具身智能策略模型:Diffusion Policy、OpenVLA 与 π0
0|先建立共同框架
|
符号 |
含义 |
SO101 中对应内容 |
|
ot |
observation,环境观察 |
顶视 / 腕部相机图像 |
|
qt |
robot state,本体状态 |
关节角、夹爪位置、末端状态 |
|
ℓ |
language instruction |
“把红色积木放进盒子” |
|
at |
单步动作 |
关节目标、末端位姿增量、夹爪命令 |
|
At |
action chunk,动作块 |
[at,at+1,...,at+H−1] |
三类模型本质都在学习:![]()
区别主要在于:动作是连续值还是离散 token,以及模型通过什么方式生成动作。
|
模型 |
核心问题 |
动作形式 |
最关键能力 |
|
Diffusion Policy |
如何生成自然连续的操作轨迹? |
连续动作块 |
多步去噪生成轨迹 |
|
OpenVLA |
如何让 VLM 看懂指令并输出动作? |
离散 action token |
视觉语言理解 |
|
π0 |
如何同时拥有 VLM 理解和连续控制? |
连续动作块 |
Flow Matching 连续生成 |
1|Diffusion Policy
核心关键词:连续动作、动作块、加噪去噪、多峰分布、滚动执行。
1.1 它解决什么问题?
普通行为克隆常写成:at=π(ot,qt) 即:根据当前图像和机器人状态,直接预测下一步动作。
Diffusion Policy 更关注未来一段完整动作:At=[at,at+1,...,at+H−1]
例如机器人抓杯子时,模型生成的不是一个“向前移动”的单点命令,而是一小段连续过程:
|
动作阶段 |
可能内容 |
|
接近 |
机械臂朝杯子移动 |
|
对准 |
调整末端位置与角度 |
|
下移 |
接近杯口或把手 |
|
抓取 |
夹爪闭合 |
|
抬起 |
物体离开桌面 |
|
转移 |
向目标位置移动 |
因此它更像是在生成一条“可执行轨迹”,而不是独立预测每个时刻的动作。
1.2 为什么不直接回归动作?
真实机器人任务常常有多个合理解。
例如抓取杯子:可以从左边接近,也可以从右边接近。若直接使用 MSE 回归:
![]()
模型容易把多种专家轨迹平均掉,得到一条“中间路线”。但中间路线可能:
- 撞上障碍物; 机械臂姿态不自然; 无法正确抓取; 不符合任何一条真实专家轨迹。
Diffusion Policy 不只学习一个平均动作,而是学习动作分布:p(At∣ot,qt) 也就是:在当前场景下,哪些动作轨迹都可能是合理的。
1.3 训练逻辑
训练时从专家动作块 A0 出发,逐步加入随机高斯噪声:
![]()
|
变量 |
含义 |
|
A0 |
专家真实动作轨迹 |
|
Ak |
加噪后的动作轨迹 |
|
k |
当前噪声等级 |
|
ϵ |
随机高斯噪声 |
|
ϵ^θ |
模型预测出的噪声 |
模型输入:(image, state, noisy action, noise level)
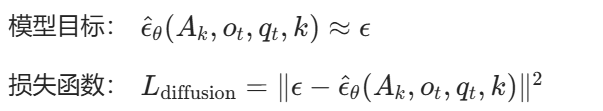
“这段动作现在很乱,但根据图像、机器人姿态和任务上下文,它应该怎样被修正回来。”
1.4 推理逻辑
推理时反过来:随机噪声动作→多次去噪→连续专家风格动作
|
阶段 |
动作状态 |
|
初始 |
完全随机的动作轨迹 |
|
第一次修正 |
大致朝目标方向靠近 |
|
中间修正 |
末端开始对准、姿态更自然 |
|
最后修正 |
形成完整抓取或放置轨迹 |
最终获得:At=[at,at+1,...,at+H−1]
但机器人通常不会把整个动作块一次执行到底,而是:预测16步→执行前4步→重新观察→再预测16步
这叫 Receding Horizon Control(滚动时域控制)。它的核心意义是:真实环境随时会变化,所以机器人要不断“看—动一点—再看”。
Diffusion Policy:从随机噪声动作中逐步去噪,生成一段连续、自然、接近专家示范的动作轨迹。
2|OpenVLA
2.1 它解决什么问题?
OpenVLA 想让机器人像视觉语言大模型一样理解任务:图像+语言指令→动作
例如:“把红色积木放进左边的盒子。”
模型需要同时理解:
|
信息 |
模型要判断什么 |
|
图像 |
哪个是积木、哪个是盒子、手臂在哪里 |
|
语言 |
红色、左边、放进去分别代表什么 |
|
状态 |
当前机械臂能否直接抓到物体 |
|
动作 |
接下来该向哪里移动、何时夹爪闭合 |
它的关键思想是:把机器人动作也变成类似文字 token 的离散符号,让 VLM 像生成句子一样生成动作。
2.2 VLM Backbone 是什么?
VLM Backbone 可以理解为模型中负责“看懂图像和理解语言”的主干大脑。
|
模块 |
主要作用 |
|
视觉编码器 |
将图像转换成视觉特征 |
|
Projector |
把视觉特征映射到语言模型可理解的空间 |
|
语言模型骨干 |
融合图像、指令和历史 token |
|
动作输出头 |
预测接下来应该输出哪些 action token |
所以 OpenVLA 的逻辑不是:语言→动作 而是:图像+语言+VLM理解→动作token
2.3 Action Token 是什么?
机器人原始动作是连续数值,例如:at=[Δx,Δy,Δz,Δr,Δp,Δy,g] 其中 g 可以是夹爪状态。
例如:[0.012,−0.005,0.008,0.00,0.03,−0.01,1]
OpenVLA 会把每个连续维度切成多个区间:0.012→第158个区间→token 158
因此:连续动作→离散动作token 推理完成后再反量化:token 158→0.012
最容易混淆的一点:Action token 不是语言转成的动作向量。
正确顺序是:图像+语言→VLM理解任务→预测离散动作token→反量化为连续动作
动作 token 的本质,是连续机器人动作离散化后的编号。
2.4 训练逻辑

|
内容 |
含义 |
|
yi |
专家动作对应的正确 token |
|
pi |
模型预测该 token 的概率 |
|
Cross Entropy |
提高正确 token 的预测概率 |
2.5 推理逻辑
图像+语言→z1→z2→...→zD 最后:[z1,z2,...,zD]→continuous action
|
token 输出 |
反量化后动作 |
|
[158,115,148,...] |
[0.012,−0.005,0.008,...] |
OpenVLA:把连续动作离散成 token,让 VLM 像生成文字一样生成机器人动作。
3|π0
3.1 它想解决什么问题?
π0 想同时保留两类模型的优点:
|
OpenVLA 的优点 |
Diffusion / Flow 的优点 |
|
能看懂图像和语言 |
能生成自然连续动作 |
|
能识别物体、颜色、空间关系 |
更适合精细轨迹控制 |
|
能利用视觉语言预训练 |
不需要把动作强行离散化 |
所以 π0 的核心表达是:VLM理解任务+FlowMatching生成连续动作
它不是只追求“知道该抓哪个物体”,还要能在真实机器人上输出高质量控制轨迹。
3.2 模型分工
|
模块 |
主要职责 |
|
VLM Backbone |
看图、理解语言、判断任务语义 |
|
Robot State 输入 |
告诉模型机械臂当前姿态 |
|
Action Expert |
专门负责生成机器人动作 |
|
Flow Matching Head |
预测动作应当如何从噪声逐渐变正确 |
VLM Backbone 负责判断“我要把哪一个物体放到哪里”;Action Expert 负责判断“SO101 的各关节接下来该如何连续运动”。
3.3 输入与输出
image+language+robot state+noisy action→action chunk
|
输入 |
作用 |
|
多视角图像 |
看见目标物、机械臂、桌面与障碍物 |
|
语言指令 |
明确任务目标 |
|
robot state |
当前关节、夹爪、底盘或末端状态 |
|
noisy action chunk |
当前待修正的动作轨迹 |
|
flow time |
当前动作处于从噪声到正确动作的哪个阶段 |
输出是连续动作块:At=[at,at+1,...,at+H−1]
3.4 π0 的 token 和 OpenVLA 不一样
OpenVLA 中:token=离散动作类别 π0 中:token=Transformer序列中的一个位置
它可能对应:文本 token; 图像 patch; state 表示; 连续动作表示。
因此不要把 π0 的 action token 理解成 OpenVLA 那种“第158号离散动作类别”。
π0 的动作本质仍在连续空间中生成。
3.5 Flow Matching 到底学什么?
Diffusion Policy 的常见说法是:预测加入了什么噪声
π0 的 Flow Matching 更强调:预测动作应该朝正确轨迹移动的速度和方向
设专家动作是 A,随机噪声是 ϵ,在两者之间构造中间动作:![]()
模型学习一个向量场:![]()
|
当前动作状态 |
模型应该做什么 |
|
动作完全随机 |
先让机械臂大致朝目标物体靠近 |
|
动作接近目标 |
调整末端高度与姿态 |
|
接近抓取位置 |
控制夹爪闭合 |
|
已抓住物体 |
向上抬起并转移 |
所以 π0 不是直接回答“最终动作是什么”,而是在不断回答:
“当前这段动作下一小步该怎么改,才能越来越像专家动作?”
3.6 推理逻辑
随机动作块→预测修正方向→更新动作块→重复多次→连续轨迹
形式上:![]() 最终得到的动作块再送往控制器执行。
最终得到的动作块再送往控制器执行。
和 Diffusion Policy 一样,真实机器人上也通常采用滚动执行:
生成一段动作→执行前几步→新图像与state→再生成
3.7 Pre-training 与 Fine-tuning
|
阶段 |
主要学习内容 |
|
Pre-training |
抓取、放置、推拉、开关、物体关系、语言任务理解 |
|
Fine-tuning |
特定机器人的关节范围、相机视角、动作尺度、夹爪习惯、任务环境 |
放到 SO101 上:
|
训练阶段 |
可以理解为 |
|
预训练 |
学会“什么叫抓、放、移动、对准” |
|
SO101 微调 |
学会“SO101 应该用什么动作完成这些操作” |
3.8 π0 的工程难点
|
难点 |
原因 |
|
机器人输入格式统一 |
不同机械臂 state/action 维度不同 |
|
动作归一化 |
不同关节、夹爪和底盘数值范围差别大 |
|
图像同步 |
图像、state、action 时间错位会直接损害训练 |
|
推理延迟 |
多次 Flow 迭代会增加控制延迟 |
|
安全约束 |
生成动作不代表它一定安全 |
π0:VLM 负责理解“做什么”,Flow Matching 负责在连续动作空间中生成“怎么做”。
3.9|π0 的训练与推理细节

|
输入 |
作用 |
|
图像 + 语言 |
看懂环境、目标物与任务 |
|
Robot State(qt) |
确定机械臂当前真实姿态,是动作轨迹的起点 |
|
Noisy Action (Atτ) |
告诉模型当前“半成品动作”长什么样 |
|
Flow Time (τ) |
告诉模型现在应粗修还是细调 |
|
输出 (vθ) |
动作块的修正方向 / 速度 |
|
推理时:随机动作块 (→) 多轮 Flow Matching 修正 (→) 连续 action chunk。动作块内各动作位置可以相互协调,因此“接近—下降—闭合夹爪—抬起”不会被当成互不相关的单步命令;部署时可执行 chunk 的前几步后重新观察和推理。 |
3.10|π0 在 SO101 上的关键工程点
|
项目 |
核心要求 |
|
时间对齐 |
图像、joint state、action 必须对应同一控制阶段:先观察当前状态,再记录接下来执行的动作;错位会导致动作慢半拍、夹爪时机错误或轨迹抖动。 |
|
输入统一 |
不同机器人 state/action 维度不同,需要 padding;缺失相机槽位要 mask,避免模型把空图当成真实场景。 |
|
Normalization |
关节、夹爪、末端增量数值范围不同,训练和部署必须使用同一套归一化统计量;模型输出动作后再反归一化。 |
|
Action 语义 |
必须始终一致:训练若使用 joint delta,部署就要加回当前真实 joint state;夹爪通常保持 absolute,例如(0=)张开、(1=)闭合。 |
|
ROS2 执行链 |
图像+state+指令(→)π0policy(→)actionchunk(→)adapter(→)限幅/限速/急停/工作空间检查(→)driver |
VLM 负责“看懂要做什么”,State 负责“知道自己在哪里”,Flow Matching 负责“把随机动作逐步修正成连续轨迹”,ROS2 安全与控制层负责“判断这条动作能不能安全执行”。
4|三者最关键的区别
|
维度 |
Diffusion Policy |
OpenVLA |
π0 |
|
核心定位 |
连续模仿学习策略 |
视觉语言动作模型 |
连续动作基础模型 |
|
图像理解 |
有,但通常较任务相关 |
强 |
强 |
|
语言理解 |
可加,但不是核心优势 |
核心优势 |
核心优势 |
|
动作形式 |
连续 |
离散 token |
连续 |
|
是否量化动作 |
否 |
是 |
否 |
|
训练 loss |
去噪损失 |
Cross Entropy |
Flow Matching loss |
|
推理过程 |
多步去噪 |
自回归 token 生成 |
多步向量场积分 |
|
适合精细操作 |
强 |
一般 |
强 |
|
数据与算力门槛 |
中等 |
较高 |
高 |
|
SO101 初期落地 |
很适合 |
更适合理解和微调 |
更适合理解前沿架构 |
5|部署到真实机器人时的统一链路
相机图像+state+指令→模型策略→action→adapter node→安全检查→机器人驱动
|
层级 |
责任 |
|
学习策略 |
决定“下一步想怎么动” |
|
Adapter Node |
转换坐标系、消息格式、动作频率 |
|
Safety Node |
限幅、超时、低电量、急停、工作空间保护 |
|
Controller / Driver |
真正发送关节或末端执行命令 |
|
FSM |
管理 IDLE、RUNNING、ERROR、RECOVERY 等状态 |

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)