飞书 + CoPaw 实现自动化打卡机器人
飞书 + CoPaw实现自动化打卡机器人
Skill技能包下载:点击下载
1. 需求设计
用户在群聊中上传打卡图并@机器人,机器人识别并自动执行流程:触发-下载-OCR识别-提取到的信息填入多维表格-成功提示
2. 基础配置
2.1 飞书
在项目开始之前,请先确保飞书中的企业自建应用已经与 CoPaw 进行关联。教程参考:CoPaw飞书设置教程
2.1.1 基础配置
- 成功获取参数
- App ID
- App Secret
- 企业自建应用已成功发布
- 事件与回调-事件配置-订阅方式为长连接模式
2.1.2 企业自建应用权限配置
- 打开 飞书开放平台,选择「权限管理」中的「批量导入/导出权限」,将以下JSON代码复制进去
提示:当前权限存在冗余情况,请根据自身需求进行权限删减。
{
"scopes": {
"tenant": [
"im:message.group_at_msg:readonly",
"aily:file:read",
"aily:file:write",
"aily:message:read",
"aily:message:write",
"base:app:read",
"base:app:update",
"base:collaborator:create",
"base:collaborator:delete",
"base:field:create",
"base:field:delete",
"base:field:read",
"base:field:update",
"base:form:read",
"base:form:update",
"base:record:create",
"base:record:delete",
"base:record:update",
"base:table:read",
"base:table:update",
"bitable:app",
"contact:user.base:readonly",
"corehr:file:download",
"im:chat",
"im:resource"
],
"user": []
}
}
2.1.3 多维表格配置
- 以下图为例,通过浏览器打开网页版多维表格,在地址栏中出现
https://my.feishu.cn/base/MGUdbDtK2aPiUnsFXhochCAGnwC?table=tblK4eo2hxSQXNgE&view=vewqDJa2St
其中 MGUdbDtK2aPiUnsFXhochCAGnwC 为多维表格的App Token,tblK4eo2hxSQXNgE为当前数据表的Table ID,之后会用到
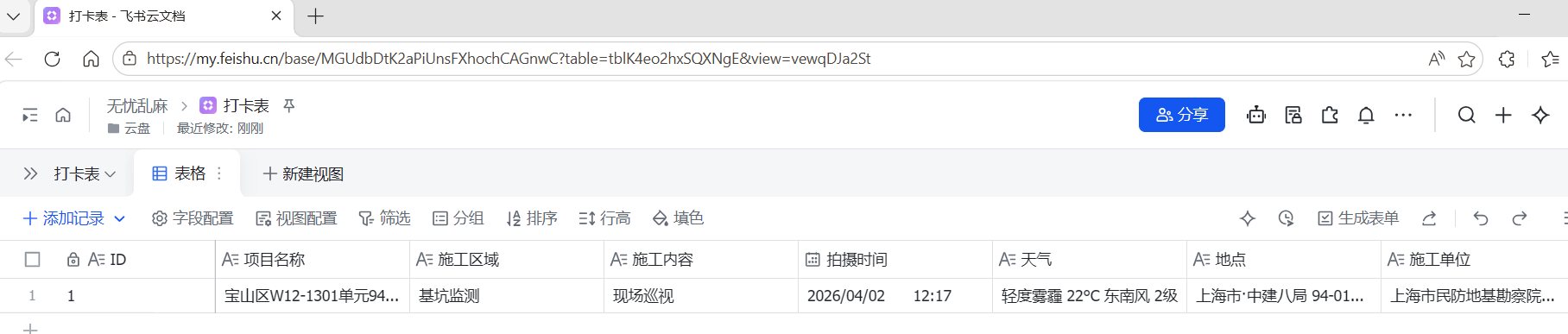
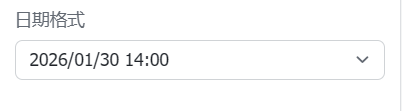
- 数据表中的 “拍摄时间” 列的日期格式建议调整为
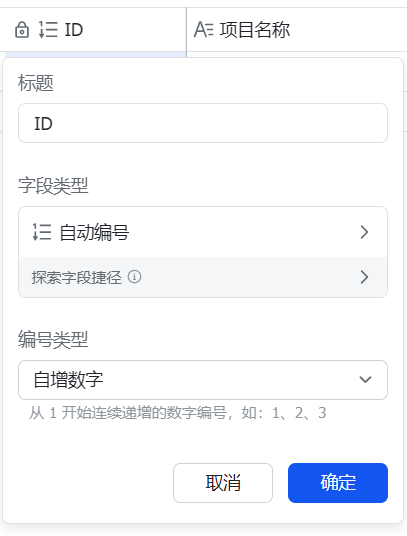
- 索引列建议设置为自动编号 - 自增数字
2.2 Copaw
2.2.1 基础配置
- 绑定好你所选用的大模型
- 按照地址 ‘C:\Users\你的用户名.copaw\config.json’ 找到config.json文件,修改飞书相关参数,可复制下方代码块进行替换
主要修改三个参数:“require_mention”: true, 确保只有@机器人,才触发,否则机器人处于静默状态。 “app_id”: “你的app id”, “app_secret”: “你的app secret”
"feishu": {
"enabled": false,
"bot_prefix": "",
"filter_tool_messages": false,
"filter_thinking": false,
"dm_policy": "open",
"group_policy": "open",
"allow_from": [],
"deny_message": "",
"require_mention": true,
"app_id": "你的app id",
"app_secret": "你的app secret",
"encrypt_key": "",
"verification_token": "",
"media_dir": null,
"domain": "feishu"
},
- CoPow左侧菜单 - 频道 -飞书 - 修改 App ID 与 App Secret - 关闭“显示工具消息” 和 “显示思考过程” - 保存
3. Skill技能包
3.1 .env文件说明
记录了py文件执行时所需要的各种密钥,若需要修改,可先转为txt文件,之后再转回.env
# 飞书应用配置
LARK_APP_ID=xxxxx
LARK_APP_SECRET=xxxxx
# 飞书多维表格配置
BASE_APP_TOKEN=xxxxx
BASE_TABLE_ID=xxxxx
# 通义千问API配置(阿里云百炼平台获取)
#主要针对使用的模型是云端大模型,本地大模型或者公司内网部署的大模型可忽略
DASHSCOPE_API_KEY=xxxxx
# 图片保存目录(你要保存的路径)
SAVE_IMAGE_DIR=xxxxx
3.2 .py文件说明
加载环境变量
# construction_checkin_local.py
# 类型: ignore[reportMissingImports]
from copaw.skills import Skill, skill
import os
import json
import time
import requests
from pathlib import Path
from dotenv import load_dotenv
import logging
# 配置日志
logger = logging.getLogger("ConstructionCheckinSkill")
# 加载环境变量
load_dotenv(dotenv_path=Path(__file__).parent / ".env")
# ==================== 配置从 .env 读取 ====================
LARK_APP_ID = os.getenv("LARK_APP_ID")
LARK_APP_SECRET = os.getenv("LARK_APP_SECRET")
BASE_APP_TOKEN = os.getenv("BASE_APP_TOKEN")
BASE_TABLE_ID = os.getenv("BASE_TABLE_ID")
# 图片保存目录(现在从环境变量读取)
SAVE_IMAGE_DIR = os.getenv("SAVE_IMAGE_DIR")
# ==========================================================
如果选用云端大模型,需要配置下方语句,并在.env文件中添加,否则忽略
DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY")
在程序启动时,完成身份验证并获取必要的运行时信息,为后续操作(如下载图片、读取多维表格)做准备
@skill
class ConstructionCheckinSkill(Skill):
name = "construction_checkin"
description = "施工打卡图片自动处理:下载 → 识别 → 录入多维表格"
def __init__(self):
super().__init__()
self.tenant_token = None
self.token_expire = 0
self.bot_id = None # 初始化为空
# 1. 验证必要配置
if not all([LARK_APP_ID, LARK_APP_SECRET, BASE_APP_TOKEN, BASE_TABLE_ID, SAVE_IMAGE_DIR]):
logger.error("❌ 严重错误:环境变量配置缺失,请检查 .env 文件")
return
# 2. 自动创建保存目录
os.makedirs(SAVE_IMAGE_DIR, exist_ok=True)
# 3. 初始化时主动获取 Token 和 Bot ID
token = self.get_tenant_token()
if token:
self.fetch_bot_open_id(token)
else:
logger.warning("⚠️ 初始化失败:无法获取 Tenant Token")
def get_tenant_token(self):
"""获取租户访问令牌(带重试机制)"""
now = time.time()
if self.tenant_token and now < self.token_expire:
return self.tenant_token
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
data = {"app_id": LARK_APP_ID, "app_secret": LARK_APP_SECRET}
max_retries = 3
for attempt in range(max_retries):
try:
resp = requests.post(url, json=data, timeout=10)
result = resp.json()
if result.get("code") == 0 or "tenant_access_token" in result:
self.tenant_token = result["tenant_access_token"]
self.token_expire = now + result.get("expire", 7140) # 7200 - 60
logger.info("✅ 成功获取 Tenant Token")
return self.tenant_token
else:
logger.warning(f"❌ 第 {attempt+1} 次获取 Token 失败: {result.get('msg', 'Unknown error')}")
except Exception as e:
logger.warning(f"❌ 第 {attempt+1} 次请求 Token 异常: {str(e)}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # 指数退避
return None
def fetch_bot_open_id(self, token):
"""调用飞书 API 获取机器人的 Open ID"""
url = "https://open.feishu.cn/open-apis/bot/v3/info"
headers = {"Authorization": f"Bearer {token}"}
try:
response = requests.get(url, headers=headers, timeout=10)
result = response.json()
if result.get("code") == 0:
self.bot_id = result["bot"]["open_id"]
logger.info(f"✅ 成功获取机器人 ID: {self.bot_id}")
else:
logger.error(f"❌ 获取机器人 ID 失败: {result.get('msg')}")
except Exception as e:
logger.error(f"❌ 请求机器人信息异常: {str(e)}")
机器人处理核心业务逻辑:接收消息、下载图片、用 AI 识别图片内容、最后把结果写入多维表格
def should_handle(self, message):
"""
最终修正版:
1. 优先处理图片消息 (msg_type == 'image')
2. 其次处理 @ 机器人的消息 (精准匹配 ID)
"""
# --- 防御性检查:确保 bot_id 已获取 ---
if not self.bot_id:
logger.warning("⚠️ 机器人 ID 未就绪,暂时忽略消息")
return False
# --- 1. 预处理:解析 Content ---
content_dict = {}
if isinstance(message.content, str):
try:
content_dict = json.loads(message.content)
except:
return False # 解析失败直接忽略
elif isinstance(message.content, dict):
content_dict = message.content
# --- 2. 图片检测逻辑 (严格判断 msg_type) ---
# 飞书图片消息的 msg_type 固定为 'image'
# 这一步能防止非图片消息误触发
if getattr(message, 'msg_type', '') == 'image':
# 再次确认 content 结构中包含 image_key
image_info = content_dict.get('image')
if image_info and isinstance(image_info, dict) and image_info.get('image_key'):
logger.info("✅ 检测到图片消息,触发处理")
return True
# --- 3. @ 机器人检测逻辑 (精准匹配 ID) ---
mentions = getattr(message, 'mentions', [])
if mentions and isinstance(mentions, list):
for mention in mentions:
# 获取被 @ 对象的 id
mention_id = mention.get('id') or mention.get('user_id') # 兼容不同字段名
if mention_id == self.bot_id:
logger.info("✅ 检测到明确 @ 机器人,触发处理")
return True
# --- 4. 其他情况不处理 ---
return False
# === 执行入口 ===
async def execute(self, message, context=None):
""" CoPaw 调用技能的标准入口。 """
# 从消息中提取 image_key
# 注意:这里需要根据 message 的实际结构获取 image_key
# 如果是图片消息,通常在 content 字典里
content = message.content
if isinstance(content, str):
try:
content = json.loads(content)
except:
return "无法解析消息内容"
image_key = content.get('image_key') if isinstance(content, dict) else None
if not image_key:
return "请发送一张图片。"
# 复用你写好的 run 逻辑
result = self.run(image_key)
return result
def download_image(self, image_key: str) -> str:
try:
token = self.get_tenant_token()
if not token:
return None
url = f"https://open.feishu.cn/open-apis/im/v1/images/{image_key}/raw"
headers = {"Authorization": f"Bearer {token}"}
resp = requests.get(url, headers=headers, timeout=30)
if resp.status_code != 200:
logger.error(f"图片下载失败,状态码:{resp.status_code}")
return None
# 保存到.env指定的目录
save_path = os.path.join(SAVE_IMAGE_DIR, f"{image_key}.png")
with open(save_path, "wb") as f:
f.write(resp.content)
logger.info(f"图片已保存:{save_path}")
return save_path
except Exception as e:
logger.error(f"下载图片异常:{str(e)}")
return None
Online和Local版本最本质的区别:针对大模型的调用方式不一样extract_info_local和extract_info_online两个代码块保留其一即可
extract_info_local为本地大模型进行图像识别的调用方式
def extract_info_local(self, image_path):
""" 使用 CopaW 内置的 Ollama 模型识别图片信息 """
try:
# 1. 导入 ollama 库
import ollama
# 2. 构建提示词
prompt = """请从这张施工打卡图片的水印中提取以下字段,只返回标准的JSON字符串,不要任何其他内容(不要包含```json标记):
字段:项目名称、施工区域、施工内容、拍摄时间、天气、地点、施工单位。
如果图片中没有该字段,请填"未识别"。"""
# 3. 调用模型
# 注意:请确保模型名称与 Ollama 中一致
response = ollama.chat(
model='Qwen3.5-35B-A3B-v3-Q8_0.gguf', # 👈 请检查你的模型名称
messages=[
{
'role': 'user',
'content': prompt,
'images': [image_path] # 👈 直接传路径
}
],
options={'temperature': 0.0}
)
# 4. 解析结果
text = response['message']['content'].strip()
# 清理可能存在的 Markdown 标记
text = text.replace("```json", "").replace("```", "").strip()
return json.loads(text)
except Exception as e:
logger.error(f"图片识别失败(Ollama): {str(e)}")
return None
extract_info_online为云端大模型进行图像识别的调用方式
def extract_info_online(self, image_path):
try:
from dashscope import MultiModalConversation
from dashscope.api_entities.dashscope_response import Role
# 确保环境变量已设置
os.environ["DASHSCOPE_API_KEY"] = DASHSCOPE_API_KEY
messages = [
{
"role": Role.USER,
"content": [
{"image": f"file://{os.path.abspath(image_path)}"},
{"text": """
请从这张施工打卡图片的水印中提取以下字段,只返回JSON,不要任何其他内容:
项目名称、施工区域、施工内容、拍摄时间、天气、地点、施工单位
没有则填“未识别”
"""}
]
}
]
response = MultiModalConversation.call(
model="qwen3.6-plus",
messages=messages,
timeout=30
)
text = response.output.choices[0].message.content[0]["text"]
text = text.strip().replace("```json", "").replace("```", "")
return json.loads(text)
except Exception as e:
logger.error(f"图片识别失败:{str(e)}")
return None
def write_to_base(self, data):
try:
token = self.get_tenant_token()
if not token:
return None
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{BASE_APP_TOKEN}/tables/{BASE_TABLE_ID}/records"
fields = {
"项目名称": data.get("项目名称", "未识别"),
"施工区域": data.get("施工区域", "未识别"),
"施工内容": data.get("施工内容", "未识别"),
"拍摄时间": data.get("拍摄时间", "未识别"),
"天气": data.get("天气", "未识别"),
"地点": data.get("地点", "未识别"),
"施工单位": data.get("施工单位", "未识别")
}
headers = {
"Authorization": f"Bearer {token}",
"Content-Type": "application/json"
}
resp = requests.post(url, json={"fields": fields}, headers=headers)
return resp.json()
except Exception as e:
logger.error(f"写入多维表格失败:{str(e)}")
return None
应用的主控逻辑—run 方法,把之前写好的各个功能模块串联起来,形成了一条完整的自动化流水线,最终返回一个飞书交互卡片
def run(self, image_key: str):
# 1. 下载图片
img_path = self.download_image(image_key)
if not img_path:
return "❌ 图片下载失败"
# 2. 识别信息
info = self.extract_info(img_path)
if not info:
return "❌ 图片信息识别失败"
# 3. 写入多维表格
write_result = self.write_to_base(info)
# 这里可以根据 write_result['code'] 判断是否写入成功
# 为了简单,我们暂时不检查返回码
# 4. 返回成功消息 (修改为卡片格式)
card_content = {
"config": {
"wide_screen_mode": True
},
"elements": [
{
"tag": "div",
"text": {
"content": f"✅ **打卡成功!**\n\n图片已识别并录入飞书多维表格。",
"tag": "lark_md"
}
},
{
"tag": "hr"
},
{
"tag": "div",
"text": {
"content": "**录入信息:**",
"tag": "lark_md"
}
},
{
"tag": "div",
"fields": [
{
"is_short": True,
"text": {
"content": f"**项目名称**\n{info.get('项目名称', '未识别')}",
"tag": "lark_md"
}
},
{
"is_short": True,
"text": {
"content": f"**施工区域**\n{info.get('施工区域', '未识别')}",
"tag": "lark_md"
}
},
{
"is_short": True,
"text": {
"content": f"**施工内容**\n{info.get('施工内容', '未识别')}",
"tag": "lark_md"
}
},
{
"is_short": True,
"text": {
"content": f"**拍摄时间**\n{info.get('拍摄时间', '未识别')}",
"tag": "lark_md"
}
},
{
"is_short": True,
"text": {
"content": f"**天气**\n{info.get('天气', '未识别')}",
"tag": "lark_md"
}
},
{
"is_short": True,
"text": {
"content": f"**地点**\n{info.get('地点', '未识别')}",
"tag": "lark_md"
}
}
]
}
],
"header": {
"title": {
"content": "施工打卡结果",
"tag": "plain_text"
},
"template": "green" # 绿色标题,表示成功
}
}
# 返回卡片对象
return {"type": "template", "data": card_content}
3.3 .md文件说明
本地大模型版
---
name: construction_checkin
version: 1.0.0
author: 你
description: 基于本地大模型的飞书施工打卡自动化处理系统
trigger:
keywords:
- 打卡
- 施工打卡
- 上传图片
permissions:
- im:message
- im:chat
- bitable:app
- file:read
- file:write
---
# 🏗️ 飞书施工打卡自动录入系统 (V1.0)
本技能旨在解决施工现场人员打卡信息录入繁琐的问题。通过**本地大模型**技术,实现从飞书群聊图片到多维表格的全自动结构化处理。
无需人工干预,发送图片并@机器人即可自动完成:
1. **图片下载与保存**:自动解析飞书消息,下载原图至本地指定目录。
2. **AI 视觉识别**:调用本地 Ollama 模型(Qwen3.5-32B)精准识别图片水印信息。
3. **数据入库**:将识别出的结构化数据自动写入飞书多维表格。
---
## ✨ 核心特性
### 1. 本地大模型驱动 (Offline AI)
* **隐私安全**:使用 `Ollama` 本地运行 `Qwen3.5` 大模型,图片数据无需上传至第三方云端,保障施工现场数据隐私。
* **稳定可靠**:不依赖外部网络 API,避免因网络波动或 API 额度限制导致的服务中断。
### 2. 智能自动化配置
* **自动 Bot ID 获取**:初始化时自动调用飞书 API 获取机器人 Open ID,无需手动配置硬编码。
* **Token 智能管理**:内置 Token 缓存机制与自动刷新逻辑,支持指数退避重试,确保服务长期稳定运行。
### 3. 严谨的触发逻辑
* **精准匹配**:“@机器人 + 发送图片”进行触发,避免误触。
* **防御性编程**:对消息格式、环境变量、文件路径进行全方位校验,防止程序崩溃。
---
## 📦 配置要求
### 环境依赖
1. **Python 3.9+**
2. **Ollama 服务**:需在本地或服务器运行,并已拉取模型。
* 推荐模型:`Qwen3.5-32b` 或 `Qwen3.5-35b` (代码中配置为 `Qwen3.5-35B-A3B-v3-Q8_0.gguf`)
3. **Python 库**:`copaw`, `dashscope` (备用), `ollama`, `python-dotenv`
### 环境变量 (.env)
请在项目根目录创建 `.env` 文件,填写以下配置:
```env
# 飞书机器人配置
LARK_APP_ID=cli_xxxxxxxx
LARK_APP_SECRET=sec_xxxxxxxx
# 飞书多维表格配置
BASE_APP_TOKEN=Basexxxxxxxx
BASE_TABLE_ID=tbl1xxxxxxxx
# 本地图片保存路径
SAVE_IMAGE_DIR=/path/to/your/image/folder
云端大模型版
---
name: construction_checkin
version: 1.0.0
author: 你
description: 基于云端大模型的飞书施工打卡自动化处理系统
trigger:
keywords:
- 打卡
- 施工打卡
permissions:
- im:message:read
- bitable:app:write
---
# 🏗️ 飞书施工打卡自动录入系统 (V1.0)
本技能旨在解决施工现场人员打卡信息录入繁琐的问题。通过**云端大模型**技术,实现从飞书群聊图片到多维表格的全自动结构化处理。
**核心流程**:
1. **智能监听**:精准识别群内 `@机器人 + 图片` 指令。
2. **云端识别**:利用通义千问 Qwen-VL 视觉模型,提取图片水印中的关键信息。
3. **数据入库**:将结构化数据自动写入飞书多维表格,生成可视化卡片反馈。
---
## ✨ 核心特性
### 1. 智能自动化配置 (Zero-Config)
* **自动 Bot ID 获取**:初始化时自动调用飞书 API 获取机器人 Open ID,彻底告别硬编码,提升部署灵活性。
* **Token 智能管理**:内置 Token 缓存机制与自动刷新逻辑,支持指数退避重试,确保服务长期稳定运行。
### 2. 精准触发逻辑
* **触发模式**:
* **@机器人 + 发送图片**:精准匹配 Bot ID,避免群内误触。
* **防御性编程**:对消息格式、环境变量、文件路径进行全方位校验,防止程序崩溃。
### 3. 云端高性能识别
* **Qwen-VL Plus 模型**:调用通义千问最新视觉模型,准确率高,响应速度快。
* **数据清洗机制**:自动去除 AI 返回结果中的 Markdown 代码块符号(```json),确保 JSON 解析稳定。
---
## 📦 配置要求
### 环境变量 (.env)
请在项目根目录创建 `.env` 文件,填写以下配置:
```env
# 飞书机器人配置 (必填)
LARK_APP_ID=cli_xxxxxxxx
LARK_APP_SECRET=sec_xxxxxxxx
# 飞书多维表格配置 (必填)
BASE_APP_TOKEN=Basexxxxxxxx
BASE_TABLE_ID=tbl1xxxxxxxx
# 通义千问 API Key (必填)
DASHSCOPE_API_KEY=sk-xxxxxxxx
# 本地图片保存路径 (必填)
SAVE_IMAGE_DIR=/path/to/your/image/folder
3.4 Skill技能包使用说明
1、根据个人的大模型使用情况(本地 OR 云端),下载不同版本的技能包
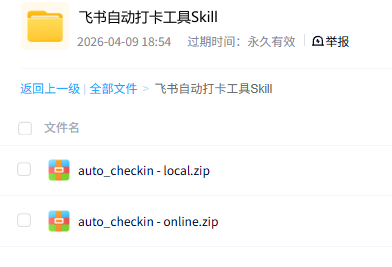
2、CoPaw - 工作区 - 技能 - 通过zip上传

3、适用频道改为“feishu”
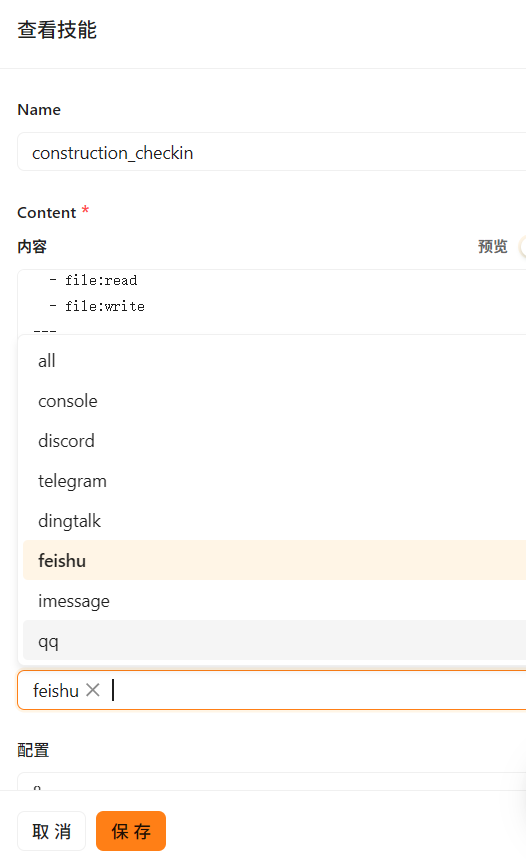
4、尝试通过飞书发送消息进行测试
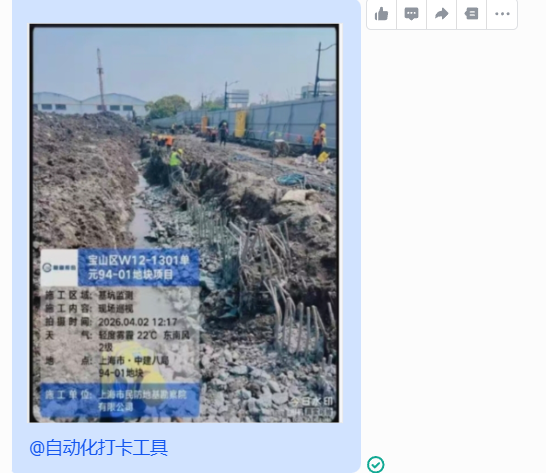
5、收到机器人自动回复,打卡成功
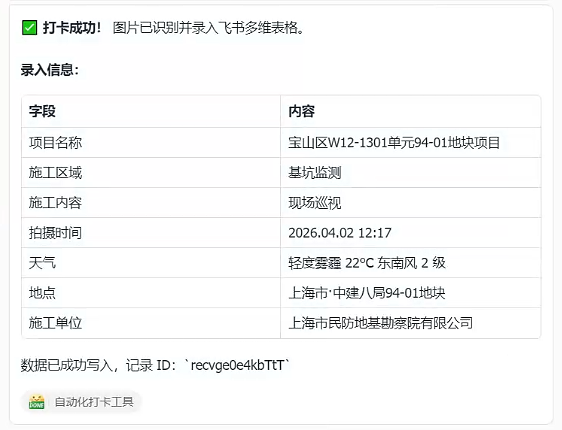
6、多维表格写入成功,测试成功

4. 问题
该技能包主要通过python代码的形式进行了自动化处理,目前机器人可以自动化完成整个全过程,但是依旧存在以下问题:
- CoPaw在接受到飞书的图片之后,会自动存入缓存区,由缓存区下载至本地,再进行后续操作。操作结束之后,机器人尝试删除缓存区数据,但是被CoPaw的安全策略拦截。目前的解决方案是,关闭CoPaw的安全策略,或者强制CoPaw在删除缓存时不需要询问。此问题可能导致流程中断。
- 图片识别的幻觉性问题,在测试过程中出现识别时间不准确问题。
- 机器人回复速度慢,回复时无法@发信人。比如A进行打卡,机器人在完成录入之后,@A提示打卡成功。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)