StarVLA:视觉-语言-动作模型开发的统一框架
文章
1. 引言
想象一下,如果每个手机厂商都使用完全不同的操作系统和接口标准,开发者需要为每个品牌重写一遍应用程序,这将是多么低效。当前的视觉-语言-动作模型(Vision-Language-Action,简称VLA)研究领域正面临着类似的困境。
VLA是什么?简单来说,就是让机器人能够"看懂"环境、"听懂"人类指令,并做出相应动作的AI模型。但问题在于,不同研究团队开发的VLA系统就像是各自为政的"孤岛",它们在以下三个方面存在严重的不兼容:
- 动作解码方式不同:有的系统让机器人一步步执行动作(像下棋一样思考每一步),有的系统让机器人直接预测整个动作序列(像一次性规划好整条路线)
- 训练流程深度绑定:数据处理、模型训练、评估测试紧密耦合在一起,改动一个地方就要重写整套代码
- 评估标准各不相同:每个团队用不同的测试环境和评分标准,导致无法公平对比谁的方法更好
这种碎片化带来了三大痛点:研究者难以公平对比不同方法的性能;复现一个已发表的算法往往需要数周甚至数月的工程投入;验证新想法变得异常困难,每次都要从零开始搭建系统。
针对这一系统性问题,香港科技大学冯·诺依曼研究所团队开源了StarVLA框架。这个框架就像是VLA领域的"Android系统",为所有研究者提供了统一的开发标准。在GitHub上已获得1.8K星标和226个分支,成为VLA领域最受关注的开源项目,被社区誉为 “VLA界的Linux”。目前代码已经在StarVLA GitHub仓库开源。项目主页。
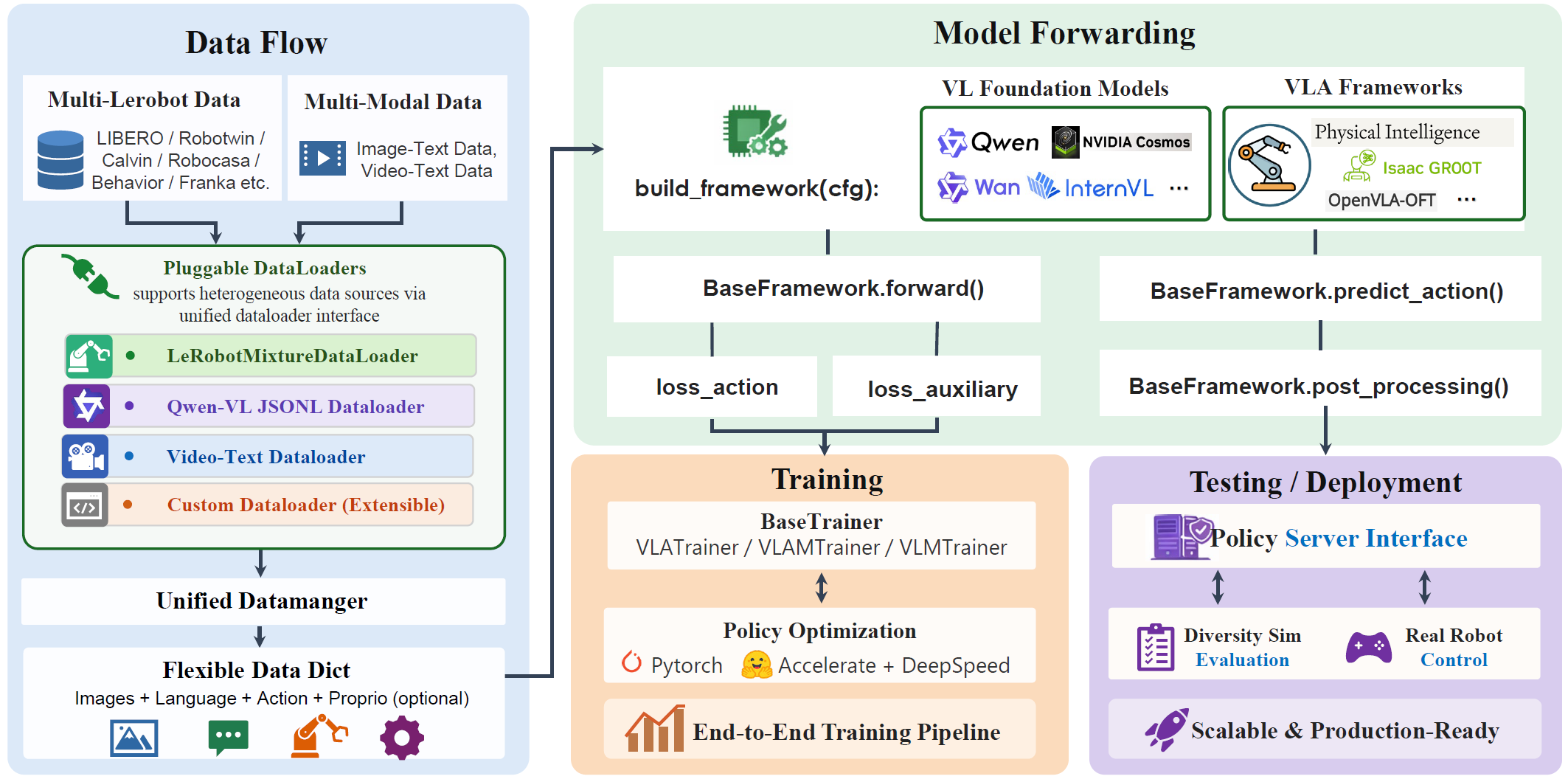
2. 核心设计理念:像搭乐高一样开发机器人AI
2.1 模块化解耦架构:把复杂系统拆成独立积木
StarVLA的设计哲学可以用一个简单的比喻来理解:传统VLA系统就像一台焊死的电脑,想换个显卡就得拆掉整台机器;而StarVLA就像组装电脑,每个部件都可以独立更换升级。
在软件工程中,这叫做"高内聚、低耦合"原则。传统VLA实现中,视觉编码器、语言模型、动作预测头以及数据处理流程往往紧密绑定在一起,形成一个难以拆解的整体。StarVLA通过引入"骨干网络-动作头"(Backbone-Action-Head)解耦架构,将复杂系统分解为可独立开发、测试和替换的模块。
骨干网络(Backbone):相当于机器人的"大脑",负责理解图像和语言指令。就像人类看到一个杯子并听到"把杯子拿起来"这句话时,大脑会理解这个任务的含义。无论是使用Qwen-VL这样的视觉语言大模型,还是使用Cosmos这样的世界模型,都可以作为统一的骨干网络。
动作头(Action Head):相当于机器人的"小脑",负责将大脑的理解转化为具体的肌肉控制指令。它专注于将语义特征转化为机器人的关节角度、移动速度等具体控制信号。
这种设计的最大优势是:研究者可以像搭乐高积木一样自由组合不同的"大脑"和"小脑",在完全控制变量的条件下系统地对比各种技术路线。想测试新的视觉模型?只需替换骨干网络。想尝试新的动作预测方法?只需更换动作头。
更重要的是,StarVLA定义了清晰的模块边界。数据加载器只返回最原始的数据(图像、文字、动作数值),不包含任何模型特定的预处理逻辑。所有模型相关的处理都封装在框架内部。这就像是定义了标准的USB接口,任何符合标准的设备都能即插即用。
# StarVLA数据加载器返回的标准数据格式
sample = {
"image": [PIL.Image, PIL.Image, ...], # 多视角图像列表
"lang": "pick up the red block", # 自然语言指令
"action": np.ndarray([T, 7]), # 动作序列 (时间步 × 动作维度)
"state": np.ndarray([..., 7]) # 可选的状态信息
}
2.2 标准化的数据接口:让不同数据源"说同一种语言"
StarVLA采用LeRobot数据格式作为统一标准,这就像是为所有机器人数据定义了一套"普通话"。无论你的数据来自单臂机械臂、双臂机器人还是移动操作平台,只要转换成这个标准格式,就能无缝接入训练流程。
数据加载器的设计遵循 "模型无关"原则。什么意思呢?就是数据加载器只负责读取和返回最原始的数据,不做任何针对特定模型的预处理。这样做的好处是,同一份数据可以用于训练任何类型的VLA模型,不需要为每个模型重新处理数据。
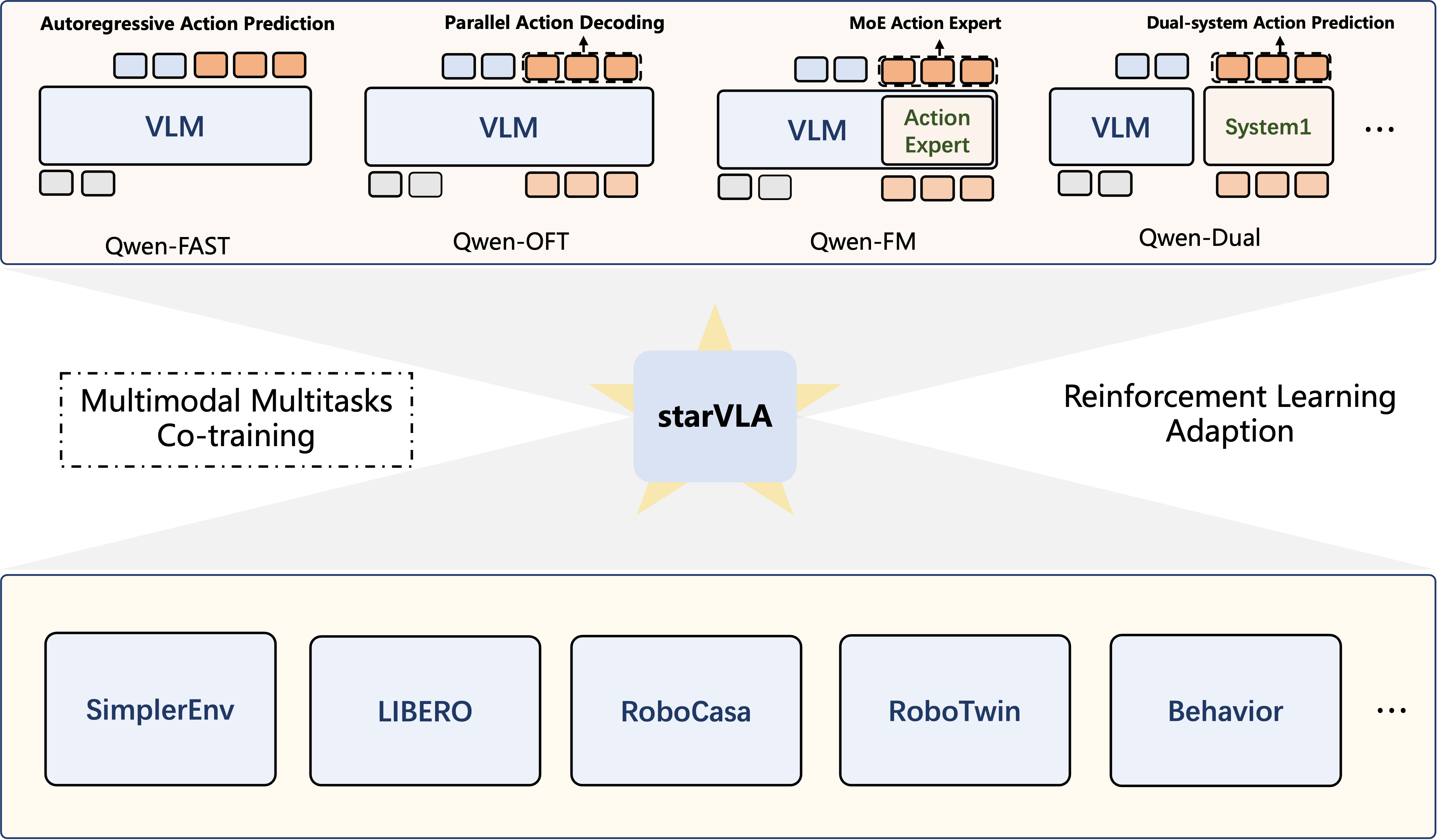
3. 四种动作解码范式:一个框架支持多种"思考方式"
为了兼容现有的各种前沿技术,StarVLA内置了四种最具代表性的动作解码范式。可以把它们理解为机器人的四种不同"思考方式",每种方式都有自己的优势和适用场景。
3.1 StarVLA-OFT:直接预测,简单高效
StarVLA-OFT采用最直接的方式进行动作预测。它的工作原理是:在视觉语言模型的词汇表中加入一个特殊的"动作token"(可以理解为一个专门代表动作的特殊符号),然后通过一个多层神经网络直接预测出机器人应该执行的动作。
这种方法的最大优势是简单高效、训练稳定,特别适合需要快速迭代验证想法的研究场景。就像是让机器人"一眼看穿"应该做什么动作,不需要复杂的推理过程。在LIBERO基准测试中,StarVLA-OFT展现出了卓越的性能,在四个任务套件的联合训练中达到了业界领先水平。
# StarVLA-OFT核心实现逻辑(简化版)
class Qwenvl_OFT(baseframework):
def forward(self, images, lang, actions):
# 1. 视觉语言模型编码:理解图像和指令
vlm_output = self.qwen_vl_interface(
images=images,
text=lang + "<|action|>" # 注入动作特殊token
)
# 2. 提取动作token的隐藏状态:获取"动作理解"
action_hidden = vlm_output.hidden_states[:, -1, :]
# 3. MLP回归预测动作:直接输出动作数值
predicted_actions = self.action_head(action_hidden)
# 4. 计算损失:预测值与真实值的差距
loss = F.l1_loss(predicted_actions, actions)
return loss
3.2 StarVLA-FAST:像语言模型一样生成动作
StarVLA-FAST借鉴了大语言模型的自回归生成方式。什么是自回归?就像ChatGPT生成文字时,一个字一个字地往外蹦,每个字都基于前面已经生成的内容。StarVLA-FAST把连续的动作数值转换成离散的"动作词汇",然后像生成句子一样逐个生成动作token。
这种方法的优势在于可以充分利用预训练语言模型的强大生成能力,特别适合需要长时序规划的复杂任务。比如"打开冰箱、拿出牛奶、倒入杯子、放回冰箱"这样的多步骤任务。
3.3 StarVLA-π:用扩散模型生成平滑动作
StarVLA-π引入了流匹配(Flow Matching)技术,这是一种比传统扩散模型更高效的生成方法。可以把它想象成:从一团随机噪声逐渐"雕刻"出精确的动作轨迹,就像雕塑家从石头中雕出艺术品。
这种方法特别适合需要处理多种可行方案的场景。比如"把杯子放到桌上"这个任务,桌上有很多位置都可以放,StarVLA-π能够生成多样化且平滑的动作轨迹,而不是每次都执行完全相同的动作。
3.4 StarVLA-GR00T:快速反应+深度思考的双系统
StarVLA-GR00T采用了最先进的双系统架构,灵感来源于认知科学中的"双过程理论"。人类的大脑也有两套系统:系统1负责快速直觉反应(比如看到球飞过来立刻躲开),系统2负责深度逻辑思考(比如下棋时的战略规划)。
在StarVLA-GR00T中:
- 系统1(快速反应系统):基于流匹配技术,能够快速生成即时的动作响应
- 系统2(深度思考系统):基于视觉语言模型,负责高层次的任务理解和规划
两个系统通过精心设计的融合机制协同工作,既保证了反应速度,又确保了决策质量。就像一个经验丰富的司机,既能快速应对突发状况,又能提前规划最优路线。
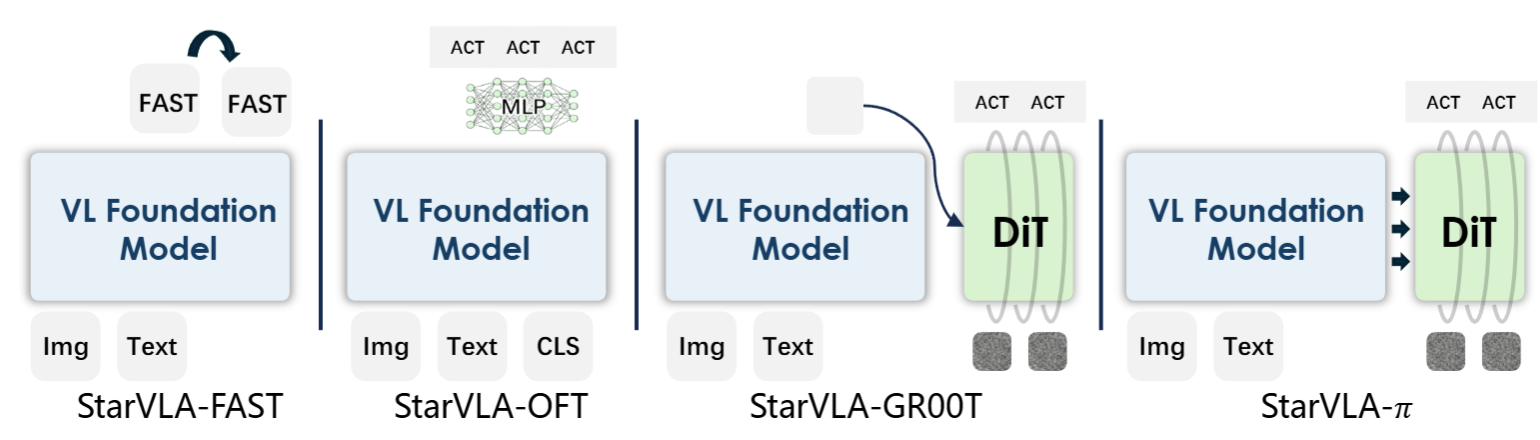
这四种范式都被封装在统一的接口下,研究者只需修改配置文件中的几行代码就能轻松切换。这种设计极大地降低了技术门槛,使得算法对比实验变得简单直接。想测试哪种方法更适合你的任务?只需要改一个参数,其他代码完全不用动。
4. 跨具身与多模态联合训练:让机器人"博学多才"
4.1 多模态联合训练:防止机器人"学了新的忘了旧的"
在传统的机器人训练中,有一个很头疼的问题:当你教机器人学习操作技能时,它可能会忘记之前学过的常识知识。这在AI领域叫做"灾难性遗忘"(Catastrophic Forgetting)。
举个例子:假设你先教一个视觉语言模型认识各种物体和理解语言,它学得很好。然后你开始教它控制机械臂抓取物体,结果训练一段时间后,它虽然学会了抓取,但却忘记了之前学过的物体识别和语言理解能力。这就像一个学生学了数学就忘了语文。
StarVLA通过多模态联合训练解决了这个问题。它的做法是:在训练过程中,同时使用两种数据:
- 机器人操作数据:教模型如何控制机械臂执行动作
- 视觉语言理解数据:保持模型对常识知识的理解能力
这就像是让学生同时学习多门课程,既学新知识,又不断复习旧知识,确保不会遗忘。实验证明,这种训练方式不仅保持了模型的语言推理能力,还提升了它在复杂场景中的操作表现。
# StarVLA多模态联合训练配置示例
datasets:
vlm_data: # 视觉语言理解数据(保持常识能力)
dataset_py: vlm_datasets
data_root_dir: playground/Datasets/LLaVA-OneVision-COCO
per_device_batch_size: 4
vla_data: # 机器人操作数据(学习动作技能)
dataset_py: lerobot_datasets
data_root_dir: playground/Datasets/LEROBOT_LIBERO_DATA
data_mix: libero_all # 支持多数据集混合
per_device_batch_size: 16
trainer:
loss_scale:
vla: 1.0 # 动作损失权重
vlm: 0.1 # 视觉语言损失权重(较小权重,起到"复习"作用)
4.2 跨具身训练:一个模型控制多种机器人
想象一下,如果你学会了开汽车,是不是开卡车、开公交车也会更容易上手?因为它们都遵循相似的驾驶原理。跨具身训练就是让AI模型学习这种"通用操作知识"。
StarVLA通过统一的数据接口支持多种机器人形态的数据混合训练。无论是单臂机械臂、双臂机器人还是移动操作平台,只要将数据转换为LeRobot标准格式,就可以无缝接入训练流程。框架会自动处理不同机器人的动作空间差异。
跨具身学习的关键在于让模型学习到与具体机器人形态无关的通用操作知识。比如"抓取"这个动作,虽然不同机器人的手爪结构不同,但抓取的基本原理是相通的:接近物体、包围物体、施加力量。通过混合训练,模型能够提取出这些跨平台的操作策略,不仅提升了在各个单独平台上的性能,还显著增强了对新机器人平台的泛化能力。
5. 统一的基准测试与评估体系
5.1 为什么需要统一的评估标准?
VLA研究领域长期面临一个问题:不同研究团队使用不同的测试环境、评估协议和性能指标,导致方法间的横向对比变得困难。这就像是有人用米尺测量,有人用英尺测量,还有人用步数测量,最后根本没法比较谁的方法更好。
StarVLA通过整合五大主流基准测试,建立了一套标准化的评估体系。所有基准测试都通过相同的接口与策略服务器通信,确保了评估结果的可复现性和可对比性。
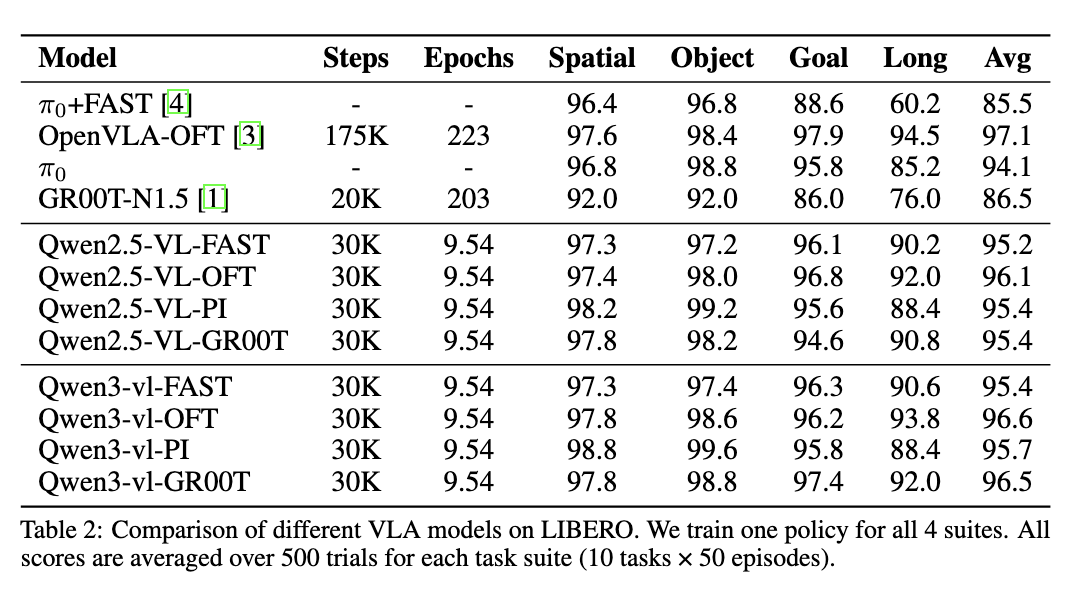
5.2 LIBERO:测试长时序操作能力
LIBERO基准测试包含四个任务套件,涵盖空间推理、物体操作、目标导向和长时序规划等多个维度。比如:
- 空间推理任务:把红色方块放到蓝色方块的左边
- 物体操作任务:打开抽屉、拿出物品、关闭抽屉
- 目标导向任务:根据语言指令完成特定目标
- 长时序任务:执行包含10个以上步骤的复杂操作
StarVLA在LIBERO上采用"统一策略训练"范式,即用一个模型同时学习所有任务。这种设置更接近真实应用场景,也更能考验模型的泛化能力。实验结果显示,StarVLA-OFT配置在四个任务套件上都取得了优异的成绩,而且采用的是极简的训练配方,没有使用复杂的数据增强或特殊训练技巧。
5.3 统一评估接口
StarVLA的统一评估接口是另一大亮点。所有基准测试都通过相同的WebSocket协议与策略服务器通信,评估脚本只需修改少量配置就能切换不同的测试环境。
# StarVLA统一评估接口示例
# 步骤1:启动策略服务器(Terminal 1)
python deployment/model_server/policy_server.py \
--checkpoint path/to/checkpoint.pt \
--framework QwenOFT
# 步骤2:运行评估客户端(Terminal 2)
python examples/LIBERO/eval_files/eval_libero.py \
--policy_server_url ws://localhost:6694 \
--task_suite libero_goal \
--num_episodes 50
这种设计的好处是:
- 模型推理与环境交互完全解耦:策略服务器可以运行在GPU服务器上,环境可以运行在仿真器或真实机器人上
- 支持并行评估:多个客户端可以同时连接到同一个策略服务器
- 易于扩展:添加新的评估环境只需实现相应的客户端适配器
6. 从数据到部署的完整流程
6.1 数据处理
StarVLA采用LeRobot数据格式作为标准,这是一个在具身智能社区广泛采用的数据规范。每个数据集的结构很清晰:
- episodes目录:存储机器人执行任务的轨迹数据
- meta目录:存储元信息,包括数据集描述、统计信息等
- videos目录:存储可选的视频记录,方便可视化分析
关键的modality.json文件定义了数据集的模态信息,告诉系统这个数据集包含哪些类型的数据:
# modality.json示例:定义数据的"身份证"
{
"observation.images.cam_high": {
"shape": [3, 224, 224], # 图像尺寸:3通道,224x224像素
"dtype": "uint8" # 数据类型:8位无符号整数
},
"action": {
"shape": [7], # 动作维度:7个自由度
"dtype": "float32", # 数据类型:32位浮点数
"names": ["x", "y", "z", "roll", "pitch", "yaw", "gripper"] # 每个维度的含义
}
}
数据加载器的设计遵循"模型无关"原则。它实现了一个通用的数据加载器,支持多数据集混合、动态采样、数据增强等功能。在训练过程中,StarVLA支持同时使用多个数据加载器,VLA数据加载器负责加载机器人操作数据,VLM数据加载器负责加载视觉语言理解数据。训练循环会交替从不同数据加载器中采样,根据配置的损失权重计算总损失并更新模型参数。
6.2 模型训练
…详情请参照古月居

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 4
4 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)