RoboLab:机器人通用策略泛化的仿真评估
摘要
通用机器人的研究催生了性能优异的基础模型,但基于仿真的基准测试仍因性能快速饱和、缺乏真正的泛化测试而成为瓶颈。现有基准的训练与评估领域往往存在大量重叠,导致成功率虚高,无法反映模型的鲁棒性。本文提出RoboLab,一款针对上述问题的仿真基准测试框架。具体而言,本框架旨在回答两个问题: (1) 如何通过仿真行为分析理解现实世界策略的性能; (2) 可控扰动下,哪些外部因素对策略行为影响最大。
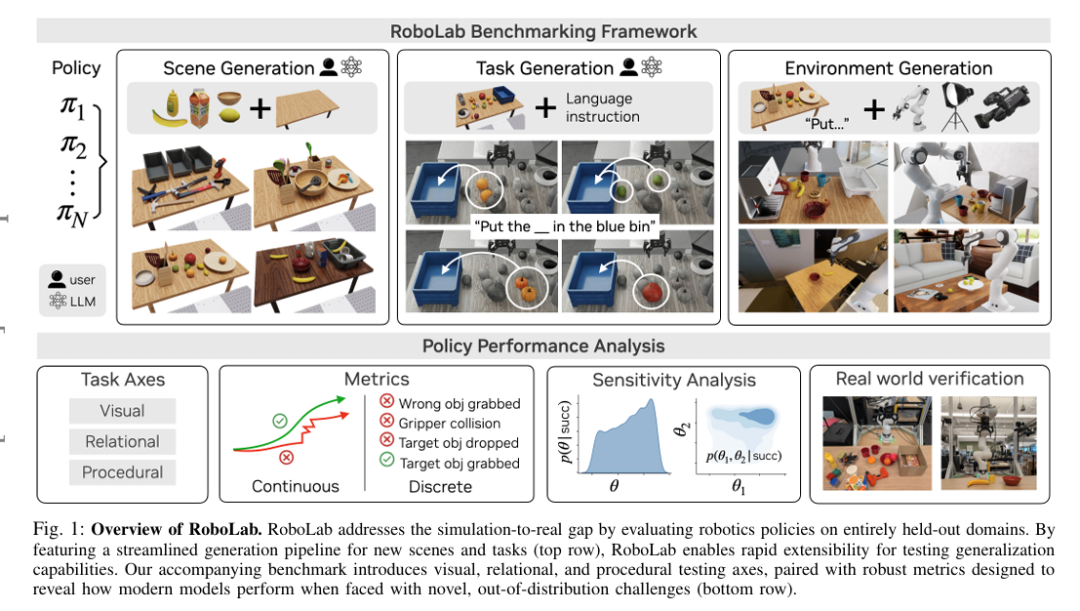
首先,RoboLab支持在物理真实、视觉逼真的仿真环境中,以与机器人和策略无关的方式,通过人工编写与LLM生成场景和任务。据此,本文提出RoboLab-120基准,包含120项任务,分为视觉、过程化、关系三大能力维度,覆盖三个难度等级。
其次,本文系统性分析现实世界策略,量化其性能与行为对可控扰动的敏感性,证明高保真仿真可作为分析性能及其外部因素依赖性的代理工具。基于RoboLab的评估揭示出当前最优模型存在显著性能差距。凭借细粒度指标与可扩展工具集,RoboLab为评估任务通用型机器人策略的真实泛化能力提供了可扩展框架。
一、引言
通用性一直是现代机器人领域的长期挑战。近期进展已诞生出能在现实世界完成复杂新颖任务的优秀通用机器人策略。尽管取得进步,评估这些策略是否真正具备任务通用性的基准发展缓慢。在现实世界评估模型成本极高、工程上难以实现,推动基于仿真的基准成为极具吸引力的替代方案。
当前机器人基准存在若干关键局限:
-
缺乏支持现实策略的高保真仿真;
-
静态任务集上性能快速饱和;
-
缺乏对策略失效模式的细粒度分析。
例如,主流基准如LIBERO常使用几乎相同的环境进行训练与评估。当策略在这些仿真专用演示数据上微调时,因缺乏有意义的领域差距,评估过程失去价值,掩盖模型真实泛化能力。许多现有平台真实度有限,或因架构僵化难以扩展,引入新物体、任务或机器人十分繁琐(图2)。

为解决上述局限,本文提出RoboLab(图1),一款用于严谨机器人评估的仿真平台与基准套件。与依赖PDDL或僵化场景图定义的现有基准不同,RoboLab提供易用接口,支持人工编写与LLM规模化生成场景与任务。RoboLab可从自然语言提示生成并验证新场景与任务,系统可创建超800种多样化场景(见补充材料),提供可扩展框架,缓解基准饱和问题并保证长期价值。
RoboLab引入全新任务维度与鲁棒性指标,提供深度诊断分析,搭配简化的场景与任务生成工具集(见图1)。为细粒度评估策略行为,本文从三大维度测试:
-
视觉能力:颜色、尺寸等感知属性;
-
过程化能力:堆叠、重定向等动作逻辑;
-
关系能力:“与/或”等空间与语言逻辑。
任务覆盖三个难度等级,由任务长度与语言复杂度决定。策略在这些任务上的执行效果通过分级任务完成度、失效与错误发生率、轨迹质量等指标评估。本文还提出新型评估指标,包括敏感性分析,用于识别对策略性能影响最大的环境因素(如相机位置)。
本文提出RoboLab-120基准,包含通过自动化流程生成并经人工验证的120项任务。任务覆盖不同难度(35项简单、28项中等、16项复杂)与多能力维度(33项关系、54项视觉、9项过程化)。为避免过拟合仿真领域,本文仅在现实世界DROID数据集上训练策略,再进行评估。该设置贴近“野外”条件,例如当前最优的在RoboLab-120上仅取得约30%成功率,凸显基准的难度。
本文贡献
-
RoboLab:全新仿真平台,用于评估现代机器人策略,具备可扩展、基于LLM的工作流,可在IsaacLab中通过人类可读的USD与Python接口程序化生成超800种独特场景与任务。
-
RoboLab-120基准:包含120项任务,覆盖三大能力维度(视觉、过程化、关系),配套四项全新鲁棒性指标;本文还在RoboLab-120上评估了五项策略。
-
策略分析:提出一整套分析工具,超越二值成功率,深入解析模型性能,全面理解策略行为。
二、相关工作
基于仿真的基准
仿真为评估机器人操作策略提供可扩展、可复现的环境。主流基准如RLBench、MetaWorld、robosuite、ManiSkill2、CALVIN、LIBERO、BEHAVIOR1K提供标准化任务集,用于在预定义任务族与物体配置下的仿真学习与评估。但在这些设置中,策略通常在相同仿真环境中训练与评估,易导致过拟合仿真特性、基准快速饱和,难以评估现实泛化能力。
本文设置中,策略在大规模现实数据(如DROID)上训练,高保真仿真仅作为可控评估环境,训练与评估领域解耦,测得性能更贴近现实鲁棒性。
VLA SOTA哪家强? 盘点20个VLA benchmarks
Real-to-sim 评估
近期研究聚焦利用三维重建,从现实视频构建照片级真实仿真场景,缩小仿真与现实的视觉对齐差距。这类工作常使用高斯泼溅、三维分割、多视图修复,逐场景处理,优化成本高,难以扩展到少量环境之外。
与之对比,本框架可在分钟级生成大规模照片级真实场景与任务,同时保留足够几何与视觉保真度用于策略评估,让实转仿基准测试在现代通用机器人策略所需规模下具备实用性。
三、RoboLab
在仿真中评估现实世界、通用型机器人策略仍是重大挑战。RoboLab作为基准测试框架,引入三大全新任务维度与三项原创指标,适配现代机器人系统。RoboLab支持对VLA模型的多维度分析,深入揭示其可扩展性与任务泛化能力。
A. RoboLab-120

受LLM领域视觉问答(VQA)基准启发,本文提出RoboLab-120基准,聚焦评估跨三个难度等级的特定能力维度。这种分类式分解可通过系统性评估性能,实现策略能力的细粒度分析。图4展示指令示例与对应场景。
能力维度定义
-
视觉能力:评估颜色、语义、尺寸识别,衡量策略将感知属性与高级推理关联的能力。
-
过程化能力:评估执行面向动作推理任务的能力,包括可及性、重定向、堆叠。
-
关系能力:测试对语言连接词(如and/or)、计数、空间关系的理解,衡量策略解析多物体指令与场景结构的效果。
这些能力维度的任务可分为简单、中等、复杂三个难度等级,由两方面决定:语言描述任务的直白程度、完成任务所需推理步骤数量。
B. 评估指标
本文建立全面的评估指标体系,覆盖策略性能的全部特征。尽管任务成功率仍是基础指标,但已有研究表明其无法揭示策略行为与失效模式的细微特征。与依赖人工判断的方法不同,本文定义一组离散与连续指标刻画策略性能,分为失效案例评分、轨迹指标、敏感性分析三类。
失效案例
除成功率外,本文计算归一化分级得分:
例如,指令“拿起柠檬与青柠”包含子任务“拿起柠檬”“拿起青柠”,每个子任务包含“抓取”“放置”等步骤。最终任务得分为子任务得分的归一化均值。

基准自动记录事件:抓取错误物体、物体掉落、夹持器碰撞。图3展示一次成功回合,但策略错误抓取无关物体,这类错误揭示了其他指标无法捕捉的策略潜在偏差。
轨迹指标
轨迹质量指标衡量运动效率与最优性,计算如下:谱弧长(SPARC):通过速度剖面归一化傅里叶幅度谱的弧长评估运动平滑度。给定末端执行器在时间区间的速度剖面:
其中为归一化傅里叶幅度谱。运动越平滑,值越接近0;轨迹越抖动,值越负。
本文采用自适应截止频率,其中,为超过阈值的频率区间集合。该自适应策略确保平滑度评估聚焦相关频率分量。
轨迹最优性通过末端执行器速度与路径长度评估,为第步末端执行器位置。路径越短,轨迹越直接,通常运动质量越好。

C. 敏感性分析
本文提出基于仿真推理(SBI)的贝叶斯框架,评估策略在多样环境条件下的鲁棒性。该分析通过学习近似后验分布,揭示哪些场景参数与成败结果强相关。
设为环境参数,包含连续变量(如物体距离、相机位移)与离散变量。在多样条件下评估策略后,生成数据集,为观测结果(如任务成功)。
后验分布通过混合神经后验估计(MNPE)近似,训练神经密度估计器直接学习观测到参数分布的映射。最终后验刻画与目标观测最相关的场景变量。本文方法系统性评估影响性能结果的关键变量,更多细节见附录B。
D. RoboLab场景与任务生成

RoboLab提供贴合现实机器人评估流程的易用工作流(图1):
-
在工作空间摆放物体创建场景;
-
以语言指令定义场景目标状态任务;
-
选择机器人、策略与场景特征(相机、光照、背景)实例化环境。
本文将任务定义与环境解耦,支持在新机器人与策略上复用,保证流程可复现、可扩展。本方法自动化环境构建,降低评估新机器人或策略的人工成本。此外,本文开发自动化流程生成新场景与任务,便于扩展评估并缓解未来基准饱和问题。
形式化定义:
-
场景,为物体实例,为位置,为朝向;
-
任务,为场景中需完成的语言指令;
-
策略,动作空间,观测空间因策略而异;
-
环境,包含任务、机器人本体、策略参数、场景变化。
更多物体、场景与任务细节见附录A。
1. 场景生成规模化
本文通过自动化流程实现场景生成规模化:
-
提示LLM生成资产摆放的结构化场景规划;
-
用几何求解器与物理仿真检查资产摆放有效性;
-
无效则优化场景。
首先,以主题(如“杂乱台面”)提示LLM,生成包含物体子集与空间谓词的结构化场景规划。LLM获取完整物体目录,包含名称与包围盒尺寸。
其次,空间求解器将关系谓词转换为有效位姿配置。物体按依赖顺序处理,支撑面先于其上物体摆放(算法1)。为检查物理稳定性,场景在Isaac Sim中受重力前向仿真300步。若物体最大欧氏位移超过阈值(通常0.02m),标记为不稳定。
最后,若任意物体不稳定,生成文本错误描述(如“物体‘苹果’从‘盘子’掉落,位移0.15m”),反馈给LLM优化场景规划并重复流程。更多空间与物理求解器细节见附录C。
2. 任务生成规模化
本文通过自动化流程实现任务生成规模化:
-
从场景与能力维度信息生成任务代码;
-
验证代码语法;
-
验证场景中资产选择;
-
无效则优化任务。
首先,以详细任务信息提示LLM:
-
场景物体目录与元数据(含包围盒、尺寸);
-
展示任务结构的示例;
-
定义子任务成功与终止条件的完整谓词库;
-
含物体、空间动词、属性占位符的能力维度语言模板;
-
难度等级、物理可行性约束(如容器尺寸约束、堆叠稳定性)。
提示禁止引用外物体,并包含已生成任务避免重复(见附录C)。
其次,检查任务代码语法有效性。 第三,资产验证确保所有物体不在禁止集合,容器类任务(如“把放进”)确保内部物体可放入容器并保留间隙。 第四,若验证失败,收集反馈生成修复提示,包含原始提示、无效输出、错误信息,交给LLM优化任务并重复。
本文使用LLM-as-judge框架评估任务生成方法。基于o1在59个场景、跨能力维度生成812项任务,提取每条自然语言指令与程序终止条件,提示第二个o1评判器从关系、目标、物体、量词匹配、指令清晰度、物理可行性六个维度(0–1分)打分,并判定对齐/部分对齐/不对齐。
整体任务对齐度0.91、清晰度0.96、可行性0.92、语义匹配0.95,76%完全对齐(不对齐≈1%),覆盖88%物体。结果表明本方法可规模化生成多样化、与语言指令语义对齐的任务(见附录D)。
四、实验
本文在RoboLab-120、可控消融、环境扰动上评估多款现成VLA策略,识别泛化能力与失效集中点。实验旨在回答: Q1:现实策略在本仿真基准表现如何? Q2:策略对语言变化的泛化能力如何? Q3:策略何时、为何失效?
A. 实验设置
本文评估80项任务,覆盖不同难度(35项简单、28项中等、16项复杂)与能力维度(33项关系、54项视觉、9项过程化),每项任务可归属一个或多个维度。实验使用DROID机器人,搭载7自由度Franka Panda机械臂、Robotiq-2F-85夹持器、外置ZED 2i相机(焦距2.1mm)、腕部ZED mini相机。
本文评估在DROID数据集微调的现成VLA模型:、-FAST、、PaliGemma、GR00T N1.6。动作空间为7自由度Franka关节位置与1自由度二值夹持器指令。环境采用类办公室默认背景与自然光照,贴近DROID数据集典型设置,腕部与外置相机位姿匹配现实DROID机器人。每项任务固定随机种子重复10次,消除物理仿真与机器人策略的不可控随机性。
B. 任务结果
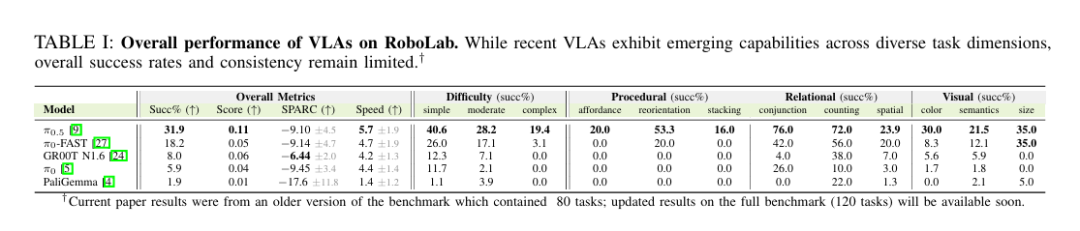
表I展示基准整体结果。整体成功率偏低,最优策略仅31.9%,与现有VLA分布外泛化观察一致。下文以为例,说明RoboLab如何支持策略能力针对性诊断与改进方向。
能力维度揭示关系推理任务的非对称泛化:在连接词(76.0%)、计数(60.0%)上表现优于空间关系(23.9%)。视觉基础方面,各属性类型性能均偏低(尺寸35.0%、颜色30.0%、语义21.5%),表明超出窄范围熟悉描述外,语言到物体的绑定较脆弱。过程化理解最具挑战:在重定向(53.3%)上表现尚可,但在可及性(20.0%)、堆叠(16.0%)上表现较差。
上述结果表明RoboLab可定位泛化失效点,支撑数据采集与训练优先级的诊断决策。
C. 消融实验
为进一步探究鲁棒性与语言基础,本文执行可控消融,单独改变指令、场景或任务(图7)。

固定场景下指令清晰度变化
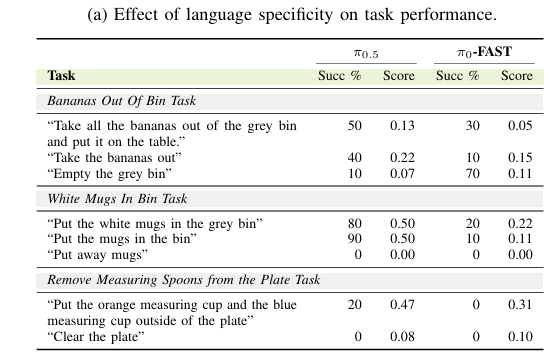
表IIa展示VLA对不同指令清晰度的响应。结果表明VLA缺乏抽象与隐含目标的基础能力。有趣的是,模糊指令“清空灰色箱子”时,试图抓取箱子而非清空内容,说明当前VLA可能依赖指令关键词匹配,而非具备识别隐含任务目标的语言推理能力。在清晰指令上性能高于模糊指令,对未明确指定的任务目标敏感。
固定指令下场景复杂度变化
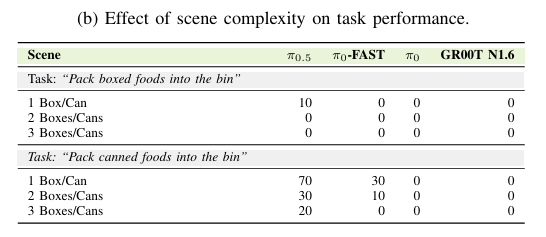
表IIb通过增加待操作物体数量,单独分析场景复杂度影响。成功率随物体数量增加下降:单目标70%→三目标20%。更关键的失效类型:VLA呈现系统性几何偏差,指令操作盒子时频繁抓取圆柱物体(罐子),表明训练数据分布形成强形状先验,覆盖语言指定目标,这是现实部署中物体几何多样场景下的关键局限。
固定场景下任务变化
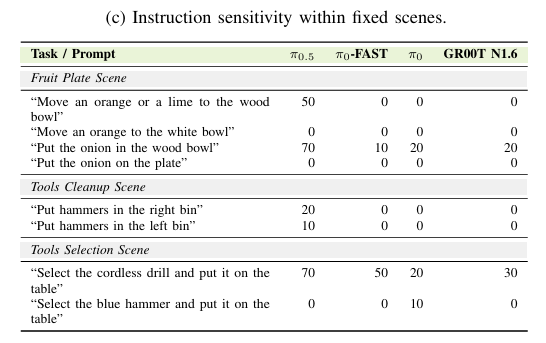
表IIc展示固定场景下VLA对不同指令的灵活响应能力。结果暴露脆弱的语言基础:对物体选择高度敏感,指令“拿起无绳电钻放桌上”成功率70%,替换为“蓝色锤子”则0%。错误分析揭示一致的物体混淆模式:视觉相似干扰物(南瓜vs橙子、电钻vs锤子)常覆盖语言指定目标(见附录表VI)。该发现表明VLA语言基础高度依赖训练中见过的特定物体-指令配对,而非具备可泛化的语言到物体绑定能力。
D. 敏感性与鲁棒性
本文在两项基础任务上执行多样变化并观测结果,例如仅改变拾取目标或放置目标,类似领域随机化(图6)。考虑的变化包括:
-
腕部与外置相机位姿;
-
物体位姿;
-
视觉特征(背景、桌面纹理);
-
光照(饱和度、色相)。
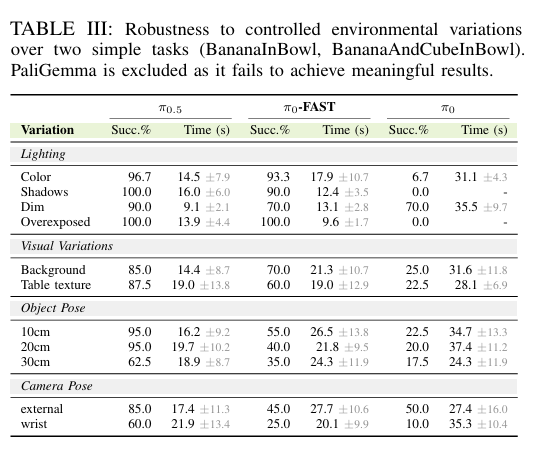
表III展示所有实验结果。
视觉与光照变化
光照:通过色温偏移、曝光、强定向光(产生运动阴影)改变光照条件。VLA对光照变化鲁棒,阴影、色温、500倍强度变化下成功率90–100%。
视觉外观:10种背景纹理、4种桌面纹理变化影响极小(退化<5%),表明对场景外观变化泛化良好。
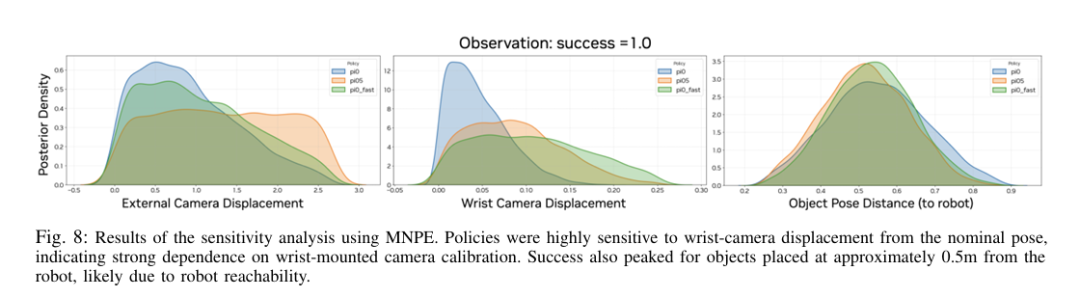
相机变化敏感性分析
本文基于任务成功推断相机位移后验(图8)。相机位姿朝向与位置随机化,每回合10次。位移相对于相机标称位置计算。所有策略中,腕部相机后验高度集中于0附近,表明成功执行常要求腕部相机接近标称位姿,而对外置相机位置变化更宽容。说明性能关键依赖腕部相机,而非外置相机。
物体位姿变化敏感性分析
本文将初始物体位姿在标称位置(机器人正前方)均匀随机化10cm、20cm、30cm,每回合10次。基于任务成功推断初始物体位姿后验(图8),相对于机器人位姿。观察到距离机器人原点0.5m处有强峰值,表明该距离摆放物体成功率最高,可能源于可达性。
E. 现实机器人验证
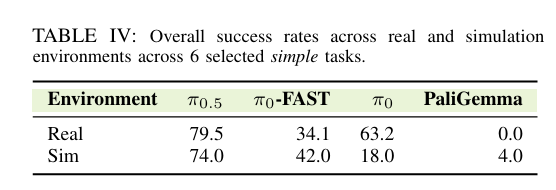
本文在少量6项简单现实机器人任务上评估相同策略,对比匹配仿真评估成功率(表IV)。现实成功率79.5%,接近仿真74.0%,表明RoboLab可作为该策略此类任务的合理代理。-FAST现实34.1%、仿真42.0%,趋势一致。为显著异常值,现实63.2%、仿真仅18.0%,定性观察该策略专为可靠抓取单物体调优,匹配所选现实任务。策略专属的仿真到现实偏差留待未来研究。
五、局限
尽管RoboLab为评估语言条件操作提供灵活可扩展框架,当前聚焦刚体桌面场景,未完全覆盖可变形物体操作(如布料、线缆、袋子)挑战。此外,许多需要精确力控、柔顺交互、复杂摩擦动力学的接触密集型技能覆盖不足,且依赖物理仿真保真度,限制RoboLab对细粒度底层控制任务的覆盖。最后,尽管高保真仿真评估是现实性能的强代理,仍存在残余视觉分布偏移,需通过分析视觉感知栈行为与鲁棒性、大量现实部署验证进一步刻画该差距。
六、结论
近期基准测试在可扩展机器人评估上取得显著进展,但主要评估训练环境扰动的鲁棒性,而非对全新场景的真正任务泛化。RoboLab填补该空白,在高保真仿真中评估现实策略,将策略能力分解为视觉、过程化、关系三大结构化评估向量,并提供新型敏感性分析,深入揭示机器人策略行为。本基准框架帮助学界严谨回答泛化与性能问题,同时设计务实易用:几分钟即可通过桌面摆放物体与附加语言指令编写新任务,生成式场景-任务-环境工作流支持基准持续演进。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 7
7 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)