Agent 落地缺个_人_?我用魔珐星云给 Agent 装上了3D身体
目录
- 前言:Agent 很聪明,但用起来很别扭
- 一、纯文本 Agent 的交互困局
- 二、给 Agent 装上身体:参数流是怎么做到的
- 三、实战:30分钟给咨询 Agent 装上3D身体
- 四、咨询场景的深度探索
- 五、关于具身 Agent 的一些思考
- 六、实际体验总结
Agent 落地缺个"人"?我用魔珐星云给 Agent 装上了3D身体
从纯文本对话到具身交互,聊聊怎么让 Agent 真正"站"到用户面前
前言:Agent 很聪明,但用起来很别扭
今年做项目最大的感受就是:Agent 越来越好用了,但用户体验越来越割裂。
我这半年做过好几个 Agent 项目——展厅问答、咨询、门店导购,底层技术其实都不差:RAG 知识库检索准确率 90% 以上,Function Calling 链路也跑通了,多轮对话逻辑也没问题。但每次给甲方演示,反馈都差不多:“功能可以,但总感觉像在跟一个输入框说话。”
这句话点出了 Agent 落地的核心矛盾:**Agent 的大脑很聪明,但它没有身体。**用户面对的仍然是一个聊天窗口、一段文字流。没有表情、没有语气、没有肢体动作,交互完全依赖用户"阅读"而非"感知"。
这不仅是体验问题,更是落地问题。展厅大屏放个聊天窗口,咨询配个文字对话框,现场体验的时候,感受不到"服务",只感受到"搜索"。
接触到魔珐星云的具身驱动 SDK后,我找到了一条把 Agent 从"文本盒子"里拉出来的路。先放一个移动端体验链接,手机打开感受一下什么叫"Agent 有了身体":
一、纯文本 Agent 的交互困局
在讲方案之前,先把问题拆清楚。纯文本 Agent 落地难,不只是"不好看"的问题,而是三个层面的交互缺陷:
1. 信息密度低,感知通道单一
人面对面交流时,信息量只有 7% 来自语言内容,38% 来自语气语调,55% 来自表情和肢体。纯文本 Agent 只用了那 7%。
举个例子,财税咨询场景里,Agent 回答"您的增值税申报需要在15号前完成",纯文本就是一行字。但如果是一个具身智能体,它可以带着表情认真地说这句话,配上轻微的点头和手指指向的手势,用户对"15号截止"这个关键信息的感知强度完全不同。
这不是锦上添花,是交互效率的本质差异。
2. 状态不可见,等待体验差
纯文本 Agent 处理复杂请求时(比如查知识库、调 API),用户只能盯着光标闪,不知道 Agent 是在思考、在查询还是卡死了。这种"黑盒等待"的体感非常糟糕。
具身智能体的解决思路很直接:让状态可见。Agent 在检索知识库时,数字人进入 `think` 状态,表情从待机切换到思考;Agent 开始回复时,数字人立刻切到 `speak` 状态,带着表情说话。用户不需要"读进度条",看数字人的状态就知道了。
3. 打断不自然,对话节奏僵硬
文本对话的打断是物理层面的——你随时可以发新消息。但在语音交互场景(展厅、大屏、机器人),打断需要"说出声音",对方需要"听到并停住"。纯文本 Agent 做不到这一点,因为它的输出通道只有文字,没有"正在说话"这个状态可以被"打断"。
这三个问题归结到一点:**纯文本 Agent 只有认知能力,没有表达能力。**它知道答案,但不知道怎么"像人一样"把答案给出去。
---
二、给 Agent 装上身体:参数流是怎么做到的
魔珐星云的思路很明确:用参数流技术把 Agent 的文本输出,实时转换成3D数字人的语音、表情和动作。
这里的"参数流"是理解整个方案的关键。我一开始也困惑——市面上数字人方案那么多,星云的区别在哪?
视频流 vs 参数流:本质区别
目前主流数字人方案走的是视频流:云端把数字人渲染成视频帧,通过网络推到前端播放。这条链路的延迟叠加非常明显——ASR 200-400ms、大模型推理 300-800ms、TTS 200-500ms、云端GPU渲染+编码 100-300ms、推流+解码 100-300ms,整个端到端普遍 2-5 秒。
星云走的是参数流:云端只计算表情参数和动作参数(几KB的数据量),传到前端由设备自己渲染。区别在哪?
视频流:云端渲染完整视频帧 → 编码 → 传输几百KB/帧 → 解码播放
参数流:云端计算表情/动作参数 → 传输几KB/帧 → 端侧实时渲染
视频流瓶颈:GPU渲染 + 带宽 + 编解码延迟
参数流优势:几KB参数 + 端侧渲染 + 无需GPU
这个架构差异带来了三个关键结果:
1. 端到端≈500ms 驱动响应:参数流把渲染从云端搬到端侧,加上数据量极小,整个链路的延迟被大幅压缩。500ms 是什么概念?真人对话的平均响应时间在 200-600ms 之间,这个数字已经接近自然对话的体感了。
2. 低延时 × 高并发 × 低成本同时成立:视频流方案里这三个指标是互斥的——低延时需要实时渲染,实时渲染要烧GPU,烧GPU就推高成本、限制并发。参数流方案下,云端不承担渲染压力,并发能力只受参数生成服务的限制,终端也只需要百元级芯片就能跑。
3. 全兼容:一套 SDK 同时适配屏幕端数字人和服务机器人两类终端,Web、Android、iOS 全覆盖。Agent 的"身体"不挑设备。
AI端渲和端侧解算:让百元芯片跑3D渲染
这是参数流能成立的技术前提。传统3D渲染需要GPU,星云的AI端渲和端侧解算技术通过算法优化,让 RK3566(720P)、RK3588(1080P)这类百元级ARM芯片就能实时渲染3D数字人。不需要游戏引擎,不需要独立GPU,参数数据到了端侧就能直接驱动渲染。
这就解决了 Agent 落地的硬件门槛问题——展厅大屏、门店POS机、桌面机器人,这些场景的终端算力有限,传统视频流方案根本跑不动,参数流方案可以。
---
三、实战:30分钟给咨询 Agent 装上3D身体
下面直接上代码。我选的场景是客服咨询——用户在大屏或手机上跟一个3D数字人对话,咨询日常问题,数字人实时回答、带表情和动作。
开发工具和模型选型
先交代技术栈,都是实际开发中用的:
- AI Coding工具:Cursor(辅助搭建前端框架和调试)+ Warp(终端命令行,写shell脚本和pnpm命令)
- 大模型:豆包 1.5 pro 作为 Agent 的对话大脑,通过 OpenAI 兼容接口对接
- 星云SDK:具身驱动 JS SDK,负责3D数字人的渲染、语音合成和状态驱动
- 前端:原生 HTML + JavaScript,保持极简,方便移植到各类终端
Step 1:星云平台配置
登录魔珐星云平台,进入控制台 → 应用管理 → 创建驱动应用。选择数字人角色、音色和表演风格,创建完成后拿到 appId 和 appSecret。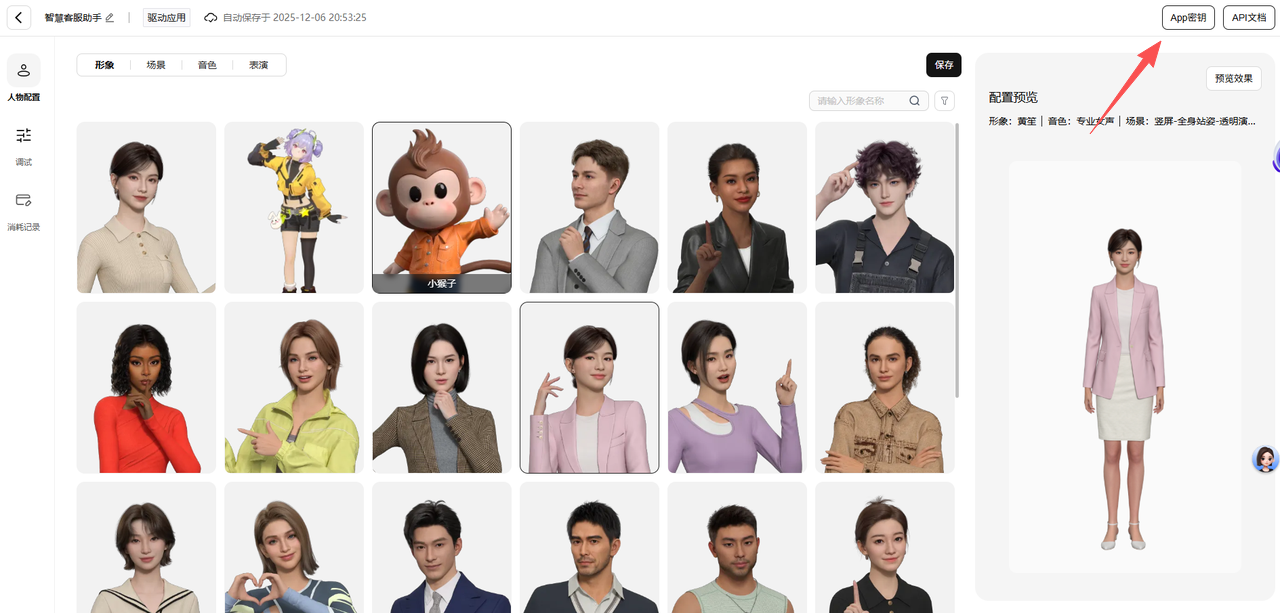
Step 2:核心Demo代码
这个Demo实现了完整的"用户提问 → Agent推理 → 数字人实时回答"链路,重点展示了如何把大模型的流式输出和星云SDK的流式speak对接起来:
引入魔珐星云SDK
SDK引入:在html文件的网页中引入 SDK 的脚本,我们需要把这个
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<!-- 页面标题 -->
<title>智慧客服助手</title>
<!-- 引入魔珐星云SDK(必须) -->
<`x`://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
</head>
<body>
<!-- Vue应用的挂载点,id必须与main.js中的选择器一致 -->
<div id="app"></div>
<!-- 由Vite构建工具自动注入模块化脚本 -->
<script type="module" src="/src/main.ts"></script>
</body>
</html>
创建SDK实例:
/**
* 魔珐星云SDK服务封装
* 参考官方文档:https://xingyun3d.com/developers/52-183
*/
class XingYunService {
constructor() {
this.sdkInstance = null
this.isInitialized = false
this.containerId = 'avatar-container'
}
/**
* 初始化星云SDK
* @param {Object} config - 配置参数
*/
async initSDK(config) {
try {
// 动态加载SDK(从你提供的CDN链接)
if (!window.XmovAvatar) {
await this.loadSDKScript()
}
// 创建SDK实例[citation:1][citation:9]
this.sdkInstance = new window.XmovAvatar({
containerId: `#${this.containerId}`,
appId: config.appId, // 替换为你的App ID
appSecret: config.appSecret, // 替换为你的App Secret
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session',
// 事件回调[citation:1][citation:6]
onStateChange: (state) => {
console.log('数字人状态变化:', state)
if (config.onStateChange) config.onStateChange(state)
},
onMessage: (message) => {
console.log('SDK消息:', message)
if (config.onMessage) config.onMessage(message)
},
onVoiceStateChange: (status) => {
console.log('语音状态:', status)
if (config.onVoiceStateChange) config.onVoiceStateChange(status)
},
// 字幕显示回调
onWidgetEvent: (data) => {
console.log('[SDK Widget事件]', data);
if (data.type === 'subtitle_on') {
if (config.onSubtitle) config.onSubtitle(data.text)
} else if (data.type === 'subtitle_off') {
if (config.onSubtitleEnd) config.onSubtitleEnd()
}
},
onMessage: (message) => {
console.log('[SDK 消息]', message);
if (config.onMessage) config.onMessage(message);
},
onStateChange: (state) => {
console.log('[SDK 状态]', state);
if (config.onStateChange) config.onStateChange(state);
},
enableLogger: process.env.NODE_ENV === 'development'
})
// 初始化连接[citation:1][citation:9]
await this.sdkInstance.init({
onDownloadProgress: (progress) => {
console.log('资源加载进度:', progress + '%')
if (config.onProgress) config.onProgress(progress)
},
onError: (error) => {
console.error('初始化错误:', error)
if (config.onError) config.onError(error)
},
onClose: () => {
console.log('连接已关闭')
if (config.onClose) config.onClose()
}
})
this.isInitialized = true
console.log('魔珐星云SDK初始化成功')
return true
} catch (error) {
console.error('初始化SDK失败:', error)
throw error
}
}
/**
* 动态加载SDK脚本[citation:1]
*/
loadSDKScript() {
return new Promise((resolve, reject) => {
const script = document.createElement('script')
script.src = 'https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js'
script.onload = resolve
script.onerror = reject
document.head.appendChild(script)
})
}
/**
* 让数字人说话
* @param {string} text - 要说的文本
* @param {boolean} isStart - 是否开始
* @param {boolean} isEnd - 是否结束
*/
speak(text, isStart = true, isEnd = true) {
if (!this.isInitialized || !this.sdkInstance) {
throw new Error('SDK未初始化')
}
this.sdkInstance.speak(text, isStart, isEnd)
}
/**
* 使用SSML控制数字人动作[citation:1]
* @param {string} text - 文本内容
* @param {string} action - 动作类型
*/
speakWithAction(text, action = 'Hello') {
const ssml = `
<speak>
<ue4event>
<type>ka</type>
<data>
<action_semantic>${action}</action_semantic>
</data>
</ue4event>
${text}
</speak>`
this.speak(ssml, true, true)
}
/**
* 断开连接
*/
disconnect() {
if (this.sdkInstance) {
this.sdkInstance.stop()
this.sdkInstance.destroy()
this.sdkInstance = null
this.isInitialized = false
}
}
/**
* 获取数字人支持的动作列表
* 注:实际应用中需要调用星云平台的KA查询接口[citation:1]
*/
getSupportedActions() {
return ['Hello', 'Goodbye', 'Agree', 'Disagree', 'Think', 'Explain']
}
}
export default new XingYunService()
初始化SDK:
连接参数:App ID、App Secret、企业级应用的凭证验证
const initAvatar = async () => {
try {
const config = {
appId: '', //换成自己的
appSecret: '', // 换成自己的// 初始化SDK
const initAvatar = async () => {
try {
const config = {
appId: '', // 替换为实际ID
appSecret: '',// 替换为实际的
onProgress: (progress) => {
loadProgress.value = progress
},
onStateChange: (state) => {
currentState.value = state
if (state === 'speak') {
isConnected.value = true
}
},
onSubtitle: (content) => {
subtitle.value = content
addMessage('avatar', content)
},
onSubtitleEnd: () => {
subtitle.value = ''
},
onError: (error) => {
console.error('SDK错误:', error)
addMessage('system', `连接错误: ${error.message}`)
}
}
await XingYunService.initSDK(config)
isConnected.value = true
addMessage('avatar', '您好!我是生活智能客服助手,很高兴为您服务。请问有什么生活上的问题需要帮助吗?')
} catch (error) {
console.error('初始化失败:', error)
addMessage('system', '初始化服务失败,请刷新页面重试。')
}
}
Step 3:核心逻辑解析
这套接口和大模型的 SSE 流式输出天然对齐——大模型每吐出一段 token,就能直接喂给 speak 驱动数字人"边想边说",不需要等整段回答生成完才开始播报。
状态变化回调 onStateChange
监听数字人状态变化(如初始化、就绪、说话中、空闲等)
将状态通过config.onStateChange传递给上层调用者,用于更新界面状态(如显示 “正在说话”)
消息回调 onMessage
接收 SDK 发送的通用消息(如系统通知、错误提示等)
通过config.onMessage转发消息,便于上层处理特定业务逻辑
**Step 4:**AI 对话服务工具
纯文字驱动只是第一步,Agent 真正"具身"的关键是语义驱动的肢体动作。星云支持 SSML 标记,可以让数字人在说话时做出特定动作:
智能对话,高效服务,随时为您解答
{{ isConnected ? ‘已连接’ : ‘连接中’ }}
<div class="main-content">
<!-- 左侧:数字人展示区 -->
<div class="avatar-section">
<div class="avatar-container">
<div :id="containerId" class="avatar-render-area"></div>
<div v-if="!isConnected" class="loading-overlay">
<div class="loading-spinner"></div>
<p>正在初始化服务...</p>
<p class="progress-text">{{ loadProgress }}%</p>
</div>
</div>
<!-- 当前状态显示 -->
<div class="avatar-status">
<div class="status-item">
<span class="status-label">服务状态:</span>
<span class="status-value">{{ currentState }}</span>
</div>
<div class="status-item" v-if="subtitle">
<span class="status-label">正在回应:</span>
<span class="status-value">{{ subtitle }}</span>
</div>
</div>
</div>
<!-- 右侧:对话交互区 -->
<div class="interaction-section">
<!-- 对话记录 -->
<div class="chat-history" ref="chatContainer">
<div
v-for="(message, index) in chatHistory"
:key="index"
:class="['message', message.type]"
>
<div class="message-content">
{{ message.content }}
</div>
<div class="message-time">
{{ message.time }}
</div>
</div>
</div>
<!-- 输入控制区 -->
<div class="input-controls">
<!-- 生活场景快速操作按钮 -->
<div class="quick-actions">
<button
v-for="action in quickActions"
:key="action.id"
class="quick-action-btn"
@click="handleQuickAction(action)"
:disabled="!isConnected"
:class="action.type === 'reset' ? 'reset-action' : ''"
>
{{ action.label }}
</button>
</div>
<div class="message-input-area">
<textarea
v-model="userInput"
placeholder="请输入您的问题..."
@keyup.enter="sendMessage"
:disabled="!isConnected"
></textarea>
<div class="input-actions">
<button
class="send-btn"
@click="sendMessage"
:disabled="!isConnected || !userInput.trim()"
>
发送消息
</button>
<select
v-model="selectedAction"
class="action-select"
:disabled="!isConnected"
>
<option value="">选择表情动作</option>
<option
v-for="action in supportedActions"
:key="action"
:value="action"
>
{{ getActionLabel(action) }}
</option>
</select>
</div>
</div>
</div>
</div>
</div>
<!-- 底部信息 -->
<footer class="footer">
<p>生活智能客服系统 | 响应迅速 < 500ms | 支持实时交互</p>
</footer>
-
核心流程:用户发送消息 → 记录对话历史 → 调用 大模型ai 生成回复 → 数字人播报回复;
-
关键联动:大模型AI回复通过XingYunService让数字人 “说出来”,同时onSubtitle回调将播报内容同步到对话框,实现「大模型AI回复→数字人播报→文字记录」的闭环。
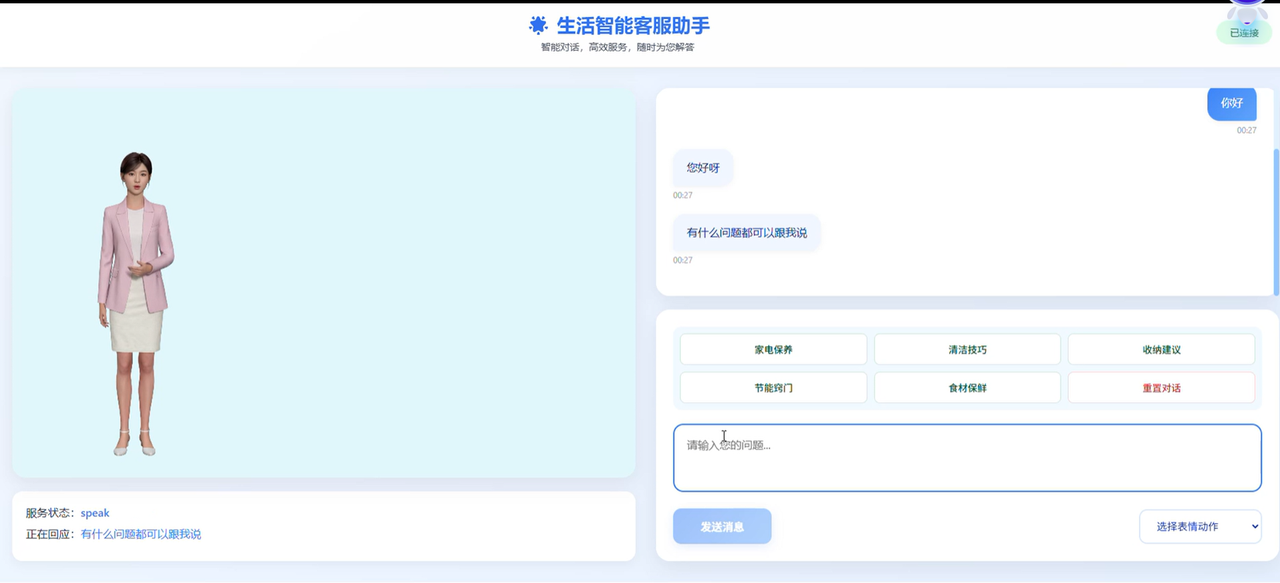
四、咨询场景的深度探索
基础 Demo 跑通后,我在财税咨询这个场景上做了更深入的探索,解决几个实际的业务问题。
1. 多轮对话的状态可见化
客服咨询经常需要多轮追问(“您需要咨询哪方面的问题?”),纯文本场景下用户不知道 Agent 还在追问还是已经结束了。星云SDK的状态管理很好地解决了这个问题:
// Agent 追问时的状态流转
async function multiTurnChat(userMessage) {
// 1. 用户说话 → 数字人倾听
sdk.listen();
// 2. 发给大模型 → 数字人思考
sdk.think();
updateStatus('thinking');
// 3. 大模型返回 → 数字人回答
// ... 流式speak逻辑同上 ...
// 4. 回答结束 → 切回待机互动状态
sdk.interactiveidle();
updateStatus('idle');
}
状态流转:listen(倾听)→ think(思考)→ speak(说话)→ interactiveidle(待机互动)。用户不需要看文字提示"正在思考",看数字人的表情切换就知道当前是什么状态。这种状态可见性在展厅大屏场景里尤其重要——用户站在大屏前,对延迟的容忍度远低于手机端。
2. 知识库 RAG + 数字人的结合
纯靠大模型做咨询风险太高(幻觉问题),实际项目必须接入专业知识库。我的方案是:
- 检索层:用户提问 → embedding 检索知识库 → 拼接相关文档片段
- 生成层:文档片段 + 用户问题 → 豆包 1.5pro生成回答
- 表达层:回答文本 → 星云SDK流式speak驱动数字人
关键代码片段——在发给大模型前先做 RAG 检索:
async function ragChat(userMessage) {
updateStatus('thinking');
sdk.think(); // 数字人进入思考状态
// RAG检索:从向量数据库召回相关文档
const docs = await retrieveFromVectorDB(userMessage);
const context = docs.map(d => d.content).join('\n');
// 拼接到prompt中发给大模型
const augmentedPrompt = `基于以下参考资料回答用户问题。
如果参考资料中没有相关信息,请如实说明。
参考资料:
${context}
用户问题:${userMessage}`;
// 后续流式speak逻辑同上...
}
这三层架构和魔珐星云平台的多模态感知层 → 大模型+智能体认知层 → 多模态具身表达层完全对应——感知用户意图,认知引擎推理,具象表达输出。Agent 从"只会思考"变成了"会思考、会表达、会交流"。
3. 打断交互的业务场景
客服咨询中打断非常常见——用户听到一半觉得理解了,想换问题;或者数字人说错了方向,用户想纠正。这要求具身智能体支持自然的打断交互:
// 用户随时打断 → 插话队列 → 平滑切换
function onUserInterrupt(newUserMessage) {
speechManager.interruptAndSpeak(
`<speak>
<ue4event>
<type>ka_intent</type>
<data><ka_intent>Nod</ka_intent></data>
</ue4event>
好的,我来为您解答这个问题。
</speak>`
);
}
这里和纯文本 Agent 的打断体验差异非常大:纯文本打断只是消息列表里多了一条,而具身智能体的打断是数字人"停住、点头、换话题"——用户能明确感知到"对方听我说了",这是拟人交互和非拟人交互的分水岭。
4. 硬件部署实测
这是最让我意外的部分。我拿一块 RK3588 开发板(市场价约200元)跑这个财税咨询 Demo,1080P 渲染流畅无卡顿。不需要GPU,不需要游戏引擎,参数流数据量小到弱网环境也能跑。
对比一下传统视频流方案在财税咨询场景的部署成本:
| 项目 | 视频流方案 | 星云参数流方案 |
|---|---|---|
| 服务端GPU | 每路并发约需0.1块A100 | 无需GPU渲染 |
| 带宽 | 5Mbps/路,专线网络 | 几十Kbps/路,普通宽带 |
| 终端硬件 | 需GPU或高性能解码器 | RK3566(720P)/ RK3588(1080P) |
| 单终端成本 | 约5000元+ | 约200元(开发板级别) |
百元级硬件芯片即可部署运行,这是参数流方案在落地场景里最大的优势——终端成本几乎可以忽略不计。
---
五、关于具身 Agent 的一些思考
做完这个项目,我对"具身 Agent"有了更具体的理解。
今年 Agent 赛道最火的概念是 MCP(Model Context Protocol)和 Function Calling,本质上都在解决 Agent "能做什么"的问题——连接外部工具、调用API、操作数据。但很少有人在解决 Agent "怎么呈现"的问题。
纯文本 Agent 的交互模型本质上还是"终端命令行"——用户输入指令,系统返回结果,只是从精确匹配变成了自然语言理解。而具身智能体把交互模型拉到了"面对面对话"的层级——有表情反馈、有肢体动作、有状态可见性、有自然打断。
魔珐星云在这个链条里的位置很清晰:**它不做Agent的"大脑"(那是大模型的事),它做Agent的"身体"——把文本输出实时转换成3D具象的拟人交互形态。**参数流技术是这个方案的技术底座,AI端渲和端侧解算保证了硬件门槛极低,端到端≈500ms 保证了交互体感接近真人。
从技术架构看,星云的三层设计(多模态感知层 → 大模型+智能体认知层 → 多模态具身表达层)是在做端到端的协同优化。不是简单地把文字转语音再配个3D模型播动画,而是让语义理解、语音合成、表情生成、动作驱动在同一个参数流管线里同步进行。所以数字人说话时表情和语音是同步的,打断时动作和状态是连贯的——这些细节决定了交互是"像真人"还是"像读稿器"。
---
六、实际体验总结
这个咨询具身 Agent 从零搭建到完整跑通,花了大约一天。Cursor 帮我快速搭了前端界面和调试联调,Warp 处理构建命令和依赖安装,核心的星云SDK对接部分参考官方的"从零到一教学"文档,API 设计比较简洁——实例化、初始化、speak,三个核心步骤就跑通了。
说几个实际体验中感受最深的点:
1. 交互体感确实是质变。500ms 端到端响应在实际使用中的感受和2秒延迟完全不是一个量级。在展厅大屏场景里,用户说完话数字人几乎是即时回应,不需要"等"。这种体感差异很难用数据传达,必须亲自试。
2. SDK 的全兼容性省了大量适配工作。一套SDK同时适配屏幕端数字人和服务机器人两类终端,Web、Android 都覆盖。同一个Agent逻辑,换一个终端只需要换个容器,不用重写交互层。
3. 硬件门槛真的低到可以规模化铺开。百元级芯片就能跑1080P渲染,这对多终端部署的项目来说意味着终端成本几乎可以忽略。做10个展厅的部署,省下来的硬件费用就够覆盖平台服务费了。
需要注意的几个点:SDK 要求 localhost 或 https 环境才能调用,本地开发时用 IP 地址访问会报 VideoDecoder is not defined;首次连接需要加载角色资源有几秒等待(后续连接会快);频繁刷新页面会触发"10005 房间限流"报错,需要在 beforeunload 里调用 sdk.destroy() 释放连接。
总的来说,如果你在做 Agent 落地项目,并且场景涉及面对面交互(展厅、咨询、导览),魔珐星云值得认真评估。它解决的不是"Agent 能不能回答"的问题,而是"Agent 怎么把回答给出去"的问题——纯文本交互生硬、无拟人反馈的行业痛点,参数流+AI端渲给出了一条可行的解法。具身智能交互,可能是 Agent 从"好用"到"愿意用"的关键一步。
相关参考资源:
-
SDK文档:https://xingyun3d.com/developers/52-183
-
从零到一教学:https://xingyun3d.com/developers/52-194
-
JS SDK Demo:https://xingyun3d.com/developers/52-187

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)