name AS '数据类型',
CASE WHEN c.max_length = -1 THEN 'MAX' ELSE CAST(c.max_length AS VARCHAR(10)) END AS '长度',
c.precision AS '精度',
c.scale AS '小数位数',
CASE WHEN c.is_nullable = 1 THEN '是' ELSE '否' END AS '是否允许为空',
CASE WHEN ic.is_primary_key = 1 THEN '是' ELSE '否' END AS '是否主键',
ep.value AS '字段注释'
FROM
sys.tables t
JOIN
sys.columns c ON t.object_id = c.object_id
JOIN
sys.types ty ON c.system_type_id = ty.system_type_id
LEFT JOIN
sys.index_columns ic ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN
sys.indexes ix ON ic.object_id = ix.object_id AND ic.index_id = ix.index_id
LEFT JOIN
sys.extended_properties ep ON c.object_id = ep.major_id AND c.column_id = ep.minor_id AND ep.name = 'MS_Description'
LEFT JOIN
sys.partitions p ON t.object_id = p.object_id AND p.index_id IN (0, 1)
WHERE
SCHEMA_NAME(t.schema_id) = 'dbo' -- 可以指定架构名
ORDER BY
t.name, c.column_id;
三、实用技巧与注意事项
MySQL注意事项:
TABLE_ROWS字段的值是InnoDB存储引擎的估算值,可能与实际行数有偏差- 对于精确统计,建议使用
COUNT(*)查询每个表 - 执行权限:需要有
SELECT权限访问information_schema
SQL Server注意事项:
- 系统视图中的行数也是近似值,对于频繁更新的表可能不准确
- 使用
sp_spaceused存储过程可以获取单个表的准确信息:EXEC sp_spaceused 'table_name' - 需要
VIEW DATABASE STATE权限才能查看完整信息
性能优化建议:
- 在非高峰期执行统计查询,避免影响业务系统
- 对于超大型数据库,可以分批统计或者使用定时任务
- 将统计结果保存到专门的表中,方便后续查询和分析
四、自动化脚本示例
为了方便日常使用,您可以创建一个存储过程来自动化这个任务:
MySQL存储过程示例:
DELIMITER $$
CREATE PROCEDURE GenerateTableStatistics(IN db_name VARCHAR(100))
BEGIN
SELECT
t.TABLE_NAME AS '表名',
t.TABLE_COMMENT AS '表注释',
t.TABLE_ROWS AS '记录数',
CONCAT(ROUND(t.DATA_LENGTH / 1024 / 1024, 2), ' MB') AS '数据大小',
CONCAT(ROUND(t.INDEX_LENGTH / 1024 / 1024, 2), ' MB') AS '索引大小'
FROM
information_schema.TABLES t
WHERE
t.TABLE_SCHEMA = db_name
ORDER BY
t.TABLE_ROWS DESC;
END$$
DELIMITER ;
-- 调用示例
CALL GenerateTableStatistics('your_database');
总结
通过以上SQL语句,您可以轻松地统计数据库中所有表的行数并生成数据字典。这些技巧不仅可以帮助您了解数据库的结构和数据分布,还能为数据库优化和容量规划提供重要依据。
无论是MySQL还是SQL Server,掌握这些系统表和视图的查询技巧,都能让您在数据库管理工作中事半功倍。希望这篇文章对您有所帮助!
提示: 定期执行这些统计可以帮助您监控数据库的增长趋势,及时发现异常表,为数据库维护提供数据支持。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)