SL-YOLO:一种更强更轻量的无人机目标检测模型
论文信息
标题:SL-YOLO:一种更强更轻量的无人机目标检测模型
作者:陈德凡(深圳大学)、张路婵(深圳大学)
论文链接:https://arxiv.org/pdf/2411.11477
摘要
在复杂场景中检测小目标(如无人机拍摄的图像)是一项艰巨的挑战,因为难以捕捉小目标的复杂特征。虽然YOLO系列在大目标检测方面取得了巨大成功,但在面对小目标时,其性能却不尽如人意。因此,本文提出了一种革命性模型SL-YOLO(Stronger and Lighter YOLO,更强更轻量的YOLO),旨在打破小目标检测的瓶颈。我们提出了分层扩展路径聚合网络(Hierarchical Extended Path Aggregation Network,HEPAN),这是一种开创性的跨尺度特征融合方法,即使在最具挑战性的环境中也能确保无与伦比的检测精度。同时,在不牺牲检测能力的前提下,我们设计了C2fDCB轻量级模块,并添加了SCDown下采样模块,大幅减少了模型的参数量和计算复杂度。我们在VisDrone2019数据集上的实验结果表明,性能有了显著提升,mAP0.5_{0.5}0.5从43.0%跃升至46.9%,mAP0.5:0.95_{0.5:0.95}0.5:0.95从26.0%增至28.9%。同时,模型参数从11.1M减少到9.6M,FPS可达132,使其成为资源受限环境中实时小目标检测的理想解决方案。
1. 引言
随着无人机技术的快速发展,航拍已成为灾害监测、交通管理、搜救和农业监管等关键领域的重要工具。与传统地面方法相比,无人机图像提供了高空视角、广泛覆盖范围和更低的运营成本。然而,无人机图像中的小目标检测面临着重大挑战,包括复杂的背景、低对比度物体和动态环境条件,这些往往导致检测错误和漏检[31, 37]。实现实时、准确的检测对于使无人机在各种应用中有效运行至关重要。例如,在灾害响应中,精确检测可以识别幸存者或危险;在农业中,检测小异常可以带来更好的作物管理。通过解决这些限制,无人机可以在复杂和苛刻的条件下可靠高效地运行,最大限度地发挥其潜力。
现有的目标检测方法大致分为两类:R-CNN系列两阶段模型[9, 10, 26]和单阶段YOLO系列[1,6,16,17,24,25,33,35,36]。YOLOv8在速度和精度之间取得了强有力的平衡,使其在许多应用中广受欢迎。然而,在复杂场景中的小目标检测方面,它仍然存在困难。最近的许多研究尝试通过多尺度特征融合、注意力机制[32]和轻量级设计来解决这一问题。经典方法如特征金字塔网络(FPN)[19]、路径聚合网络(PAN)[20]和最近的BiFPN[30]优化了多尺度特征处理。然而,即使有了这些进步,无人机图像中的小目标检测仍然具有挑战性。MobileNets[13, 14, 27]、ShuffleNets[23, 40]和EfficientNets[28, 29]等轻量级模型在保持精度的同时降低了计算成本,但在基于无人机的小目标场景中表现不佳。
通过克服现有模型的局限性,我们的研究提出了一种更强、更轻量的模型SL-YOLO,该模型基于YOLOv8s,在复杂条件下和资源受限设备上处理小目标检测。该模型不仅打破了传统无人机目标检测的边界,还为动态复杂环境中智能实时监控的新时代铺平了道路,使其能够在实际应用中发挥有意义的作用。具体来说,我们提出了分层扩展路径聚合网络(HEPAN),它可以更好地融合不同层次的特征,从而提高模型捕获小目标的能力。此外,我们设计了C2fDCB轻量级模块,通过优化网络的卷积结构,减少了模型参数数量和计算复杂度。本研究的主要贡献如下:
· 增加小目标检测头。针对YOLOv8在无人机图像中小目标检测效果较差的问题,本文增加了一个专门用于小目标检测的额外检测层。该层通过融合浅层和深层特征信息,显著增强了模型捕获小目标的能力。
· 优化网络结构。我们提出了分层扩展路径聚合网络(HEPAN),以进一步增强融合不同层次特征的能力。在HEPAN中,我们在网络结构的中间层添加了额外的卷积层,并使用残差连接来加强梯度流。它显著增强了模型捕获小物体的能力,减少了漏检和误检的可能性。
· 引入轻量级设计。在本文中,我们通过综合深度可分离卷积[2]和RepVGG重参数化方法[3]设计了C2fDCB轻量级模块,以提高C2f模块的计算效率。同时,引入了SCDown下采样模块,以减少模型参数数量和计算开销。因此,该模型能够在资源受限的环境中高效运行,同时保持高检测精度。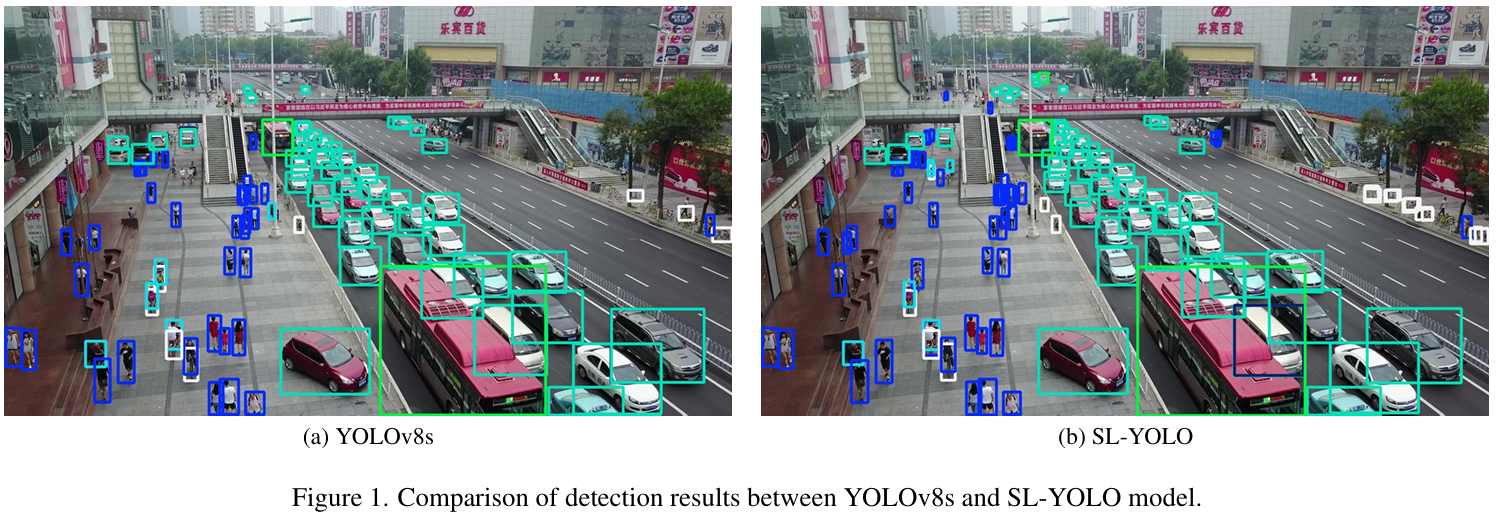
通过对VisDrone2019数据集[4]的实验验证,本文提出的SL-YOLO模型在mAP和其他关键评估指标上有了显著改进,证明了该模型能够在有限资源条件下实现良好的检测性能。在图1中,我们展示了YOLOv8s(图1(a))与我们的SL-YOLO(图1(b))在小目标检测方面的性能对比。可以清楚地看到,SL-YOLO能够更准确地识别复杂背景中的小目标,显著减少了漏检和误检,从而验证了我们SL-YOLO模型的有效性。
2. 相关工作
目标检测的一个难点是检测不同尺度的目标,特别是小目标。小目标具有较少的特征信息,在深度卷积神经网络的池化和下采样过程中容易丢失。为此,研究人员提出了多尺度特征融合技术,以确保网络能够有效检测不同大小的目标。早期的目标检测模型,如RCNN[10]和Fast RCNN[9],通常使用单尺度特征图,导致检测性能有限。Faster RCNN[26]引入了区域建议网络(RPN),但仍依赖于固定尺度的特征。特征金字塔网络(FPN)[19]通过多分辨率特征图实现多尺度检测,增强了小目标检测能力,成为多尺度特征融合的经典之作。路径聚合网络(PANet)[20]通过添加自下而上的路径来增强低级和高级特征的融合,从而改进了FPN。自适应空间特征融合(ASFF)[21]通过在每个尺度上自适应选择代表性空间特征来优化特征选择。NAS-FPN[8]使用神经架构搜索自动识别最佳融合策略,但这种方法显著增加了计算成本。加权双向特征金字塔网络(BiFPN)[30]通过结合可学习的加权机制来平衡不同特征层次的贡献,实现了更有效的融合过程。
近年来,轻量级网络设计方面取得了一些重要进展,为资源受限环境中的深度学习应用提供了有效解决方案。ResNet[12]通过残差连接解决了梯度消失问题;DenseNet[15]通过密集连接促进特征重用,从而减少模型参数并提高性能;ResNeXt[38]引入了"分组卷积"和"乘积"概念,通过增加基数来强调结构多样性并提高模型性能。MobileNet[14]使用深度可分离卷积显著减少计算量,适用于移动设备等场景;ShuffleNet[23]结合通道混洗和分组卷积,实现高效的特征学习;EfficientNet[28]通过复合缩放优化网络的宽度、深度和分辨率,成为轻量级设计的基准。CSPNet[34]通过特征图分离和跨阶段连接减少计算量并提高模型表达能力;GhostNet[11]的"Ghost"模块进一步提高了特征表示能力;RepVGG[3]通过推理阶段的模块转换显著减少了推理的计算开销。这些网络的设计理念相互借鉴和创新,促进了深度学习模型实际应用的发展。
YOLO(You Only Look Once)作为一种实时目标检测模型,自2016年提出以来已成为计算机视觉的重要基准之一。YOLOv1[22,24]将目标检测视为回归问题,通过单个神经网络直接预测边界框和类别标签,显著提高了检测速度,但其小目标检测能力有限。YOLOv2[25]引入多尺度检测和锚框机制,提高了模型精度;YOLOv3[6]使用残差网络结构增强小目标检测能力,并在速度和精度之间取得平衡。YOLOv4[1, 7,39, 41]结合CSPDarknet和多种数据增强技术,进一步提高了检测性能。后续改进版本(YOLOv5、YOLOv6[17]、YOLOv7[35]、YOLOv8[16]、YOLOv9[36]和YOLOv10[33])在易用性和模型轻量化方面进行了创新,使该模型广泛应用于自动驾驶、安全监控和医学图像分析等多个领域。未来研究将继续关注提高模型的鲁棒性和准确性,以应对更复杂的场景和任务需求。
3. 方法论
在本节中,我们将详细介绍SL-YOLO模型的网络设计。我们的目标是改进YOLOv8s模型的检测性能,特别是在无人机图像中具有挑战性的小目标检测任务上。我们通过专注于优化多尺度特征融合机制和引入轻量级模块,突破了小目标检测的极限。这些创新使模型能够更好地捕获小目标的关键特征信息,同时在复杂和杂乱的背景中保持出色的精度。在以下小节中,我们将深入探讨这些增强的核心方面,并探索其详细实现。我们增强网络的整体结构如图2所示。它由三个主要组件组成:骨干网络(Backbone)、颈部(Neck)和头部(Head)。骨干网络包括标准卷积(Conv)、C2f和我们的轻量级C2fDCB模块,负责特征提取和压缩。颈部使用分层扩展路径聚合网络(HEPAN)来融合多尺度特征,增强小目标检测。头部包含四个不同尺度的检测层,确保模型能够准确识别多尺度物体。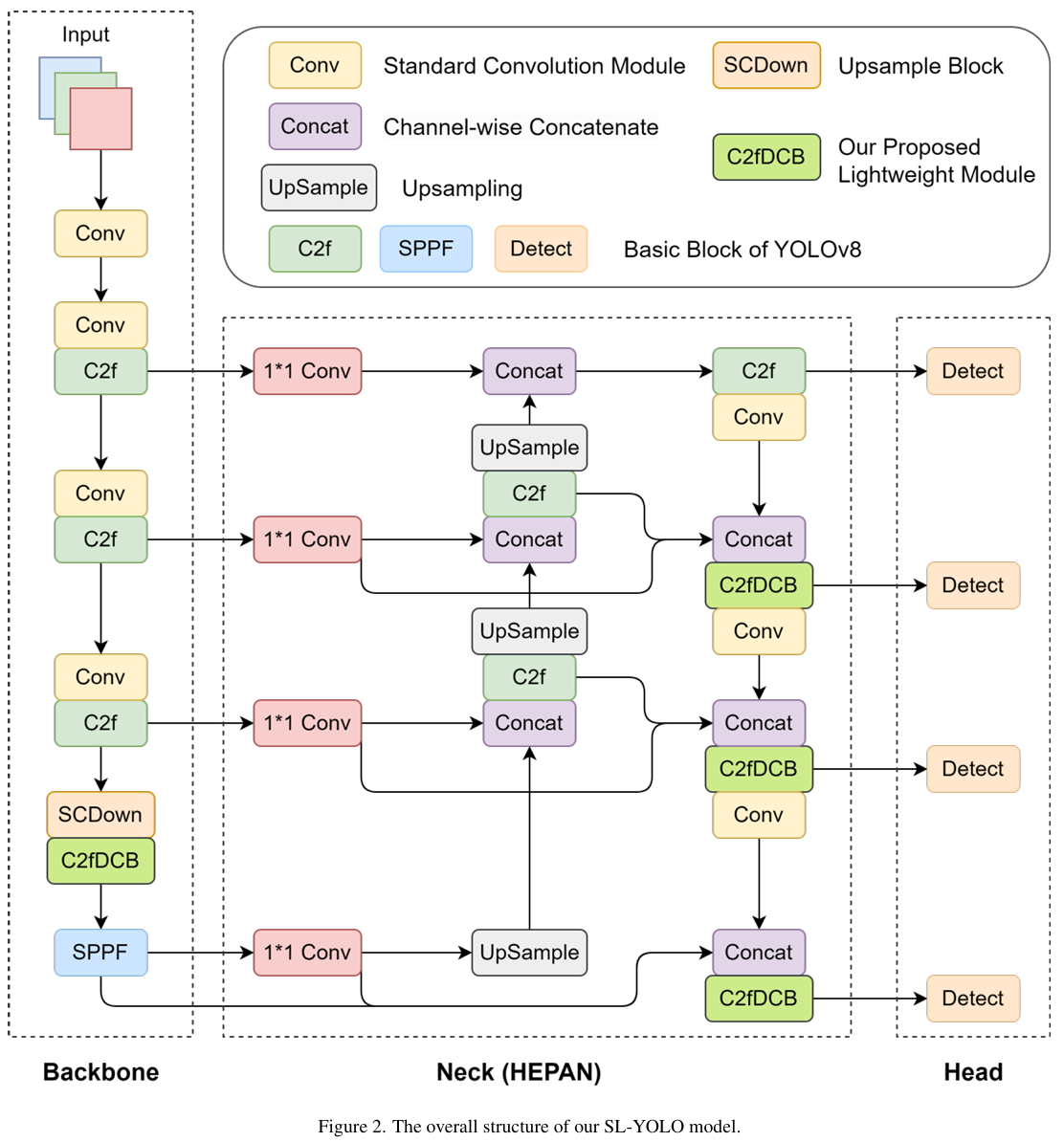
3.1 增加小目标检测头
在本研究中,我们首先应用了一种常见的改进方法来解决YOLOv8在无人机航拍图像中小目标检测效果差的问题——增加一个小目标检测层。在有许多小目标的无人机航拍图像中,虽然YOLOv8在常见目标检测场景中表现良好,但其卷积特征提取机制在处理小目标时面临重大挑战。随着网络深度的增加,小目标的信息在深层特征中逐渐丢失。为此,我们在YOLOv8模型中引入了一个新的小目标检测层,旨在通过整合浅层和深层特征来增强小目标的检测能力。具体而言,我们在网络的颈部结构中进行上采样,生成更高分辨率(160x160)的特征图,并将其与骨干网络的输出融合,以提高小目标的特征捕获能力。这种方法能够改善小目标的检测效果,并增强模型的适应性。
3.2 优化网络结构
YOLOv8的整体结构采用路径聚合网络(PANet),如图3(a)所示。该结构的骨干网络包含多个卷积层,逐渐增加特征图的深度和分辨率,使模型能够有效捕获不同层次的特征信息。然而,在实际应用中,YOLOv8在处理小目标时表现出一定的缺陷。主要原因是特征融合效果不理想,低级特征(如小目标的细节信息)和高级特征(如全局上下文信息)的整合不足,导致模型在小目标检测中的准确率和召回率有限。这种限制显著影响了模型在复杂场景中的性能,特别是在场景中目标数量大但小目标占比较小的情况下。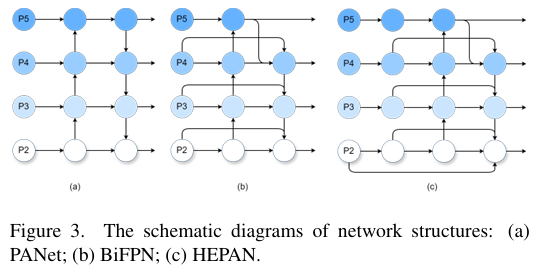
为了解决这些限制,Li[30]提出了加权双向特征金字塔网络(BiFPN),如图3(b)所示。BiFPN结构的核心在于其双向信息流设计,使模型能够同时利用不同尺度的特征。具体而言,该结构通过跨层连接和融合操作增强低级特征和高级特征之间的交互,并提高小目标的特征表达能力。此外,BiFPN通过在特征融合过程中自适应加权不同层次的特征,确保更重要的特征在融合过程中占主导地位。这种设计不仅提高了小目标的检测能力,还提高了模型在复杂场景中的整体性能。
我们进一步优化了特征融合机制,并通过引入高效的分层扩展路径聚合网络(HEPAN)实现了更细致的特征连接和信息流,如图3©所示。在HEPAN结构中,我们在颈部引入了额外的卷积层,以进一步增强特征提取和表达能力,并引入了残差连接,以提高梯度流的稳定性。与传统的PAN和BiFPN结构相比,HEPAN能够显著提高小目标检测的准确性,特别是在复杂背景环境中。
3.3 改进轻量级模块
在小目标检测任务中,模型的计算复杂度和参数大小对实时性能和效率有着至关重要的影响,特别是在部署在资源受限设备上时。因此,模型的轻量化设计已成为提高检测速度和降低功耗的关键环节。我们从轻量化角度优化了模型设计,旨在减少冗余计算的同时保持出色的检测性能。通过设计新的特征提取模块,显著减少了模型参数数量和计算成本。
3.3.1 C2fDCB
YOLOv8中的C2f模块通过通道特征融合技术建立特征图之间的连接,有效整合了不同层次的特征信息。然而,在参数效率和降低计算复杂度方面仍有改进空间。我们通过将深度可分离卷积与经典的C2f模块相结合,设计了C2fDCB模块,进一步减少了参数和计算复杂度,同时保持了特征的丰富性。与传统卷积层相比,这种设计使模型在小目标检测任务中实现轻量化,同时仍能捕获关键特征,使其适用于资源受限的无人机环境。具体而言,不考虑偏置,传统卷积操作的参数数量和计算复杂度可以通过公式(1)和(2)分别计算。深度可分离卷积的参数数量和复杂度低于传统卷积,可以通过公式(3)和(4)分别计算。
Pconv=K12⋅Cin⋅CoutP_{conv}=K_{1}^{2}\cdot C_{in}\cdot C_{out}Pconv=K12⋅Cin⋅Cout
Fconv=K12⋅Cin⋅Cout⋅H⋅WF_{conv}=K_{1}^{2}\cdot C_{in}\cdot C_{out}\cdot H\cdot WFconv=K12⋅Cin⋅Cout⋅H⋅W
Pdconv=K22⋅Cin+K32⋅Cin⋅CoutP_{dconv}=K_{2}^{2}\cdot C_{in}+K_{3}^{2}\cdot C_{in}\cdot C_{out}Pdconv=K22⋅Cin+K32⋅Cin⋅Cout
Fdconv=K22⋅Cin⋅H⋅W+K32⋅Cin⋅Cout⋅H⋅WF_{dconv}=K_{2}^{2}\cdot C_{in}\cdot H\cdot W+K_{3}^{2}\cdot C_{in}\cdot C_{out}\cdot H\cdot WFdconv=K22⋅Cin⋅H⋅W+K32⋅Cin⋅Cout⋅H⋅W
其中,K1=3K_{1}=3K1=3是标准卷积的核大小,K2=3K_{2}=3K2=3和K3=1K_{3}=1K3=1分别是深度卷积和点卷积的核大小。CinC_{in}Cin和CoutC_{out}Cout分别是输入和输出通道的数量,H和W是输出特征图的高度和宽度。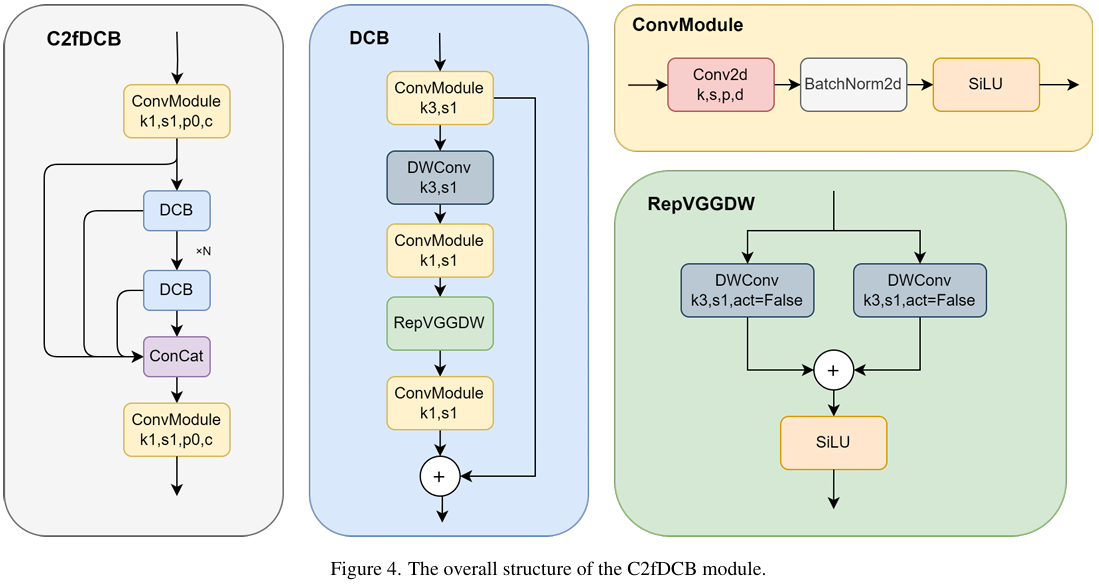
深度卷积块(DCB)是C2fDCB模块的核心组件,如图4所示。它展示了SL-YOLO中C2fDCB模块的结构,包括深度可分离卷积和RepVGGDW卷积等关键组件。DCB模块从3x3标准卷积开始,用于保持模型的特征提取能力。标准卷积通过应用多个卷积核,使模型能够捕获输入特征中的局部模式和结构信息,为后续特征处理奠定基础。接下来,模块引入了逐通道卷积,对每个输入通道独立应用卷积核,有效降低了计算复杂度。随后,使用点卷积来整合不同通道的特征。通过1x1卷积操作,点卷积可以有效混合来自每个通道的信息,从而提高特征表示的丰富性和表达能力。这一层的设计确保了通道间的信息流,使模型能够学习更复杂的特征。最后,模块中引入了RepVGGDW卷积。该卷积结合了深度可分离卷积的优势,进一步降低了计算复杂度,同时保持了高性能的特征提取能力。
3.3.2 SCDown
SCDown模块由两个主要卷积层组成,旨在高效地减少特征图的空间和通道维度。第一个卷积层使用1x1卷积核,将输入特征图的通道数从c1压缩到c2。这一过程不仅减少了后续计算的复杂性,还使模型能够关注更关键的特征信息。第二个卷积层进一步处理通道压缩后的特征图。该层使用kxk卷积核和步长s,实现逐通道卷积以提高计算效率。通过调整空间维度,可以有效地下采样特征图,增强模型捕获不同尺度信息的能力。
4. 实验
4.1 数据集
在本文中,我们使用VisDrone2019数据集[4],这是由天津大学和其他团队开发的大规模无人机视角数据集。它主要用于目标检测,包含带有相应标注的图像,分为训练集(6471张图像)、验证集(548张图像)、测试集(1610张图像)和竞赛集(1580张图像)。图像尺寸范围从2000×15002000\times15002000×1500到480×360480\times360480×360。由于无人机视角,该数据集与MS COCO[18]和VOC2012[5]等地面级数据集在角度、内容、背景和光照方面有所不同。它涵盖了各种光照条件下的街道、公园和学校等场景,并标注了10种目标类型,包括行人、汽车和自行车。
4.2 实验环境
在本实验中,我们选择Ubuntu 24.04.1作为操作系统,计算环境使用Python 3.10.14、PyTorch 2.3.1和Cuda 11.8。在硬件方面,我们使用了NVIDIA RTX 6000 Ada显卡。神经网络的实现基于Ultralytics提供的YOLOv8官方代码,并进行了相应修改。为确保实验的可重复性,训练、测试和验证过程中使用的超参数保持一致。具体设置为训练600个epoch,输入图像大小调整为640x640。所有网络都使用预训练权重yolov8s.pt进行训练,在测试过程中使用单张图像进行速度测量(bs=1)({\mathsf{bs}}{=}1)(bs=1)。
4.3 与其他模型的比较
表1显示了各种YOLO版本在VisDrone2019-val数据集上的实验结果,包括mAP0.5(%)\mathrm{mAP_{0.5}(\%)}mAP0.5(%)、mAP0.5:0.95(%)\mathrm{mAP_{0.5:0.95}(\%)}mAP0.5:0.95(%)、参数数量(M)、计算量(GFLOPs)和单图像推理速度(FPS)。从表中结果可以看出,SL-YOLO在多个指标上表现良好,特别是在mAP和推理速度方面。具体而言,SL-YOLO在mAP0.5\mathrm{mAP_{0.5}}mAP0.5和mAP0.5:0.95\mathrm{mAP_{0.5:0.95}}mAP0.5:0.95方面分别达到46.9%和28.9%,比其他模型具有更高的检测精度。与标准YOLOv8s(43.0%,26.0%)相比,SL-YOLO的mAP提高了近4个百分点,显示了其在精度方面的显著优势。此外,SL-YOLO在推理速度方面也表现出色,FPS达到132,接近YOLOv8s(163)和YOLOv8s-p2(139)等轻量级模型,而其性能优势体现在更低的参数量(9.6M)和计算复杂度(36.7GFLOPs)上,展示了其高效的计算和推理能力。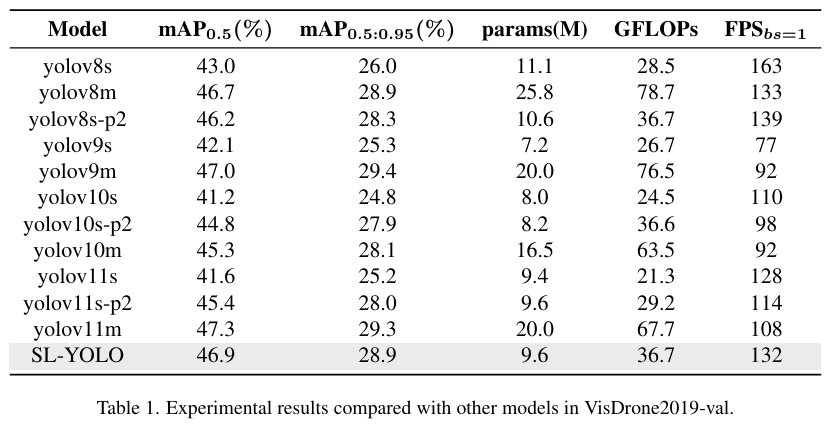
表2显示了各种YOLO版本在VisDrone2019-test数据集上的实验结果。从表中数据可以看出,SL-YOLO\mathrm{SL\text{-}YOLO}SL-YOLO的mAP0.5\mathrm{mAP_{0.5}}mAP0.5达到38.3%,与其他YOLO模型相比处于领先地位,仅略低于YOLOv9m(38.9%)和YOLOv11m(38.8%),但其参数量(9.6M)和计算复杂度(36.7 GFLOPs)远低于这两者(分别为20.0M和67.7 GFLOPs)。相比之下,SL-YOLO的计算效率更为突出,与YOLOv8s-p2\mathrm{YOLOv8s}\text{-}\mathrm{p}2YOLOv8s-p2具有相同的计算复杂度,但精度更高(37.4%对38.3%)。此外,SL-YOLO\mathrm{SL}\text{-}\mathrm{YOLO}SL-YOLO在参数量方面也具有优势,几乎与YOLOv8s-p2(10.6M)相同,但其精度有了显著提高。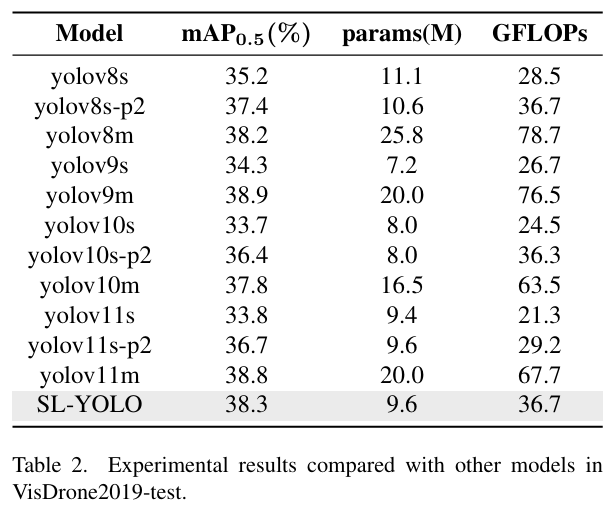
总之,SL-YOLO在精度和速度之间找到了良好的平衡。它是该任务中最高效和优秀的模型之一,特别适用于对实时性能和精度要求较高的场景。
4.4 消融实验
为了进一步验证所提出算法的有效性,在VisDrone-2019验证集上进行了消融实验。以YOLOv8s为基线模型,逐步添加本文中提到的各种改进方法,以验证每种方法对目标检测性能的改进。表3给出了在VisDrone-2019验证数据集上进行的消融实验结果。实验涉及将各种改进逐渐添加到基础YOLOv8s模型中,包括添加P2层小目标检测头、HEPAN结构、C2fDCB模块、SCDown以及这些改进的组合。从表中可以看出,基础YOLOv8s模型在实验中获得mAP0.5\mathrm{mAP_{0.5}}mAP0.5为43.0%,mAP0.5:0.95\mathrm{mAP_{0.5:0.95}}mAP0.5:0.95为26.0%,参数数量为11.1M,GFLOPs为28.5。在基线模型中添加P2层后,mAP0.5\mathrm{mAP_{0.5}}mAP0.5增加到46.2%(+3.2%),mAP0.5:0.95\mathrm{mAP_{0.5:0.95}}mAP0.5:0.95增加到28.3%(+2.3%),参数数量从11.1M减少到10.6M,GFLOPs增加到36.7。这表明添加小目标层显著提高了检测精度,特别是小目标的检测能力,但计算量增加了。进一步改进为HEPAN结构后,mAP0.5\mathrm{mAP_{0.5}}mAP0.5进一步增加到47.2%(+1.0%),mAP0.5:0.95\mathrm{mAP_{0.5:0.95}}mAP0.5:0.95增加到29.1%(+0.8%),参数数量增加到11.3M,GFLOPs为38.1。这一结果证明了HEPAN结构进一步提高了整体网络性能,特别是高IoU阈值下的性能。将C2f模块替换为C2fDCB后,mAP0.5\mathrm{mAP_{0.5}}mAP0.5略微下降到47.0%(-0.2%),mAP0.5:0.95\mathrm{mAP_{0.5:0.95}}mAP0.5:0.95保持在29.1%,参数数量减少到10.6M,GFLOPs也减少到37.3。虽然精度略有下降,但模型变得更轻量,参数数量和计算量都减少了。最后,在将下采样模块替换为SCDown模块后,模型的mAP0.5\mathrm{mAP_{0.5}}mAP0.5为46.9%,mAP0.5:0.95\mathrm{mAP_{0.5:0.95}}mAP0.5:0.95为28.9%,参数数量显著减少到9.6M(−1.0M)9.6\mathrm{M}\mathrm{(-}1.0\mathrm{M})9.6M(−1.0M),GFLOPs减少到36.7(-0.6),显示了SCDown模块在简化模型结构方面的优势。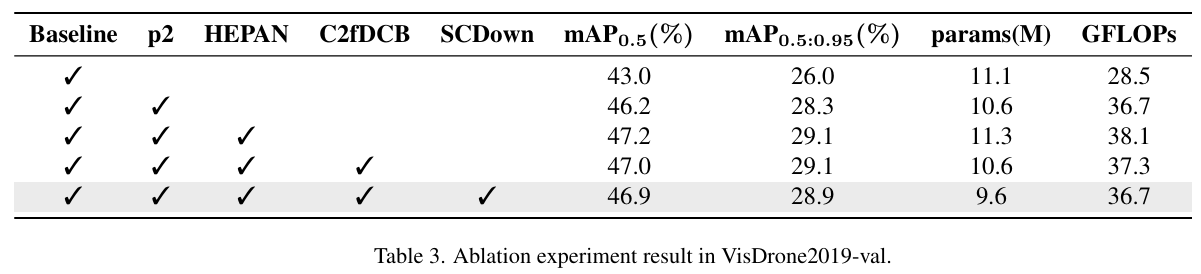
不同网络结构的分析。在表4中,比较了在VisDrone2019-val数据集上使用PAN、BiFPN和HEPAN三种网络结构的模型性能。HEPAN结构实现了最高的检测效果,达到mAP0.5\mathrm{mAP_{0.5}}mAP0.5(47.2%),参数大小为11.3M,GFLOPs为38.1,优于PAN和BiFPN结构(分别为46.2%和46.4%)。虽然HEPAN的计算复杂度略高,但性能提升显著。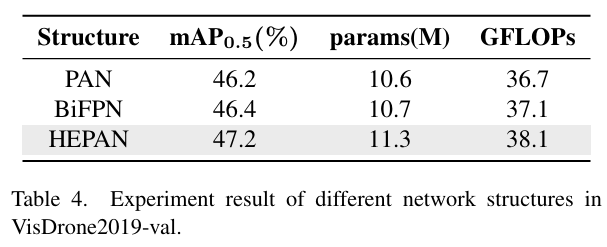
不同模块的分析。表5比较了分别使用C3、C2f和C2fDCB模块的效果。C2f模块实现了最高的mAP0.5_{0.5}0.5(47.2%),参数为11.3M,GFLOPs为38.1。相比之下,C2fDCB具有略低的参数和计算量(10.6M和37.3 GFLOPs),但其性能略低,达到mAP0.5\mathrm{mAP_{0.5}}mAP0.5为47.0%。这表明C2f模块在性能和计算之间具有良好的平衡。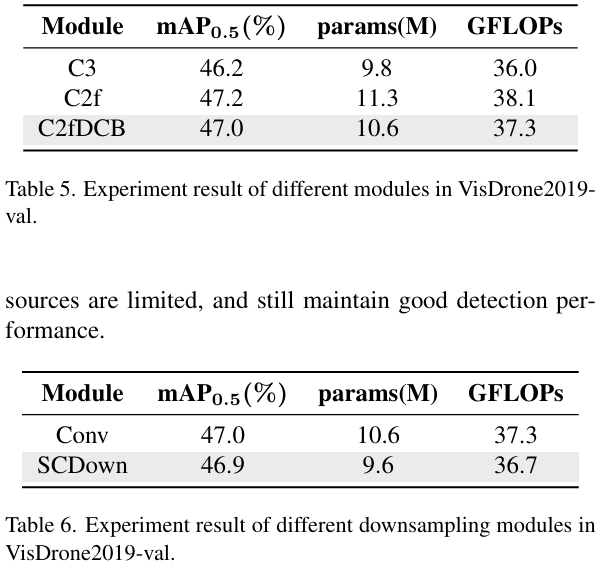
不同下采样模块的分析。实验结果如表6所示。虽然Conv模块在mAP0.5\mathrm{mAP_{0.5}}mAP0.5方面略优于SCDown,但两者之间的性能差距几乎可以忽略不计。然而,SCDown模块在参数数量和计算复杂度方面都优于Conv。因此,在实际应用中,尤其是在资源有限的情况下,选择SCDown模块可能会带来更好的平衡,同时仍能保持良好的检测性能。
5. 结论
在本文中,我们提出了SL-YOLO模型,这是一种用于复杂环境中无人机目标检测的更强、更轻量的模型。SL-YOLO结合了分层扩展路径聚合网络(HEPAN)以改进跨尺度特征融合,增强小目标精度,同时结合C2fDCB和SCDown模块以减少参数和计算负载,同时保持高性能。SL-YOLO的设计使无人机能够在复杂环境中高效检测小目标,为灾害响应和智能监控等关键任务提供坚实支持。未来,我们计划进一步优化SL-YOLO的跨场景适应性,使其在更多不同场景中展示出色的小目标检测性能,为无人机领域的智能化发展提供更多可能性。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 36
36 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)