具身智能的任务规划:机器人如何把一句话变成一串可执行动作
摘要:具身智能的难点,不只是让机器人听懂人话,而是让它把一句自然语言指令拆解成可执行、可验证、可纠错的动作序列。本文从入门视角介绍任务规划在具身智能中的作用,包括语言理解、环境感知、技能库、可供性判断、动作执行和反馈闭环,并解释为什么大模型需要和机器人控制系统结合,才能真正从“会回答”走向“会行动”。
一、机器人听懂一句话,还远远不够
人对机器人说:“帮我把桌上的杯子放进水槽。”
对人来说,这句话很简单。但对机器人来说,它至少包含几个隐含问题:桌子在哪里?杯子是哪一个?水槽在哪里?杯子能不能抓?移动路径是否安全?如果杯子滑落怎么办?
这就是具身智能和普通聊天 AI 的关键区别。聊天 AI 只需要生成合理回答,具身智能系统必须把语言落到真实世界里的动作上,并且为动作结果负责。
所以,任务规划不是一个附加模块,而是具身智能从“理解”走向“行动”的中枢。
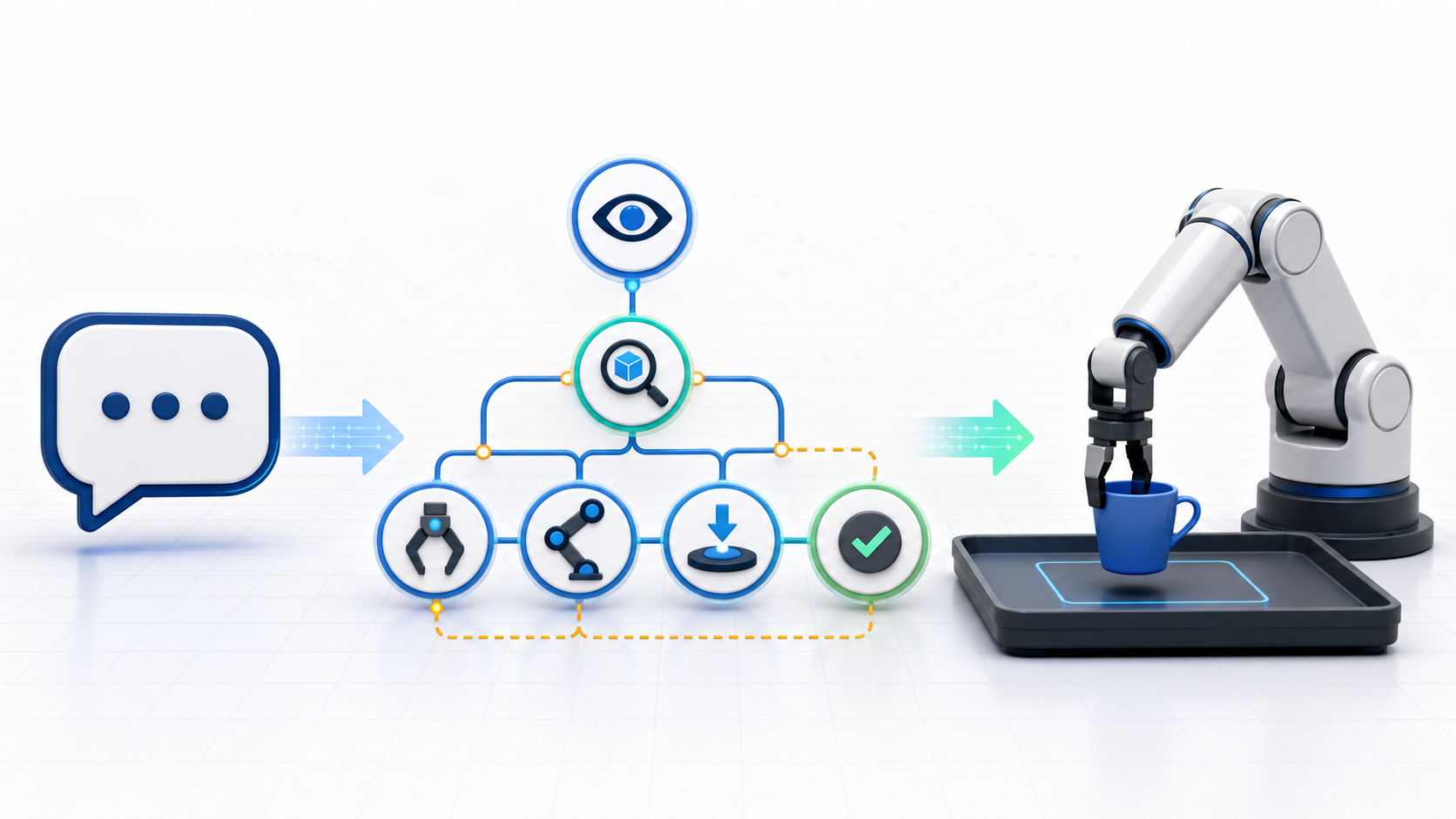
二、任务规划要解决什么问题?
任务规划的核心,是把一个高层目标拆成一组可执行的小步骤。
例如“整理桌面”可以拆成:识别桌面物体,区分垃圾、餐具和文具,选择抓取顺序,移动到对应位置,检查是否完成。如果某一步失败,还要重新规划。
这和传统机器人里的路径规划不同。路径规划更关注“从 A 点怎么移动到 B 点”,任务规划更关注“为了完成目标,应该先做什么、后做什么”。
在具身智能里,两者通常要配合起来:大模型负责理解目标和拆任务,机器人控制系统负责把动作落到关节、夹爪、轮子和传感器上。
三、语言模型为什么不能单独完成任务?
大模型很擅长把复杂任务拆成步骤。比如它可以说:“先找到杯子,再抓住杯子,最后放进水槽。” 但问题是,它不一定知道机器人此刻是否真的看见杯子,也不一定知道这个机器人有没有抓杯子的能力。
这就引出了一个重要概念:可供性。简单说,就是某个动作在当前环境和当前机器人能力下“能不能做”。
一个机械臂可能能抓杯子,但抓不了柔软毛巾;一个轮式机器人可以在平地移动,但不能跨越台阶。任务规划如果不考虑这些限制,就会变成漂亮但无法执行的计划。
SayCan 这类研究路线的启发就在这里:让语言模型提出可能的步骤,再结合机器人已有技能和环境可行性进行筛选,避免“说得对但做不了”。

四、一个可用的任务规划系统通常长什么样?
可以把它拆成六层。
第一层是感知。机器人通过摄像头、深度传感器、力觉或触觉传感器观察环境。
第二层是语义理解。系统把“桌上的杯子”映射到场景里的具体物体。
第三层是技能库。这里存放机器人已经学会的基础动作,比如抓取、放置、推开、打开、移动到某个位置。
第四层是任务规划。系统把用户目标拆成动作序列,并决定调用哪些技能。
第五层是低层控制。控制器把技能转成机械臂轨迹、夹爪力度和底盘运动。
第六层是反馈修正。机器人执行后检查结果,如果失败,就调整动作或重新规划。
真正难的地方是,这六层不能各自为政。任务规划必须随时读取现实反馈,否则机器人就会像照着剧本演戏,一旦场景变化就卡住。
五、VLA 模型带来了什么新思路?
近几年,视觉语言动作模型,也就是 VLA,成为具身智能里的重要路线。它试图把图像、语言和动作放进同一个模型框架里学习。
RT-2 的思路就是让模型不仅学习网页图文知识,也学习机器人轨迹数据,并把动作表示成类似语言 token 的形式。这样,模型可以在理解语义的同时输出机器人动作。
这条路线的意义在于,机器人不再只是“先听懂,再查规则,再执行”,而是有机会把语义理解和动作决策更紧密地融合起来。
但它并不意味着传统规划和控制会消失。现实机器人仍然需要安全约束、动作校验、碰撞检测和失败恢复。更可能的趋势是,大模型负责开放任务理解,控制系统负责稳定执行,中间由规划模块连接。

六、任务规划最先会在哪些场景落地?
短期看,任务规划会先在半结构化场景里落地,比如仓储分拣、实验室自动化、工业巡检、餐饮后厨、医院物流和办公服务。
这些场景的特点是任务相对明确,环境变化可控,容错机制容易设计。机器人不需要一开始就像人一样什么都能做,只要能稳定完成一组高频任务,就有实际价值。
家庭机器人会更难。因为家庭环境太开放:物品位置不固定,用户表达不标准,任务边界模糊,还涉及安全和隐私。它会是长期方向,但不会一夜成熟。
七、真正的难点是“做完以后知道自己做没做对”
很多演示视频里,机器人完成动作看起来很顺畅。但在真实场景中,失败才是常态:没抓稳、拿错物体、路径被挡、目标位置变化、用户中途改口。
所以,任务规划系统不能只会生成计划,还要能验证结果。比如杯子是否真的到了水槽?桌面是否真的清空?门是否真的关上?
这一步决定了机器人能不能从演示走向产品。没有反馈闭环,机器人只是执行脚本;有了反馈闭环,它才开始接近真正的具身智能。
结尾总结
具身智能的任务规划,本质上是把“人类意图”翻译成“机器可执行动作”的过程。
它连接语言理解、环境感知、技能库、动作控制和反馈修正。大模型让机器人更容易理解开放指令,但机器人能不能真正行动,还取决于可供性判断、低层控制和失败恢复。
未来的机器人不会只是一个会聊天的外壳,而会是一个能理解目标、拆解任务、执行动作并根据结果调整自己的系统。任务规划,就是这条路上最关键的桥。
参考资料
1. SayCan: Grounding Language in Robotic Affordances:SayCan: Grounding Language in Robotic Affordances
2. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control:[2307.15818] RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
3. PaLM-E: An Embodied Multimodal Language Model:[2303.03378] PaLM-E: An Embodied Multimodal Language Model
4. Open X-Embodiment: Robotic Learning Datasets and RT-X Models:https://arxiv.org/abs/2310.08864

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)