【深度学习-最简单的回归项目】新冠疫情预测
文章目录
一.回归任务框架
1.数据
【腾讯文档】covid.train
https://docs.qq.com/sheet/DYkxYVWtmUVNaRmZw
数据的划分包括:
(1)训练集:通过训练优化模型
(2)验证集:仅仅做验证,而不优化模型
(3)测试集:在训练模型过程中模型从未见过的数据,用于验证模型的泛化能力
2.模型
输入X得到预测值Y
3.超参
超参一般包括:学习率、优化器和损失函数,为人为设定不可修改
4.训练流程
用上以上三部分,形成一个用于训练和测试模型的程序
一般而言,项目的2、3部分高度相似,仅仅在数据处理部分有较大差别
二.项目简介
美国有40个州, 这四十个州呢 ,统计了连续三天的新冠阳性人数,和每天的一些社会特征,比如带口罩情况, 居家办公情况等等。现在有一群人比较坏,把第三天的数据遮住了,我们就要用前两天的情况以及第三天的特征,来预测第三天的阳性人数。但幸好的是,我们还是有一些数据可以作为参考的,就是我们的训练集。用训练集训练模型并且由训练的模型预测第三天阳性人数。
三.代码解析
#引用的包的介绍
csv用来读EXCEL文件
numpy矩阵处理的包
Dataset,DataLoader数据处理相关的包
torch.nn 中打包了深度学习梯度下降等功能,用于搭建自己的model
time用于记录训练时间的包
matplotlib.pyplot用于作图的包
import csv
import numpy as np
import time
import matplotlib.pyplot as plt
import matplotlib
import pandas as pd
from torch import optim
import torch.nn as nn
import torch
from torch.utils.data import Dataset,DataLoader
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
1.数据处理部分
数据处理一般都是在一个Dataset类中实现的,其中包括三个函数:
(1)init:初始化,将数据读入,放入X[ ]和Y[ ] 中,方便操作
(2)getitem:取数据,提供一个下标[idx],取得一个X[idx],Y[idx]
(3)len:数据长度
所给数据格式如图:
其中使用了独热编码,有效数据前四十列每一列代表一个州
后面才是影响因素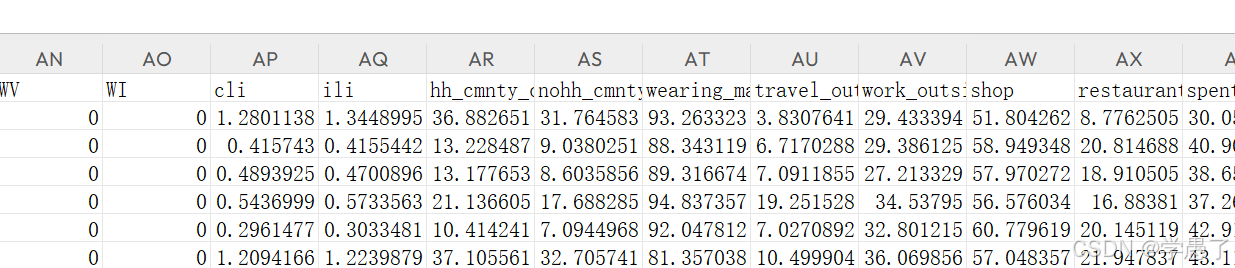
相关系数优化数据
def get_feature_importance(feature_data, label_data, k =4,column = None):
"""
此处省略 feature_data, label_data 的生成代码。
如果是 CSV 文件,可通过 read_csv() 函数获得特征和标签。
这个函数的目的是, 找到所有的特征种, 比较有用的k个特征, 并打印这些列的名字。
"""
model = SelectKBest(chi2, k=k) #定义一个选择k个最佳特征的函数
feature_data = np.array(feature_data, dtype=np.float64)
# label_data = np.array(label_data, dtype=np.float64)
X_new = model.fit_transform(feature_data, label_data) #用这个函数选择k个最佳特征
#feature_data是特征数据,label_data是标签数据,该函数可以选择出k个特征
print('x_new', X_new)
scores = model.scores_ # scores即每一列与结果的相关性
# 按重要性排序,选出最重要的 k 个
indices = np.argsort(scores)[::-1] #[::-1]表示反转一个列表或者矩阵。
# argsort这个函数, 可以矩阵排序后的下标。 比如 indices[0]表示的是,scores中最小值的下标。
if column: # 如果需要打印选中的列
k_best_features = [column[i+1] for i in indices[0:k].tolist()] # 选中这些列 打印
print('k best features are: ',k_best_features)
return X_new, indices[0:k] # 返回选中列的特征和他们的下标。
class covidDataset(Dataset):
init部分
首先读入文件,然后将第一行,也就是数据的标签,特征等列名放入column中,以便后续进行数据处理。由于要取真正数据有效部分,于是要去除数据的第一行”列名“以及第一列”标号“。
在使用数据时,使用了相关系数优化处理,可有两种选择方式,使用全部数据或者是重要影响数据。
然后根据输入分成三种情况,训练集(每五个数据取前四个),验证集(每五个取一个)以及测试集,其中训练集和验证集需要最后一行也就是结果,而测试集无最后一行。
分好后将当前数据以及模式(训练or验证or测试)记录下来。
最后对数据进行归一化处理。
def __init__(self, path, mode="train", feature_dim=5, all_feature=False):
with open(path,'r') as f:
csv_data = list(csv.reader(f))
column = csv_data[0]
x = np.array(csv_data)[1:,1:-1]
y = np.array(csv_data)[1:,-1]
if all_feature:
col_indices = np.array([i for i in range(0,93)]) # 若全选,则选中所有列。
else:
_, col_indices = get_feature_importance(x, y, feature_dim, column) # 选重要的dim列。
# X_new = get_feature_importance_with_pca(x, feature_dim, column) # 选重要的特征
col_indices = col_indices.tolist() # col_indices 从array 转为列表。
csv_data = np.array(csv_data[1:])[:,1:].astype(float) #取csvdata从第二行开始, 第二列开始的数据,并转为float
if mode == 'train': # 训练数据逢5选4, 记录他们的所在行
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
self.y = torch.tensor(csv_data[indices,-1]) # 训练标签是csvdata的最后一列。 要转化为tensor型
elif mode == 'val': # 验证数据逢5选1, 记录他们的所在列
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
# data = torch.tensor(csv_data[indices,col_indices])
self.y = torch.tensor(csv_data[indices,-1]) # 验证标签是csvdata的最后一列。 要转化为tensor型
else:
indices = [i for i in range(len(csv_data))] # 测试机只有数据
# data = torch.tensor(csv_data[indices,col_indices])
data = torch.tensor(csv_data[indices, :]) # 根据选中行取 X , 即模型的输入特征
self.data = data[:, col_indices] # col_indices 表示了重要的K列, 根据重要性, 选中k列。
self.mode = mode # 表示当前数据集的模式
self.data = (self.data - self.data.mean(dim=0,keepdim=True)) / self.data.std(dim=0,keepdim=True) # 对数据进行列归一化
assert feature_dim == self.data.shape[1] # 判断数据的列数是否为规定的dim列, 要不然就报错。
print('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})'
.format(mode, len(self.data), feature_dim)) # 打印读了多少数据
getitnt部分
在init部分中以及将输入路径文件内容存起来,getitint部分则是取数据了。对于非测试集,既要x,又要y来更新模型或者验证好坏。而对于测试集,是最后测试模型的,所以不应该输入y,只要x,得到预测的y即可。
def __getitem__(self, item): # getitem 需要完成读下标为item的数据
if self.mode == 'test': # 测试集没标签。 注意data要转为模型需要的float32型
return self.data[item].float()
else : # 否则要返回带标签数据
return self.data[item].float(), self.y[item].float()
len部分
def __len__(self):
return len(self.data) # 返回数据长度。
2.模型
模型包括两部分:
(1)init初始化,神经网络模型的样子
(2)forward,数据通过模型
init部分
两层全连接,每层都要加上激活函数relu
class myNet(nn.Module):
def __init__(self,inDim):
super(myNet,self).__init__()
self.fc1 = nn.Linear(inDim, 64) # 全连接
self.relu = nn.ReLU() # 激活函数
self.fc2 = nn.Linear(64,1) # 全连接
forward部分
x一层层通过模型
最后输出的predy结果是(16,1)而真实结果y是(16),x.squeeze(1)就是去掉(~,1)这一维,这样才能相减求loss
def forward(self, x): #forward, 即模型前向过程
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
if len(x.size()) > 1:
return x.squeeze(1)
else:
return x
3.训练过程
记录各个模式下的loss
def train_val(model, trainloader, valloader,optimizer, loss, epoch, device, save_):
# trainloader = DataLoader(trainset,batch_size=batch,shuffle=True)
# valloader = DataLoader(valset,batch_size=batch,shuffle=True)
model = model.to(device) # 模型和数据 ,要在一个设备上。
plt_train_loss = []
plt_val_loss = []
val_rel = []
min_val_loss = 100000 # 记录训练验证loss 以及验证loss和结果
发起冲锋的号角,即使什么也不懂,看到这里也要直到开始训练了。
记录下开始训练的时间
for i in range(epoch): # 训练epoch 轮
start_time = time.time() # 记录开始时间
训练模式:
与线性表示-训练过程一样,取一批数据,将数据放到cpu上,得到预测结果,计算loss,梯度下降优化模型,计算本批次loss和,直到本轮结束,记录本轮次的平均loss
model.train() # 模型设置为训练状态
train_loss = 0.0
val_loss = 0.0
for data in trainloader: # 从训练集取一个batch的数据
optimizer.zero_grad() # 梯度清0
x , target = data[0].to(device), data[1].to(device) # 将数据放到设备上
pred = model(x) # 用模型预测数据
bat_loss = loss(pred, target, model) # 计算loss
bat_loss.backward() # 梯度回传, 反向传播。
optimizer.step() #用优化器更新模型。
train_loss += bat_loss.detach().cpu().item() #记录loss和
plt_train_loss. append(train_loss/trainloader.dataset.__len__())
#记录loss到列表。注意是平均的loss ,因此要除以数据集长度。
验证模式:
验证模式与训练模式很相似,验证与训练不同点是,训练模型要优化模型,而验证模型不要优化模型,因此模型不再计算梯度,但是仍要通过模型,计算本批次loss以及平均loss,如果本批次loss更小,则当前模型是目前最好模型,保存下来
model.eval() # 模型设置为验证状态
with torch.no_grad(): # 模型不再计算梯度
for data in valloader: # 从验证集取一个batch的数据
val_x , val_target = data[0].to(device), data[1].to(device) # 将数据放到设备上
val_pred = model(val_x) # 用模型预测数据
val_bat_loss = loss(val_pred, val_target, model) # 计算loss
val_loss += val_bat_loss.detach().cpu().item() # 计算loss
val_rel.append(val_pred) #记录预测结果
if val_loss < min_val_loss:
torch.save(model, save_) #如果loss比之前的最小值小, 说明模型更优, 保存这个模型
plt_val_loss.append(val_loss/valloader.dataset.__len__()) #记录loss到列表。注意是平均的loss ,因此要除以数据集长度。
打印训练信息:
当前轮次/总轮次,训练时间,训练loss,验证集loss
print('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f' % \
(i, epoch, time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1])
) #打印训练结果。 注意python语法, %2.2f 表示小数位为2的浮点数, 后面可以对应。
可视化
plt.plot(plt_train_loss) # 画图, 向图中放入训练loss数据
plt.plot(plt_val_loss) # 画图, 向图中放入训练loss数据
plt.title('loss') # 画图, 标题
plt.legend(['train', 'val']) # 画图, 图例
plt.show() # 画图, 展示
训练完,得到最好的模型后,我们还需要完成预测,也就是输入测试集,输出结果,提交结果。测试时,需要传入最好的模型,测试集,结果保存地址,以及设备。
首先加载模型,然后取测试集里的数据,注意shuffle = Fales,测试时一定不能打乱顺序。数据通过模型,并记录在val_rel中,最后记录到指定文件里。
def evaluate(model_path, testset, rel_path ,device):
model = torch.load(model_path).to(device) # 模型放到设备上。
testloader = DataLoader(testset,batch_size=1,shuffle=False) # 将验证数据放入loader 验证时, 一般batch为1
val_rel = []
model.eval() # 模型设置为验证状态
with torch.no_grad(): # 模型不再计算梯度
for data in testloader: # 从测试集取一个batch的数据
x = data.to(device) # 将数据放到设备上
pred = model(x) # 用模型预测数据
val_rel.append(pred.item()) #记录预测结果
print(val_rel) #打印预测结果
with open(rel_path, 'w') as f: #打开保存的文件
csv_writer = csv.writer(f) #初始化一个写文件器 writer
csv_writer.writerow(['id','tested_positive']) #在第一行写上 “id” 和 “tested_positive”
for i in range(len(testset)): # 把测试结果的每一行放入输出的excel表中。
csv_writer.writerow([str(i),str(val_rel[i])])
print("rel已经保存到"+ rel_path)
4.优化时必要操作
线性相关优化后选出的重要列
all_col = False #是否使用所有的列
device = 'cuda' if torch.cuda.is_available() else 'cpu' #选择使用cpu还是gpu计算。
print(device)
train_path = 'covid.train.csv' # 训练数据路径
test_path = 'covid.test.csv' # 测试数据路径
file = pd.read_csv(train_path)
file.head() # 用pandas 看看数据长啥样
if all_col == True:
feature_dim = 93
else:
feature_dim = 6 #是否使用所有的列
启动验证、测试、训练
trainset = covidDataset(train_path,'train',feature_dim=feature_dim, all_feature=all_col)
valset = covidDataset(train_path,'val',feature_dim=feature_dim, all_feature=all_col)
testset = covidDataset(test_path,'test',feature_dim=feature_dim, all_feature=all_col) #读取训练, 验证,测试数据
正则化代码(用于提升优化器)
def mseLoss(pred, target, model):
loss = nn.MSELoss(reduction='mean')
''' Calculate loss '''
regularization_loss = 0 # 正则项
for param in model.parameters():
# TODO: you may implement L1/L2 regularization here
# 使用L2正则项
# regularization_loss += torch.sum(abs(param))
regularization_loss += torch.sum(param ** 2) # 计算所有参数平方
return loss(pred, target) + 0.00075 * regularization_loss # 返回损失。
loss = mseLoss # 定义mseloss 即 平方差损失,
5.超参部分
一共50轮
一批数据为256
优化器为SGD
lr学习率
momentum动量,防止模型处于极小值点而不是最小值点
early_stop早停法,防止200轮训练模型无变化造成过拟合
save_path保存路径
config = {
'n_epochs': 50, # maximum number of epochs
'batch_size': 256, # mini-batch size for dataloader
'optimizer': 'SGD', # optimization algorithm (optimizer in torch.optim)
'optim_hparas': { # hyper-parameters for the optimizer (depends on which optimizer you are using)
'lr': 0.0001, # learning rate of SGD
'momentum': 0.9 # momentum for SGD
},
'early_stop': 200, # early stopping epochs (the number epochs since your model's last improvement)
'save_path': 'model_save/model.pth', # your model will be saved here
}
model = myNet(feature_dim).to(device) # 实例化模型
optimizer = optim.SGD(model.parameters(), lr=0.001,momentum=0.9) # 定义优化器
trainloader = DataLoader(trainset, batch_size=config['batch_size'],shuffle=True)
valloader = DataLoader(valset, batch_size=config['batch_size'],shuffle=True) # 将数据装入loader 方便取一个batch的数据
train_val(model, trainloader, valloader, optimizer, loss, config['n_epochs'], device,save_=config['save_path']) # 训练
evaluate(config['save_path'], testset, 'pred.csv', device) # 验证
完整代码
import csv
import numpy as np
import time
import matplotlib.pyplot as plt
import matplotlib
import pandas as pd
from torch import optim
import torch.nn as nn
import torch
from torch.utils.data import Dataset,DataLoader
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
def get_feature_importance(feature_data, label_data, k =4,column = None):
"""
此处省略 feature_data, label_data 的生成代码。
如果是 CSV 文件,可通过 read_csv() 函数获得特征和标签。
这个函数的目的是, 找到所有的特征种, 比较有用的k个特征, 并打印这些列的名字。
"""
model = SelectKBest(chi2, k=k) #定义一个选择k个最佳特征的函数
feature_data = np.array(feature_data, dtype=np.float64)
# label_data = np.array(label_data, dtype=np.float64)
X_new = model.fit_transform(feature_data, label_data) #用这个函数选择k个最佳特征
#feature_data是特征数据,label_data是标签数据,该函数可以选择出k个特征
print('x_new', X_new)
scores = model.scores_ # scores即每一列与结果的相关性
# 按重要性排序,选出最重要的 k 个
indices = np.argsort(scores)[::-1] #[::-1]表示反转一个列表或者矩阵。
# argsort这个函数, 可以矩阵排序后的下标。 比如 indices[0]表示的是,scores中最小值的下标。
if column: # 如果需要打印选中的列
k_best_features = [column[i+1] for i in indices[0:k].tolist()] # 选中这些列 打印
print('k best features are: ',k_best_features)
return X_new, indices[0:k] # 返回选中列的特征和他们的下标。
# def get_feature_importance_with_pca(feature_data, k=4, column=None):
# """
# 使用PCA进行特征降维,并找出对前k个主成分影响最大的原始特征。
#
# 参数:
# feature_data (pd.DataFrame or np.ndarray): 特征数据。
# k (int): 选择的主成分数目,默认为4。
# column (list, optional): 特征名称列表。如果feature_data是DataFrame,则可以省略此参数。
#
# 返回:
# X_new (np.ndarray): 降维后的特征数据。
# selected_features (list of lists): 对每个主成分影响最大的原始特征及其载荷。
# """
# # 如果提供了列名或feature_data是DataFrame,获取列名
# if column is None and hasattr(feature_data, 'columns'):
# column = feature_data.columns.tolist()
# elif column is None:
# raise ValueError("Column names must be provided if feature_data is not a DataFrame.")
#
# # 数据标准化
# scaler = StandardScaler()
# feature_data_scaled = scaler.fit_transform(feature_data)
#
# # 应用PCA
# pca = PCA(n_components=k)
# X_new = pca.fit_transform(feature_data_scaled)
# return X_new
class covidDataset(Dataset):
def __init__(self, path, mode="train", feature_dim=5, all_feature=False):
with open(path,'r') as f:
csv_data = list(csv.reader(f))
column = csv_data[0]
x = np.array(csv_data)[1:,1:-1]
y = np.array(csv_data)[1:,-1]
if all_feature:
col_indices = np.array([i for i in range(0,93)]) # 若全选,则选中所有列。
else:
_, col_indices = get_feature_importance(x, y, feature_dim, column) # 选重要的dim列。
# X_new = get_feature_importance_with_pca(x, feature_dim, column) # 选重要的特征
col_indices = col_indices.tolist() # col_indices 从array 转为列表。
csv_data = np.array(csv_data[1:])[:,1:].astype(float) #取csvdata从第二行开始, 第二列开始的数据,并转为float
if mode == 'train': # 训练数据逢5选4, 记录他们的所在行
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
self.y = torch.tensor(csv_data[indices,-1]) # 训练标签是csvdata的最后一列。 要转化为tensor型
elif mode == 'val': # 验证数据逢5选1, 记录他们的所在列
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
# data = torch.tensor(csv_data[indices,col_indices])
self.y = torch.tensor(csv_data[indices,-1]) # 验证标签是csvdata的最后一列。 要转化为tensor型
else:
indices = [i for i in range(len(csv_data))] # 测试机只有数据
# data = torch.tensor(csv_data[indices,col_indices])
data = torch.tensor(csv_data[indices, :]) # 根据选中行取 X , 即模型的输入特征
self.data = data[:, col_indices] # col_indices 表示了重要的K列, 根据重要性, 选中k列。
self.mode = mode # 表示当前数据集的模式
self.data = (self.data - self.data.mean(dim=0, keepdim=True)) / self.data.std(dim=0,keepdim=True) # 对数据进行列归一化
assert feature_dim == self.data.shape[1] # 判断数据的列数是否为规定的dim列, 要不然就报错。
print('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})'
.format(mode, len(self.data), feature_dim)) # 打印读了多少数据
def __getitem__(self, item): # getitem 需要完成读下标为item的数据
if self.mode == 'test': # 测试集没标签。 注意data要转为模型需要的float32型
return self.data[item].float()
else : # 否则要返回带标签数据
return self.data[item].float(), self.y[item].float()
def __len__(self):
return len(self.data) # 返回数据长度。
class myNet(nn.Module):
def __init__(self,inDim):
super(myNet,self).__init__()
self.fc1 = nn.Linear(inDim, 64) # 全连接
self.relu = nn.ReLU() # 激活函数
self.fc2 = nn.Linear(64,1) # 全连接
def forward(self, x): #forward, 即模型前向过程
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
if len(x.size()) > 1:
return x.squeeze(1)
else:
return x
def train_val(model, trainloader, valloader,optimizer, loss, epoch, device, save_):
# trainloader = DataLoader(trainset,batch_size=batch,shuffle=True)
# valloader = DataLoader(valset,batch_size=batch,shuffle=True)
model = model.to(device) # 模型和数据 ,要在一个设备上。
plt_train_loss = []
plt_val_loss = []
val_rel = []
min_val_loss = 100000 # 记录训练验证loss 以及验证loss和结果
for i in range(epoch): # 训练epoch 轮
start_time = time.time() # 记录开始时间
model.train() # 模型设置为训练状态
train_loss = 0.0
val_loss = 0.0
for data in trainloader: # 从训练集取一个batch的数据
optimizer.zero_grad() # 梯度清0
x , target = data[0].to(device), data[1].to(device) # 将数据放到设备上
pred = model(x) # 用模型预测数据
bat_loss = loss(pred, target, model) # 计算loss
bat_loss.backward() # 梯度回传, 反向传播。
optimizer.step() #用优化器更新模型。
train_loss += bat_loss.detach().cpu().item() #记录loss和
plt_train_loss. append(train_loss/trainloader.dataset.__len__())
#记录loss到列表。注意是平均的loss ,因此要除以数据集长度。
model.eval() # 模型设置为验证状态
with torch.no_grad(): # 模型不再计算梯度
for data in valloader: # 从验证集取一个batch的数据
val_x , val_target = data[0].to(device), data[1].to(device) # 将数据放到设备上
val_pred = model(val_x) # 用模型预测数据
val_bat_loss = loss(val_pred, val_target, model) # 计算loss
val_loss += val_bat_loss.detach().cpu().item() # 计算loss
val_rel.append(val_pred) #记录预测结果
if val_loss < min_val_loss:
torch.save(model, save_) #如果loss比之前的最小值小, 说明模型更优, 保存这个模型
plt_val_loss.append(val_loss/valloader.dataset.__len__()) #记录loss到列表。注意是平均的loss ,因此要除以数据集长度。
#
print('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f' % \
(i, epoch, time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1])
) #打印训练结果。 注意python语法, %2.2f 表示小数位为2的浮点数, 后面可以对应。
# print('[%03d/%03d] %2.2f sec(s) TrainLoss : %3.6f | valLoss: %.6f' % \
# (i, epoch, time.time()-start_time, 2210.2255411, plt_val_loss[-1])
# ) #打印训练结果。 注意python语法, %2.2f 表示小数位为2的浮点数, 后面可以对应。
plt.plot(plt_train_loss) # 画图, 向图中放入训练loss数据
plt.plot(plt_val_loss) # 画图, 向图中放入训练loss数据
plt.title('loss') # 画图, 标题
plt.legend(['train', 'val']) # 画图, 图例
plt.show() # 画图, 展示
def evaluate(model_path, testset, rel_path ,device):
model = torch.load(model_path).to(device) # 模型放到设备上。
testloader = DataLoader(testset,batch_size=1,shuffle=False) # 将验证数据放入loader 验证时, 一般batch为1
val_rel = []
model.eval() # 模型设置为验证状态
with torch.no_grad(): # 模型不再计算梯度
for data in testloader: # 从测试集取一个batch的数据
x = data.to(device) # 将数据放到设备上
pred = model(x) # 用模型预测数据
val_rel.append(pred.item()) #记录预测结果
print(val_rel) #打印预测结果
with open(rel_path, 'w') as f: #打开保存的文件
csv_writer = csv.writer(f) #初始化一个写文件器 writer
csv_writer.writerow(['id','tested_positive']) #在第一行写上 “id” 和 “tested_positive”
for i in range(len(testset)): # 把测试结果的每一行放入输出的excel表中。
csv_writer.writerow([str(i),str(val_rel[i])])
print("rel已经保存到"+ rel_path)
all_col = False #是否使用所有的列
device = 'cuda' if torch.cuda.is_available() else 'cpu' #选择使用cpu还是gpu计算。
print(device)
train_path = 'covid.train.csv' # 训练数据路径
test_path = 'covid.test.csv' # 测试数据路径
file = pd.read_csv(train_path)
file.head() # 用pandas 看看数据长啥样
if all_col == True:
feature_dim = 93
else:
feature_dim = 6 #是否使用所有的列
trainset = covidDataset(train_path,'train',feature_dim=feature_dim, all_feature=all_col)
valset = covidDataset(train_path,'val',feature_dim=feature_dim, all_feature=all_col)
testset = covidDataset(test_path,'test',feature_dim=feature_dim, all_feature=all_col) #读取训练, 验证,测试数据
def mseLoss(pred, target, model):
loss = nn.MSELoss(reduction='mean')
''' Calculate loss '''
regularization_loss = 0 # 正则项
for param in model.parameters():
# TODO: you may implement L1/L2 regularization here
# 使用L2正则项
# regularization_loss += torch.sum(abs(param))
regularization_loss += torch.sum(param ** 2) # 计算所有参数平方
return loss(pred, target) + 0.00075 * regularization_loss # 返回损失。
loss = mseLoss # 定义mseloss 即 平方差损失,
config = {
'n_epochs': 50, # maximum number of epochs
'batch_size': 256, # mini-batch size for dataloader
'optimizer': 'SGD', # optimization algorithm (optimizer in torch.optim)
'optim_hparas': { # hyper-parameters for the optimizer (depends on which optimizer you are using)
'lr': 0.0001, # learning rate of SGD
'momentum': 0.9 # momentum for SGD
},
'early_stop': 200, # early stopping epochs (the number epochs since your model's last improvement)
'save_path': 'model_save/model.pth', # your model will be saved here
}
model = myNet(feature_dim).to(device) # 实例化模型
optimizer = optim.SGD(model.parameters(), lr=0.001,momentum=0.9) # 定义优化器
trainloader = DataLoader(trainset, batch_size=config['batch_size'],shuffle=True)
valloader = DataLoader(valset, batch_size=config['batch_size'],shuffle=True) # 将数据装入loader 方便取一个batch的数据
train_val(model, trainloader, valloader, optimizer, loss, config['n_epochs'], device,save_=config['save_path']) # 训练
evaluate(config['save_path'], testset, 'pred.csv', device) # 验证
四.总结
本项目在最基础的回归模型上,增加了正则化和相关系数两种优化方式
正则化:
在普通的nn.MSELoss又+ww,即loss = loss + ww,不仅loss越小越好,w也越小越好,防止模型过拟合。(有时个别特例的数据会影响整个模型的性能)
def mseLoss(pred, target, model):
loss = nn.MSELoss(reduction='mean')
''' Calculate loss '''
regularization_loss = 0 # 正则项
for param in model.parameters():
# TODO: you may implement L1/L2 regularization here
# 使用L2正则项
# regularization_loss += torch.sum(abs(param))
regularization_loss += torch.sum(param ** 2) # 计算所有参数平方
return loss(pred, target) + 0.00075 * regularization_loss # 返回损失。
相关系数:线性相关(selectKBest)
在众多影响结果的因素中,有些因素对于结果的影响更大,通过线性相关可以挑出那些影响更大的因素来训练模型,使得模型会更好。
def get_feature_importance(feature_data, label_data, k =4,column = None):
"""
此处省略 feature_data, label_data 的生成代码。
如果是 CSV 文件,可通过 read_csv() 函数获得特征和标签。
这个函数的目的是, 找到所有的特征种, 比较有用的k个特征, 并打印这些列的名字。
"""
model = SelectKBest(chi2, k=k) #定义一个选择k个最佳特征的函数
feature_data = np.array(feature_data, dtype=np.float64)
# label_data = np.array(label_data, dtype=np.float64)
X_new = model.fit_transform(feature_data, label_data) #用这个函数选择k个最佳特征
#feature_data是特征数据,label_data是标签数据,该函数可以选择出k个特征
print('x_new', X_new)
scores = model.scores_ # scores即每一列与结果的相关性
# 按重要性排序,选出最重要的 k 个
indices = np.argsort(scores)[::-1] #[::-1]表示反转一个列表或者矩阵。
# argsort这个函数, 可以矩阵排序后的下标。 比如 indices[0]表示的是,scores中最小值的下标。
if column: # 如果需要打印选中的列
k_best_features = [column[i+1] for i in indices[0:k].tolist()] # 选中这些列 打印
print('k best features are: ',k_best_features)
return X_new, indices[0:k] # 返回选中列的特征和他们的下标。
主成分分析PCA(本项目未使用,留作拓展)
减少数据的维度,同时尽可能保留原始数据的信息。这对于处理高维数据特别有用,可以提高计算效率和减少存储空间。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)