ICLR 2026论文分享 | WorldGym:用世界模型打造机器人策略评估新范式
本文介绍了ICLR 2026的论文WorldGym,一种基于视频世界模型的机器人策略评估环境。它仅需单张初始图像即可在虚拟环境中完成策略评估,与真实世界成功率高度相关,支持便捷的分布外测试,为机器人研发提供了高效安全的新工具。
本文介绍了ICLR 2026的论文《WorldGym: World Model as an Environment for Policy Evaluation》。该论文提出了一种基于视频世界模型的机器人策略评估平台WorldGym。该框架能够仅通过单张初始图像,在生成的虚拟环境中完成机器人策略的全流程评估。WorldGym的架构如图1所示。首先,给定初始帧和语言指令,世界模型根据策略输出的动作序列交互式预测未来帧,作为生成式模拟器;随后,通过视觉语言模型(Visual Language Model,VLM)从生成的视频中评估任务完成度,输出最终奖励。实验表明,WorldGym中的策略成功率与真实世界高度相关,且能准确保留不同策略的相对排名,同时支持便捷的分布外(Out-of-Distribution,OOD)任务测试,为机器人部署前的安全、高效评估提供了全新解决方案。
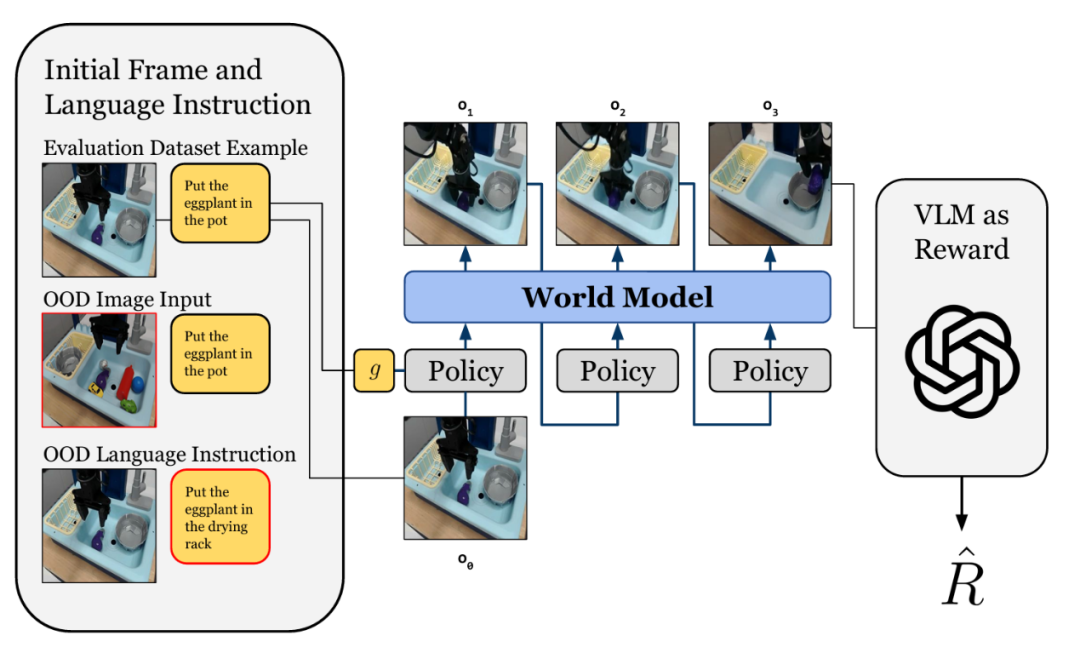
图 1 WorldGym的整体架构
论文链接:https://arxiv.org/abs/2506.00613
代码链接:https://world-model-eval.github.io
本推文作者为邓镝,审校为韩煦。
一、研究背景
机器人策略评估一直是制约机器人技术落地的核心瓶颈,具体表现在如下几方面。
(1)真实世界测试成本极高,耗时耗力,且存在损坏设备或伤害人类的风险
(2)传统手工模拟器(如MuJoCo、Gazebo)需要大量人工工程来提升真实感,难以模拟软物体、复杂接触等物理交互,严重导致从仿真到现实存在巨大差距。
(3)现有离线策略评估方法大多依赖完整状态信息,无法直接应用于基于图像观测的真实机器人系统
随着大规模视频生成模型的发展,研究者提出了一个根本性问题:能否训练一个通用的视频世界模型,来模拟真实世界的物理交互,从而作为机器人策略评估的虚拟环境?
论文表明,虽然任务和策略多种多样,但我们生活的物理世界只有一个,且遵循相同的物理定律。基于此,论文提出了一个基于自回归动作条件视频生成模型的策略评估平台WorldGym。它能够学习跨环境、跨机器人形态的通用物理规律,从而实现对任意策略在任意任务上的评估。
二、研究方法
WorldGym由三个核心模块组成:动作条件视频世界模型、策略推理模型、VLM奖励模型。
2.1 世界模型架构
WorldGym采用基于Diffusion Forcing训练的潜在扩散Transformer(Diffusion Transformer,DiT)作为世界模型骨干,先将256×256输入图像通过Stable Diffusion 3的VAE编码到潜在空间,运用因果时间注意力块和空间注意力块交替的架构处理视频序列,同时对机器人动作向量进行线性投影,将其与扩散时间步嵌入相加后通过AdaLN-Zero调制注入模型,该方法还引入动作随机丢弃和无分类器引导机制,有效显著提升模型对动作输入的依从性,模型训练时采用20帧上下文窗口,推理阶段可借助滑动窗口实现任意长度的长程rollout。
2.2 可变预测步长推理
针对不同机器人策略输出长度不一的动作块这一问题,WorldGym创新性地设计了可变预测步长推理机制,该机制依托Diffusion Forcing的自回归特性,可在推理阶段灵活调节并行去噪的帧数,即预测步长,通过将预测步长与策略的动作块大小精准匹配,最大限度提升硬件利用效率。相较于Cosmos等采用固定预测步长的模型,该机制能够适配各类动作块尺寸场景、始终保持最优运行效率,在4帧并行推理的设置下,可实现2.8倍的推理速度提升。
2.3 VLM作为奖励模型
WorldGym以GPT-4o作为自动奖励模型,摆脱了人工标注的依赖,能够自主完成任务完成度评估工作。该模型将生成的视频序列与语言指令作为输入,依靠视觉语言模型判别任务是否完成,同时支持自定义评分标准,可输出0、0.5、1的分级评分,区分不同程度的任务完成情况。实验结果证实,这套VLM奖励机制的评估准确率高达81%,且假阳性率极低,可有效避免模型对策略性能的高估问题。

图 2 世界模型生成视频与真实视频的定性对比。上排为真实机器人执行的视频,下排为WorldGym基于相同动作序列生成的视频。模型在不同机器人形态(Bridge、RT-1、VIOLA、Berkeley UR5)上均能准确模拟机器人运动和物体交互。
三、实验结果
论文在多个主流VLA策略模型和数据集上进行了全面评估,验证了WorldGym的有效性。
3.1 真实世界与模拟性能的强相关性
在OpenVLA的Bridge评估套件(17个未见任务)上,对RT-1-X、Octo和OpenVLA三个主流策略模型进行评估。如图3所示,实验结果显示,单任务成功率的Pearson相关系数高达r=0.78(p<0.001),三个策略的平均成功率与真实世界的差异仅为3%。
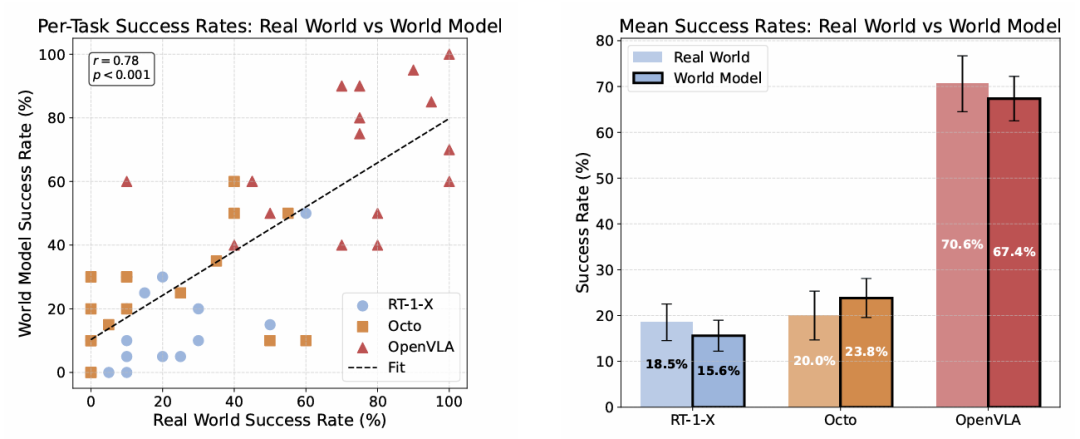
图 3 真实世界与WorldGym中的策略成功率对比。(a)每个任务的成功率散点图,显示出强线性相关性;(b)三个策略的平均成功率对比。
3.2 对不同策略模型进行比较
WorldGym不仅能区分不同模型,还能准确反映同一模型不同版本、大小和训练阶段的性能差异,如图4、5所示。
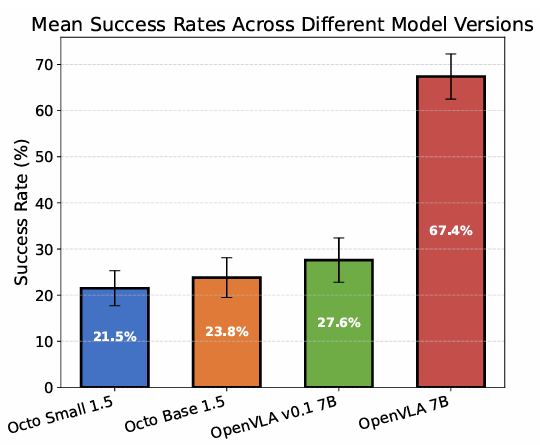
图 4 不同模型版本在WorldGym中的平均成功率。从左到右依次为:Octo Small 1.5B(21.5%)、Octo Base 1.5B(23.8%)、OpenVLA v0.1 7B(27.6%)、OpenVLA 7B(67.4%)。可以清晰看到,更大、更新的模型在WorldGym中获得了更高的评分,这与真实世界实验的结论完全一致。
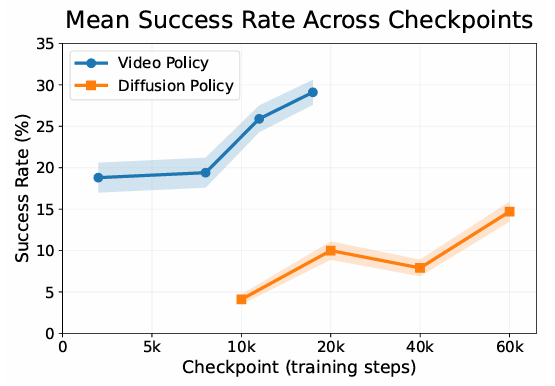
图 5 训练过程中WorldGym内的成功率变化。蓝色曲线为视频策略(UniPi),橙色曲线为扩散策略(DexVLA)。两条曲线都显示出明显的单调上升趋势,即随着训练步数增加,策略在WorldGym中的成功率稳步提高,与它们在验证集上的损失下降趋势完全吻合。
随着训练步数增加,视频策略和扩散策略的成功率均单调上升。这意味着WorldGym可用于策略训练过程中的快速验证和checkpoint选择,无需每次都进行真实世界测试
3.3分布外(OOD)任务评估
WorldGym最大的优势之一是支持极其便捷的OOD测试,只需修改初始图像或语言指令即可创建全新的测试场景。
(1)OOD图像输入
使用图像编辑模型(如Nano Banana)修改初始帧,添加未见物体、干扰物或改变物体属性。如图6所示,OpenVLA难以通过形状区分胡萝卜和橙子。部分情况下会被屏幕上显示的胡萝卜图像干扰,暴露出3D/2D区分能力的不足。所有策略在面对随机干扰物时性能均显著下降,其中Octo下降最严重,OpenVLA最稳健。
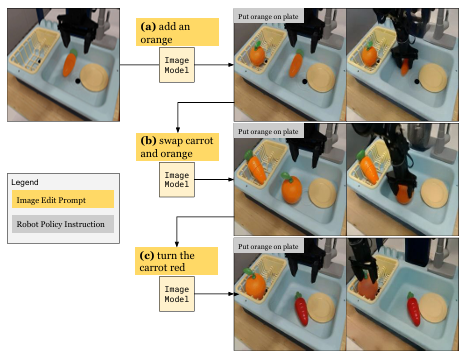
图 6 OOD未见物体测试。(a-b)当胡萝卜和橙子同时存在时,OpenVLA会拿起更近的那个;(c)将胡萝卜涂成红色后,OpenVLA总能正确拿起橙子,说明其主要依赖颜色而非形状进行物体识别。

(2)OOD语言指令
如图7所示,直接修改任务描述,测试策略的语言泛化能力。OpenVLA在所有OOD语言任务上均表现最佳,是唯一能完成"将锅移到台面上"任务的模型。该任务在训练数据中从未出现,因为所有轨迹都局限在水槽区域内。
图 7 分布外(OOD)语言指令。从OpenVLA Bridge评估任务集中选取若干任务,并对其语言指令进行修改,例如更换目标物体或目标位置。
四、结论
WorldGym构建了全新的机器人策略评估范式。该研究首次验证了视频世界模型可作为通用机器人策略评估环境,其评估结果与真实世界性能高度契合,同时创新性提出可变预测步长推理机制,能够高效适配不同动作块尺寸的策略rollout过程,还可实现便捷的OOD任务测试,精准挖掘出机器人策略在真实场景中难以暴露的潜在缺陷,且整套评估流程仅需单张A100 GPU即可在一小时内完成,相较于耗时数天的真实场景测试,整体评估效率实现了数十倍的显著提升。
尽管在复杂物体交互的真实感上仍有提升空间,但WorldGym已经成为机器人部署前进行安全、可复现、低成本评估的强大工具。未来,随着世界模型规模的扩大和训练数据的增加,WorldGym有望进一步缩小与真实世界的差距,甚至成为机器人策略训练的主要环境。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 1
1 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)