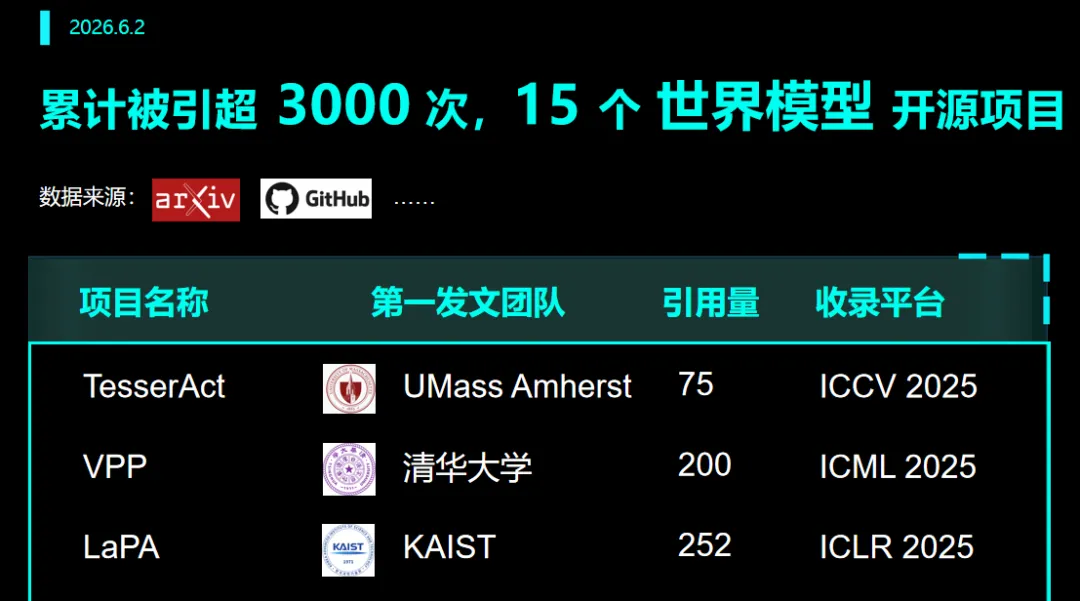
近三年世界模型 3 大技术路线!这 15 个项目全开源(推荐收藏)
▲图4 | mimic-video 概述:一种新型视频-动作模型(VAM),它将机器人策略建立在预训练视频模型中,利用视频骨干的固有视觉动态来解决控制问题,实现高效率的灵巧操作任务。它采用联合视频-动作潜在表示和解耦的视频-动作解码,在保证高精度动作输出的同时,实现了高效的实时推理,为联合架构提供了一个坚实的开源基线。它强调,无动作的视频数据对于泛化到新任务至关重要,仅需极少量演示数据即可提取强大
什么样的预测,才值得机器人“托付”一次真实的物理交互?
——深蓝具身智能
目录
(ICCV 2025)TesserAct:构建4D具身世界模型
(ICML 2025)Video Prediction Policy (VPP):视频预测即策略
Video Generators are Robot Policies:视频生成器本身就是机器人策略
WorldVLA / RynnVLA-002:自回归动作世界模型
(RSS 2025)Unified World Models (UWM):耦合视频与动作扩散
(RSS 2025)Unified Video Action (UVA):统一视频动作模型
(NeurIPS 2025)RLVR-World:用强化学习训练世界模型
机器人执行任何动作之前,都面临一个根本问题:该动作会引发怎样的后果?先预测该动作可能引发的未来状态变化,再据此优化决策——
这一能力被称为世界模型,是当前具身智能领域的最关键的技术方向之一。
自2024-2026近三年来,全球各大高校与大厂持续发力,涌现出一批高质量开源世界模型项目。
因此,为提供一份侧重可操作性的参考,本文盘点的 15 个开源项目,累计被引已超 3000 次,清晰勾勒出世界模型的三条技术路线:
- 级联架构:先将未来视觉“脑补”出来,再据此决策;
- 联合架构:则让想象与动作在同一次扩散或自回归中交融,消除级联误差;
- 虚拟沙盒:则更进一步,让智能体在脑海内强化试错,避免真实世界的昂贵碰壁。
从《Nature》到各大顶会(ICLR、ICML、RSS、NeurIPS 等)。既包含可直接复现的代码基线,也有可部署到真实机器人的工程实现。
它们共同回应了一个核心问题:什么样的预测,才值得机器人托付一次真实的物理交互?
注:本文提及的研究项目,其引用数据截止2026年6月2日。各项目发布时间不同,引用量存在自然差异,仅作参考,不作为衡量研究水平的标准。受检索范围所限,收录难免有遗漏,欢迎在评论区留言补充,我们将持续跟踪并更新。以下盘点不分先后。
01 级联架构:先预测未来,再决定动作
级联架构的核心思想是分步走:先让世界模型生成对未来状态的预测(如视频帧或潜在特征),再由动作模型根据这个预测解码出具体的控制指令。
(ICCV 2025)TesserAct:构建4D具身世界模型
- 研究团队:马萨诸塞大学阿默斯特分校、香港科技大学、哈佛大学
- 引用次数:75
- 项目概述:
TesserAct 是首个开源的通用4D机器人世界模型。
它接收输入图像和文本指令,生成RGB、深度和法线视频,重建4D场景并预测动作。不仅在域内数据上表现出色,还能有效泛化到未见场景、新物体和跨域场景。
实验表明,其策略学习性能显著优于以往基于2D视频的世界模型。

▲图1 | TesserAct:4D具身世界模型。
(ICML 2025)Video Prediction Policy (VPP):视频预测即策略
- 研究团队:清华大学、上海AI Lab等
- 引用次数:200
- 项目概述:
VPP 利用视频扩散模型(VDMs)强大的物理世界理解能力,生成包含当前静态信息和预测未来动态的视觉表征。
基于这些表征,VPP 学习了一个隐式逆动力学模型。在 Calvin ABC-D 泛化基准测试中,VPP 比现有最佳方法相对提升了 18.6%;在复杂的真实世界灵巧手操作任务中,成功率大幅提升了 31.6%。
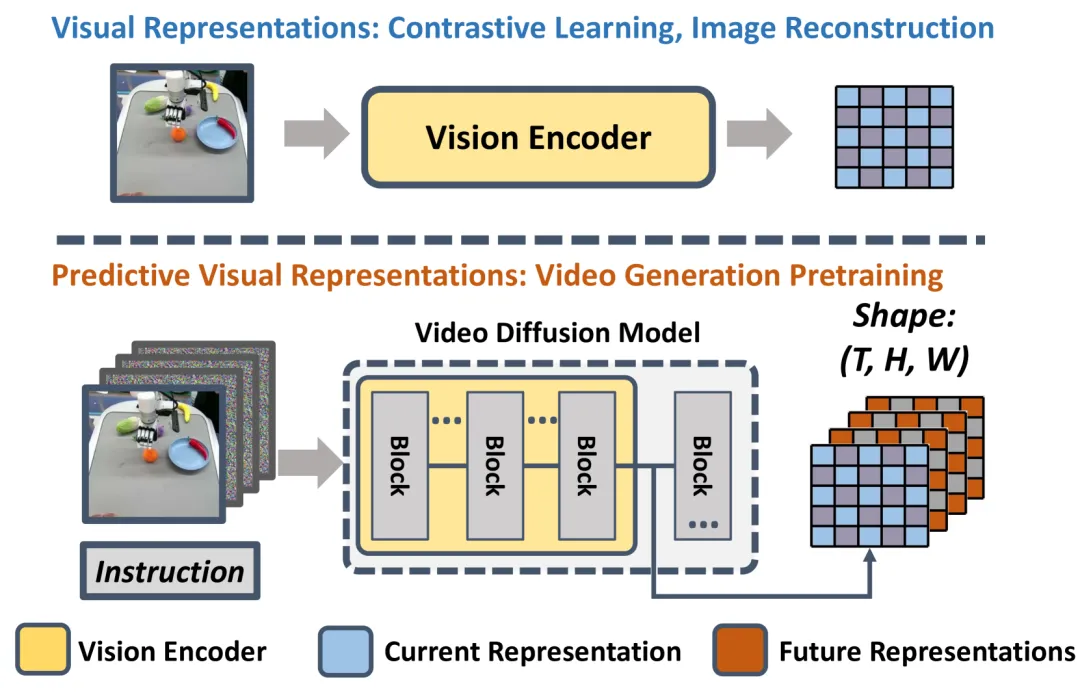
▲图2 | 视频预测模型中的视觉表征明确表达了当前和未来帧,为具身智能体提供了有价值的未来信息。而以前的视觉编码器缺乏明确的未来表征。
(ICLR 2025)LaPA:从无动作标签的视频中学习
- 研究团队:华盛顿大学、微软、英伟达等
- 引用次数:252
- 项目概述:
现有的 VLA 模型极度依赖人类遥操作收集的动作标签,这限制了数据的规模。
LaPA 提出了一种无监督方法,直接从互联网规模的无标签视频中学习离散的"潜在动作"(Latent Actions),随后只需少量机器人数据微调,就能实现卓越的泛化能力。
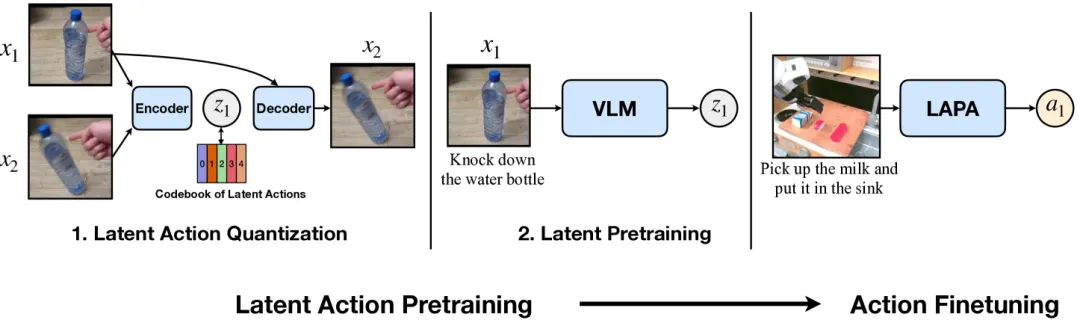
▲图3 | LAPA(潜藏动作预训练)的整体流程图。
该图展示了潜藏动作量化和潜藏预训练两个主要阶段,以及如何将潜藏空间映射到机械臂动作空间。
在多项真实世界操作任务中超越了使用完整动作标签训练的 SOTA VLA 模型。
mimic-video:视频-动作模型的崛起
- 研究团队:Microsoft Zurich、ETH Zurich、UC Berkeley等
- 引用次数:29
- 项目概述:
mimic-video 认为,单纯的视觉-语言预训练缺乏物理因果关系。
他们将预训练的互联网视频模型与基于流匹配(Flow Matching)的动作解码器结合,将动作解码器作为逆动力学模型(IDM)。
这种方法在模拟和真实世界任务中实现了最先进的性能,样本效率提高了 10 倍,收敛速度提高了 2 倍。
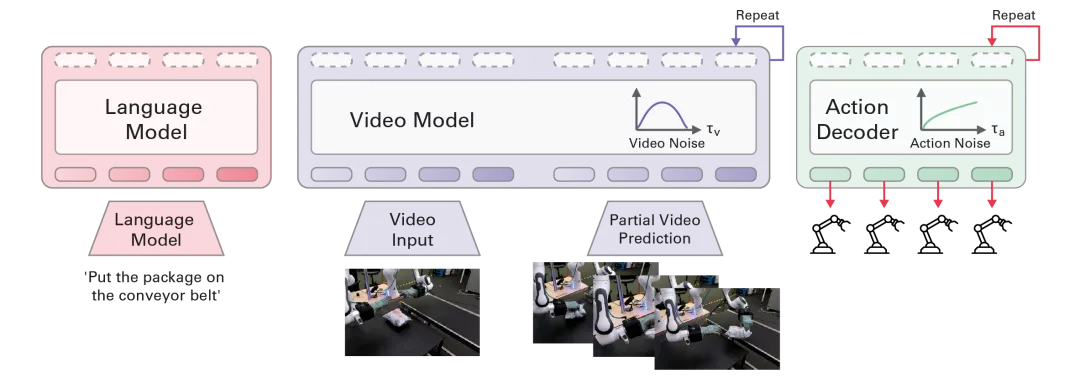
▲图4 | mimic-video 概述:一种新型视频-动作模型(VAM),它将机器人策略建立在预训练视频模型中,利用视频骨干的固有视觉动态来解决控制问题,实现高效率的灵巧操作任务。
villa-X:增强潜在动作建模
- 研究团队:微软研究院、清华大学、武汉大学等
- 引用次数:58
- 项目概述:
villa-X 提出了一个新颖的视觉-语言-潜在动作(ViLLA)框架,改进了潜在动作的学习方式及其在 VLA 预训练中的整合。
它实现了零样本生成潜在动作计划的能力,特别适用于未见过的实体和开放词汇的符号理解,在多种模拟任务及真实机器人设置中均取得了卓越性能。
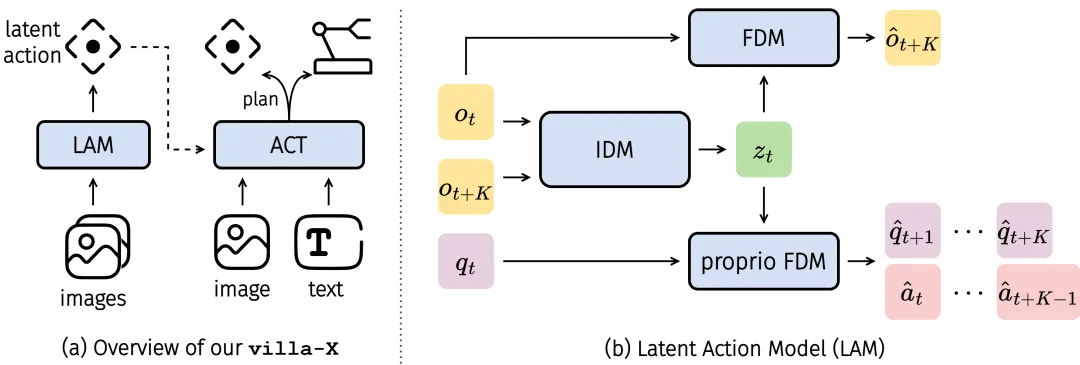
▲图5 | villa-X 方法的高层架构图和潜在动作模型(LAM)组件的详细结构图。
Video Generators are Robot Policies:视频生成器本身就是机器人策略
- 研究团队:哥伦比亚大学、丰田研究所
- 引用次数:41
- 项目概述:
这项工作证明了一个模块化的端到端系统,结合视频生成和动作生成,可以作为机器人策略学习的有效代理。

▲图6 | 该图展示了视频生成作为机器人策略学习的代理。
给定初始观察和自然语言任务提示,模型生成机器人执行任务的视频(顶部)以及通过单独的扩散网络生成机器人动作(中部)。
它强调,无动作的视频数据对于泛化到新任务至关重要,仅需极少量演示数据即可提取强大的策略,在对未见物体、背景和任务的泛化上表现出强大能力。
02 联合架构:理解与生成的深度统一
联合架构将未来状态预测与动作生成紧密耦合在一个共享模型中,通常采用自回归或扩散模型的方式,减少了级联架构中的误差传递。
WorldVLA / RynnVLA-002:自回归动作世界模型
- 研究团队:阿里达摩院、浙江大学等
- 引用次数:180
- 项目概述:
WorldVLA 将 VLA 模型和世界模型集成在单一框架中。
世界模型预测未来图像以学习环境物理,动作模型则基于图像观察生成动作,两者相互增强。
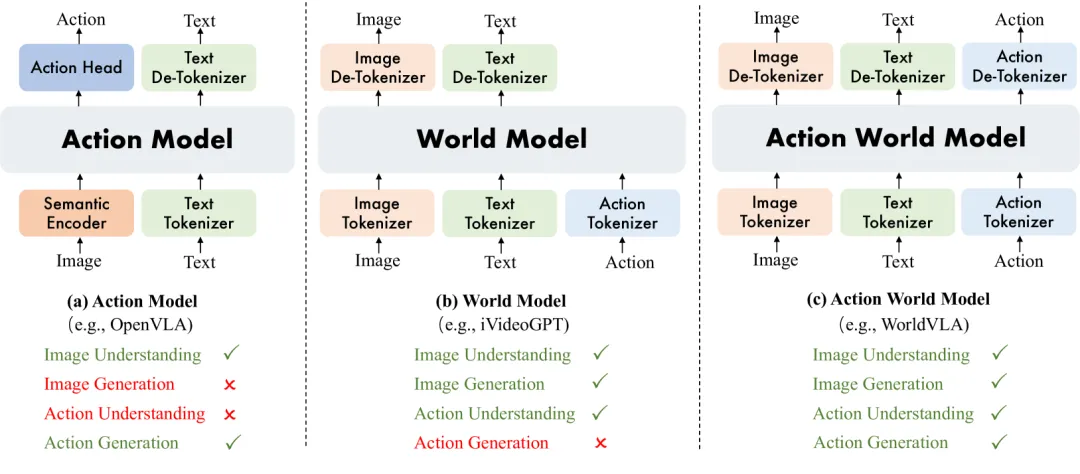
▲图7 | WorldVLA 统一了动作和图像的理解与生成,通过动作模型理解动作,世界模型生成图像,实现双向增强。
工程实现版本 RynnVLA-002 在此基础上进一步添加了连续动作 Transformer、腕部相机输入与生成、状态输入等功能,并提出了创新的注意力掩码策略以解决自回归生成中的误差传播问题。
(RSS 2025)Unified World Models (UWM):耦合视频与动作扩散
- 研究团队:艾伦计算机科学及工程学院,华盛顿大学、丰田研究所
- 引用次数:102
- 项目概述:
UWM 将动作和视频扩散集成到统一的Transformer架构中,通过模态特定的扩散时间步进行控制。
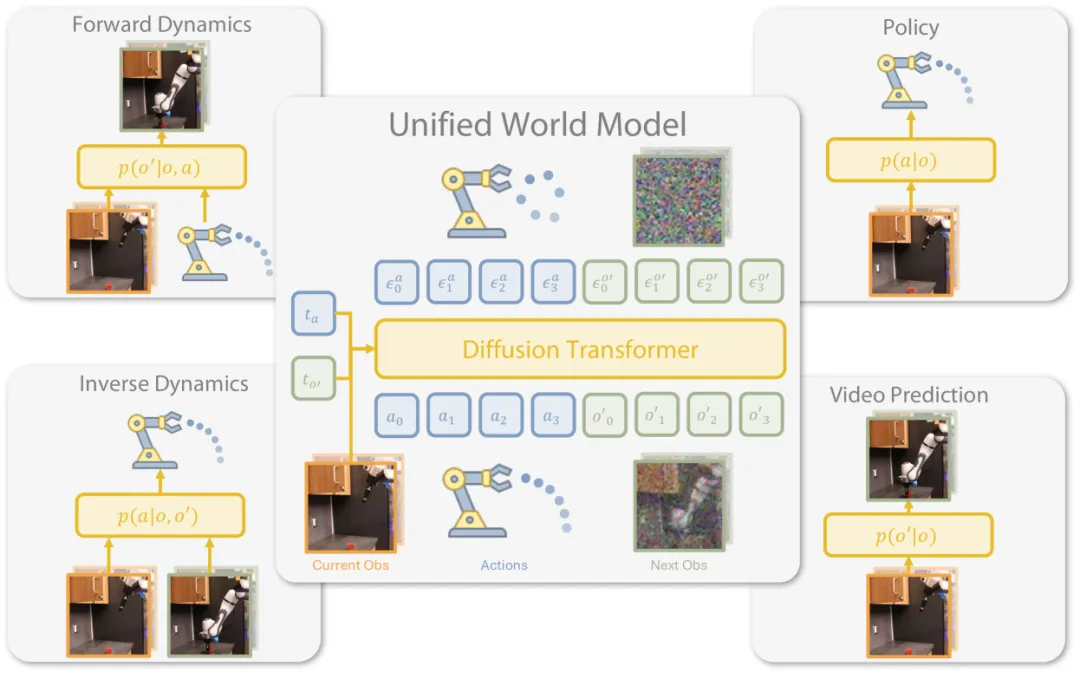
▲图8 | 统一世界模型(UWM)
通过独立控制每个模态的扩散时间步,它可以灵活地表示策略、正向动力学、逆向动力学和视频生成器,从而在大规模多任务数据集上进行有效预训练,生成比模仿学习更具泛化性和鲁棒性的策略。
(ICLR 2024)GR-1:大规模视频生成预训练的威力
- 研究团队:字节
- 引用次数:358
- 项目概述:
GR-1 是一个 GPT 风格的模型,以端到端的方式同时预测机器人动作和未来图像。得益于其灵活的设计,它在经过大规模视频数据集预训练后,可以无缝微调到机器人数据上。在 CALVIN 基准测试中,成功率从 88.9% 提升至 94.9%;在零样本未见场景泛化中,成功率从 53.3% 提升至 85.4%,是联合架构的重要基线工作。
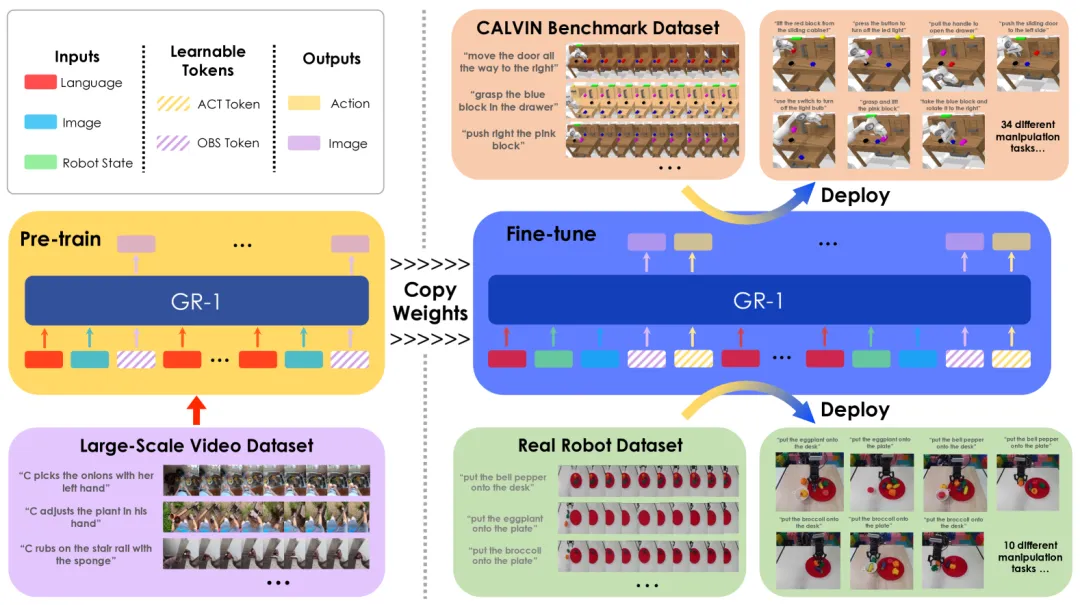
▲图9 | GR-1模型概述。该模型首先在大规模视频数据集上进行视频预测预训练,然后针对机器人数据进行微调,以实现多任务视觉机器人操作。
(RSS 2025)Unified Video Action (UVA):统一视频动作模型
- 研究团队:斯坦福大学
- 引用次数:140
- 项目概述:
UVA 是首个将视频生成与实时策略推理集成在同一模型中的工作。
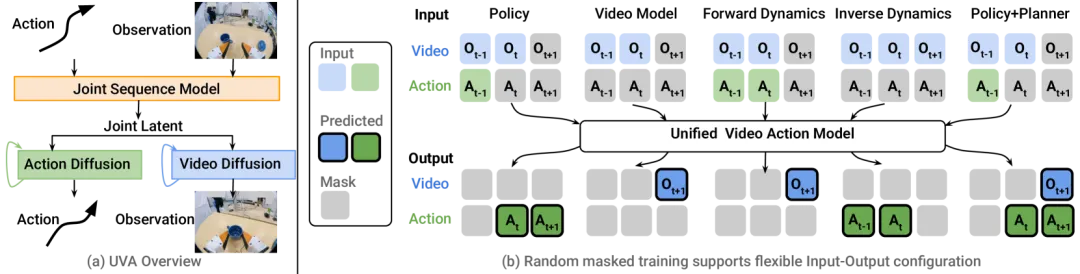
▲图10 | 统一视频动作模型。
它采用联合视频-动作潜在表示和解耦的视频-动作解码,在保证高精度动作输出的同时,实现了高效的实时推理,为联合架构提供了一个坚实的开源基线。
Cosmos Policy:微调视频大模型实现机器人控制
- 研究团队:英伟达、斯坦福大学
- 引用次数:61
- 项目概述:
英伟达提出的 Cosmos Policy 探索了直接微调强大的视频基础模型(Cosmos-Predict2)来实现视觉运动控制和规划的路径。
它在单阶段训练中同时支持动作潜在帧、未来状态预测和规划,展示了视频大模型在具身智能领域的巨大潜力。
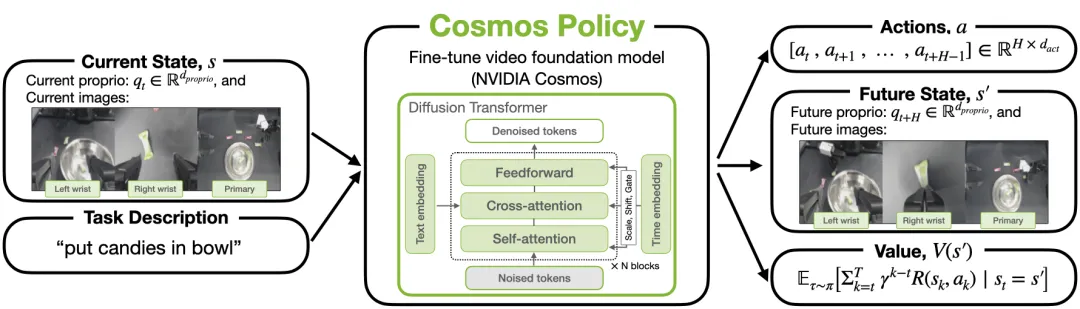
▲图11 | Cosmos Policy
F1-VLA:桥接理解与生成的 VLA 模型
- 研究团队:上海人工智能实验室、哈尔滨工业大学(深圳)
- 引用次数:24
- 项目概述:
来自上海人工智能实验室的 F1 模型采用混合专家 Transformer 架构,包含感知、视觉预见生成和控制三个专用模块。理解模块处理指令和观察以生成预测图像,然后将其输入行动模块,通过预测逆动力学模型预测目标行动。
它通过下一尺度预测机制合成目标条件的视觉预见,将动作生成重新表述为预见引导的逆动力学问题。在真实世界多任务操作中,F1 相比 π₀ 基线平均提升了 20%。
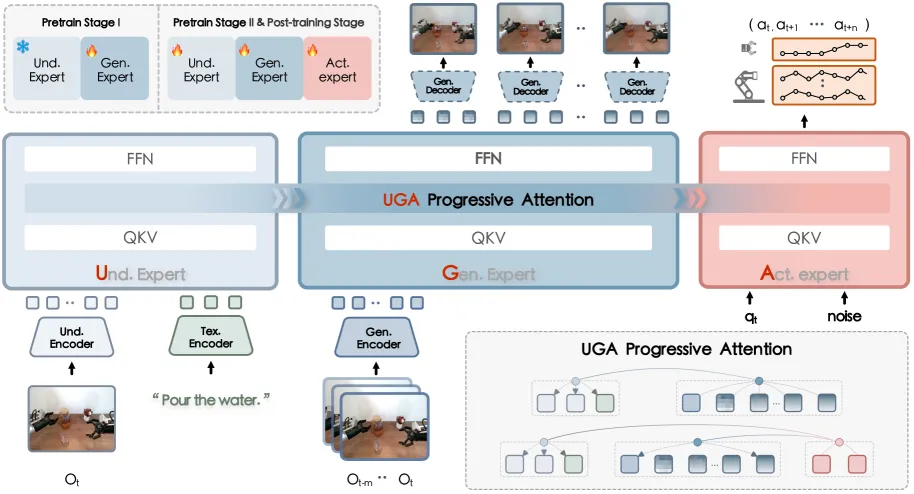
▲图12 | F1 框架的概览图。
03 虚拟沙盒:服务于策略评估与强化学习
除了直接生成动作,世界模型还可以作为高保真的"虚拟环境",用于强化学习微调或策略评估,极大降低了在真实物理世界中试错的成本。
(Nature)DreamerV3:通用强化学习的里程碑
- 研究团队:谷歌DeepMind、多伦多大学
- 引用次数:1475
- 项目概述:
DreamerV3 是世界模型领域的经典之作,于 2025 年正式发表在 Nature 上。
它通过学习环境模型并在其中"想象"未来场景来改进行为,使用单一固定的超参数配置,就在 150 多个不同的任务中超越了专用方法。
而且,它是第一个无需人类数据或课程,从零开始在 Minecraft 中收集钻石的算法。
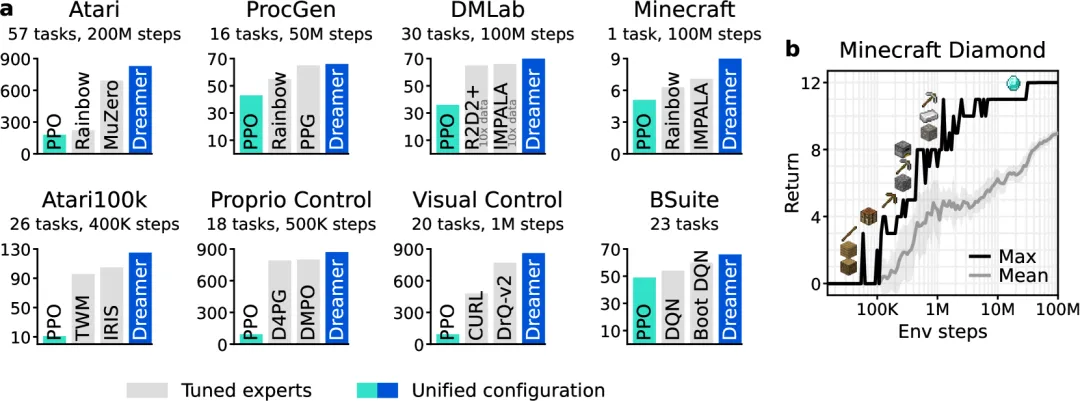
▲图13 | 基准测试总结。Dreamer在广泛的基准和数据预算下,表现优于经过调优的专家算法。
(NeurIPS 2025)RLVR-World:用强化学习训练世界模型
- 研究团队:清华大学
- 引用次数:34
- 项目概述:
传统的训练往往只是让世界模型"预测得像"。RLVR-World 提出利用带可验证奖励的强化学习(RLVR)直接优化世界模型,将其与特定任务的成功指标对齐,让模型的"想象"变得更有目的性。
该框架在语言游戏、网络导航和机器人操作等多个领域均取得了显著的性能提升。
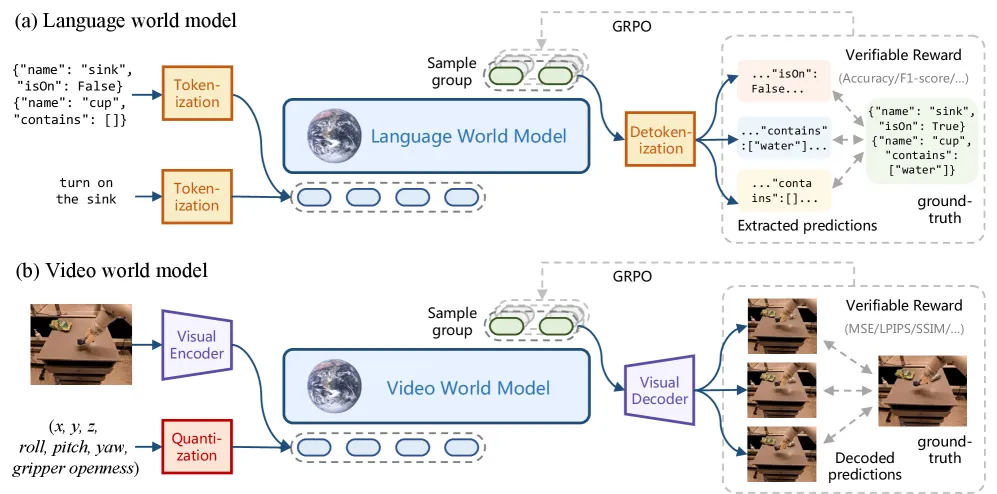
▲图14 | RLVR-World 框架的示意图。该框架将不同模态的世界模型统一在序列建模公式下,并利用任务特定的预测指标作为可验证的奖励。
WorldGym:策略评估的虚拟靶场
- 研究团队:斯坦福大学、谷歌DeepMind等
- 引用次数:13
- 项目概述:
在真实机器人上评估策略既昂贵又耗时。WorldGym 提供了一个基于世界模型的策略评估环境,利用视觉-语言模型提供奖励,通过蒙特卡洛模拟评估策略。
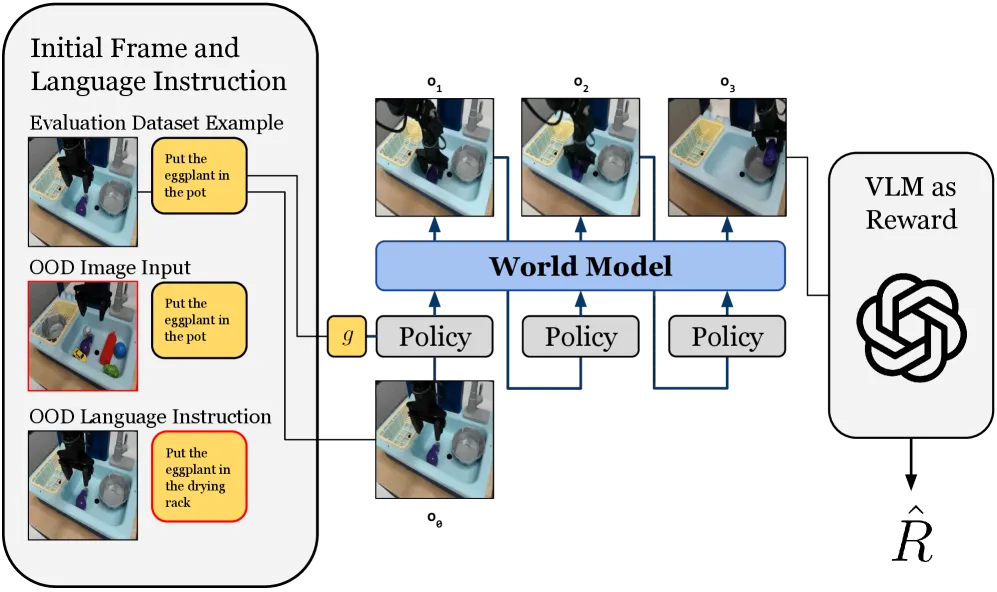
▲图15 | WorldGym 概览。WorldGym 利用世界模型预测未来帧,并通过视觉语言模型提供奖励,用于策略评估。
实验表明,在 WorldGym 中评估的策略成功率与真实世界高度相关,能够有效保持不同策略版本和训练检查点之间的相对排名。
04 世界模型:从“辅助模块”走向“核心引擎”
从级联架构到联合架构,再到作为虚拟沙盒的强化学习环境,世界动作模型正在以不同的技术路径,共同推动具身智能走向更强的泛化能力与物理理解。
三条技术路线并非彼此替代,而是在不同任务复杂度与实时性要求下各有侧重。
当前更值得关注的趋势是,这些路径正在相互渗透:级联架构开始引入联合训练以降低误差传播,联合模型逐步吸收虚拟沙盒的闭环自演进能力。
如今,具身智能早已跳出单纯的感知与复刻,迈入了以世界模型为核心、以环境推演为能力底座的全新阶段。本文收录的15个项目,本质上是世界模型在具身智能中从“辅助模块”走向“核心引擎”的过程切片。
它们的共同指向是明确的:让机器人真正拥有在行动前推演后果的能力,并用这种能力来指导每一次决策。
代码已开源,路线已交汇……

Ref
1. TesserAct: Learning 4D Embodied World Models(https://arxiv.org/pdf/2504.20995)
2. Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations(https://arxiv.org/pdf/2412.14803)
3. LATENT ACTION PRETRAINING FROM VIDEOS(https://arxiv.org/pdf/2410.11758)
4. mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs(https://arxiv.org/pdf/2512.15692)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 1
1 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)